

下面是視頻(優酷的清晰度有限):還是建議大家去B站觀看:[B站觀看地址](https://www.bilibili.com/video/BV1sE411P7C1/)。如果您覺得我做的工作對您有幫助,請去B站點贊、關注、轉發、收藏,您的支持是我不竭的創作動力!
```[youku]
XNDYwODU2MjEwNA
```
## 一、回顧Stream管道流操作
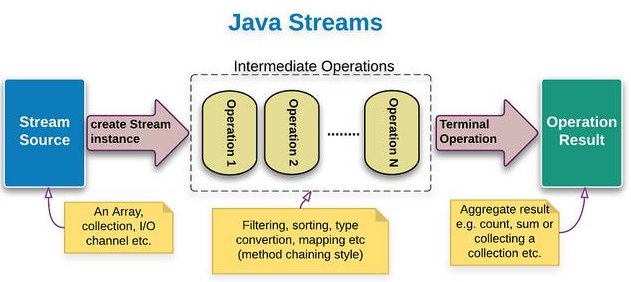
通過前面章節的學習,我們應該明白了Stream管道流的基本操作。我們來回顧一下:
* 源操作:可以將數組、集合類、行文本文件轉換成管道流Stream進行數據處理
* 中間操作:對Stream流中的數據進行處理,比如:過濾、數據轉換等等
* 終端操作:作用就是將Stream管道流轉換為其他的數據類型。這部分我們還沒有講,我們后面章節再介紹。
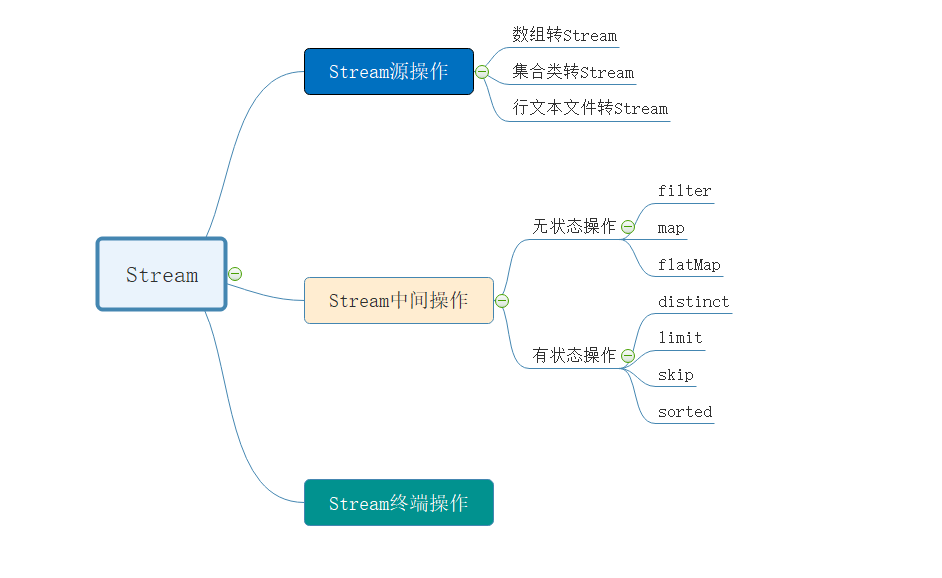
看下面的腦圖,可以有更清晰的理解:
## 二、中間操作:有狀態與無狀態
其實在程序員編程中,經常會接觸到“有狀態”,“無狀態”,絕大部分的人都比較蒙。而且在不同的場景下,“狀態”這個詞的含義似乎有所不同。但是“萬變不離其宗”,理解“狀態”這個詞在編程領域的含義,筆者教給大家幾個關鍵點:
* 狀態通常代表公用數據,有狀態就是有“公用數據”
* 因為有公用的數據,狀態通常需要額外的存儲。
* 狀態通常被多人、多用戶、多線程、多次操作,這就涉及到狀態的管理及變更操作。
是不是更蒙了?舉個例子,你就明白了
* web開發session就是一種狀態,訪問者的多次請求關聯同一個session,這個session需要存儲到內存或者redis。多次請求使用同一個公用的session,這個session就是狀態數據。
* vue的vuex的store就是一種狀態,首先它是多組件公用的,其次是不同的組件都可以修改它,最后它需要獨立于組件單獨存儲。所以store就是一種狀態。
回到我們的Stream管道流
* filter與map操作,不需要管道流的前面后面元素相關,所以不需要額外的記錄元素之間的關系。輸入一個元素,獲得一個結果。
* sorted是排序操作、distinct是去重操作。像這種操作都是和別的元素相關的操作,我自己無法完成整體操作。就像班級點名就是無狀態的,喊到你你就答到就可以了。如果是班級同學按大小個排序,那就不是你自己的事了,你得和周圍的同學比一下身高并記住,你記住的這個身高比較結果就是一種“狀態”。所以這種操作就是有狀態操作。
## 三、Limit與Skip管道數據截取
~~~
List<String> limitN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.limit(2)
.collect(Collectors.toList());
List<String> skipN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.skip(2)
.collect(Collectors.toList());
~~~
* limt方法傳入一個整數n,用于截取管道中的前n個元素。經過管道處理之后的數據是:\[Monkey, Lion\]。
* skip方法與limit方法的使用相反,用于跳過前n個元素,截取從n到末尾的元素。經過管道處理之后的數據是: \[Giraffe, Lemur\]
## 四、Distinct元素去重
我們還可以使用distinct方法對管道中的元素去重,涉及到去重就一定涉及到元素之間的比較,distinct方法時調用Object的equals方法進行對象的比較的,如果你有自己的比較規則,可以重寫equals方法。
~~~
List<String> uniqueAnimals = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.distinct()
.collect(Collectors.toList());
~~~
上面代碼去重之后的結果是: \["Monkey", "Lion", "Giraffe", "Lemur"\]
## 五、Sorted排序
默認的情況下,sorted是按照字母的自然順序進行排序。如下代碼的排序結果是:[Giraffe, Lemur, Lion, Monkey\],字數按順序G在L前面,L在M前面。第一位無法區分順序,就比較第二位字母。
~~~
List<String> alphabeticOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted()
.collect(Collectors.toList());
~~~
排序我們后面還會給大家詳細的講一講,所以這里暫時只做一個了解。
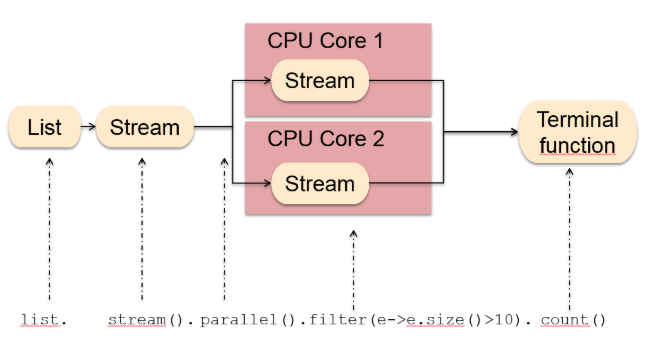
## 六、串行、并行與順序
通常情況下,有狀態和無狀態操作不需要我們去關心。除非?:你使用了并行操作。
還是用班級按身高排隊為例:班級有一個人負責排序,這個排序結果最后就會是正確的。那如果有2個、3個人負責按大小個排隊呢?最后可能就亂套了。一個人只能保證自己排序的人的順序,他無法保證其他人的排隊順序。
* 串行的好處是可以保證順序,但是通常情況下處理速度慢一些
* 并行的好處是對于元素的處理速度快一些(通常情況下),但是順序無法保證。這**可能會導致**進行一些**有狀態操作**的時候,最后得到的不是你想要的結果。
```
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);
```
* parallel()函數表示對管道中的元素進行并行處理,而不是串行處理。但是這樣就有可能導致管道流中后面的元素先處理,前面的元素后處理,也就是元素的順序無法保證。
> 如果數據量比較小的情況下,不太能觀察到,數據量大的話,就能觀察到數據順序是無法保證的。
```
Monkey
Lion
Lemur
Giraffe
Lion
```
通常情況下,parallel()能夠很好的利用CPU的多核處理器,達到更好的執行效率和性能,建議使用。但是有些特殊的情況下,parallel并不適合:深入了解請看這篇文章:
[https://blog.oio.de/2016/01/22/parallel-stream-processing-in-java-8-performance-of-sequential-vs-parallel-stream-processing/](https://blog.oio.de/2016/01/22/parallel-stream-processing-in-java-8-performance-of-sequential-vs-parallel-stream-processing/)
該文章中幾個觀點,說明并行操作的適用場景:
* 數據源易拆分:從處理性能的角度,parallel()更適合處理ArrayList,而不是LinkedList。因為ArrayList從數據結構上講是基于數組的,可以根據索引很容易的拆分為多個。
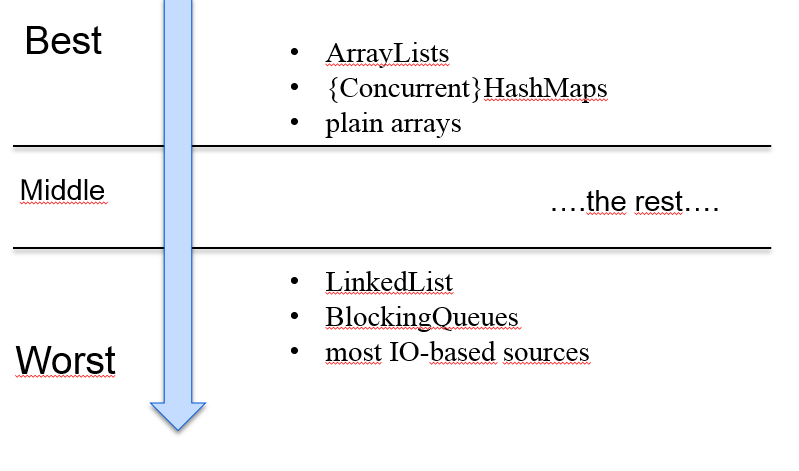
* 適用于無狀態操作:每個元素的計算都不得依賴或影響任何其他元素的計算,的運算場景。
* 基礎數據源無變化:從文本文件里面邊讀邊處理的場景,不適合parallel()并行處理。parallel()一開始就容量固定的集合,這樣能夠平均的拆分、同步處理。
- 前言
- 1.lambda表達式會用了么
- 2.初識Stream-API
- 3.Stream的filter與謂語邏輯
- 4.Stream管道流的map操作
- 5.Stream的狀態與并行操作
- 6.Stream性能差?不要人云亦云
- 7.像使用SQL一樣排序集合
- 8.函數式接口Comparator
- 9.Stream查找與匹配元素
- 10.Stream集合元素歸約
- 11.StreamAPI終端操作
- 12.java8如何排序Map
- Stream流逐行文件處理
- java8-forEach(持續發布中)
- 筆者其它作品推薦
- vue深入淺出系列
- 手摸手教你學Spring Boot2.0
- Spring Security-JWT-OAuth2一本通
- 實戰前后端分離RBAC權限管理系統
- 實戰SpringCloud微服務從青銅到王者