
# kubernetes 的馬洛斯需求
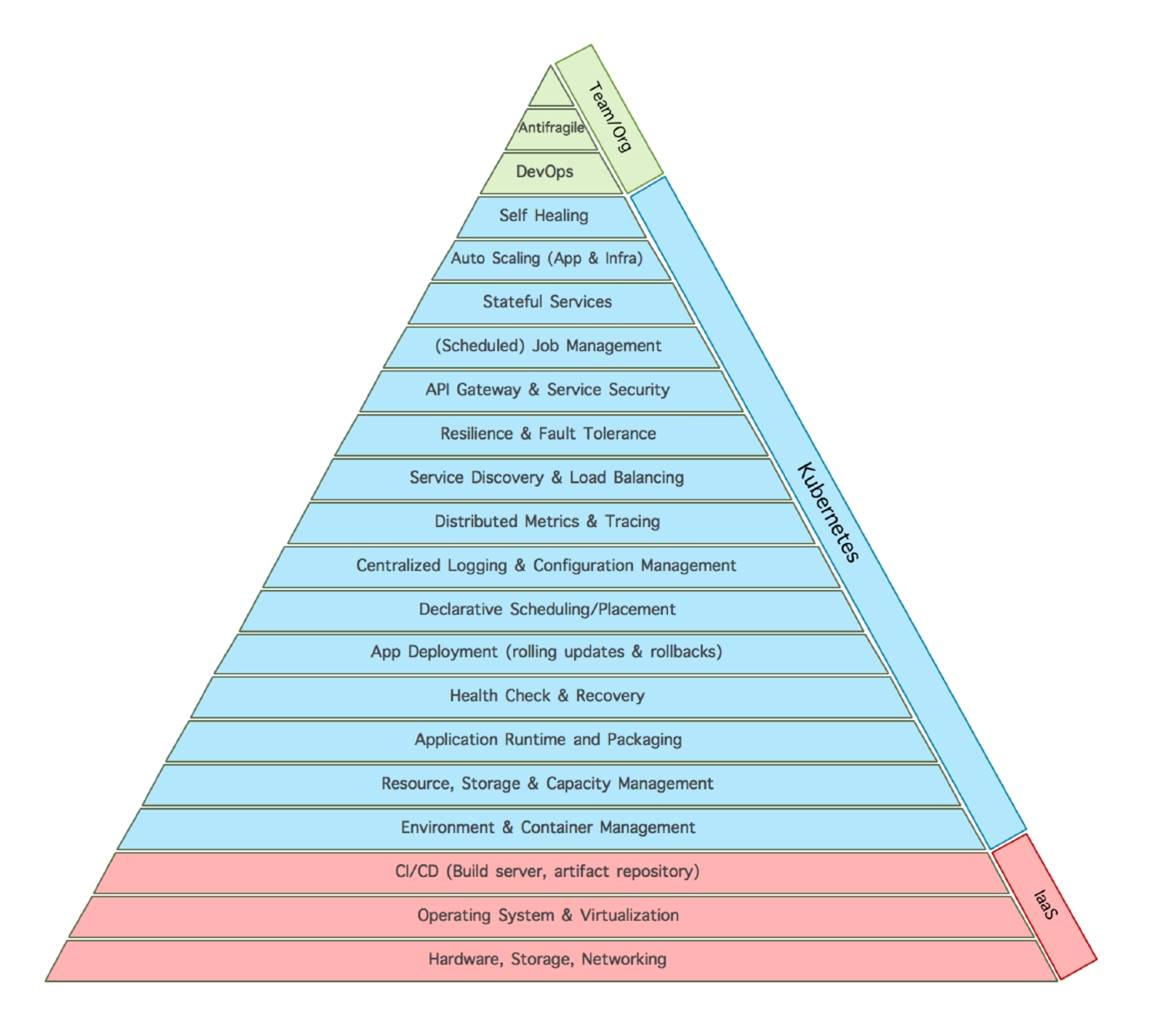
---
### kubernetes 架構圖
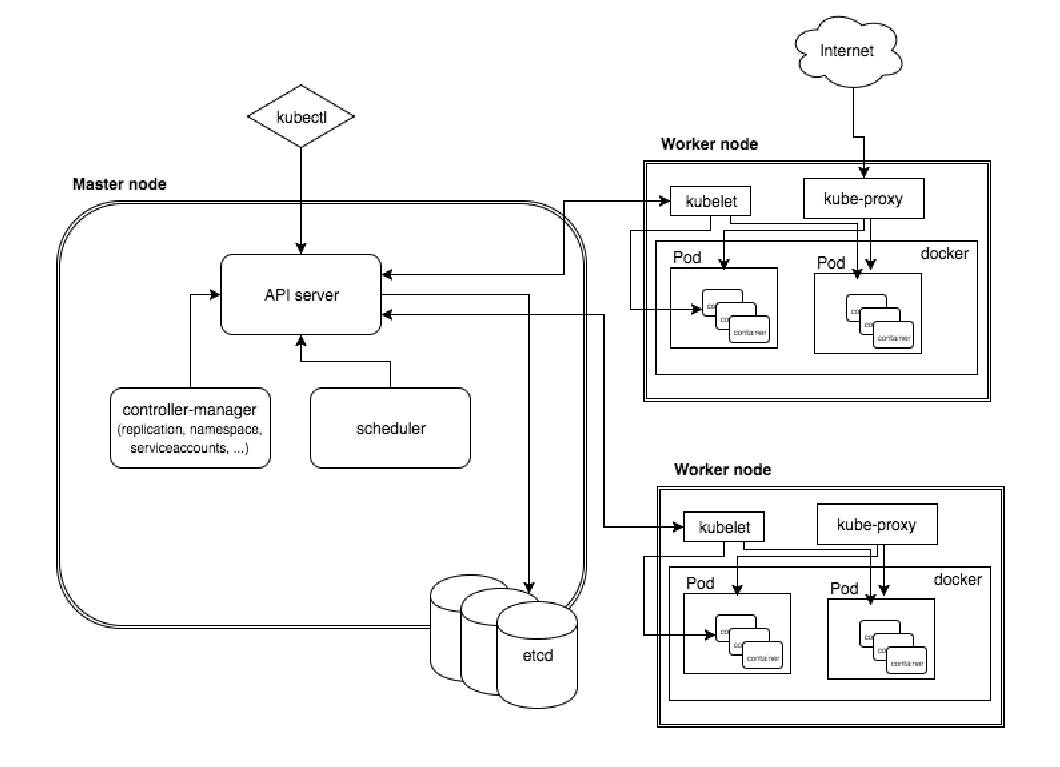
---
### kubernetes 主要基本概念和術語
- # master
- 1. Kubernets API server,提供
- 2. Kubernets Controlle Manager (kube-controller-manager),kubernets 里面所有資源對象的自動化控制中心,可以理解為資源對象的大總管。
- 3. Kubernets Scheduler (kube-scheduler),負責資源調度(pod調度)的進程,相當去公交公司的‘調度室’
- # node
每個Node 節點上都運行著以下一組關鍵進程
- 1. kubelet:負責pod對應的容器創建、啟停等任務,同時與master 節點密切協作,實現集群管理的基本功能。
- 2. kube-proxy:實現kubernetes Service 的通信與負載均衡機制的重要組件。
- 3. Docker Engine: Docker 引擎,負責本機的容器創建和管理工作。
- # pod:
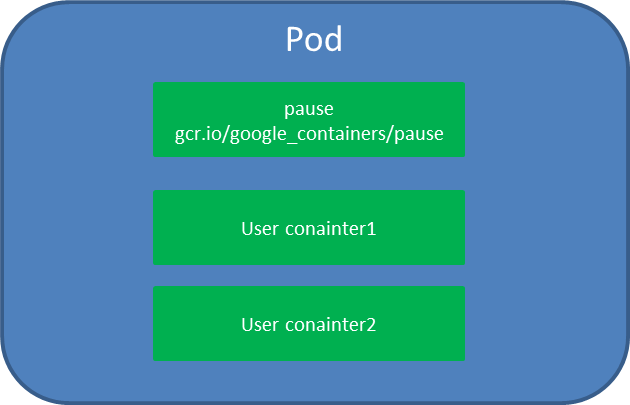
1. Pod是kubernetes中可以創建的最小部署單元
1. V1 core版本的Pod的配置模板見[Pod Template](https://rootsongjc.gitbooks.io/kubernetes-handbook/content/manifests/template/pod-v1-template.yaml)
2. Example:創建一個tomcat實例
apiVersion: vl
kind: Pod
metadata:
name: myweb
labels:
name: myweb
spec:
containers:
- name: myweb
image: kubeguide/tomcat-app:vl
ports:
- containerPort: 8080
env:
- name: MYSQL_SERVICE_HOST
value: 'mysql'
- name: MYSQL_SERVICE_PORT
value: '3306'
- # label(標簽)
- 1. 一個label是一個key=value的簡直對,其中key與value由用戶自己指定。Label可以附加到各種資源對象上,列入Node、pod、Server、RC 等。
- 2. Label 示例如下:
```
版本標簽:release:stable,release:canary
環境標簽:environment:dev,environment:qa,environment:production
架構標簽: tier:frontend,tier:backend,tier:cache
分區標簽:partition:customerA,partition:customerB
質量管控標簽:track:daily,track:weekly
```
- 3. Label selector
Label不是唯一的,很多object可能有相同的label
通過label selector,客戶端/用戶可以指定一個object集合,通過label selector對object的集合進行操作。
- Label selector有兩種類型:
- equality-based :可以使用=、==、!=操作符,可以使用逗號分隔多個表達式
- et-based :可以使用in、notin、!操作符,另外還可以沒有操作符,直接寫出某個label的key,表示過濾有某個key的object而不管該key的value是何值,!表示沒有該label的object
- 示例
```
$ kubectl get pods -l 'environment=production,tier=frontend'
$ kubectl get pods -l 'environment in (production),tier in (frontend)'
$ kubectl get pods -l 'environment in (production, qa)'
$ kubectl get pods -l 'environment,environment notin (frontend)'
```
- Label Selector 的作用范圍1
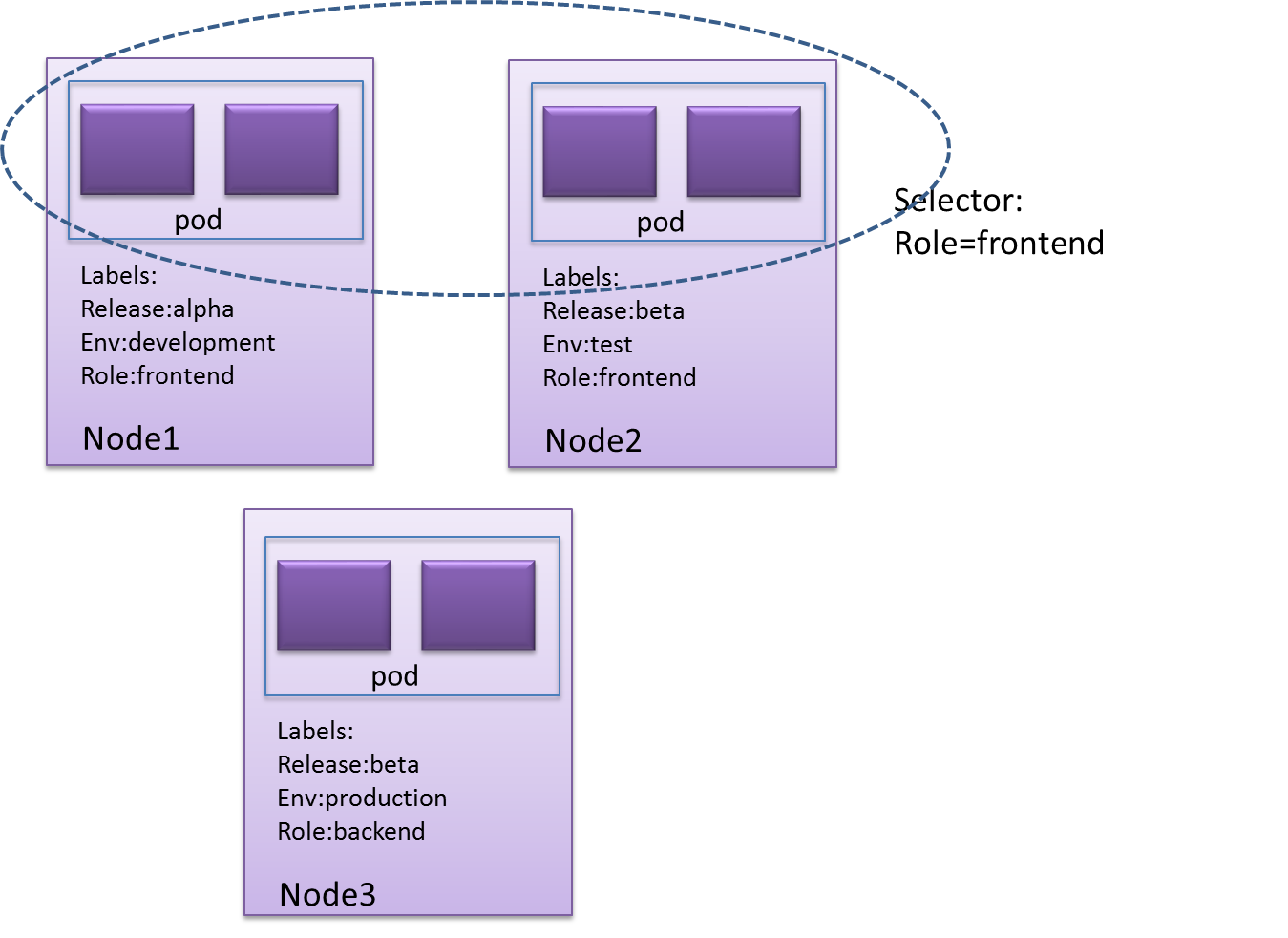
- Label Selector 的作用范圍2

- # Replication Contoller
### 簡述:
定義了一個期望的場景,即聲明某種Pod的副本數量在任意時刻都符合某個預期值,所以RC的定義包含如下幾個場景:
- 1. Pod 期待的副本數
- 2. 用于篩選Pod的Label Selector
- 3. 當pod的副本數量小于預期的時候,用于創建新的Pod的pod模板(Template)
- 4. 一個完整的RC示例:
```
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: frontend
# these labels can be applied automatically
# from the labels in the pod template if not set
# labels:
# app: guestbook
# tier: frontend
spec:
# this replicas value is default
# modify it according to your case
replicas: 3
# selector can be applied automatically
# from the labels in the pod template if not set,
# but we are specifying the selector here to
# demonstrate its usage.
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
resources:
requests:
cpu: 100m
memory: 100Mi
env:
- name: GET_HOSTS_FROM
value: dns
# If your cluster config does not include a dns service, then to
# instead access environment variables to find service host
# info, comment out the 'value: dns' line above, and uncomment the
# line below.
# value: env
ports:
- containerPort: 80
```
- # Deployment
- ### 簡述
Deployment 為 Pod 和 ReplicaSet 提供了一個聲明式定義(declarative)方法,用來替代以前的ReplicationController 來方便的管理應用。
- ### 典型的應用場景包括:
- 使用Deployment來創建ReplicaSet。ReplicaSet在后臺創建pod。檢查啟動狀態,看它是成功還是失敗。
- 然后,通過更新Deployment的PodTemplateSpec字段來聲明Pod的新狀態。這會創建一個新的ReplicaSet,Deployment會按照控制的速率將pod從舊的ReplicaSet移動到新的ReplicaSet中。
- 如果當前狀態不穩定,回滾到之前的Deployment revision。每次回滾都會更新Deployment的revision。
- 擴容Deployment以滿足更高的負載。
- 暫停Deployment來應用PodTemplateSpec的多個修復,然后恢復上線。
- 根據Deployment 的狀態判斷上線是否hang住了。
- 清除舊的不必要的 ReplicaSet。
- ### 一個簡單的nginx 應用可以定義為:
```
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
```
- # Horizontal Pod Autoscaler
- ### 簡述:
應用的資源使用率通常都有高峰和低谷的時候,如何削峰填谷,提高集群的整體資源利用率,讓service中的Pod個數自動調整呢?這就有賴于Horizontal Pod Autoscaling了,顧名思義,使Pod水平自動縮放。這個Object(跟Pod、Deployment一樣都是API resource)也是最能體現kubernetes之于傳統運維價值的地方,不再需要手動擴容了,終于實現自動化了,還可以自定義指標,沒準未來還可以通過人工智能自動進化呢!
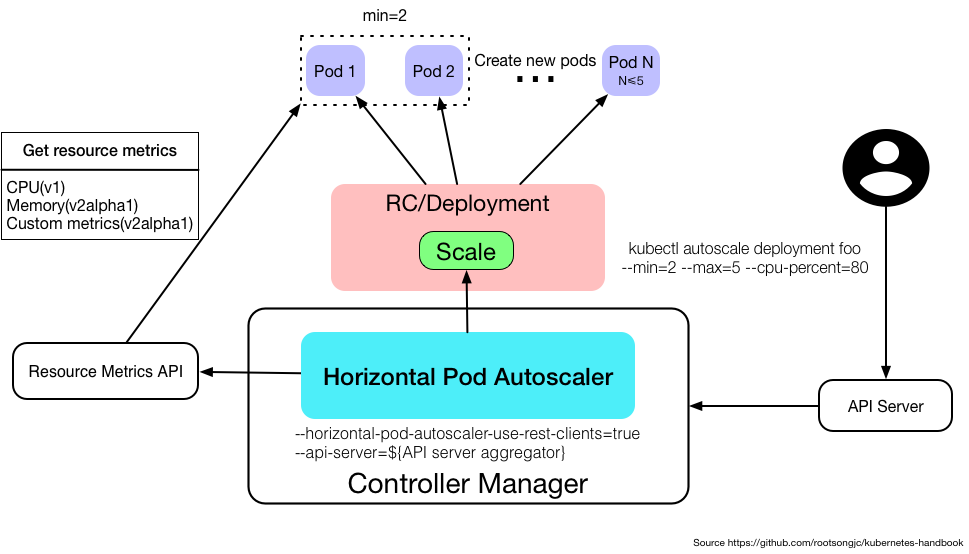
- ### Metrics支持
在不同版本的API中,HPA autoscale時可以根據以下指標來判斷:
- autoscaling/v1
- CPU
- autoscaling/v2alpha1
- 內存
- 自定義
- kubernetes1.6起支持自定義metrics,但是必須在kube-controller-manager中配置如下兩項
- --horizontal-pod-autoscaler-use-rest-clients=true
- --api-server指向kube-aggregator,也可以使用heapster來實現,通過在啟動heapster的時候指定--api-server=true。查看kubernetes metrics
- 多種metrics組合
- HPA會根據每個metric的值計算出scale的值,并將最大的那個指作為擴容的最終結果
- 一個簡單的HPA示例:
```
apiVersion: autoscaling/vl
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
maxReplicas: 5
minReplicas: 2
scaleTargetRef:
kind: Deployment
name: php-apache
targetCPUUtilizationPercentage: 90
```
- # Service
- 簡述:
- Kubernetes Service 定義了這樣一種抽象:一個 Pod 的邏輯分組,一種可以訪問它們的策略 —— 通常稱為微服務。 這一組 Pod 能夠被 Service 訪問到,通常是通過 Label Selector(查看下面了解,為什么可能需要沒有 selector 的 Service)實現的。
- Pod、 RC 與Service的關系 
- Endpoint: Pod IP + Container Port
- 一個service 示例
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
- ### kubernetes 的服務發現機制
Kubernetes 支持2種基本的服務發現模式 —— 環境變量和 DNS。
1. - ### 環境變量
當 Pod 運行在 Node 上,kubelet 會為每個活躍的 Service 添加一組環境變量。 它同時支持 Docker links 兼容 變量(查看 makeLinkVariables)、簡單的 {SVCNAME}_SERVICE_HOST 和 {SVCNAME}_SERVICE_PORT 變量,這里 Service 的名稱需大寫,橫線被轉換成下劃線。
舉個例子,一個名稱為 "redis-master" 的 Service 暴露了 TCP 端口 6379,同時給它分配了 Cluster IP 地址 10.0.0.11,這個 Service 生成了如下環境變量:
```
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
```
2. - ### DNS
kubernets 通過Add-On增值包的方式引入了DNS 系統,把服務名稱作為DNS域名,這樣一來,程序就可以直接使用服務名來建立通信連接。目前kubernetes上的大部分應用都已經采用了DNS這一種發現機制,在后面的章節中我們會講述如何部署與使用這套DNS系統。
3. - ### 外部系統訪問service的問題
為了更加深刻的理解和掌握Kubernetes,我們需要弄明白kubernetes里面的“三種IP”這個關鍵問題,這三種IP 分別如下:
- Node IP: Node(物理主機)的IP地址
- Pod IP:Pod的IP地址
- Cluster IP: Service 的IP地址
4. - ### 服務類型
對一些應用(如 Frontend)的某些部分,可能希望通過外部(Kubernetes 集群外部)IP 地址暴露 Service。
Kubernetes ServiceTypes 允許指定一個需要的類型的 Service,默認是 ClusterIP 類型。
Type 的取值以及行為如下:
- ClusterIP:通過集群的內部 IP 暴露服務,選擇該值,服務只能夠在集群內部可以訪問,這也是默認的 ServiceType
- NodePort:通過每個 Node 上的 IP 和靜態端口(NodePort)暴露服務。NodePort 服務會路由到 ClusterIP 服務,這個 ClusterIP 服務會自動創建。通過請求 <NodeIP>:<NodePort>,可以從集群的外部訪問一個 NodePort 服務
- LoadBalancer:使用云提供商的負載均衡器,可以向外部暴露服務。外部的負載均衡器可以路由到 NodePort 服務和 ClusterIP 服務。
- ExternalName:通過返回 CNAME 和它的值,可以將服務映射到 externalName 字段的內容(例如, foo.bar.example.com)。 沒有任何類型代理被創建,這只有 Kubernetes 1.7 或更高版本的 kube-dns 才支持。
- 一個Node Port 的簡單示例
```
apiVersion: vl
kind: Service
metadata;
name: tomcat-service
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31002
selector:
tier: frontend
```
- # Volume 存儲卷
- 簡述
我們知道默認情況下容器的數據都是非持久化的,在容器消亡以后數據也跟著丟失,所以Docker提供了Volume機制以便將數據持久化存儲。類似的,Kubernetes提供了更強大的Volume機制和豐富的插件,解決了容器數據持久化和容器間共享數據的問題
1. - Volume
目前,Kubernetes支持以下Volume類型:
```
- emptyDir
- hostPath
- gcePersistentDisk
- awsElasticBlockStore
- nfs
- iscsi
- flocker
- glusterfs
- rbd
- cephfs
- gitRepo
- secret
- persistentVolumeClaim
- downwardAPI
- azureFileVolume
- vsphereVolume
- flexvolume
```
> 注意,這些volume并非全部都是持久化的,比如emptyDir、secret、gitRepo等,這些volume會隨著Pod的消亡而消失
2. - PersistentVolume
對于持久化的Volume,PersistentVolume (PV)和PersistentVolumeClaim (PVC)提供了更方便的管理卷的方法:PV提供網絡存儲資源,而PVC請求存儲資源。這樣,設置持久化的工作流包括配置底層文件系統或者云數據卷、創建持久性數據卷、最后創建claim來將pod跟數據卷關聯起來。PV和PVC可以將pod和數據卷解耦,pod不需要知道確切的文件系統或者支持它的持久化引擎。
3. - PV
PersistentVolume(PV)是集群之中的一塊網絡存儲。跟 Node 一樣,也是集群的資源。PV 跟 Volume (卷) 類似,不過會有獨立于 Pod 的生命周期。比如一個本地的PV可以定義為
```
kind: PersistentVolume
apiVersion: v1
metadata:
name: grafana-pv-volume
labels:
type: local
spec:
storageClassName: grafana-pv-volume
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
hostPath:
path: "/data/volume/grafana"
```
pv的訪問模式有三種
- 第一種,ReadWriteOnce:是最基本的方式,可讀可寫,但只支持被單個Pod掛載。
- 第二種,ReadOnlyMany:可以以只讀的方式被多個Pod掛載。
- 第三種,ReadWriteMany:這種存儲可以以讀寫的方式被多個Pod共享。不是每一種存儲都支持這三種方式,像共享方式,目前支持的還比較少,比較常用的是NFS。在PVC綁定PV時通常根據兩個條件來綁定,一個是存儲的大小,另一個就是訪問模式
4. - StorageClass
上面通過手動的方式創建了一個NFS Volume,這在管理很多Volume的時候不太方便。Kubernetes還提供了StorageClass來動態創建PV,不僅節省了管理員的時間,還可以封裝不同類型的存儲供PVC選用。
- Ceph RBD的例子:
```
apiVersion: storage.k8s.io/v1beta1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/rbd
parameters:
monitors: 10.16.153.105:6789
adminId: kube
adminSecretName: ceph-secret
adminSecretNamespace: kube-system
pool: kube
userId: kube
userSecretName: ceph-secret-user
```
5. - PVC
PV是存儲資源,而PersistentVolumeClaim (PVC) 是對PV的請求。PVC跟Pod類似:Pod消費Node的源,而PVC消費PV資源;Pod能夠請求CPU和內存資源,而PVC請求特定大小和訪問模式的數據卷。
```
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: grafana-pvc-volume
namespace: "monitoring"
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: grafana-pv-volume
```
PVC可以直接掛載到Pod中:
```
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: dockerfile/nginx
volumeMounts:
- mountPath: "/var/www/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: grafana-pvc-volume
```
6. - 其他volume 說明
- NFS
NFS 是Network File System的縮寫,即網絡文件系統。Kubernetes中通過簡單地配置就可以掛載NFS到Pod中,而NFS中的數據是可以永久保存的,同時NFS支持同時寫操作。
```
volumes:
- name: nfs
nfs:
# FIXME: use the right hostname
server: 10.254.234.223
path: "/data"
```
- emptyDir
如果Pod配置了emptyDir類型Volume, Pod 被分配到Node上時候,會創建emptyDir,只要Pod運行在Node上,emptyDir都會存在(容器掛掉不會導致emptyDir丟失數據),但是如果Pod從Node上被刪除(Pod被刪除,或者Pod發生遷移),emptyDir也會被刪除,并且永久丟失。
```
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: gcr.io/google_containers/test-webserver
name: test-container
volumeMounts:
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
emptyDir: {}
```
- # namespace
- 簡述
在一個Kubernetes集群中可以使用namespace創建多個“虛擬集群”,這些namespace之間可以完全隔離,也可以通過某種方式,讓一個namespace中的service可以訪問到其他的namespace中的服務,我們在CentOS中部署kubernetes1.6集群的時候就用到了好幾個跨越namespace的服務,比如Traefik ingress和kube-systemnamespace下的service就可以為整個集群提供服務,這些都需要通過RBAC定義集群級別的角色來實現。
- 哪些情況下適合使用多個namesapce
因為namespace可以提供獨立的命名空間,因此可以實現部分的環境隔離。當你的項目和人員眾多的時候可以考慮根據項目屬性,例如生產、測試、開發劃分不同的namespace。
- Namespace使用,獲取集群中有哪些namespace
```kubectl get ns ```
集群中默認會有default和kube-system這兩個namespace。
在執行kubectl命令時可以使用-n指定操作的namespace。
用戶的普通應用默認是在default下,與集群管理相關的為整個集群提供服務的應用一般部署在kube-system的namespace下,例如我們在安裝kubernetes集群時部署的kubedns、heapseter、EFK等都是在這個namespace下面。
另外,并不是所有的資源對象都會對應namespace,node和persistentVolume就不屬于任何namespace。
---
# CI/CD 部署應用
### 流程說明
應用構建和發布流程說明。
1. 用戶向Gitlab提交代碼,代碼中必須包含Dockerfile
1. 將代碼提交到遠程倉庫
1. 用戶在發布應用時需要填寫git倉庫地址和分支、服務類型、服務名稱、資源數量、實例個數,確定后觸發Jenkins自動構建
1. Jenkins的CI流水線自動編譯代碼并打包成docker鏡像推送到Harbor鏡像倉庫
1. Jenkins的CI流水線中包括了自定義腳本,根據我們已準備好的kubernetes的YAML模板,將其中的變量替換成用戶輸入的選項
1. 生成應用的kubernetes YAML配置文件
1. 更新Ingress的配置,根據新部署的應用的名稱,在ingress的配置文件中增加一條路由信息
1. 更新PowerDNS,向其中插入一條DNS記錄,IP地址是邊緣節點的IP地址。關于邊緣節點,請查看邊緣節點配置
1. Jenkins調用kubernetes的API,部署應用
- 第一章 kubernetes 功能介紹
- 第二章 在CentOS上部署kubernetes1.7.6集群
- 第三章 創建TLS證書和秘鑰
- 第四章 安裝kubectl命令行工具
- 第五章 創建kubeconfig 文件
- 第六章 etcd 集群部署
- 第七章 部署k8s-master-v1.7.6節點
- 第八章 部署k8s-v1.7.6 node 節點
- 第九章 kubectl 操作示例
- 第十章 在kubernetes 部署第一個應用
- 第十一章 kubernetes之pod 調度
- 第十二章 K8S服務組件之kube-dns&Dashboard
- 第十三章 Kubernetes中的角色訪問控制機制(RBAC)支持
- 第十四章 部署nginx ingress
- 第十五章 使用Prometheus監控Kubernetes集群和應用
- 第十六章 使用helm 應用部署工具
- 第十七章 kubernetes 從1.7 到1.8升級記錄
- 第十八章 在kubernetes 使用ceph
- 第十九章 基于 Jenkins 的 CI/CD(一)
- 第二十章 基于jenkins的CI/CD(二)
- 第二十一章 基于prometheus自定指標HPA彈性伸縮