
# Kubernetes核心技術Pod
## Pod概述
Pod是K8S系統中可以創建和管理的最小單元,是資源對象模型中由用戶創建或部署的最小資源對象模型,也是在K8S上運行容器化應用的資源對象,其它的資源對象都是用來支撐或者擴展Pod對象功能的,比如控制器對象是用來管控Pod對象的,Service或者Ingress資源對象是用來暴露Pod引用對象的,PersistentVolume資源對象是用來為Pod提供存儲等等,K8S不會直接處理容器,而是Pod,Pod是由一個或多個container組成。
Pod是Kubernetes的最重要概念,每一個Pod都有一個特殊的被稱為 “根容器”的Pause容器。Pause容器對應的鏡像屬于Kubernetes平臺的一部分,除了Pause容器,每個Pod還包含一個或多個緊密相關的用戶業務容器。
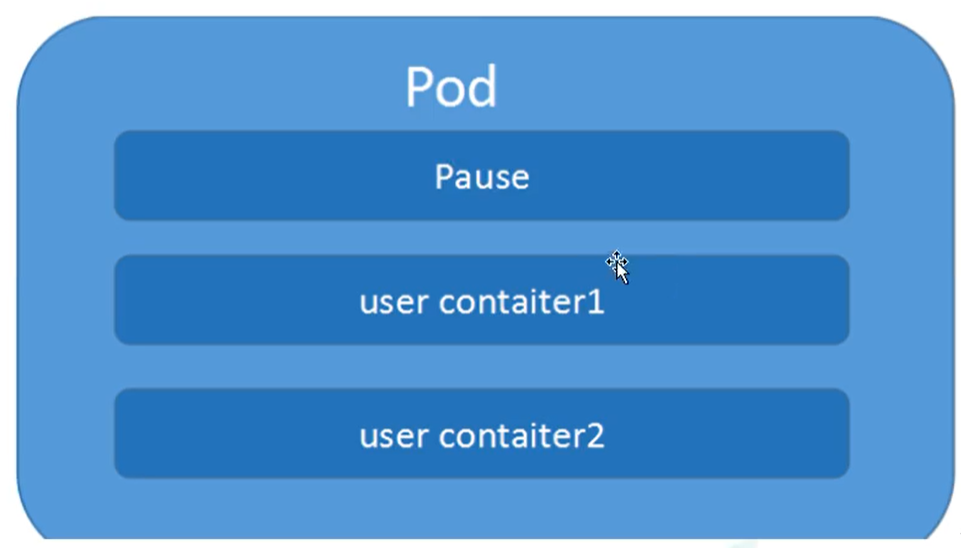
### Pod基本概念
- 最小部署的單元
- Pod里面是由一個或多個容器組成【一組容器的集合】
- 一個pod中的容器是共享網絡命名空間
- Pod是短暫的
- 每個Pod包含一個或多個緊密相關的用戶業務容器
### Pod存在的意義
- 創建容器使用docker,一個docker對應一個容器,一個容器運行一個應用進程
- Pod是多進程設計,運用多個應用程序,也就是一個Pod里面有多個容器,而一個容器里面運行一個應用程序
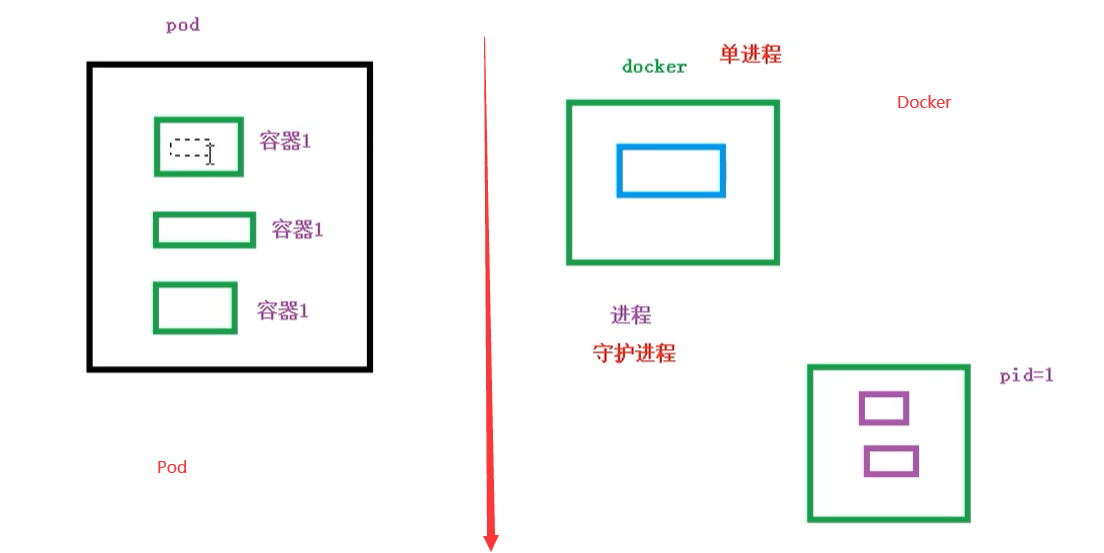
- Pod的存在是為了親密性應用
- 兩個應用之間進行交互
- 網絡之間的調用【通過127.0.0.1 或 socket】
- 兩個應用之間需要頻繁調用
Pod是在K8S集群中運行部署應用或服務的最小單元,它是可以支持多容器的。Pod的設計理念是支持多個容器在一個Pod中共享網絡地址和文件系統,可以通過進程間通信和文件共享這種簡單高效的方式組合完成服務。同時Pod對多容器的支持是K8S中最基礎的設計理念。在生產環境中,通常是由不同的團隊各自開發構建自己的容器鏡像,在部署的時候組合成一個微服務對外提供服務。
Pod是K8S集群中所有業務類型的基礎,可以把Pod看作運行在K8S集群上的小機器人,不同類型的業務就需要不同類型的小機器人去執行。目前K8S的業務主要可以分為以下幾種
- 長期伺服型:long-running
- 批處理型:batch
- 節點后臺支撐型:node-daemon
- 有狀態應用型:stateful application
上述的幾種類型,分別對應的小機器人控制器為:Deployment、Job、DaemonSet 和 StatefulSet (后面將介紹控制器)
## Pod實現機制
主要有以下兩大機制
- 共享網絡
- 共享存儲
### 共享網絡
容器本身之間相互隔離的,一般是通過 **namespace** 和 **group** 進行隔離,那么Pod里面的容器如何實現通信?
- 首先需要滿足前提條件,也就是容器都在同一個**namespace**之間
關于Pod實現原理,首先會在Pod會創建一個根容器: `pause容器`,然后我們在創建業務容器 【nginx,redis 等】,在我們創建業務容器的時候,會把它添加到 `info容器` 中
而在 `info容器` 中會獨立出 ip地址,mac地址,port 等信息,然后實現網絡的共享
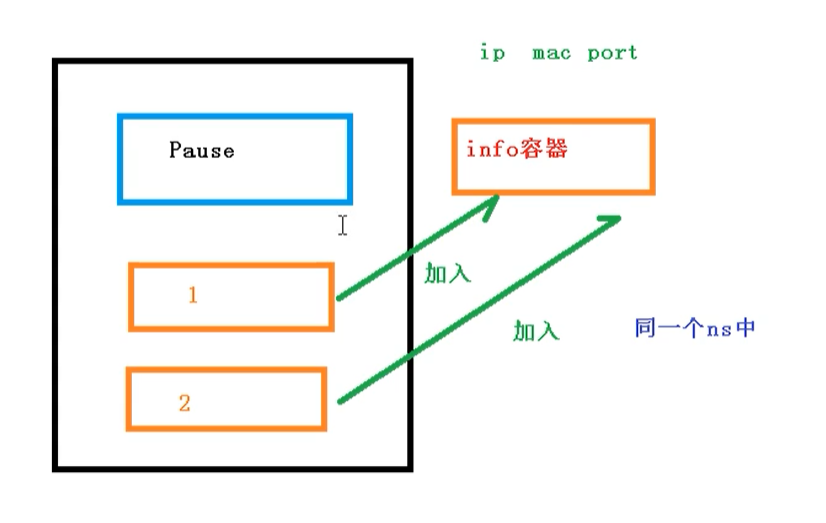
完整步驟如下
- 通過 Pause 容器,把其它業務容器加入到Pause容器里,讓所有業務容器在同一個名稱空間中,可以實現網絡共享
### 共享存儲
Pod持久化數據,專門存儲到某個地方中
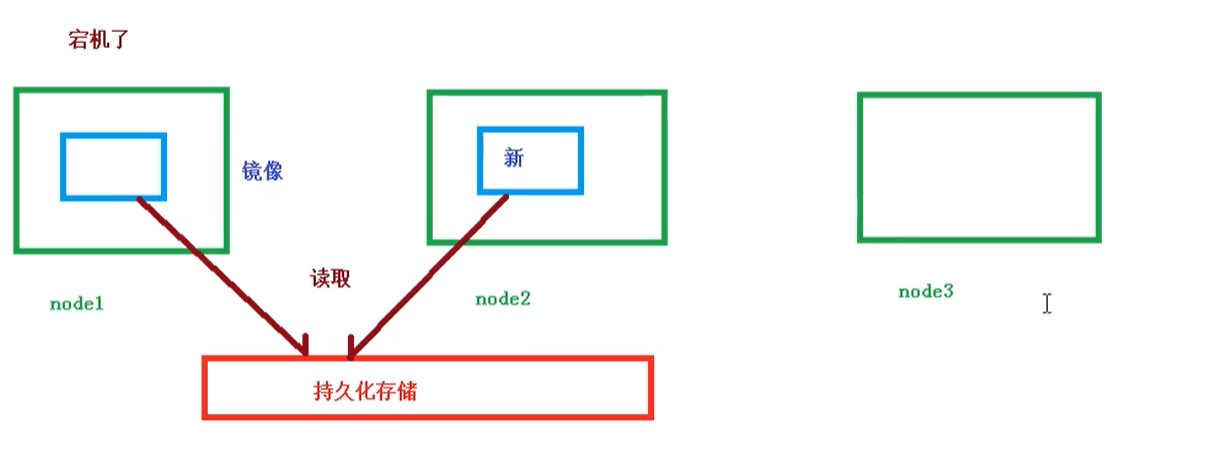
使用 Volumn數據卷進行共享存儲,案例如下所示

## Pod鏡像拉取策略
我們以具體實例來說,拉取策略就是 `imagePullPolicy`

拉取策略主要分為了以下幾種
- IfNotPresent:默認值,鏡像在宿主機上不存在才拉取
- Always:每次創建Pod都會重新拉取一次鏡像
- Never:Pod永遠不會主動拉取這個鏡像
## Pod資源限制
也就是我們Pod在進行調度的時候,可以對調度的資源進行限制,例如我們限制 Pod調度是使用的資源是 2C4G,那么在調度對應的node節點時,只會占用對應的資源,對于不滿足資源的節點,將不會進行調度
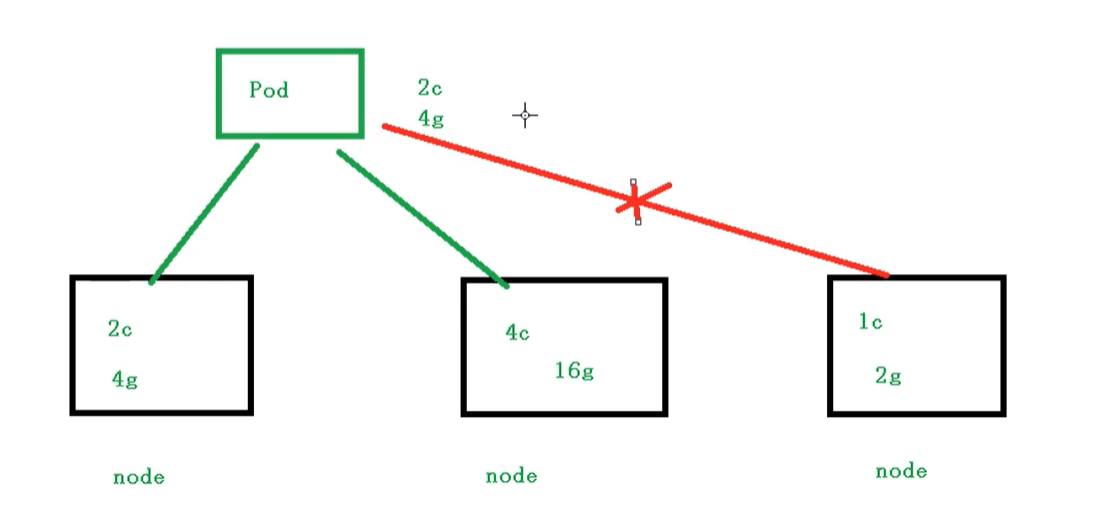
### 示例
我們在下面的地方進行資源的限制
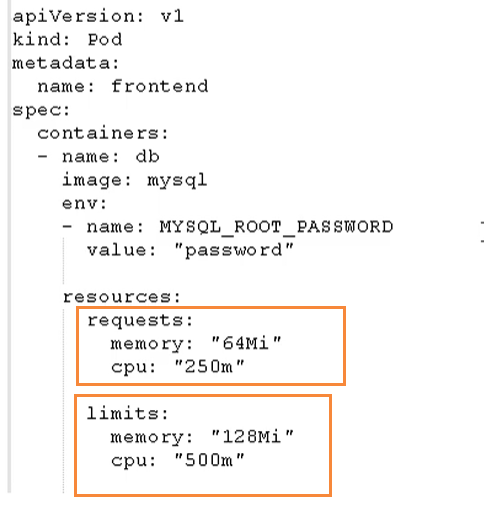
這里分了兩個部分
- request:表示調度所需的資源
- limits:表示最大所占用的資源
## Pod重啟機制
因為Pod中包含了很多個容器,假設某個容器出現問題了,那么就會觸發Pod重啟機制
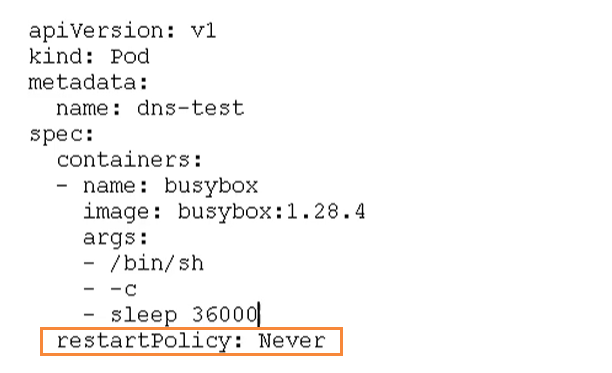
重啟策略主要分為以下三種
- Always:當容器終止退出后,總是重啟容器,默認策略 【nginx等,需要不斷提供服務】
- OnFailure:當容器異常退出(退出狀態碼非0)時,才重啟容器。
- Never:當容器終止退出,從不重啟容器 【批量任務】
## Pod健康檢查
通過容器檢查,原來我們使用下面的命令來檢查
```bash
kubectl get pod
```
但是有的時候,程序可能出現了 **Java** 堆內存溢出,程序還在運行,但是不能對外提供服務了,這個時候就不能通過 容器檢查來判斷服務是否可用了
這個時候就可以使用應用層面的檢查
```bash
# 存活檢查,如果檢查失敗,將殺死容器,根據Pod的restartPolicy【重啟策略】來操作
livenessProbe
# 就緒檢查,如果檢查失敗,Kubernetes會把Pod從Service endpoints中剔除
readinessProbe
```

Probe支持以下三種檢查方式
- http Get:發送HTTP請求,返回200 - 400 范圍狀態碼為成功
- exec:執行Shell命令返回狀態碼是0為成功
- tcpSocket:發起TCP Socket建立成功
## Pod調度策略
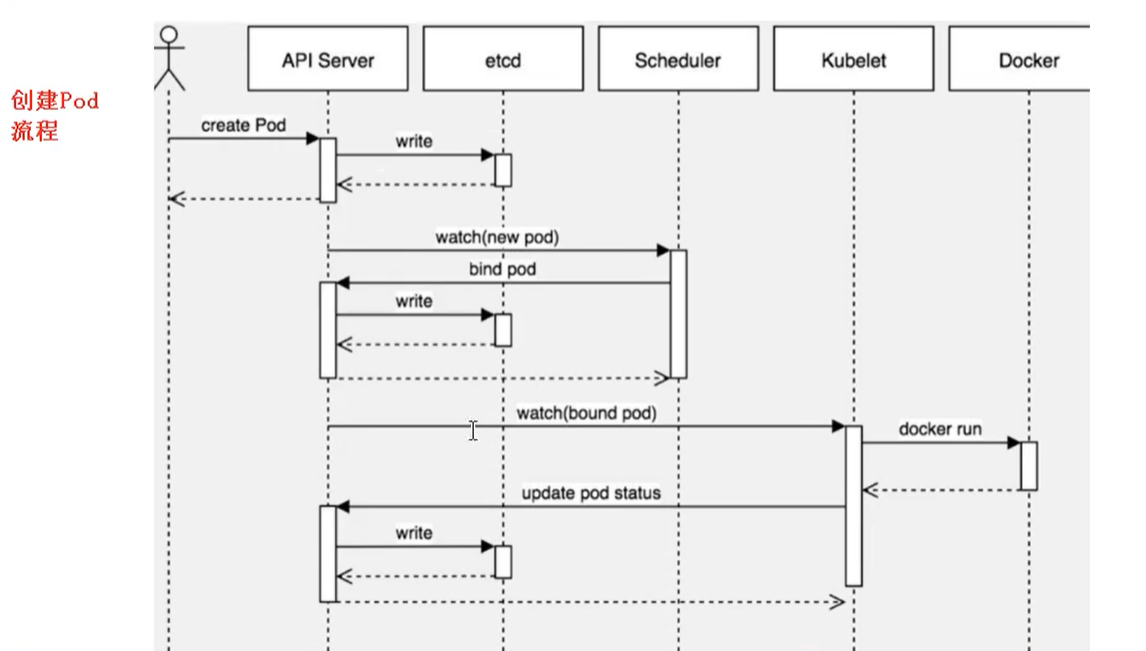
### 創建Pod流程
- 首先創建一個pod,然后創建一個API Server 和 Etcd【把創建出來的信息存儲在etcd中】
- 然后創建 Scheduler,監控API Server是否有新的Pod,如果有的話,會通過調度算法,把pod調度某個node上
- 在node節點,會通過 `kubelet -- apiserver ` 讀取etcd 拿到分配在當前node節點上的pod,然后通過docker創建容器
### 影響Pod調度的屬性
Pod資源限制對Pod的調度會有影響
#### 根據request找到足夠node節點進行調度

#### 節點選擇器標簽影響Pod調度

關于節點選擇器,其實就是有兩個環境,然后環境之間所用的資源配置不同
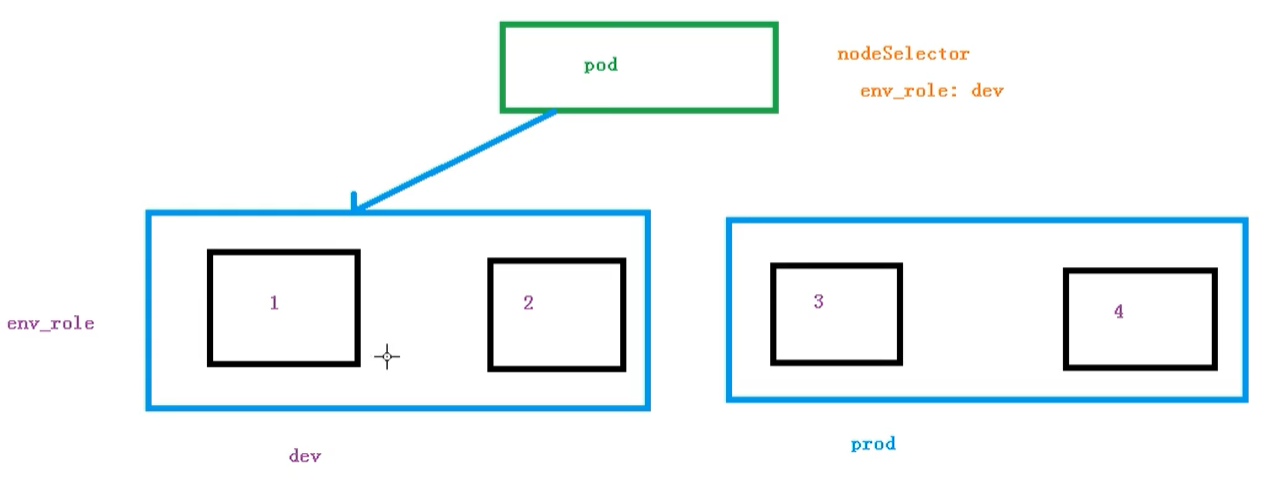
我們可以通過以下命令,給我們的節點新增標簽,然后節點選擇器就會進行調度了
```bash
kubectl label node node1 env_role=prod
```
#### 節點親和性
節點親和性 **nodeAffinity** 和 之前nodeSelector 基本一樣的,根據節點上標簽約束來決定Pod調度到哪些節點上
- 硬親和性:約束條件必須滿足
- 軟親和性:嘗試滿足,不保證

支持常用操作符:in、NotIn、Exists、Gt、Lt、DoesNotExists
反親和性:就是和親和性剛剛相反,如 NotIn、DoesNotExists等
## 污點和污點容忍
### 概述
nodeSelector 和 NodeAffinity,都是Prod調度到某些節點上,屬于Pod的屬性,是在調度的時候實現的。
Taint 污點:節點不做普通分配調度,是節點屬性
### 場景
- 專用節點【限制ip】
- 配置特定硬件的節點【固態硬盤】
- 基于Taint驅逐【在node1不放,在node2放】
### 查看污點情況
```bash
kubectl describe node k8smaster | grep Taint
```

污點值有三個
- NoSchedule:一定不被調度
- PreferNoSchedule:盡量不被調度【也有被調度的幾率】
- NoExecute:不會調度,并且還會驅逐Node已有Pod
### 未節點添加污點
```bash
kubectl taint node [node] key=value:污點的三個值
```
舉例:
```bash
kubectl taint node k8snode1 env_role=yes:NoSchedule
```
### 刪除污點
```bash
kubectl taint node k8snode1 env_role:NoSchedule-
```

### 演示
我們現在創建多個Pod,查看最后分配到Node上的情況
首先我們創建一個 nginx 的pod
```bash
kubectl create deployment web --image=nginx
```
然后使用命令查看
```bash
kubectl get pods -o wide
```

我們可以非常明顯的看到,這個Pod已經被分配到 k8snode1 節點上了
下面我們把pod復制5份,在查看情況pod情況
```bash
kubectl scale deployment web --replicas=5
```
我們可以發現,因為master節點存在污點的情況,所以節點都被分配到了 node1 和 node2節點上

我們可以使用下面命令,把剛剛我們創建的pod都刪除
```bash
kubectl delete deployment web
```
現在給了更好的演示污點的用法,我們現在給 node1節點打上污點
```bash
kubectl taint node k8snode1 env_role=yes:NoSchedule
```
然后我們查看污點是否成功添加
```bash
kubectl describe node k8snode1 | grep Taint
```

然后我們在創建一個 pod
```bash
# 創建nginx pod
kubectl create deployment web --image=nginx
# 復制五次
kubectl scale deployment web --replicas=5
```
然后我們在進行查看
```bash
kubectl get pods -o wide
```
我們能夠看到現在所有的pod都被分配到了 k8snode2上,因為剛剛我們給node1節點設置了污點

最后我們可以刪除剛剛添加的污點
```bash
kubectl taint node k8snode1 env_role:NoSchedule-
```
### 污點容忍
污點容忍就是某個節點可能被調度,也可能不被調度

- Kubernetes簡介
- 搭建K8S集群前置知識
- 使用kubeadm方式搭建K8S集群
- 使用二進制方式搭建K8S集群
- Kubeadm和二進制方式對比
- Kubernetes集群管理工具kubectl
- Kubernetes集群YAML文件詳解
- Kubernetes核心技術Pod
- Kubernetes核心技術Controller
- Kubernetes核心技術Service
- Kubernetes控制器Controller詳解
- Kubernetes配置管理
- Kubernetes集群安全機制
- Kubernetes核心技術Ingress
- Kubernetes核心技術Helm
- Kubernetes持久化存儲
- Kubernetes集群資源監控
- Kubernetes搭建高可用集群
- Kubernetes容器交付介紹
- 使用kubeadm-ha腳本一鍵安裝K8S
- Kubernetes可視化界面kubesphere
- Kubernetes配置默認存儲類
- 使用Rancher搭建Kubernetes集群
- Kubernetes中的CRI