
[TOC]
[推薦地址](https://www.cnblogs.com/ggjucheng/archive/2013/01/13/2856896.html)
# 簡短說明
` `Linux grep 命令用于查找文件里符合條件的字符串。
` `grep 指令用于查找內容包含指定的范本樣式的文件,如果發現某文件的內容符合所指定的范本樣式,預設 grep 指令會把含有范本樣式的那一列顯示出來。若不指定任何文件名稱,或是所給予的文件名為 -,則 grep 指令會從標準輸入設備讀取數據。
## 語法
~~~
grep [-abcEFGhHilLnqrsvVwxy][-A<顯示列數>][-B<顯示列數>][-C<顯示列數>][-d<進行動作>][-e<范本樣式>][-f<范本文件>][--help][范本樣式][文件或目錄...]
~~~
## 參數
**-a 或 --text** : 不要忽略二進制的數據。
**-A 或 --after-context=** : 除了顯示符合范本樣式的那一列之外,并顯示該行之后的內容。
**-b 或 --byte-offset** : 在顯示符合樣式的那一行之前,標示出該行第一個字符的編號。
**-B 或 --before-context=** : 除了顯示符合樣式的那一行之外,并顯示該行之前的內容。
**-c 或 --count** : 計算符合樣式的列數。
**-C 或 --context=或-** : 除了顯示符合樣式的那一行之外,并顯示該行之前后的內容。
**-d 或 --directories=** : 當指定要查找的是目錄而非文件時,必須使用這項參數,否則grep指令將回報信息并停止動作。
**-e 或 --regexp=** : 指定字符串做為查找文件內容的樣式。
**-E 或 --extended-regexp** : 將樣式為延伸的正則表達式來使用。
**-f 或 --file=** : 指定規則文件,其內容含有一個或多個規則樣式,讓grep查找符合規則條件的文件內容,格式為每行一個規則樣式。
* **-F 或 --fixed-regexp** : 將樣式視為固定字符串的列表。
* **-G 或 --basic-regexp** : 將樣式視為普通的表示法來使用。
* **-h 或 --no-filename** : 在顯示符合樣式的那一行之前,不標示該行所屬的文件名稱。
* **-H 或 --with-filename** : 在顯示符合樣式的那一行之前,表示該行所屬的文件名稱。
* **-i 或 --ignore-case** : 忽略字符大小寫的差別。
* **-l 或 --file-with-matches** : 列出文件內容符合指定的樣式的文件名稱。
* **-L 或 --files-without-match** : 列出文件內容不符合指定的樣式的文件名稱。
* **-n 或 --line-number** : 在顯示符合樣式的那一行之前,標示出該行的列數編號。
* **-o 或 --only-matching** : 只顯示匹配PATTERN 部分。
* **-q 或 --quiet或--silent** : 不顯示任何信息。
* **-r 或 --recursive** : 此參數的效果和指定"-d recurse"參數相同。
* **-s 或 --no-messages** : 不顯示錯誤信息。
* **-v 或 --revert-match** : 顯示不包含匹配文本的所有行。
* **-V 或 --version** : 顯示版本信息。
* **-w 或 --word-regexp** : 只顯示全字符合的列。
* **-x --line-regexp** : 只顯示全列符合的列。
* **-y** : 此參數的效果和指定"-i"參數相同。
## 示例
1、在當前目錄中,查找后綴有 file 字樣的文件中包含 test 字符串的文件,并打印出該字符串的行。此時,可以使用如下命令:
~~~
grep test *file
~~~
```
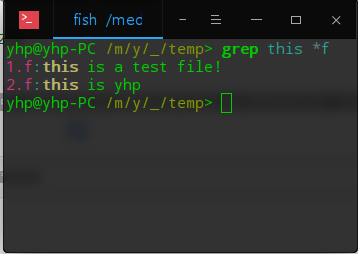
查找文件后綴為f的文件中含有this字符的字符串
yhp@yhp-PC /m/y/_/temp> grep this *f
1.f:this is a test file!
2.f:this is yhp
yhp@yhp-PC /m/y/_/temp>
```
```
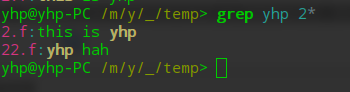
查找文件前綴含有2的文件中含有yhp字符串的行
yhp@yhp-PC /m/y/_/temp> grep yhp 2*
2.f:this is yhp
22.f:yhp hah
yhp@yhp-PC /m/y/_/temp>
```
2、以遞歸的方式查找符合條件的文件。例如,查找指定目錄/etc/acpi 及其子目錄(如果存在子目錄的話)下所有文件中包含字符串"update"的文件,并打印出該字符串所在行的內容,使用的命令為:
~~~
grep -r update /etc/acpi
~~~
輸出結果如下:
~~~
$ grep -r update /etc/acpi #以遞歸的方式查找“etc/acpi”
#下包含“update”的文件
/etc/acpi/ac.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.)
Rather than
/etc/acpi/resume.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of
IO.) Rather than
/etc/acpi/events/thinkpad-cmos:action=/usr/sbin/thinkpad-keys--update
~~~
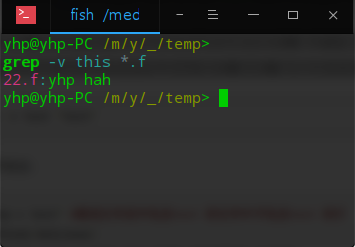
3、反向查找。前面各個例子是查找并打印出符合條件的行,通過"-v"參數可以打印出不符合條件行的內容。
查找文件名中包含 test 的文件中不包含test 的行,此時,使用的命令為:
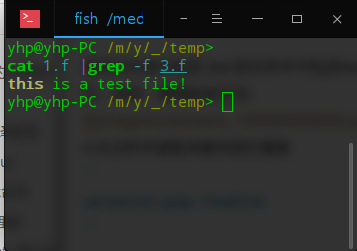
4.從文件中讀取關鍵字進行搜索
```
cat?test.txt?|?grep?-f?test2.txt
```
# 詳解
## 簡介
` `grep (global search regular expression(RE) and print out the line,全面搜索正則表達式并把行打印出來)是一種強大的文本搜索工具,它能使用正則表達式搜索文本,并把匹配的行打印出來。
` `Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的擴展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它們把所有的字母都看作單詞,也就是說,正則表達式中的元字符表示回其自身的字面意義,不再特殊。linux使用GNU版本的grep。它功能更強,可以通過-G、-E、-F命令行選項來使用egrep和fgrep的功能。
## grep常用用法
```
[root@www ~]# grep [-acinv] [--color=auto] '搜尋字符串' filename
選項與參數:
-a :將 binary 文件以 text 文件的方式搜尋數據
-c :計算找到 '搜尋字符串' 的次數
-i :忽略大小寫的不同,所以大小寫視為相同
-n :順便輸出行號
-v :反向選擇,亦即顯示出沒有 '搜尋字符串' 內容的那一行!
--color=auto :可以將找到的關鍵詞部分加上顏色的顯示喔!
```
### 將/etc/passwd,有出現 root 的行取出來
```
# grep root /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
或
# cat /etc/passwd | grep root
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
```
### 將/etc/passwd,有出現 root 的行取出來,同時顯示這些行在/etc/passwd的行號
```
# grep -n root /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
30:operator:x:11:0:operator:/root:/sbin/nologin
```
` `在關鍵字的顯示方面,grep 可以使用 --color=auto 來將關鍵字部分使用顏色顯示。 這可是個很不錯的功能啊!但是如果每次使用 grep 都得要自行加上 --color=auto 又顯的很麻煩~ 此時那個好用的 alias 就得來處理一下啦!你可以在 ~/.bashrc 內加上這行:『alias grep='grep --color=auto'』再以『 source ~/.bashrc 』來立即生效即可喔! 這樣每次運行 grep 他都會自動幫你加上顏色顯示啦
### 將/etc/passwd,將沒有出現 root 的行取出來
~~~
# grep -v root /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
~~~
### 將/etc/passwd,將沒有出現 root 和nologin的行取出來
~~~
# grep -v root /etc/passwd | grep -v nologin
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
~~~
### 用 dmesg 列出核心信息,再以 grep 找出內含 eth 那行,要將捉到的關鍵字顯色,且加上行號來表示
~~~
[root@www ~]# dmesg | grep -n --color=auto 'eth'
247:eth0: RealTek RTL8139 at 0xee846000, 00:90:cc:a6:34:84, IRQ 10
248:eth0: Identified 8139 chip type 'RTL-8139C'
294:eth0: link up, 100Mbps, full-duplex, lpa 0xC5E1
305:eth0: no IPv6 routers present
# 你會發現除了 eth 會有特殊顏色來表示之外,最前面還有行號喔!
~~~
### 根據文件內容遞歸查找目錄
```
# grep ‘energywise’ * #在當前目錄搜索帶'energywise'行的文件
# grep -r ‘energywise’ * #在當前目錄及其子目錄下搜索'energywise'行的文件
# grep -l -r ‘energywise’ * #在當前目錄及其子目錄下搜索'energywise'行的文件,但是不顯示匹配的行,只顯示匹配的文件
```
這幾個命令很使用,是查找文件的利器。
## grep與正規表達式
**字符類**
字符類的搜索:如果我想要搜尋 test 或 taste 這兩個單字時,可以發現到,其實她們有共通的 't?st' 存在~這個時候,我可以這樣來搜尋:
~~~
[root@www ~]# grep -n 't[ae]st' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
~~~
其實 [] 里面不論有幾個字節,他都謹代表某『一個』字節, 所以,上面的例子說明了,我需要的字串是『tast』或『test』兩個字串而已!
字符類的反向選擇 [^] :如果想要搜索到有 oo 的行,但不想要 oo 前面有 g,如下
~~~
[root@www ~]# grep -n '[^g]oo' regular_express.txt
2:apple is my favorite food.
3:Football game is not use feet only.
18:google is the best tools for search keyword.
19:goooooogle yes!
~~~
第 2,3 行沒有疑問,因為 foo 與 Foo 均可被接受!
但是第 18 行明明有 google 的 goo 啊~別忘記了,因為該行后面出現了 tool 的 too 啊!所以該行也被列出來~ 也就是說, 18 行里面雖然出現了我們所不要的項目 (goo) 但是由於有需要的項目 (too) , 因此,是符合字串搜尋的喔!
至於第 19 行,同樣的,因為 goooooogle 里面的 oo 前面可能是 o ,例如: go(ooo)oogle ,所以,這一行也是符合需求的!
字符類的連續:再來,假設我 oo 前面不想要有小寫字節,所以,我可以這樣寫 [^abcd....z]oo , 但是這樣似乎不怎么方便,由於小寫字節的 ASCII 上編碼的順序是連續的, 因此,我們可以將之簡化為底下這樣:
~~~
[root@www ~]# grep -n '[^a-z]oo' regular_express.txt
3:Football game is not use feet only.
~~~
也就是說,當我們在一組集合字節中,如果該字節組是連續的,例如大寫英文/小寫英文/數字等等, 就可以使用[a-z],[A-Z],[0-9]等方式來書寫,那么如果我們的要求字串是數字與英文呢? 呵呵!就將他全部寫在一起,變成:[a-zA-Z0-9]。
我們要取得有數字的那一行,就這樣:
~~~
[root@www ~]# grep -n '[0-9]' regular_express.txt
5:However, this dress is about $ 3183 dollars.
15:You are the best is mean you are the no. 1.
~~~
- 0 工具
- 0.1 圖片無損放大
- 1 deepin系統
- 1.1 deepin系統安裝
- 1.2 deepin創建desktop文件
- 1.3 瀏覽器運行虛擬機
- 1.4 linux的百度網盤突然打不
- 1.5 deepin安裝后個人配置
- 1.5.1 安裝公式編輯器AxMath
- 1.5.2 Deepin標題欄太高的解決辦法(自定義高度)
- 1.5.3 linux下配置VS Code的標題欄風格
- 1.5.4 安裝腳本解釋器fish
- 1.6 關于軟件安裝
- 1.6.1 rpm和deb包想換轉換的方法
- 1.7 deepin開機自啟的設置方法
- 2 tiny core系統
- 2.1 安裝系統到硬盤
- 2.2 系統軟件安裝介紹
- 2.3 安裝控制臺計算器bc
- 2.4 關機保存的方法
- 2.5 linux文件結構說明
- 2.6 為tinycore配置ssh
- 3 使用Linux中的一些技巧
- 3.1 軟連接的使用
- 3.2 LInux下解壓
- 3.3 刪除操作
- 3.4 Zenity-在命令行和Shell腳本中創建圖形(GTK +)對話框
- 3.4.1 列表框
- 3.4.2 口令對話框
- 3.4.3 消息對話框
- 3.4.3.1 信息對話框
- 3.4.3.2 錯誤框
- 3.4.3.3 問題對話框
- 3.4.3.4 警告對話框
- 3.4.4 范圍對話框(滑條)
- 3.4.5 文件選擇對話框
- 3.4.6 表單對話框
- 3.4.7 文本信息框
- 3.4.8 進度框
- 3.4.9 文本輸入框
- 3.4.10 通知區域圖標
- 3.4.11 日歷對話框
- 3.4.12 顏色對話框
- 3.4.13 上述對話框測試文件
- 3.4.14 使用C++調用zenity
- 3.5 Linux whereis、find和locate命令
- 3.6 字體下載
- 3.7 使用Electron 創建跨平臺的應用程序
- 3.8 shell的使用
- 3.8.1 $$,$?等表示什么
- 3.8.2 shell隨機產生某一個范圍內的整數
- 3.8.3 寫shel腳本的一些使用操作
- 3.8.4 linux shell操作二進制文件
- 3.8.5 shell中的一些實用技巧
- 3.8.5.1 列出當前路徑下的所有文件夾
- 3.8.5.2 列出當前路徑下所有文件
- 3.8.5.3 獲取當前虛擬終端的大小
- 3.8.5.4 判斷輸入字符串是否為數字
- 3.8.5.5 bash中的數學運算
- 3.8.5.6 按照文件創建時間順序列出文件
- 3.8.5.7 echo輸出含空格不換行的設置方法
- 3.8.5.8 find 遞歸/不遞歸 查找子目錄的方法
- 3.8.5.9 echo顯示顏色設置
- 3.8.5.10 bash中使用${}字符操作方法
- 3.8.5.11 ls查找目錄,文件,軟連接等的方法
- 3.8.5.12 檢測某個程序是否在運行
- 3.8.5.13 bash/shell 解析命令行參數工具:getopts/getopt
- 3.8.5.14 獲取腳本的絕對路徑
- 3.8.6 使用bash寫的腳本管理腳本
- 3.9 Linux創建自定義命令
- 3.10 deepin掛載遠程文件夾到本地
- 3.11 linux root用戶添加用戶
- 3.12 實用腳本或者命令
- 3.12.1 命令行 將ppt轉換為 pdf
- 3.12.2 deepin上實現自定義命令
- 4 slitaz系統
- 4.1 系統安裝
- 4.2 安裝軟件命令tazpkg
- 4.3 使用說明
- 4.4 用 tazlito 構建 livecd自制linux系統
- 4.5 英文顯示支持設置方法
- 4.6 配置ssh
- 5 busybox的編譯使用
- 5.1 busybox介紹
- 5.2 busybox編譯使用
- 6 配置自己的linux
- 6.1 在deepin上編譯linux內核
- 7 每天一個linux命令
- 7.1 文件管理類
- 7.1.1 cat--接文件并打印到標準輸出設備上
- 7.1.2 chattr--改變文件屬性
- 7.1.3 chgrp--變更文件或目錄的所屬群組
- 7.1.4 chmod --控制文件如何被他人所調
- 7.1.5 chown命令--指定文件的擁有者改為指定的用戶或組
- 7.1.6 grep命令--用于查找文件里符合條件的字符串
- 7.1.7 其他
- 7.2 文檔編輯類
- 7.2.1 col--過濾控制字符
- 7.2.2 colrm--濾掉指定的行
- 7.2.3 comm --比較兩個已排過序的文件
- 7.2.4 awk--一種處理文本文件的語言,是一個強大的文本分析工具
- 7.2.5 sed命令
- 7.3 文件傳輸類
- 7.3.1 prm--將一個工作由打印機貯列中移除
- 7.4 磁盤管理類
- 7.4.1 cd--切換當前工作目錄至 dirName(目錄參數)。
- 7.4.2 df--顯示目前在Linux系統上的文件系統的磁盤使用情況統計
- 7.4.3 dirs--顯示目錄記錄
- 7.4.5 du--顯示目錄或文件的大小
- 8 其他系統
- 8.1 Alpine Liunx
- 8.1.2 簡介
- 8.1.2 本地安裝
- 8.1.3 apk軟件包管理
- 8.1.4 配置ssh