
[TOC]
## 2、Golang的協程調度器原理及GMP設計思想?
> 本節為**重點**章節
> 本章節含視頻版:
[](https://www.bilibili.com/video/BV19r4y1w7Nx)
---
## 一、Golang“調度器”的由來?
### (1) 單進程時代不需要調度器
我們知道,一切的軟件都是跑在操作系統上,真正用來干活(計算)的是CPU。早期的操作系統每個程序就是一個進程,知道一個程序運行完,才能進行下一個進程,就是“單進程時代”
一切的程序只能串行發生。
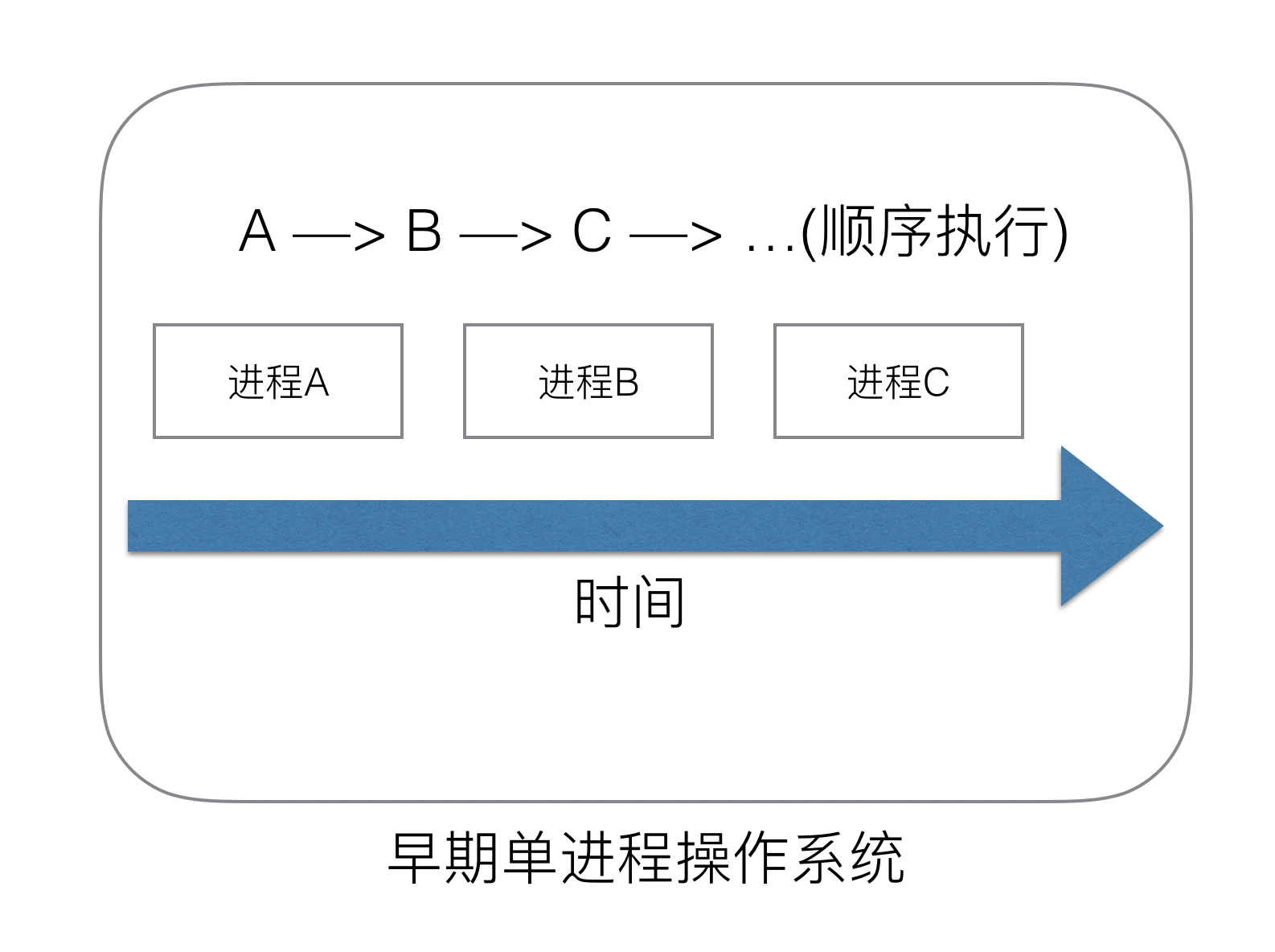
早期的單進程操作系統,面臨2個問題:
1.單一的執行流程,計算機只能一個任務一個任務處理。
2.進程阻塞所帶來的CPU時間浪費。
那么能不能有多個進程來宏觀一起來執行多個任務呢?
后來操作系統就具有了**最早的并發能力:多進程并發**,當一個進程阻塞的時候,切換到另外等待執行的進程,這樣就能盡量把CPU利用起來,CPU就不浪費了。
### (2)多進程/線程時代有了調度器需求
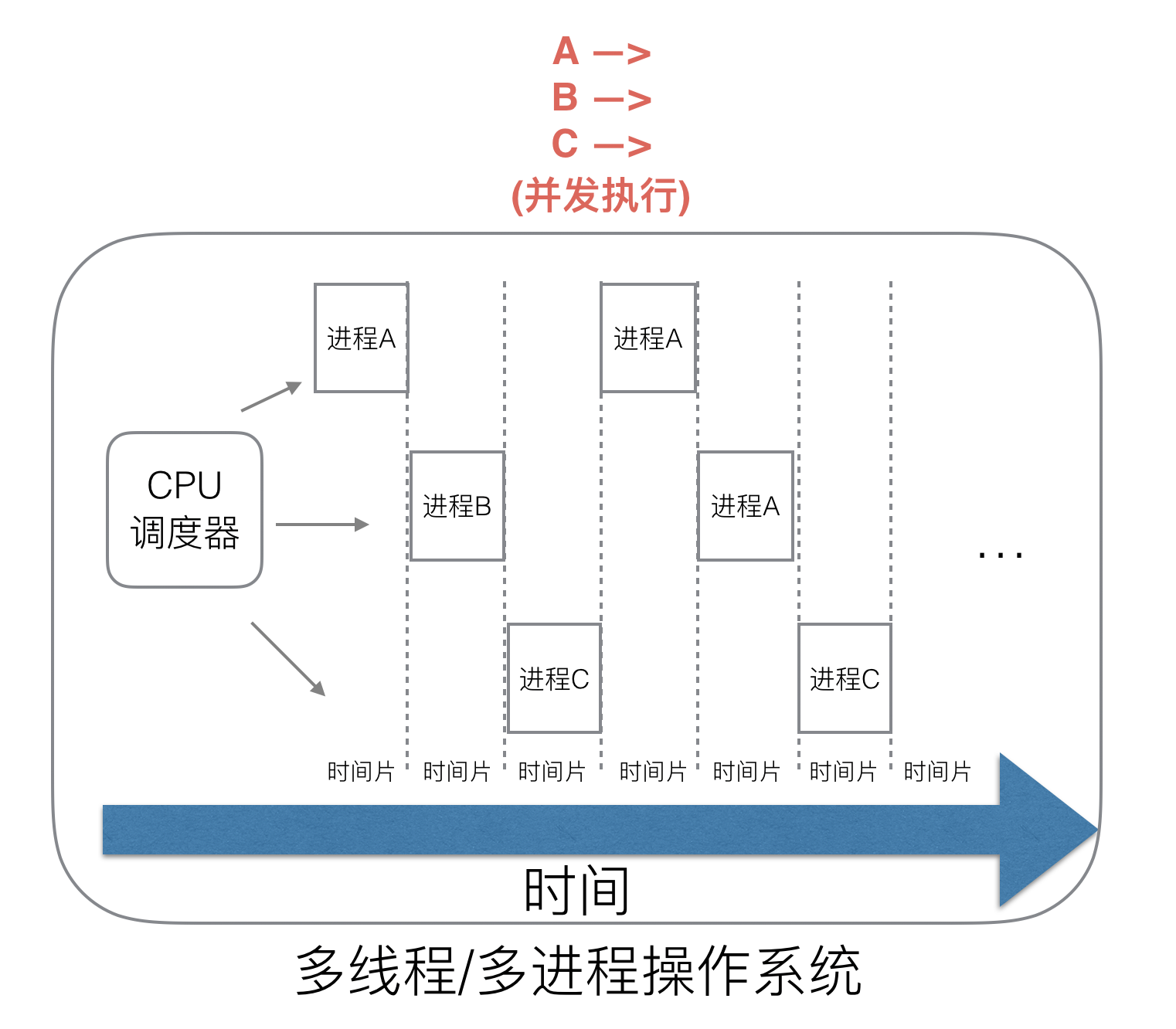
在多進程/多線程的操作系統中,就解決了阻塞的問題,因為一個進程阻塞cpu可以立刻切換到其他進程中去執行,而且調度cpu的算法可以保證在運行的進程都可以被分配到cpu的運行時間片。這樣從宏觀來看,似乎多個進程是在同時被運行。
但新的問題就又出現了,進程擁有太多的資源,進程的創建、切換、銷毀,都會占用很長的時間,CPU雖然利用起來了,但如果進程過多,CPU有很大的一部分都被用來進行進程調度了。
**怎么才能提高CPU的利用率呢?**
但是對于Linux操作系統來講,cpu對進程的態度和線程的態度是一樣的。
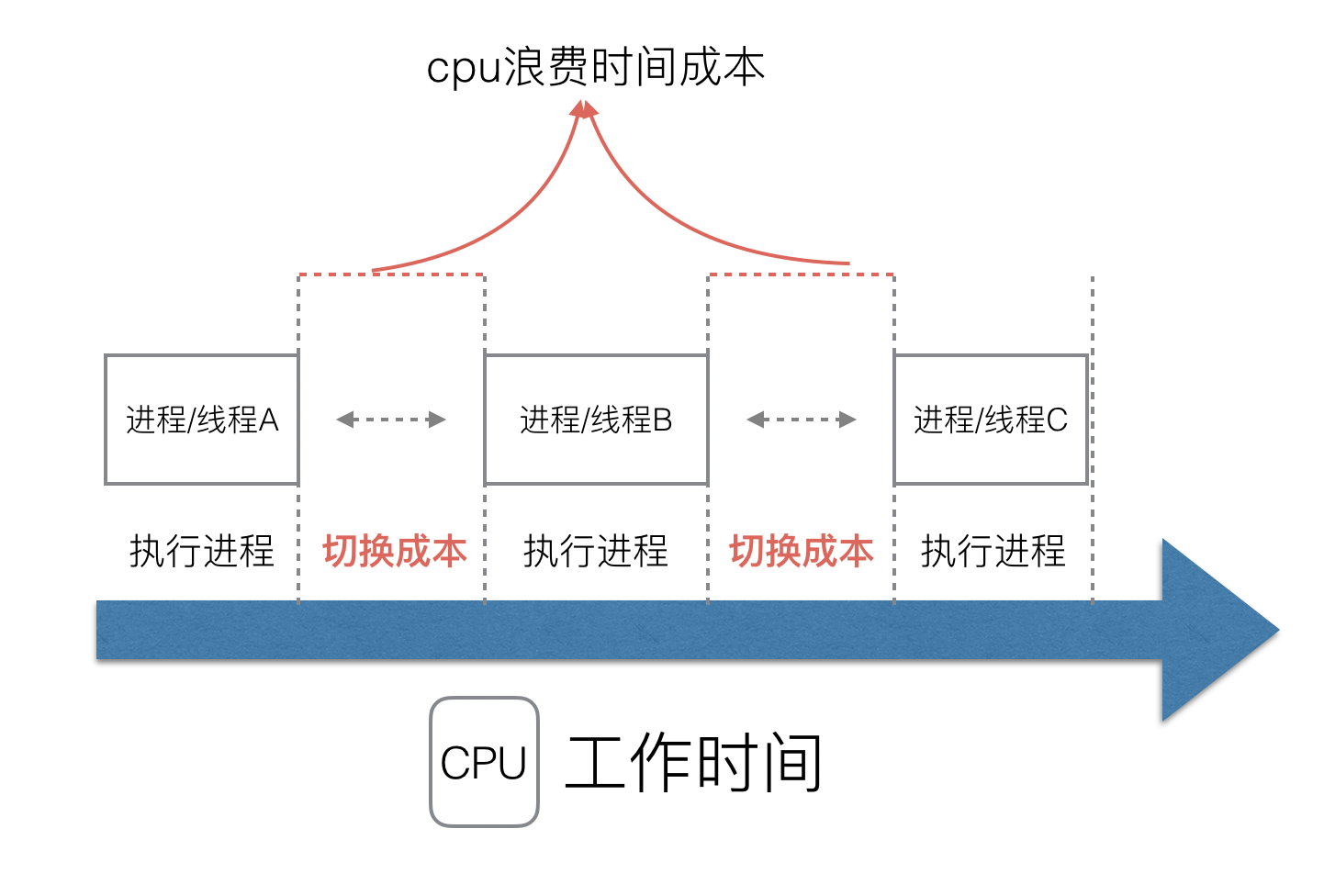
很明顯,CPU調度切換的是進程和線程。盡管線程看起來很美好,但實際上多線程開發設計會變得更加復雜,要考慮很多同步競爭等問題,如鎖、競爭沖突等。
### (3)協程來提高CPU利用率
多進程、多線程已經提高了系統的并發能力,但是在當今互聯網高并發場景下,為每個任務都創建一個線程是不現實的,因為會消耗大量的內存(進程虛擬內存會占用4GB[32位操作系統], 而線程也要大約4MB)。
大量的進程/線程出現了新的問題
* 高內存占用
* 調度的高消耗CPU
好了,然后工程師們就發現,其實一個線程分為“內核態“線程和”用戶態“線程。
一個“用戶態線程”必須要綁定一個“內核態線程”,但是CPU并不知道有“用戶態線程”的存在,它只知道它運行的是一個“內核態線程”(Linux的PCB進程控制塊)。
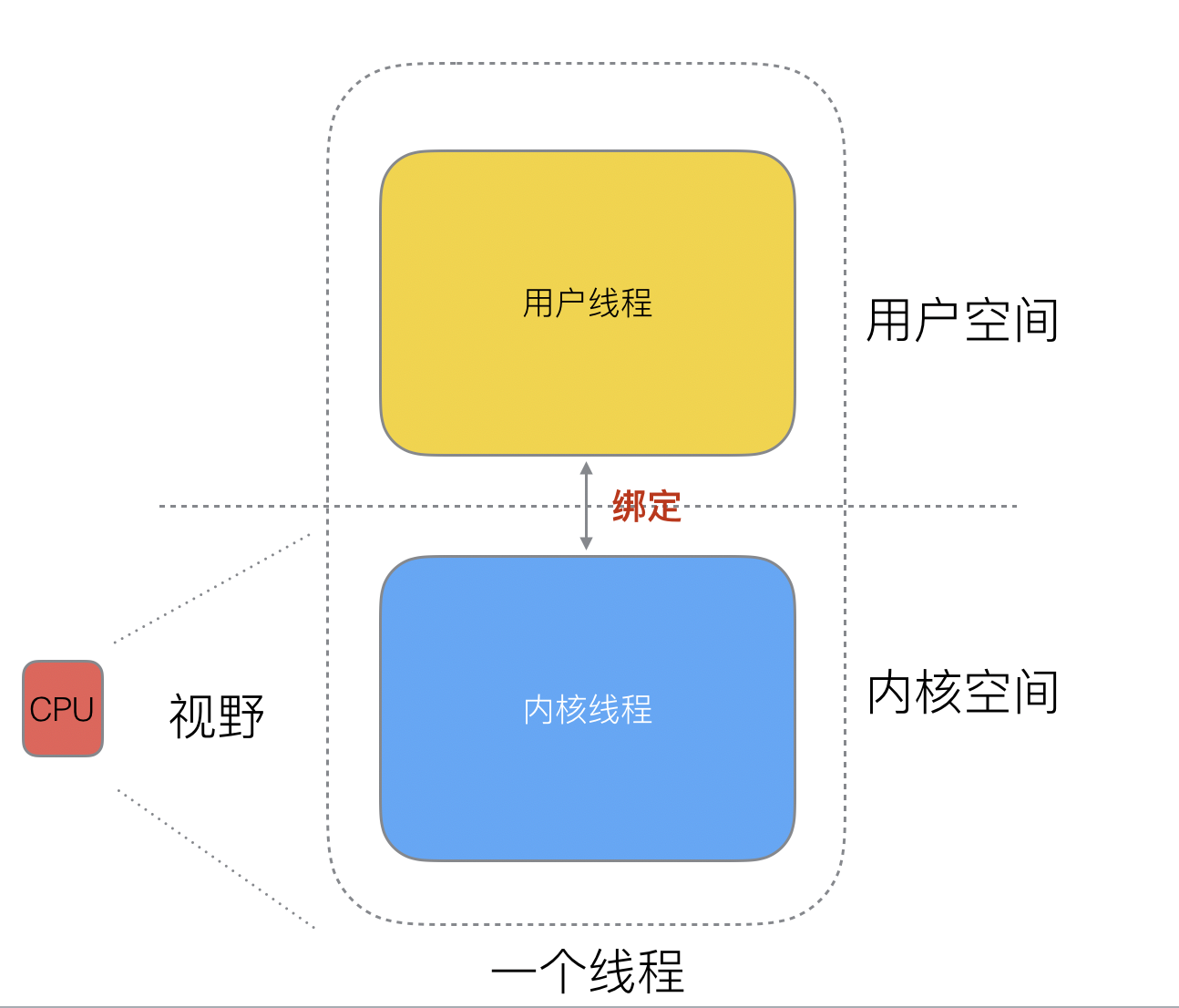
?
? 這樣,我們再去細化去分類一下,內核線程依然叫“線程(thread)”,用戶線程叫“協程(co-routine)".
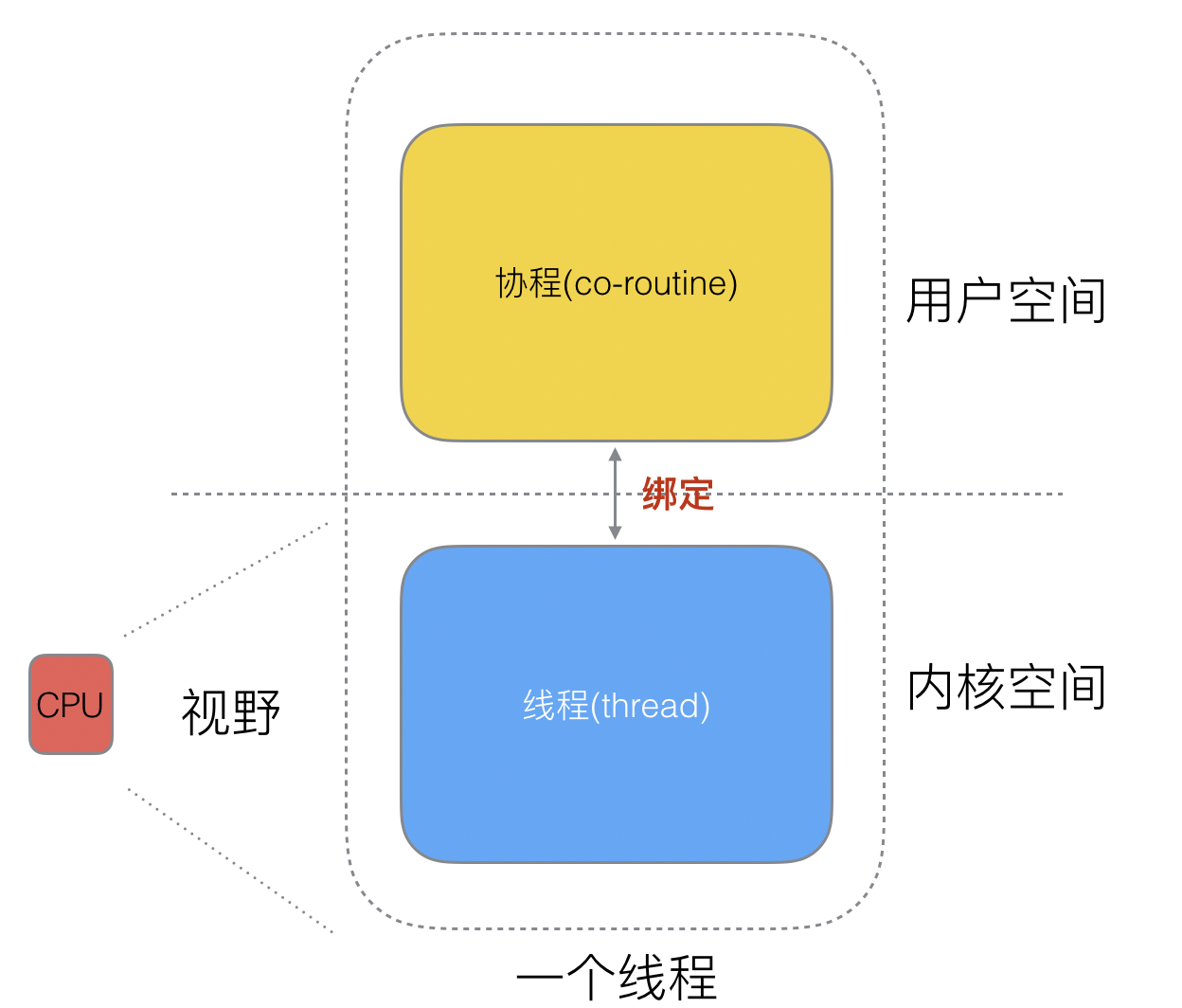
? 看到這里,我們就要開腦洞了,既然一個協程(co-routine)可以綁定一個線程(thread),那么能不能多個協程(co-routine)綁定一個或者多個線程(thread)上呢。
? 之后,我們就看到了有3中協程和線程的映射關系:
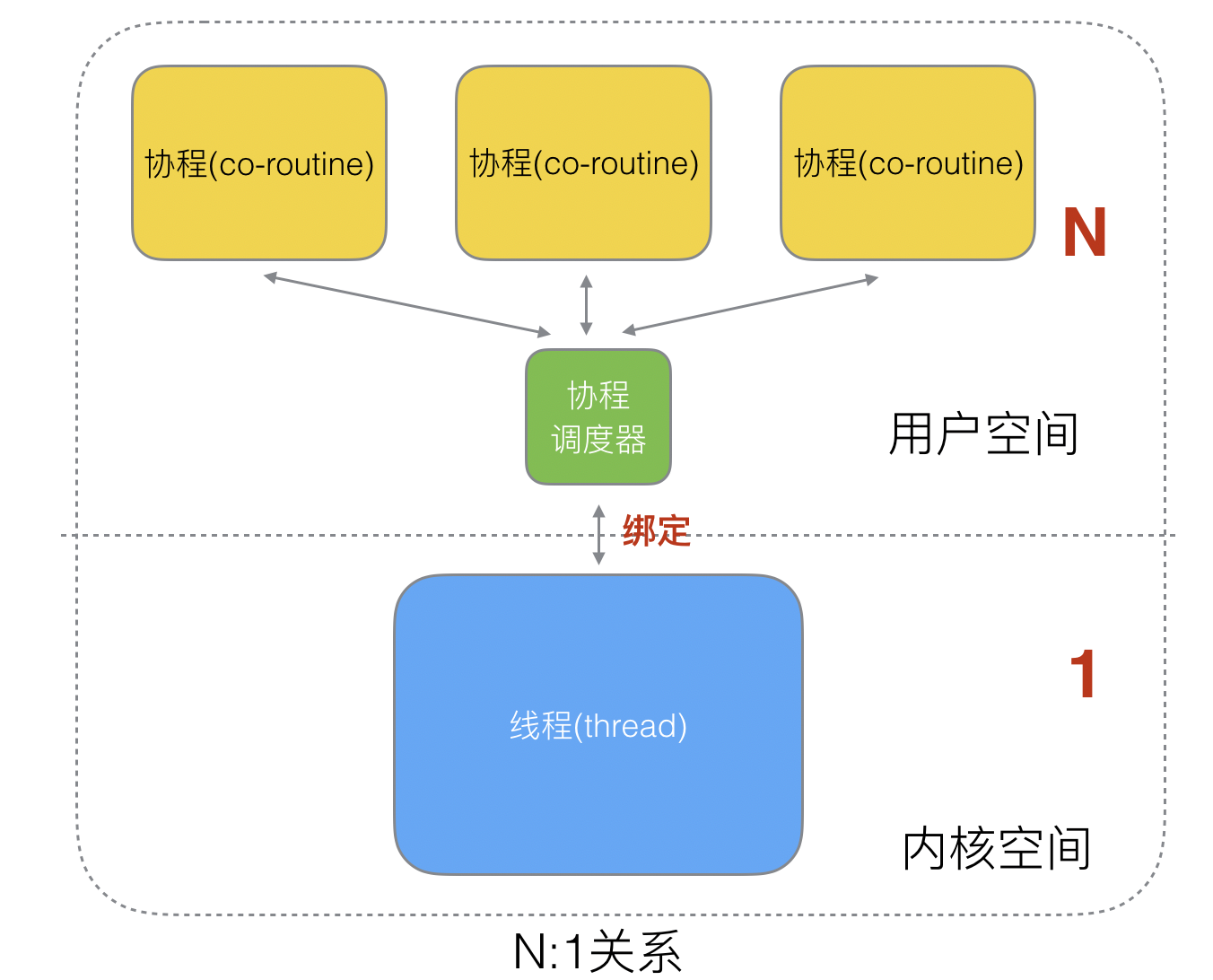
> #### N:1關系
N個協程綁定1個線程,優點就是**協程在用戶態線程即完成切換,不會陷入到內核態,這種切換非常的輕量快速**。但也有很大的缺點,1個進程的所有協程都綁定在1個線程上
缺點:
* 某個程序用不了硬件的多核加速能力
* 一旦某協程阻塞,造成線程阻塞,本進程的其他協程都無法執行了,根本就沒有并發的能力了。
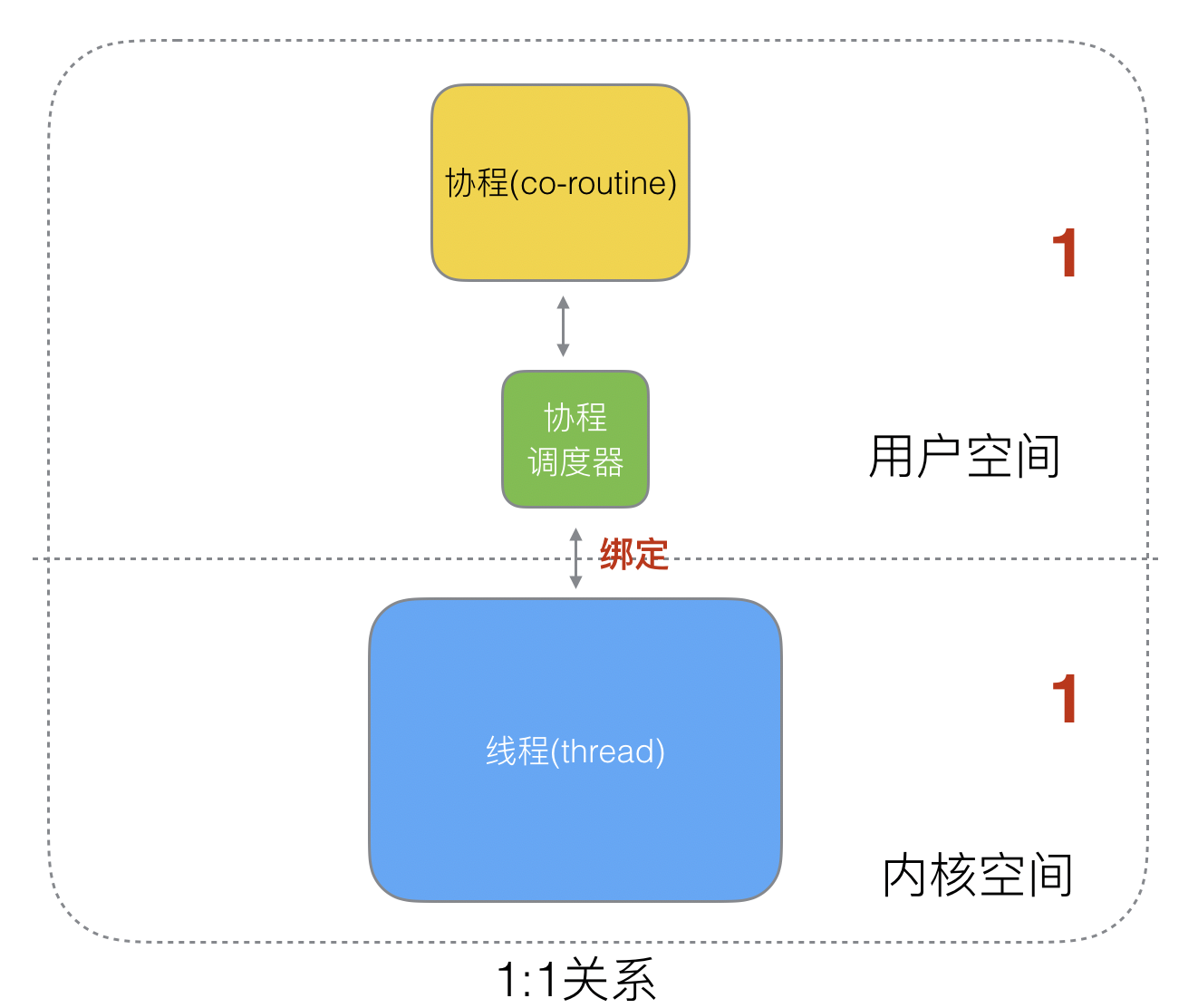
> #### 1:1 關系
1個協程綁定1個線程,這種最容易實現。協程的調度都由CPU完成了,不存在N:1缺點,
缺點:
* 協程的創建、刪除和切換的代價都由CPU完成,有點略顯昂貴了。
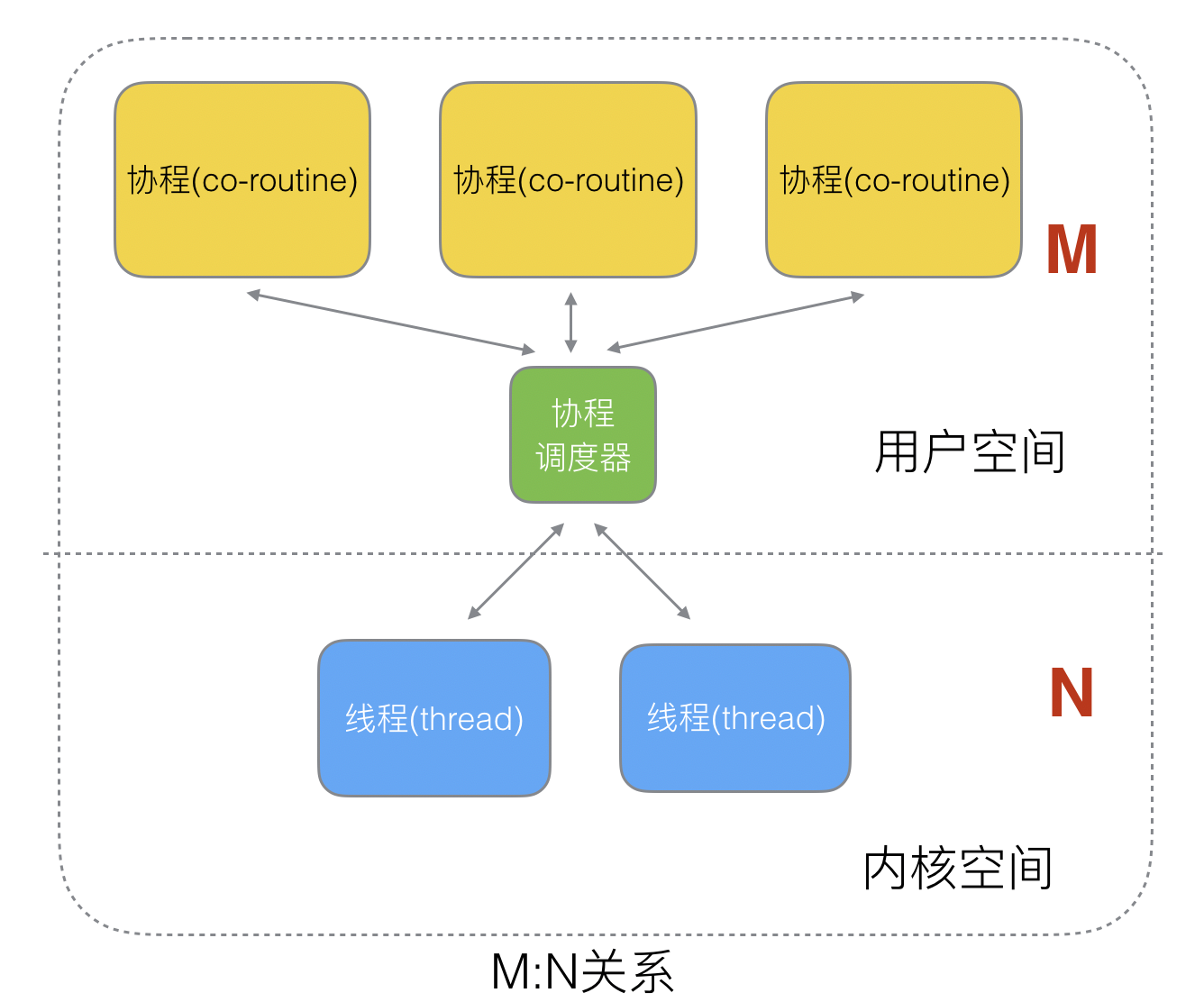
> #### M:N關系
M個協程綁定1個線程,是N:1和1:1類型的結合,克服了以上2種模型的缺點,但實現起來最為復雜。
? 協程跟線程是有區別的,線程由CPU調度是搶占式的,**協程由用戶態調度是協作式的**,一個協程讓出CPU后,才執行下一個協程。
?
### (4)Go語言的協程goroutine
**Go為了提供更容易使用的并發方法,使用了goroutine和channel**。goroutine來自協程的概念,讓一組可復用的函數運行在一組線程之上,即使有協程阻塞,該線程的其他協程也可以被`runtime`調度,轉移到其他可運行的線程上。最關鍵的是,程序員看不到這些底層的細節,這就降低了編程的難度,提供了更容易的并發。
Go中,協程被稱為goroutine,它非常輕量,一個goroutine只占幾KB,并且這幾KB就足夠goroutine運行完,這就能在有限的內存空間內支持大量goroutine,支持了更多的并發。雖然一個goroutine的棧只占幾KB,但實際是可伸縮的,如果需要更多內容,`runtime`會自動為goroutine分配。
Goroutine特點:
* 占用內存更小(幾kb)
* 調度更靈活(runtime調度)
### (5)被廢棄的goroutine調度器
? 好了,既然我們知道了協程和線程的關系,那么最關鍵的一點就是調度協程的調度器的實現了。
Go目前使用的調度器是2012年重新設計的,因為之前的調度器性能存在問題,所以使用4年就被廢棄了,那么我們先來分析一下被廢棄的調度器是如何運作的?
> 大部分文章都是會用G來表示Goroutine,用M來表示線程,那么我們也會用這種表達的對應關系。
? 下面我們來看看被廢棄的golang調度器是如何實現的?
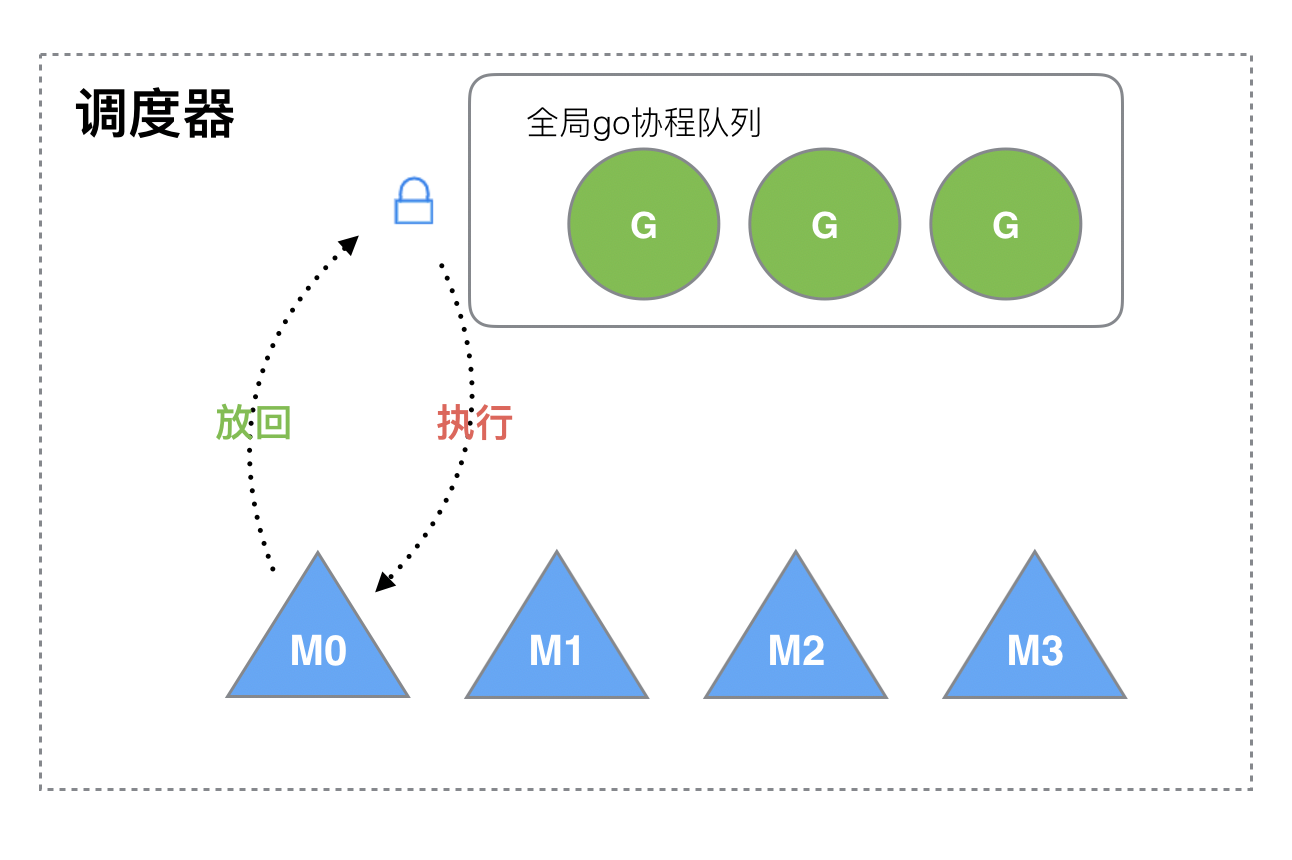
? M想要執行、放回G都必須訪問全局G隊列,并且M有多個,即多線程訪問同一資源需要加鎖進行保證互斥/同步,所以全局G隊列是有互斥鎖進行保護的。
老調度器有幾個缺點:
1. 創建、銷毀、調度G都需要每個M獲取鎖,這就形成了**激烈的鎖競爭**。
2. M轉移G會造成**延遲和額外的系統負載**。比如當G中包含創建新協程的時候,M創建了G’,為了繼續執行G,需要把G’交給M’執行,也造成了**很差的局部性**,因為G’和G是相關的,最好放在M上執行,而不是其他M'。
3. 系統調用(CPU在M之間的切換)導致頻繁的線程阻塞和取消阻塞操作增加了系統開銷。
## 二、Goroutine調度器的GMP模型的設計思想
面對之前調度器的問題,Go設計了新的調度器。
在新調度器中,出列M(thread)和G(goroutine),又引進了P(Processor)。
**Processor,它包含了運行goroutine的資源**,如果線程想運行goroutine,必須先獲取P,P中還包含了可運行的G隊列。
### (1)GMP模型
在Go中,**線程是運行goroutine的實體,調度器的功能是把可運行的goroutine分配到工作線程上**。
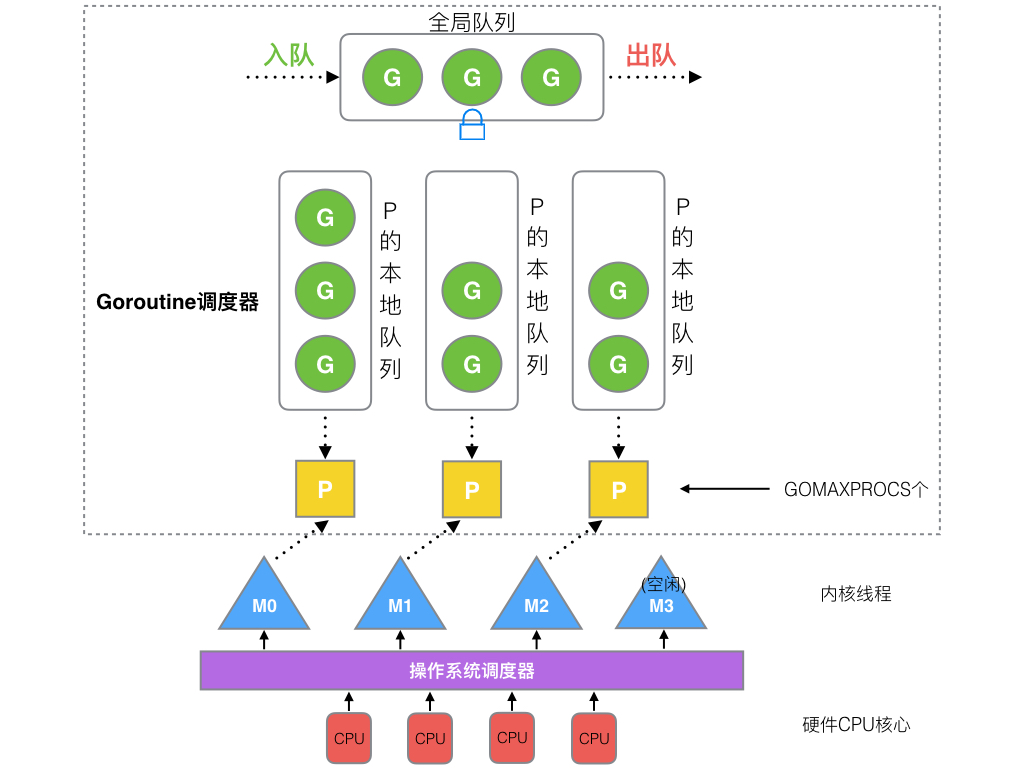
1. **全局隊列**(Global Queue):存放等待運行的G。
2. **P的本地隊列**:同全局隊列類似,存放的也是等待運行的G,存的數量有限,不超過256個。新建G'時,G'優先加入到P的本地隊列,如果隊列滿了,則會把本地隊列中一半的G移動到全局隊列。
3. **P列表**:所有的P都在程序啟動時創建,并保存在數組中,最多有`GOMAXPROCS`(可配置)個。
4. **M**:線程想運行任務就得獲取P,從P的本地隊列獲取G,P隊列為空時,M也會嘗試從全局隊列**拿**一批G放到P的本地隊列,或從其他P的本地隊列**偷**一半放到自己P的本地隊列。M運行G,G執行之后,M會從P獲取下一個G,不斷重復下去。
**Goroutine調度器和OS調度器是通過M結合起來的,每個M都代表了1個內核線程,OS調度器負責把內核線程分配到CPU的核上執行**。
> #### 有關P和M的個數問題
1、P的數量:
- 由啟動時環境變量`$GOMAXPROCS`或者是由`runtime`的方法`GOMAXPROCS()`決定。這意味著在程序執行的任意時刻都只有`$GOMAXPROCS`個goroutine在同時運行。
2、M的數量:
- go語言本身的限制:go程序啟動時,會設置M的最大數量,默認10000.但是內核很難支持這么多的線程數,所以這個限制可以忽略。
- runtime/debug中的SetMaxThreads函數,設置M的最大數量
- 一個M阻塞了,會創建新的M。
M與P的數量沒有絕對關系,一個M阻塞,P就會去創建或者切換另一個M,所以,即使P的默認數量是1,也有可能會創建很多個M出來。
> #### P和M何時會被創建
1、P何時創建:在確定了P的最大數量n后,運行時系統會根據這個數量創建n個P。
2、M何時創建:沒有足夠的M來關聯P并運行其中的可運行的G。比如所有的M此時都阻塞住了,而P中還有很多就緒任務,就會去尋找空閑的M,而沒有空閑的,就會去創建新的M。
### (2)調度器的設計策略
**復用線程**:避免頻繁的創建、銷毀線程,而是對線程的復用。
1)work stealing機制
? 當本線程無可運行的G時,嘗試從其他線程綁定的P偷取G,而不是銷毀線程。
2)hand off機制
? 當本線程因為G進行系統調用阻塞時,線程釋放綁定的P,把P轉移給其他空閑的線程執行。
**利用并行**:`GOMAXPROCS`設置P的數量,最多有`GOMAXPROCS`個線程分布在多個CPU上同時運行。`GOMAXPROCS`也限制了并發的程度,比如`GOMAXPROCS = 核數/2`,則最多利用了一半的CPU核進行并行。
**搶占**:在coroutine中要等待一個協程主動讓出CPU才執行下一個協程,在Go中,一個goroutine最多占用CPU 10ms,防止其他goroutine被餓死,這就是goroutine不同于coroutine的一個地方。
**全局G隊列**:在新的調度器中依然有全局G隊列,但功能已經被弱化了,當M執行work stealing從其他P偷不到G時,它可以從全局G隊列獲取G。
### (3) go func() 調度流程
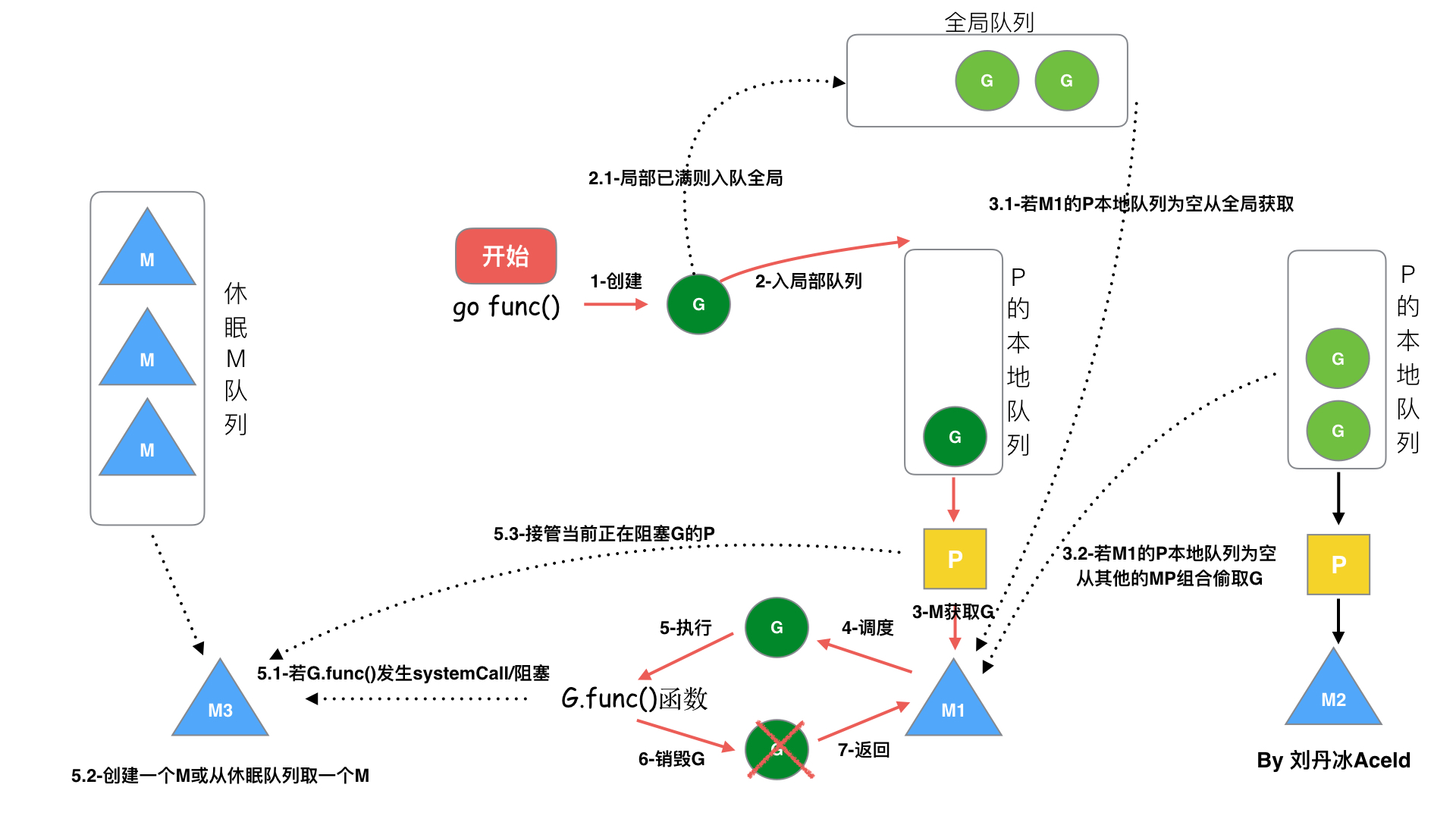
從上圖我們可以分析出幾個結論:
? 1、我們通過 go func()來創建一個goroutine;
? 2、有兩個存儲G的隊列,一個是局部調度器P的本地隊列、一個是全局G隊列。新創建的G會先保存在P的本地隊列中,如果P的本地隊列已經滿了就會保存在全局的隊列中;
? 3、G只能運行在M中,一個M必須持有一個P,M與P是1:1的關系。M會從P的本地隊列彈出一個可執行狀態的G來執行,如果P的本地隊列為空,就會想其他的MP組合偷取一個可執行的G來執行;
? 4、一個M調度G執行的過程是一個循環機制;
? 5、當M執行某一個G時候如果發生了syscall或則其余阻塞操作,M會阻塞,如果當前有一些G在執行,runtime會把這個線程M從P中摘除(detach),然后再創建一個新的操作系統的線程(如果有空閑的線程可用就復用空閑線程)來服務于這個P;
? 6、當M系統調用結束時候,這個G會嘗試獲取一個空閑的P執行,并放入到這個P的本地隊列。如果獲取不到P,那么這個線程M變成休眠狀態, 加入到空閑線程中,然后這個G會被放入全局隊列中。
### (4)調度器的生命周期
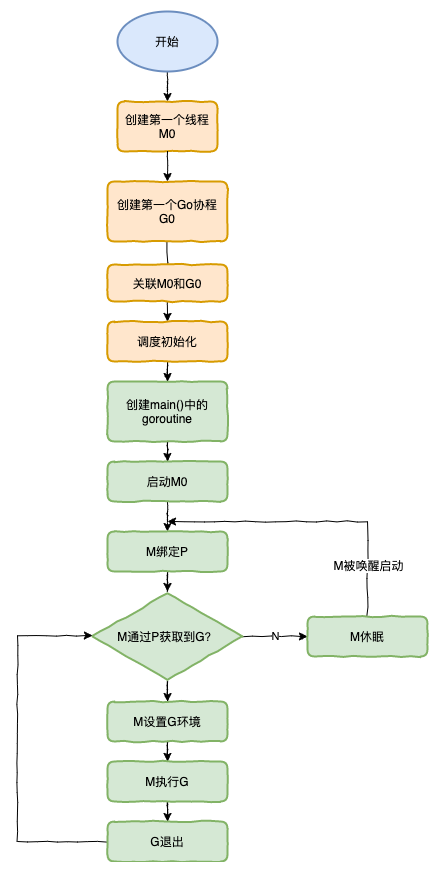
特殊的M0和G0
**M0**
`M0`是啟動程序后的編號為0的主線程,這個M對應的實例會在全局變量runtime.m0中,不需要在heap上分配,M0負責執行初始化操作和啟動第一個G, 在之后M0就和其他的M一樣了。
**G0**
`G0`是每次啟動一個M都會第一個創建的gourtine,G0僅用于負責調度的G,G0不指向任何可執行的函數, 每個M都會有一個自己的G0。在調度或系統調用時會使用G0的棧空間, 全局變量的G0是M0的G0。
我們來跟蹤一段代碼
```go
package main
import "fmt"
func main() {
fmt.Println("Hello world")
}
```
接下來我們來針對上面的代碼對調度器里面的結構做一個分析。
也會經歷如上圖所示的過程:
1. runtime創建最初的線程m0和goroutine g0,并把2者關聯。
2. 調度器初始化:初始化m0、棧、垃圾回收,以及創建和初始化由GOMAXPROCS個P構成的P列表。
3. 示例代碼中的main函數是`main.main`,`runtime`中也有1個main函數——`runtime.main`,代碼經過編譯后,`runtime.main`會調用`main.main`,程序啟動時會為`runtime.main`創建goroutine,稱它為main goroutine吧,然后把main goroutine加入到P的本地隊列。
4. 啟動m0,m0已經綁定了P,會從P的本地隊列獲取G,獲取到main goroutine。
5. G擁有棧,M根據G中的棧信息和調度信息設置運行環境
6. M運行G
7. G退出,再次回到M獲取可運行的G,這樣重復下去,直到`main.main`退出,`runtime.main`執行Defer和Panic處理,或調用`runtime.exit`退出程序。
調度器的生命周期幾乎占滿了一個Go程序的一生,`runtime.main`的goroutine執行之前都是為調度器做準備工作,`runtime.main`的goroutine運行,才是調度器的真正開始,直到`runtime.main`結束而結束。
### (5)可視化GMP編程
有2種方式可以查看一個程序的GMP的數據。
**方式1:go tool trace**
trace記錄了運行時的信息,能提供可視化的Web頁面。
簡單測試代碼:main函數創建trace,trace會運行在單獨的goroutine中,然后main打印"Hello World"退出。
> trace.go
```go
package main
import (
"os"
"fmt"
"runtime/trace"
)
func main() {
//創建trace文件
f, err := os.Create("trace.out")
if err != nil {
panic(err)
}
defer f.Close()
//啟動trace goroutine
err = trace.Start(f)
if err != nil {
panic(err)
}
defer trace.Stop()
//main
fmt.Println("Hello World")
}
```
運行程序
```bash
$ go run trace.go
Hello World
```
會得到一個`trace.out`文件,然后我們可以用一個工具打開,來分析這個文件。
```golang
$ go tool trace trace.out
2020/02/23 10:44:11 Parsing trace...
2020/02/23 10:44:11 Splitting trace...
2020/02/23 10:44:11 Opening browser. Trace viewer is listening on http://127.0.0.1:33479
```
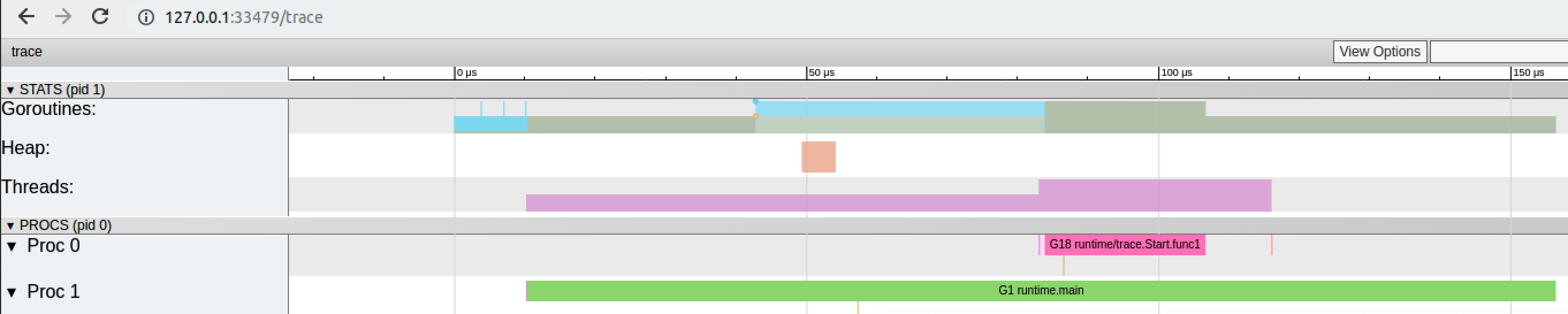
我們可以通過瀏覽器打開`http://127.0.0.1:33479`網址,點擊`view trace` 能夠看見可視化的調度流程。
**G信息**
點擊Goroutines那一行可視化的數據條,我們會看到一些詳細的信息。
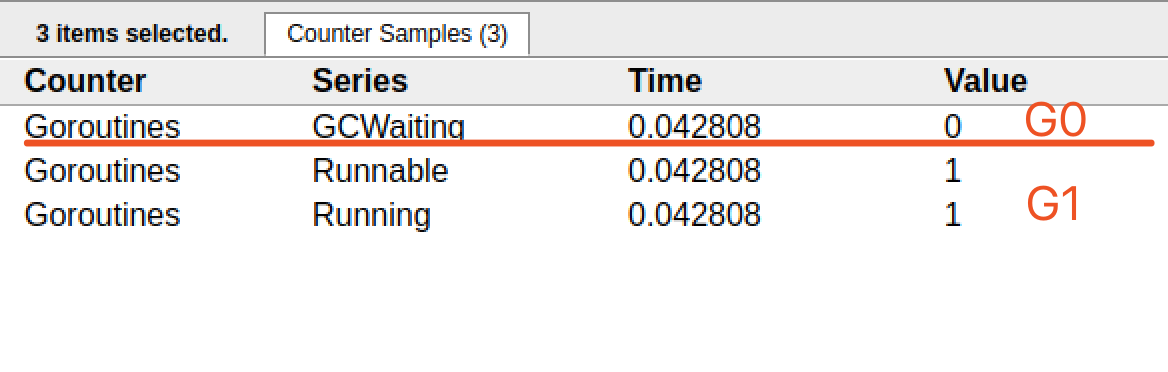
? 一共有兩個G在程序中,一個是特殊的G0,是每個M必須有的一個初始化的G,這個我們不必討論。
其中G1應該就是main goroutine(執行main函數的協程),在一段時間內處于可運行和運行的狀態。
**M信息**
點擊Threads那一行可視化的數據條,我們會看到一些詳細的信息。
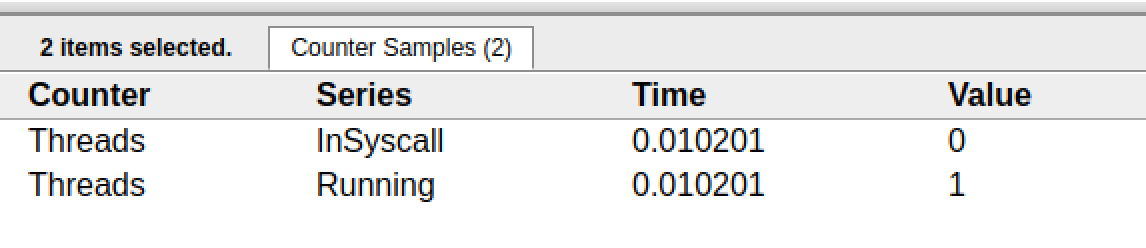
? 一共有兩個M在程序中,一個是特殊的M0,用于初始化使用,這個我們不必討論。
**P信息**

G1中調用了`main.main`,創建了`trace goroutine g18`。G1運行在P1上,G18運行在P0上。
這里有兩個P,我們知道,一個P必須綁定一個M才能調度G。
我們在來看看上面的M信息。
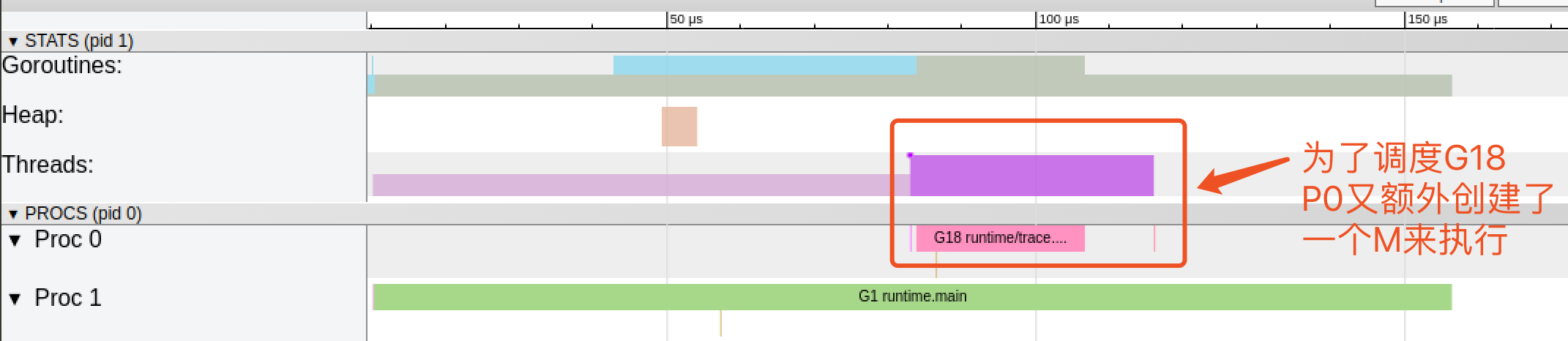
我們會發現,確實G18在P0上被運行的時候,確實在Threads行多了一個M的數據,點擊查看如下:
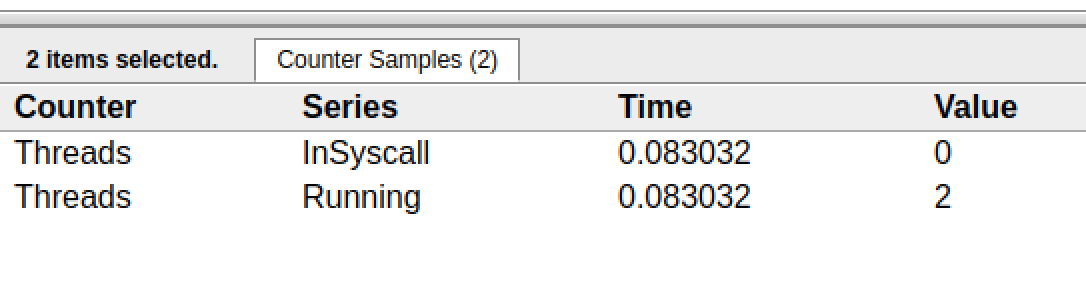
多了一個M2應該就是P0為了執行G18而動態創建的M2.
**方式2:Debug trace**
```go
package main
import (
"fmt"
"time"
)
func main() {
for i := 0; i < 5; i++ {
time.Sleep(time.Second)
fmt.Println("Hello World")
}
}
```
編譯
```bash
$ go build trace2.go
```
通過Debug方式運行
```bash
$ GODEBUG=schedtrace=1000 ./trace2
SCHED 0ms: gomaxprocs=2 idleprocs=0 threads=4 spinningthreads=1 idlethreads=1 runqueue=0 [0 0]
Hello World
SCHED 1003ms: gomaxprocs=2 idleprocs=2 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0]
Hello World
SCHED 2014ms: gomaxprocs=2 idleprocs=2 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0]
Hello World
SCHED 3015ms: gomaxprocs=2 idleprocs=2 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0]
Hello World
SCHED 4023ms: gomaxprocs=2 idleprocs=2 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0]
Hello World
```
- `SCHED`:調試信息輸出標志字符串,代表本行是goroutine調度器的輸出;
- `0ms`:即從程序啟動到輸出這行日志的時間;
- `gomaxprocs`: P的數量,本例有2個P, 因為默認的P的屬性是和cpu核心數量默認一致,當然也可以通過GOMAXPROCS來設置;
- `idleprocs`: 處于idle狀態的P的數量;通過gomaxprocs和idleprocs的差值,我們就可知道執行go代碼的P的數量;
- t`hreads: os threads/M`的數量,包含scheduler使用的m數量,加上runtime自用的類似sysmon這樣的thread的數量;
- `spinningthreads`: 處于自旋狀態的os thread數量;
- `idlethread`: 處于idle狀態的os thread的數量;
- `runqueue=0`: Scheduler全局隊列中G的數量;
- `[0 0]`: 分別為2個P的local queue中的G的數量。
下一篇,我們來繼續詳細的分析GMP調度原理的一些場景問題。
## 三、Go調度器調度場景過程全解析
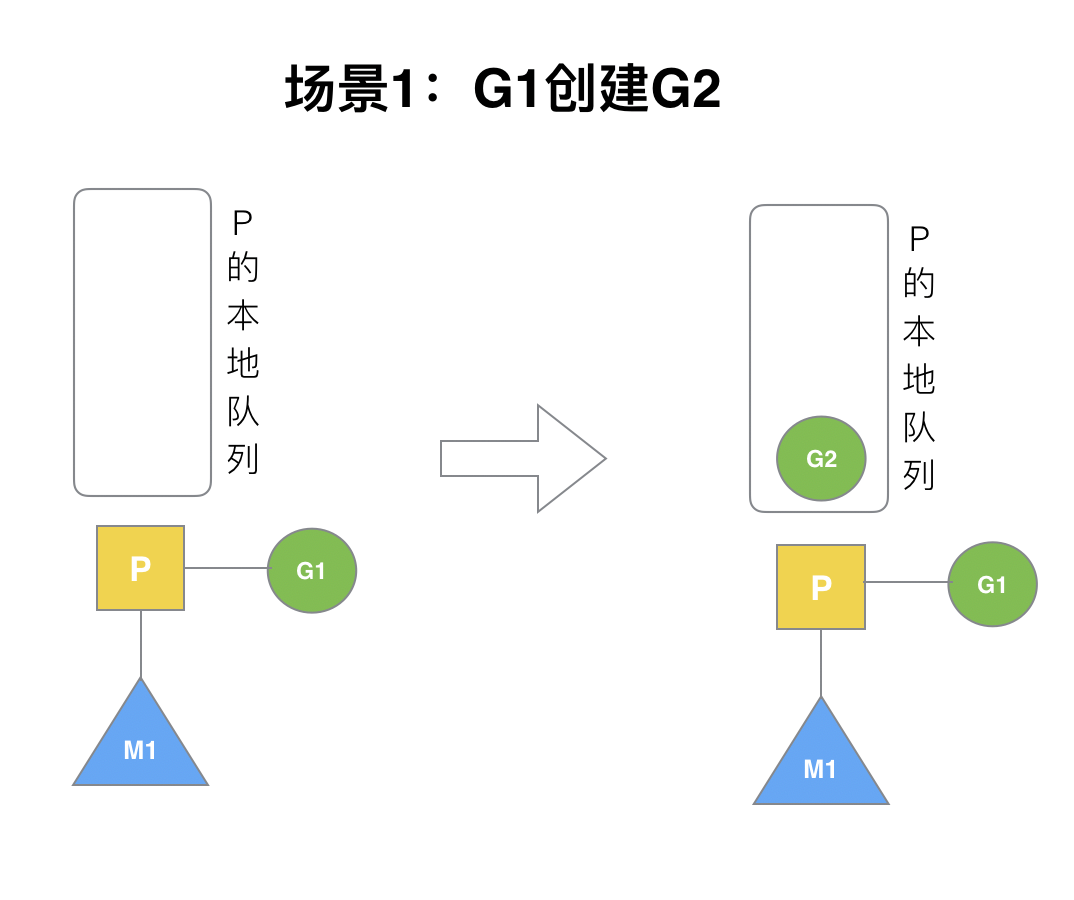
### (1)場景1
P擁有G1,M1獲取P后開始運行G1,G1使用`go func()`創建了G2,為了局部性G2優先加入到P1的本地隊列。
---
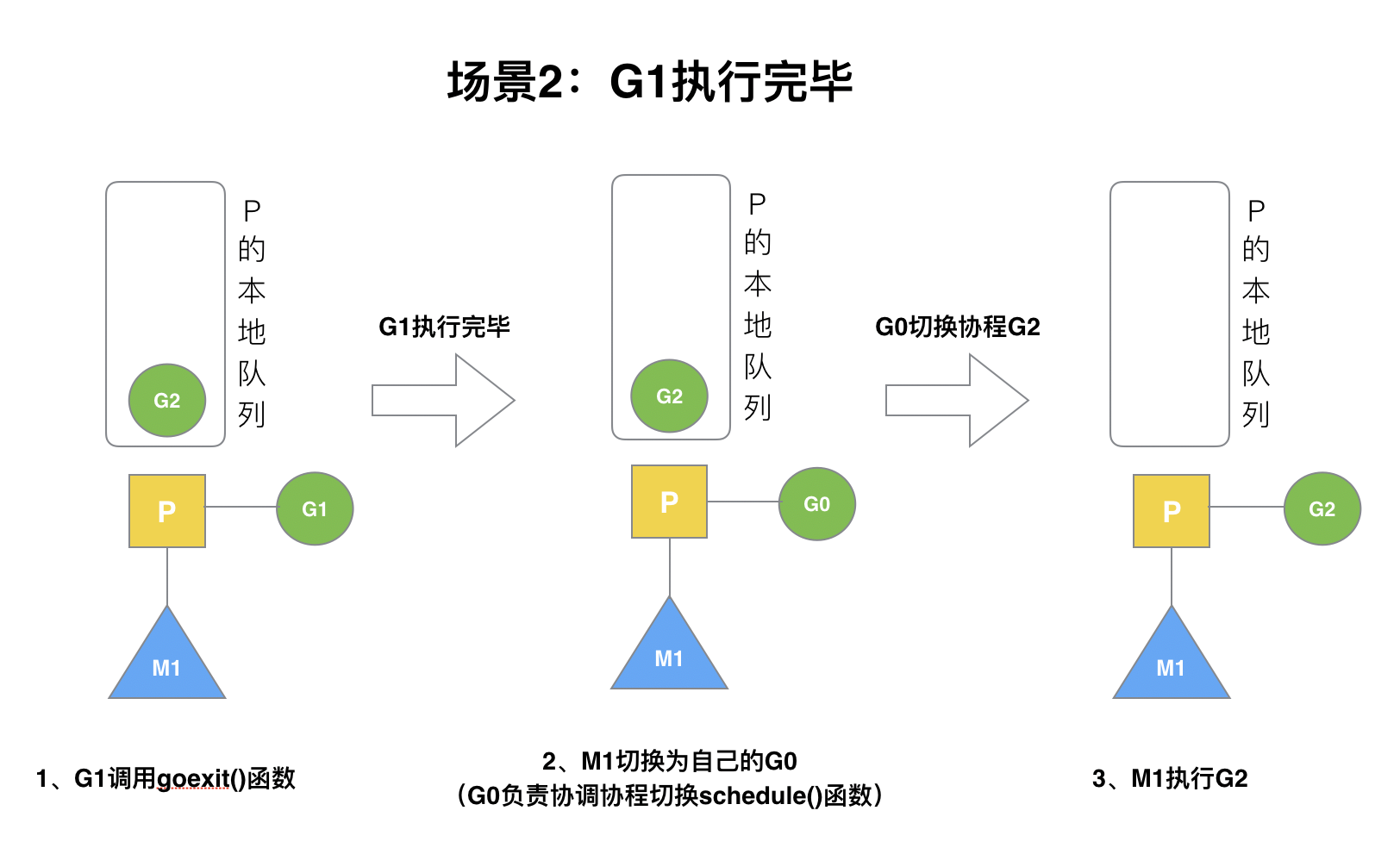
### (2)場景2
G1運行完成后(函數:`goexit`),M上運行的goroutine切換為G0,G0負責調度時協程的切換(函數:`schedule`)。從P的本地隊列取G2,從G0切換到G2,并開始運行G2(函數:`execute`)。實現了線程M1的復用。
---
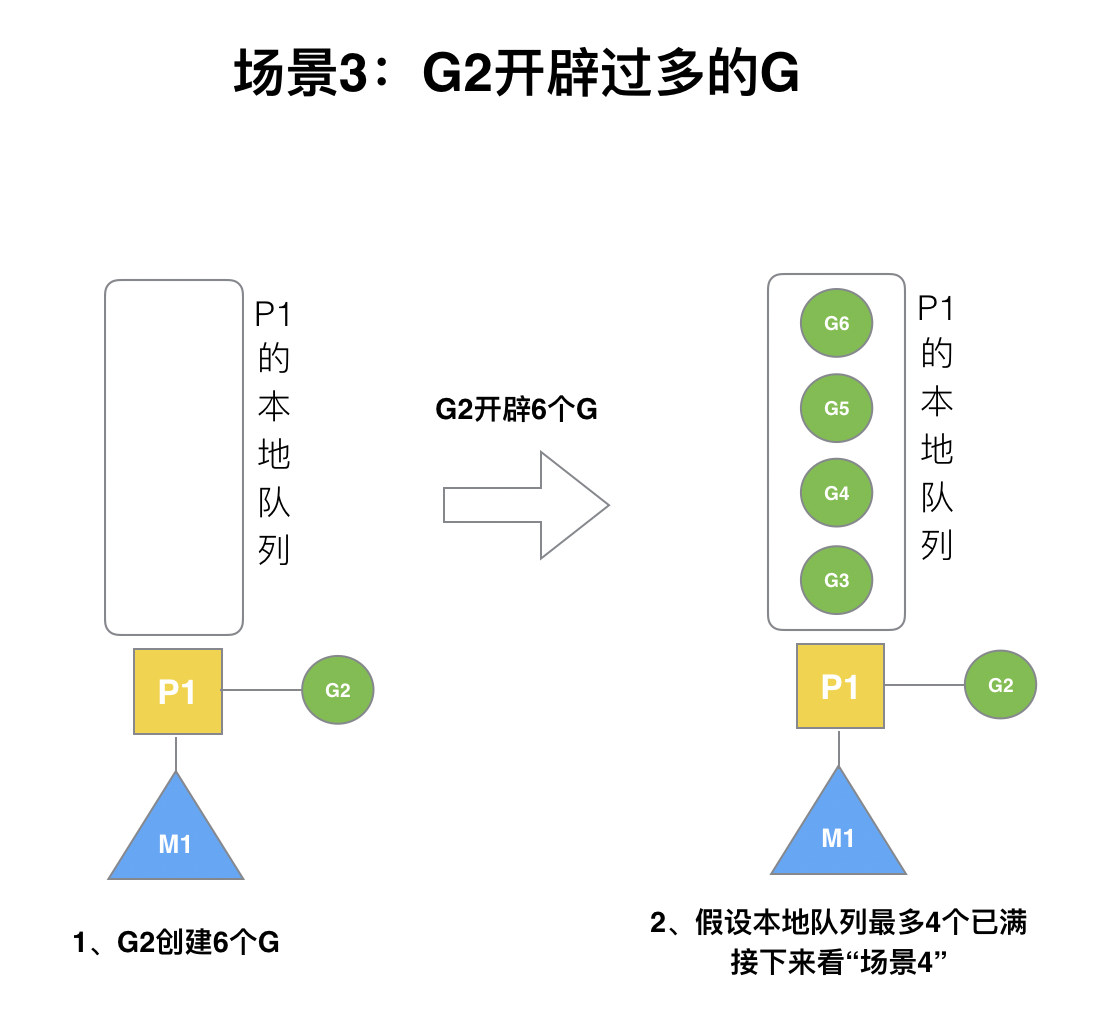
### (3)場景3
假設每個P的本地隊列只能存3個G。G2要創建了6個G,前3個G(G3, G4, G5)已經加入p1的本地隊列,p1本地隊列滿了。
---
### (4)場景4
G2在創建G7的時候,發現P1的本地隊列已滿,需要執行**負載均衡**(把P1中本地隊列中前一半的G,還有新創建G**轉移**到全局隊列)
> (實現中并不一定是新的G,如果G是G2之后就執行的,會被保存在本地隊列,利用某個老的G替換新G加入全局隊列)
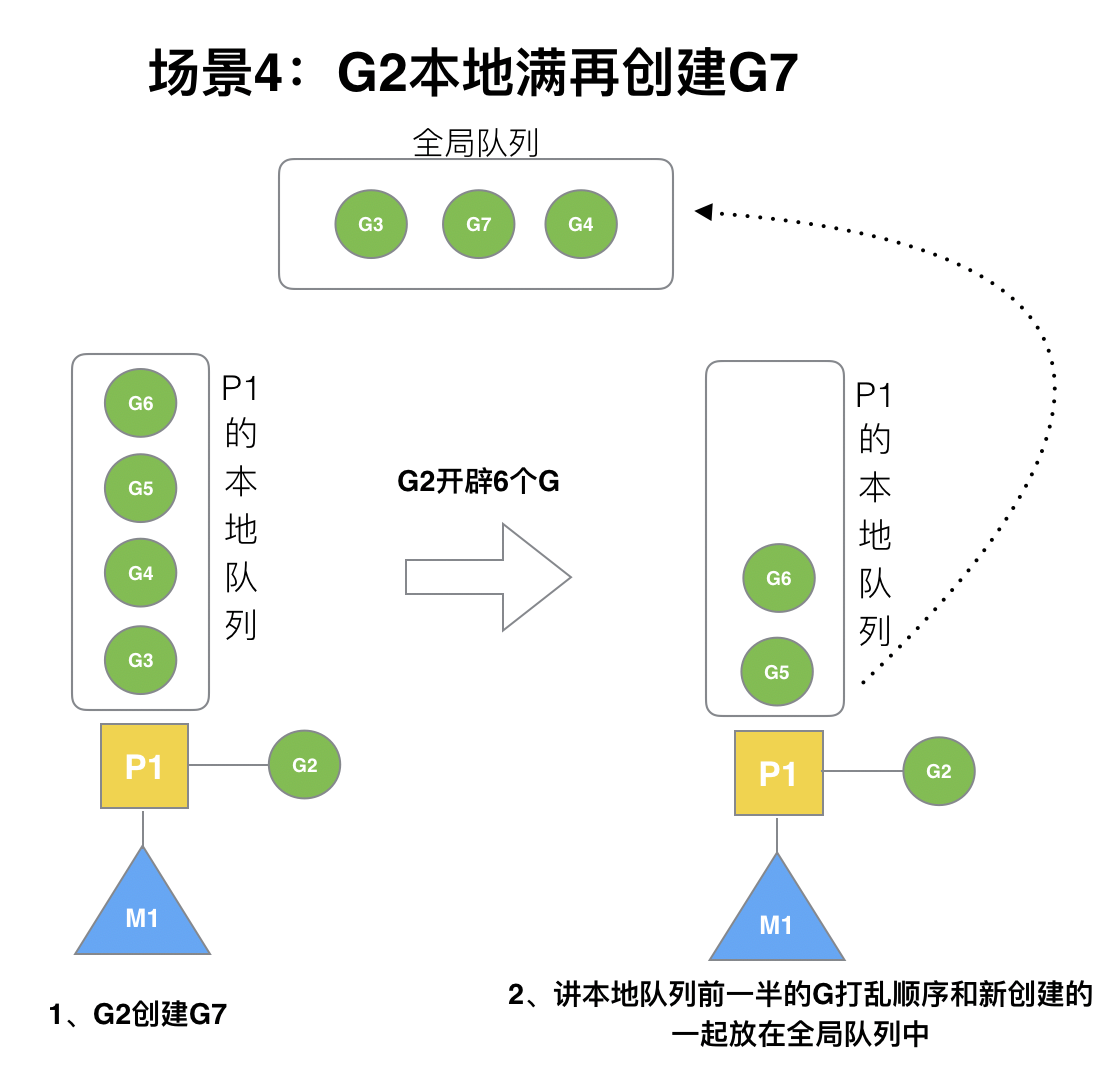
這些G被轉移到全局隊列時,會被打亂順序。所以G3,G4,G7被轉移到全局隊列。
---
### (5)場景5
G2創建G8時,P1的本地隊列未滿,所以G8會被加入到P1的本地隊列。
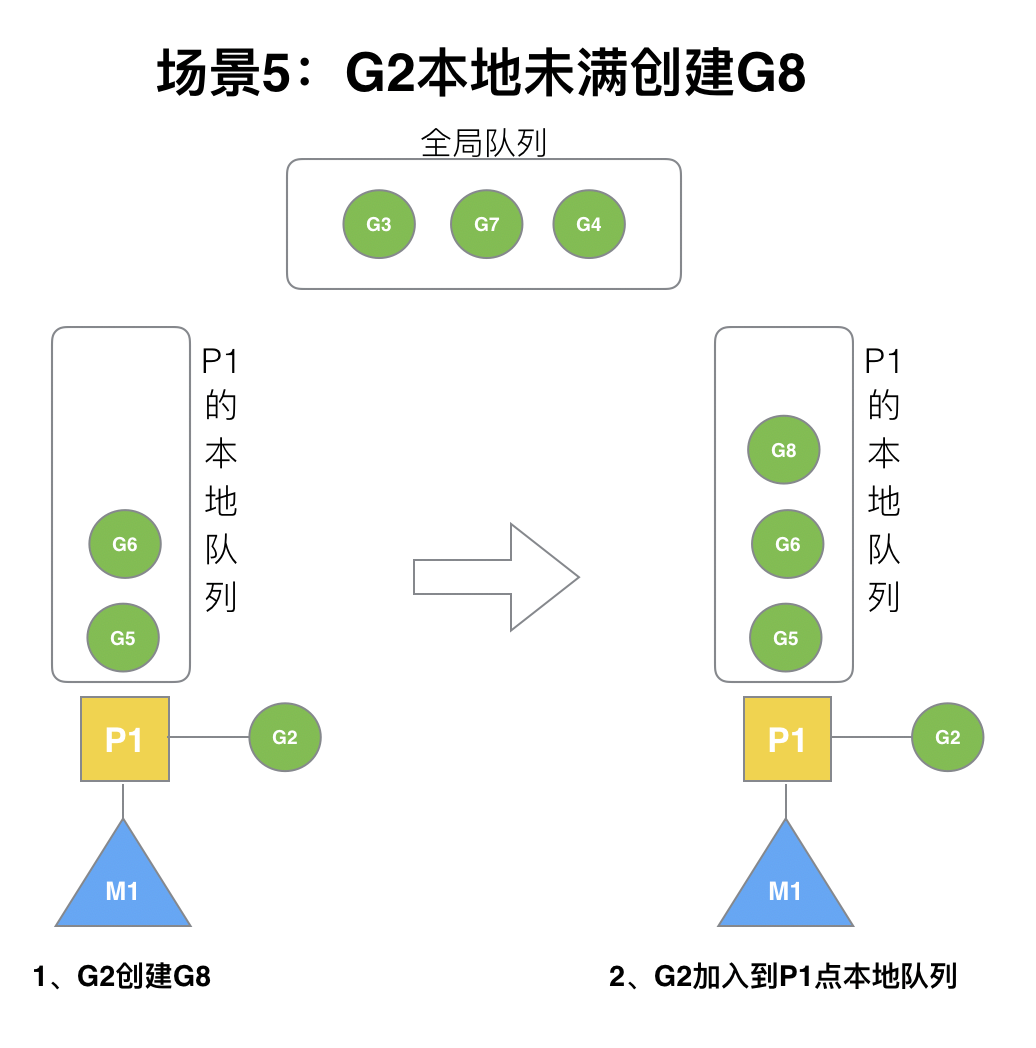
? G8加入到P1點本地隊列的原因還是因為P1此時在與M1綁定,而G2此時是M1在執行。所以G2創建的新的G會優先放置到自己的M綁定的P上。
---
### (6)場景6
規定:**在創建G時,運行的G會嘗試喚醒其他空閑的P和M組合去執行**。
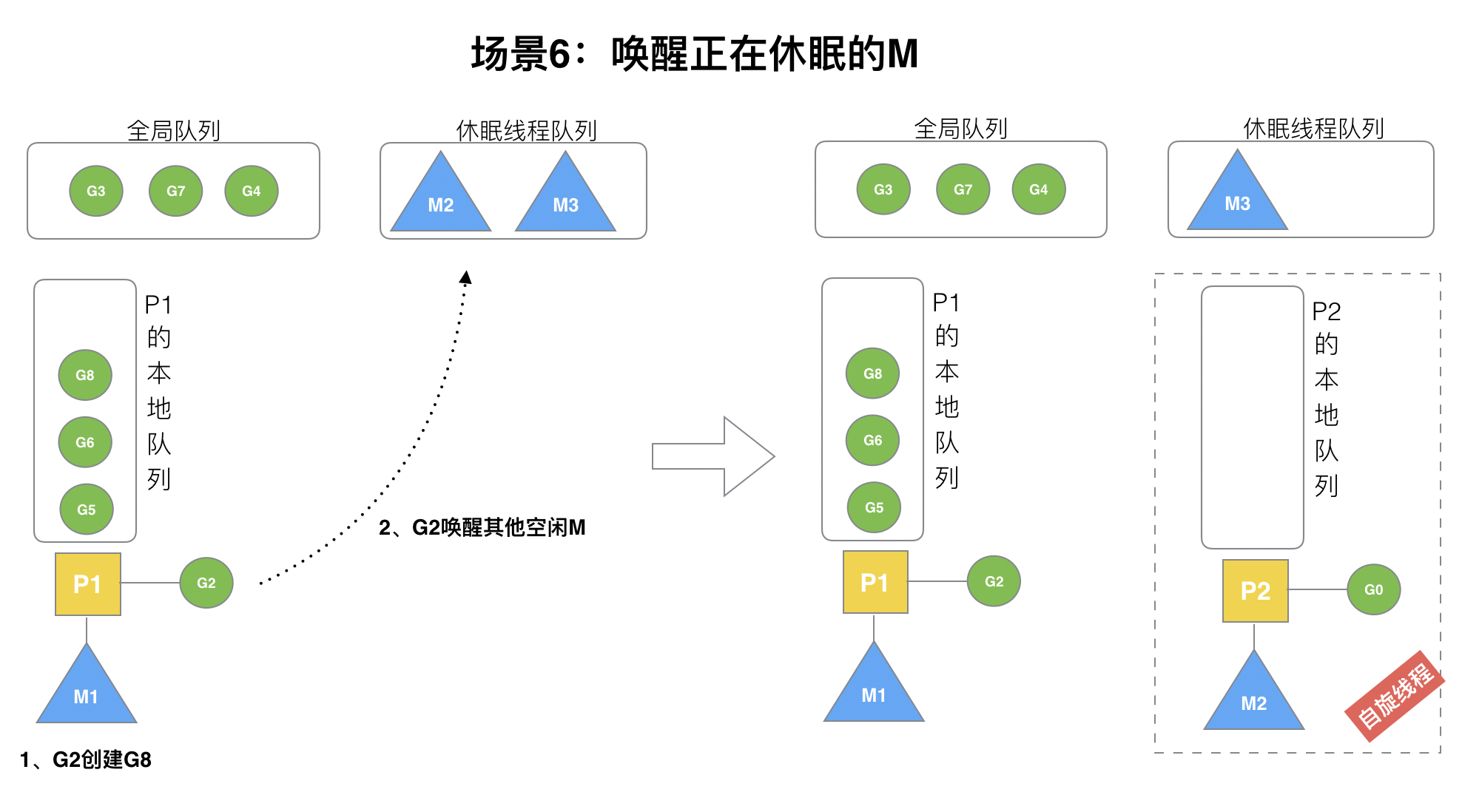
假定G2喚醒了M2,M2綁定了P2,并運行G0,但P2本地隊列沒有G,M2此時為自旋線程**(沒有G但為運行狀態的線程,不斷尋找G)**。
---
### (7)場景7
M2嘗試從全局隊列(簡稱“GQ”)取一批G放到P2的本地隊列(函數:`findrunnable()`)。M2從全局隊列取的G數量符合下面的公式:
```go
n = min(len(GQ) / GOMAXPROCS + 1, cap(LQ) / 2 )
```
相關源碼參考:
```go
// 從全局隊列中偷取,調用時必須鎖住調度器
func globrunqget(_p_ *p, max int32) *g {
// 如果全局隊列中沒有 g 直接返回
if sched.runqsize == 0 {
return nil
}
// per-P 的部分,如果只有一個 P 的全部取
n := sched.runqsize/gomaxprocs + 1
if n > sched.runqsize {
n = sched.runqsize
}
// 不能超過取的最大個數
if max > 0 && n > max {
n = max
}
// 計算能不能在本地隊列中放下 n 個
if n > int32(len(_p_.runq))/2 {
n = int32(len(_p_.runq)) / 2
}
// 修改本地隊列的剩余空間
sched.runqsize -= n
// 拿到全局隊列隊頭 g
gp := sched.runq.pop()
// 計數
n--
// 繼續取剩下的 n-1 個全局隊列放入本地隊列
for ; n > 0; n-- {
gp1 := sched.runq.pop()
runqput(_p_, gp1, false)
}
return gp
}
```
至少從全局隊列取1個g,但每次不要從全局隊列移動太多的g到p本地隊列,給其他p留點。這是**從全局隊列到P本地隊列的負載均衡**。
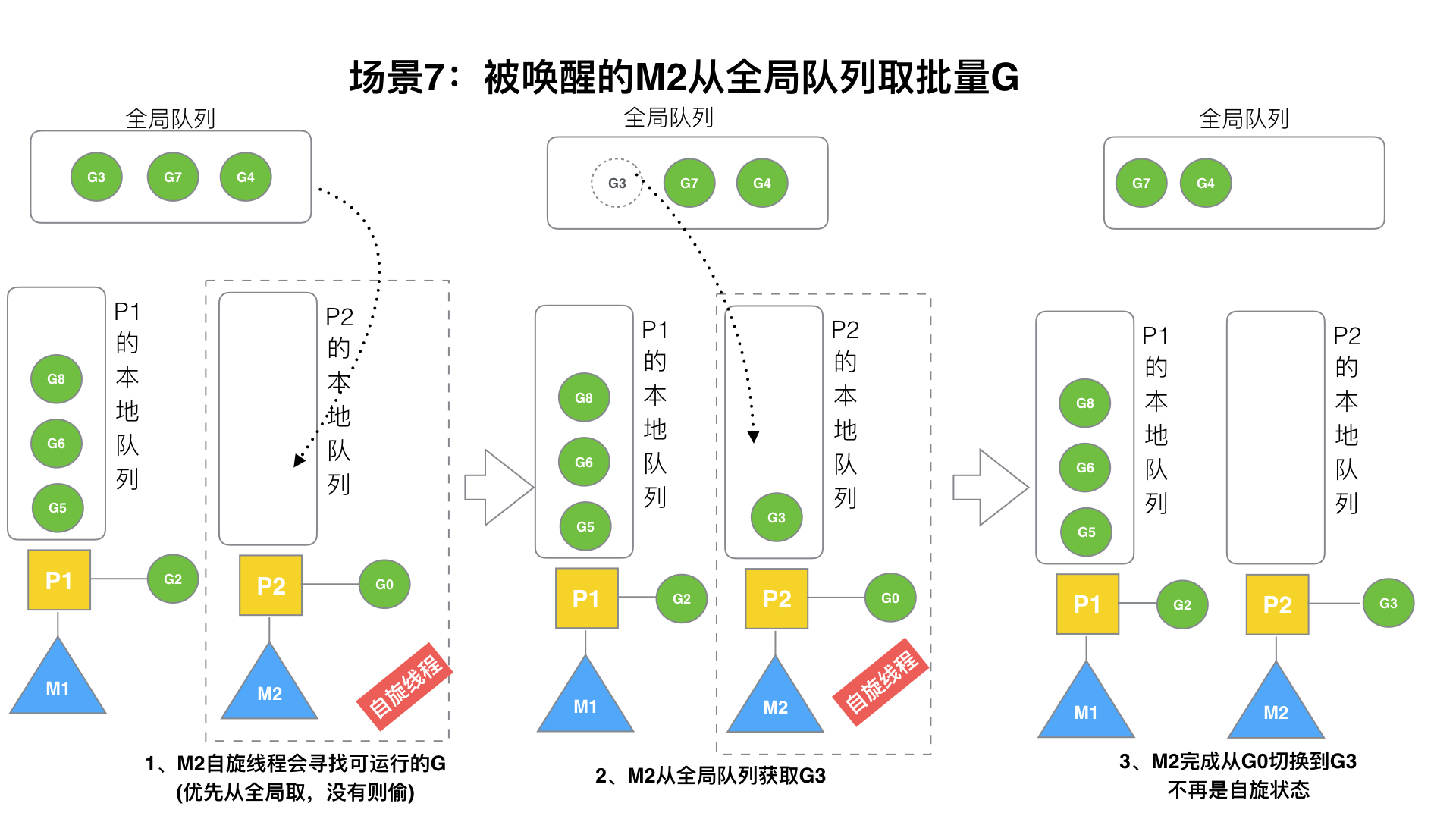
? 假定我們場景中一共有4個P(GOMAXPROCS設置為4,那么我們允許最多就能用4個P來供M使用)。所以M2只從能從全局隊列取1個G(即G3)移動P2本地隊列,然后完成從G0到G3的切換,運行G3。
---
### (8)場景8
假設G2一直在M1上運行,經過2輪后,M2已經把G7、G4從全局隊列獲取到了P2的本地隊列并完成運行,全局隊列和P2的本地隊列都空了,如場景8圖的左半部分。
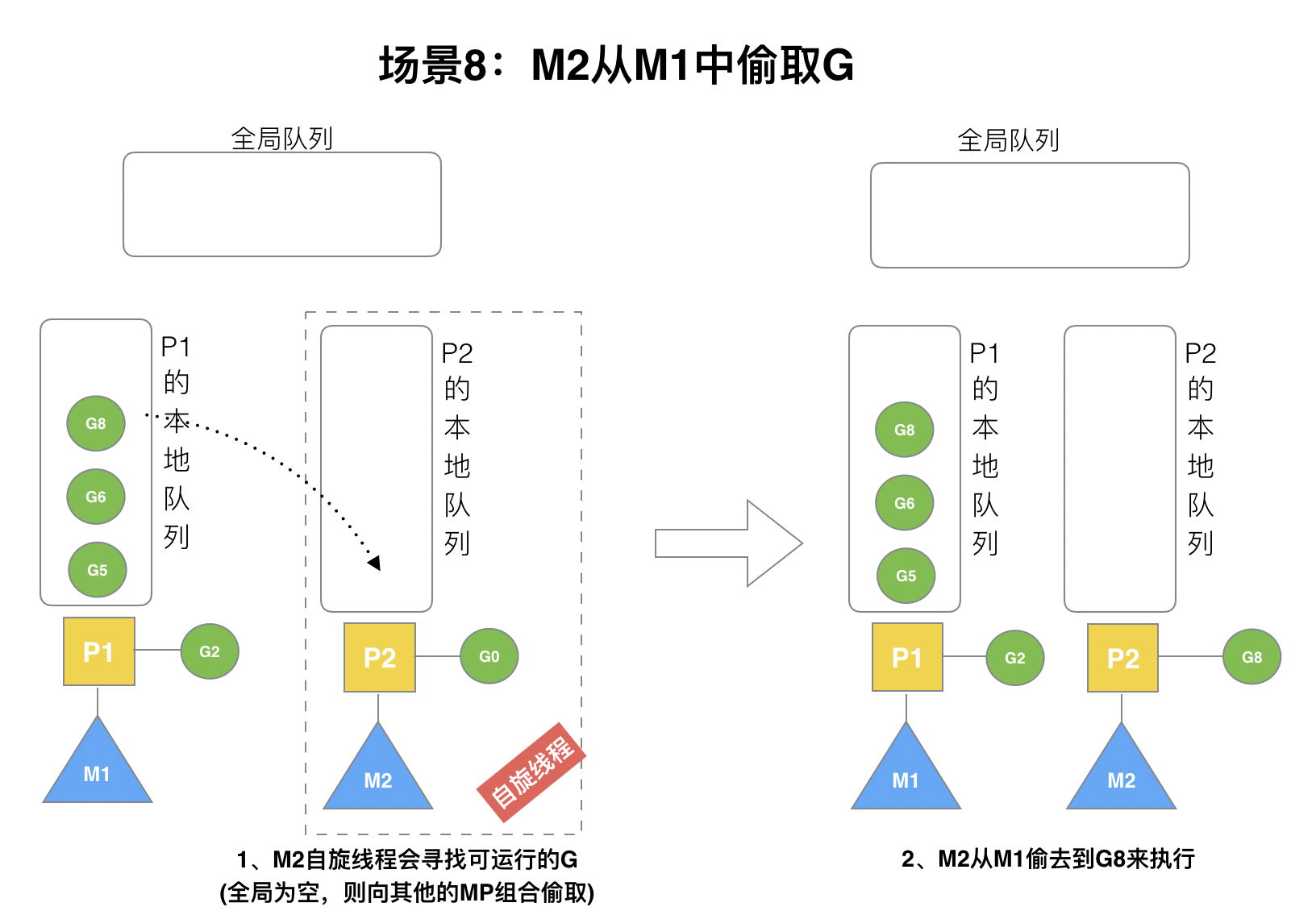
? **全局隊列已經沒有G,那m就要執行work stealing(偷取):從其他有G的P哪里偷取一半G過來,放到自己的P本地隊列**。P2從P1的本地隊列尾部取一半的G,本例中一半則只有1個G8,放到P2的本地隊列并執行。
---
### (9)場景9
G1本地隊列G5、G6已經被其他M偷走并運行完成,當前M1和M2分別在運行G2和G8,M3和M4沒有goroutine可以運行,M3和M4處于**自旋狀態**,它們不斷尋找goroutine。
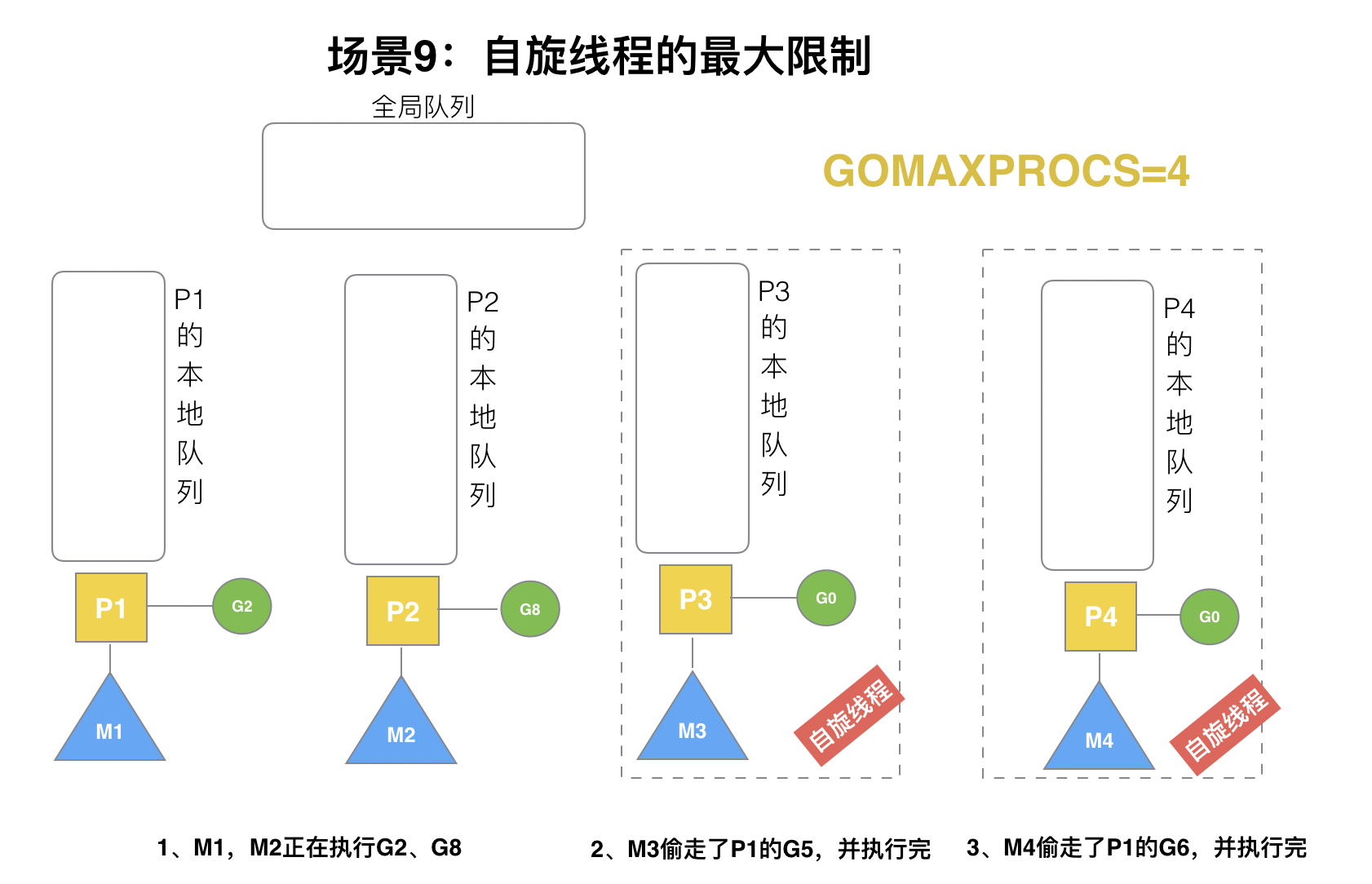
? 為什么要讓m3和m4自旋,自旋本質是在運行,線程在運行卻沒有執行G,就變成了浪費CPU. 為什么不銷毀現場,來節約CPU資源。因為創建和銷毀CPU也會浪費時間,我們**希望當有新goroutine創建時,立刻能有M運行它**,如果銷毀再新建就增加了時延,降低了效率。當然也考慮了過多的自旋線程是浪費CPU,所以系統中最多有`GOMAXPROCS`個自旋的線程(當前例子中的`GOMAXPROCS`=4,所以一共4個P),多余的沒事做線程會讓他們休眠。
---
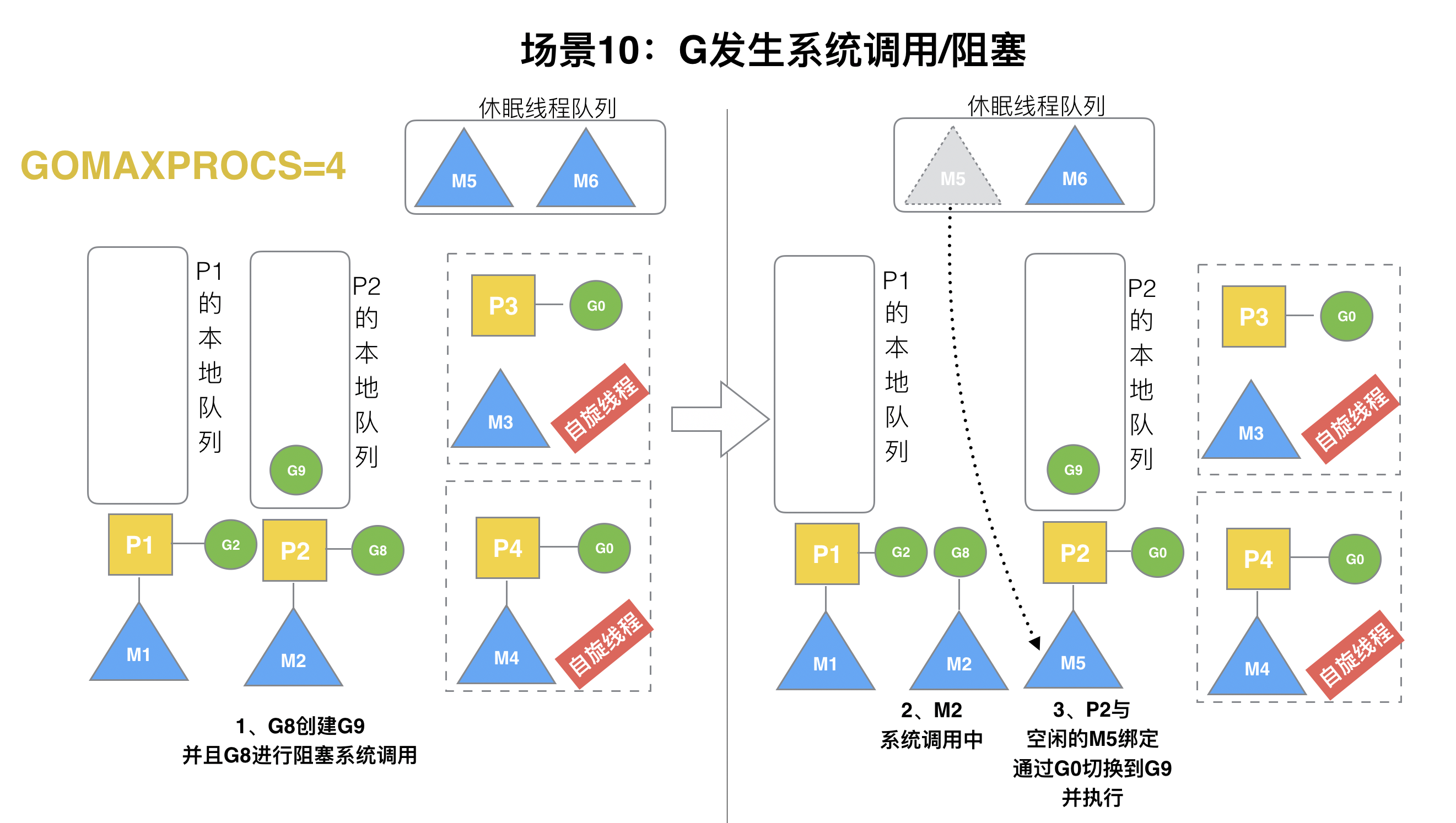
### (10)場景10
? 假定當前除了M3和M4為自旋線程,還有M5和M6為空閑的線程(沒有得到P的綁定,注意我們這里最多就只能夠存在4個P,所以P的數量應該永遠是M>=P, 大部分都是M在搶占需要運行的P),G8創建了G9,G8進行了**阻塞的系統調用**,M2和P2立即解綁,P2會執行以下判斷:如果P2本地隊列有G、全局隊列有G或有空閑的M,P2都會立馬喚醒1個M和它綁定,否則P2則會加入到空閑P列表,等待M來獲取可用的p。本場景中,P2本地隊列有G9,可以和其他空閑的線程M5綁定。
---
### (11)場景11
G8創建了G9,假如G8進行了**非阻塞系統調用**。
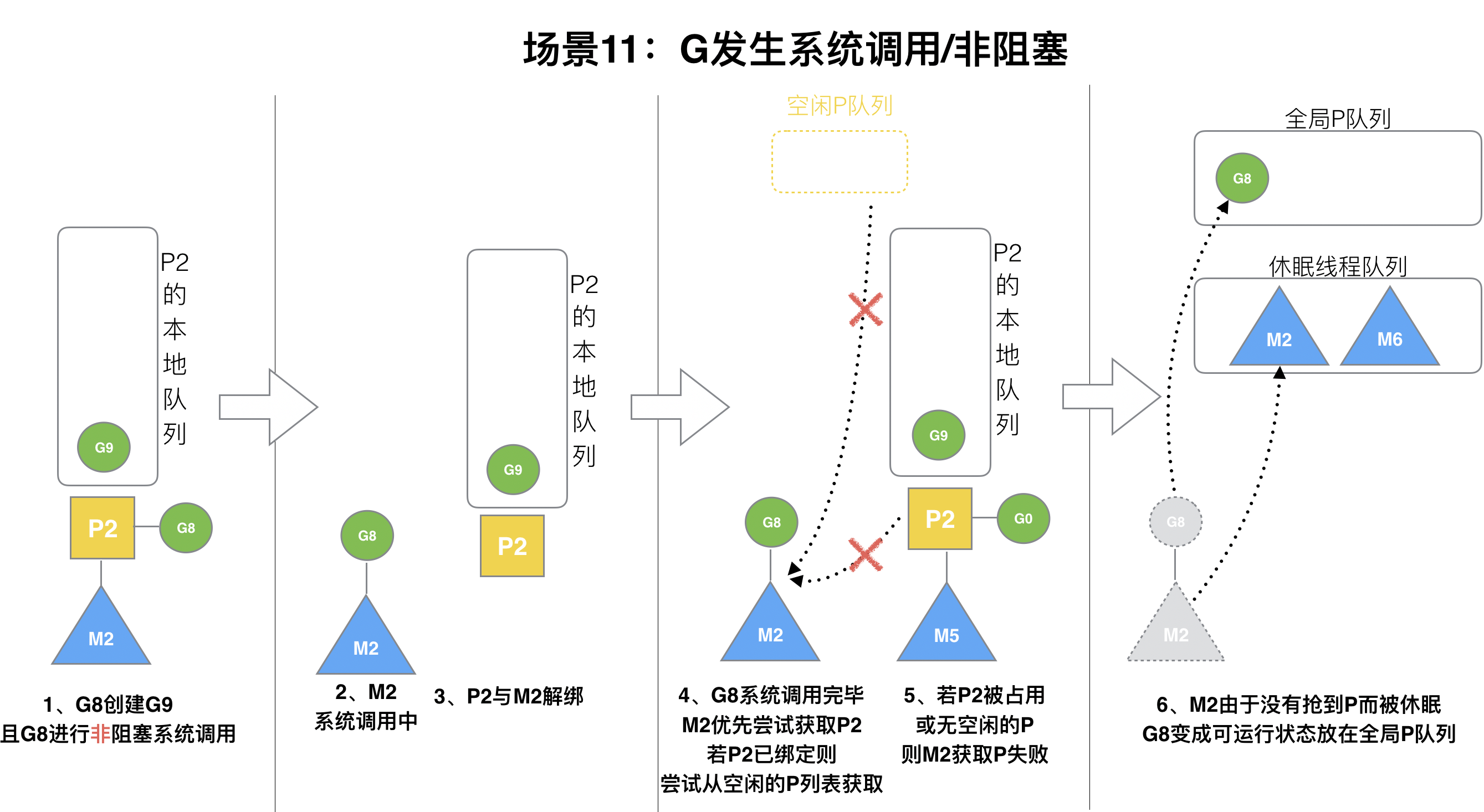
? M2和P2會解綁,但M2會記住P2,然后G8和M2進入**系統調用**狀態。當G8和M2退出系統調用時,會嘗試獲取P2,如果無法獲取,則獲取空閑的P,如果依然沒有,G8會被記為可運行狀態,并加入到全局隊列,M2因為沒有P的綁定而變成休眠狀態(長時間休眠等待GC回收銷毀)。
---
## 四、小結
總結,Go調度器很輕量也很簡單,足以撐起goroutine的調度工作,并且讓Go具有了原生(強大)并發的能力。**Go調度本質是把大量的goroutine分配到少量線程上去執行,并利用多核并行,實現更強大的并發。**
## 五、思維導圖筆記
- 封面
- 第一篇:Golang修養必經之路
- 1、最常用的調試 golang 的 bug 以及性能問題的實踐方法?
- 2、Golang的協程調度器原理及GMP設計思想?
- 3、Golang中逃逸現象, 變量“何時棧?何時堆?”
- 4、Golang中make與new有何區別?
- 5、Golang三色標記+混合寫屏障GC模式全分析
- 6、面向對象的編程思維理解interface
- 7、Golang中的Defer必掌握的7知識點
- 8、精通Golang項目依賴Go modules
- 9、一站式精通Golang內存管理
- 第二篇:Golang面試之路
- 1、數據定義
- 2、數組和切片
- 3、Map
- 4、interface
- 5、channel
- 6、WaitGroup
- 第三篇、Golang編程設計與通用之路
- 1、流?I/O操作?阻塞?epoll?
- 2、分布式從ACID、CAP、BASE的理論推進
- 3、對于操作系統而言進程、線程以及Goroutine協程的區別
- 4、Go是否可以無限go? 如何限定數量?
- 5、單點Server的N種并發模型匯總
- 6、TCP中TIME_WAIT狀態意義詳解
- 7、動態保活Worker工作池設計