
## 綜述
爬蟲入門之后,我們有兩條路可以走。
一個是繼續深入學習,以及關于設計模式的一些知識,強化Python相關知識,自己動手造輪子,繼續為自己的爬蟲增加分布式,多線程等功能擴展。另一條路便是學習一些優秀的框架,先把這些框架用熟,可以確保能夠應付一些基本的爬蟲任務,也就是所謂的解決溫飽問題,然后再深入學習它的源碼等知識,進一步強化。
就個人而言,前一種方法其實就是自己動手造輪子,前人其實已經有了一些比較好的框架,可以直接拿來用,但是為了自己能夠研究得更加深入和對爬蟲有更全面的了解,自己動手去多做。后一種方法就是直接拿來前人已經寫好的比較優秀的框架,拿來用好,首先確保可以完成你想要完成的任務,然后自己再深入研究學習。第一種而言,自己探索的多,對爬蟲的知識掌握會比較透徹。第二種,拿別人的來用,自己方便了,可是可能就會沒有了深入研究框架的心情,還有可能思路被束縛。
不過個人而言,我自己偏向后者。造輪子是不錯,但是就算你造輪子,你這不也是在基礎類庫上造輪子么?能拿來用的就拿來用,學了框架的作用是確保自己可以滿足一些爬蟲需求,這是最基本的溫飽問題。倘若你一直在造輪子,到最后都沒造出什么來,別人找你寫個爬蟲研究了這么長時間了都寫不出來,豈不是有點得不償失?所以,進階爬蟲我還是建議學習一下框架,作為自己的幾把武器。至少,我們可以做到了,就像你拿了把槍上戰場了,至少,你是可以打擊敵人的,比你一直在磨刀好的多吧?
## 框架概述
博主接觸了幾個爬蟲框架,其中比較好用的是 Scrapy 和PySpider。就個人而言,pyspider上手更簡單,操作更加簡便,因為它增加了 WEB 界面,寫爬蟲迅速,集成了phantomjs,可以用來抓取js渲染的頁面。Scrapy自定義程度高,比 PySpider更底層一些,適合學習研究,需要學習的相關知識多,不過自己拿來研究分布式和多線程等等是非常合適的。
在這里博主會一一把自己的學習經驗寫出來與大家分享,希望大家可以喜歡,也希望可以給大家一些幫助。
## PySpider
[PySpider](https://github.com/binux/pyspider)是[binux](https://github.com/binux)做的一個爬蟲架構的開源化實現。主要的功能需求是:
* 抓取、更新調度多站點的特定的頁面
* 需要對頁面進行結構化信息提取
* 靈活可擴展,穩定可監控
而這也是絕大多數python爬蟲的需求 —— 定向抓取,結構化化解析。但是面對結構迥異的各種網站,單一的抓取模式并不一定能滿足,靈活的抓取控制是必須的。為了達到這個目的,單純的配置文件往往不夠靈活,于是,通過腳本去控制抓取是最后的選擇。
而去重調度,隊列,抓取,異常處理,監控等功能作為框架,提供給抓取腳本,并保證靈活性。最后加上web的編輯調試環境,以及web任務監控,即成為了這套框架。
pyspider的設計基礎是:**以python腳本驅動的抓取環模型爬蟲**
* 通過python腳本進行結構化信息的提取,follow鏈接調度抓取控制,實現最大的靈活性
* 通過web化的腳本編寫、調試環境。web展現調度狀態
* 抓取環模型成熟穩定,模塊間相互獨立,通過消息隊列連接,從單進程到多機分布式靈活拓展
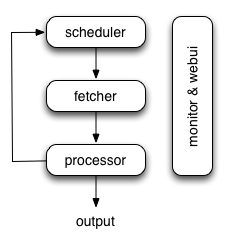
pyspider的架構主要分為 scheduler(調度器), fetcher(抓取器), processor(腳本執行):
* 各個組件間使用消息隊列連接,除了scheduler是單點的,fetcher 和 processor 都是可以多實例分布式部署的。 scheduler 負責整體的調度控制
* 任務由 scheduler 發起調度,fetcher 抓取網頁內容, processor 執行預先編寫的python腳本,輸出結果或產生新的提鏈任務(發往 scheduler),形成閉環。
* 每個腳本可以靈活使用各種python庫對頁面進行解析,使用框架API控制下一步抓取動作,通過設置回調控制解析動作。
## Scrapy
> Scrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架。 可以應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。
> 其最初是為了頁面抓取 (更確切來說, 網絡抓取 )所設計的, 也可以應用在獲取API所返回的數據(例如 Amazon Associates Web Services ) 或者通用的網絡爬蟲。Scrapy用途廣泛,可以用于數據挖掘、監測和自動化測試
Scrapy 使用了 Twisted?異步網絡庫來處理網絡通訊。整體架構大致如下

Scrapy主要包括了以下組件:
* 引擎(Scrapy): 用來處理整個系統的數據流處理, 觸發事務(框架核心)
* 調度器(Scheduler): 用來接受引擎發過來的請求, 壓入隊列中, 并在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是鏈接)的優先隊列, 由它來決定下一個要抓取的網址是什么, 同時去除重復的網址
* 下載器(Downloader): 用于下載網頁內容, 并將網頁內容返回給蜘蛛(Scrapy下載器是建立在twisted這個高效的異步模型上的)
* 爬蟲(Spiders): 爬蟲是主要干活的, 用于從特定的網頁中提取自己需要的信息, 即所謂的實體(Item)。用戶也可以從中提取出鏈接,讓Scrapy繼續抓取下一個頁面
* 項目管道(Pipeline): 負責處理爬蟲從網頁中抽取的實體,主要的功能是持久化實體、驗證實體的有效性、清除不需要的信息。當頁面被爬蟲解析后,將被發送到項目管道,并經過幾個特定的次序處理數據。
* 下載器中間件(Downloader Middlewares): 位于Scrapy引擎和下載器之間的框架,主要是處理Scrapy引擎與下載器之間的請求及響應。
* 爬蟲中間件(Spider Middlewares): 介于Scrapy引擎和爬蟲之間的框架,主要工作是處理蜘蛛的響應輸入和請求輸出。
* 調度中間件(Scheduler Middewares): 介于Scrapy引擎和調度之間的中間件,從Scrapy引擎發送到調度的請求和響應。
Scrapy運行流程大概如下:
* 首先,引擎從調度器中取出一個鏈接(URL)用于接下來的抓取
* 引擎把URL封裝成一個請求(Request)傳給下載器,下載器把資源下載下來,并封裝成應答包(Response)
* 然后,爬蟲解析Response
* 若是解析出實體(Item),則交給實體管道進行進一步的處理。
* 若是解析出的是鏈接(URL),則把URL交給Scheduler等待抓取
## 結語
對這兩個框架進行基本的介紹之后,接下來我會介紹這兩個框架的安裝以及框架的使用方法,希望對大家有幫助。
- Python爬蟲入門
- (1):綜述
- (2):爬蟲基礎了解
- (3):Urllib庫的基本使用
- (4):Urllib庫的高級用法
- (5):URLError異常處理
- (6):Cookie的使用
- (7):正則表達式
- (8):Beautiful Soup的用法
- Python爬蟲進階
- Python爬蟲進階一之爬蟲框架概述
- Python爬蟲進階二之PySpider框架安裝配置
- Python爬蟲進階三之Scrapy框架安裝配置
- Python爬蟲進階四之PySpider的用法
- Python爬蟲實戰
- Python爬蟲實戰(1):爬取糗事百科段子
- Python爬蟲實戰(2):百度貼吧帖子
- Python爬蟲實戰(3):計算大學本學期績點
- Python爬蟲實戰(4):模擬登錄淘寶并獲取所有訂單
- Python爬蟲實戰(5):抓取淘寶MM照片
- Python爬蟲實戰(6):抓取愛問知識人問題并保存至數據庫
- Python爬蟲利器
- Python爬蟲文章
- Python爬蟲(一)--豆瓣電影抓站小結(成功抓取Top100電影)
- Python爬蟲(二)--Coursera抓站小結
- Python爬蟲(三)-Socket網絡編程
- Python爬蟲(四)--多線程
- Python爬蟲(五)--多線程續(Queue)
- Python爬蟲(六)--Scrapy框架學習
- Python爬蟲(七)--Scrapy模擬登錄
- Python筆記
- python 知乎爬蟲
- Python 爬蟲之——模擬登陸
- python的urllib2 模塊解析
- 蜘蛛項目要用的數據庫操作
- gzip 壓縮格式的網站處理方法
- 通過瀏覽器的調試得出 headers轉換成字典
- Python登錄到weibo.com
- weibo v1.4.5 支持 RSA協議(模擬微博登錄)
- 搭建Scrapy爬蟲的開發環境
- 知乎精華回答的非專業大數據統計
- 基于PySpider的weibo.cn爬蟲
- Python-實現批量抓取妹子圖片
- Python庫
- python數據庫-mysql
- 圖片處理庫PIL
- Mac OS X安裝 Scrapy、PIL、BeautifulSoup
- 正則表達式 re模塊
- 郵件正則
- 正則匹配,但過濾某些字符串
- dict使用方法和快捷查找
- httplib2 庫的使用