
[TOC]
## 5、單點Server的N種并發模型匯總
本文主要介紹常見的Server的并發模型,這些模型與編程語言本身無關,有的編程語言可能在語法上直接透明了模型本質,所以開發者沒必要一定要基于模型去編寫,只是需要知道和了解并發模型的構成和特點即可。
那么在了解并發模型之前,我們需要兩個必備的前置知識:
* socket網絡編程
* 多路IO復用機制
* 多線程/多進程等并發編程理論
### 模型一、單線程Accept(無IO復用)
#### (1) 模型結構圖
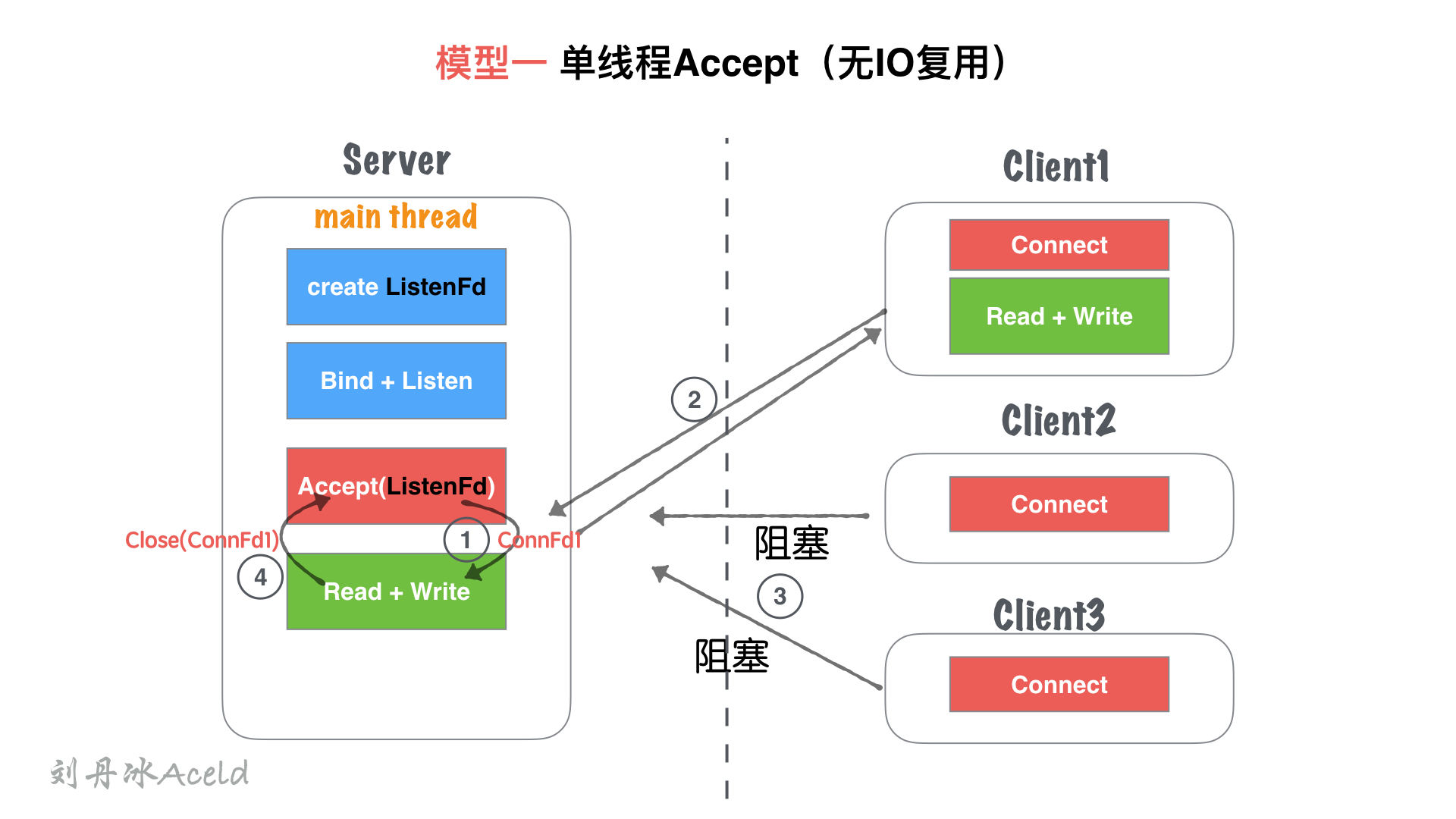
#### (2) 模型分析
① 主線程`main thread`執行阻塞Accept,每次客戶端Connect鏈接過來,`main thread`中accept響應并建立連接
② 創建鏈接成功,得到`Connfd1`套接字后, 依然在`main thread`串行處理套接字讀寫,并處理業務。
③ 在②處理業務中,如果有新客戶端`Connect`過來,`Server`無響應,直到當前套接字全部業務處理完畢。
④ 當前客戶端處理完后,完畢鏈接,處理下一個客戶端請求。
#### (3) 優缺點
**優點**:
* socket編程流程清晰且簡單,適合學習使用,了解socket基本編程流程。
**缺點**:
* 該模型并非并發模型,是串行的服務器,同一時刻,監聽并響應最大的網絡請求量為`1`。 即并發量為`1`。
* 僅適合學習基本socket編程,不適合任何服務器Server構建。
### 模型二、單線程Accept+多線程讀寫業務(無IO復用)
#### (1) 模型結構圖
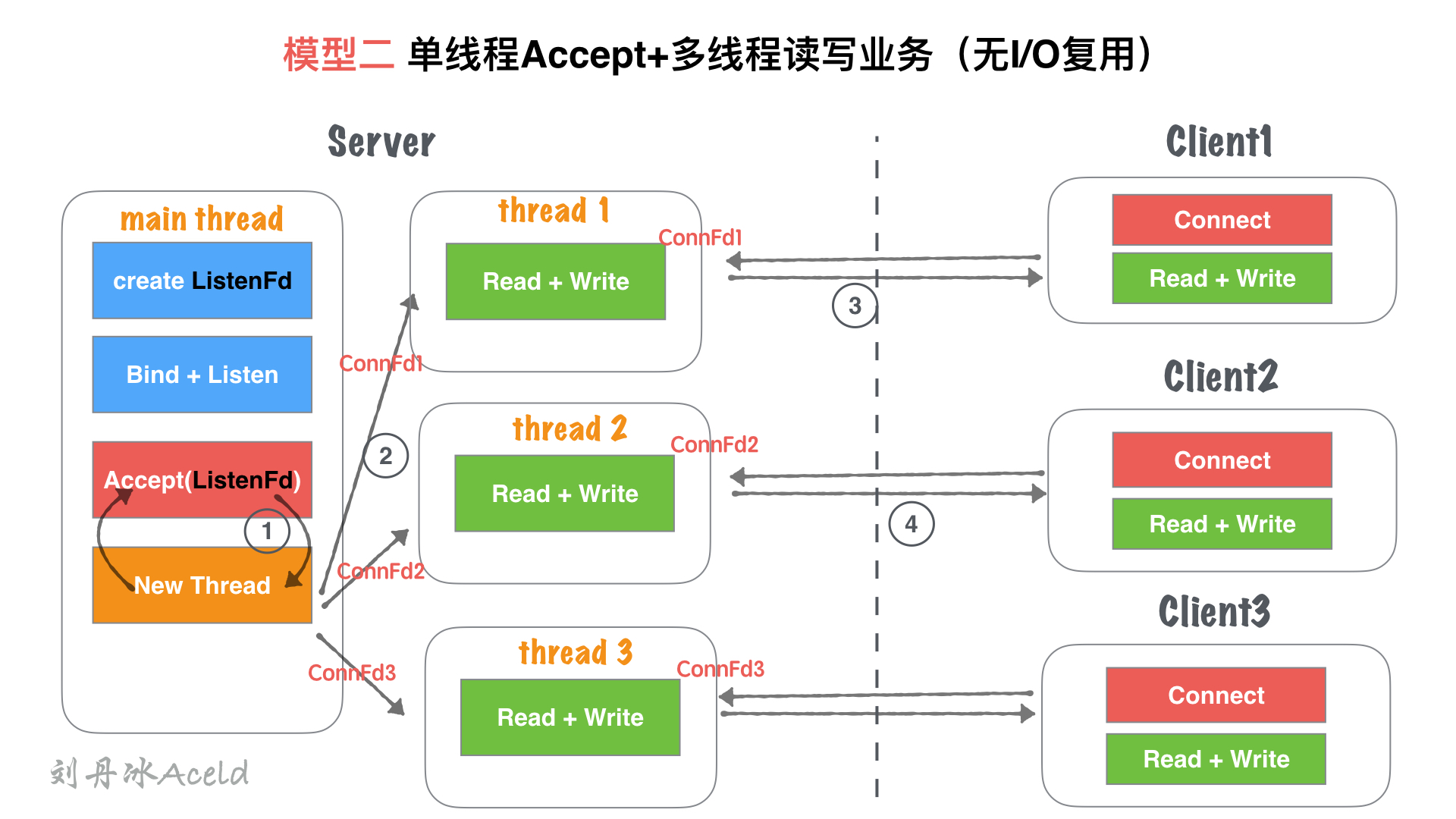
#### (2) 模型分析
① 主線程`main thread`執行阻塞Accept,每次客戶端Connect鏈接過來,`main thread`中accept響應并建立連接
② 創建鏈接成功,得到`Connfd1`套接字后,創建一個新線程`thread1`用來處理客戶端的讀寫業務。`main thead`依然回到`Accept`阻塞等待新客戶端。
③ `thread1`通過套接字`Connfd1`與客戶端進行通信讀寫。
④ server在②處理業務中,如果有新客戶端`Connect`過來,`main thread`中`Accept`依然響應并建立連接,重復②過程。
#### (3) 優缺點
**優點**:
* 基于`模型一:單線程Accept(無IO復用)` 支持了并發的特性。
* 使用靈活,一個客戶端對應一個線程單獨處理,`server`處理業務內聚程度高,客戶端無論如何寫,服務端均會有一個線程做資源響應。
**缺點**:
* 隨著客戶端的數量增多,需要開辟的線程也增加,客戶端與server線程數量`1:1`正比關系,一次對于高并發場景,線程數量收到硬件上限瓶頸。
* 對于長鏈接,客戶端一旦無業務讀寫,只要不關閉,server的對應線程依然需要保持連接(心跳、健康監測等機制),占用連接資源和線程開銷資源浪費。
* 僅適合客戶端數量不大,并且數量可控的場景使用。
僅適合學習基本socket編程,不適合任何服務器Server構建。
### 模型三、單線程多路IO復用
#### (1) 模型結構圖
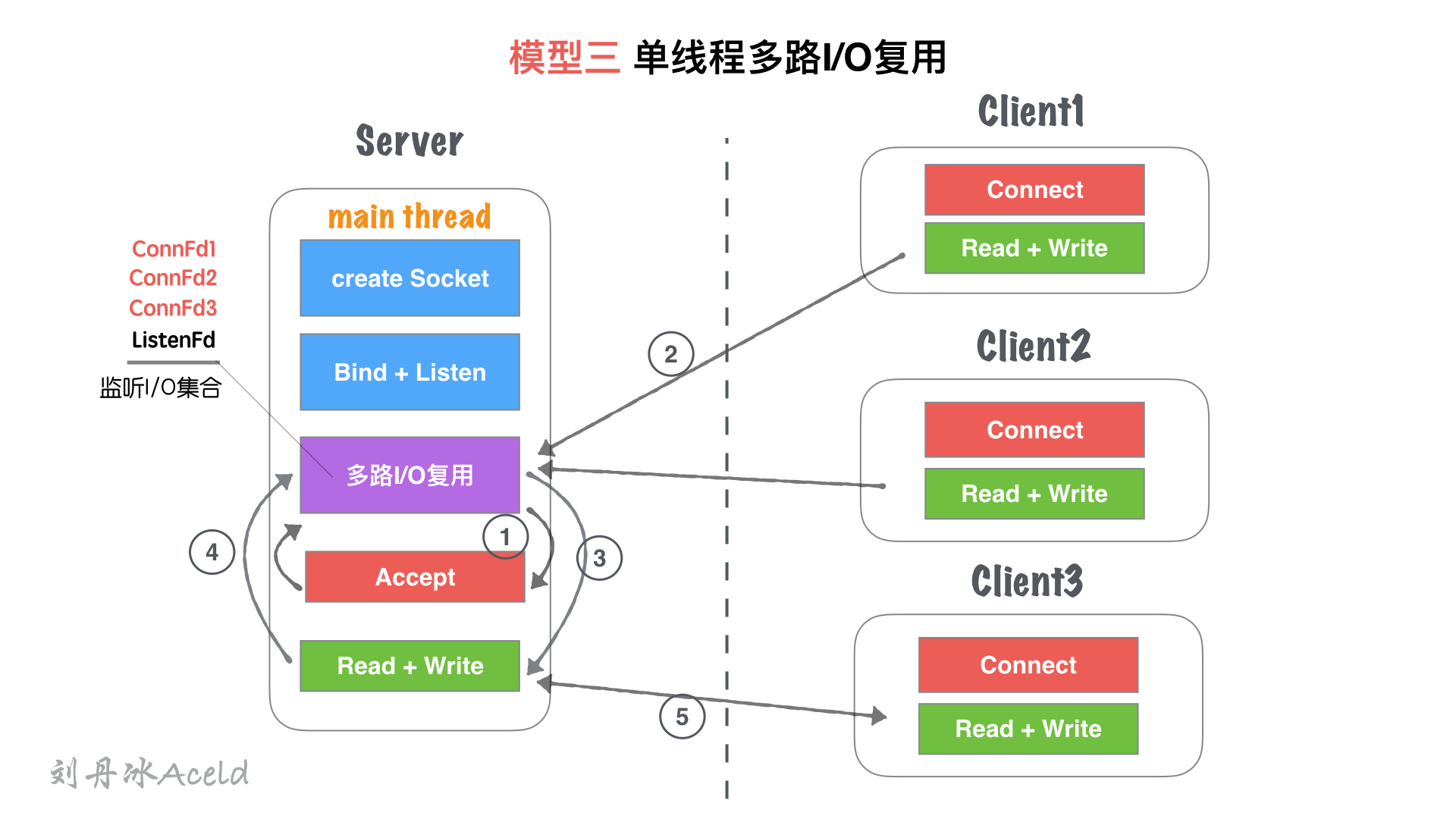
#### (2) 模型分析
① 主線程`main thread`創建`listenFd`之后,采用多路I/O復用機制(如:select、epoll)進行IO狀態阻塞監控。有`Client1`客戶端`Connect`請求,I/O復用機制檢測到`ListenFd`觸發讀事件,則進行`Accept`建立連接,并將新生成的`connFd1`加入到`監聽I/O集合`中。
② `Client1`再次進行正常讀寫業務請求,`main thread`的`多路I/O復用機制`阻塞返回,會觸該套接字的讀/寫事件等。
③ 對于`Client1`的讀寫業務,Server依然在`main thread`執行流程提繼續執行,此時如果有新的客戶端`Connect`鏈接請求過來,Server將沒有即時響應。
④ 等到Server處理完一個連接的`Read+Write`操作,繼續回到`多路I/O復用機制`阻塞,其他鏈接過來重復 ②、③流程。
#### (3) 優缺點
**優點**:
* 單流程解決了可以同時監聽多個客戶端讀寫狀態的模型,不需要`1:1`與客戶端的線程數量關系。
* 多路I/O復用阻塞,非忙詢狀態,不浪費CPU資源, CPU利用率較高。
**缺點**:
* 雖然可以監聽多個客戶端的讀寫狀態,但是同一時間內,只能處理一個客戶端的讀寫操作,實際上讀寫的業務并發為1。
* 多客戶端訪問Server,業務為串行執行,大量請求會有排隊延遲現象,如圖中⑤所示,當`Client3`占據`main thread`流程時,`Client1,Client2`流程卡在`IO復用`等待下次監聽觸發事件。
### 模型四、單線程多路IO復用+多線程讀寫業務(業務工作池)
#### (1) 模型結構圖
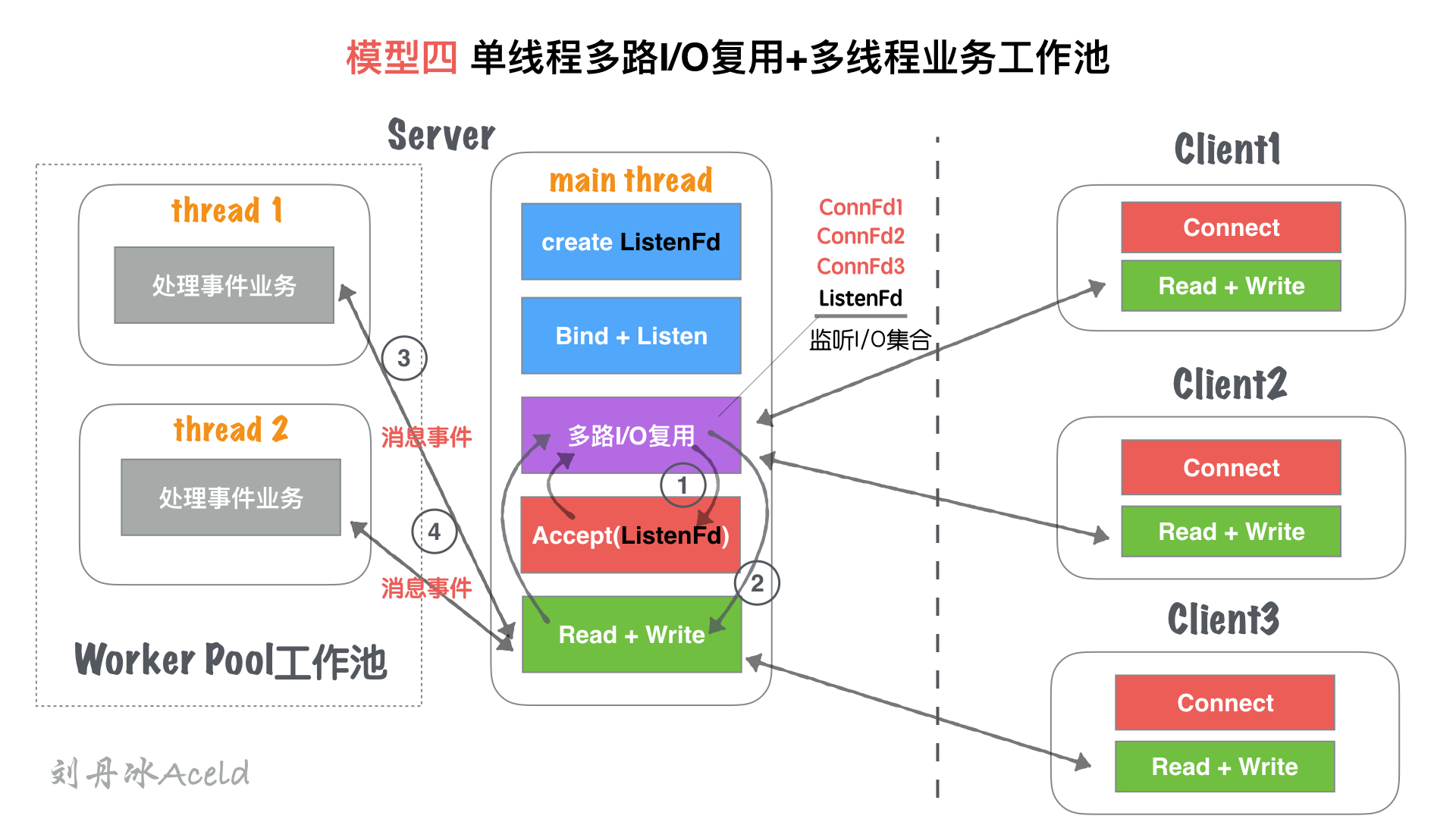
#### (2) 模型分析
① 主線程`main thread`創建`listenFd`之后,采用多路I/O復用機制(如:select、epoll)進行IO狀態阻塞監控。有`Client1`客戶端`Connect`請求,I/O復用機制檢測到`ListenFd`觸發讀事件,則進行`Accept`建立連接,并將新生成的`connFd1`加入到`監聽I/O集合`中。
② 當`connFd1`有可讀消息,觸發讀事件,并且進行讀寫消息
③ `main thread`按照固定的協議讀取消息,并且交給`worker pool`工作線程池, 工作線程池在server啟動之前就已經開啟固定數量的`thread`,里面的線程只處理消息業務,不進行套接字讀寫操作。
④ 工作池處理完業務,觸發`connFd1`寫事件,將回執客戶端的消息通過`main thead`寫給對方。
##### (3) 優缺點
**優點**:
* 對于`模型三`, 將業務處理部分,通過工作池分離出來,減少多客戶端訪問Server,業務為串行執行,大量請求會有排隊延遲時間。
* 實際上讀寫的業務并發為1,但是業務流程并發為worker pool線程數量,加快了業務處理并行效率。
**缺點**:
* 讀寫依然為`main thread`單獨處理,最高讀寫并行通道依然為1.
* 雖然多個worker線程處理業務,但是最后返回給客戶端,依舊需要排隊,因為出口還是`main thread`的`Read + Write`
### 模型五、單線程IO復用+多線程IO復用(鏈接線程池)
#### (1) 模型結構圖
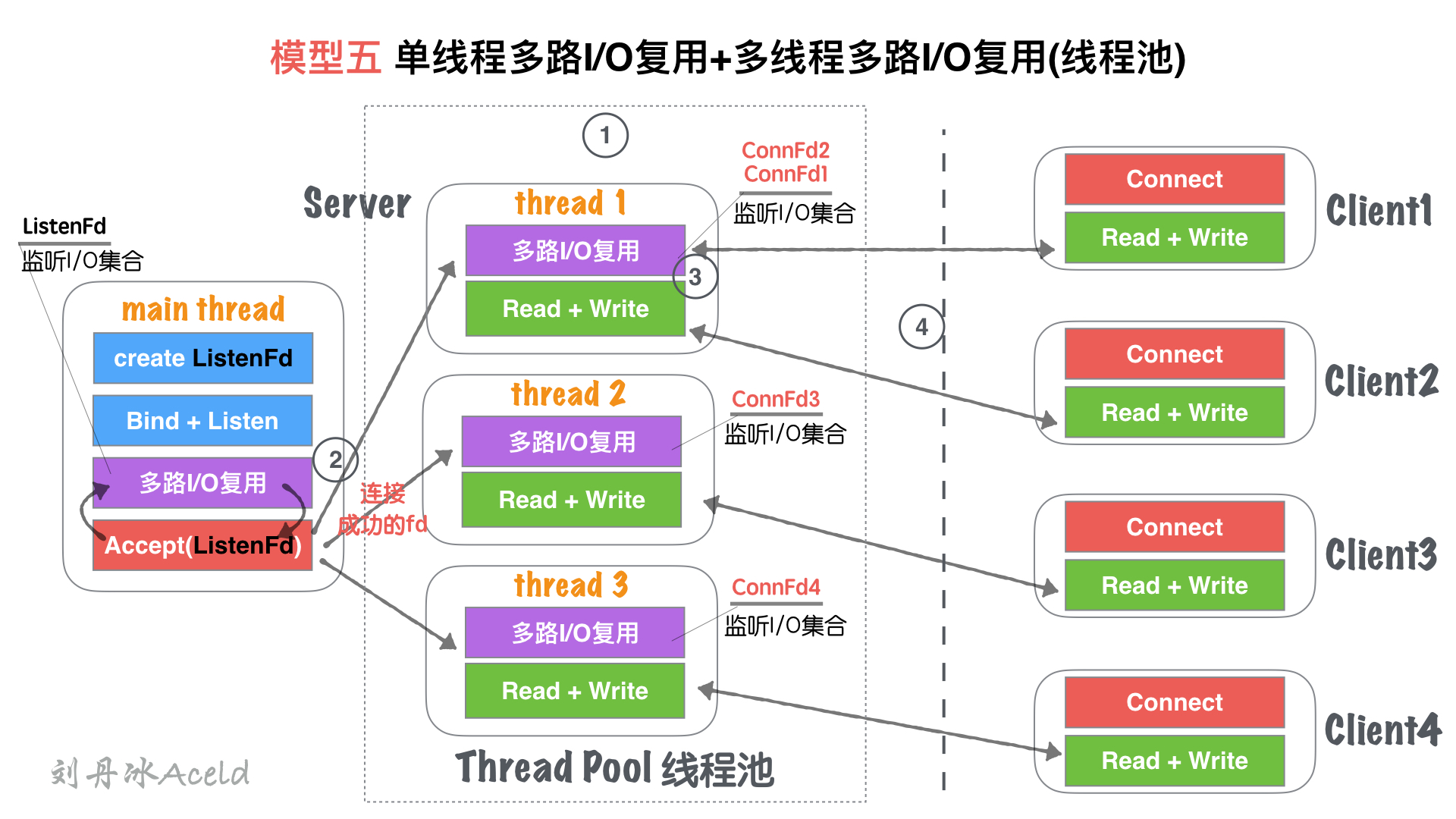
#### (2) 模型分析
① Server在啟動監聽之前,開辟固定數量(N)的線程,用`Thead Pool`線程池管理
② 主線程`main thread`創建`listenFd`之后,采用多路I/O復用機制(如:select、epoll)進行IO狀態阻塞監控。有`Client1`客戶端`Connect`請求,I/O復用機制檢測到`ListenFd`觸發讀事件,則進行`Accept`建立連接,并將新生成的`connFd1`分發給`Thread Pool`中的某個線程進行監聽。
③ `Thread Pool`中的每個`thread`都啟動`多路I/O復用機制(select、epoll)`,用來監聽`main thread`建立成功并且分發下來的socket套接字。
④ 如圖, `thread`監聽`ConnFd1、ConnFd2`, `thread2`監聽`ConnFd3`,`thread3`監聽`ConnFd4`. 當對應的`ConnFd`有讀寫事件,對應的線程處理該套接字的讀寫及業務。
#### (3) 優缺點
**優點**:
* 將`main thread`的單流程讀寫,分散到多線程完成,這樣增加了同一時刻的讀寫并行通道,并行通道數量`N`, `N`為線程池`Thread`數量。
* server同時監聽的`ConnFd套接字`數量幾乎成倍增大,之前的全部監控數量取決于`main thread`的`多路I/O復用機制`的最大限制***(select 默認為1024, epoll默認與內存大小相關,約3~6w不等)***,所以理論單點Server最高響應并發數量為`N*(3~6W)`(`N`為線程池`Thread`數量,建議與CPU核心成比例1:1)。
* 如果良好的線程池數量和CPU核心數適配,那么可以嘗試CPU核心與Thread進行綁定,從而降低CPU的切換頻率,提升每個`Thread`處理合理業務的效率,降低CPU切換成本開銷。
**缺點**:
* 雖然監聽的并發數量提升,但是最高讀寫并行通道依然為`N`,而且多個身處同一個Thread的客戶端,會出現讀寫延遲現象,實際上每個`Thread`的模型特征與`模型三:單線程多路IO復用`一致。
### 模型五(進程版)、**單進程多路I/O復用+多進程多路I/O復用(進程池)**
#### (1) 模型結構圖
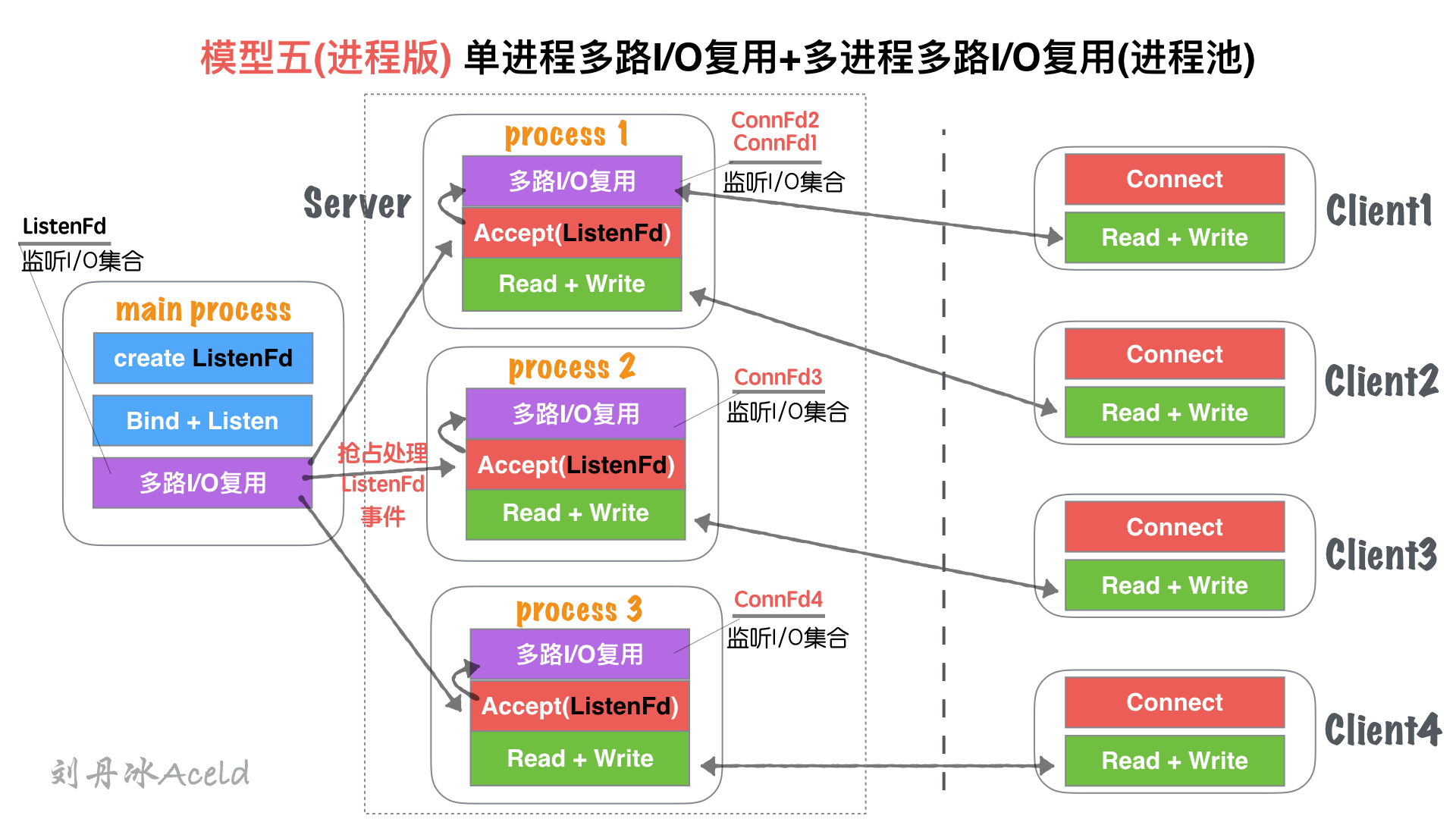
#### (2) 模型分析
與`五、單線程IO復用+多線程IO復用(鏈接線程池)`無大差異。
不同處
* 進程和線程的內存布局不同導致,`main process`(主進程)不再進行`Accept`操作,而是將`Accept`過程分散到各個`子進程(process)`中.
* 進程的特性,資源獨立,所以`main process`如果Accept成功的fd,其他進程無法共享資源,所以需要各子進程自行Accept創建鏈接
* `main process`只是監聽`ListenFd`狀態,一旦觸發讀事件(有新連接請求). 通過一些IPC(進程間通信:如信號、共享內存、管道)等, 讓各自子進程`Process`競爭`Accept`完成鏈接建立,并各自監聽。
#### (3) 優缺點
與`五、單線程IO復用+多線程IO復用(鏈接線程池)`無大差異。
不同處:
多進程內存資源空間占用稍微大一些
多進程模型安全穩定型較強,這也是因為各自進程互不干擾的特點導致。
### 模型六、**單線程多路I/O復用+多線程多路I/O復用+多線程**
#### (1) 模型結構圖
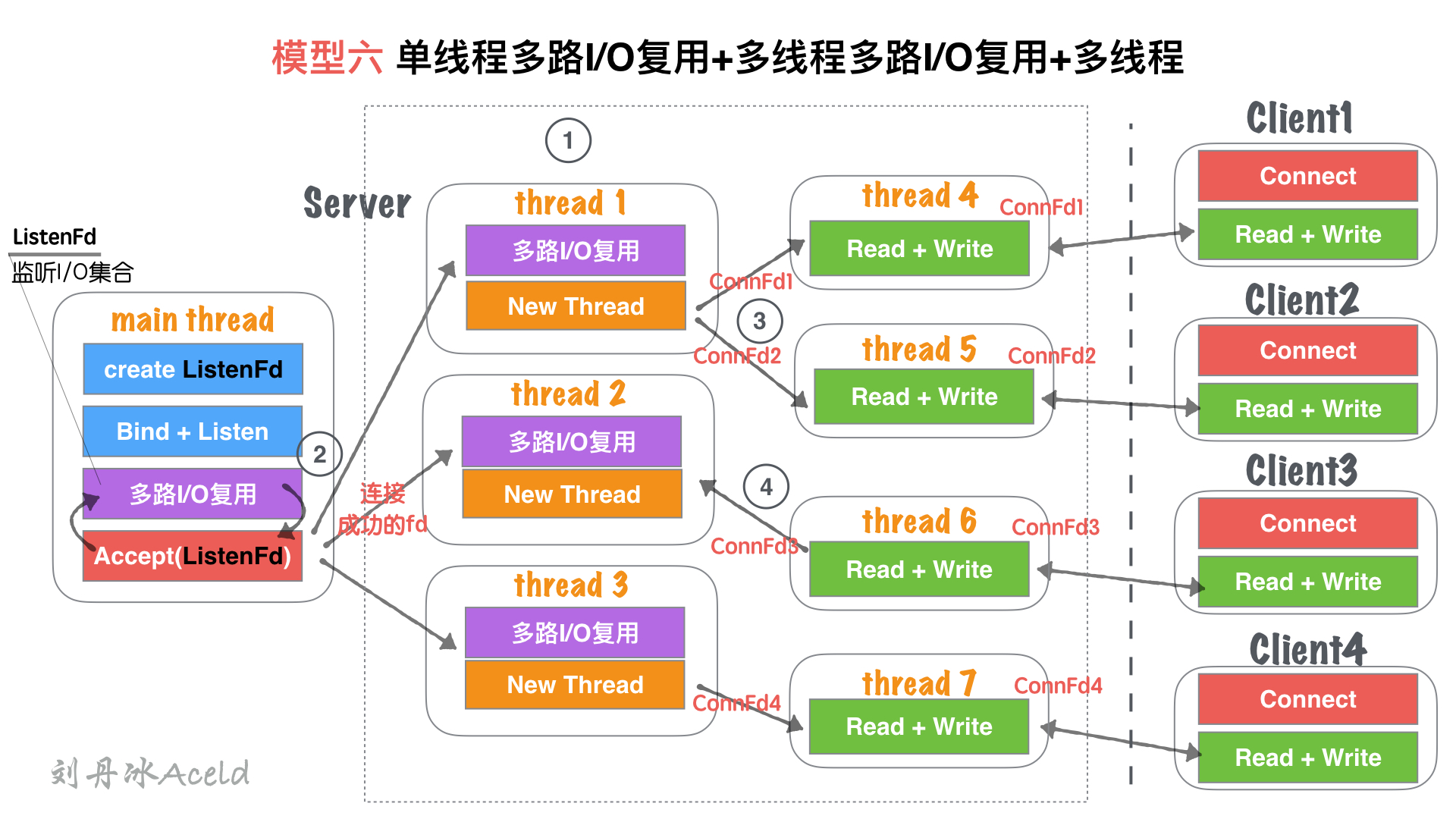
#### (2) 模型分析
① Server在啟動監聽之前,開辟固定數量(N)的線程,用`Thead Pool`線程池管理
② 主線程`main thread`創建`listenFd`之后,采用多路I/O復用機制(如:select、epoll)進行IO狀態阻塞監控。有`Client1`客戶端`Connect`請求,I/O復用機制檢測到`ListenFd`觸發讀事件,則進行`Accept`建立連接,并將新生成的`connFd1`分發給`Thread Pool`中的某個線程進行監聽。
③ `Thread Pool`中的每個`thread`都啟動`多路I/O復用機制(select、epoll)`,用來監聽`main thread`建立成功并且分發下來的socket套接字。一旦其中某個被監聽的客戶端套接字觸發`I/O讀寫事件`,那么,會立刻開辟一個新線程來處理`I/O讀寫`業務。
④ 但某個讀寫線程完成當前讀寫業務,如果當前套接字沒有被關閉,那么將當前客戶端套接字`如:ConnFd3`重新加回線程池的監控線程中,同時自身線程自我銷毀。
#### (3) 優缺點
**優點**:
* 在`模型五、單線程IO復用+多線程IO復用(鏈接線程池)`基礎上,除了能夠保證同時響應的`最高并發數`,又能解決`讀寫并行通道`局限的問題。
* 同一時刻的讀寫并行通道,達到`最大化極限`,一個客戶端可以對應一個單獨執行流程處理讀寫業務,讀寫并行通道與客戶端數量`1:1`關系。
**缺點**:
* 該模型過于理想化,因為要求CPU核心數量足夠大。
* 如果硬件CPU數量可數(目前的硬件情況),那么該模型將造成大量的CPU切換成本浪費。因為為了保證讀寫并行通道與客戶端`1:1`的關系,那么Server需要開辟的`Thread`數量就與客戶端一致,那么線程池中做`多路I/O復用`的監聽線程池綁定CPU數量將變得毫無意義。
* 如果每個臨時的讀寫`Thread`都能夠綁定一個單獨的CPU,那么此模型將是最優模型。但是目前CPU的數量無法與客戶端的數量達到一個量級,目前甚至差的不是幾個量級的事。
### 總結
綜上,我們整理了7中Server的服務器處理結構模型,每個模型都有各自的特點和優勢,那么對于多少應付高并發和高CPU利用率的模型,目前多數采用的是模型五(或模型五進程版,如Nginx就是類似模型五進程版的改版)。
至于并發模型并非設計的約復雜越好,也不是線程開辟的越多越好,我們要考慮硬件的利用與和切換成本的開銷。模型六設計就極為復雜,線程較多,但以當今的硬件能力無法支撐,反倒導致該模型性能極差。所以對于不同的業務場景也要選擇適合的模型構建,并不是一定固定就要使用某個來應用。
- 封面
- 第一篇:Golang修養必經之路
- 1、最常用的調試 golang 的 bug 以及性能問題的實踐方法?
- 2、Golang的協程調度器原理及GMP設計思想?
- 3、Golang中逃逸現象, 變量“何時棧?何時堆?”
- 4、Golang中make與new有何區別?
- 5、Golang三色標記+混合寫屏障GC模式全分析
- 6、面向對象的編程思維理解interface
- 7、Golang中的Defer必掌握的7知識點
- 8、精通Golang項目依賴Go modules
- 9、一站式精通Golang內存管理
- 第二篇:Golang面試之路
- 1、數據定義
- 2、數組和切片
- 3、Map
- 4、interface
- 5、channel
- 6、WaitGroup
- 第三篇、Golang編程設計與通用之路
- 1、流?I/O操作?阻塞?epoll?
- 2、分布式從ACID、CAP、BASE的理論推進
- 3、對于操作系統而言進程、線程以及Goroutine協程的區別
- 4、Go是否可以無限go? 如何限定數量?
- 5、單點Server的N種并發模型匯總
- 6、TCP中TIME_WAIT狀態意義詳解
- 7、動態保活Worker工作池設計