
## 介紹
MySQL 提供了一個**EXPALIN**命令,可以用于對**SELECT 語句**的執行計劃進行分析,并詳細的輸出分析結果,供開發人員進行針對性的優化。
我們想要查詢一條sql有沒有用上索引,有沒有全表查詢,這些都可以通過explain這個命令來查看。
通過explain命令,我們可以深入了解到MySQL的基于開銷的優化器,還可以獲得很多被優化器考慮到的訪問策略的細節以及運行sql語句時哪種策略預計會被優化器采用。
explain的使用十分簡單,通過在查詢語句前面加一個explain關鍵字即可。

## 參數說明
explain 命令一共返回12列信息,分別是:
~~~text
id、select_type、table、partitions、type、possible_keys、key、key_len、ref、rows、filtered、Extra
~~~
以下是本文的案例表:
~~~mysql
# 用戶表
CREATE TABLE user(
id int primary key auto_increment,
nickname varchar(100),
name varchar(100),
age int,
sex tinyint(1),
dep int,
addr int,
description varchar(100)
)ENGINE INNODB;
# 部門表
CREATE TABLE dep(
id int primary key auto_increment,
name varchar(100)
)ENGINE INNODB;
# 地址表
CREATE TABLE addr(
id int primary key auto_increment,
address varchar(100)
)ENGINE INNODB;
# 普通索引
ALTER TABLE user ADD INDEX idx_dep(dep);
# 唯一索引
ALTER TABLE user ADD unique INDEX uniq_name(name);
# 復合索引
ALTER TABLE user ADD INDEX c_nickname_age_sex(nickname,age,sex);
# 全文索引
ALTER TABLE user ADD FULLTEXT f_description(description);
# 普通索引
ALTER TABLE dep ADD INDEX idx_name(name);
~~~
## id 列
* 每個select語句都會自動分配的一個唯一標識符
* 表示查詢中,操作表的順序,有三種情況
* id相同,執行順序從上到下
* id不同,如果是子查詢,id號會自增,id越大,**優先級越高**
* id相同的不相同的同時存在
* id列為null表示為結果集,不需要使用這個語句來查詢
## select\_type 列(很重要)
查詢類型,主要用于區別**普通查詢、聯合查詢(union、union all)、子查詢等復雜查詢。**
**simple**
表示不需要union操作或者不包含子查詢的簡單select查詢。有連接查詢時,外層的查詢為simple,且只有一個。

**primary**
一個需要使用union的操作或者含有子查詢的select,位于最外層的單位查詢的select\_type即為primary。且只有一個

**subquery**
除了from子句中包含的子查詢外,其它地方出現的子查詢都可能時subquery

**dependent subquery**
子查詢的結果受到外層的影響:

**union、union result**
union 連接的多表查詢,第一個查詢是primary,后面的是union, 結果集是 union result

**dependent union**
和union一樣,出現在union或者union all中,但是這個查詢要受到外部查詢的影響

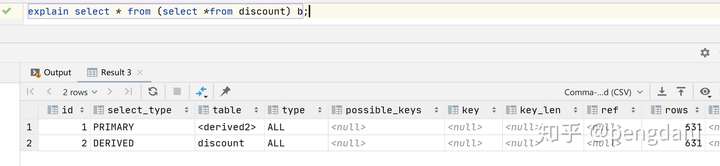
**derived**
在from子句后面的子查詢,也叫派生表,**注意,在MySql5.6 對于此查詢沒有優化,所以查詢類型是derived.在mysql 5.7 使用了 Merge Derived table 優化,查詢類型變為SIMPLE。通過控制參數: optimizer\_switch='derived=on|off' 決定開始還是優化。默認開啟。**

mysql 5.7
mysql 5.6
## table 列
* 顯示的查詢表名,如果查詢使用了別名,那么這里顯示的就是別名
* 如果不涉及對數據表的操作,那么這里就是null
* 如果顯示為尖括號括起來的就表示這是一個臨時表,N就是執行計劃的id,表示結果來自這個查詢
* 如果顯示為尖括號括起來的也表示一個臨時表,表示來自union查詢id為n、m的結果集
## partitions 列
分區信息
## type 列 重要
* 依次從好到差:
~~~mysql
system、const、eq_ref、ref、full_text、ref_or_null、unique_subquery、
index_subquery、range、index_merge、index、all
~~~
除了 All 以外,其它的類型都可以用到索引,除了index\_merge可以使用多個索引之外,其它的類型最多只能使用到一個索引。
注意!!最少也應該要使用索引到range級別!
**system**
表中只有一行數據或者是空表。

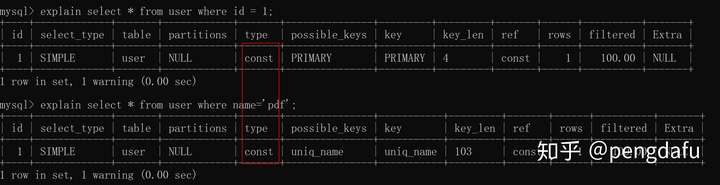
**const**
使用唯一**索引或者主鍵**,返回記錄一定是一條的等值where條件時,通常type是const。
**eq\_ref**
連接字段為主鍵或者唯一索引,此類型通常出現于多表的join查詢,表示對于前表的每一個結果,都對應后表的唯一一條結果。并且查詢的比較是=操作,查詢效率比較高。

上面未使用覆蓋索引,下面使用覆蓋索引,減少回表
**ref**
ref有三種情況:
1. 非主鍵或者唯一鍵的等值查詢
2. join連接字段是非主鍵或者唯一鍵
3. 最左前綴索引匹配
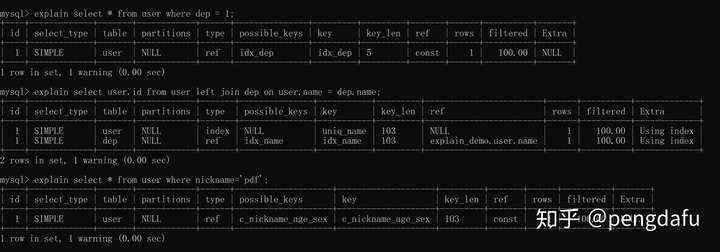
三個查詢分別對應上面三種情況
**fulltext**
全文檢索索引。
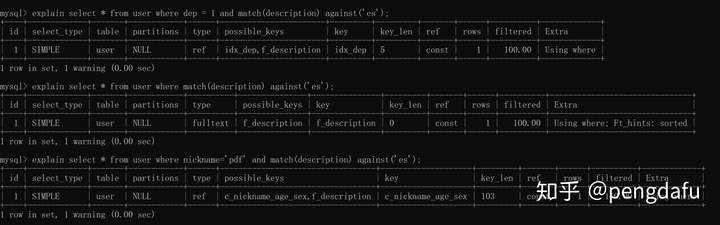
并不是優先使用全文索引
**ref\_or*\_*null**
和ref類似,增加了null值判斷
**unique\_subquery、 index\_subquery**
都是子查詢,前者返回唯一值,后者返回可能有重復。
**range 重要**
索引范圍掃描,常用于 ><,is null,between,in,like等

**index\_merge(索引合并)**
表示查詢使用了兩個或者以上的索引數量,常見于and或者or查詢匹配上了多個不同索引的字段
**index(輔助索引)**
減少回表次數,因為要查詢的索引都在一顆索引樹上

**all 全表掃描**
## possible\_keys 列
此次查詢中,可能選用的索引
## key 列
查詢實際使用的索引,select\_type為index\_merge時,key列可能有多個索引,其它時候這里只會有一個
## key\_len 列
* 用于處理查詢的索引長度,如果是單列索引,那么整個索引長度都會計算進去,如果是多列索引,那么查詢不一定能使用到所有的列,具體使用了多少個列的索引,這里就會計算進去,沒有使用到的索引,這里不會計算進去。
* 留意一下這個長度,計算一下就知道這個索引使用了多少列
* 另外,key\_len 只計算 where 條件使用到索引長度,而排序和分組就算用到了索引也不會計算key\_len
## ref
* 如果是使用的常數等值查詢,這里會顯示const
* 如果是連接查詢,被驅動表的執行計劃這里會顯示驅動表的關聯字段
* 如果是條件使用了表達式或者函數,或者條件列發生了內部隱式轉換,這里可能會顯示func
## rows
執行計劃估算的掃描行數,不是精確值(innodb不是精確值,myisam是精確值,主要是因為innodb使用了mvcc)。
## extra
這個列包含很多不適合在其它列顯示的重要信息,有很多種,常用的有:
* **using temporary**
* 表示使用了臨時表存儲中間結果
* MySQL在對**order by和group by**時使用臨時表
* 臨時表可以是內存臨時表和磁盤臨時表,執行計劃中看不出來,需要查看status變量:used\_tmp\_table、used\_tmp\_disk\_table才可以看出來

* no table used
不帶from字句的查詢或者from dual查詢(explain select 1;)
**使用 not in() 形式的子查詢查詢或者not exists運算符的連接查詢,這種叫做反鏈接**
**即:**一般連接先查詢內表再查詢外表,反鏈接就是先查詢外表再查詢內表
* **using filesort**
* 排序時無法使用到所以就會出現這個,常見于order by和group by
* 說明MySQL會使用一個外部的索引進行排序,而不是按照索引順序進行讀取
* MySQL中無法利用索引完成的排序就叫“文件排序”

* **using index 查詢時候不需要回表**
* 表示相應的select查詢中使用到了**覆蓋索引(Covering index)**,避免訪問表的數據行
* 如果同時出現了using where,說明索引被用來執行查詢鍵值
* 如果沒有using where,表示讀取數據而不是執行查找操作

* **using where**
* 表示存儲引擎返回的記錄并不都是符合條件的,需要在server層進行篩選過濾,性能很低

* **using index condition**
* 索引下推,不需要再在server層進行過濾,5.6.x開始支持
* **first match**
* 5.6.x 開始出現的優化子查詢的新特性之一,常見于where字句含有in()類型的子查詢,如果內表數據量過大,可能出現
* **loosescan**
* 5.6.x 開始出現的優化子查詢的新特性之一,常見于where字句含有in()類型的子查詢,如果內表返回有重復值,可能出現
## filtered 列
5.7之后的版本默認就有這個字段,不需要使用explain extended了。這個字段表示存儲引擎返回的數據在server層過濾后,剩下多少滿足查詢的記錄數量的比例,注意是百分比,不是具體記錄數。
轉載:https://zhuanlan.zhihu.com/p/149807046
- PHP書寫規則
- 代碼縮進
- 大括號{ }書寫規則
- 變量賦值對齊
- if條件判斷規范
- 避免嵌入式賦值
- 函數和方法的注釋
- 項目規范
- 業務邏輯logic
- model模型
- 控制器
- view視圖
- 定制項目開發
- 接口輸出變量格式
- mysql設計規范
- 二維碼系列
- php 用phprqcode 生成簡單的二維碼
- 小程序二維碼
- 其他小工具
- 獲取單個漢字拼音首字母
- js 調起打印多出一張空白的問題?
- php 2張圖片合拼
- 判斷一個漢字可以等于1個字符,2個字符,3個字符
- 微信小程序獲取頁面路徑
- 小程序js、canvas實現矩形圓角、圓形頭像圖片
- php phpMailer 發送郵件(親測有效)
- 系統配置表
- php 用tcpdf 生成pdf
- PHP mkdir():創建目錄
- php 通過svg動態生成生成后綴圖標
- php 本地安裝SSL證書
- php 生成首字母頭像
- php 接口數據壓縮返回,減少帶寬
- PHP向二維數組多維數組追加相同元素
- php 指定時間戳上加上一天,一個月,一年的方法
- Spreadsheet 表格生成
- php 多維數組排序 多維數組按照某個字段排序
- php根據開始和結束時間獲取期間日期
- php 獲取本周、上周、本月、上月及指定時間所在周、月的起止時間
- php GeoIP2通過ip獲取國家和地區城市
- 奇葩報錯問題
- session賦值報錯
- 服務器配置lnmp
- 開啟mysql binglog 日志
- lnmp 開啟遠程訪問3306
- 開啟mysql 慢日志查詢
- 開通Liunx 3306 端口(遠程連接開放)
- 搭建lnmp
- liunx 多臺服務器搭建共享文件夾圖片文件夾
- liunx 操作命令1
- nginx專區
- 禁止外部ip訪問
- 強制跳轉到https
- mysql專區
- 版本5.7報錯 only_full_group_by
- 把同一張表的一個字段的內容復制到另一個字段里
- lnmp關閉嚴格模式
- mysql 兩張不同結構的表連表查詢,合并,并分頁,排序 教你如何實現UNION
- mysql 查詢一張表中某個字段不同狀態的數量統計
- mysql數據庫快速插入百萬條級別的測試數據
- MySQL EXPLAIN 詳解,可用EXPLAIN來分析優化數據庫sql語句
- mysql 三星索引
- mysql 返回數據排名查詢獲取排名的方法,親測有效
- mysql使用查詢出來的值并且更新update新的表報錯?叫你一招
- mysql 怎樣自定義in查詢操作排序
- mysql 百萬級別和千萬級數據分頁查詢性能優化
- mysql 查詢某個字段按照逗號分割返回
- mysql 用sql命令導入數據庫
- mysql 根據某個字段的值匹配替換某個值
- Mysql中分組后取最新的一條數據排序
- Certbot-免費的https證書
- session_start()報錯問題
- 文件大打不開?代碼實現分割
- windows服務器專區
- apache 突然重啟動不了
- windows 定時任務
- liunx專區
- liunx 定時器檢查php是否能訪問,重啟
- liunx 操作命令
- 定時器 tp5 命令行
- liunx查看端口是否開放
- liunx上傳或者下載本地文件
- 前端
- jq克隆html
- Jquery添加元素(append,prepend,after,before四種方法區別對比)
- 小程序switch樣式修改
- css div 里面模塊 平均展開
- 安全小學堂
- 驗證碼一次一碼
- 實戰thinkphp6
- 前言
- 中間件
- 開啟多語言
- RabbitMQ 專區
- 下載RabbitMQ
- ftp專區
- Linux安裝vsftpd及配置詳解
- 小程序欄目
- 微信小程序封裝統一接口請求api數據
- 云數據庫
- 小程序云開發更新云函數數組的某一項,并且某個是變量代替
- php面試總結
- Mysql面試
- PHP面試知識
- Thinkphp框架小知識
- fastadmin 文檔
- fastadmin js 渲染 動態下拉(SelectPage)組件
- fastadmin 列表搜索欄 支持三級聯動 地區選項
- fastadmin searchList組件自定義數據返回
- 開發工具
- phpstorm 一直在Indexing,一直加載索引,無法正常使用
- PHP專區
- session 工作流程
- Redis
- php redis 基本操作
- SourceTree 3.3.9跳過注冊安裝
- composer 專區
- 手把手教你寫一個composer包
- freessl證書申請