
[TOC]
# 實用篇
## 1.shell判斷字符串或者read的是否為數字
```
read -p "Please select the operation number you need to perform:" input
#判斷輸入是否為數字
expr $input "+" 10 &> /dev/null
if [ $? -eq 0 ];then
echo "$1 is number"
else
echo "$1 not number"
fi
```
## 2.shell腳本只列出目錄下的所有文件
```
files=$(ls -l ./ |awk '/^-/ {print $NF}')
echo
index=1
for sfile in $files #加載功能
do
echo ${index}.${sfile}
index=$[$index+1]
done
```
## 3.列出當前目錄下所有文件夾
```
#獲取當前路徑下所有文件夾名稱
dir=$(ls -l ./ |awk '/^d/ {print $NF}')
cnt=1
for i in $dir
do
linux_list[cnt]=$i #存儲菜單到數組linux_list
echo ${cnt}.${linux_list[cnt]}
cnt=$[$cnt+1]
done
```
## 4.讀取文件第n行內容
```
content=`awk 'NR==2' ${sfile}` #讀取文件第2行內容
```
## 5.刪除、替換字符串中指定的字符
```
text="#1234455#rr"
# 只替換字符串中第一個#為-
text=${text/#/-}
# 替換字符串中所有#為-
text=${text//#/-}
```
注意:使用替換當然可以實現刪除指定字符的目的。
## 6.目錄路徑截取
```
FILE=/home/yhp/prj
appname=${FILE##\*/} #掃描字符,截取最有一個/符號后面的字符出來
```
## 7.獲取時間日期并打印
```bash
starttime=$(date +%Y-%m-%d\\ %H:%M:%S)
echo $starttime
ttime=`date +"%Y-%m-%d %H:%M:%S"`
echo $ttime
```
## 8.將變量寫入文件和從文件讀取變量的一中方法
```
#!/bin/bash
#[shell]
#將shell中使用的變量存入文件中,以及從文件調取變量
################################################
#文件中的格式為 VAR= 變量
#注意上面的等于號后面一定要有個空格才行
#假設var.dat文件中有一行為 VAR= yuan-hp
#那么腳本讀取就是 var=`awk ’/VAR=/{print $2}‘ var.dat`
#其實就是讀取該行第二例,所以按空格分列,你的變量不能含有空格
#當然可以通過-F參數自定義分隔符號來實現空格額問題
################################################
clear
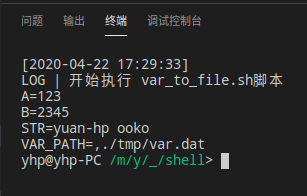
echo "LOG | 開始執行 var_to_file.sh腳本"
VAR=./tmp/var.dat #文件路徑
#新建文件用于測試
if [ ! -f $VAR ];then #沒有文件則創建文件
echo "LOG | 生成變量存儲文件:$VAR"
echo "VAR_PATH= $VAR">$VAR
echo "A=123">>$VAR
echo "B=324">>$VAR
echo "STR=sfgrtt">>$VAR
fi
#從文件讀取變量
A=`awk '/A=/{print $2}' $VAR`
B=`awk '/B=/{print $2}' $VAR`
STR=`awk '/STR=/{print $2}' $VAR`
VAR_PATH=`awk '/VAR_PATH=/{print $2}' $VAR`
echo "A=$A"
echo "B=$B"
echo "STR=$STR"
echo "VAR_PATH=$VAR_PATH"
```
自定義分隔符:
```
clear
echo "LOG | 開始執行 var_to_file.sh腳本"
VAR=./tmp/var.dat #文件路徑
#新建文件用于測試
if [ ! -f $VAR ];then #沒有文件則創建文件
echo "LOG | 生成變量存儲文件:$VAR"
echo "VAR_PATH=$VAR">$VAR
fi
#從文件讀取變量
A=`awk -F'=' '/A=/{print $2}' $VAR`
B=`awk -F'=' '/B=/{print $2}' $VAR`
STR=`awk -F'=' '/STR=/{print $2}' $VAR`
VAR_PATH=`awk -F'=' '/VAR_PATH=/{print $2}' $VAR`
if [ -z $A ];then
echo A為空
fi
echo "A=$A"
echo "B=$B"
echo "STR=$STR"
echo "VAR_PATH=$VAR_PATH"
```

## 9.linux中bash變量自加方法
[**Linux**](http://www.51testing.com/?uid-225738-action-viewspace-itemid-220988)?[**Shell**](http://www.51testing.com/?uid-225738-action-viewspace-itemid-220988)中寫循環時,常常要用到變量的自增,現在總結一下整型變量自增的方法。
1. i=`expr $i + 1`;
2. let i+=1;
3. ((i++));
4. i=$[$i+1];
5. i=$(( $i + 1 ))
## 10.獲取文件大小
` `可使用`do -b filename`獲取,如下:
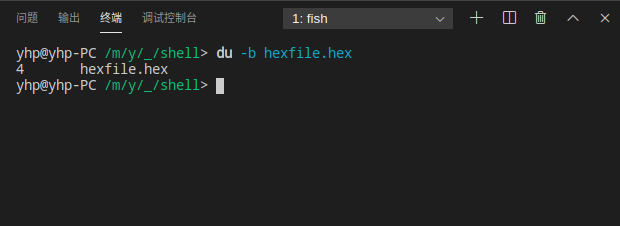
得到文件大小為4bytes
## 11.使用dd實現文件分割
```
dd的作用是轉換和拷貝文件,我們可以利用它來分割文件,相關的選項如下:
if=filename:輸入的文件名
of=finename:輸出的文件名
bs=bytes:一次讀寫的字節數,默認是512bytes
skip=blocks:拷貝前,跳過的輸入文件的前blocks塊,塊的大小有bs決定
count=blocks:只拷貝輸入文件的前blocks塊
例如,現在有一個文件file,大小為116616字節:
[root]# du -b file?
116616? file?
將其分割為兩文件file1和file2,那我們就設置每塊為1024字節,將file的前60塊放入file1,余下的放入file2:
[root]# dd if=file bs=1024 count=60 skip=0? of=file1?
[root]# dd if=file bs=1024 count=60 skip=60 of=file2
可以用md5sum驗證一下file和file.bak:
[root]# md5sum file?
3ff53f7c30421ace632eefff36148a70? file?
[root]# md5sum file.bak?
3ff53f7c30421ace632eefff36148a70? file.bak?
可以證明兩個文件時完全相同的。
```
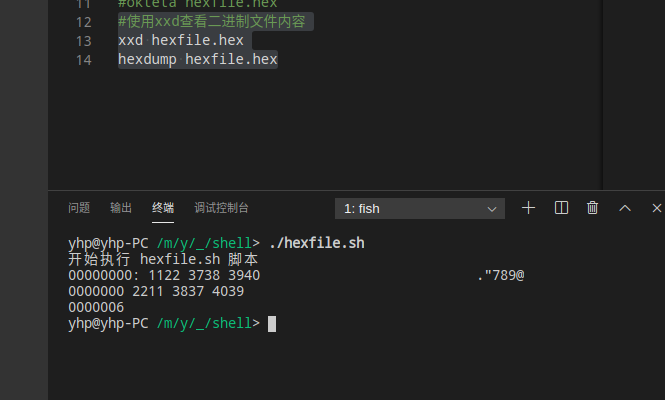
## 12.查看二進制文件
```
#使用xxd查看二進制文件內容
xxd hexfile.hex
hexdump hexfile.hex
```
## 13.獲取字符串的長度
```
len=`echo 'string' |wc -L` #獲取字符串長度
```
## 14獲取當前終端的寬度
```
col=`stty size|awk '{print $2}'`
```
# 網絡篇
## 1.shel中是一個jq解析json串
語法:jq '.key'
```shell
#!/bin/bash
#聯網隨機獲取一句語句并顯示
while true
do
clear
js=`curl -s https://v1.hitokoto.cn/`
text=` echo $js | jq '.hitokoto'`
text=${text//\"/} #去除引號
echo $text
sleep 5s
done
```
## 2.bash將字符轉換為urlencode
```
key=`echo '黃昏' | tr -d '\\n' | xxd -plain | sed 's/\\(..\\)/%\\1/g'`
```
- 0 工具
- 0.1 圖片無損放大
- 1 deepin系統
- 1.1 deepin系統安裝
- 1.2 deepin創建desktop文件
- 1.3 瀏覽器運行虛擬機
- 1.4 linux的百度網盤突然打不
- 1.5 deepin安裝后個人配置
- 1.5.1 安裝公式編輯器AxMath
- 1.5.2 Deepin標題欄太高的解決辦法(自定義高度)
- 1.5.3 linux下配置VS Code的標題欄風格
- 1.5.4 安裝腳本解釋器fish
- 1.6 關于軟件安裝
- 1.6.1 rpm和deb包想換轉換的方法
- 1.7 deepin開機自啟的設置方法
- 2 tiny core系統
- 2.1 安裝系統到硬盤
- 2.2 系統軟件安裝介紹
- 2.3 安裝控制臺計算器bc
- 2.4 關機保存的方法
- 2.5 linux文件結構說明
- 2.6 為tinycore配置ssh
- 3 使用Linux中的一些技巧
- 3.1 軟連接的使用
- 3.2 LInux下解壓
- 3.3 刪除操作
- 3.4 Zenity-在命令行和Shell腳本中創建圖形(GTK +)對話框
- 3.4.1 列表框
- 3.4.2 口令對話框
- 3.4.3 消息對話框
- 3.4.3.1 信息對話框
- 3.4.3.2 錯誤框
- 3.4.3.3 問題對話框
- 3.4.3.4 警告對話框
- 3.4.4 范圍對話框(滑條)
- 3.4.5 文件選擇對話框
- 3.4.6 表單對話框
- 3.4.7 文本信息框
- 3.4.8 進度框
- 3.4.9 文本輸入框
- 3.4.10 通知區域圖標
- 3.4.11 日歷對話框
- 3.4.12 顏色對話框
- 3.4.13 上述對話框測試文件
- 3.4.14 使用C++調用zenity
- 3.5 Linux whereis、find和locate命令
- 3.6 字體下載
- 3.7 使用Electron 創建跨平臺的應用程序
- 3.8 shell的使用
- 3.8.1 $$,$?等表示什么
- 3.8.2 shell隨機產生某一個范圍內的整數
- 3.8.3 寫shel腳本的一些使用操作
- 3.8.4 linux shell操作二進制文件
- 3.8.5 shell中的一些實用技巧
- 3.8.5.1 列出當前路徑下的所有文件夾
- 3.8.5.2 列出當前路徑下所有文件
- 3.8.5.3 獲取當前虛擬終端的大小
- 3.8.5.4 判斷輸入字符串是否為數字
- 3.8.5.5 bash中的數學運算
- 3.8.5.6 按照文件創建時間順序列出文件
- 3.8.5.7 echo輸出含空格不換行的設置方法
- 3.8.5.8 find 遞歸/不遞歸 查找子目錄的方法
- 3.8.5.9 echo顯示顏色設置
- 3.8.5.10 bash中使用${}字符操作方法
- 3.8.5.11 ls查找目錄,文件,軟連接等的方法
- 3.8.5.12 檢測某個程序是否在運行
- 3.8.5.13 bash/shell 解析命令行參數工具:getopts/getopt
- 3.8.5.14 獲取腳本的絕對路徑
- 3.8.6 使用bash寫的腳本管理腳本
- 3.9 Linux創建自定義命令
- 3.10 deepin掛載遠程文件夾到本地
- 3.11 linux root用戶添加用戶
- 3.12 實用腳本或者命令
- 3.12.1 命令行 將ppt轉換為 pdf
- 3.12.2 deepin上實現自定義命令
- 4 slitaz系統
- 4.1 系統安裝
- 4.2 安裝軟件命令tazpkg
- 4.3 使用說明
- 4.4 用 tazlito 構建 livecd自制linux系統
- 4.5 英文顯示支持設置方法
- 4.6 配置ssh
- 5 busybox的編譯使用
- 5.1 busybox介紹
- 5.2 busybox編譯使用
- 6 配置自己的linux
- 6.1 在deepin上編譯linux內核
- 7 每天一個linux命令
- 7.1 文件管理類
- 7.1.1 cat--接文件并打印到標準輸出設備上
- 7.1.2 chattr--改變文件屬性
- 7.1.3 chgrp--變更文件或目錄的所屬群組
- 7.1.4 chmod --控制文件如何被他人所調
- 7.1.5 chown命令--指定文件的擁有者改為指定的用戶或組
- 7.1.6 grep命令--用于查找文件里符合條件的字符串
- 7.1.7 其他
- 7.2 文檔編輯類
- 7.2.1 col--過濾控制字符
- 7.2.2 colrm--濾掉指定的行
- 7.2.3 comm --比較兩個已排過序的文件
- 7.2.4 awk--一種處理文本文件的語言,是一個強大的文本分析工具
- 7.2.5 sed命令
- 7.3 文件傳輸類
- 7.3.1 prm--將一個工作由打印機貯列中移除
- 7.4 磁盤管理類
- 7.4.1 cd--切換當前工作目錄至 dirName(目錄參數)。
- 7.4.2 df--顯示目前在Linux系統上的文件系統的磁盤使用情況統計
- 7.4.3 dirs--顯示目錄記錄
- 7.4.5 du--顯示目錄或文件的大小
- 8 其他系統
- 8.1 Alpine Liunx
- 8.1.2 簡介
- 8.1.2 本地安裝
- 8.1.3 apk軟件包管理
- 8.1.4 配置ssh