
在日常工作中,應用或者系統出現性能問題往往是不可避免的,除了在有一定規模的 IT 企業或者專注于特定性能領域的企業,可能大多數工程師并不會成為專職的性能工程師,但是掌握基本的性能知識和技能,往往是日常工作的需要,并且也是工程師進階的必要條件之一,能否定位和解決性能問題也是對你知識、技能和能力的檢驗。
今天我要問你的問題是,后臺服務出現明顯“變慢”,談談你的診斷思路?
## 典型回答
首先,需要對這個問題進行更加清晰的定義:
* 服務是突然變慢還是長時間運行后觀察到變慢?類似問題是否重復出現?
* “慢”的定義是什么,我能夠理解是系統對其他方面的請求的反應延時變長嗎?
第二,理清問題的癥狀,這更便于定位具體的原因,有以下一些思路:
* 問題可能來自于 Java 服務自身,也可能僅僅是受系統里其他服務的影響。初始判斷可以先確認是否出現了意外的程序錯誤,例如檢查應用本身的錯誤日志。
對于分布式系統,很多公司都會實現更加系統的日志、性能等監控系統。一些 Java 診斷工具也可以用于這個診斷,例如通過 JFR([Java Flight Recordera>),監控應用是否大量出現了某種類型的異常。
如果有,那么異常可能就是個突破點。
如果沒有,可以先檢查系統級別的資源等情況,監控 CPU、內存等資源是否被其他進程大量占用,并且這種占用是否不符合系統正常運行狀況。](https://docs.oracle.com/javacomponents/jmc-5-4/jfr-runtime-guide/about.htm#JFRUH173)
[](https://docs.oracle.com/javacomponents/jmc-5-4/jfr-runtime-guide/about.htm#JFRUH173)
[* 監控 Java 服務自身,例如 GC 日志里面是否觀察到 Full GC 等惡劣情況出現,或者是否 Minor GC 在變長等;利用 jstat 等工具,獲取內存使用的統計信息也是個常用手段;利用 jstack 等工具檢查是否出現死鎖等。
* 如果還不能確定具體問題,對應用進行 Profiling 也是個辦法,但因為它會對系統產生侵入性,如果不是非常必要,大多數情況下并不建議在生產系統進行。
* 定位了程序錯誤或者 JVM 配置的問題后,就可以采取相應的補救措施,然后驗證是否解決,否則還需要重復上面部分過程。
](https://docs.oracle.com/javacomponents/jmc-5-4/jfr-runtime-guide/about.htm#JFRUH173)
[
## 考點分析
今天我選擇的是一個常見的并且比較貼近實際應用的的性能相關問題,我提供的回答包括兩部分。
* 在正面回答之前,先探討更加精確的問題定義是什么。有時候面試官并沒有表達清楚,有必要確認自己的理解正確,然后再深入回答。
* 從系統、應用的不同角度、不同層次,逐步將問題域盡量縮小,隔離出真實原因。具體步驟未必千篇一律,在處理過較多這種問題之后,經驗會令你的直覺分外敏感。
大多數工程師也許并沒有全面的性能問題診斷機會,如果被問到也不必過于緊張,你可以向面試官展示診斷問題的思考方式,展現自己的知識和綜合運用的能力。接觸到一個陌生的問題,通過溝通,能夠條理清晰地將排查方案逐步確定下來,也是能力的體現。
面試官可能會針對某個角度的診斷深入詢問,兼顧工作和面試的需求,我會針對下面一些方面進行介紹。目的是讓你對性能分析有個整體的印象,在遇到特定領域問題時,即使不知道具體細節的工具和手段,至少也可以找到探索、查詢的方向。
* 我將介紹業界常見的性能分析方法論。
* 從系統分析到 JVM、應用性能分析,把握整體思路和主要工具。對于線程狀態、JVM 內存使用等很多方面,我在專欄前面已經陸陸續續介紹了很多,今天這一講也可以看作是聚焦性能角度的一個小結。
如果你有興趣進行系統性的學習,我建議參考 Charlie Hunt 編撰的《Java Performance》或者 Scott Oaks 的《Java Performance:The Definitive Guide》。另外,如果不希望出現理解偏差,最好是閱讀英文版。
## 知識擴展
首先,我們來了解一下業界最廣泛的性能分析方法論。
根據系統架構不同,分布式系統和大型單體應用也存在著思路的區別,例如,分布式系統的性能瓶頸可能更加集中。傳統意義上的性能調優大多是針對單體應用的調優,專欄的側重點也是如此,Charlie Hunt 曾將其方法論總結為兩類:
](https://docs.oracle.com/javacomponents/jmc-5-4/jfr-runtime-guide/about.htm#JFRUH173)
[* 自上而下。從應用的頂層,逐步深入到具體的不同模塊,或者更近一步的技術細節單元,找到可能的問題和解決辦法。這是最常見的性能分析思路,也是大多數工程師的選擇。
](https://docs.oracle.com/javacomponents/jmc-5-4/jfr-runtime-guide/about.htm#JFRUH173)* [](https://docs.oracle.com/javacomponents/jmc-5-4/jfr-runtime-guide/about.htm#JFRUH173)
[自下而上。從類似 CPU 這種硬件底層,判斷類似](https://docs.oracle.com/javacomponents/jmc-5-4/jfr-runtime-guide/about.htm#JFRUH173)[Cache-Miss](https://en.wikipedia.org/wiki/CPU_cache#Cache_miss)之類的問題和調優機會,出發點是指令級別優化。這往往是專業的性能工程師才能掌握的技能,并且需要專業工具配合,大多數是移植到新的平臺上,或需要提供極致性能時才會進行。
例如,將大數據應用移植到 SPARC 體系結構的硬件上,需要對比和盡量釋放性能潛力,但又希望盡量不改源代碼。
我所給出的回答,首先是試圖排除功能性錯誤,然后就是典型的自上而下分析思路。
第二,我們一起來看看自上而下分析中,各個階段的常見工具和思路。需要注意的是,具體的工具在不同的操作系統上可能區別非常大。
**系統性能分析**中,CPU、內存和 IO 是主要關注項。
對于 CPU,如果是常見的 Linux,可以先用 top 命令查看負載狀況,下圖是我截取的一個狀態。
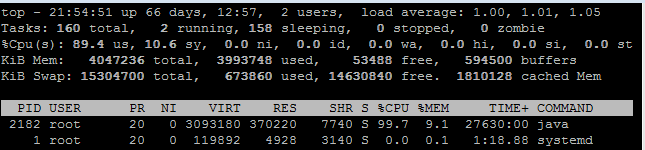
可以看到,其平均負載(load average)的三個值(分別是 1 分鐘、5 分鐘、15 分鐘)非常低,并且暫時看并沒有升高跡象。如果這些數值非常高(例如,超過 50%、60%),并且短期平均值高于長期平均值,則表明負載很重;如果還有升高的趨勢,那么就要非常警惕了。
進一步的排查有很多思路,例如,我在專欄第 18 講曾經問過,怎么找到最耗費 CPU 的 Java 線程,簡要介紹步驟:
* 利用 top 命令獲取相應 pid,“-H”代表 thread 模式,你可以配合 grep 命令更精準定位。
~~~
top –H
~~~
* 然后轉換成為 16 進制。
~~~
printf "%x" your_pid
~~~
* 最后利用 jstack 獲取的線程棧,對比相應的 ID 即可。
當然,還有更加通用的診斷方向,利用 vmstat 之類,查看上下文切換的數量,比如下面就是指定時間間隔為 1,收集 10 次。
~~~
vmstat -1 -10
~~~
輸出如下:
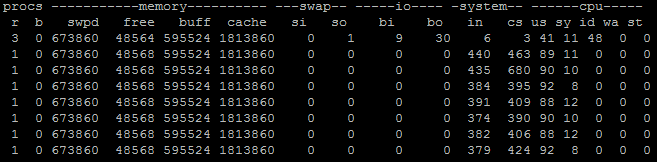
如果每秒上下文(cs,[context switch](https://en.wikipedia.org/wiki/Context_switch))切換很高,并且比系統中斷高很多(in,system[](https://en.wikipedia.org/wiki/Interrupt)[interrupt](https://en.wikipedia.org/wiki/Interrupt)),就表明很有可能是因為不合理的多線程調度所導致。當然還需要利用[pidstat](https://linux.die.net/man/1/pidstat)等手段,進行更加具體的定位,我就不再進一步展開了。
除了 CPU,內存和 IO 是重要的注意事項,比如:
* 利用 free 之類查看內存使用。
* 或者,進一步判斷 swap 使用情況,top 命令輸出中 Virt 作為虛擬內存使用量,就是物理內存(Res)和 swap 求和,所以可以反推 swap 使用。顯然,JVM 是不希望發生大量的 swap 使用的。
* 對于 IO 問題,既可能發生在磁盤 IO,也可能是網絡 IO。例如,利用 iostat 等命令有助于判斷磁盤的健康狀況。我曾經幫助診斷過 Java 服務部署在國內的某云廠商機器上,其原因就是 IO 表現較差,拖累了整體性能,解決辦法就是申請替換了機器。
講到這里,如果你對系統性能非常感興趣,我建議參考[Brendan Gregg](http://www.brendangregg.com/linuxperf.html)提供的完整圖譜,我所介紹的只能算是九牛一毛。但我還是建議盡量結合實際需求,免得迷失在其中。
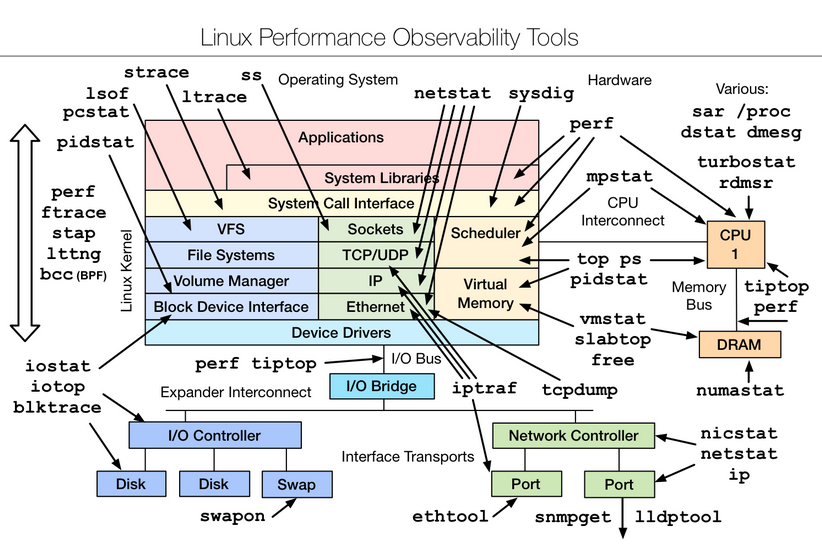
對于**JVM 層面的性能分析**,我們已經介紹過非常多了:
* 利用 JMC、JConsole 等工具進行運行時監控。
* 利用各種工具,在運行時進行堆轉儲分析,或者獲取各種角度的統計數據(如[jstat](https://docs.oracle.com/javase/7/docs/technotes/tools/share/jstat.html)\-gcutil 分析 GC、內存分帶等)。
* GC 日志等手段,診斷 Full GC、Minor GC,或者引用堆積等。
這里并不存在放之四海而皆準的辦法,具體問題可能非常不同,還要看你是否能否充分利用這些工具,從種種跡象之中,逐步判斷出問題所在。
對于**應用**[**Profiling**](https://en.wikipedia.org/wiki/Profiling_(computer_programming)),簡單來說就是利用一些侵入性的手段,收集程序運行時的細節,以定位性能問題瓶頸。所謂的細節,就是例如內存的使用情況、最頻繁調用的方法是什么,或者上下文切換的情況等。
我在前面給出的典型回答里提到,一般不建議生產系統進行 Profiling,大多數是在性能測試階段進行。但是,當生產系統確實存在這種需求時,也不是沒有選擇。我建議使用 JFR 配合[JMC](http://www.oracle.com/technetwork/java/javaseproducts/mission-control/java-mission-control-1998576.html)來做 Profiling,因為它是從 Hotspot JVM 內部收集底層信息,并經過了大量優化,性能開銷非常低,通常是低于**2%**的;并且如此強大的工具,也已經被 Oracle 開源出來!
所以,JFR/JMC 完全具備了生產系統 Profiling 的能力,目前也確實在真正大規模部署的云產品上使用過相關技術,快速地定位了問題。
它的使用也非常方便,你不需要重新啟動系統或者提前增加配置。例如,你可以在運行時啟動 JFR 記錄,并將這段時間的信息寫入文件:
~~~
Jcmd <pid> JFR.start duration=120s filename=myrecording.jfr
~~~
然后,使用 JMC 打開“.jfr 文件”就可以進行分析了,方法、異常、線程、IO 等應有盡有,其功能非常強大。如果你想了解更多細節,可以參考相關[指南](https://blog.takipi.com/oracle-java-mission-control-the-ultimate-guide/)。
今天我從一個典型性能問題出發,從癥狀表現到具體的系統分析、JVM 分析,系統性地整理了常見性能分析的思路;并且在知識擴展部分,從方法論和實際操作的角度,讓你將理論和實際結合,相信一定可以對你有所幫助。
## 一課一練
關于今天我們討論的題目你做到心中有數了嗎? 今天的思考題是,Profiling 工具獲取數據的主要方式有哪些?各有什么優缺點。
- 前言
- 開篇詞
- 開篇詞 -以面試題為切入點,有效提升你的Java內功
- 模塊一 Java基礎
- 第1講 談談你對Java平臺的理解?
- 第2講 Exception和Error有什么區別?
- 第3講 談談final、finally、 finalize有什么不同?
- 第4講 強引用、軟引用、弱引用、幻象引用有什么區別?
- 第5講 String、StringBuffer、StringBuilder有什么區別?
- 第6講 動態代理是基于什么原理?
- 第7講 int和Integer有什么區別?
- 第8講 對比Vector、ArrayList、LinkedList有何區別?
- 第9講 對比Hashtable、HashMap、TreeMap有什么不同?
- 第10講 如何保證集合是線程安全的? ConcurrentHashMap如何實現高效地線程安全?
- 第11講 Java提供了哪些IO方式? NIO如何實現多路復用?
- 第12講 Java有幾種文件拷貝方式?哪一種最高效?
- 第13講 談談接口和抽象類有什么區別?
- 第14講 談談你知道的設計模式?
- 模塊二 Java進階
- 第15講 synchronized和ReentrantLock有什么區別呢?
- 第16講 synchronized底層如何實現?什么是鎖的升級、降級?
- 第17講 一個線程兩次調用start()方法會出現什么情況?
- 第18講 什么情況下Java程序會產生死鎖?如何定位、修復?
- 第19講 Java并發包提供了哪些并發工具類?
- 第20講 并發包中的ConcurrentLinkedQueue和LinkedBlockingQueue有什么區別?
- 第21講 Java并發類庫提供的線程池有哪幾種? 分別有什么特點?
- 第22講 AtomicInteger底層實現原理是什么?如何在自己的產品代碼中應用CAS操作?
- 第23講 請介紹類加載過程,什么是雙親委派模型?
- 第24講 有哪些方法可以在運行時動態生成一個Java類?
- 第25講 談談JVM內存區域的劃分,哪些區域可能發生OutOfMemoryError?
- 第26講 如何監控和診斷JVM堆內和堆外內存使用?
- 第27講 Java常見的垃圾收集器有哪些?
- 第28講 談談你的GC調優思路?
- 第29講 Java內存模型中的happen-before是什么?
- 第30講 Java程序運行在Docker等容器環境有哪些新問題?
- 模塊三 Java安全基礎
- 第31講 你了解Java應用開發中的注入攻擊嗎?
- 第32講 如何寫出安全的Java代碼?
- 模塊四 Java性能基礎
- 第33講 后臺服務出現明顯“變慢”,談談你的診斷思路?
- 第34講 有人說“Lambda能讓Java程序慢30倍”,你怎么看?
- 第35講 JVM優化Java代碼時都做了什么?
- 模塊五 Java應用開發擴展
- 第36講 談談MySQL支持的事務隔離級別,以及悲觀鎖和樂觀鎖的原理和應用場景?
- 第37講 談談Spring Bean的生命周期和作用域?
- 第38講 對比Java標準NIO類庫,你知道Netty是如何實現更高性能的嗎?
- 第39講 談談常用的分布式ID的設計方案?Snowflake是否受冬令時切換影響?
- 周末福利
- 周末福利 談談我對Java學習和面試的看法
- 周末福利 一份Java工程師必讀書單
- 結束語
- 結束語 技術沒有終點
- 結課測試 Java核心技術的這些知識,你真的掌握了嗎?