
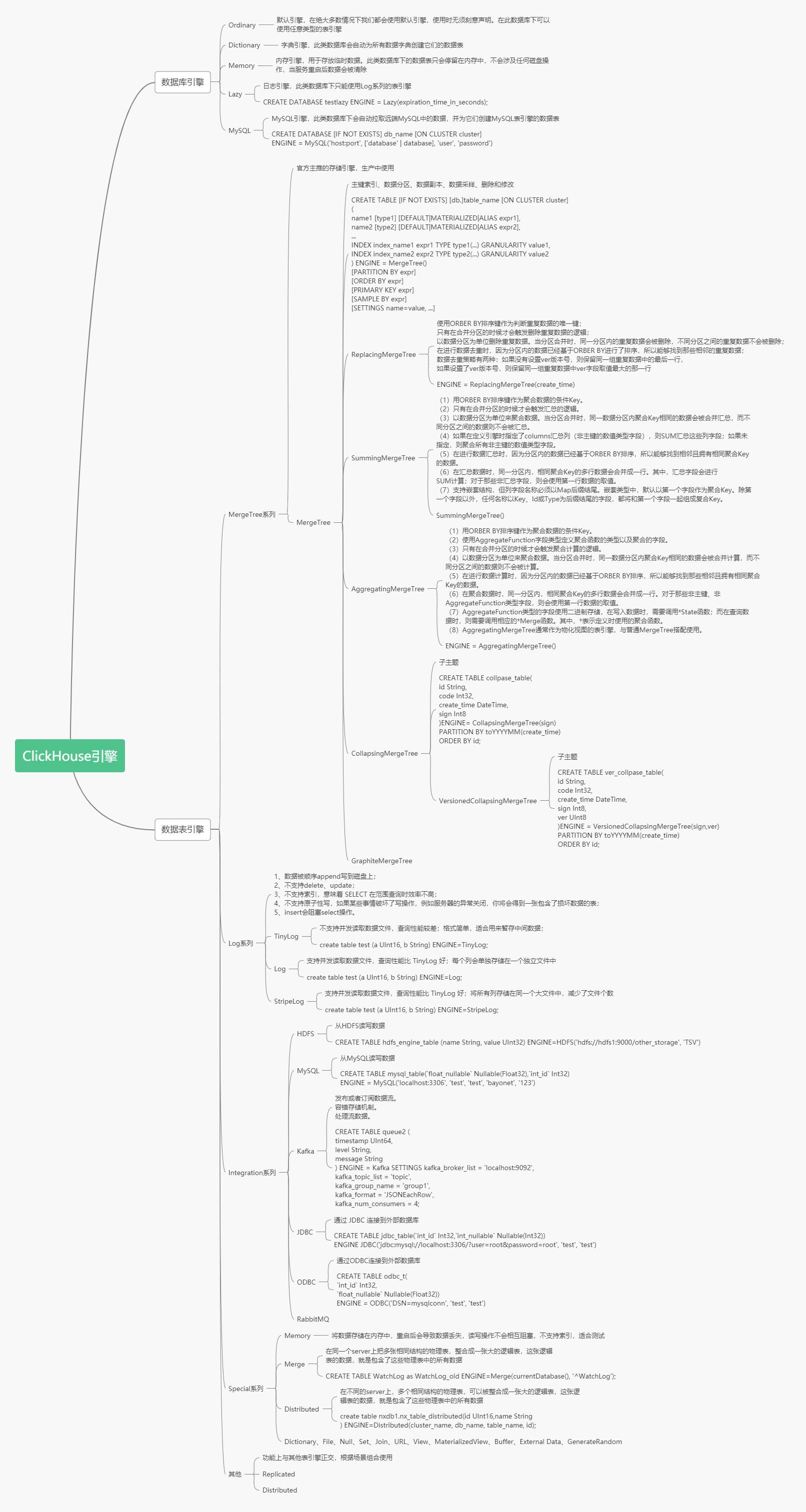
# ClickHouse引擎
數據庫引擎默認是Ordinary,在這種數據庫下面的表可以是任意類型引擎。
表引擎是ClickHouse設計實現中的一大特色 ,數據表擁有何種特性、數據以何種形式被存儲以及如何被加載。ClickHouse擁有非常龐大的表引擎體系。
生產環境中常用的表引擎是MergeTree系列,也是官方主推的引擎。MergeTree是基礎引擎,有主鍵索引、數據分區、數據副本、數據采樣、刪除和修改等功能,ReplacingMergeTree有了去重功能,SummingMergeTree有了匯總求和功能,AggregatingMergeTree有聚合功能,CollapsingMergeTree有折疊刪除功能,VersionedCollapsingMergeTree有版本折疊功能,GraphiteMergeTree有壓縮匯總功能。在這些的基礎上還可以疊加Replicated和Distributed。
Integration系列用于集成外部的數據源,常用的有HADOOP,MySQL。
## 數據庫引擎
## 表引擎
### Memory引擎
讀寫操作不會相互阻塞。不支持索引。查詢是并行化的。在簡單查詢上達到最大速率(超過10 GB /秒),因為沒有磁盤讀取,不需要解壓縮或反序列化數據。(值得注意的是,在許多情況下,與 MergeTree 引擎的性能幾乎一樣高)。重新啟動服務器時,表中的數據消失,表將變為空。通常,使用此表引擎是不合理的。但是,它可用于測試。
### LOG引擎系列
#### Log系列表引擎的特點
#### 共性特點
* 數據存儲在磁盤上
* 當寫數據時,將數據追加到文件的末尾
* 不支持**并發讀寫**,當向表中寫入數據時,針對這張表的查詢會被阻塞,直至寫入動作結束
* 不支持索引
* 不支持原子寫:如果某些操作(異常的服務器關閉)中斷了寫操作,則可能會獲得帶有損壞數據的表
* 不支持**ALTER操作**(這些操作會修改表設置或數據,比如delete、update等等)
#### 區別
* **TinyLog**
TinyLog是Log系列引擎中功能簡單、性能較低的引擎。它的存儲結構由數據文件和元數據兩部分組成。其中,**數據文件是按列獨立存儲的,也就是說每一個列字段都對應一個文件**。除此之外,TinyLog不支持并發數據讀取。
* **StripLog**支持并發讀取數據文件,當讀取數據時,ClickHouse會使用多線程進行讀取,每個線程處理一個單獨的數據塊。另外,**StripLog將所有列數據存儲在同一個文件中**,減少了文件的使用數量。
* **Log**支持并發讀取數據文件,當讀取數據時,ClickHouse會使用多線程進行讀取,每個線程處理一個單獨的數據塊。**Log引擎會將每個列數據單獨存儲在一個獨立文件中**。\*\*\*\*
| 引擎 | 存儲文件數 | 并行查詢 | 效率 | mark文件 | 適用場景 |
| --- | --- | --- | --- | --- | --- |
| Log | 每列一個文件 | 支持 | 高 | 有 | 適用于臨時數據,一次性寫入、測試場景 |
| StripeLog | 所有列一個文件 | 支持 | 較高 | 有 | 在你需要寫入許多小數據量(小于一百萬行)的表的場景下使用這個引擎。 |
| TinyLog | 每列一個文件 | 不支持 | 低 | 無 | 適用于**一次寫入,多次讀取的場景**。對于處理小批數據的中間表可以使用該引擎。值得注意的是,使用大量的小表存儲數據,性能會很低。 |
* * *
1)LOG引擎
日志與 TinyLog 的不同之處在于,標記的小文件與列文件存在一個文件夾里。這些標記在每個數據塊上,并且包含偏移量,這些偏移量指示從哪里開始讀取文件以便跳過指定的行數。這使得可以在多個線程中讀取表數據。對于并發數據訪問,可以同時執行讀取操作,而寫入操作則阻塞讀取和其它寫入。Log 引擎不支持索引。同樣,如果寫入表失敗,則該表將被破壞,并且從該表讀取將返回錯誤。
~~~
create table tb_log(id String,name String)engine=Log
~~~
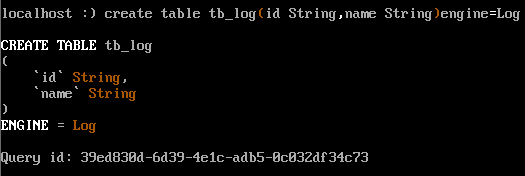
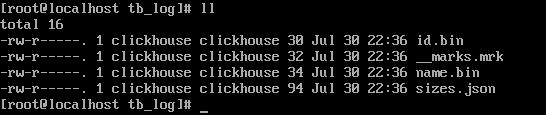
* 列.bin:數據文件,數據文件按列單獨存儲
* \_\_marks.mrk:數據標記,統一保存了數據在各個.bin文件中的位置信息。利用數據標記能夠使用多個線程,以并行的方式讀取。.bin內的壓縮數據塊,從而提升數據查詢的性能。
* sizes.json:記錄了.bin和\_\_marks.mrk大小的信息
每一次的INSERT操作,都會對應一個數據塊
支持多線程處理
并發讀寫
* * *
2)TinyLog引擎
最簡單的表引擎,用于將數據存儲在磁盤上。每列都存儲在單獨的壓縮文件中,寫入時,數據將附加到文件末尾。該引擎沒有并發控制。
create table tb\_tinylog (
id String,
name String,
age UInt8
)engine=TinyLog;
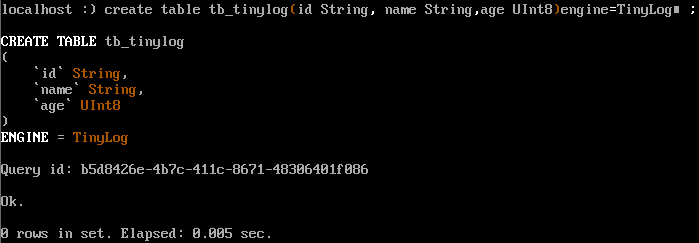
插入數據,看存儲的文件結構:
1、最簡單的引擎
2、沒有標記塊
3、寫入操作是追加寫
4、數據以列字段文件存儲
5、不允許同時讀寫
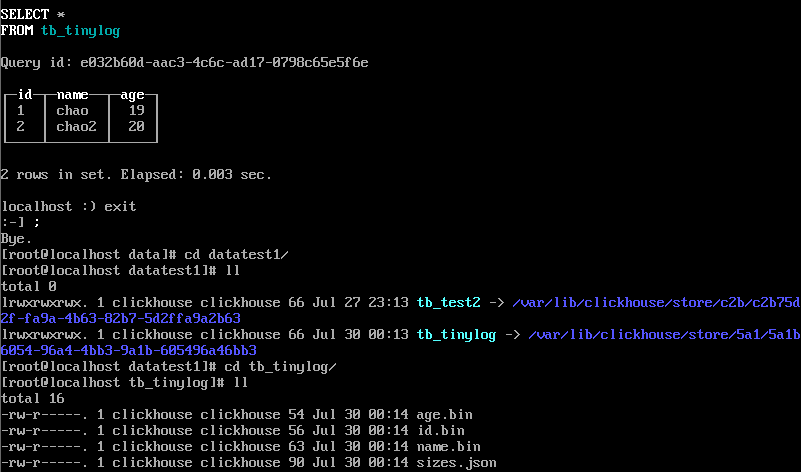
**如果操作寫入失敗,會損壞表結構,只能刪除表,刪除表需要刪除data下的該表結構和metadata下的該表元數據**
* * *
3)StripeLog引擎
在你需要寫入許多小數據量(小于一百萬行)的表的場景下使用這個引擎。
~~~
create table test_stripelog( id UInt8 , name String , age UInt8)engine=StripeLog ;
~~~
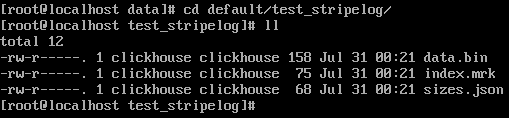
* data.bin:數據文件,所有的列字段使用同一個文件保存,它們的數據都會被寫入data.bin。
* index.mrk:數據標記,保存了數據在data.bin文件中的位置信息(每個插入數據塊對應列的offset),利用數據標記能夠使用多個線程,以并行的方式讀取data.bin內的壓縮數據塊,從而提升數據查詢的性能。
* sizes.json:元數據文件,記錄了data.bin和index.mrk大小的信息
每次的**INSERT**操作,ClickHouse會將**數據塊**追加到表文件的末尾
### MergeTree引擎
在所有的表引擎中,最為核心的當屬MergeTree系列表引擎,這些表引擎擁有最為強大的性能和最廣泛的使用場合。對于非MergeTree系列的其他引擎而言,主要用于特殊用途,場景相對有限。而MergeTree系列表引擎是官方主推的存儲引擎,支持幾乎所有ClickHouse核心功能。
MergeTree在寫入一批數據時,數據總會以數據片段的形式寫入磁盤,且數據片段不可修改。為了避免片段過多,ClickHouse會通過后臺線程,定期合并這些數據片段,屬于相同分區的數據片段會被合成一個新的片段。這種數據片段往復合并的特點,也正是合并樹名稱的由來。
MergeTree作為家族系列最基礎的表引擎,主要有以下特點:
* 存儲的數據按照主鍵排序:允許創建稀疏索引,從而加快數據查詢速度
* 支持分區,可以通過PRIMARY KEY語句指定分區字段。
* 支持數據副本
* 支持數據采樣
* 在MergeTree中主鍵并不用于去重,而是用于索引,加快查詢速度
* 創建表
~~~
create table tb_merge_tree(
uid UIn8,
name String,
birthday Date,
city String,
gender String
)engine =MergeTree()
primary key uid
order by (uid,birthday)
~~~
* 插入數據
~~~
insert into tb_merge_tree values(1,'南京',toDate(now()),'南京','男'),(1,'南京2',toDate('1996-7-25'),'南京','男')
insert into tb_merge_tree values(1,'南京3',toDate(now()),'南京','M'),(1,'南京4',toDate('1996-7-25'),'南京','M')
~~~

/var/lib/clickhouse/data/下數據文件
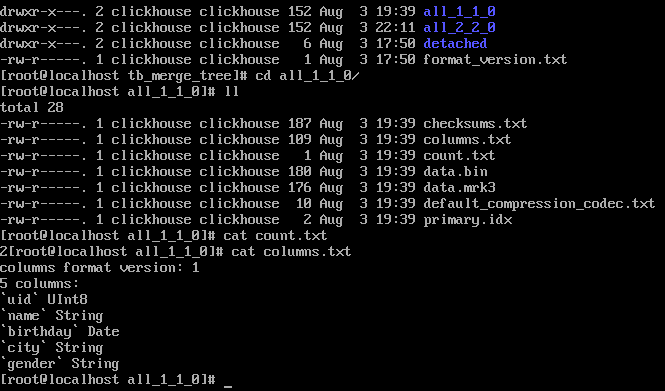
* 合并數據
~~~
optimize table tb_merge_tree final ;
~~~
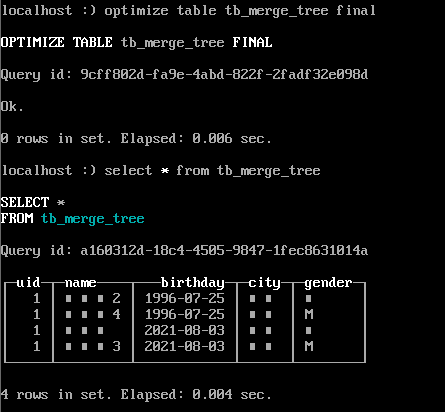
合并后/var/lib/clickhouse/data/下數據文件多出一個all\_1\_2\_1的文件夾,其中第一個數字代表最小版本,第二個數據代表最大的版本,第三個數字代表第幾次合并。

### ReplacingMergeTree表引擎
上文提到**MergeTree**表引擎無法對相同主鍵的數據進行去重,ClickHouse提供了ReplacingMergeTree引擎,可以針對相同主鍵的數據進行去重,它能夠在合并分區時刪除重復的數據。值得注意的是,**ReplacingMergeTree**只是在一定程度上解決了數據重復問題,但是并不能完全保障數據不重復。
~~~
CREATETABLE?emp_replacingmergetree?(
??emp_id?UInt16?COMMENT'員工id',
nameStringCOMMENT'員工姓名',
??work_place?StringCOMMENT'工作地點',
??age?UInt8?COMMENT'員工年齡',
??depart?StringCOMMENT'部門',
??salary?Decimal32(2)?COMMENT'工資'
??)ENGINE=ReplacingMergeTree()
ORDERBY?emp_id
PRIMARY?KEY?emp_id
PARTITIONBY?work_place
??;
--?插入數據?
INSERTINTO?emp_replacingmergetree
VALUES?(1,'tom','上海',25,'技術部',20000),(2,'jack','上海',26,'人事部',10000);
INSERTINTO?emp_replacingmergetree
VALUES?(3,'bob','北京',33,'財務部',50000),(4,'tony','杭州',28,'銷售事部',50000);
~~~
ReplacingMergeTree在去除重復數據時,是以ORDERBY排序鍵為基準的,而不是PRIMARY KEY
執行合并,相同主鍵的數據,保留最近插入的數據,舊的數據被清除
只有在相同的數據分區內重復的數據才可以被刪除,而不同數據分區之間的重復數據依然不能被剔除
### SummingMergeTree表引擎
### Aggregatingmergetree表引擎
### CollapsingMergeTree表引擎
### VersionedCollapsingMergeTree表引擎
### GraphiteMergeTree表引擎
### 文件表引擎
數據源是以 Clickhouse 支持的一種輸入格式(TabSeparated,Native等)存儲數據的文件。
* 從 ClickHouse 導出數據到文件。
* 將數據從一種格式轉換為另一種格式。
* 通過編輯磁盤上的文件來更新 ClickHouse 中的數據。
* TabSeparated格式
~~~
CREATE TABLE file_engine_table (name String, value UInt32) ENGINE=File(TabSeparated)
~~~
默認情況下,Clickhouse 會創建目錄`/var/lib/clickhouse/data/default/file_engine_table`。
手動創建`/var/lib/clickhouse/data/default/file_engine_table/data.TabSeparated`文件,并且包含內容:
文件命名必須是data.TabSeparated
文件內容:
~~~
$ cat data.TabSeparated
one 1
two 2
~~~
* CSV格式
~~~
create table tb_file_demo2(uid UInt16,name String)engine=File(CSV)
~~~
在/var/lib/clickhouse/data/文件夾下創建data.CSV文件
~~~
vi data.CSV
11 aa
22 bb
~~~
* local語法
這種方式不會創建表,可以查詢數據,并且表引擎只能是File
~~~
-- 0或stdin,1或stdout
cat user.CSV | clickhouse-local -q "create table tb_file3(id Int8,name String)engine=File(CSV,stdin)";
~~~

* client語法
~~~
可以指定任意表引擎
create table tb_client(id Uint8,name String)engine=TinyLog;
-- 導入數據
cat user.CSV | clickhouse-client -q "insert into tb_client FORMAT CSV"
-- 自定義分隔符--format_csv_delimiter,指定數據庫-d
cat user.txt | clickhouse-client -q --format_csv_delimiter = '|' -d datatest1 'insert into tb_client FORMAT CSV'
~~~
表引擎參考文章:[https://my.oschina.net/maoxiang/blog/4617507](https://my.oschina.net/maoxiang/blog/4617507)
- ClickHouse
- 第一節 ClickHouse入門
- 1.1 ClickHouse概述
- 1.2 ClickHouse單機安裝
- 1.3 ClickHouse配置
- 1.4 ClickHouse數據庫引擎
- 1.5 ClickHouse集群部署
- 第二節 ClickHouse進階
- 2.1 ClicKHouse數據類型
- 2.2 ClicKHouse基本語法
- 2.3 ClickHouse引擎
- 2.4 ClickHouse函數
- 2.5 ClickHouse分布式表
- 2.6 ClickHouse權限和密碼加密
- 2.7 ClickHouse數據導入和導出
- 第三節 ClicKHouse實戰篇
- 3.1 ClickHouse的JDBC連接
- 3.2 ClickHouse用戶行為分析
- 3.3 ClickHouse實戰
- 第四節 ClicKHouse常見問題
- 4.1 ClickHouse常見問題匯總
- 第五節 ClickHouse其他
- 5.1 ClickHouse可視化工具
- 5.2 ClickHouse學習教程