# 4語法和基本數據類型
> by [九月](https://i.getshell.cn/)
[TOC]
## 4.1語法
本節討論了對于任一版本的CSS(包括CSS2.2)都相同的語法(及向下兼容的解析規則)。CSS以后的版本將保持這一核心語法,盡管它們可以加入額外的語法限制。
這些描述是標準化的。在[附錄 G](https://www.w3.org/TR/CSS22/grammar.html)中的語法規則是它們的補充和完善。
在本說明書中,表述“緊接之前”或“之后立即”表示沒有中間空白或注釋。
### 4.1.1標識化
CSS的所有級別——級別1,級別2以及將來的級別——都使用相同的核心語法。這就可以讓用戶端解析(盡管不是完全理解)樣式表,而這些樣式表可能是以用戶端出現時還沒有的CSS級別寫成的。設計者以此來創建可以在老的用戶端上工作的樣式表,同時又保持使用最新級別的CSS。
在詞匯級別,CSS樣式表包含一系列的表征。CSS2的表征見下表所列。定義采用Lex樣式規范表達式。八進制數參見ISO 10646([[ISO10646]](https://www.w3.org/TR/CSS22/refs.html#ref-ISO10646))。在Lex中,如果出現多重匹配,則最長的那個匹配決定了表征。
~~~
標識 語義
IDENT {ident}
ATKEYWORD @{ident}
STRING {string}
BAD_STRING {badstring}
BAD_URI {baduri}
BAD_COMMENT {badcomment}
HASH #{name}
NUMBER {num}
PERCENTAGE {num}%
DIMENSION {num}{ident}
URI {U}{R}{L}\({w}{string}{w}\)|
{U}{R}{L}\({w}([!#$%&*-\[\]-~]|{nonascii}|{escape})*{w}\)
UNICODE-RANGE u\+[?]{1,6}|
u\+[0-9a-f]{1}[?]{0,5}|
u\+[0-9a-f]{2}[?]{0,4}|
u\+[0-9a-f]{3}[?]{0,3}|
u\+[0-9a-f]{4}[?]{0,2}|
u\+[0-9a-f]{5}[?]{0,1}|
u\+[0-9a-f]{6}|
u\+[0-9a-f]{1,6}-[0-9a-f]{1,6}
CDO <!--
CDC -->
: :
; ;
{ \{
} \}
( \(
) \)
[ \[
] \]
S [ \t\r\n\f]+
COMMENT \/\*[^*]*\*+([^/*][^*]*\*+)*\/
FUNCTION {ident}\(
INCLUDES ~=
DASHMATCH |=
DELIM any other character not matched by the above rules, and neither a single nor a double quote
~~~
上述包含在花括號({})中的宏的定義如下:
~~~
宏 定義
ident {nmstart}{nmchar}*
name {nmchar}+
nmstart [a-zA-Z]|{nonascii}|{escape}
nonascii [^\0-\177]
unicode \\[0-9a-f]{1,6}[ \n\r\t\f]?
escape {unicode}|\\[ -~\200-\4177777]
nmchar [a-z0-9-]|{nonascii}|{escape}
num [0-9]+|[0-9]*\.[0-9]+
string {string1}|{string2}
string1 \"([\t !#$%&(-~]|\\{nl}|\'|{nonascii}|{escape})*\"
string2 \'([\t !#$%&(-~]|\\{nl}|\"|{nonascii}|{escape})*\'
nl \n|\r\n|\r|\f
w [ \t\r\n\f]*
~~~
以下是CSS的核心語法。 以下各節介紹如何使用它。 附錄G描述了更接近CSS級別2語言的更嚴格的語法。 根據此語法可以解析的樣式表部分,但不能根據[附錄G](https://www.w3.org/TR/CSS22/grammar.html)中的語法解析的部分將根據處理解析[錯誤的規則](https://www.w3.org/TR/CSS22/syndata.html#parsing-errors)被忽略。
~~~
stylesheet : [ CDO | CDC | S | statement ]*;
statement : ruleset | at-rule;
at-rule : ATKEYWORD S* any* [ block | ';' S* ];
block : '{' S* [ any | block | ATKEYWORD S* | ';' S* ]* '}' S*;
ruleset : selector? '{' S* declaration-list '}' S*;
declaration-list: declaration [ ';' S* declaration-list ]?
| at-rule declaration-list
| /* empty */;
selector : any+;
declaration : property S* ':' S* value;
property : IDENT;
value : [ any | block | ATKEYWORD S* ]+;
any : [ IDENT | NUMBER | PERCENTAGE | DIMENSION | STRING
| DELIM | URI | HASH | UNICODE-RANGE | INCLUDES
| DASHMATCH | ':' | FUNCTION S* [any|unused]* ')'
| '(' S* [any|unused]* ')' | '[' S* [any|unused]* ']'
] S*;
unused : block | ATKEYWORD S* | ';' S* | CDO S* | CDC S*;
~~~
“unuse”的用法不在CSS中使用,也不會被任何未來的擴展使用。 它僅包含在這里以幫助處理錯誤。 (請參閱4.2“處理分析錯誤的規則”。)
注釋的特征不在語法中出現(為了使語法更容易讀)。不過,任意數目的這些特征可以出現在其它特征的任何地方。
上述語法中的S表征表示空白。只有字符“空格”(Unicode編碼32),“制表符”(9),“換行”(10),“回車”(13)以及“換頁”(12)可以出現在空白中。其它類似空格的字符,如“em-space”(8195)和“表意空格”(12288)肯定不是空白的一部分。
### 4.1.2 關鍵字
關鍵字以標識符的形式出現。關鍵字不可以放置在引號("..."或'...')之間。因此,
red
是一個關鍵字,而
"red"
則不是。(它是一個字符串。)其它不合法的例子如:
~~~
width: "auto";
border: "none";
background: "red";
~~~
#### 4.1.2.1 瀏覽器廠商特定擴展
在CSS中,標示符可以以'-' (劃線) 或 '_' (下劃線)開始。關鍵詞或屬性名以'-'或'_'開始的保留給各種瀏覽器擴展使用。下面是CSS瀏覽器廠商特定擴展(Vendor-specific extensions)的公式:
~~~
-瀏覽器廠商標示符-名稱
_瀏覽器廠商標示符_名稱
~~~
例如,如果XYZ組織添加了一個屬性來描述顯示屏東側的邊框顏色,則可以將其稱為-xyz-border-east-color。
~~~
-moz-box-sizing
-moz-border-radius
-wap-accesskey
~~~
我們要保證短劃線或下劃線不會被任何當前或未來級別的CSS用于屬性或關鍵字。 因此,典型的CSS實現可能無法識別這些屬性,并可能根據處理解析錯誤的規則忽略它們。 但是,由于最初的短劃線或下劃線是語法的一部分,CSS 2.2實現者應始終能夠使用符合CSS的解析器,而不管它們是否支持任何特定于供應商的擴展。
作者應該避免瀏覽器廠商特定擴展
#### 4.1.2.2歷史記錄
在撰寫本文時,已知存在以下前綴:
| 前綴| 組織 |
| --- | --- |
| -ms-, mso- | Microsoft |
| -moz- | Mozilla |
| -o-, -xv- | Opera Software |
| -atsc- | Advanced Television Standards Committee |
| -wap- | The WAP Forum |
| -khtml- | KDE |
| -webkit- | Apple |
| prince- | YesLogic |
| -ah- | Antenna House |
| -hp- | Hewlett Packard |
| -ro- | Real Objects |
| -rim- | Research In Motion |
| -tc- | TallComponents |
### 4.1.3 字符和大小寫
下面的規則總是有效:
* 所有CSS樣式表都是大小寫不敏感,除了不在CSS控制之下的那些部分。例如,HTML屬性“id”和“class”的值的大小寫敏感性,字體名稱,及URI內容,這些都在本規范討論范圍之外。特別注意,在HTML中元素名稱與大小寫無關,而在XML中是大小寫敏感的。
* CSS中,標識符(包括[選擇器](https://www.w3.org/TR/CSS22/selector.html)中的元素名,類和ID)只能包含字符[A-Za-z0-9]以及ISO 10646字符編號161及以上,加上連字號(-);它們不能以連字號或數字開頭。它們還可以包含轉義字符加任何ISO 10646字符作為一個數字編碼(見下一條)。例如,標識符"B&W?"可以寫成"B\&W\?"或"B\26 W\3F"。
注意,Unicode和ISO 10646是碼碼對應的(參見[[UNICODE]](https://www.w3.org/TR/CSS22/refs.html#ref-UNICODE)及[[ISO10646]](https://www.w3.org/TR/CSS22/refs.html#ref-ISO10646))。
* CSS2.2中,反斜杠(\)字符表示三種類型的字符轉義。
首先,在字符串中,反斜杠后接一個新行將被忽略(即,好象字符串既不包含反斜杠,也不包含新行)。
第二,它取消了特殊的CSS字符的含義。任何字符(除了十六進制數)都可以由反斜杠轉義而消除了它本來的含義。例如,"\""是一個包含雙引號的字符串。樣式表的處理器不可以在樣式表中去除這些反斜杠,否則會改變樣式表的含義。
第三,反斜杠轉義允許作者引用在文檔中不易輸入的字符。在這種情況下,反斜杠后接最長為六位的十六進制數(0..9A..F),表示ISO 10646([ISO10646])中對應于該數值的字符。 如果在十六進制數后跟著數字或字母,那么該十六進制數的結束要標記清楚。有兩個方法可以做到:
帶一個空格(或其它空白字符):"\26 B" ("&B")
補足十六進制數到六位:"\000026B" ("&B")
事實上,這兩個方法可以結合起來。在十六進制后只忽略一個空白字符。這就意味著轉義之后的真正的空白必須轉義或重復一次。
* 反斜杠轉義總是被認為是標識符或字符串的一部分(即,"\7B"不是一個標點符號,而"{"則是。"\32"可以用作類名的開頭,而"2"就不可以)。
### 4.1.4 語句
任何版本的CSS的CSS樣式表,包含一系列的語句(見上面的語法)。有兩種語句:@規則和規則集。語句周圍可以有空白。
### 4.1.5 @規則
@規則以一個關鍵字@開始,緊跟在后的是一個[標識符](https://www.w3.org/TR/CSS22/syndata.html#value-def-identifier)(如'@import','@page')。
一個@規則包括到下一個分號(;)或下一個[塊](https://www.w3.org/TR/CSS22/syndata.html#block)間的所有內容(以先出現的為分界)。CSS用戶端一旦遇上不認識的@規則,它必須忽略這一規則,并繼續其后的解析。
CSS2用戶端必須[忽略](https://www.w3.org/TR/CSS22/syndata.html#ignore)在塊內出現或在其它任何一個規則集之后出現的任何['@import'](https://www.w3.org/TR/CSS22/cascade.html#at-import)規則。
假定一個CSS2解析器遇到如下的樣式表:
~~~
@import "subs.css";
H1 { color: blue }
@import "list.css";
~~~
根據CSS2.2,第二個'@import'是非法的。CSS2.2解析器忽略整個@規則,從而有效的樣式表縮減為:
~~~
@import "subs.css";
h1 { color: blue }
~~~
下面這個例子中,第二個'@import'規則是無效的,因為它出現在一個'@media' 塊中。
~~~
@import "subs.css";
@media print {
@import "print-main.css";
body { font-size: 10pt }
}
h1 {color: blue }
~~~
相反,要實現僅為“print”媒體樣式表導入的效果,請使用具有媒體語法的@import規則,例如:
~~~
@import "subs.css";
@import "print-main.css" print;
@media print {
body { font-size: 10pt }
}
h1 {color: blue }
~~~
### 4.1.6 塊
塊以一個左花括號({)開始,并以相匹配的右花括號(})結束。在其間,可以是任何字符。但是,括號(( )),方括號([ ])和花括號({ })必須成對出現,并可以嵌套。單引號(')和雙引號(")也必須成對出現,其間的字符被解析為一個字符串。字符串的定義參見上面的[標識化](https://www.w3.org/TR/CSS22/syndata.html#tokenization)。
~~~
這里是一個塊的例子。注意,雙引號內的右花括號并不匹配本塊開始的花括號。而第二個單引號是在轉義字符中,從而不匹配第一個單引號:
{ causta: "}" + ({7} * '\'') }
注意,上例盡管不是有效的CSS2.2,但還是一個塊的定義。
~~~
### 4.1.7 規則集,聲明塊和選擇器
一個規則集(也稱為“規則”)包含一個選擇子,以及隨后的聲明塊。
一個聲明塊(下文中也稱為{}塊)以左花括號開始({),以與之匹配的右花括號(})結束。其間是零個或多個以分號(;)分割的聲明的列表。
選擇器(參見[選擇器](https://www.w3.org/TR/CSS22/selector.html)一節)包含延伸到(但是不包含)第一個左花括號({)的所有內容。 一個選擇子總是和一個{}塊相隨。如果用戶端無法解析選擇子(例如,它不是有效的CSS2),它也必須忽略{}塊。
CSS2.2賦予選擇子中的逗號(,)以特殊的含義。不過,由于還不知道在將來的CSS版本中逗號是否會獲得其它的含義,當選擇子中任何地方出錯后,即使選擇子的其它部分可能看起來和CSS2。2吻合,但是整個語句將被忽略。
例如,由于"&"在CSS2.2中不是一個有效的表征,CSS2。2用戶端必須忽略整個第二行,也不把H3的顏色設置為紅色:
h1, h2 {color: green }
h3, h4 & h5 {color: red }
h6 {color: black }
~~~
下面是一個更復雜的例子。前兩對花括號在字符串中,并不標記著選擇子的結束。它是一個有效的CSS2語句。
p[example="public class foo\
{\
private int x;\
\
foo(int x) {\
this.x = x;\
}\
\
}"] { color: red }
~~~
### 4.1.8 聲明和屬性
一個聲明要么為空,要么包含一個屬性,隨后是一個冒號(:),隨后是一個值。其間可以有[空白](https://www.w3.org/TR/CSS22/syndata.html#whitespace)。
鑒于選擇子器工作的方式,同一選擇子的多重聲明可以組成以分號(;)分割的組。
~~~
因此,下面的規則:
H1 { font-weight: bold }
H1 { font-size: 12pt }
H1 { line-height: 14pt }
H1 { font-family: Helvetica }
H1 { font-variant: normal }
H1 { font-style: normal }
就等同于:
H1 {
font-weight: bold;
font-size: 12pt;
line-height: 14pt;
font-family: Helvetica;
font-variant: normal;
font-style: normal
}
~~~
一個屬性是一個[標識符](https://www.w3.org/TR/CSS22/syndata.html#value-def-identifier)。值中可以出現任何字符,不過括號("( )"),花括號("{ }"),單引號(')和雙引號(")必須匹配成對出現。而不在字符串中的分號必須[轉義](https://www.w3.org/TR/CSS22/syndata.html#escaped-characters)。括號,方括號和花括號可以嵌套。在引號中,字符解析為一個字符串。
值的語法由各屬性單獨規定。在任何情況下,值的構成包含標識符,字符串,數值,長度,百分比,URI,顏色,角度,時間和頻率等。
用戶端必須[忽略](https://www.w3.org/TR/CSS22/syndata.html#ignore)帶有無效屬性名或無效值的聲明。每一個CSS2屬性都有它自己的語法和語義的限制,規定它可以接受的值。
~~~
例如,我們假定CSS2解析器遇到如下的樣式表:
H1 { color: red; font-style: 12pt } /* 無效值:12pt */
P { color: blue; font-vendor: any; /* 無效屬性:font-vendor */
font-variant: small-caps }
EM EM { font-style: normal }
第一行中,第二個聲明帶有一個無效值'12pt'。第二行的第二個聲明包含未定義的屬性'font-vendor'。CSS2解析器將忽略這些聲明,從而有效的樣式表縮減為:
H1 { color: red; }
P { color: blue; font-variant: small-caps }
EM EM { font-style: normal }
~~~
### 4.1.9 注解
注解以字符"/*"開始,并以字符"*/"結束。它們可以在表征之間的任何位置出現,它們的內容對渲染沒有任何影響。注解不能嵌套。
CSS也允許SGML注解的分割符("<!--"及"-->")出現在某些特定的地方,但是它們不分割CSS的注解。允許SGML注解的分割符可以使樣式規則出現在HTML源文檔中的STYLE元素內,并且對于3.2版本以前的HTML用戶端是不可見的。更多的信息,請參見HTML 4.0規范[HTML40])。
## 4.2 解析錯誤的處理規則
某些情況下,用戶端必須忽略一個不合法的樣式表的一部分。本規范定義忽略的含義是用戶端解析不合法的部分(以找到它的開始和結束),但是不加以任何處理,就如同它不存在那樣。
為了保證在將來能為已有的屬性加入新的值或加入新的屬性,用戶端在碰到如下情形時,必須遵循如下規則:
***未知的屬性***。用戶端必須忽略帶有未知屬性的聲明。例如,如果有這樣一個樣式表:
~~~
H1 { color: red; rotation: 70minutes }
用戶處理這一樣式表時,如同
H1 { color: red }
~~~
***非法值*** 用戶端必須忽略帶有非法值的聲明。例如:
~~~
IMG { float: left } /* 正確的CSS2 */
IMG { float: left here } /* "here"不是'float'的值 */
IMG { background: "red" } /* CSS2中關鍵字不可以加引號 */
IMG { border-width: 3 } /* 長度值必須指定單位 */
CSS2.2解析器將保留第一條規則并忽略其它的規則,就如同:
IMG { float: left }
IMG { }
IMG { }
IMG { }
與將來的CSS規范一致的用戶端還可以接受一條或多條其它的規則。
~~~
***聲明異常***。用戶端必須在聲明結束以前處理好聲明異常的標識符,同時也要遵循,匹配(),[],{},“”和“'成對的規則,并正確處理轉義。 例如,聲明異常可能是缺少屬性名稱,冒號(:)或屬性值。
當UA期望聲明或規則的開始(即,IDENT標記或ATKEYWORD標記)但是發現意外標記時,該標記被認為是畸形聲明的第一個標記。 即,對于格式錯誤的聲明而不是格式錯誤的聲明的規則被用于確定哪種令牌在這種情況下被忽略。
例如:
~~~
p { color:green }
p { @foo { bar: baz } color:green } /* unknown at-rule */
p { color:green; color } /* malformed declaration missing ':', value */
p { color:red; color; color:green } /* same with expected recovery */
p { color:green; color: } /* malformed declaration missing value */
p { color:red; color:; color:green } /* same with expected recovery */
p { color:green; color{;color:maroon} } /* unexpected tokens { } */
p { color:red; color{;color:maroon}; color:green } /* same with recovery */
~~~
***語句異常*** 用戶端必須在聲明結束以前處理好語句異常的標識符,同時也要遵循,匹配(),[],{},“”和“'成對的規則,并正確處理轉義。例如,格式錯誤的語句可能包含意外的大括號或at關鍵字。
以下是實例:
~~~
p @here {color: red} /* ruleset with unexpected at-keyword "@here" */
@foo @bar; /* at-rule with unexpected at-keyword "@bar" */
}} {{ - }} /* ruleset with unexpected right brace */
) ( {} ) p {color: red } /* ruleset with unexpected right parenthesis */
~~~
***無效的at關鍵字*** 用戶端必須忽略一個無效的at關鍵字及其后面的所有內容,一直到包含無效的at關鍵字的塊的末尾,或者直到包括下一個分號(;),或者直到并包括下一個塊
({...}), 以先到者為準。
例如,考慮以下幾點:
~~~
@three-dee {
@background-lighting {
azimuth: 30deg;
elevation: 190deg;
}
h1 { color: red }
}
h1 { color: blue }
~~~
'@ three-dee'at-rule不是css 2.2的一部分。
因此,整個規則(直到并包括第三個右大括號)都被忽略。
一個css 2.2用戶代理忽略它,有效地將樣式表減少到:
~~~
h1 { color: blue }
~~~
在規則內的某些內容因為無效而被忽略,如@ media-rule內的無效聲明,并不會使整個規則無效。
***樣式結束錯誤***
用戶端必須關閉樣式表末尾的所有打開的結構(例如:塊,括號,括號,規則,字符串和注釋)。
~~~
@media screen {
p:before { content: 'Hello
~~~
將被視為下面這樣:
~~~
@media screen {
p:before { content: 'Hello'; }
}
~~~
以符合UA
***意外的字符串結尾*** 用戶端必須在到達行末時關閉字符串(即,在未轉義的換行符,回車符或換頁符之前),然后刪除其中找到該字符串的構造(聲明或規則)。
例如:
~~~
p {
color: green;
font-family: 'Courier New Times
color: red;
color: green;
}
~~~
將被視為下面這樣:
~~~
p { color: green; color: green; }
~~~
因為第二個聲明(從'font-family'到'color:red'之后的分號)是無效的并且被丟棄。
* 另請參閱[解析聲明塊的規則的規則集,聲明塊和選擇器](https://www.w3.org/TR/CSS22/syndata.html#rule-sets)。
## 4.3 值
### 4.3.1 整型和實型數
某些值的類型可以包括整型值(表示為<integer>)或實型值(表示為<number>)。實型和整型數都只以十進制符號表示。<integer>包括一個或多個數字"0"到數字"9"。<number>可以是一個<integer>,或者在點號(.)后接零個或多個數字。整數和實數可以前綴一個"-"或"+"來表示符號。
注意,很多接受整數和實數作為其值的屬性實際上會有取值范圍的限制,通常是非負值。
### 4.3.2 長度
長度是指水平或垂直方向的度量。
長度值的格式(本規范中表示為<length>)為:一個可選的符號字符('+'或'-','+'是缺省的符號),緊接在后的是一個<[number](https://www.w3.org/TR/CSS22/syndata.html#value-def-number)>(小數點可有可無),緊接在后的是一個單位標識符(如px,deg等等)。在'0'長度之后,單位標識符可以省略的。
某些屬性允許負的長度值,不過這將使格式化模型變得復雜,并可能伴隨著與實現相關得限制。如果不能支持負的長度值,它應該被轉換到最接近的可以被支持的[值](https://www.w3.org/TR/CSS22/cascade.html#usedValue)。
有兩種類型的長度單位:相對的和絕對的。 相對長度單位規定一個長度相對于另外一個長度屬性。使用相對單位的樣式表在從一個媒介轉移到另一個媒介(如從計算機顯示器到激光打印機)時,定比會相對簡單一些。
相對單位有:
* em:相關字體的'[font-size](https://www.w3.org/TR/CSS22/fonts.html#propdef-font-size)'
* ex:相關字體的'x-height'
~~~
h1 { margin: 0.5em } /* em */
h1 { margin: 1ex } /* ex */
~~~
'em'單位等于它所使用的元素的'font-size'屬性的計算值。例外情況是當'font-size'屬性本身的值出現'em'時,在這種情況下,它指的是父元素的字體大小。
它可以用于垂直或水平測量。(該單位有時也被稱為印刷文本中的四邊形寬度。)
'ex'單元由元素的第一個可用字體定義。
在'font-size'屬性的值中出現'ex'的情況除外,在這種情況下,它指向父元素的'ex'。
'x-height'之所以這么叫,因為它通常等于小寫字母“x”的高度。
然而,即使對于不包含“x”的字體也定義了“ex”
字體的x高度可以通過不同的方式找到。一些字體包含x高度的可靠指標。如果可靠的字體指標不可用,則可以從小寫字形的高度確定x高度。一種可能的啟發是查看小寫字母“o”的字形在基線以下延伸多遠,并從邊界框的頂部減去該值。在確定x高度不可能或不切實際的情況下,應使用0.5em的值。
~~~
下面的規則:
h1 { line-height: 1.2em }
意味著“h1”元素的行高將比“h1”元素的字體大20%。另一方面:
h1 { font-size: 1.2em }
意味著“h1”元素的字體大小將比“h1”元素繼承的字體大20%。
~~~
如果出現在文檔樹[根節點](https://www.w3.org/TR/CSS22/conform.html#doctree)(如HTML中的"HTML")時,'em'和'ex'參考屬性的[初始值](https://www.w3.org/TR/CSS22/about.html#initial-value)。0
子元素不會繼承為其父項指定的相對值;他們繼承計算值。
~~~
在以下規則中,如果“h1”是“body”元素的子元素,則計算的“h1”元素的“文本縮進”值將為36px,而不是45px。
body {
font-size: 12px;
text-indent: 3em; /* i.e., 36px */
}
h1 { font-size: 15px }
~~~
絕對長度單位相對于彼此是固定的。
它們的主要作用發揮在,當輸出環境已知時。
絕對單位由物理單位(in,cm,mm,pt,pc)和px單位組成:
* in: 英寸 — 1in is equal to 2.54cm.
* cm: 公分
* mm: 毫米
* pt: 點 — the points used by CSS are equal to 1/72nd of 1in.
* pc: 比薩餅 — 1pc is equal to 12pt.
* px: 像素 單元 — 1px is equal to 0.75pt.
對于css設備,通過將物理單位與他們的物理測量相關聯,或者(ii)通過將像素單位與參考像素相關聯,來錨定這些維度(i)。對于印刷媒體和類似的高分辨率設備,錨單元應該是標準物理單位之一(英寸,厘米等)。對于分辨率較低的設備以及具有異常觀看距離的設備,建議使用錨點單元作為像素單元。對于這樣的設備,建議像素單位是指最接近參考像素的整個設備像素數目。
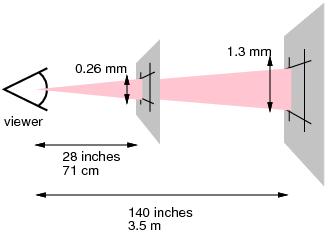
參考像素是像素密度為96dpi的設備上的一個像素的視角以及距手臂長度的閱讀器的距離。對于28英寸的標稱臂長,因此視角約為0.0213度。對于手臂長度來說,1px因此對應于大約0.26mm(1/96英寸)。
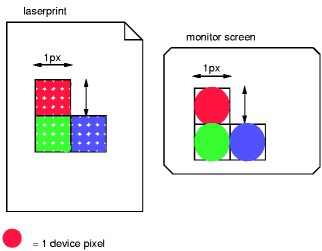
下面的圖片說明了觀看距離對參考像素大小的影響:71厘米(28英寸)的讀取距離導致參考像素為0.26毫米,而3.5米(12英尺)的讀取距離導致1.3毫米的參考像素。
第二幅圖像說明了設備在像素單元上的分辨率的影響:在低分辨率設備(例如,典型的計算機顯示器)中,1px×1px的區域被單個點覆蓋,而同一區域在更高分辨率的設備(如打印機)中覆蓋16個點
~~~
h1 { margin: 0.5in } /* inches */
h2 { line-height: 3cm } /* centimeters */
h3 { word-spacing: 4mm } /* millimeters */
h4 { font-size: 12pt } /* points */
h4 { font-size: 1pc } /* picas */
p { font-size: 12px } /* px */
~~~
### 4.3.3 百分比
百分比值的格式(本規范中表示為<percentage>)為:一個可選的符號字符('+'或'-','+'是缺省值),緊接在后的是一個<number>,緊接在后的是'%'。
百分比值總是相對于另外一個值,如長度。允許百分比值的每一個屬性也定義了百分比所參考的值。這個值可以是同一元素的另外一個屬性的值,其前輩元素的屬性值,或者格式化上下文的值(如包含塊的寬度)。如果根元素的屬性指定了百分比值,而百分比值又被定義為參考某個屬性的繼承值,那么結果值就是百分比乘以那個屬性的初始值。
~~~
由于子元素(通常)繼承其父元素的計算值,下例中,P元素的子元素的'line-height'將繼承12pt的值,而不是百分比值(120%)
P { font-size: 10pt }
P { line-height: 120% } /* 120% of 'font-size' */
~~~
### 4.3.4 URLs + URIs
URL(統一資源定位,參見[RFC1738]及[RFC1808])提供了網絡上一個資源的地址。可以預見的一個定位資源的新方法稱為URN(統一資源名稱)。兩者結合稱為URI(統一資源標識符,參見[URI])。本規范使用術語URI。
本規范中,URI值表示為<uri>。用來在屬性值中指定URI的函數符號是"url()",如:
~~~
BODY { background: url("http://www.bg.com/pinkish.gif") }
~~~
URI值的格式是:'url(',后跟可選的空白,后跟可選的單引號或雙引號,后跟URI本身,后跟可選的單引號或雙引號,后跟可選的空白,后跟')'。兩個引號字符必須一致。
~~~
沒有引號的例子:
LI { list-style: url(http://www.redballs.com/redball.png) disc }
~~~
括號,逗號,空白字符,單引號和雙引號如果出現在URI中,則必須用反斜杠轉義:'\(','\)','\,'。
根據URI的類型,也可能將上述字符寫成URI轉義(其中"(" = %28,")" = %29,等等)。參見[URI]。
為了創建不依賴于資源的絕對位置的模板樣式表,作者可以使用相對URIs。相對URI(定義見[RFC1808])根據基準URI解析為完全URI。RFC 1808的第3節定義了這一過程的標準化算法。對于CSS樣式表,基準URI是樣式表的位置,而不是源文檔的位置。
~~~
例如,假定如下的規則:
BODY { background: url("yellow") }
定位在由如下URI指定的樣式表中:
http://www.myorg.org/style/basic.css
則源文檔BODY的背景將由如下URI指定的圖形資源堆疊而成(不管那個圖形是什么):
http://www.myorg.org/style/yellow
~~~
用戶端在處理指定不可獲得或不適用的資源的URI時,方法可能不同。
### 4.3.5 記數器
記數器表示為標識符(參見'counter-increment'及'counter-reset'屬性)。要引用一個記數器的值,可以采用'counter(<identifier>)'或'counter(<identifier>, <list-style-type>)'。缺省的樣式是'decimal'。
要引用有相同名稱的嵌套記數器序列,采用'counters(<identifier>, <string>)'或'counters(<identifier>, <string>,<list-style-type>)'。參見生成的內容一章中的“記數器嵌套和作用范圍”。
CSS2中,記數器的值只可以由'content'屬性引用。注意,'none'也是一個可能的<list-style-type>:'counter(x, none)'返回一個空字符串
~~~
下面的樣式表為每一章(H1)中的段落(P)進行編號。編號的方式是以羅馬數字編號,后接一個點和一個空格:
P {counter-increment: par-num}
H1 {counter-reset: par-num}
P:before {content: counter(par-num, upper-roman) ". "}
~~~
### 4.3.6 顏色
<顏色>或者是一個關鍵字,或一個RGB數字。
他的顏色關鍵詞列表是:水色,黑色,藍色,紫紅色,灰色,綠色,青檸,栗色,海軍藍,橄欖色,橙色,紫色,紅色,銀色,藍綠色,白色和黃色。這17種顏色具有以下值:
~~~
maroon #800000
red #ff0000
orange #ffA500
yellow #ffff00
olive #808000
purple #800080
fuchsia #ff00ff
white #ffffff
lime #00ff00
green #008000
navy #000080
blue #0000ff
aqua #00fffft
eal #008080
black #000000
silver #c0c0c0gray #808080
~~~
除了這些顏色的關鍵字,用戶也可以指定在用戶環境中特定對象使用的顏色所對應的關鍵字。詳細內容請參見[系統顏色](https://www.w3.org/TR/CSS22/ui.html#system-colors)一節。
~~~
body {color: black; background: white }
h1 { color: maroon }
h2 { color: olive }
~~~
RGB顏色模型用在顏色的數字表示中。下面這些例子都指定了相同的顏色:
~~~
em { color: #f00 } /* #rgb */
em { color: #ff0000 } /* #rrggbb */
em { color: rgb(255,0,0) }
em { color: rgb(100%, 0%, 0%) }
~~~
以十六進制表示的RGB值的格式為:'#'號,緊接在后的是三個或六個十六進制字符。三位的RGB表示通過重復數字(而不是加零)轉化到六位的RGB表示。例如,#fb0擴展為#ffbb00。這樣保證了白色(#ffffff)可以簡縮表示為#fff,并消除了對于顯示的顏色深度的依賴性。
在函數表示中的RGB值的格式為:'rgb(',緊接在后的是用逗號分割的,三個數值(可以是三個整數值或三個百分比值),后接')'。整數值255代表100%,相當于十六進制表示的F或FF:rgb(255,255,255) = rgb(100%,100%,100%) =#FFF。數值周圍可以有空白字符。
所有的RGB顏色都定義在sRGB顏色空間中(參見[SRGB])。用戶端呈現這些顏色的忠實度可能會有差異。但是使用sRGB給顏色呈現提供了一個沒有歧義的、客觀的、可衡量的定義,也可以和國際標準相關聯(參見[COLORIMETRY])。
與規范一致的用戶端可以通過執行伽瑪校正,來限制它們顯示顏色的嘗試。sRGB規定了在特定瀏覽條件下,顯示伽瑪系數為2.2。用戶端應該調整在CSS中給出的顏色,和輸出設備的“自然”顯示伽瑪系數相結合,而使有效的顯示伽瑪系數為2.2。更多的細節,請參見伽瑪校正一節。注意,只有在CSS中規定的顏色才受影響;例如,圖形可能會自帶顏色信息。
超出設備范圍的值要加以修正:必須修改紅、綠、藍的值,使之和設備支持的范圍相吻合。對于一個典型的CRT顯示器,其設備范圍和sRGB相同,下面三個例子的效果一樣:
~~~
em { color: rgb(255,0,0) } /* integer range 0 - 255 */
em { color: rgb(300,0,0) } /* clipped to rgb(255,0,0) */
em { color: rgb(255,-10,0) } /* clipped to rgb(255,0,0) */
em { color: rgb(110%, 0%, 0%) } /* clipped to rgb(100%,0%,0%) */
~~~
其它設備,如打印機,和sRGB有不同的設備范圍;某些超出0..255的范圍的顏色使可以呈現的(在設備范圍之內),而其它一些在0..255范圍內的顏色會在設備范圍之外,從而被加以修正。
* 注意:盡管顏色給文檔帶來可觀的信息,并使文檔更加容易閱讀,但是也要考慮到某些顏色的組合會給色盲的讀者帶來困難。如果你使用背景圖形或設置了背景色,請相應地調整前景顏色。
### 4.3.7字符串
字符串可以包含在雙引號或單引號中。在雙引號對中不可以再出現雙引號,除非將其轉義(如'\"'或'\22')。單引號與此類似("\'"或"\27")。
~~~
"this is a 'string'"
"this is a \"string\""
'this is a "string"'
'this is a \'string\''
~~~
一個字符串不可以直接包含新行。要在字符串中包含新行,可以使用轉義字符"\A"(十六進制的A在Unicode中表示換行字符,在CSS中表示通用的"newline")。參見'content'屬性的例子。
為了美觀或其它別的原因,可以將字符串分成幾行。不過在這種情況下,換行本身要加以轉義。例如,下面的兩個選擇子是一樣的:
~~~
a[title="a not s\
o very long title"] {/*...*/}
a[title="a not so very long title"] {/*...*/}
~~~
### 4.3.8不支持的值
如果ua不支持特定的值,那么在解析樣式表時應忽略該值,就好像該值是非法值。
例如:
~~~
h3 {
display: inline;
display: run-in;
}
~~~
支持'display'屬性的'run-in'值的ua將接受第一個顯示聲明,然后用第二個顯示聲明“寫入”該值。
不支持“運行”值的ua將處理第一個顯示聲明并忽略第二個顯示聲明。
## 4.4 CSS文檔呈現
CSS樣式表是通用字符集(參見[ISO10646])中一系列字符的序列。為了傳送和寸儲的需要,這些字符必須由支持US-ASCII(如ISO 8859-x,SHIFT JIS等)字符集的編碼器加以編碼。有關字符集和字符編碼的詳細解釋,請參閱HTML 4.0規范([HTML40]第5章),也可參見XML 1.0規范([XML10]2.2節和4.3.3節),以及附錄E。
如果樣式表嵌套在另一個文檔中,如包含在HTML的STYLE元素或"style"屬性內,則該樣式表和整個文檔共享相同的字符編碼。
如果樣式表存在于對立的文件中,用戶端在確定文檔的字符編碼時,必須遵循如下的優先級(由高到低排列):
1、在"Content-Type"域中的"charset"HTTP參數(或其他協議中的類似參數)。
2、bom和/或@charset(見下文)
3、`<link charset =“”>`或來自鏈接機制的其他元數據(如果有的話)
4、引用樣式表或文檔的字符集(如果有的話)
5、假設utf-8
在外部樣式表中最多有一個@charset規則可以出現——它不可以出現在嵌套的樣式表中——它也必須出現在文檔的最開始,前面沒有任何字符。在"@charset"之后,用戶指定字符編碼的名稱。名稱必須是在IANA注冊表(參見[IANA]。完整的字符集列表也參見[CHARSETS])中描述的字符集名。例如:
~~~
@charset "ISO-8859-1";
~~~
@charset必須字面書寫,即10個字符的@charset“'(小寫,無反斜杠轉義符),后面跟著編碼名稱,后跟'”;'。
該名稱必須是iana注冊表中描述的字符集名稱。請參閱[charsets]獲取charsets的完整列表。作者應該使用iana注冊表中標記為“首選MIME名稱”的字符集名稱。
用戶端必須至少支持utf-8編碼。
如果上面的規則1(一個http“charset”參數或類似的)產生一個字符編碼,并且它是utf-8,utf-16或utf-32中的一個,那么文件開頭的一個bom(如果有的話)將覆蓋字符編碼如下:
~~~
First bytes (hexadecimal) Resulting encoding
00 00 FE FF UTF-32, big-endian
FF FE 00 00 UTF-32, little-endian
FE FF UTF-16, big-endian
FF FE UTF-16, little-endian
EF BB BF UTF-8
~~~
如果規則1產生utf-16be,utf-16le,utf-32be或utf-32le的字符編碼,那么如果文件以bom開頭,則會出錯。一個css ua必須通過忽略指定的編碼并使用上面的表來恢復。
用戶端必須忽略不在樣式表開頭的任何@charset規則。當用戶端使用bom和/或@charset規則檢測字符編碼時,它們應該遵循以下規則:
* 除了這些規則中的規定外,所有@charset規則都會被忽略。
* 根據開始樣式表的字節流檢測編碼。下表給出了一組初始字節序列(以十六進制寫入)的可能性。匹配樣式表開頭的第一行給出了基于bom和/或@charset規則的編碼檢測結果。如果沒有行匹配,則根據bom和/或@charset規則無法檢測到編碼。符號(...)*表示重復,其中最佳匹配是重復盡可能少的次數。標記為“xx”的字節是用于確定編碼名稱的字節,按照給定的順序將它們視為一系列ascii字符。標有“yy”的字節是相似的,但需要按照說明轉碼成ascii。如果用戶代理不支持與條目相關的任何編碼,則可能會忽略表中的條目。
* 如果基于上表中標記為“如指定”的條目中的一個條目檢測到編碼,則如果用戶代理在解碼導致的字符流的開始處沒有解析適當的@charset規則,則忽略該樣式表所選的@charset。這確保:
1、@charset規則只能在樣式表編碼時才能使用,
2、字節順序標記僅在支持字節順序標記的編碼中被忽略
3、編碼名稱不能包含換行符。
用戶端必須忽略未知編碼中的樣式表。
### 指的是未用字符編碼表示的字符
樣式表可能引用那些在當前字符編碼中無法表示的字符。這些字符必須寫成ISO 10646字符的轉義引用。這些轉義和在HTML或XML文檔中數字字符引用的功能是一樣的(參見[HTML40]第5章和第25章)。
轉義字符機制應該用在只有少數字符需要如此操作的情況下。如果文檔中的大部分字符需要轉義,用戶應該用更合適的編碼來編碼文檔(比方說,如果文檔包含很多希臘字符,作者可以使用"ISO-8859-7"或"UTF-8")。
如果中間處理器使用不同的字符編碼,它可以將這些轉義序列翻譯為它所使用的編碼的字節序列。另一方面,中間處理器不可以改變轉義序列而取消一個ASCII字符的特殊含義。
一致的用戶端必須將它們認識的任何字符編碼正確地映射到Unicode(或者它們應該表現為它們可以)。
例如,以ISO-8859-1(Latin-1)編碼的文檔不可以直接包含希臘字符: "κουρο?" (希臘文:"kouros")必須寫為"\3BA\3BF\3C5\3C1\3BF\3C2"。
~~~
注意:HTML 4.0中,數字字符引用的解釋發生在"style"屬性值中,而不在STYLE元素中。由于這一不對稱性,對于"style"屬性和STYLE元素,我們推薦作者使用CSS字符轉義機制而不是數字字符引用。例如,我們推薦:
<SPAN style="voice-family: D\FC rst">...</SPAN>
而不是:
<SPAN style="voice-family: Dürst">...</SPAN>
~~~
