
我在專欄上一講介紹了微基準測試和相關的注意事項,其核心就是避免 JVM 運行中對 Java 代碼的優化導致失真。所以,系統地理解 Java 代碼運行過程,有利于在實踐中進行更進一步的調優。
今天我要問你的問題是,JVM 優化 Java 代碼時都做了什么?
與以往我來給出典型回答的方式不同,今天我邀請了隔壁專欄[《深入拆解 Java 虛擬機》](http://time.geekbang.org/column/intro/108?utm_source=app&utm_medium=article&utm_campaign=108-presell&utm_content=java)的作者,同樣是來自 Oracle 的鄭雨迪博士,讓他以 JVM 專家的身份去思考并回答這個問題。
## 來自 JVM 專欄作者鄭雨迪博士的回答
JVM 在對代碼執行的優化可分為運行時(runtime)優化和即時編譯器(JIT)優化。運行時優化主要是解釋執行和動態編譯通用的一些機制,比如說鎖機制(如偏斜鎖)、內存分配機制(如 TLAB)等。除此之外,還有一些專門用于優化解釋執行效率的,比如說模版解釋器、內聯緩存(inline cache,用于優化虛方法調用的動態綁定)。
JVM 的即時編譯器優化是指將熱點代碼以方法為單位轉換成機器碼,直接運行在底層硬件之上。它采用了多種優化方式,包括靜態編譯器可以使用的如方法內聯、逃逸分析,也包括基于程序運行 profile 的投機性優化(speculative/optimistic optimization)。這個怎么理解呢?比如我有一條 instanceof 指令,在編譯之前的執行過程中,測試對象的類一直是同一個,那么即時編譯器可以假設編譯之后的執行過程中還會是這一個類,并且根據這個類直接返回 instanceof 的結果。如果出現了其他類,那么就拋棄這段編譯后的機器碼,并且切換回解釋執行。
當然,JVM 的優化方式僅僅作用在運行應用代碼的時候。如果應用代碼本身阻塞了,比如說并發時等待另一線程的結果,這就不在 JVM 的優化范疇啦。
## 考點分析
感謝鄭雨迪博士從 JVM 的角度給出的回答。今天這道面試題在專欄里有不少同學問我,也是會在面試時被面試官刨根問底的一個知識點,鄭博士的回答已經非常全面和深入啦。
大多數 Java 工程師并不是 JVM 工程師,知識點總歸是要落地的,面試官很有可能會從實踐的角度探討,例如,如何在生產實踐中,與 JIT 等 JVM 模塊進行交互,落實到如何真正進行實際調優。
在今天這一講,我會從 Java 工程師日常的角度出發,側重于:
* 從整體去了解 Java 代碼編譯、執行的過程,目的是對基本機制和流程有個直觀的認識,以保證能夠理解調優選擇背后的邏輯。
* 從生產系統調優的角度,談談將 JIT 的知識落實到實際工作中的可能思路。這里包括兩部分:如何收集 JIT 相關的信息,以及具體的調優手段。
## 知識擴展
首先,我們從整體的角度來看看 Java 代碼的整個生命周期,你可以參考我提供的示意圖。
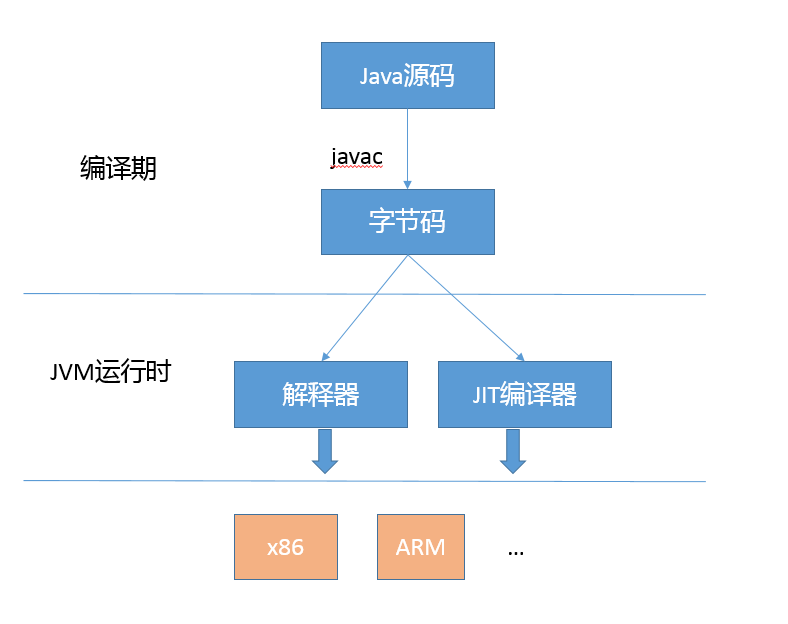
我在[專欄第 1 講](http://time.geekbang.org/column/article/6845)就已經提到過,Java 通過引入字節碼這種中間表達方式,屏蔽了不同硬件的差異,由 JVM 負責完成從字節碼到機器碼的轉化。
通常所說的編譯期,是指 javac 等編譯器或者相關 API 等將源碼轉換成為字節碼的過程,這個階段也會進行少量類似常量折疊之類的優化,只要利用反編譯工具,就可以直接查看細節。
javac 優化與 JVM 內部優化也存在關聯,畢竟它負責了字節碼的生成。例如,Java 9 中的字符串拼接,會被 javac 替換成對 StringConcatFactory 的調用,進而為 JVM 進行字符串拼接優化提供了統一的入口。在實際場景中,還可以通過不同的[策略](http://openjdk.java.net/jeps/280)選項來干預這個過程。
今天我要講的重點是**JVM 運行時的優化**,在通常情況下,編譯器和解釋器是共同起作用的,具體流程可以參考下面的示意圖。
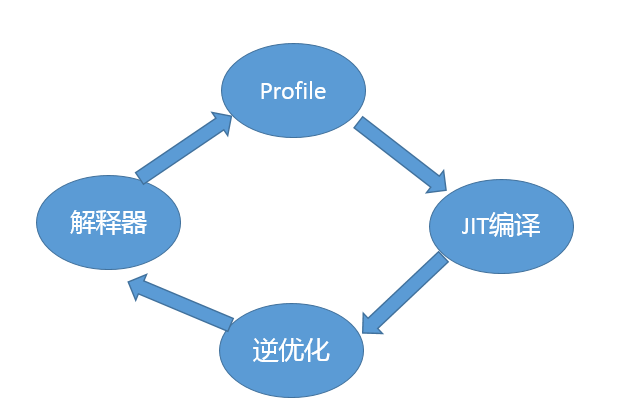
JVM 會根據統計信息,動態決定什么方法被編譯,什么方法解釋執行,即使是已經編譯過的代碼,也可能在不同的運行階段不再是熱點,JVM 有必要將這種代碼從 Code Cache 中移除出去,畢竟其大小是有限的。
就如鄭博士所回答的,解釋器和編譯器也會進行一些通用優化,例如:
* 鎖優化,你可以參考我在[專欄第 16 講](http://time.geekbang.org/column/article/9042)提供的解釋器運行時的源碼分析。
* Intrinsic 機制,或者叫作內建方法,就是針對特別重要的基礎方法,JDK 團隊直接提供定制的實現,利用匯編或者編譯器的中間表達方式編寫,然后 JVM 會直接在運行時進行替換。
這么做的理由有很多,例如,不同體系結構的 CPU 在指令等層面存在著差異,定制才能充分發揮出硬件的能力。我們日常使用的典型字符串操作、數組拷貝等基礎方法,Hotspot 都提供了內建實現。
而**即時編譯器(JIT)**,則是更多優化工作的承擔者。JIT 對 Java 編譯的基本單元是整個方法,通過對方法調用的計數統計,甄別出熱點方法,編譯為本地代碼。另外一個優化場景,則是最針對所謂熱點循環代碼,利用通常說的棧上替換技術(OSR,On-Stack Replacement,更加細節請參考[R 大的文章](https://github.com/AdoptOpenJDK/jitwatch/wiki/Understanding-the-On-Stack-Replacement-(OSR)-optimisation-in-the-HotSpot-C1-compiler)),如果方法本身的調用頻度還不夠編譯標準,但是內部有大的循環之類,則還是會有進一步優化的價值。
從理論上來看,JIT 可以看作就是基于兩個計數器實現,方法計數器和回邊計數器提供給 JVM 統計數據,以定位到熱點代碼。實際中的 JIT 機制要復雜得多,鄭博士提到了[逃逸分析](https://en.wikipedia.org/wiki/Escape_analysis)、[循環展開](https://en.wikipedia.org/wiki/Loop_unrolling)、方法內聯等,包括前面提到的 Intrinsic 等通用機制同樣會在 JIT 階段發生。
第二,有哪些手段可以探查這些優化的具體發生情況呢?
專欄中已經陸陸續續介紹了一些,我來簡單總結一下并補充部分細節。
* 打印編譯發生的細節。
~~~
-XX:+PrintCompilation
~~~
* 輸出更多編譯的細節。
~~~
-XX:UnlockDiagnosticVMOptions -XX:+LogCompilation -XX:LogFile=<your_file_path>
~~~
JVM 會生成一個 xml 形式的文件,另外, LogFile 選項是可選的,不指定則會輸出到
~~~
hotspot_pid<pid>.log
~~~
具體格式可以參考 Ben Evans 提供的[JitWatch](https://github.com/AdoptOpenJDK/jitwatch/)工具和[分析指南](http://www.oracle.com/technetwork/articles/java/architect-evans-pt1-2266278.html)。

* 打印內聯的發生,可利用下面的診斷選項,也需要明確解鎖。
~~~
-XX:+PrintInlining
~~~
* 如何知曉 Code Cache 的使用狀態呢?
很多工具都已經提供了具體的統計信息,比如,JMC、JConsole 之類,我也介紹過使用 NMT 監控其使用。
第三,我們作為應用開發者,有哪些可以觸手可及的調優角度和手段呢?
* 調整熱點代碼門限值
我曾經介紹過 JIT 的默認門限,server 模式默認 10000 次,client 是 1500 次。門限大小也存在著調優的可能,可以使用下面的參數調整;與此同時,該參數還可以變相起到降低預熱時間的作用。
~~~
-XX:CompileThreshold=N
~~~
很多人可能會產生疑問,既然是熱點,不是早晚會達到門限次數嗎?這個還真未必,因為 JVM 會周期性的對計數的數值進行衰減操作,導致調用計數器永遠不能達到門限值,除了可以利用 CompileThreshold 適當調整大小,還有一個辦法就是關閉計數器衰減。
~~~
-XX:-UseCounterDecay
~~~
如果你是利用 debug 版本的 JDK,還可以利用下面的參數進行試驗,但是生產版本是不支持這個選項的。
~~~
-XX:CounterHalfLifeTime
~~~
* 調整 Code Cache 大小
我們知道 JIT 編譯的代碼是存儲在 Code Cache 中的,需要注意的是 Code Cache 是存在大小限制的,而且不會動態調整。這意味著,如果 Code Cache 太小,可能只有一小部分代碼可以被 JIT 編譯,其他的代碼則沒有選擇,只能解釋執行。所以,一個潛在的調優點就是調整其大小限制。
~~~
-XX:ReservedCodeCacheSize=<SIZE>
~~~
當然,也可以調整其初始大小。
~~~
-XX:InitialCodeCacheSize=<SIZE>
~~~
注意,在相對較新版本的 Java 中,由于分層編譯(Tiered-Compilation)的存在,Code Cache 的空間需求大大增加,其本身默認大小也被提高了。
* 調整編譯器線程數,或者選擇適當的編譯器模式
JVM 的編譯器線程數目與我們選擇的模式有關,選擇 client 模式默認只有一個編譯線程,而 server 模式則默認是兩個,如果是當前最普遍的分層編譯模式,則會根據 CPU 內核數目計算 C1 和 C2 的數值,你可以通過下面的參數指定的編譯線程數。
~~~
-XX:CICompilerCount=N
~~~
在強勁的多處理器環境中,增大編譯線程數,可能更加充分的利用 CPU 資源,讓預熱等過程更加快速;但是,反之也可能導致編譯線程爭搶過多資源,尤其是當系統非常繁忙時。例如,系統部署了多個 Java 應用實例的時候,那么減小編譯線程數目,則是可以考慮的。
生產實踐中,也有人推薦在服務器上關閉分層編譯,直接使用 server 編譯器,雖然會導致稍慢的預熱速度,但是可能在特定工作負載上會有微小的吞吐量提高。
* 其他一些相對邊界比較混淆的所謂“優化”
比如,減少進入安全點。嚴格說,它遠遠不只是發生在動態編譯的時候,GC 階段發生的更加頻繁,你可以利用下面選項診斷安全點的影響。
~~~
-XX:+PrintSafepointStatistics ?XX:+PrintGCApplicationStoppedTime
~~~
注意,在 JDK 9 之后,PrintGCApplicationStoppedTime 已經被移除了,你需要使用“-Xlog:safepoint”之類方式來指定。
很多優化階段都可能和安全點相關,例如:
* 在 JIT 過程中,逆優化等場景會需要插入安全點。
* 常規的鎖優化階段也可能發生,比如,偏斜鎖的設計目的是為了避免無競爭時的同步開銷,但是當真的發生競爭時,撤銷偏斜鎖會觸發安全點,是很重的操作。所以,在并發場景中偏斜鎖的價值其實是被質疑的,經常會明確建議關閉偏斜鎖。
~~~
-XX:-UseBiasedLocking
~~~
主要的優化手段就介紹到這里,這些方法都是普通 Java 開發者就可以利用的。如果你想對 JVM 優化手段有更深入的了解,建議你訂閱 JVM 專家鄭雨迪博士的專欄。
## 一課一練
關于今天我們討論的題目你做到心中有數了嗎? 請思考一個問題,如何程序化驗證 final 關鍵字是否會影響性能?
- 前言
- 開篇詞
- 開篇詞 -以面試題為切入點,有效提升你的Java內功
- 模塊一 Java基礎
- 第1講 談談你對Java平臺的理解?
- 第2講 Exception和Error有什么區別?
- 第3講 談談final、finally、 finalize有什么不同?
- 第4講 強引用、軟引用、弱引用、幻象引用有什么區別?
- 第5講 String、StringBuffer、StringBuilder有什么區別?
- 第6講 動態代理是基于什么原理?
- 第7講 int和Integer有什么區別?
- 第8講 對比Vector、ArrayList、LinkedList有何區別?
- 第9講 對比Hashtable、HashMap、TreeMap有什么不同?
- 第10講 如何保證集合是線程安全的? ConcurrentHashMap如何實現高效地線程安全?
- 第11講 Java提供了哪些IO方式? NIO如何實現多路復用?
- 第12講 Java有幾種文件拷貝方式?哪一種最高效?
- 第13講 談談接口和抽象類有什么區別?
- 第14講 談談你知道的設計模式?
- 模塊二 Java進階
- 第15講 synchronized和ReentrantLock有什么區別呢?
- 第16講 synchronized底層如何實現?什么是鎖的升級、降級?
- 第17講 一個線程兩次調用start()方法會出現什么情況?
- 第18講 什么情況下Java程序會產生死鎖?如何定位、修復?
- 第19講 Java并發包提供了哪些并發工具類?
- 第20講 并發包中的ConcurrentLinkedQueue和LinkedBlockingQueue有什么區別?
- 第21講 Java并發類庫提供的線程池有哪幾種? 分別有什么特點?
- 第22講 AtomicInteger底層實現原理是什么?如何在自己的產品代碼中應用CAS操作?
- 第23講 請介紹類加載過程,什么是雙親委派模型?
- 第24講 有哪些方法可以在運行時動態生成一個Java類?
- 第25講 談談JVM內存區域的劃分,哪些區域可能發生OutOfMemoryError?
- 第26講 如何監控和診斷JVM堆內和堆外內存使用?
- 第27講 Java常見的垃圾收集器有哪些?
- 第28講 談談你的GC調優思路?
- 第29講 Java內存模型中的happen-before是什么?
- 第30講 Java程序運行在Docker等容器環境有哪些新問題?
- 模塊三 Java安全基礎
- 第31講 你了解Java應用開發中的注入攻擊嗎?
- 第32講 如何寫出安全的Java代碼?
- 模塊四 Java性能基礎
- 第33講 后臺服務出現明顯“變慢”,談談你的診斷思路?
- 第34講 有人說“Lambda能讓Java程序慢30倍”,你怎么看?
- 第35講 JVM優化Java代碼時都做了什么?
- 模塊五 Java應用開發擴展
- 第36講 談談MySQL支持的事務隔離級別,以及悲觀鎖和樂觀鎖的原理和應用場景?
- 第37講 談談Spring Bean的生命周期和作用域?
- 第38講 對比Java標準NIO類庫,你知道Netty是如何實現更高性能的嗎?
- 第39講 談談常用的分布式ID的設計方案?Snowflake是否受冬令時切換影響?
- 周末福利
- 周末福利 談談我對Java學習和面試的看法
- 周末福利 一份Java工程師必讀書單
- 結束語
- 結束語 技術沒有終點
- 結課測試 Java核心技術的這些知識,你真的掌握了嗎?