
一、環境介紹
1.1 主機清單
職責 | ip地址 | 備注
Prometheus服務器 | 192.168.100.85 | docker指式的prometheus
待覽控Linux | 192.168.100.141 | 待準備組件:docker指式的prometheus
1.2 調用鏈路圖
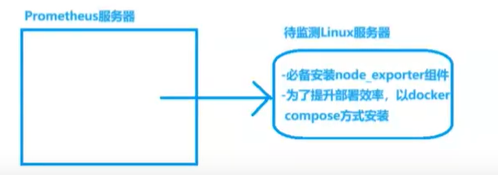
<hr>
二、待監控Linux機準備
2.1 Centos7安裝
2.2 調整host名稱
#修改hosts文件
vi /etc/hosts
#錄入以下內容,:wq保存并退出
#被監控機器IP
192.168.100.141 centos2
#Prometheus服務器IP
192.168.100.85 centos1
2.3 安裝docker
2.4 安裝docker-compose
<hr>
三、安裝node_exporter
192.168,28.141的centos2上,以docker-compose萬式快速安裝node_exporter
3.1創建node_exporter文件夾
mkdir /data/node exporter -p
cd /data/node exporter
3.2 創建docker-compose.yaml文件
vi docker-compose.yaml
services:
node_exporter:
image: registry.cn-hangzhou.aliyuncs.com/ldw520/node-exporter:v1.8.0
container_name: node-exporter
restart: always
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)'
ports:
- '9100:9100'
<hr>
3.3 運行docker-compose
docker-compose up -d (-d后臺運行)
<hr>
3.4 在prometheus服務器 加監控機器配置
cd /data/docker-compose
vi prometheus/prometheus.yml
如下圖所示,在node_exporter里面加多個tartgets配置,服務器ip寫被監控的服務器ip
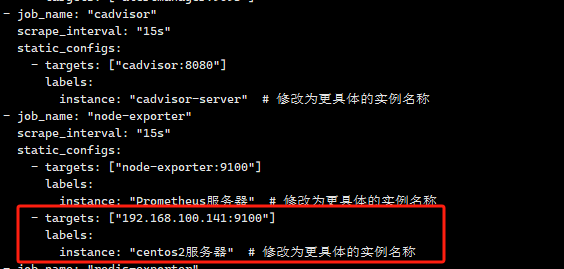
保存配置后,讓配置生效
#centos1中執行
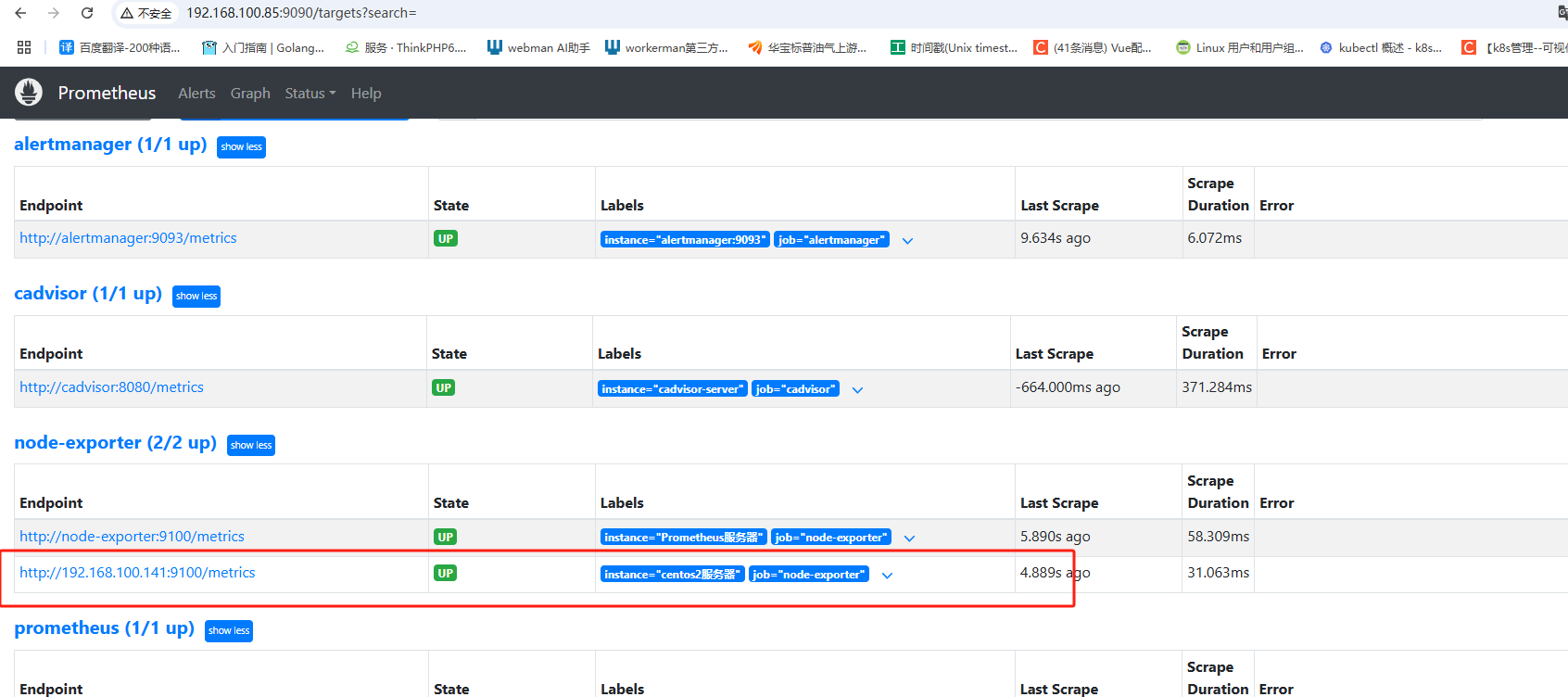
curl ·X PosT http://localhost:9090/-/reload
查看Prometheus網頁可發現多了一個監控,已成功
<hr>
四、常用的Linux服務器監控指標
1.CPU
2.內存
3.硬盤
4.網絡流量
5.文件描述符
6.系統負載
7.系統服務
4.1 cpu監控
CPU的監控質名稱是:node_cpusecondstotal,便用總量直接執行node_cpu_seconds_total查詢后會出現很多監控指標,然不是想要的node_cpu_seconds_[ota執行后會出現很多監控指標,其中各種類型的比如系統態,用戶志都會出mmode標簽來區分
我們想要查詢CPU的使用率的思路量:查出當前空閑的CPU百分比,晨后用100減去,mode標簽值idle就表示當前率閑的CPU
node_cpu_seconds_total
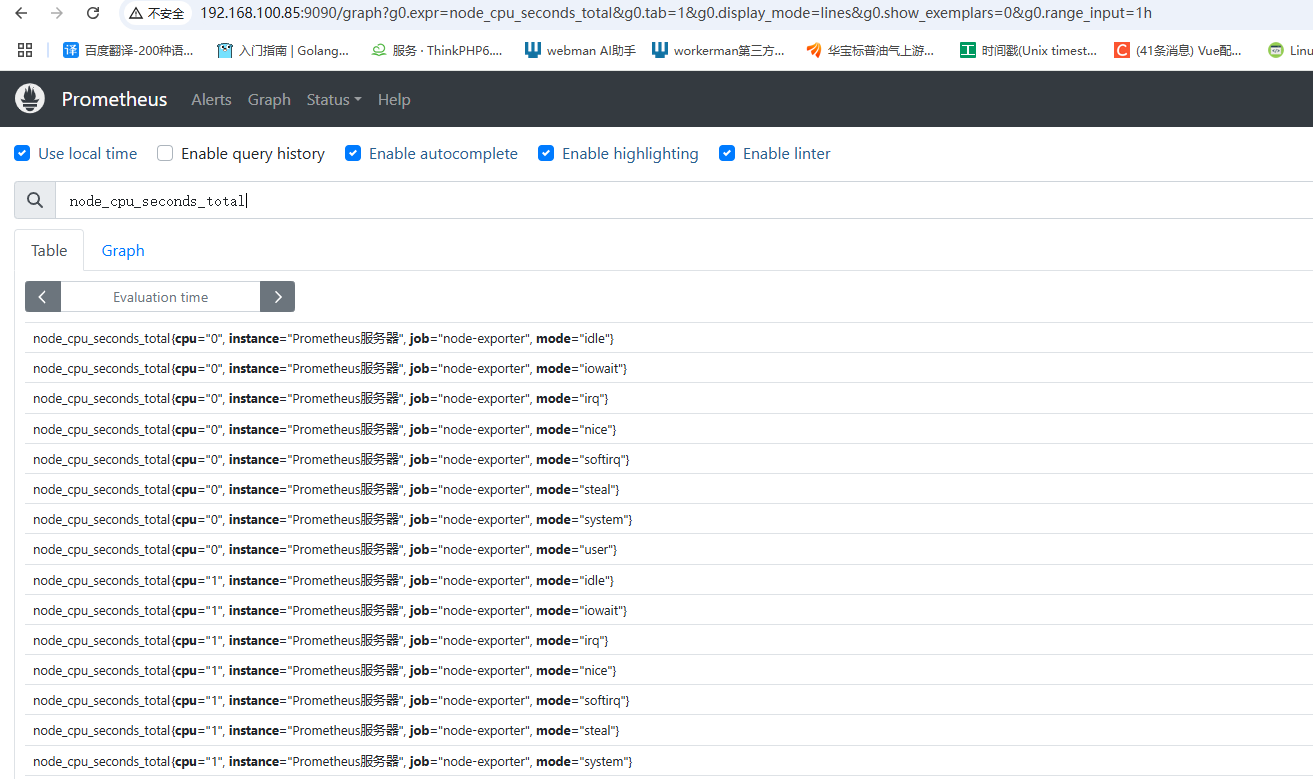
cpu="0”代表第1核cpu
cpu="1”代表第2核cpu
- 獲取空閑cpu監控數據
mode標簽值為idle的為空閑(user代表mode為用戶,system代表mode為系統...)
node_cpu_seconds_total{mode="idle"}
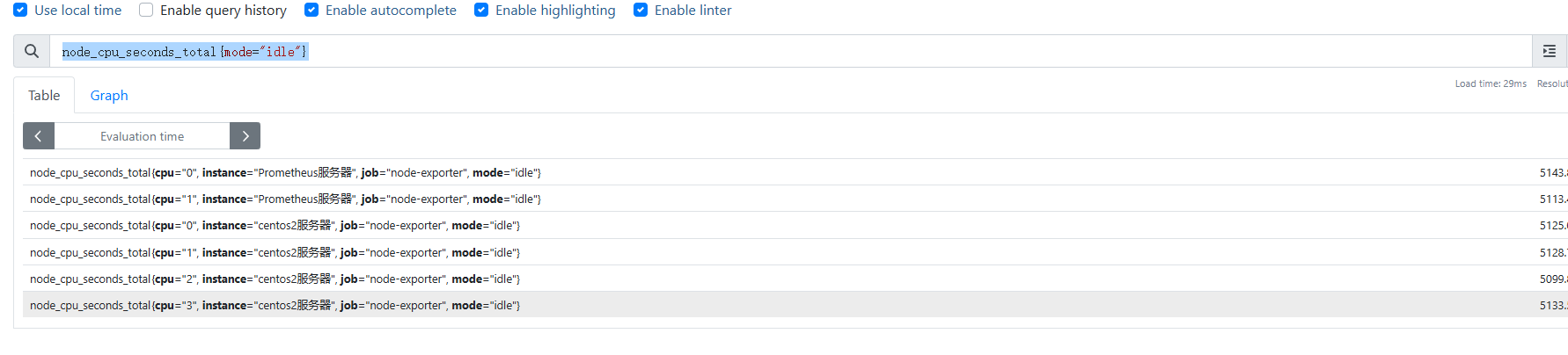
獲取某臺監控機器的cPu數據
instance標簽值為centos2服務器的cpu數據
node_cpu_seconds_total{instance='centos2服務器'}
獲取1分鐘/5分鐘/15分鐘的cpu負毅
node _load1
node load5
node load15
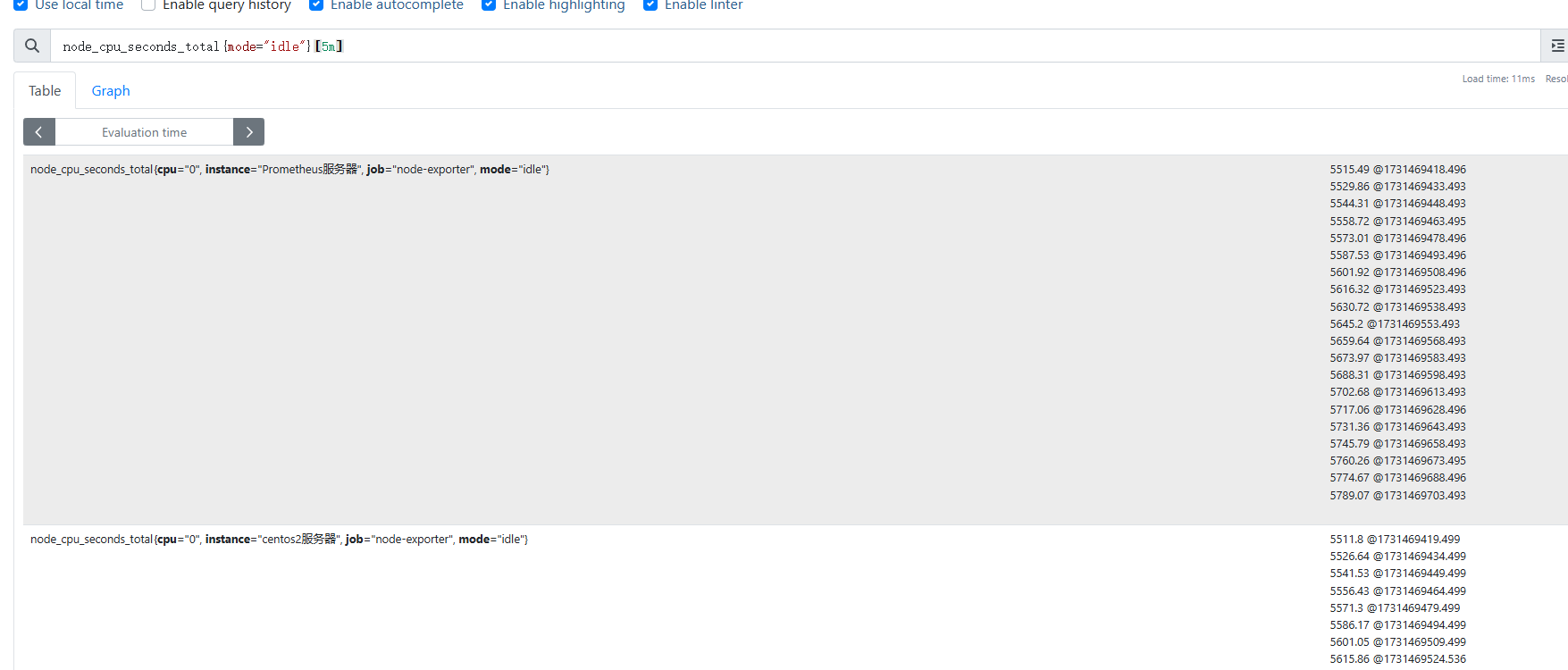
獲取5分鐘內的監控數據
之前雖然可以查出來結果,但是不太理想,因為CPU是不斷波動的,我們可以在增加一個條件,查詢5分鐘內的一個CPU使用情況
node_cpu_seconds_total{mode='idle'}[5m]
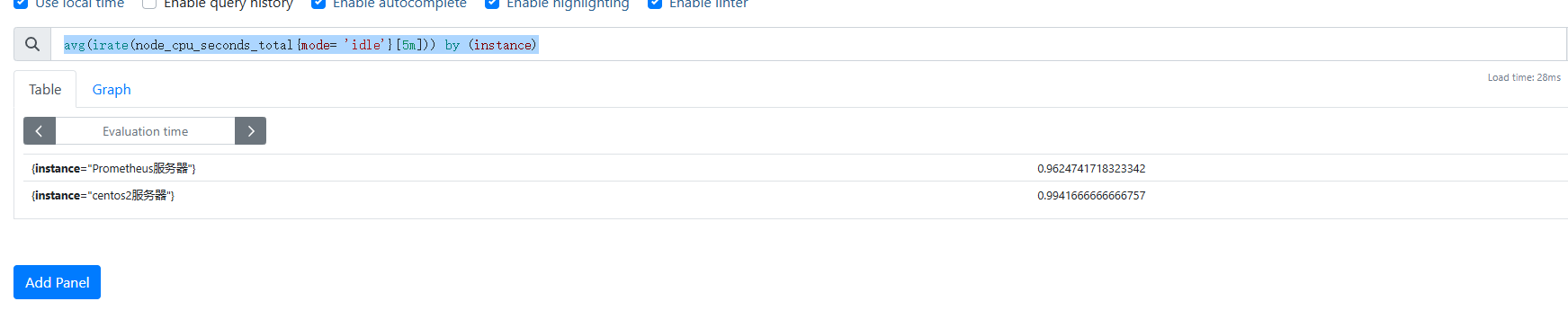
獲取5分鐘內的cpu平均空閑狀況我們可以便用irate和avg的數結合剛才查詢出5分鐘內數據做一個平均情況展示函數的便用方法:的數(指標獲取方式)
avg(irate(node_cpu_seconds_total{mode= 'idle'}[5m])) by (instance)
#y(instance)表示以instance標簽進行分組
獲取cpu5分鐘內的使用率
最后我們可以*100得出一個百分比的空閑率,再由100·即可得到CPU的使用率
100 * avg(irate(node_cpu_seconds_total{mode= 'idle'}[5m])) by (instance)

<hr>
4.2 內存監控
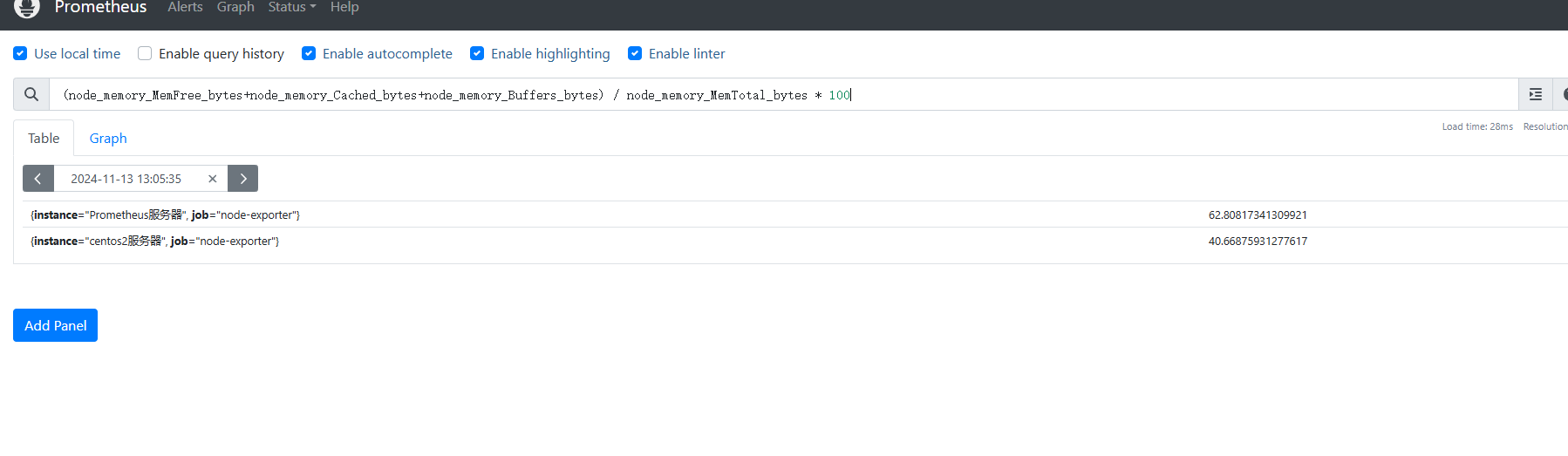
由于內存的監控項沒有像CPU一樣區分了很多標簽,因此內存監控相較于CPU則需要結合很多個監控
node_memory_MemFree_bytes //空閑內存
node_memory_MemTotal bytes //總內存
node_memory_Cached_bytes //愛愛存
node_memory_Buffers_bytes //緩沖區內存監控內存使用的思路:
1.空閑內存+縵存+縵沖區內存得出空閑總內存
2.得出的空閑總內存再除總內存大小再乘100,得出空閑率
3.再用100·空閑率就得出使用率
首先是獲取空閑內存
<hr>
5.3 磁盤使用率
關于磁盤使用率,這里我們用到的主要有:
node,filesystem_free_bytes //剩余磁盤空間
node_filesystem_size_bytes //磁盤空間總大小
node disk相關
這兩個監控項中都有相同的標簽可以關聯,我們這里用到的標簽有fstype,fstype標簽值是關于磁盤的文件系統類型,對于磁盤監控,我們主要對x5、ext4等文件系統的磁盤進行監控,像(mpfs這種的不必要監控,另一個主要的標簽是mountpoint,這個標簽值主要用來儲存磁盤的掛我點,我們可以通過標簽來選擇要對那個掛我點的磁盤進行監控磁盤使用率實現思路
1.由磁盤空閑客量除磁盤總容量乘100即可得到磁盤空閑潮
2.用100減磁盤空閑率即可得到磁盤使用率
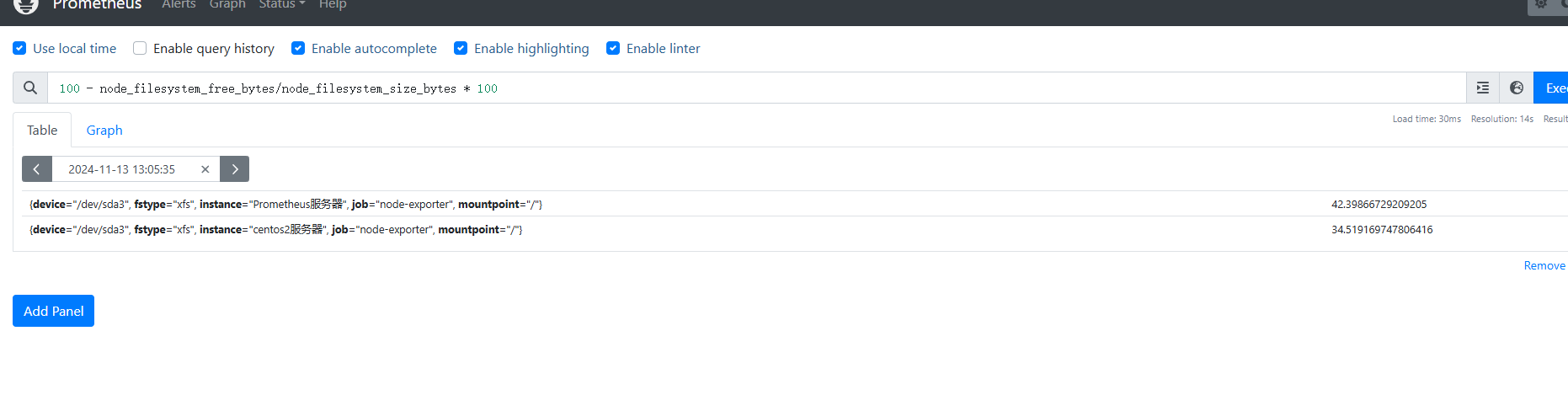
#linux中獲取磁盤空閑率命令
df -hT
<hr>
5.4 網絡采集
node_network_相關都屬于網絡采集數據
#阿絡涼出流量
node_network_transmit_bytes_total
#網絡流入流量
node_network_receive_bytes_total
- Prometheus教程
- 一. dokcer 安裝
- 二. 安裝docker-compose
- 三. docker-compose安裝Prometheus
- 四. 配置grafana的數據源
- 五. Prometheus的Exporter
- 六. Prometheus的基本術語
- 七. 監控Linux
- 八. 監控redis和mongodb
- 九. 監控mysql數據庫
- 十. 監控go程序
- 十一. 監控nginx
- 十二. 監控消息隊列
- 十三. 監控docker
- 十四. 監控進程
- 十五. 域名監控
- 十六. SNMP監控
- 十七. 黑盒監控
- 十八. 自定義監控
- 十九. go實現自定義監控
- 二十. 服務發現概述
- 二十一. 基于文件的服務發現
- 二十二. 基于Consul的服務發現
- 二十三. relabeling機制