
https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=402261356&idx=1&sn=f66ee62b002b8a9879d3c428f846e440&scene=21#wechat_redirect
[TOC]
深度學習計算密集,所以你需要一個快速多核CPU,對吧?還是說買一個快速CPU可能是種浪費?搭建一個深度學習系統時,最糟糕的事情之一就是把錢浪費在并非必需的硬件上。本文中,我將一步步帶你了解一個高性能經濟系統所需的硬件。
研究并行化深度學習過程中,我搭建了一個GPU集群,為此,我需要仔細挑選硬件。盡管經過了仔細的研究和邏輯推理,但是,挑選硬件時,我還是會犯相當多的錯誤,當我在實踐中應用集群時,錯誤就會顯現出來。下面就是我想分享的東西,希望你們可以不要再掉入同樣的陷阱。
****GPU****
在這篇博文中,我們假設你會利用GPU來進行深度學習。如果你正在構建或升級你的深度學習系統,忽視GPU是不理智的。GPU正是深度學習應用的核心要素——計算性能提升上,收獲巨大,不可忽視。
我在以前的博客中詳細談到過GPU的選擇,GPU的選擇也許是深度學習系統中最關鍵的選擇。當前市場上的GPU:通常來說,如果你缺錢,我推薦到eBay上購買GTX 680,或者GTX Titan X(如果你很有錢,用來做卷積),或者GTX 980(非常有性價比,但對于大型卷積神經網絡有點局限),另外如果你需要一個低成本的存儲則可以選擇GTX Titan。我之前支持過GTX 580,但是由于cnDNN庫的新升級大幅增加了卷積的速度,所有不支持cuDNN的GPU都得淘汰了——GTX 580就是這樣的一個GPU。如果你完全不使用卷積神經網絡,那么GTX 580仍然是一個可靠的選擇。

*Suspect line-up嫌疑人清單:你能夠識別哪個硬件是糟糕表現的罪魁禍首嗎?這些GPU之一?或者還是CPU的錯?*
****CPU****
為了能夠明智地選擇CPU我們首先需要理解CPU,以及它是如何與深度學習相關聯的,CPU能為深度學習做什么呢?當你在GPU上跑深度網絡時,CPU進行的計算很少,但是CPU仍然需要處理以下事情:
* 在代碼中寫入并讀取變量
* 執行指令,如函數調用
* 啟動在GPU上函數調用
* 創建小批量數據
* 啟動到GPU的數據傳輸
**所需CPU核的數量**
當我用三個不同的庫訓練深度學習網絡時,我經常觀察到一個CPU線程顯示100%(并且有時候另一個線程會在0-100%之間浮動),你會立刻知道大部分深度學習庫——以及實際上大部分通用軟件應用——僅僅只利用一個線程。這意味著多核CPU非常無用。但如果你運行多GPU,并使用像MPI一樣的并行化框架,那么你就同時運行了多個程序,你也會需要多個線程。每個GPU跑一個線程還不錯,但是每個GPU跑兩個線程對于大部分深度學習庫來說能夠帶來更好的表現;這些庫在單核上運行,但是某些時候調用異步函數則會用到第二個CPU線程。記住許多CPU能夠在每一個核上運行多個線程(尤其對于Intel的CPU來說),因此每個GPU對應一個CPU核通常就夠了。
**CPU與PCI-Express**
這里是個陷阱!一些新型號Haswell CPU并不支持全部40個PCIe通道,而舊的CPU則可以——避免這些CPU,如果你希望建立一個多GPU的系統。并且確保你的處理器確定能夠支持PCIe3.0,如果你的主板采用PCIe 3.0。
**CPU緩存大小**
正如我們之后會看到的,CPU緩存大小與CPU-GPU下游管道運算沒有關聯,但是我會用一個簡短的部分來說明,這樣我們就可以確定計算管道上每個可能的瓶頸都被考慮在內,從而全面理解整個過程。
人們購買CPU時經常會忽視緩存這個問題,但是通常來說,它在整個性能問題中是非常重要的一部分。CPU緩存是容量非常小的直接位于CPU芯片上的存儲,物理位置非常接近CPU,能夠用來進行高速計算和操作。CPU通常有緩存分級,從小型高速緩存(L1,L2)到低速大型緩存(L3,L4)。作為一個程序員,你可以將它想成一個哈希表,每條數據都是一個鍵值對(key-value-pair),可以高速的基于特定鍵進行查找:如果找到,就可以在緩存得值中進行快速讀取和寫入操作;如果沒有找到(被稱為緩存未命中),CPU需要等待RAM趕上,之后再從內存進行讀值——一個非常緩慢的過程。重復的緩存未命中會導致性能的大幅下降。有效的CPU緩存方案與架構對于CPU性能來說非常關鍵。
CPU是如何決定它的緩存方案是一個復雜的話題,但是通常來說,重復使用的變量、指令和內存RAM地址會保存在緩存中,而不經常出現的則不會。
在深度學習中,對于每一個小批量數據單元相同的內存范圍會重復進行讀取直至送至GPU(同時這塊內存范圍會被新數據覆蓋),但是內存數據是否能夠被存儲在緩存中則取決于小批量單元大小。對于128的小批量單元的大小,我們會有相對應的0.4MB的MNIST數據與1.5MB的CIFAR數據,能夠放入大部分CPU緩存。對于ImageNet來說,我們每個小批量單元有超過85MB的數據,這即使對于最大的緩存(L3緩存僅僅有幾個MB)來說也實在太大了。
由于通常數據集對于緩存太過巨大,每一批新的小批量處理單元數據都需要從內存RAM中進行讀取——因此對內存RAM的訪問是持續在進行。
內存RAM記憶地址存儲于緩存中(CPU能夠在緩存中迅速查找,指出數據在RAM中的確切地址),但是這只在整個數據集都存儲于RAM的時候才能如此,否則記憶地址會改變,緩存也不會加速(你可能會想利用固定保留地址避免這種情況,但是就像你之后會看到的,其實這也沒有意義)。
深度學習代碼的其他部分——例如變量與函數調用——則會從緩存中受益,但是這些通常都數量很少,并且很容易就存儲于幾乎所有CPU的小型快速L1緩存中。
從這些推論中可以總結一下,CPU緩存大小并不是很重要,下一部分的深層分析則會繼續闡述這個結論。
**尋找合適的CPU時鐘頻率(頻率)**
當人們想到快速的CPU時,他們一般最先想到其時鐘頻率(clock rate)。4GHz比3.5GHz快,是這樣嗎?在比較具有相同架構的處理器時,這一般是對的,例如「第三代酷睿處理器」(Ivy Bridge)。但在比較不同架構的處理器時,這個想法卻不那么正確。而且這也不總是對于性能的最好測量指標。
在深度學習中,只有很少一部分的計算會用CPU來運行:增值幾個變量、評估幾個布爾表達式、在GPU或在編程里面調用幾個函數——所有這些會取決于CPU核的頻率。
這種推理似乎是合理的,但當我運行深度學習編程的時候,CPU會有100%的使用率,那這是怎么回事兒?為了找出原因,我做了一些CPU核頻率降頻的實驗。

*CPU降頻后在MNIST及ImageNet的表現:使用不同的CPU核頻率,將MNIST數據集運行200遍或遍歷1/4的ImageNet數據集運行作為測量時間,我們測量CPU的性能,其中我們將每個CPU的最高頻率定位參照線。對于比較:在性能上,GTX Titan比GTX 680提升了15%;GTX 980比GTX Titan提升了20%;GPU超頻比任何GPU提升了5%。*
問題是:為什么當CPU核頻率是無關緊要的的時候,它會用上100%的使用率?答案可能是CPU的高速緩存未命中:一般情況下,CPU會不斷忙于訪問RAM,與此同時,它需要一直等待頻率較慢的RAM跟上步伐,因此這可能導致了即忙碌著等待中的矛盾狀態。如果真是這樣,將CPU核降頻將不會導致其性能的大幅降低——正如你在上面看到的結果。
CPU也執行其他一些操作,如將數據抄到微型批次里,并將數據準備好以便復制到GPU,但這些操作其實只取決于內存頻率,而不是CPU核頻率。所以我們現在來看看內存。
**尋找合適的RAM頻率**
CPU-RAM以及其他設備與RAM的互動都式非常復雜的。我在這兒會給出該互動過程的一個簡化版。為了得到一個更為全面的理解,讓我們潛入其中并剖析從CPU RAM 到 GPU RAM的這一過程。
CPU的內存頻率與RAM是相互交織的。CPU的內存頻率決定了RAM的最大頻率,并且這兩個東西結合起來構成了CPU整體內存的帶寬。但通常RAM本身決定了整體可使用的帶寬,因為它可以比CPU的內存頻率更慢。你可以如此決定帶寬,其中64是64位的CPU結構。而我的處理器及RAM模塊的帶寬是51.2GB/s。

那么這與深度學習程序有什么關系?我剛剛說帶寬有可能是重要的,但在下一個步驟中,它還不是那么重要。RAM的帶寬決定了小批次數據對應內存被覆蓋并被分配來啟動一次到GPU數據傳輸上有多快,但在下一個步驟,從 CPU-RAM到GPU-RAM,才真正是瓶頸了,此步驟利用了直接存儲器存取(DMA)。正如上面所引述的,我的RAM模塊的內存帶寬是51.2GB/s,但DMA帶寬卻只有12GB/s!
DMA帶寬與一般的帶寬相關,但細節是不太需要知道的,你可以看看這個維基百科條目(http://en.wikipedia.org/wiki/DDR3_SDRAM#JEDEC_standard_modules),你能在此查閱RAM模塊的DMA帶寬(峰值傳輸限制)。但先讓我們看看DMA是如何工作的。
**直接存儲存取(DMA)**
CPU和其對應的RAM只能透過DMA與GPU通信。第一步,一個特定的DMA傳輸緩沖器在CPU RAM 及 GPU RAM里被保留;第二步,CPU將所請求的數據寫入CPU那邊的DMA緩沖器里;第三步,受保留的緩沖器在沒有CPU的幫助下被轉移到GPU RAM里。你的PCIe的帶寬是8GB/s (PCIe 2.0) 或是 15.75GB/s (PCIe 3.0),所以你需要買一個像上面所說的,具有良好峰值傳輸限制的RAM嗎?
未必。軟件在這里起著很大的作用。如果你用聰明的方法來做一些傳輸的話,你將可以能利用更便宜更慢的內存來完成任務。
**異步的微批次分配**
一旦你的GPU在當前的微批次中完成計算,它希望馬上計算下一微批次。現在你當然可以初始化一個DMA傳輸,然后等待傳輸完成以使你的GPU可以繼續運算。但有一個更有效的方法:提前準備好下一批微批次以便讓你的GPU完全不再需要等待。這可以輕易并異步地完成來確保發揮出GPU的性能。

*異步迷你批次分配的CUDA代碼:當GPU開始處理當前批次時,頭兩個調用被執行;當GPU處理完當前批次以后,最后兩個調用被執行。數據傳輸早在數據流在第二步被同步的時候完成了,所以GPU可以無延遲的開始處理下一個批次。*
在ImageNet 2012,對于Alex Krishevsky的卷積網絡,一個大小為128的迷你批次只用了0.35秒就進行了一次完整的反向傳播。我們能在這么短的時間里分配下一個批次嗎?
如果我們采用大小為128的批次及維度為244x244x3的數據,大概總量為0.085 GB。采用超慢內存,我們也有6.4GB/s的速度,或換句話說,每秒75迷你批次!所以有了異步迷你批次分配,即使是最慢的RAM對于應付深度學習也是綽綽有余了。只要采用了異步迷你批次分配,買較快的RAM模塊將沒有任何好處。
這個過程還間接意味著CPU緩存是不相關的。對于DMA傳輸來說,CPU可以多快改寫(在高速緩存中)及準備(將緩存寫入RAM)一個迷你批次是無關緊要的,因為整個傳輸早在GPU要求下一個迷你批次前就完成了——所以大型緩存真的不是那么重要。
因此底線是RAM的頻率是不相關的。買那些便宜的吧——故事完結。
但你需要購買多少呢?
****內存大小****
你應該擁有至少和你的GPU內存大小相同的內存。你能用更小的內存工作,但是,你或許需要一步步轉移數據。不過,就我個人經驗而言,內存越大,工作起來越舒服。
心理學家告訴我們,專注力這種資源會隨著時間的推移而逐漸耗盡。內存就是為數不多的,讓你保存注意力資源,以解決更困難編程問題的硬件之一。與其在內存瓶頸上兜轉,浪費時間,不如把注意力放在更加緊迫的問題上,如果你有更多的內存。有了這一前提條件,你可以避免那些瓶頸,節約時間,在更緊迫問題上投入更多的生產力。特別是在Kaggle競賽中,我發現,額外的內存對特征工程非常有用。所以,如果你有錢而且需要做很多預處理工作,那么,額外內存將會是不錯的選擇。
****硬盤驅動器/SSD****
在一些深度學習案例中,硬驅會成為明顯的瓶頸。如果你的數據組很大,通常會在硬驅上放一些數據,內存中也放一些,GPU內存中也放兩mini-batch。為了持續供給GPU,我們需要以GPU能夠跑完這些數據的速度提供新的mini-batch。
為此,我們需要采用和異步mini-batch分配一樣的思路。用多重mini-batch異步讀取文件 ——這真的很重要!如果不異步處理,結果表現會被削弱很多(5-10%),而且讓你認真打造的硬件優勢蕩然無存 ——在GTX680上,好的深度學習軟件跑起來會快得多,勝過GTX980上的糟糕的深度學習軟件。
出于這種考慮,如果我們將數據保存為32比特浮點數據,我們會遇到Alex參加ImageNet 所使用的卷積網絡遇到的數據傳輸速率問題,大約每0.3秒0.085GB,計算如下:

或每秒290MB。
不過,如果我們將它保存為jpeg數據,我們就能將它壓縮5-15倍,將所需讀取帶寬降低到大約30MB每秒。
類似,一個人能夠使用mp3或者其他壓縮技巧來處理聲音文件,但是,對于其他處理原始32比特浮點數據的數據組來說,不可能很好地壓縮數據:我們只能壓縮32比特的浮點數據的10-15%。因此,如果你有大的32比特數據組,那么,你肯定需要SSD,因為100-150MB/S的硬驅會很慢,不足以跟上你的GPU——因此,如果你的工作需要處理這樣的數據,買個SSD吧,否則的話,普通硬驅就夠了。
許多人買一個SSD是為了舒服:程序開始和響應都快多了,大文件預處理也快很多,但是,對于深度學習來說,僅當你的輸入維數很高,不能充分壓縮數據時,這才是必須的。
如果你買了SSD,你應該選擇能夠存下和你通常要處理的數據集大小相當的存儲容量,也額外留出數十GB的空間。另外用普通硬驅保存你尚未使用的數據集的主意也不錯。
****電源供應設備(PSU)****
一般說來,你需要一個給你未來所有GPU充足供應的PSU。隨著時間的推移,GPU通常會更加高效節能;因此,盡管其他組件會需要更換,PSU會用很久,一個好的PSU是一個好的投資。
CPU加上GPU所需瓦特,再加上其他組件額外所需以及作為電力峰值緩沖的100-300瓦特,你就能計算出所需瓦特。
一個需要注意的重要部分就是,你的PSU的PCIe接頭是否支持帶有一條連接線的8pin+6pin接頭。我買過一個PSU,有6x PCIe端口,但是,僅適用于8pin或者6pin的接頭,所以,我沒法用那個PSU跑4個GPU。
另一個重要的事情就是買一個能效等級高的PSU,——特別是,如果你跑很多GPU而且還要跑比較久。
在全功率(1000-1500瓦特)上跑一個4 GPU系統,訓練一個卷積網絡兩個禮拜,耗能300-500kWh,在德國——電力成本更高,每kWh多出20美分——會花60到100歐元(66到111美元)。如果這是百分百高效節能的價格,那么,用80%的電源供應來訓練這樣一個網絡,成本將額外增加18到26歐元。對于1個GPU來說,花費就少很多,但是,仍要抓住要點 ——將更多的錢花在高效電源供應上,很有意義。
****散熱****
散熱十分重要,這更有可能成為一個大瓶頸,比糟糕的硬件選擇更能降低系統表現。你可能會滿足于給CPU配一個標準的散熱片,但是,要給你的GPU配些什么東西,需要特別的考量。
當現代的GPU運行一個算法時,它會一直加速至最大極限,同時加速的還有能量消耗,但當到達它的溫度壁壘,通常是80攝氏度,它就會降低運行速度來避免打破臨界溫度。在保護GPU避免過熱、情況安全的同時,也讓GPU達到最佳狀態。
但是,典型的電扇速度設置是被預編程的,完全不是為運行深度學習項目而設計的,所以,在開始深度學習程序后的幾秒內就會達到其溫度壁壘。結果,GPU的運行效果下降(幾個百分比),如果有好幾個GPU,由于GPU之間會相互加熱,那么,整體效果的下降幅度就會非常明顯(10-25%)。
由于NVIDIA GPU是首屈一指的電競GPU,它們非常適應Windows系統的運作。Windows系統中,你可以通過幾個簡單的按鍵改變風扇的設置,但在Linux系統中不行,不過,多數深度學習庫都是在Linux環境下運行的,所以,這會導致問題出現。
最容易且性價比最高的變通方案就是,用一個有更合理風扇設定的BIOS程序更新GPU以提升速度,這樣就能保持GPU涼爽的同時,噪聲也不至于不可接受(如果你用服務器解決這個問題,那么,為了避免難以忍受的噪聲,你很可能會在風扇運行速度上打折)。也可能超速運行GPU的存儲器,這會有一些噪聲(30-50兆赫),這也是相對可行的方法。更新BIO的軟件是一個在Windows系統下設計的程序,但可以用wine操作系統從Linux/Unix OS中調用這個程序。
另一個選擇是為你的Xorg 服務器(Ubuntu操作系統)設置配置(set a configuration),在這個Xorg 服務器中,設置「coolbits」選項。在只有一臺GPU的時候這個方法非常有效,但如果對多臺GPU,也就是說有「無頭(headless)」GPU,比如這些「無頭」GPU沒有連顯示器,那么,就必須模擬一臺顯示器,但模擬顯示器難度非常之高。我曾試了很久,無比沮喪的花了數個小時,用實時(live)啟動光盤恢復我的圖形設置,始終沒法讓這個程序在「無頭」GPU上正常運轉。
還有一個方法花費較高也較為復雜,就是用水冷卻。應用于單GPU時,即使是最大功率的情況,也幾乎可以將溫度減半,所以永遠不會達到溫度壁壘。就算是面對空氣降溫無法應對的多GPU情況,也可以很好的降溫。用水降溫的另一個好處是,它運行時產生的噪音較少,如果你處在一個與他們共同工作的環境下,這將帶來極大的方便。水冷卻法花費大約為每GPU100美元左右,前期大概要額外投入50美元。水冷卻法還需要另花一些精力組裝電腦,對于這方面可以找到很多詳盡實用的指南手冊,且花不了幾個小時。維護期間就會簡單方便許多了。
從我的經驗來看,這些是比較對癥下藥的方法。我為我的深度學習組團買過大型的塔型機箱,因為他們在GPU的區域有另加的風扇,但我發現,這并沒有太大的作用,大約只降低了2-5攝氏度,不值得為此花這么多錢還得忍受笨重的機箱。最重要的還是直接作用于GPU的降溫措施:更新BIOS,水冷法或忍受打了一定折扣的運行效果,在某些場合下,這些都是非常有效的應對方式,你可以根據自己需要找到合適的應對方式。
****主板和電腦機箱****
你的主板要有足夠的PCIe接口,來支持你希望同時運行的GPU(通常局限于4臺GPU,即使主板上有很多PCIe槽。記住,多數GPU都需要占2個PCIe槽的寬度,例如,你會需要7個槽口來鏈接4臺GPU。PCIe2.0接口也是可以接受的,但PCIe3.0接口更加經濟,即使只對單GPU性價比也很高,如果對多GPU,通常都會使用PCIe3.0接口,這會對多GPU運作帶來很大的好處,因為PCIe的連接口多數情況下是個瓶頸所在。
主板的選擇策略十分直接:就選那款可以支持你想要的硬件配置的就行。
當你選擇機箱時,要確保它能滿足你GPU的長度要求,這樣它才能在主板上放穩。多數機箱都能滿足要求,但如果你選的是一個小機箱,就需要多加留心。要核查它的面積和規格,你也可以嘗試用google的圖片搜索引擎,看看能不能找到GPU放在上面的圖片。
****顯示器****
我剛開始也覺得寫顯示器是件很滑稽的事,但他們確實會造成很大的影響,非常重要,不能忽視。
我在我的3'27英寸顯示器上付出了可能是我從未有過的大代價,買了幾個顯示器后,效率提高了很多。如果我只能用一臺顯示器,那我的效率肯定會大打折扣。別在這上面和自己過不去,如果你不能有效的運轉一個快速的深度學習系統,那它又有什么好處?
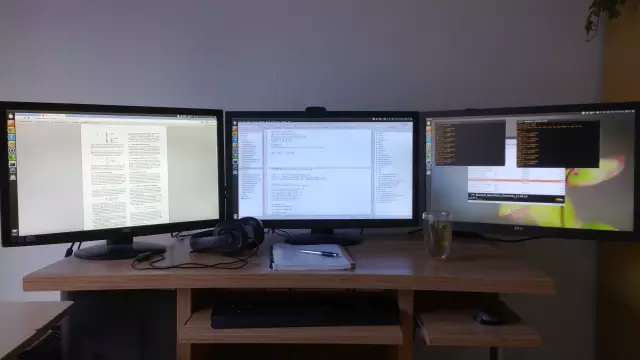
*我進行深度學習系統工作時,顯示器的典型布置一般是:Papers、Google搜索、gmail、stackoverflow網在左,中間是編程界面,右邊是輸出窗口、R、文件夾、系統顯示器、GPU顯示器、待辦事項以及一些其他小的應用。*
****組裝電腦的其他感言****
很多人都會被組裝電腦這個主意嚇到,硬件很貴,誰都不想花冤枉錢。但道理其實很簡單,本就不該裝在一起的硬件沒法湊合。手動主板上的每個組件都有特定的位置,如果你沒有經驗也可以找到很多指南、手把手的教程視頻教你。
關于組裝電腦有一個很大的好處就是,只要你組裝過一次,你就會知道各個組件的位置,因為電腦都是以非常相似的方法組建起來的——所以組裝電腦可以成為一個重復應用相伴一生的技能。還有什么理由不試一下呢!
****結論 / TL;DR****
**GPU**
GTX 680 或者GTX 960 (窮); GTX 980 (表現最佳); GTX Titan (如果你需要存儲器的話); GTX 970 (no convolutional nets)。
**CPU**
每個GPU 2個線程; 全套40 PCIe 線路和合適的PCIe 配件(和主板配套); > 2GHz; 快速緩沖儲存區不用太在意。
**內存**
使用異步mini-batch分配; 時鐘頻率和內存時序無關緊要;購買至少像GPU內存一樣多的CPU內存。
**硬驅**
**硬驅動/SSD**:使用異步batch-file讀取和壓縮數據,如果你有圖像或聲音數據;除非你處理的是帶有高輸入維度的32比特浮點數據組,否則,普通硬驅就可以了。
**PSU**
GPU+CPU+(100-300)就是你所需的電源供應量;如果你采用的是大的卷積網絡,那么,就買個能效級別高的;確保有足夠PCIe接頭(6+8pin),并足以支持你未來可能買入的GPU的運行。
**散熱**
如果運行單個GPU,在你的設置中設定「coolbits」flag;否則,更新BIOS和加快風扇轉速就是最便宜最簡單的辦法;需要降低噪音(與其他共處一室)時,用水來為你的多GPU散熱。
**主板**
選擇PCIe 3.0,帶有和你以后所需GPU數量一樣多的槽口(一個GPU需要兩個槽口;每個系統最多4個GPU)
**顯示器**
如果你想升級系統,讓它生產力更高,較之升級GPU,再買一臺顯示器會有意義得多。
(注:文章于2015年4月22日更新:去除了對GTX580的推薦。)
- 15張圖閱盡人工智能現狀
- LeCun臺大演講:AI最大缺陷是缺乏常識,無監督學習突破困境
- Google首席科學家談Google是怎么做深度學習的
- 為你的深度學習任務挑選性價比最高GPU
- 史上最全面的深度學習硬件指南
- 機器學習
- 普通程序員如何向人工智能靠攏?
- 從機器學習談起
- 普通程序員如何轉向AI方向
- 機器學習6大算法,優勢劣勢全解析
- 除了 Python ,這些語言寫的機器學習項目也很牛(二)
- 五個鮮為人知,但又不可不知的機器學習開源項目
- 機器學習入門算法:從線性模型到神經網絡
- 機器學習常見算法分類匯總
- 最實用的機器學習算法Top5
- NLP
- Lucene的原理和應用
- 理解和使用自然語言處理之終極指南(Python編碼)(經典收藏版12k字,附數據簡化籌技術人員)
- 神經網絡
- 曾經歷過兩次低谷的人工神經網絡,還會迎來下一個低谷么?
- 人工神經網絡——維基
- 深度學習——維基
- A Neural Network in 11 lines of Python (Part 1)
- 深度學習
- 基于深度學習的機器翻譯
- 谷歌研究員2萬字批駁上海交大用深度學習推斷犯罪分子
- 理解這25個概念,你的「深度學習」才算入門!
- Deep Learning(深度學習)學習筆記整理系列
- 概述、背景、人腦視覺機理
- 特征
- Deep Learning
- Deep Learning 訓練
- Deep Learning(中文)
- 第1章 引言
- 深度學習如何入門?——知乎
- 文章收錄
- 神經系統