
# 基礎教程
> 原文: [http://docs.cython.org/en/latest/src/tutorial/cython_tutorial.html](http://docs.cython.org/en/latest/src/tutorial/cython_tutorial.html)
## Cython 的基礎知識
Cython 的基本特性可歸納如下:Cython 是具有 C 數據類型的 Python。
Cython 是 Python:幾乎任何 Python 代碼都是有效的 Cython 代碼。 (有一些 [限制](../userguide/limitations.html#cython-limitations) ,但這種近似現在將起作用。)Cython 編譯器將其轉換為 C 代碼,它對 Python / C API 進行等效調用。
但 Cython 遠不止于此,因為參數和變量可以聲明為具有 C 數據類型。操作 Python 值和 C 值的代碼可以自由混合,只要有可能就會自動進行轉換。 Python 操作的引用計數維護和錯誤檢查也是自動的,并且即使在操作 C 數據的過程中,您也可以使用 Python 的異常處理工具(包括 try-except 和 try-finally 語句)的全部功能。
## Cython Hello World
由于 Cython 幾乎可以接受任何有效的 python 源文件,因此入門中最困難的事情之一就是弄清楚如何編譯擴展。
所以讓我們從規范的 python hello 世界開始:
```py
print("Hello World")
```
將此代碼保存在名為`helloworld.pyx`的文件中。現在我們需要創建`setup.py`,它就像一個 python Makefile(有關更多信息,請參閱 [源文件和編譯](../userguide/source_files_and_compilation.html#compilation) )。你的`setup.py`看起來像:
```py
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("helloworld.pyx")
)
```
要使用它來構建您的 Cython 文件,請使用命令行選項:
```py
$ python setup.py build_ext --inplace
```
這將在您的本地目錄中將文件保留在 unix 中的`helloworld.so`或 Windows 中的`helloworld.pyd`中。現在使用這個文件:啟動 python 解釋器并簡單地導入它就好像它是一個普通的 python 模塊:
```py
>>> import helloworld
Hello World
```
恭喜!您現在知道如何構建 Cython 擴展。但到目前為止,這個例子并沒有真正讓人感覺為什么會想要使用 Cython,所以讓我們創建一個更現實的例子。
### `pyximport`:面向開發人員的 Cython 編譯
如果您的模塊不需要任何額外的 C 庫或特殊的構建設置,那么您可以使用最初由 Paul Prescod 開發的 pyximport 模塊在導入時直接加載.pyx 文件,而無需每個都運行`setup.py`文件你改變代碼的時候了。它隨 Cython 一起發貨和安裝,可以像這樣使用:
```py
>>> import pyximport; pyximport.install()
>>> import helloworld
Hello World
```
[Pyximport ](../userguide/source_files_and_compilation.html#pyximport)模塊還具有對普通 Python 模塊的實驗性編譯支持。這允許您在 Py??thon 導入的每個.pyx 和.py 模塊上自動運行 Cython,包括標準庫和已安裝的軟件包。 Cython 仍然無法編譯很多 Python 模塊,在這種情況下,導入機制將回退到加載 Python 源模塊。 .py 導入機制安裝如下:
```py
>>> pyximport.install(pyimport=True)
```
請注意,建議不要讓 [Pyximport](../userguide/source_files_and_compilation.html#pyximport)在最終用戶端構建代碼,因為它會掛鉤到他們的導入系統。滿足最終用戶的最佳方式是以[輪](https://wheel.readthedocs.io/)包裝格式提供預先構建的二進制包。
## 斐波那契樂趣
從官方 Python 教程中,一個簡單的 fibonacci 函數定義為:
```py
from __future__ import print_function
def fib(n):
"""Print the Fibonacci series up to n."""
a, b = 0, 1
while b < n:
print(b, end=' ')
a, b = b, a + b
print()
```
現在按照 Hello World 示例的步驟,我們首先將文件重命名為 <cite>.pyx</cite> 擴展名,讓我們說`fib.pyx`,然后我們創建`setup.py`文件。使用為 Hello World 示例創建的文件,您需要更改的是 Cython 文件名的名稱,以及生成的模塊名稱,我們這樣做:
```py
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize("fib.pyx"),
)
```
使用與 helloworld.pyx 相同的命令構建擴展:
```py
$ python setup.py build_ext --inplace
```
并使用新的擴展名:
```py
>>> import fib
>>> fib.fib(2000)
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597
```
## Primes
這是一個小例子,展示了一些可以做的事情。這是查找素數的例程。你告訴它你想要多少素數,并將它們作為 Python 列表返回。
`primes.pyx`:
|
```py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
```
|
```py
def primes(int nb_primes):
cdef int n, i, len_p
cdef int p[1000]
if nb_primes > 1000:
nb_primes = 1000
len_p = 0 # The current number of elements in p.
n = 2
while len_p < nb_primes:
# Is n prime?
for i in p[:len_p]:
if n % i == 0:
break
# If no break occurred in the loop, we have a prime.
else:
p[len_p] = n
len_p += 1
n += 1
# Let's return the result in a python list:
result_as_list = [prime for prime in p[:len_p]]
return result_as_list
```
|
您將看到它的開始就像普通的 Python 函數定義一樣,除了參數`nb_primes`被聲明為`int`類型。這意味著傳遞的對象將被轉換為 C 整數(如果不能,則會引發`TypeError.`)。
現在,讓我們深入研究該函數的核心:
```py
cdef int n, i, len_p
cdef int p[1000]
```
第 2 行和第 3 行使用`cdef`語句定義一些本地 C 變量。結果在處理期間存儲在 C 數組`p`中,并將在末尾復制到 Python 列表中(第 22 行)。
注意
您不能以這種方式創建非常大的數組,因為它們是在 C 函數調用堆棧上分配的,這是一個相當珍貴和稀缺的資源。要請求更大的數組,甚至是只在運行時知道長度的數組,您可以學習如何有效地使用 [C 內存分配](memory_allocation.html#memory-allocation) , [Python 數組](array.html#array-array) 或 [NumPy 陣列](../userguide/memoryviews.html#memoryviews) 與 Cython。
```py
if nb_primes > 1000:
nb_primes = 1000
```
與在 C 中一樣,聲明靜態數組需要在編譯時知道大小。我們確保用戶沒有設置大于 1000 的值(或者我們會有一個分段錯誤,就像在 C 中一樣)。
```py
len_p = 0 # The number of elements in p
n = 2
while len_p < nb_primes:
```
第 7-9 行設置了一個循環,它將測試候選數字的完整性,直到找到所需的素數。
```py
# Is n prime?
for i in p[:len_p]:
if n % i == 0:
break
```
嘗試將候選人除以迄今為止發現的所有素數的第 11-12 行特別令人感興趣。因為沒有引用 Python 對象,所以循環完全轉換為 C 代碼,因此運行速度非常快。你會注意到我們迭代`p` C 數組的方式。
```py
for i in p[:len_p]:
```
循環被轉換為快速 C 循環,就像迭代 Python 列表或 NumPy 數組一樣。如果不使用`[:len_p]`對 C 數組進行切片,則 Cython 將循環遍歷數組的 1000 個元素。
```py
# If no break occurred in the loop
else:
p[len_p] = n
len_p += 1
n += 1
```
如果沒有發生中斷,則意味著我們找到了一個素數,并且將執行`else`行 16 之后的代碼塊。我們添加了`p`找到的素數。如果你發現在 for 循環奇怪之后有`else`,只要知道它是 Python 語言鮮為人知的特性,并且 Cython 會以 C 速度為你執行它。如果 for-else 語法讓您感到困惑,請參閱這篇優秀的[博客文章](https://shahriar.svbtle.com/pythons-else-clause-in-loops)。
```py
# Let's put the result in a python list:
result_as_list = [prime for prime in p[:len_p]]
return result_as_list
```
在第 22 行,在返回結果之前,我們需要將 C 數組復制到 Python 列表中,因為 Python 無法讀取 C 數組。 Cython 可以自動將許多 C 類型轉換為 Python 類型,如 [類型轉換](../userguide/language_basics.html#type-conversion) 的文檔中所述,因此我們可以使用簡單的列表解析來復制 C `int`值為 Python `int`對象的 Python 列表,Cython 在此過程中自動創建。您也可以在 C 數組上手動迭代并使用`result_as_list.append(prime)`,結果將是相同的。
您會注意到我們聲明的 Python 列表與 Python 中的完全相同。因為變量`result_as_list`尚未使用類型顯式聲明,所以假定它包含一個 Python 對象,并且從賦值中,Cython 也知道確切的類型是 Python 列表。
最后,在第 18 行,普通的 Python return 語句返回結果列表。
使用 Cython 編譯器編譯 primes.pyx 會生成一個擴展模塊,我們可以在交互式解釋器中嘗試如下:
```py
>>> import primes
>>> primes.primes(10)
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
```
看,它有效!如果您對 Cython 為您節省了多少工作感到好奇,請查看為此模塊生成的 C 代碼。
Cython 有一種方法可視化與 Python 對象和 Python 的 C-API 進行交互的位置。為此,將`annotate=True`參數傳遞給`cythonize()`。它生成一個 HTML 文件。讓我們來看看:
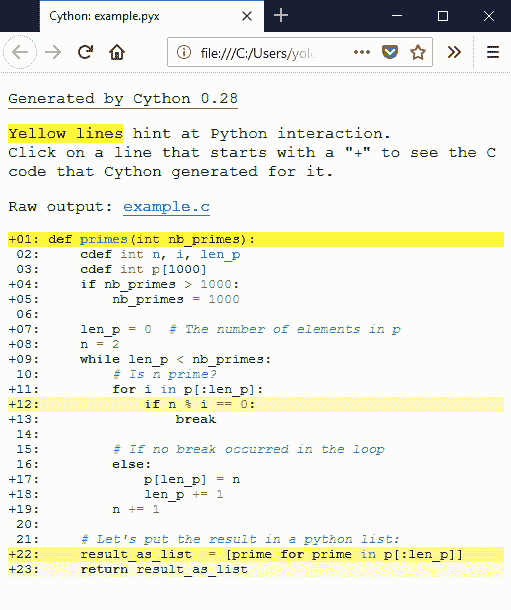
如果一行為白色,則表示生成的代碼不與 Python 交互,因此將以與普通 C 代碼一樣快的速度運行。黃色越深,該行中的 Python 交互越多。這些黃色線通常可以在 Python 對象上運行,引發異常,或執行其他類型的高級操作,而不是可以輕松轉換為簡單快速的 C 代碼。函數聲明和返回使用 Python 解釋器,因此這些行是黃色的。列表推導也是如此,因為它涉及創建 Python 對象。但行`if n % i == 0:`,為什么?我們可以檢查生成的 C 代碼來理解:
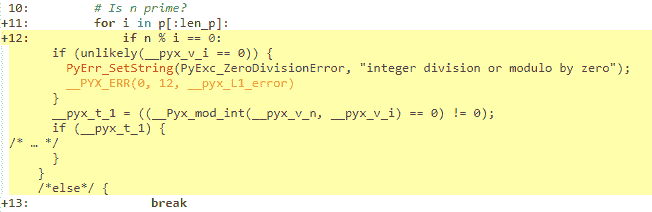
我們可以看到一些檢查發生。因為 Cython 默認使用 Python 行為,所以語言將在運行時執行除法檢查,就像 Python 一樣。您可以使用 [編譯器指令](../userguide/source_files_and_compilation.html#compiler-directives) 取消激活這些檢查。
現在讓我們看看,即使我們有分區檢查,我們也獲得了提升速度。讓我們編寫相同的程序,但是 Python 風格:
```py
def primes_python(nb_primes):
p = []
n = 2
while len(p) < nb_primes:
# Is n prime?
for i in p:
if n % i == 0:
break
# If no break occurred in the loop
else:
p.append(n)
n += 1
return p
```
也可以采用普通的`.py`文件并使用 Cython 進行編譯。讓我們拿`primes_python`,將函數名改為`primes_python_compiled`并用 Cython 編譯(不改變代碼)。我們還將文件名更改為`example_py_cy.py`,以區別于其他文件。現在`setup.py`看起來像這樣:
```py
from distutils.core import setup
from Cython.Build import cythonize
setup(
ext_modules=cythonize(['example.pyx', # Cython code file with primes() function
'example_py_cy.py'], # Python code file with primes_python_compiled() function
annotate=True), # enables generation of the html annotation file
)
```
現在我們可以確保這兩個程序輸出相同的值:
```py
>>> primes_python(1000) == primes(1000)
True
>>> primes_python_compiled(1000) == primes(1000)
True
```
現在可以比較速度:
```py
python -m timeit -s 'from example_py import primes_python' 'primes_python(1000)'
10 loops, best of 3: 23 msec per loop
python -m timeit -s 'from example_py_cy import primes_python_compiled' 'primes_python_compiled(1000)'
100 loops, best of 3: 11.9 msec per loop
python -m timeit -s 'from example import primes' 'primes(1000)'
1000 loops, best of 3: 1.65 msec per loop
```
`primes_python`的 cythonize 版本比 Python 版本快 2 倍,而不需要更改單行代碼。 Cython 版本比 Python 版本快 13 倍!有什么可以解釋這個?
Multiple things:
* 在這個程序中,每行都進行很少的計算。因此 python 解釋器的開銷非常重要。如果你要在每一行做很多計算,那將會非常不同。以 NumPy 為例。
* 數據位置。使用 C 時,使用 Python 時可能會有更多的內容適合 CPU 緩存。因為 python 中的所有內容都是一個對象,并且每個對象都是作為字典實現的,所以這不是很容易緩存的。
通常加速比在 2x 到 1000x 之間。這取決于你調用 Python 解釋器的程度。與往常一樣,請記住在各地添加類型之前進行配置添加類型會降低代碼的可讀性,因此請謹慎使用它們。
## 使用 C ++ 語言
使用 Cython,也可以利用 C ++語言,特別是 C ++標準庫的一部分可以直接從 Cython 代碼導入。
讓我們看看當使用 C ++標準庫中的[向量](https://en.cppreference.com/w/cpp/container/vector)時我們的`primes.pyx`變成了什么。
Note
C ++中的 Vector 是一種數據結構,它基于可調整大小的 C 數組實現列表或堆棧。它類似于`array`標準庫模塊中的 Python `array`類型。有一種方法<cite>保留</cite>可用,如果你事先知道你要在矢量中放入多少元素,它將避免復制。有關詳細信息,請參閱 cppreference 中的[此頁面。](https://en.cppreference.com/w/cpp/container/vector)
|
```py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
```
|
```py
# distutils: language=c++
from libcpp.vector cimport vector
def primes(unsigned int nb_primes):
cdef int n, i
cdef vector[int] p
p.reserve(nb_primes) # allocate memory for 'nb_primes' elements.
n = 2
while p.size() < nb_primes: # size() for vectors is similar to len()
for i in p:
if n % i == 0:
break
else:
p.push_back(n) # push_back is similar to append()
n += 1
# Vectors are automatically converted to Python
# lists when converted to Python objects.
return p
```
|
第一行是編譯器指令。它告訴 Cython 將您的代碼編譯為 C ++。這將允許使用 C ++語言功能和 C ++標準庫。請注意,使用 <cite>pyximport</cite> 無法將 Cython 代碼編譯為 C ++。您應該使用`setup.py`或筆記本來運行此示例。
您可以看到向量的 API 類似于 Python 列表的 API,有時可以用作 Cython 中的替代品。
有關在 Cython 中使用 C ++的更多詳細信息,請參閱 [在 Cython](../userguide/wrapping_CPlusPlus.html#wrapping-cplusplus)中使用 C ++。
## 語言詳細信息
有關 Cython 語言的更多信息,請參閱 [語言基礎知識](../userguide/language_basics.html#language-basics) 。要在數值計算環境中直接使用 Cython,請參閱 [類型內存視圖](../userguide/memoryviews.html#memoryviews) 。
- Cython 3.0 中文文檔
- 入門
- Cython - 概述
- 安裝 Cython
- 構建 Cython 代碼
- 通過靜態類型更快的代碼
- Tutorials
- 基礎教程
- 調用 C 函數
- 使用 C 庫
- 擴展類型(又名.cdef 類)
- pxd 文件
- Caveats
- Profiling
- Unicode 和傳遞字符串
- 內存分配
- 純 Python 模式
- 使用 NumPy
- 使用 Python 數組
- 進一步閱讀
- 相關工作
- 附錄:在 Windows 上安裝 MinGW
- 用戶指南
- 語言基礎
- 擴展類型
- 擴展類型的特殊方法
- 在 Cython 模塊之間共享聲明
- 與外部 C 代碼連接
- 源文件和編譯
- 早期綁定速度
- 在 Cython 中使用 C ++
- 融合類型(模板)
- 將 Cython 代碼移植到 PyPy
- Limitations
- Cython 和 Pyrex 之間的區別
- 鍵入的內存視圖
- 實現緩沖協議
- 使用并行性
- 調試你的 Cython 程序
- 用于 NumPy 用戶的 Cython
- Pythran 作為 Numpy 后端