
# 集群模式概述
該文檔給出了 Spark 如何在集群上運行、使之更容易來理解所涉及到的組件的簡短概述。通過閱讀 [應用提交指南](13.md) 來學習在集群上如何啟動應用程序。
# 組件
Spark 應用在集群上作為獨立的進程組來運行,在你的 `main` 進程中通過 `SparkContext` 來協調(稱之為 *driver 進程*)。
具體的說,為了運行在集群上,SparkContext 可以連接至幾種類型的 *Cluster Manager*(既可以用 Spark 自己的 `Standlone Cluster Manager`,或者 `Mesos`,也可以使用 `YARN`),它們會分配應用的資源。一旦連接上,Spark 獲得集群節點上的 `Executor`,這些進程可以運行計算并且為你的應用存儲數據。接下來,它將發送你的應用代碼(通過 `JAR` 或者 `Python` 文件定義傳遞給 `SparkContext`)至 `Executor`。最終,`SparkContext` 將發送 *`Task`* 到 `Executor` 進行運行。
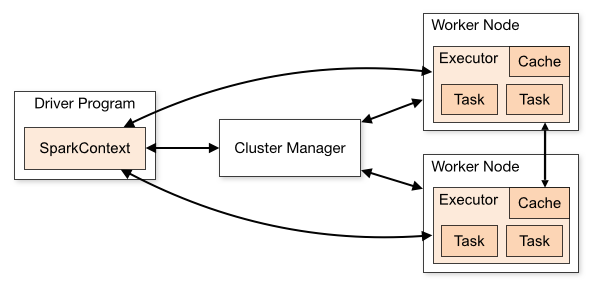
這里有幾個關于架構需要 *注意* 的地方 :
1. 每個應用獲取到它自己的 `Executor` 進程,它們會存活于整個應用生命周期中并且在多個線程中運行 `Task`(任務)。這樣做的優點是把應用互相隔離,在調度方面(每個 `Driver` 調度它自己的 `task`)和 `Executor` 方面(來自不同應用的 `task` 運行在不同的 ` JVM ` 中)。然而,這也意味著若是不把數據寫到外部存儲系統的話,數據就不能夠被不同的 `Spark ` 應用(`SparkContext` 的實例)之間共享。
2. `Spark` 是不知道也不需要知道底層的 `Cluster Manager` 到底是什么類型。只要它能夠獲得 `Executor` 進程,并且它們之間可以通信,那么即便在一個也支持其它應用的 `Cluster Manager`(例如,`Mesos` / `YARN`)上來運行它也是相對簡單的。
3. `Driver` 進程必須在自己生命周期內(例如,請參閱 [配置章節](20.md) 網絡配置部分 `spark.driver.port` 配置。監聽和接受來自它的 Executor 的連接請求。同樣的,driver 程序必須可以從 worker 節點上網絡尋址(就是網絡沒問題)。
4. 因為 `driver` 調度了集群上的 `task`(任務),更好的方式應該是在相同的局域網中靠近 `worker` 的節點上運行。如果你不喜歡發送請求到遠程的集群,倒不如打開一個 `RPC` 至 `driver` 并讓它就近提交操作而不是從很遠的 `worker` 節點上運行一個 `driver`。
# Cluster Manager 類型
系統目前支持多種 `cluster manage` 類型:
* [Standalone](15.md) -- 包含在 `Spark` 中使得更容易安裝集群的一個簡單 `Cluster Manage`
* [Apache Mesos](16.md) -- 一個通用的 `Cluster Manager`,它也可以運行 Hadoop `MapReduce` 和其它服務應用。
* [Hadoop YARN](17.md) -- Hadoop 2 中的 `resource manager`(資源管理器)。
* [Kubernetes](18.md) -- 用于自動化部署、擴展和管理容器化應用程序的開源系統。
存在一個第三方項目(不受Spark項目支持)來添加對[`Nomad`](https://github.com/hashicorp/nomad-spark)作為集群管理器的支持。
# 提交應用程序
使用 **spark-submit** 腳本可以提交應用程序到任何類型的集群。在 [應用提交指南](13.md) 介紹了在不同的集群上如何提交應用程序。
# 監控
每個 `driver` 都有一個 **Web UI**,通常在端口 `4040` 上,可以顯示有關正在運行的 `task`,`executor`,和存儲使用情況的信息。只需在 Web 瀏覽器中的`http://<driver-node>:4040` 中訪問此 UI。[監控指南](21.md) 中還介紹了其它監控相關工具介紹。
# Job 調度
Spark 即可以在應用間(Cluster Manager 級別),也可以在應用內(如果多個計算發生在相同的 SparkContext 上時)控制資源分配。在 [任務調度概述](23.md) 中更詳細地描述了這一點。
# 術語
下表總結了你學習過程中會看到的用于引用集群概念的術語:
<table class="table">
<thead>
<tr><th style="width: 130px;">Term</th><th>Meaning</th></tr>
</thead>
<tbody>
<tr>
<td>Application</td>
<td>用戶構建在 Spark 上的應用程序。由集群上的一個 <em>driver 進程</em> 和多個 <em>executor</em> 組成</td>
</tr>
<tr>
<td>Application jar</td>
<td>
一個包含用戶 Spark 應用的 Jar。有時候用戶會想要去創建一個包含他們應用以及它的依賴的 “uber jar”。用戶的 Jar 應該沒有包括 Hadoop 或者 Spark 庫,然而,它們將會在運行時被添加。
</td>
</tr>
<tr>
<td>Driver program</td>
<td>該進程運行應用的 main() 方法并且創建了 <em>SparkContext。</em> </td>
</tr>
<tr>
<td>Cluster manager</td>
<td>一個外部的用于獲取集群上資源的服務。(例如,Standlone Manager,Mesos,YARN)</td>
</tr>
<tr>
<td>Deploy mode</td>
<td>根據 driver 程序運行的地方區別。在 “Cluster” 模式中,框架在群集內部啟動 driver。在 “Client” 模式中,submitter(提交者)在 Custer 外部啟動 driver。</td>
</tr>
<tr>
<td>Worker node</td>
<td>在集群中可以運行應用程序代碼的任何節點。</td>
</tr>
<tr>
<td>Executor</td>
<td>一個為了在 worker 節點上的應用而啟動的進程,它運行 task 并且將數據保持在內存中或者硬盤存儲。每個應用有它自己的 Executor。</td>
</tr>
<tr>
<td>Task</td>
<td>一個將要被發送到 Executor 中的工作單元。</td>
</tr>
<tr>
<td>Job</td>
<td>一個由多個任務組成的并行計算,并且能從 Spark action 中獲取響應(例如 <code>save</code>,<code>collect</code>); 你將在 driver 的日志中看到這個術語。</td>
</tr>
<tr>
<td>Stage</td>
<td>每個 Job 被拆分成更小的被稱作 <em>stage</em> (階段)的 <em>task</em>(任務)組,<em>stage</em> 彼此之間是相互依賴的(與 <em>MapReduce</em> 中的 map/reduce <em>stage</em> 相似)。你將在 driver 的日志中看到這個術語。</td>
</tr>
</tbody>
</table>
- Spark 概述
- 編程指南
- 快速入門
- Spark 編程指南
- 構建在 Spark 之上的模塊
- Spark Streaming 編程指南
- Spark SQL, DataFrames and Datasets Guide
- MLlib
- GraphX Programming Guide
- API 文檔
- 部署指南
- 集群模式概述
- Submitting Applications
- 部署模式
- Spark Standalone Mode
- 在 Mesos 上運行 Spark
- Running Spark on YARN
- 其它
- 更多
- Spark 配置
- Monitoring and Instrumentation
- Tuning Spark
- 作業調度
- Spark 安全
- 硬件配置
- Accessing OpenStack Swift from Spark
- 構建 Spark
- 其它
- 外部資源
- Spark RDD(Resilient Distributed Datasets)論文
- 翻譯進度