這里以官網的一個入門案例來進行回顧:
### 1. 導入包
```
import tensorflow as tf
```
### 2. 準備和處理數據集
```
// [MNIST 數據集](http://yann.lecun.com/exdb/mnist/)
mnist = tf.keras.datasets.mnist
// 加載訓練集和測試集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
```
由于圖片的構成為0-255的值,且含有三個維度,所以這里為了方便進行灰度處理,也就是:
```
x_train, x_test = x_train / 255.0, x_test / 255.0
```
將其數值整到0-1的范圍,其維度不變,這里不妨看下維度信息:
```
x_train.shape
y_train.shape
```
結果為:

### 3. 定義模型
示例中使用的是序列接模型:
```
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
```
使用Flatten來將三維數據扁平化,變為二維數據,也就是60000x768。Dense為一個全連接層,定義為:
~~~
`output = activation(dot(input, kernel) + bias)`
~~~
傳入的128,也就是units,表示輸出的維度。activation為激活函數,當然它還有其余的參數:
~~~
tf.keras.layers.Dense(units, activation=None, use_bias=True,
kernel_initializer='glorot_uniform',? ? bias_initializer='zeros',
kernel_regularizer=None,? ? bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None,? ? bias_constraint=None, **kwargs)
~~~

注意到這里只指定了輸出的維度為128,而沒有想第一層Flatten中指定input_shape,因為默認程序自己可以知道,所以不必設置。
Dropout定義為:
~~~
tf.keras.layers.Dropout(rate, noise_shape=None, seed=None, **kwargs)
~~~
主要用來防止過擬合,也就是:Dropout層在訓練期間的每一步中將輸入單位隨機設置為0,未設置為0的輸入將按1 /(1\-rate)放大,以使**所有輸入的總和不變**。比如在官網中給的例子:

### 4. 模型訓練
先指定一下優化器,損失函數和度量值:
```
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
```
不妨看下模型參數量:
```
model.summary()
```

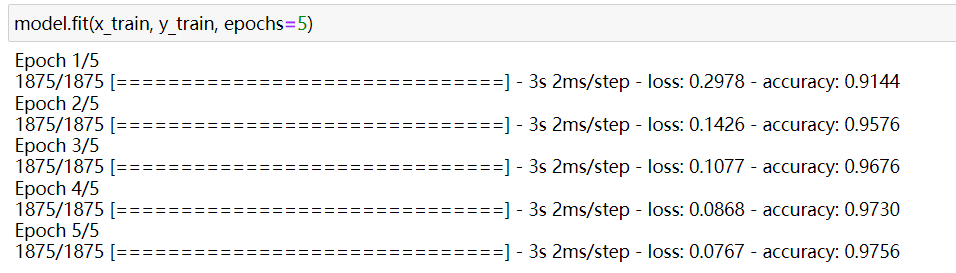
然后進行擬合數據,訓練:
```
model.fit(x_train, y_train, epochs=5)
```
可以看見訓練過程中的結果:
### 5. 模型評估
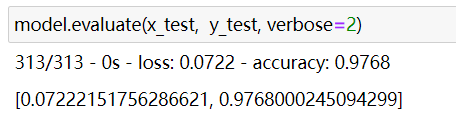
```
model.evaluate(x_test, y_test, verbose=2)
```