## Spark Streaming

### 特點
* 高容錯、高吞吐。
* 支持批處理、機器學習、圖計算。
* 集群。
### 生態環境
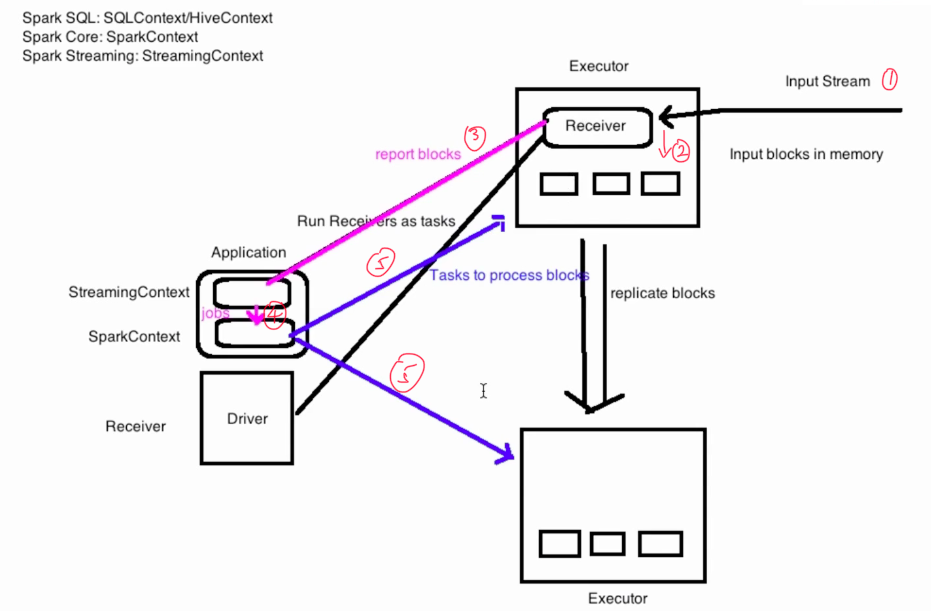
### 工作原理(粗粒度)
### Spark Streaming
~~~scala
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//間隔一秒
val ssc = new StreamingContext(conf, Seconds(1))
~~~
**After a context is defined, you have to do the following.**
1. Define the input sources by creating input DStreams.
2. Define the streaming computations by applying transformation and output operations to DStreams.
3. Start receiving data and processing it using `streamingContext.start()`.
4. Wait for the processing to be stopped (manually or due to any error) using `streamingContext.awaitTermination()`.
5. The processing can be manually stopped using `streamingContext.stop()`.
**注意點:**
* Once a context has been started, no new streaming computations can be set up or added to it.
* Once a context has been stopped, it cannot be restarted.
* Only one StreamingContext can be active in a JVM at the same time.
* stop() on StreamingContext also stops the SparkContext. To stop only the StreamingContext, set the optional parameter of `stop()` called `stopSparkContext` to false.
* A SparkContext can be re-used to create multiple StreamingContexts, as long as the previous StreamingContext is stopped (without stopping the SparkContext) before the next StreamingContext is created.
### DStream
* 是持續的數據流。
* 一系列的RDD。
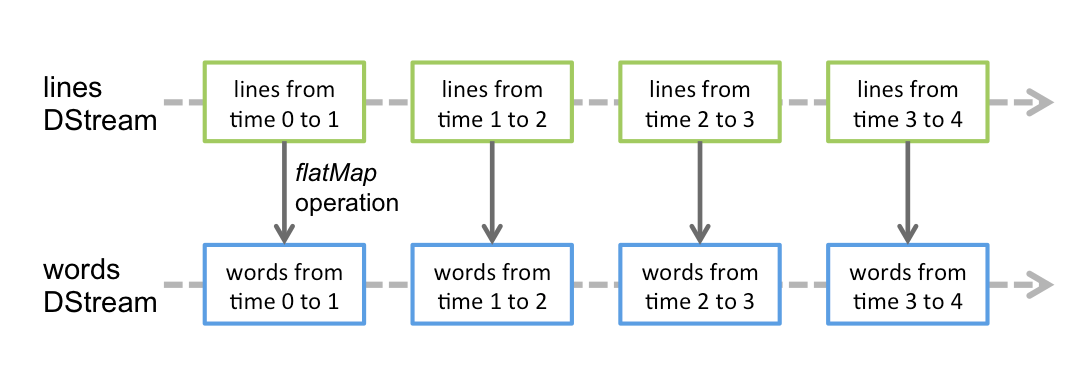
**flatMap**
* 會對每個RDD做相同的操作。
### Input DStream 和 Receiver
* Input DStream 是接受數據的DStream。
* 每一個Input DStream都需要Receiver(除了文件系統)。
* 有Receiver的Input DStream不能使用local[1],因為一個線程是不夠的。
## Transformations on DStreams[](http://spark.apache.org/docs/latest/streaming-programming-guide.html#transformations-on-dstreams)
Similar to that of RDDs, transformations allow the data from the input DStream to be modified. DStreams support many of the transformations available on normal Spark RDD’s. Some of the common ones are as follows.
| Transformation | Meaning |
| --- | --- |
| **map**(*func*) | Return a new DStream by passing each element of the source DStream through a function *func*. |
| **flatMap**(*func*) | Similar to map, but each input item can be mapped to 0 or more output items. |
| **filter**(*func*) | Return a new DStream by selecting only the records of the source DStream on which *func* returns true. |
| **repartition**(*numPartitions*) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| **union**(*otherStream*) | Return a new DStream that contains the union of the elements in the source DStream and *otherDStream*. |
| **count**() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| **reduce**(*func*) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function *func* (which takes two arguments and returns one). The function should be associative and commutative so that it can be computed in parallel. |
| **countByValue**() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| **reduceByKey**(*func*, \[*numTasks*\]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. **Note:** By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property `spark.default.parallelism`) to do the grouping. You can pass an optional `numTasks` argument to set a different number of tasks. |
| **join**(*otherStream*, \[*numTasks*\]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| **cogroup**(*otherStream*, \[*numTasks*\]) | When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq\[V\], Seq\[W\]) tuples. |
| **transform**(*func*) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| **updateStateByKey**(*func*) | Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
A few of these transformations are worth discussing in more detail.
