
# Spark RDD(Resilient Distributed Datasets)論文
* [概要](#概要)
* [1:介紹](#1-介紹)
* [2:Resilient Distributed Datasets(RDDs)](#2-resilient-distributed-datasetsrdds)
* [2.1 RDD 抽象](#21-rdd-抽象)
* [2.2 Spark 編程接口](#22-spark-編程接口)
* [2.2.1 例子 – 監控日志數據挖掘](#221-例子--監控日志數據挖掘)
* [2.3 RDD 模型的優勢](#23-rdd-模型的優勢)
* [2.4 不適合用 RDDs 的應用](#24-不適合用-rdds-的應用)
* [3 Spark 編程接口](#3-spark-編程接口)
* [3.1 Spark 中 RDD 的操作](#31-spark-中-rdd-的操作)
* [3.2 舉例應用](#32-舉例應用)
* [3.2.1 線性回歸](#321-線性回歸)
* [3.2.2 PageRank](#322-pagerank)
* [4 表達 RDDs](#4-表達-rdds)
* [5 實現](#5-實現)
* [5.1 job 調度器](#51-job-調度器)
* [5.2 集成解釋器](#52-集成解釋器)
* [5.3 內存管理](#53-內存管理)
* [5.4 對 Checkpointing 的支持](#54-對-checkpointing-的支持)
* [6 評估](#6-評估)
* [6.1 迭代式機器學習應用](#61-迭代式機器學習應用)
* [6.2 PageRank](#62-pagerank)
* [6.3 容錯](#63-容錯)
* [6.4 內存不足的行為](#64-內存不足的行為)
* [6.5 用 spark 構建的用戶應用](#65-用-spark-構建的用戶應用)
* [6.6 交互性的數據挖掘](#66-交互性的數據挖掘)
* [7 討論](#7-討論)
* [7.1 已經存在的編程模型的表達](#71-已經存在的編程模型的表達)
* [7.2 利用 RDDs 來 debug](#72-利用-rdds-來-debug)
* [8 相關工作](#8-相關工作)
* [9 結尾](#9-結尾)
* [鳴謝](#鳴謝)
* [引用資料](#引用資料)
* [原文鏈接](#原文鏈接)
* [貢獻者](#貢獻者)
## 概要
為了能解決程序員能在大規模的集群中以一種容錯的方式進行內存計算這個問題,我們提出了 RDDs 的概念。當前的很多框架對迭代式算法場景與交互性數據挖掘場景的處理性能非常差,這個是 RDDs 的提出的動機。如果能將數據保存在內存中,將會使的上面兩種場景的性能提高一個數量級。為了能達到高效的容錯,RDDs 提供了一種受限制的共享內存的方式,這種方式是基于粗粒度的轉換共享狀態而非細粒度的更新共享狀態。然而,我們分析表明 RDDs 可以表達出很多種類的計算,包括目前專門從事迭代任務的編程計算模型,比如 Pregel,當然也可以表達出目前模型表達不出的計算。我們通過 Spark 系統來實現了 RDDs,并且通過各種各樣的用戶應用和測試來評估了這個系統。
## 1:介紹
像 MapReduce 和 Dryad 等分布式計算框架已經廣泛應用于大數據集的分析。這些系統可以讓用戶不用擔心分布式工作以及容錯,而是使用一系列的高層次的操作 api 來達到并行計算的目的。
雖然當前的框架提供了大量的對訪問利用計算資源的抽象,但是它們缺少了對利用分布式內存的抽象。樣使的它們在處理需要在多個計算之間復用中間結果的應用的時候會非常的不高效。數據的復用在迭代機器學習和圖計算領域(比如 PageRank,K-means 以及線性回歸等算法)是很常見的。在交互式數據挖掘中,一個用戶會經常對一個相同的數據子集進行多次不同的特定查詢,所以數據復用在交互式數據挖掘也是很常見的。然而,目前的大部分的框架對計算之間的數據復用的處理方式就是將中間數據寫到一個靠穩定的系統中(比如分布式文件系統),這樣會由于數據的復制備份,磁盤的 I/O 以及數據的序列化而致應用任務執行很費時間。
認識到這個問題后,研究者們已經為一些需要中間數據復用的應用開發出了一些特殊的框架。比如Pregel 在做迭代式圖計算的時候會將中間結果放在內存中。HaLoop 也提供了迭代式 MapReduce 接口。然而,這些框架僅僅支持一些特殊的計算模式(比如循環一系列的 MapReduce 步驟),并且它們是隱式的為些計算模式提供數據共享。它們沒有提供更加普遍數據復用的抽象,比如可以讓用戶加載幾個數據集到存中然后對這些內存中的數據集進行專門的查詢。
在這篇論文中,我們提出了一個全新的抽象,叫做 RDDs,它可以高效的處理廣泛的應用中涉及到的數據用的場景。RDDs 是一個可以容錯且并行的數據結構,它可以讓用戶顯式的將中間結果數據集保存在內中、控制數據集的分區來達到數據存放處理最優以及可以使用豐富的操作 api 來操作數據集。
在設計 RDDs 的時候,最大的挑戰是定義一個可以高效容錯的編程接口。已經存在的分布式內存抽象系統比如 distributed shared memory、key-value stores、databases 以及 Poccolo,都是提供了基于粒度的更新可變狀態(比如 table 中的 cells)的接口,基于這種接口下,保證容錯的方式無非是將數據復備份到多臺機器或者在多臺機器上記錄更新的日志,這兩種方式在數據密集性的工作任務中都是非常的耗時的,因為需要通過網絡傳輸在機器節點間復制大量的數據,寬帶傳輸數據的速度遠遠比 RAM 內存慢,而這兩種方式會占用大量的存儲空間。
與這些系統相反,RDDs 提供了基于粗粒度轉換(比如 map,filter 以及 join)的接口,這些接口可以對多的數據條目應用相同的操作。這樣就可以通過記錄來生成某個數據集的一系列轉換(就是這個數據集 lineage)而不是記錄真實的數據來達到提供高效的容錯機制。這個 RDD 就有足夠的信息知道它是從哪 RDDs 轉換計算來的,如果一個 RDD 的分區數據丟失掉了,那么重新計算這個 RDD 所依賴的那個 RDD 對應的區就行了。因此可以很快且不用通過復制備份方式來恢復丟失的數據。
雖然基于粗粒度的轉換一開始看起來受限制,但是 RDDs 非常適合很多并行計算的應用,因為這些應用基都是在大量的數據元素上應用相同的操作方法。事實上,我們分析表明 RDDs 不僅可以高效的表達出目前括 MapReduce,DryadLINQ,SQL,Pregel 以及 HaLoop 等系統提出的分布式編程模型,而且還能表達它們表達不了的新的應用的計算模型,比如交互型數據挖掘。我們相信,RDDs 解決那些新的框架提出來計算需求的能力將會成為是 RDD 抽象強大的最有力證據。
我們在 Spark 系統中實現了 RDDs,這個系統已經在 UC Berkeley 以及好些個公司中應用于研究和生產應中。Spark 和 DryadLINQ 類似使用scala語言提供了很方便語言集成編程接口。另外,Spark可以利用 scala 的解釋器來對大數據集進行交互式的查詢。我們相信 spark 是首個允許使用多種編程語言來進行分布式內存中交互式數據挖掘的系統。
我們通過為基準測試以及用戶應用的測試兩個方面來評估了 RDDs 和 spark。我們分析顯示,Spark 在迭代應用中可以比 hadoop 快上 20 倍以上、使的現實中的數據分析報表的速度提升了 40 倍以及使的交互式的掃1TB數據集的延遲在 5-7 秒。更重要的是,為了彰顯 RDDs 的普遍性,我們基于spark 用相對較小的程序(每個包只有 200 行代碼)實現了 Pregel 和 HaLoop 的編程模型,包括它們使用的數據分布優化。本篇論文以 RDDs(第二節)和 Spark(第三節)的概述開始。然后在第四節中討論 了RDD s內部的表達、在第節中討論了我們的實現以及在第六節中討論了實驗結果。最后,我們討論了 RDDs 是怎么樣來表達現在已存在的幾個系統的編程模型(第七節)、調查相關工作(第八節)以及總結。
## 2:Resilient Distributed Datasets(RDDs)
這節主要講述 RDDs 的概要,首先定義 RDDs(2.1)以及介紹 RDDs 在 spark 中的編程接口(2.2),然后對 RDDs 和細粒度共享內存抽象進行的對比(2.3)。最后我們討論了 RDD 模型的限制性。
### 2.1 RDD 抽象
一個 RDD 是一個只讀,被分區的數據集。我們可以通過兩種對穩定的存儲系統和其他的 RDDs 進行操作而創建一個新的 RDDs。為了區別開 RDDs 的其他操作,我們稱這些操作為 transformations,比如 map,filter 以及 join 等都是 transformations 操作。
RDDs 并不要始終被具體化,一個 RDD 有足夠的信息知道自己是從哪個數據集計算而來的(就是所謂的依賴血統),這是一個非常強大的屬性:其實,一個程序你能引用一個不能從失敗中重新構建的 RDD。
最后,用戶可以控制 RDDs 的兩個方面:數據存儲和分區。對于需要復用的 RDD,用戶可以明確的選擇一個數據存儲策略(比如內存緩存)。他們也可以基于一個元素的 key 來為 RDD 所有的元素在機器節點間進行數據分區,這樣非常利于數據分布優化,比如給兩個數據集進行相同的 hash 分區,然后進行 join,可以提高 join 的性能。
### 2.2 Spark 編程接口
Spark 和 DryadLINQ 和 FlumeJava 一樣通過集成編程語言 api 來暴露 RDDs,這樣的話,每一個數據集就代表一個對象,我們可以調用這個對象中的方法來操作這個對象。
編程者可以通過對穩定存儲的數據進行轉換操作(即 transformations,比如 map 和 filter 等)來得到一個或者多個 RDDs。然后可以對這些 RDDs 進行 actions 操作,這些操作可以是得到應用的結果值,也可以是將結果數據寫入到存儲系統中,actions 包括:count(表示返回這個數據集的元素的個數)、collect(表示返回數據集的所有元素)以及 save(表示將輸出結果寫入到存儲系統中)。和 DryadLINQ 一樣,spark 在定義 RDDs 的時候并不會真正的計算,而是要等到對這個 RDDs 觸發了 actions 操作才會真正的觸發計算,這個稱之為 RDDs 的 lazy 特性,所以我們可以先對 transformations 進行組裝一系列的 pipelines,然后再計算。
另外,編程者可以通過調用 RDDs 的 persist 方法來緩存后續需要復用的 RDDs。Spark 默認是將緩存數據放在內存中,但是如果內存不足的話則會寫入到磁盤中。用戶可以通過 persist 的參數來調整緩存策略,比如只將數據存儲在磁盤中或者復制備份數據到多臺機器。最后,用戶可以為每一個 RDDs 的緩存設置優先級,以達到哪個在內存中的 RDDs 應該首先寫道磁盤中
#### 2.2.1 例子 – 監控日志數據挖掘
假設一個 web 服務正發生了大量的錯誤,然后運維人員想從存儲在 hdfs 中的幾 TB 的日志中找出錯誤的原因。運維人員可以通過 spark 將日志中的錯誤信息加載到分布式的內存中,然后對這些內存中的數據進行查詢。她首先需要寫下面的 scala 代碼:
```
line = spark.textFile("hdfs://..")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()
```
第一行表示從一個 HDFS 文件(許多行的文件數據集)上定義了一個 RDD,第二行表示基于前面定義的 RDD 進行過濾數據。第三行將過濾后的 RDD 結果存儲在內存中,以達到多個對這個共享 RDD 的查詢。需要注意的事,filter 的參數是 scala 語法中的閉包。
到目前為止,集群上還沒有真正的觸發計算。然而,用戶可以對RDD進行action操作,比如對錯誤信息的計數:
```
errors.count()
```
用戶也可以繼續對 RDD 進行 transformations 操作,然后計算其結果,比如:
```
//對錯誤中含有 ”MySQL” 單詞的數據進行計數
errors.filters(_.contains("MySQL")).count()
//返回錯誤信息中含有 "HDFS" 字樣的信息中的時間字段的值(假設每行數據的字段是以 tab 來切分的,時間字段是第 3 個字段)
errors.filter(_.contains("HDFS"))
.map(_.split("\t")(3))
.collect()
```
在對 errors 第一次做 action 操作的后,spark 會將 errors 的所有分區的數據存儲在內存中,這樣后面對 errors 的計算速度會有很大的提升。需要注意的是,像 lines 這種基礎數據的 RDD 是不會存儲在內存中的。因為包含錯誤信息的數據可能只是整個日志數據的一小部分,所以將包含錯誤數據的日志放在內存中是比較合理的。
最后,為了說明我們的模型是如何達到容錯的,我們在圖一種展示了第三個查詢的血緣關系圖(lineage graph)。在這個查詢種,我們以對 lines 進行過濾后的 errors 開始,然后在對 errors 進行了 filter 和 map 操作,最后做了 action 操作即 collect。Spark 會最后兩個 transformations 組成一個 pipeline,然后將這個 pipeline 分解成一系列的 task,最后將這些 task 調度到含有 errors 緩存數據的機器上進行執行。此外,如果 errors 的一個分區的數據丟失了,spark 會對 lines 的相對應的分區應用 filter 函數來重新創建 errors 這個分區的數據
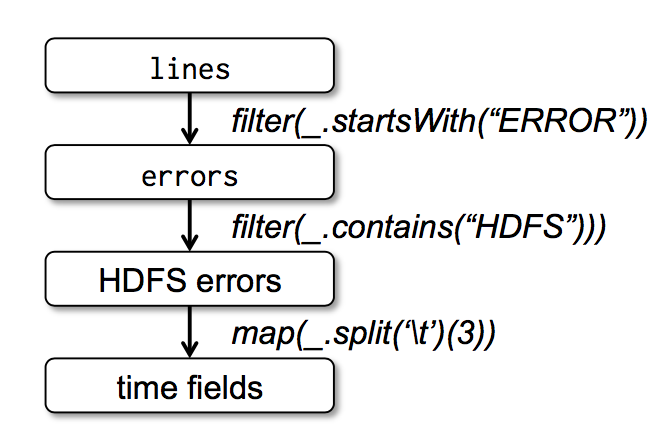
圖一:我們例子中第三個查詢的血緣關系圖,其中方框表示 RDDs,箭頭表示轉換
### 2.3 RDD 模型的優勢
為了理解作為分布式內存抽象的 RDDs 的好處,我們在表一中用 RDDs 和分布式共享內存系統(Distributed shared memory 即 DSM)進行了對比。在所有的 DSM 系統中,應用從一個全局的地址空間中的任意位置中讀寫數據。需要注意的是,依據這個定義,我們所說的 DSM 系統不僅包含了傳統的共享內存系統,還包含了對共享狀態的細粒度寫操作的其他系統(比如 Piccolo),以及分布式數據庫。DSM 是一個很普遍的抽象,但是這個普遍性使得它在商用集群中實現高效且容錯的系統比較困難。
| Aspect(概念)| RDDs | Distribute shared memory(分布式共享內存)|
| --- | --- | --- |
| Reads | 粗粒度或者細粒度 | 細粒度 |
| Writes | 粗粒度 | 細粒度 |
| 數據一致性 | 不重要的(因為RDD是不可變的)| 取決于app 或者 runtime |
| 容錯 | 利用lineage達到細粒度且低延遲的容錯 | 需要應用checkpoints(就是需要寫磁盤)并且需要程序回滾 |
| 計算慢的任務 | 可以利用備份的任務來解決 | 很難做到 |
| 計算數據的位置 | 自動的機遇數據本地性 | 取決于app(runtime是以透明為目標的)|
| 內存不足時的行為 | 和已經存在的數據流處理系統一樣,寫磁盤 | 非常糟糕的性能(需要內存的交換?)|
表一:RDDs 和 Distributed shared memory 對比
RDDs 只能通過粗粒度的轉換被創建(或者被寫),然而 DSM 允許對每一個內存位置進行讀寫,這個是 RDDs 和 DSM 最主要的區別。這樣使都 RDDs在 應用中大量寫數據受到了限制,但是可以使的容錯變的更加高效。特別是,RDDs 不需要發生非常耗時的 checkpoint 操作,因為它可以根據 lineage 進行恢復數據。而且,只有丟掉了數據的分區才會需要重新計算,并不需要回滾整個程序,并且這些重新計算的任務是在多臺機器上并行運算的。
RDDs 的第二個好處是:它不變的特性使的它可以和 MapReduce 一樣來運行執行很慢任務的備份任務來達到緩解計算很慢的節點的問題。在 DSM 中,備份任務是很難實現的,因為原始任務和備份任務或同時更新訪問同一個內存地址和接口。
最后,RDDs 比 DSM 多提供了兩個好處。第一,在對 RDDs 進行大量寫操作的過程中,我們可以根據數據的本地性來調度 task 以提高性能。第二,如果在 scan-base 的操作中,且這個時候內存不足以存儲這個 RDDs,那么 RDDs 可以慢慢的從內存中清理掉。在內存中存儲不下的分區數據會被寫到磁盤中,且提供了和現有并行數據處理系統相同的性能保證。
### 2.4 不適合用 RDDs 的應用
經過上面的討論介紹,我們知道 RDDs 非常適合將相同操作應用在整個數據集的所有的元素上的批處理應用。在這些場景下,RDDs 可以利用血緣關系圖來高效的記住每一個 transformations 的步驟,并且不需要記錄大量的數據就可以恢復丟失的分區數據。RDDs 不太適合用于需要異步且細粒度的更新共享狀態的應用,比如一個 web 應用或者數據遞增的 web 爬蟲應用的存儲系統。對于這些應用,使用傳統的紀錄更新日志以及對數據進行 checkpoint 會更加高效。比如使用數據庫、RAMCloud、Percolator 以及 Piccolo。我們的目標是給批量分析提供一個高效的編程模型,對于這些異步的應用需要其他的特殊系統來實現。
## 3 Spark 編程接口
Spark 使用 scala 語言實現了抽象的 RDD,scala 是建立在 java VM 上的靜態類型函數式編程語言。我們選擇 scala 是因為它結合了簡潔(很方便進行交互式使用)與高效(由于它的靜態類型)。然而,并不是說 RDD 的抽象需要函數式語言來實現。
開發員需要寫連接集群中的 workers 的 driver 程序來使用 spark,就比如圖 2 展示的。Driver 端程序定義了一系列的 RDDs 并且調用了 RDD 的 action 操作。Driver 的程序同時也會跟蹤 RDDs 之間的的血緣關系。workers 是可以將 RDD 分區數據存儲在內存中的長期存活的進程。
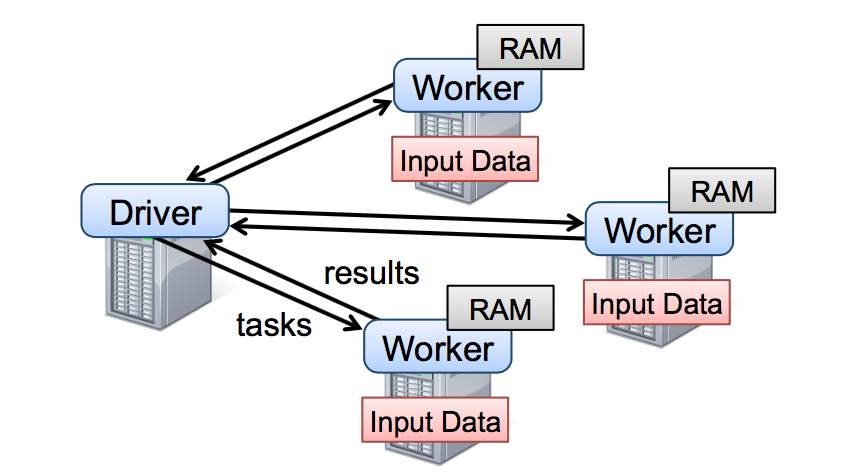
圖二:這個是 Spark 運行時的圖,用戶寫的 driver 端程序啟動多個 workers,這些 workers 可以從分布書的存儲系統中讀取數據塊并且可以將計算出來的 RDD 分區數據存放在內存中。
在 2.2.1 小節中的日志挖掘例子中,我們提到,用戶提供給 RDD 操作比如 map 以參數作為這個操作的閉包(說白了就是函數)。Scala 將這些函數看作一個 java 對象,這些對象是可以序列化的,并且可以通過網絡傳輸傳輸到其他的機器節點上的。Scala 將函數中的變量看作一個對象中的變量。比如,我們可以寫一段這樣的代碼:var x = 5; rdd.map(_ + 5)來達到給這個 RDD 每一個元素加上 5 的目的。
RDDs 是被一元素類型參數化的靜態類型對象,比如,RDD[Int] 表示一個類型為整數的 RDD。然而,我們很多例子中的 RDD 都會省去這個類型,這個是因為 scala 支持類型推斷。
雖然我們用 scala 實現 RDD 的方法很簡單,但是我們需要處理用反射實現的閉包對象相關的工作,我們還需要做很多的工作使的 spark 可以用 scala 的解釋器,這個我們在 5.2 小節中會討論到。盡管如此,我們是不需要修改 scala 的編譯器的。
### 3.1 Spark 中 RDD 的操作
表 2 中列舉了 Spark 中 RDD 常用的 transformations 和 actions 操作,且描述了每一個方法的簽名以及類型。我們需要記住 transformations 是用來定義一個新的 RDD 的 lazy 操作,而actions 是真正觸發一個能返回結果或者將結果寫到文件系統中的計算。

表二:Spark 中 RDD 常用的 transformations 和 actions 操作。Seq[T] 表示元素類型為 T 的一個列表。
需要注意的是,一些操作比如 join 只適合用于 key-value 類型的 RDDs。我們取的函數的名稱和 scala 或者其他函數式編程語言的函數名是一致的。比如,map 是一個 one-to-one 的映射操作,而 flatMap 的每一個輸入值會對應一個或者更多的輸出值(有點像 MapReduce 中的 map)
除了這些操作,用戶可以通過 persist 操作來請求緩存 RDD。另外,用戶可以拿到被 Partitioner 分區后的分區數以及根據 Partitioner 對另一個 dataset 進行分區。像 groupByKey、reduceByKey 以及 sort 等操作都是經過了hash 或者 rang 分區后的 RDD。
### 3.2 舉例應用
我們用兩個迭代式的應用:線性回歸和 PageRank 來補充 2.2.1 提到的數據挖掘的例子。稍后也會展示下如何控制 RDD 的分區以達到提升性能的目的。
#### 3.2.1 線性回歸
很多的機器學習算法一般都是迭代式的計算,因為它們需要跑迭代的優化程序(比如梯度下降)來達到最大化功能。他們將數據存放在內存中以達到很快的速度。
作為一個例子,下面的程序實現了線性回歸,一個能找到最佳區分兩種點集(垃圾郵件以及非垃圾郵件)的超平面 w 的常用的分類算法。這個算法用了梯度下降的方法:一個隨機的值作為 w 的初始值,每次迭代都會將含有 w 的方法應用到每一個數據點然后累加得到梯度值,然后將 w 往改善結果的方向移動。

一開始我們定義一個叫 points 的 RDD,這個 RDD 從一個文本文件中經過 map 將每一行轉換為 Point 對象得到。然后我們重復對 points 進行 map 和 reduce 操作計算出每一步的梯度值。在迭代之間我們將 points 存放在內存中可以使的性能提高 20 倍,我們將會在 6.1 節中討論。
#### 3.2.2 PageRank
在 PageRank 中數據共享更加復雜。如果一個文檔引用另一個文檔,那被引用的文檔的排名值(rank)需要加上引用的文檔發送過來的貢獻值,當然這個過程是個迭代的過程。在每一次迭代中,每一個文檔都會發送 r/n 的貢獻值給它的鄰居,其中 r 表示這個文檔的排名值,n 表示這個文檔的鄰居數量。然后更新文檔的排名值為,這個表達式值表示這個文檔收到的貢獻值,N 表示所有的文檔的數量,我們可以用如下的 spark 代碼來表達 PageRank:

其中 links 表示(URL , outlinks)鍵值對。這個程序的 RDD 的血緣關系圖如圖三。在每一次迭代中我們都是根據上一次迭代的 contribs 和 ranks 以及原始不變的 links 數據集來創建一個新的 ranks 數據集。隨著迭代次數的變多這張圖會變的越長,這個是這個圖比較有意思的特點。如果這個 job 的迭代次數很多的話,那么備份一些版本的 ranks 來達到減少從錯誤中恢復出來的時間是很有必要的,用戶可以調用標記為 RELIABLE 的 persist 函數來達到這個目的。需要注意的是,links 是不需要備份的,因為它的分區數據可以快速的從重新計算輸入文件中對應的數據塊而得到,這個數據集一般會比 ranks 數據集大上很多倍,因為每一個文檔會有很多的連接但只會有一個排名值,所以利用 RDD 的血緣關系來恢復數據肯定比 checkpoint 內存中的數據快很多(因為數據量太大)。
最后,我們可以控制 RDDs 的分區方式來優化 PageRank 中的節點通訊。如果我們事先為 links 指定一個分區方式(比如,根據 link 的 url 來 hash 分區,就是將相同的 url 發送到同一個節點中),然后我們對 ranks 進行相同的分區方式,這樣就可以保證 links 和 ranks 之間的 join 不需要機器節點之間的通訊(因為相同的 url 都在同一個機器節點了,那么相對應的 rank 和 link 肯定也是在同一個機器節點了)。我們也可以自定義分區器來實現將一組頁面 url 放到一起(比如按照 url 的 domain 進行分區)。以上兩種優化方式都可以通過在定義 links 的時候調用 partitionBy 來實現:
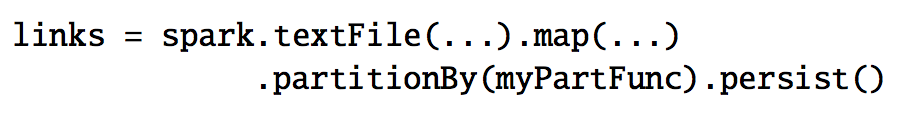
在調用了 partitionBy 后,links 和 ranks 之間的 join 操作會自動的在 link 所在的機器進行每一個 URL 的貢獻值的聚合計算,然后在相同的機器計算新的排名值,然后計算出來的新的 ranks 在相同的機器和 links 進行 join。這種在迭代之間進行數據一致分區是像 Pregel 這種框架中的主要的優化計算方式。RDDs 使的用戶可以直接自己來實現這種優化機制。
## 4 表達 RDDs
在抽象 RDDs 的過程中,怎么表達出 RDDs 能跟蹤很多的 transformations 操作之間血緣關系是一個比較大的挑戰。理想的情況下,一個實現 RDDs 系統應該是盡可能多的提供 transformations 操作(比如表二中的操作),并且可以讓用戶以任意的方式來組合這些 transformations 操作。我們提出了基于圖的 RDDs 展現方式來達到以上的目的。我們在 spark 中利用這種展現方式達到了在不需要給調度系統為每一個 transformation 操作增加任何的特殊邏輯就可以支持大量的 transformations 操作,這樣極大的簡化了我們的系統設計。
概括的說,以下五個信息可以表達 RDDs:一個分區列表,每一個分區就是數據集的原子塊。一個父親 RDDs 的依賴列表。一個計算父親的數據集的函數。分區模式的元數據信息以及數據存儲信息。比如,基于一個 HDFS 文件創建出來的的 RDD 中文件的每一個數據塊就是一個分區,并且這個 RDD 知道每一個數據塊存儲在哪些機器上,同時,在這個 RDD 上進行 map 操作后的結果有相同的分區數,當計算元素的時候,將 map 函數應用到父親 RDD 數據中的。我們在表三總結了這些接口:
| 操作接口 | 含義 |
| --- | --- |
| partitions() | 返回一個分區對象的列表 |
| preferredLocations(p) | 分區p數據存儲在哪些機器節點中 |
| dependencies() | 返回一個依賴列表 |
| iterator(p, parentIters) | 根據父親分區的數據輸入計算分區p的所有數據 |
| partitioner() | 返回這個RDD是hash還是range分區的元數據信息 |
表三:Spark 中表達 RDDs 的接口
在設計如何表達 RDDs 之間依賴的接口是一個非常有意思的問題。我們發現將依賴定義成兩種類型就足夠了:窄依賴,表示父親 RDDs 的一個分區最多被子 RDDs 一個分區所依賴。寬依賴,表示父親 RDDs 的一個分區可以被子 RDDs 的多個子分區所依賴。比如,map 操作是一個窄依賴,join 操作是一個寬依賴操作(除非父親 RDDs 已經被 hash 分區過),圖四顯示了其他的例子:
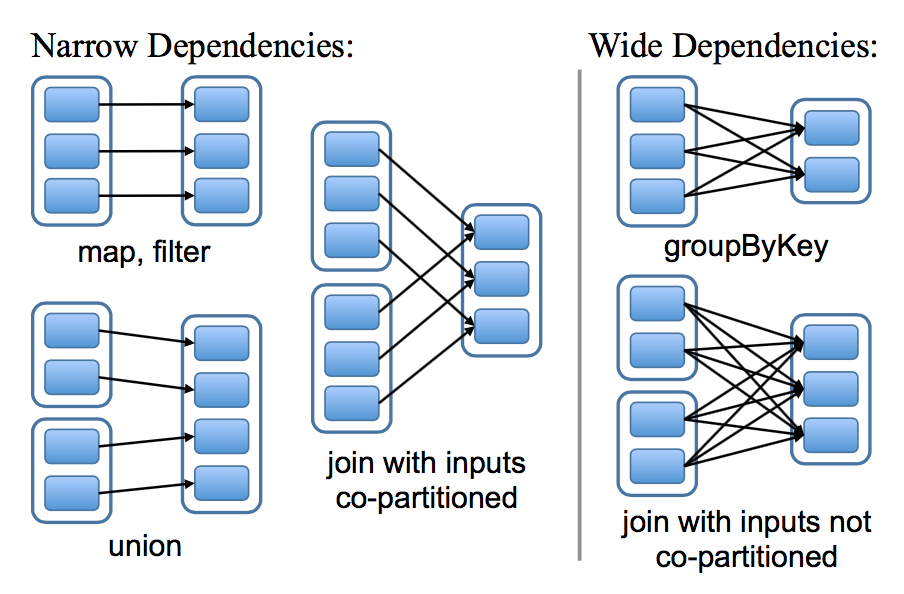
圖四:窄依賴和寬依賴的例子。每一個方框表示一個 RDD,帶有顏色的矩形表示分區
以下兩個原因使的這種區別很有用,第一,窄依賴可以使得在集群中一個機器節點的執行流計算所有父親的分區數據,比如,我們可以將每一個元素應用了 map 操作后緊接著應用 filter 操作,與此相反,寬依賴需要父親 RDDs 的所有分區數據準備好并且利用類似于 MapReduce 的操作將數據在不同的節點之間進行重新洗牌和網絡傳輸。第二,窄依賴從一個失敗節點中恢復是非常高效的,因為只需要重新計算相對應的父親的分區數據就可以,而且這個重新計算是在不同的節點進行并行重計算的,與此相反,在一個含有寬依賴的血緣關系 RDDs 圖中,一個節點的失敗可能導致一些分區數據的丟失,但是我們需要重新計算父 RDD 的所有分區的數據。
Spark 中的這些 RDDs 的通用接口使的實現很多 transformations 操作的時候只花了少于 20 行的代碼。實際上,新的 spark 用戶可以在不了解調度系統的細節之上來實現新的 transformations 操作(比如,采樣和各種 join 操作)。下面簡要的概括了一些 RDD 的實現:
* HDFS files:抽樣的輸入 RDDs 是 HDFS 中的文件。對于這些 RDDs,partitions 返回文件中每一個數據塊對應的一個分區信息(數據塊的位置信息存儲在 Partition 對象中),preferredLocations 返回每一個數據塊所在的機器節點信息,最后 iterator 負責數據塊的讀取操作。
* map:對任意的 RDDs 調用 map 操作將會返回一個 MappedRDD 對象。這個對象含有和其父親 RDDs 相同的分區信息和數據存儲節點信息,但是在 iterator 中對父親的所有輸出數據記錄應用傳給 map 的函數。
* union:對兩個 RDDs 調用 union 操作將會返回一個新的 RDD,這個 RDD 的分區數是他所有父親 RDDs 的所有分區數的總數。每一個子分區通過相對應的窄依賴的父親分區計算得到。
* sample:sampling 和 mapping 類似,除了 sample RDD 中為每一個分區存儲了一個隨機數,作為從父親分區數據中抽樣的種子。
* join:對兩個 RDDs 進行 join 操作,可能導致兩個窄依賴(如果兩個 RDDs 都是事先經過相同的 hash/range 分區器進行分區),或者導致兩個寬依賴,或者一個窄依賴一個寬依賴(一個父親 RDD 經過分區而另一個沒有分區)。在上面所有的惡場景中,join 之后的輸出 RDD 會有一個 partitioner(從父親 RDD 中繼承過來的或者是一個默認的 hash partitioner)。
## 5 實現
我們用了 14000 行 scala 代碼實現了 spark。Spark 系統跑在集群管理者 mesos 上,這樣可以使的它和其他的應用比如 hadoop 、 MPI 等共享資源,每一個 spark 程序都是由它的 driver 和 workers 組成,這些 driver 和 workers 都是以一個 mesos 應用運行在 mesos 上的,mesos 可以管理這些應用之間的資源共享問題。
Spark 可以利用已經存在的 hadoop 的 api 組件讀取任何的 hadoop 的輸入數據源(比如:HDFS 和 Hbase 等),這個程序 api 是運行在沒有更改的 scala 版本上。
我們會簡要的概括下幾個比較有意思的技術點:我們的 job 調度器(5.1 節),可以用于交互的 spark 解釋器(5.2 節),內存管理(5.3 節)以及對 checkpointing 的支持(5.4 節)。
### 5.1 job 調度器
spark 的調度器依賴我們在第 4 章中討論的 RDDs 的表達。
從總體上看,我們的調度系統有點和 Dryad 相似,但是它還考慮了被存儲的 RDDs 的哪些分區還在內存中。當一個用戶對某個 RDD 調用了 action 操作(比如 count 或者 save)的時候調度器會檢查這個 RDD 的血緣關系圖,然后根據這個血緣關系圖構建一個含有 stages 的有向無環圖(DAG),最后按照步驟執行這個 DAG 中的 stages,如圖 5 的說明。每一個 stage 包含了盡可能多的帶有窄依賴的 transformations 操作。這個 stage 的劃分是根據需要 shuffle 操作的寬依賴或者任何可以切斷對父親 RDD 計算的某個操作(因為這些父親 RDD 的分區已經計算過了)。然后調度器可以調度啟動 tasks 來執行沒有父親 stage 的 stage(或者父親 stage 已經計算好了的 stage),一直到計算完我們的最后的目標 RDD 。
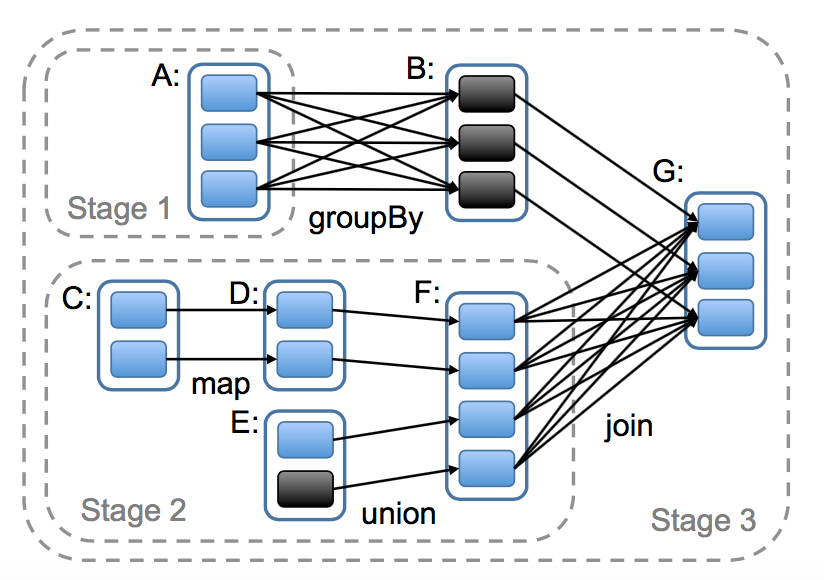 圖五:怎么計算 spark job stage 的例子。實現的方框表示 RDDs ,帶有顏色的方形表示分區,黑色的是表示這個分區的數據存儲在內存中,對 RDD G 調用 action 操作,我們根據寬依賴生成很多 stages,且將窄依賴的 transformations 操作放在 stage 中。在這個場景中,stage 1 的輸出結果已經在內存中,所以我們開始運行 stage 2,然后是 stage 3。
我們調度器在分配 tasks 的時候是采用延遲調度來達到數據本地性的目的(說白了,就是數據在哪里,計算就在哪里)。如果某個分區的數據在某個節點上的內存中,那么將這個分區的計算發送到這個機器節點中。如果某個 RDD 為它的某個分區提供了這個數據存儲的位置節點,則將這個分區的計算發送到這個節點上。
對于寬依賴(比如 shuffle 依賴),我們將中間數據寫入到節點的磁盤中以利于從錯誤中恢復,這個和 MapReduce 將 map 后的結果寫入到磁盤中是很相似的。
只要一個任務所在的 stage 的父親 stage 還是有效的話,那么當這個 task 失敗的時候,我們就可以在其他的機器節點中重新跑這個任務。如果一些 stages 變的無效的話(比如因為一個 shuffle 過程中 map 端的一個輸出結果丟失了),我們需要重新并行提交沒有父親 stage 的 stage(或者父親 stage 已經計算好了的 stage)的計算任務。雖然備份 RDD 的血緣關系圖示比較容易的,但是我們還不能容忍調度器調度失敗的場景。
雖然目前 spark 中所有的計算都是響應 driver 程序中調用的 action 操作,但是我們也是需要嘗試在集群中調用 lookup 操作,這種操作是根據 key 來隨機訪問已經 hash 分區過的 RDD 所有元素以獲取相應的 value。在這種場景中,如果一個分區沒有計算的話,那么 task 需要將這個信息告訴調度器。
### 5.2 集成解釋器
scala 和 Ruby 以及 Python 一樣包含了一個交互型的 shell 腳本工具。考慮到利用內存數據可以獲得低延遲的特性,我們想讓用戶通過解釋器來交互性的運行 spark,從而達到查詢大數據集的目的。
Scala 解釋器通常是將用戶輸入的每一行代碼編譯成一個類,然后將這個類加載到 JVM 中,然后調用這個類的方法。這個類中包含了一個單例對象,這個單例對象包含了用戶輸入一行代碼中的變量或者函數,還包含了一個運行用戶輸入那行代碼的初始化方法。比如,用戶輸入 var x = 5,然后再輸入 println(x),scala 解釋器定義個包含了 x 的叫做 Line 1 的類,然后將第二行代碼編譯成 println(Line 1.getInstance(). x )。
我們對 spark 中的解釋器做了如下兩個改變:
1. Class shipping:為了讓 worker 節點能拿到用戶輸入的每一行代碼編譯成的 class 的二進制代碼,我們使的解釋器為這些 classes 的二進制代碼提供 HTTP 服務。
2. 修改了代碼生成:正常情況下,我們通過訪問對應的類的靜態方法來達到訪問將用戶輸入每一行代碼編譯成的單例對象。這個意味著,當我們將一個含有在前面行中定義的變量(比如上面例子中的 Line 1.x)的閉包序列化發送到 worker 節點的時候,java 是不會通過對象圖來跟蹤含有 x 的實力 Line 1 的,這樣的話 worker 節點將收不到變量 x。我們修改了代碼生成邏輯來達到能直接引用每一行代碼生成的實例。
圖六顯示了經過我們的改變后,解釋器是如何將用戶輸入的一系列的代碼轉換成 java 對象。
 圖六:顯示 spark 解釋器是如何將用戶輸入的代碼轉換成 java 對象的例子
我們發現 spark 解釋器在處理我們研究中的大量已經獲取到的痕跡數據以及探索存儲在 hdfs 中的數據集時是非常有用的。我們正在打算用這個來實現更高層面的交互查詢語言,比如 SQL。
### 5.3 內存管理
Spark 在持久化 RDDs 的時候提供了 3 種存儲選:存在內存中的非序列化的 java 對象、存在內存中的序列化的數據以及存儲在磁盤中。第一種選擇的性能是最好的,因為 java VM 可以很快的訪問 RDD 的每一個元素。第二種選擇是在內存有限的情況下,使的用戶可以以很低的性能代價而選擇的比 java 對象圖更加高效的內存存儲的方式。如果內存完全不夠存儲的下很大的 RDDs,而且計算這個 RDD 又很費時的,那么選擇第三種方式。
為了管理有限的內存資源,我們在 RDDs 的層面上采用 LRU(最近最少使用)回收策略。當一個新的 RDD 分區被計算但是沒有足夠的內存空間來存儲這個分區的數據的時候,我們回收掉最近很少使用的 RDD 的分區數據的占用內存,如果這個 RDD 和這個新的計算分區的 RDD 時同一個 RDD 的時候,我們則不對這個分區數據占用的內存做回收。在這種情況下,我們將相同的 RDD 的老分區的數據保存在內存中是為了不讓老是重新計算這些分區的數據,這點是非常重要的,因為很多操作都是對整個 RDD 的所有的 tasks 進行計算的,所以非常有必要將后續要用到的數據保存在內存中。到目前為止,我們發現這種默認的機制在所有的應用中工作的很好,但是我們還是將持久每一個 RDD 數據的策略的控制權交給用戶。
最后,在一個集群中的每一個 spark 實例的內存空間都是分開的,我們以后打算通過統一內存管理達到在 spark 實例之間共享 RDDs。
### 5.4 對 Checkpointing 的支持
雖然我們總是可以使用 RDDs 的血緣關系來恢復失敗的 RDDs 的計算,但是如果這個血緣關系鏈很長的話,則恢復是需要耗費不少時間的。因此,將一些 RDDs 的數據持久化到穩定存儲系統中是有必要的
一般來說,checkpointing 對具有很長的血緣關系鏈且包含了寬依賴的 RDDs 是非常有用的,比如我們在 3.2.2 小節中提到的 PageRank 的例子。在這些場景下,集群中的某個節點的失敗會導致每一個父親 RDD 的一些數據的丟失,進而需要重新所有的計算。與此相反的,對于存儲在穩定存儲系統中且是窄依賴的 RDDs(比如 3.2.1 小節中線性回歸例子中的 points 和 PageRank 中的 link 列表數據),checkpointing 可能一點用都沒有。如果一個節點失敗了,我們可以在其他的節點中并行的重新計算出丟失了數據的分區,這個成本只是備份整個 RDD 的成本的一點點而已。
spark 目前提供了一個 checkpointing 的 api(persist 中的標識為 REPLICATE,還有 checkpoint()),但是需要將哪些數據需要 checkpointing 的決定權留給了用戶。然而,我們也在調查怎么樣自動的 checkpoing,因為我們的調度系統知道數據集的大小以及第一次計算這個數據集花的時間,所以有必要選擇一些最佳的 RDDs 來進行 checkpointing,來達到最小化恢復時間
最后,需要知道的事 RDDs 天生的只讀的特性使的他們比一般的共享內存系統做 checkpointing 更簡單了。因為不用考慮數據的一致性,我們可以不終止程序或者 take 快照,然后在后臺將 RDDs 的數據寫入到存儲系統中。
### 6 評估
我們通過在亞馬遜 EC 2 傷進行一系列的實驗以及用用戶的應用做基準測試來評估 spark,總的來說,下面是我們的結論:
* 在迭代式機器學習和圖計算中,spark 以 20 倍的速度超過了 hadoop。提速的點主要是在避免了 I / O 操作以及將數據以 java 對象的形式存在內存中從而降低了反序列化的成本。
* 用戶寫的應用程序運行平穩以及很好擴展。特別的,我們利用 spark 為一個分析報表提速了 40 倍,相對于 hadoop 來說。
* 當節點失敗的時候,spark 可以通過重新計算失去的 rdd 分區數據達到快速的恢復。
* spark 在查詢 1 TB 的數據的時候的延遲可以控制在 5 到 7 秒。
我們通過和 hadoop 對比,展示迭代式機器學習(6.1 節)和 PageRank(6.2 節)的基準測試。然后我們評估了 spark 的錯誤恢復機制(6.3 節)以及當內存不足以存儲一個數據集的行為(6.4 節),最后我們討論了用戶應用(6.5 節)和交互式數據挖掘(6.6 節)的結果 除非另外聲明,我們都是用類型為 m 1.xlarge 的 EC 2 節點,4 核以及 15 GB 內存。我們是有數據塊大小為 256 M 的 HDFS 存儲系統。在每一次測試之前,我們都會清理 OS 的緩存,以達到準確的測量 IO 成本的目的
### 6.1 迭代式機器學習應用
我們實現了兩種迭代式機器學習應用,線性回歸核 K - means,來和下面的系統進行性能的對比:
* Hadoop:版本號為 0.20.0 的穩定版。
* HadoopBinMem:這個系統在迭代的一開始會將輸入數據轉換成底開銷的二進制形式,這樣可以為接下來的迭代消除解析文本數據的開銷,并且將數據存儲在 hdfs 實例的內存中。
* Spark:我們的 RDDs 的實現。
我們在 25-100 臺機器上存儲 100 G 數據,兩種算法都是對這 100 G 數據跑 10 次迭代。兩個應用之間的關鍵不同點是他們對相同數據的計算量不一樣。K-means 的迭代時間都是花在計算上,然而線性回歸是一個計算量不大,時間都是花在反序列化和 I/O 上。由于典型的機器學習算法都是需要上千次的迭代來達到收斂,所以我們將第一次迭代花的時間和接下來的迭代時間分開顯示。我們發現通過 RDDs 的共享數據極大的提高了后續的迭代速度
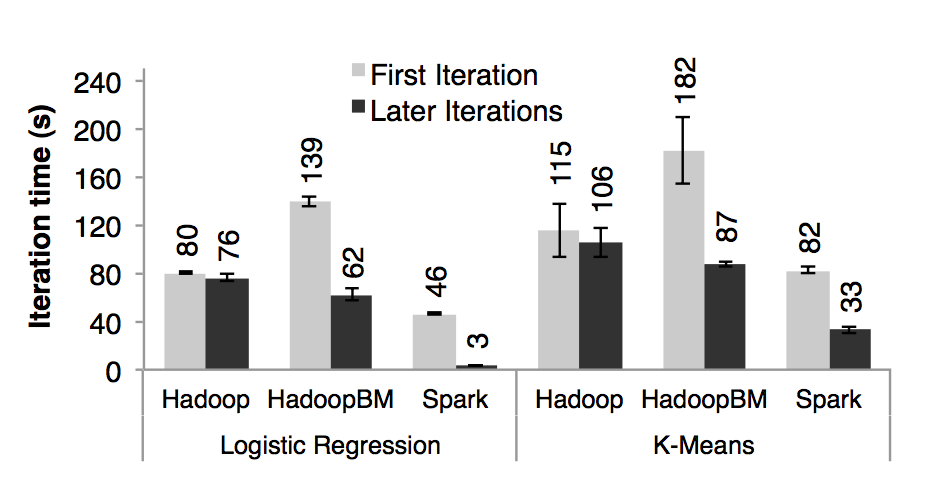 圖七:在 100 臺機器的集群上分別用 hadoop 、 hadoopBinMem 以及 spark 對 100 GB 的數據進行,線性回歸和 k - means 的首次迭代和隨后迭代花的時間
**首次迭代**:三個系統在首次迭代中都是讀取 HDFS 中的數據,從圖七的條形圖中我們可以看出,在實驗中,spark 穩定的比 hadoop 要快。這個是由于 hadoop 主從節點之間的心跳信息的信號開銷導致的。HadoopBinMen 是最慢的,這個是因為它啟動了一個額外的 MapReduce 任務來將數據轉換為二進制,它還需要通過網絡傳輸數據以達到備份內存中的數據的目的。**隨后的迭代**:圖七也顯示了隨后迭代花的平均時間。圖八則是顯示了集群大小不斷擴展時候的花的時間。對于線性回歸,在 100 臺機器上,spark 分別比 hadoop 和 hadoopBinMem 快上 25.3 倍和 20.7 倍。對于計算型的 k - means 應用,spark 仍然分別提高了 1.9 倍和 3.2 倍。
 圖八: hadoop 、 hadoopBinMem 以及 spark 在隨后的迭代花的時間,都是處理 100 G 的數據
**理解為什么提速了**:我們驚奇的發現 spark 甚至比基于內存存儲二進制數據的 hadoopBinMem 還要快 20 倍。在 hadoopBinMem 中,我們使用的是 hadoop 標準的二進制文件格式(sequenceFile)和 256 m 這么大的數據塊大小,以及我們強制將 hadoop 的數據目錄放在一個內存的文件系統中。然而,Hadoop 仍然因為下面幾點而比 spark 慢:
1. Hadoop 軟件棧的最低開銷。
2. HDFS 提供數據服務的開銷。
3. 將二進制數據轉換成有效的內存中的 java 對象的反序列化的成本開銷。
我們依次來調查上面的每一個因素。為了測量第一個因素,我們跑了一些空的 hadoop 任務,我們發現單單完成 job 的設置、任務的啟動以及任務的清理等工作就花掉了至少 25 秒鐘。對于第二個元素,我們發現 HDFS 需要執行多份內存數據的拷貝以及為每一個數據塊做 checksum 計算。
最后,為了測試第 3 個因素,我們在單機上做了一個微型的基準測試,就是針對不同文件類型的 256 M 數據來跑線性回歸計算。我們特別的對比了分別從 HDFS 文件(HDFS 技術棧的耗時將會很明顯)和本地內存文件(內核可以很高效的將數據傳輸給應用程序)中處理文本和二進制類型數據所話的時間、
圖九中是我們我們測試結果的展示。從 In - memory HDFS(數據是在本地機器中的內存中)中讀數據比從本地內存文件中讀數據要多花費 2 秒中。解析文本文件要比解析二進制文件多花費 7 秒鐘。最后,即使從本地內存文件中讀數據,但是將預先解析了二進制數據轉換成 java 對象也需要 3 秒鐘,這個對于線性回歸來說也是一個非常耗時的操作。Spark 將 RDDs 所有元素以 java 對象的形式存儲在內存中,進而避免了上述說的所有的耗時
### 6.2 PageRank
我們分別用 spark 和 hadoop 對 54 GB 的維基百科的轉儲數據進行了 PageRank 機器學習,并比對了它們的性能。我們用 PageRank 的算法處理了大約 4 百萬相互連接的文章,并進行了 10 次迭代。圖十展示了在 30 個節點上,只用內存存儲使的 spark 擁有了比 hadoop 2.4 倍的性能提升。另外,就和 3.2.2 小節討論的,如果控制 RDD 的分區使的迭代之間數據的平衡更可以使的性能速度提升到 7.2 倍。將節點數量擴展到 60 個,spark 的性能速度提升也是上面的結果
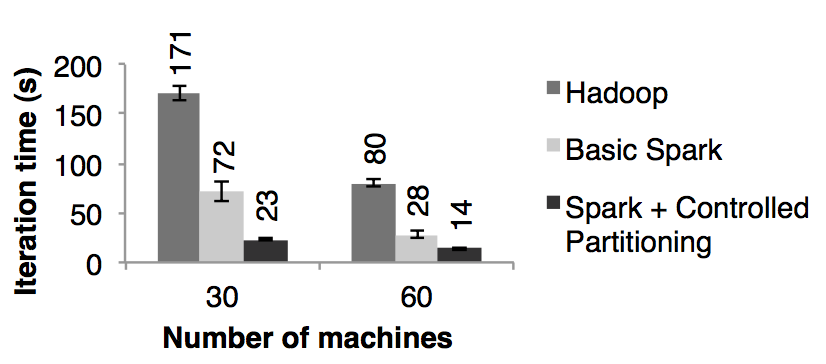 圖十:分別基于 Hadoop 和 spark 的 PageRank 的性能對比
我們也評估了在第 7.1 節中提到的用我們基于 spark 而實現的 Pregel 重寫的 PageRank。迭代次數和圖十是一樣的,但是慢了 4 秒鐘,這個是因為每一次迭代 Pregel 都要跑額外的操作來讓頂點進行投票決定是否需要結束任務。
### 6.3 容錯
我們評估了當在 k - means 應用中一個節點失敗了而利用 RDD 的血緣關系鏈來重建 RDD 的分區需要的成本。圖十一對比的是在 75 個節點中運行 10 次迭代的 k - means 正常情況和在第 6 次迭代一個節點失敗的情況。如果沒有任何失敗的話,每一次迭代都是在 100 GB 的數據上跑 400 個 tasks。
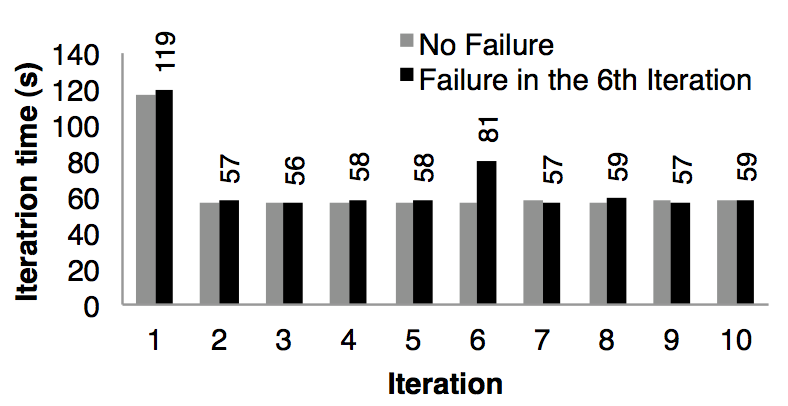 圖十一:出現了失敗的 k - means 每次迭代時間。在第 6 次迭代中一臺機器被殺掉了,導致需要利用血緣關系鏈重建 RDD 的部分分區
第五次迭代的時間是 58 秒。在第 6 次迭代,一臺機器被殺死了,導致丟失了運行在這臺機器上的 tasks 以及存儲在這臺機器上的 RDD 分區數據。Spark 在其他機器節點上重新讀取相應的輸入數據以及通過血緣關系來重建 RDD,然后并行的重跑丟失的 tasks,使的這次迭代的時間增加到 80s。一旦丟失的 RDD 分區數據重建好了,迭代的時間又回到了 58s。
需要注意的是,如果是基于 checkpoint 的容錯機制的話,那么需要通過重跑好幾個迭代才能恢復,需要重跑幾個取決于 checkpoints 的頻率。此外,系統需要通過網絡傳輸來備份應用需要的 100GB 數據(被轉化為二進制的文本數據),以及為了達到在內存中備份數據而消耗掉 2 倍的內存,或者等待將 100GB 數據寫入到磁盤中。與此相反的是,在我們的例子中每一個 RDDs 的血緣關系圖的大小都是小于 10KB 的。
### 6.4 內存不足的行為
在目前為止,我們都是假設集群中的每一臺機器都是有足夠的內存來存儲迭代之間的 RDDs 的數據的。當沒有足夠的內存來存儲任務的數據的時候 spark 是怎么運行的呢? 在這個實驗中,我們給 spark 每一個節點配置很少的內存,這些內存不足以存儲的下 RDDs。我們在圖十二中,我們展示了不同存儲空間下的運行線性回歸應用需要的時間。可以看出,隨著空間的減少,性能速度慢慢的下降:
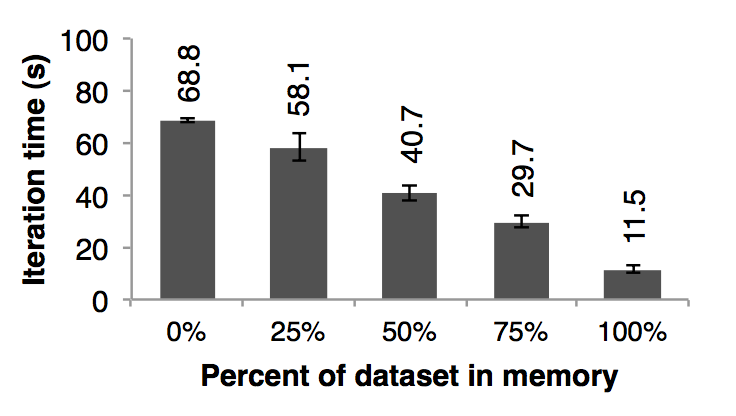 圖十二:每次都是使用不同的內存,然后在 25 臺機器中對 100 GB 的數據運行線性回歸的性能對比圖
### 6.5 用 spark 構建的用戶應用
**內存中分析**: Conviva Inc 是一個視頻提供商,他們用 spark 來加速之前在 hadoop 上運行的幾個數據報表分析。比如,其中一個報表是運行一系列的 Hive 查詢來計算一個用戶的各種統計信息。這些查詢都是基于相同的數據子集(基于自定義的過濾器過濾出來的數據)但是需要很多 MapReduce 任務來為分組字段進行聚合運算(平均值、百分位數值以及 count distinct)。將這些數據子集創建成一個可以共享的 spark 中的 RDD 來實現這些查詢使的這個報表的速度提升了 40 倍。對 200 GB 已經壓縮的數據在 hadoop 集群上跑這個報表花了 20 個小時,但是利用 2 臺機器的 spark 只用了 30 分鐘而已。此外,spark 程序只花了 96 G 的內存,因為只需要將報表關心的列數據存儲在內存中進行共享就行,而不是所有的解壓后的數據。
**交通模型**:伯克利分校的 Mobile Millennium 項目組的研究員在收集到的零星的汽車的 GPS 信息上并行運行一個機器學習算法試圖推斷出道路交通是否擁擠。在都市區域道路網絡中的 10000 條道路和 600000 個裝有 GPS 設備的汽車點對點的旅行時間(每一條路線的旅行時間可能包含了多條道路)樣本是數據源。利用交通模型可以估算出通過每一條獨立的道路需要多長時間。研究人員利用 EM 算法來訓練模型,這個算法在迭代的過程中重復執行 map 和 reduceByKey 步驟。這個應用近似線性的將機器規模從 20 臺擴展到 80 臺,每臺機器 4 個 cores,如圖 13(a)所示。
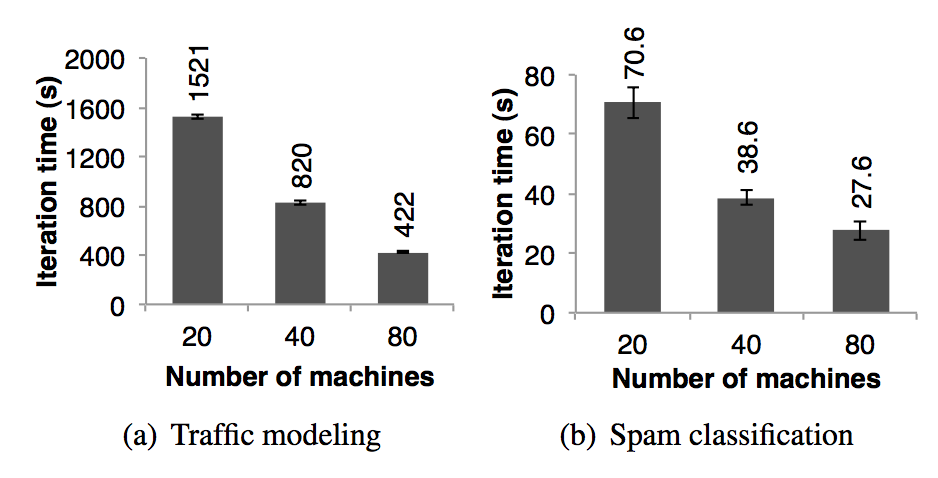 圖十三:兩個用 spark 實現的用戶應用的每次迭代的時間,誤差線表示標準誤差
**推特垃圾郵件分類**:伯克利分校的 Monarch 項目利用 spark 來標記推特消息中的垃圾鏈接。它們實現的線性回歸分類器和第 6.1 節中很相似,但是他們利用了分布式的 reduceByKey 來并行的累加梯度向量值。圖 13(b) 中顯示了對 50 GB 的數據子集進行分類訓練需要的時間(隨著機器擴展),這個數據子集中包含了 25000 URLs 以及每一個 url 對應的頁面的網絡和內容屬性相關的 10000000 個特征/緯度。圖 13(b) 中的時間不是線性的下降是因為每一次迭代花費了很高的且固定的通訊成本。
### 6.6 交互性的數據挖掘
為了演示 spark 在交互查詢大數據集的能力,我們來分析 1 TB 的維基頁面訪問日志數據(2 年的數據)。在這個實驗中,我們使用 100 個 m 2.4 xlarge EC 2 實例,每一個實例 8 個 cores 以及 68 G 內存。我們查詢出(1)所有頁面的瀏覽量,(2)頁面標題等于某個單詞的頁面的瀏覽量以及(3)頁面標題部分的等于某個單詞的頁面的瀏覽量。每一個查詢都是掃描整個輸入數據集。
圖十四展示的分別是查詢整個數據集、一半數據集一集十分之一的數據集的響應時間。即使是 1 TB 的數據,用 spark 來查詢僅僅花了 5-7 秒而已。這個比查詢磁盤數據的速度快了一個數量級,比如,查詢磁盤文件中的 1 TB 數據需要 170 秒。這個可以說明 RDDs 使的 spark 是一個非常強大的交互型數據挖掘的工具。
## 7 討論
雖然由于 RDDs 的天然不可變性以及粗粒度的轉換導致它們似乎提供了有限制的編程接口,但是我們發現它們適合很多類型的應用。特別的,RDDs 可以表達出現在各種各樣的框架提出的編程模型,而且還可以將這些模型組合在同一個程序中(比如跑一個 MapReduce 任務來創建一個圖,然后基于這個圖來運行 Pregel)以及可以在這些模型中共享數據。在這一章中,我們在第 7.1 節中討論 RDDs 可以表達哪些模型以及為什么適合表達這些編程模型。另外,我們在第 7.2 節中討論我們推崇的 RDD 的血緣信息的好處,利用這些信息可以幫助我們 debug 模型。
### 7.1 已經存在的編程模型的表達
對于到目前為止很多獨立提出的編程模型,RDDs 都可以高效的表達出來。這里所說的 “高效”,不僅僅是指使用 RDDs 的輸出結果和獨立提出的編程模型狂簡的輸出結果是一致的,而且 RDDs 在優化性能方面比這些框架還要強大,比如將特定的數據保存在內存中、對數據分區以減少網絡傳輸以及高效的從錯誤中恢復。可以用 RDDs 表達的模型如下:
* MapReduce:可以利用 spark 中的 flatMap 和 groupByKey 操作來表達這個模型,或者如果需要聚合的話可以使用 reduceByKey。
* DryadLINQ:DryadLINQ 系統比 MapReduce 更多的操作,但是這些操作都是直接和 RDD 的轉換操作(map,groupByKey,join 等)對應的批量操作。
* SQL:和 DryadLINQ 一樣,SQL 查詢都是對一個數據集進行并行的操作計算。
* Pregel:Google 的 Pregel 是一個專門解決迭代圖計算應用的模型,它一開始看起來和面向數據集的編程模型的其他系統完全不同。在 Pregel 中,一個程序運行一些列的相互協調的“ supersteps ”。在每一個 superstep 上,對圖上的每一個頂點運行用戶自定義的函數來更新這個頂點的相關的狀態、改變圖的拓撲結構以及向其他頂點發送下一個 superstep 需要的消息。這種模型可以表達非常多的圖計算算法,包括最短路徑、二部圖匹配以及 PageRank。
Pregel 在每一次迭代中都是對所有頂點應用相同的用戶定義的函數,這個是使的我們用 RDDs 來實現這個模型的關鍵點。因此,每次迭代后,我們都可以將頂點的狀態保存在 RDD 中,然后執行一個批量轉換操作(apply)來應用這個函數以及生成一個消息的 RDD。然后我們可以用這個 RDD 通頂點的狀態進行 join 來完成消息的交換。和 Pregel 一樣,RDDs 允許將點的狀態保存在內存中、控制它們的分區以減少網絡通訊以及指出從失敗中恢復。我們在 spark 上用了 200 行代碼的包實現了 Pregel,讀者可以參考第 33 個文獻來了解更多的細節
* 迭代 MapReduce:最近提出的幾個系統,包括 HaLoop 和 Twister,它們提供了可以讓用戶循環跑一系列的 MapReduce 任務的迭代式 MapReduce 模型。這些系統在迭代之間保持數據分區一致,Twister 也可以將數據保存在內存中。RDDs 可以很簡單的表達以上兩個優化,而且我們基于 spark 花了 200 行代碼實現了 HaLoop。
* 批量流處理: 研究人員最近提出了一些增量處理系統,這些系統是為定期接受新數據然后根據數據更新結果的應用服務的。比如,一個應用需要實時接收新數據,然后每 15 分鐘就將接收到的數據和前面 15 分鐘的時間窗口的數據進行 join 聚合,將聚合的結果更新到統計數據中。這些系統執行和 Dryad 類似的批處理,但是它們將應用的狀態數據存儲在分布式系統中。將中間結果放在 RDDs 中可以提高處理速度。
* 闡釋 RDDs 的表達力為什么這么豐富:為什么 RDDs 可以表達多種多樣編程模型?原因就是 RDDs 的限制性對很多并行計算的應用的影響是很小的。特別指出的是,雖然 RDDs 只能通過批量轉換而得到,但是很多的并行計算的程序都是將相同的操作應用到大量的數據條目中,這樣使的 RDDs 的表達力變的豐富。類似的,RDDs 的不變性并不是障礙,因為我們可以創建多個 RDDs 來表達不同版本的相同數據集。事實上,現在很多的 MapReduce 的應用都是運行在不能對文件修改數據的文件系統中,比如 HDFS。
最后一個問題是為什么之前的框架沒有提供這中通用型的表達能力呢? 我們相信這個是因為這些框架解決的是 MapReduce 和 Dryad 不能解決的特殊性的問題,比如迭代,它們沒有洞察到這些問題的共同原因是因為缺少了數據共享的抽象。
### 7.2 利用 RDDs 來 debug
當我們一開始設計 RDDs 通過重新計算來達到容錯的時候,這種特性同時也促使了 debugging 的產生。特別的,在一個任務中通過記錄 RDDs 的創建的血緣,我們可以:
1. 后面可以重新構建這些 RDDs 以及可以讓用戶交互性的查詢它們。
2. 通過重新計算其依賴的 RDD 分區來達到在一個進程 debugger 中重跑任何的任務。
和傳統的通用分布式系統的重跑 debugger 不一樣,傳統的需要捕獲和引用多個節點之間的事件發生的順序,RDDs 這種 debugger 方式不需要依賴任何的數據,而只是需要記錄 RDD 的血緣關系圖。我們目前正在基于這些想法來開發一個 spark debbger。
## 8 相關工作
**集群編程模型**:集群編程模型的相關工作分為以下幾類:
* 第一,像 MapReduce,Dryad 以及 Ciel 一樣支持一系列處理數據的操作,并且需要通過穩定的存儲系統來共享數據,RDDs 表達了一種比穩定存儲系統更高效的數據共享抽象,因為它避免了數據備份、 I / O 以及序列化的成本。
* 第二,幾個數據流系統的高層面上的編程接口,包括 DryadLINQ 和 FlumeJava ,它們提供了語言集成 api,使的用戶可以通過像 map 和 join 等操作來操作并行的集合。然而,在這些系統中,并行的集合是指在磁盤上的文件或者一個查詢計劃表達的臨時數據集。雖然這些系統在相同的查詢中的操作之間組裝數據的 pipeline(比如,一個 map 操作后跟另外一個 map),但是它們不能在查詢之間進行高效的數據共享。我們在并行集合模式上建立 spark api,是由于它的便利性以及在集成語言接口上不要求新穎性,但是我們基于在這些接口背后以 RDDs 作為存儲抽象,就可以使的 spark 支持大量類型的應用了。
* 第三種系統為許多專門的需要數據共享的應用提供了高層的接口。比如,pregel 支持迭代式的圖計算應用、 Twister 和 HaLoop 支持迭代式的 MapReduce。然而,這些框架只是為他們支持的計算模型隱式的共享數據,并沒有提供可以讓用戶根據自己的需求顯式的共享數據的通用抽象。比如,一個用戶不能用 Pregel 或者 Twister 將數據加載到內存中然后決定在數據集上面跑什么樣的查詢。RDDs 提供了一個顯式的分布式存儲抽象,因此可以支持那些特殊系統不能支持的應用,比如交互式數據挖掘。
最后,一些系統暴露共享可變狀態以使的用戶可以執行內存計算。比如,Piccolo 使的用戶通過分布式的函數來讀取和更新分布式 hash 表中的單元格數據。DSM 和像 RAMCloud 這樣的 key - value 存儲系統提供了類似的模型。RDDs 和這些系統有兩個方面的不同,第一,RDDs 基于像 map,sot 以及 join 等操作提供了高層的編程接口,然而,在 Piccolo 和 DSM 中的接口只是讀取和更新表的單元格數據。第二,Piccolo 和 DSM 通過 checkpoint 和回滾機制實現容錯,在許多應用中這種機制比機遇血緣機制的 RDDs 的容錯的成本更大。最后,如 2.3 小節討論的,相對于 DSM,RDDs 還提供了其他的優勢功能,比如執行慢的 task 的處理機制
**緩存系統**:Nectar 可以通過標識通用的程序分析的子表達式來達到在 DryadLINQ 任務之間對中間數據結果的復用。這種能力肯定會加入到基于 RDD 的系統中。然而,Nectar 即沒有提供基于內存的緩存(他是將數據放到分布式文件系統中)也不能讓用戶可以顯式的對數據集進行緩存控制和分區控制。Ciel 和 FlumeJava 同樣可以緩存任務結果,但是也不提供基于內存的緩存或者顯式的控制哪些數據可以緩存
Ananthanarayanan et al 已經提出在分布式文件系統上加一層基于內存的緩存來利用數據訪問的暫時性和本地性。這種解決方案卻是加快了已經存在于文件系統中的數據訪問速度,但是它在共享同一個應用中的中間結果方面并沒有 RDD 高效,因為它在每一個 stage 之間仍然需要將數據寫入到文件系統中
**血緣**:在科學計算以及數據庫中,捕獲數據的血緣或者來源信息是一個很長時間被研究的話題了,對于像解釋結果的應用,需要讓他們可以從其他的應用重新產生,且當在工作流中存在一個 bug 或者數據丟失的時候可以重新對數據進行計算。對于這邊面的容錯的工作,我們推薦讀者看第 [5] 和 [9]的資料。RDDs 提供了一種并行編程模型,記錄跟蹤細粒度的血緣的成本很低,我們可以根據血緣來達到容錯的目的。
我們基于血緣的容錯機制和 MapReduce 以及 Dryad 一個任務中的容錯機制是類似的,在 DAG 中跟蹤任務的依賴。然而,在這些系統中,一個任務結束后血緣信息也就丟失了,用戶需要依靠數據備份式的存儲系統來共享任務之間的數據。與此相反,RDDs 可以在任務之間通過將數據存儲在內存中達到高效的數據共享,并不需要數據的備份和磁盤的 I/O 關系型數據庫:RDDs 在概念上和數據庫中的視圖比較類似,存儲的 RDDs 則像具體的視圖。然而,像 DSM 系統,數據庫一般允許細粒度的對所有的數據進行讀寫訪問,這種方式需要對操作和數據進行記錄日志,用于容錯,以及需要額外的開銷來保持數據的一致性,對于粗粒度轉換模型的 RDDs 來說,這些額外的開銷式不需要的。
## 9 結尾
我們已經展示了在集群應用中一個高效的,通用的以及容錯的對共享數據的抽象的 RDDs。RDDs 可以表達大量的并行應用,包括特殊的編程模型提出的迭代式計算以及這些模型表達不了的新的應用。和已經存在的對集群存儲抽象不同的是,RDDs 提供了基于粗粒度轉換的 api,可以使的用戶通過血緣達到高效的容錯。我們在 spark 系統中實現了 RDDs,在迭代式的應用中,性能是 hadoop 的 20 倍,并且可以用于交互式的查詢數百 GB 的數據。
我們已經在 spark-project.org 中開源了 Spark,作為一個穩定的數據分析和系統研究的手段。
## 鳴謝
We thank the first Spark users, including Tim Hunter, Lester Mackey, Dilip Joseph, and Jibin Zhan, for trying out our system in their real applications, providing many good suggestions, and identifying a few research challenges along the way. We also thank our shepherd, Ed Nightingale, and our reviewers for their feedback. This research was supported in part by Berkeley AMP Lab sponsors Google, SAP, Amazon Web Services, Cloudera, Huawei, IBM, Intel, Microsoft, NEC, NetApp and VMWare, by DARPA (contract #FA8650-11-C-7136), by a Google PhD Fellowship, and by the Natural Sciences and Engineering Research Council of Canada.
## 引用資料
[1] ApacheHive.http://hadoop.apache.org/hive.
[2] Scala.http://www.scala-lang.org.
[3] G.Ananthanarayanan,A.Ghodsi,S.Shenker,andI.Stoica. Disk-locality in datacenter computing considered irrelevant. In HotOS ’11, 2011.
[4] P.Bhatotia,A.Wieder,R.Rodrigues,U.A.Acar,and R. Pasquin. Incoop: MapReduce for incremental computations. In ACM SOCC ’11, 2011.
[5] R.BoseandJ.Frew.Lineageretrievalforscientificdata processing: a survey. ACM Computing Surveys, 37:1–28, 2005.
[6] S.BrinandL.Page.Theanatomyofalarge-scalehypertextual web search engine. In WWW, 1998.
[7] Y.Bu,B.Howe,M.Balazinska,andM.D.Ernst.HaLoop: efficient iterative data processing on large clusters. Proc. VLDB Endow., 3:285–296, September 2010.
[8] C.Chambers,A.Raniwala,F.Perry,S.Adams,R.R.Henry, R. Bradshaw, and N. Weizenbaum. FlumeJava: easy, efficient data-parallel pipelines. In PLDI ’10\. ACM, 2010.
[9] J.Cheney,L.Chiticariu,andW.-C.Tan.Provenancein databases: Why, how, and where. Foundations and Trends in Databases, 1(4):379–474, 2009.
[10] J.DeanandS.Ghemawat.MapReduce:Simplifieddata processing on large clusters. In OSDI, 2004.
[11] J. Ekanayake, H. Li, B. Zhang, T. Gunarathne, S.-H. Bae, J. Qiu, and G. Fox. Twister: a runtime for iterative mapreduce. In HPDC ’10, 2010.
[12] P.K.Gunda,L.Ravindranath,C.A.Thekkath,Y.Yu,and L. Zhuang. Nectar: automatic management of data and computation in datacenters. In OSDI ’10, 2010.
[13] Z.Guo,X.Wang,J.Tang,X.Liu,Z.Xu,M.Wu,M.F. Kaashoek, and Z. Zhang. R2: an application-level kernel for record and replay. OSDI’08, 2008.
[14] T.Hastie,R.Tibshirani,andJ.Friedman.TheElementsof Statistical Learning: Data Mining, Inference, and Prediction. Springer Publishing Company, New York, NY, 2009.
[15] B.He,M.Yang,Z.Guo,R.Chen,B.Su,W.Lin,andL.Zhou. Comet: batched stream processing for data intensive distributed computing. In SoCC ’10.
[16] A.Heydon,R.Levin,andY.Yu.Cachingfunctioncallsusing precise dependencies. In ACM SIGPLAN Notices, pages 311–320, 2000.
[17] B.Hindman,A.Konwinski,M.Zaharia,A.Ghodsi,A.D. Joseph, R. H. Katz, S. Shenker, and I. Stoica. Mesos: A platform for fine-grained resource sharing in the data center. In NSDI ’11.
[18] T.Hunter,T.Moldovan,M.Zaharia,S.Merzgui,J.Ma,M.J. Franklin, P. Abbeel, and A. M. Bayen. Scaling the Mobile Millennium system in the cloud. In SOCC ’11, 2011.
[19] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: distributed data-parallel programs from sequential building blocks. In EuroSys ’07, 2007\.
[20] S.Y.Ko,I.Hoque,B.Cho,andI.Gupta.Onavailabilityof intermediate data in cloud computations. In HotOS ’09, 2009.
[21] D. Logothetis, C. Olston, B. Reed, K. C. Webb, and K. Yocum. Stateful bulk processing for incremental analytics. SoCC ’10.
[22] G.Malewicz,M.H.Austern,A.J.Bik,J.C.Dehnert,I.Horn, N. Leiser, and G. Czajkowski. Pregel: a system for large-scale graph processing. In SIGMOD, 2010.
[23] D.G.Murray,M.Schwarzkopf,C.Smowton,S.Smith, A. Madhavapeddy, and S. Hand. Ciel: a universal execution engine for distributed data-flow computing. In NSDI, 2011.
[24] B.NitzbergandV.Lo.Distributedsharedmemory:asurveyof issues and algorithms. Computer, 24(8):52 –60, Aug 1991.
[25] J.Ousterhout,P.Agrawal,D.Erickson,C.Kozyrakis, J. Leverich, D. Mazie\`res, S. Mitra, A. Narayanan, G. Parulkar, M. Rosenblum, S. M. Rumble, E. Stratmann, and R. Stutsman. The case for RAMClouds: scalable high-performance storage entirely in DRAM. SIGOPS Op. Sys. Rev., 43:92–105, Jan 2010\.
[26] D.PengandF.Dabek.Large-scaleincrementalprocessingusing distributed transactions and notifications. In OSDI 2010.
[27] R.PowerandJ.Li.Piccolo:Buildingfast,distributedprograms with partitioned tables. In Proc. OSDI 2010, 2010.
[28] R.RamakrishnanandJ.Gehrke.DatabaseManagement Systems. McGraw-Hill, Inc., 3 edition, 2003.
[29] K.Thomas,C.Grier,J.Ma,V.Paxson,andD.Song.Designand evaluation of a real-time URL spam filtering service. In IEEE Symposium on Security and Privacy, 2011\.
[30] J.W.Young.Afirstorderapproximationtotheoptimum checkpoint interval. Commun. ACM, 17:530–531, Sept 1974.
[31] Y.Yu,M.Isard,D.Fetterly,M.Budiu,U ?.Erlingsson,P.K. Gunda, and J. Currey. DryadLINQ: A system for general-purpose distributed data-parallel computing using a high-level language. In OSDI ’08, 2008.
[32] M.Zaharia,D.Borthakur,J.SenSarma,K.Elmeleegy,S. Shenker, and I. Stoica. Delay scheduling: A simple technique for achieving locality and fairness in cluster scheduling. In EuroSys ’10, 2010.
[33] M.Zaharia,M.Chowdhury,T.Das,A.Dave,J.Ma,M. McCauley, M. Franklin, S. Shenker, and I. Stoica. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. Technical Report UCB/EECS-2011-82, EECS Department, UC Berkeley, 2011.
## 原文鏈接
[http://people.csail.mit.edu/matei/papers/2012/nsdi_spark.pdf](http://people.csail.mit.edu/matei/papers/2012/nsdi_spark.pdf)
## 貢獻者
* [@老湯](http://edu.51cto.com/course/10932.html)(老湯)
* [@wangyangting](https://github.com/wangyangting)(那伊抹微笑)
- Spark 概述
- 編程指南
- 快速入門
- Spark 編程指南
- 構建在 Spark 之上的模塊
- Spark Streaming 編程指南
- Spark SQL, DataFrames and Datasets Guide
- MLlib
- GraphX Programming Guide
- API 文檔
- 部署指南
- 集群模式概述
- Submitting Applications
- 部署模式
- Spark Standalone Mode
- 在 Mesos 上運行 Spark
- Running Spark on YARN
- 其它
- 更多
- Spark 配置
- Monitoring and Instrumentation
- Tuning Spark
- 作業調度
- Spark 安全
- 硬件配置
- Accessing OpenStack Swift from Spark
- 構建 Spark
- 其它
- 外部資源
- Spark RDD(Resilient Distributed Datasets)論文
- 翻譯進度