## **數據庫架構的演變**
在業務數據量比較少的時代,我們使用單機數據庫就能滿足業務使用,隨著業務請求量越來越多,數據庫中的數據量快速增加,這時單機數據庫已經不能滿足業務的性能要求,數據庫主從復制架構隨之應運而生。<p>
主從復制是將數據庫寫操作和讀操作進行分離,使用多個只讀實例(slaver replication)負責處理讀請求,主實例(master)負責處理寫請求,只讀實例通過復制主實例的數據來保持與主實例的數據一致性。由于只讀實例可以水平擴展,所以更多的讀請求不成問題,隨著云計算、大數據時代的到來,事情并沒有完美的得以解決,當寫請求越來越多,主實例的寫請求變成主要的性能瓶頸。<p>
如何解決上述問題?如果僅僅通過增加一個主實例來分擔寫請求,寫操作如何在兩個主實例之間同步來保證數據一致性,如何避免雙寫,問題會變的更加復雜。這時就需要用到分庫分表(sharding),邏輯上大致如下圖所示:

Sharding-Proxy是一個分布式數據庫中間件,徹底解決了數據庫的擴展性問題,對應用透明地實現海量數據的高并發訪問,實現了讀寫分離和分庫分表。
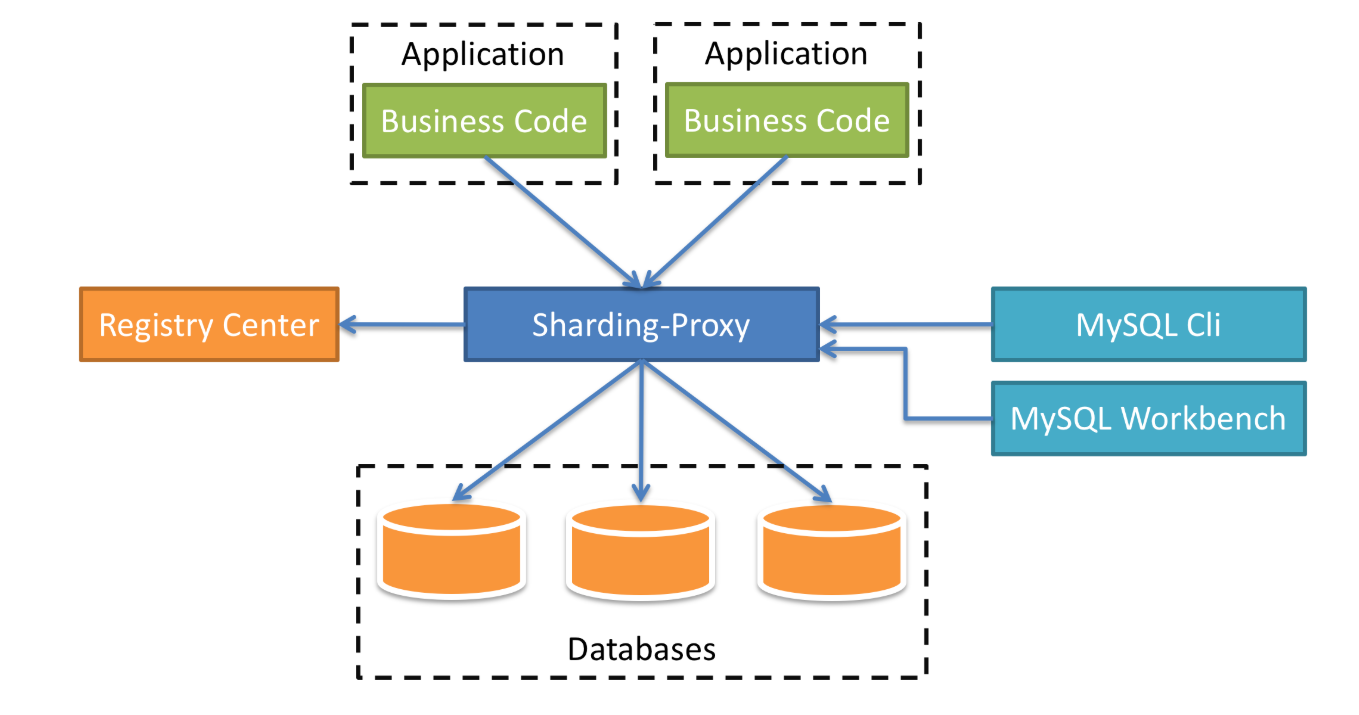
在架構圖中,中間的藍色方塊就是我們的中間件Sharding-Proxy,下面連接的是數據庫,我們可以配置每一個數據庫的分片,還可以配置數據庫的讀寫分離,影子庫等等。上方則是我們的業務代碼,他們統一連接Sharding-Proxy,就像直接連接數據庫一樣,而具體的數據插入哪一個數據庫,則由Sharding-Proxy中的分片規則決定。再看看右側,右側是一些數據庫的工具,比如:MySQL CLI,Navicat,SQLYog等。最后再來看看左側,是一個注冊中心,目前支持最好的是Zookeeper,在注冊中心中,我們可以統一配置分片規則,讀寫數據源等,而且是實時生效的,在管理多個Sharding-Proxy時,非常的方便。
## **對比**
| | *Sharding-JDBC* | *Sharding-Proxy* | *Sharding-Sidecar* |
| --- | --- | --- | --- |
| 數據庫 | 任意 | `MySQL/PostgreSQL` | MySQL/PostgreSQL |
| 連接消耗數 | 高 | `低` | 高 |
| 異構語言 | 僅Java | `任意` | 任意 |
| 性能 | 損耗低 | `損耗略高` | 損耗低 |
| 無中心化 | 是 | `否` | 是 |
| 靜態入口 | 無 | `有` | 無 |
Sharding-Proxy的優勢在于對異構語言的支持,以及為DBA提供可操作入口。
* 向應用程序完全透明,可直接當做MySQL/PostgreSQL使用。
* 適用于任何兼容MySQL/PostgreSQL協議的的客戶端。
- 數據庫架構的演變
- 安裝Sharding-Proxy
- 數據分片之概念篇
- 數據分片之水平分庫分表
- 數據分片之垂直分庫分表(解決中文亂碼問題)
- tp6 基于Sharding-Proxy的分庫分表
- 全局分布式ID生成
- 范圍分片-按年分庫按月分表
- tp6 基于Sharding-Proxy的讀寫分離
- 基于docker搭建mysql8的GTID半同步復制
- 數據讀寫分離實戰
- Hint 強制查詢走主庫
- 廣播表
- 數據脫敏
- tp6 基于Sharding-Proxy的事務管理
- 本地事務
- 兩階段事務(XA強一致事務)
- 柔性事務-BASE
- logback 自定義日志級別及存儲方案
- Sharding-Proxy 整合Nginx實現高可用
- Sharding-Proxy 集群擴容方案