
https://www.zhihu.com/question/26006703/answer/129209540
[TOC]
作者:jacky yang
鏈接:https://www.zhihu.com/question/26006703/answer/129209540
來源:知乎
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。
關于深度學習,網上的資料很多,不過貌似大部分都不太適合初學者。 這里有幾個原因: 1.深度學習確實需要一定的數學基礎。如果不用深入淺出地方法講,有些讀者就會有畏難的情緒,因而容易過早地放棄。 2.中國人或美國人寫的書籍或文章,普遍比較難一些。我不太清楚為什么,不過確實是這樣子的。
深度學習,確實需要一定的數學基礎,但真的那么難么?這個,還真沒有。不信?聽我來給你侃侃。看完,你也會覺得沒那么難了。
本文是針對初學者,高手可以無視,有不對的地方,還請多多批評指正。
這里,先推薦一篇非常不錯的文章: 《1天搞懂深度學習》,300多頁的ppt,臺灣李宏毅教授寫的,非常棒。 不夸張地說,是我看過最系統,也最通俗易懂的,關于深度學習的文章。
這是slideshare的鏈接: [http://www.slideshare.net/tw_dsconf/ss-62245351?qid=108adce3-2c3d-4758-a830-95d0a57e46bc&v=&b=&from_search=3](https://link.zhihu.com/?target=http%3A//www.slideshare.net/tw_dsconf/ss-62245351%3Fqid%3D108adce3-2c3d-4758-a830-95d0a57e46bc%26v%3D%26b%3D%26from_search%3D3)
沒梯子的同學,可以從我的網盤下: 鏈接:[http://pan.baidu.com/s/1nv54p9R](https://link.zhihu.com/?target=http%3A//pan.baidu.com/s/1nv54p9R) 密碼:3mty
要說先準備什么,私以為,其實只需要知道導數和相關的函數概念就可以了。高等數學也沒學過?很好,我就是想讓文科生也能看懂,您只需要學過初中數學就可以了。
其實不必有畏難的情緒,個人很推崇李書福的精神,在一次電視采訪中,李書福說:誰說中國人不能造汽車?造汽車有啥難的,不就是四個輪子加兩排沙發嘛。當然,他這個結論有失偏頗,不過精神可嘉。
導數是什么,無非就是變化率唄,王小二今年賣了100頭豬,去年賣了90頭,前年賣了80頭。。。變化率或者增長率是什么?每年增長10頭豬,多簡單。這里需要注意有個時間變量---年。王小二賣豬的增長率是10頭/年,也就是說,導數是10. 函數y=f(x)=10x+30,這里我們假設王小二第一年賣了30頭,以后每年增長10頭,x代表時間(年),y代表豬的頭數。 當然,這是增長率固定的情形,現實生活中,很多時候,變化量也不是固定的,也就是說增長率也不是恒定的。比如,函數可能是這樣: y=f(x)=5x2+30,這里x和y依然代表的是時間和頭數,不過增長率變了,怎么算這個增長率,我們回頭再講。或者你干脆記住幾個求導的公式也可以。
深度學習還有一個重要的數學概念:偏導數,偏導數的偏怎么理解?偏頭疼的偏,還是我不讓你導,你偏要導?都不是,我們還以王小二賣豬為例,剛才我們講到,x變量是時間(年),可是賣出去的豬,不光跟時間有關啊,隨著業務的增長,王小二不僅擴大了養豬場,還雇了很多員工一起養豬。所以方程式又變了:y=f(x)=5x?2+8x? + 35x? +30 這里x?代表面積,x?代表員工數,當然x?還是時間。 上面我們講了,導數其實就是變化率,那么偏導數是什么?偏導數無非就是多個變量的時候,針對某個變量的變化率唄。在上面的公式里,如果針對x?求偏導數,也就是說,員工對于豬的增長率貢獻有多大,或者說,隨著(每個)員工的增長,豬增加了多少,這里等于35---每增加一個員工,就多賣出去35頭豬. 計算偏導數的時候,其他變量都可以看成常量,這點很重要,常量的變化率為0,所以導數為0,所以就剩對35x? 求導數,等于35\. 對于x?求偏導,也是類似的。 求偏導我們用一個符號 表示:比如 y/ x? 就表示y對 x?求偏導。
廢話半天,這些跟深度學習到底有啥關系?有關系,我們知道,深度學習是采用神經網絡,用于解決線性不可分的問題。關于這一點,我們回頭再討論,大家也可以網上搜一下相關的文章。我這里主要講講數學與深度學習的關系。先給大家看幾張圖:
<img src="https://pic3.zhimg.com/v2-91704850c698cbe0cdfd0af76d328ebe_b.png" data-rawwidth="631" data-rawheight="488" class="origin_image zh-lightbox-thumb" width="631" data-original="https://pic3.zhimg.com/v2-91704850c698cbe0cdfd0af76d328ebe_r.png">
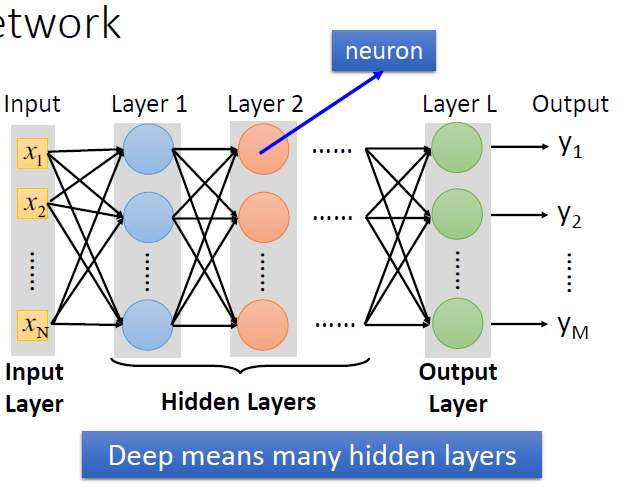
圖1\. 所謂深度學習,就是具有很多個隱層的神經網絡。
<img src="https://pic4.zhimg.com/v2-7875411304340d5accd6d800be9f933b_b.jpg" data-rawwidth="432" data-rawheight="576" class="origin_image zh-lightbox-thumb" width="432" data-original="https://pic4.zhimg.com/v2-7875411304340d5accd6d800be9f933b_r.jpg">
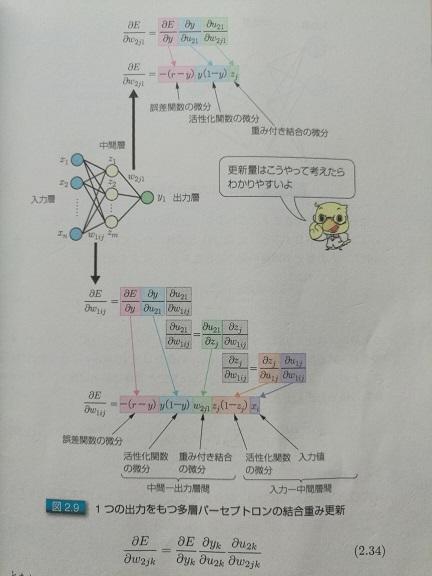
圖2.單輸出的時候,怎么求偏導數
<img src="https://pic2.zhimg.com/v2-c52b1fcdd42c3ac413120b56e40a8619_b.jpg" data-rawwidth="432" data-rawheight="576" class="origin_image zh-lightbox-thumb" width="432" data-original="https://pic2.zhimg.com/v2-c52b1fcdd42c3ac413120b56e40a8619_r.jpg">
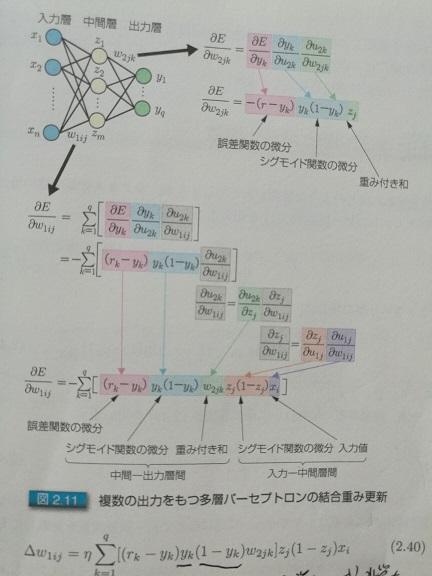
圖3.多輸出的時候,怎么求偏導數。后面兩張圖是日語的,這是日本人寫的關于深度學習的書。感覺寫的不錯,把圖盜來用一下。所謂入力層,出力層,中間層,分別對應于中文的:輸入層,輸出層,和隱層。
大家不要被這幾張圖嚇著,其實很簡單的。干脆再舉一個例子,就以撩妹為例。男女戀愛我們大致可以分為三個階段: 1.初戀期。相當于深度學習的輸入層。別人吸引你,肯定是有很多因素,比如:身高,身材,臉蛋,學歷,性格等等,這些都是輸入層的參數,對每個人來說權重可能都不一樣。 2.熱戀期。我們就讓它對應于隱層吧。這個期間,雙方各種磨合,柴米油鹽醬醋茶。 3.穩定期。對應于輸出層,是否合適,就看磨合得咋樣了。
大家都知道,磨合很重要,怎么磨合呢?就是不斷學習訓練和修正的過程嘛!比如女朋友喜歡草莓蛋糕,你買了藍莓的,她的反饋是negative,你下次就別買了藍莓,改草莓了。 ------------------------------------------------------------------------------------------------ 看完這個,有些小伙可能要開始對自己女友調參了。有點不放心,所以補充一下。 撩妹和深度學習一樣,既要防止欠擬合,也要防止過擬合。所謂欠擬合,對深度學習而言,就是訓練得不夠,數據不足,就好比,你撩妹經驗不足,需要多學著點,送花當然是最基本的了,還需要提高其他方面,比如,提高自身說話的幽默感等,因為本文重點并不是撩妹,所以就不展開講了。這里需要提一點,欠擬合固然不好,但過擬合就更不合適了。過擬合跟欠擬合相反,一方面,如果過擬合,她會覺得你有陳冠希老師的潛質,更重要的是,每個人情況不一樣,就像深度學習一樣,訓練集效果很好,但測試集不行!就撩妹而言,她會覺得你受前任(訓練集)影響很大,這是大忌!如果給她這個映象,你以后有的煩了,切記切記! ------------------------------------------------------------------------------------------------
深度學習也是一個不斷磨合的過程,剛開始定義一個標準參數(這些是經驗值。就好比情人節和生日必須送花一樣),然后不斷地修正,得出圖1每個節點間的權重。為什么要這樣磨合?試想一下,我們假設深度學習是一個小孩,我們怎么教他看圖識字?肯定得先把圖片給他看,并且告訴他正確的答案,需要很多圖片,不斷地教他,訓練他,這個訓練的過程,其實就類似于求解神經網絡權重的過程。以后測試的時候,你只要給他圖片,他就知道圖里面有什么了。
所以訓練集,其實就是給小孩看的,帶有正確答案的圖片,對于深度學習而言,訓練集就是用來求解神經網絡的權重的,最后形成模型;而測試集,就是用來驗證模型的準確度的。
對于已經訓練好的模型,如下圖所示,權重(w1,w2...)都已知。
<img src="https://pic1.zhimg.com/v2-8521e1fa289e08dbbab5aa63b6527bd4_b.png" data-rawwidth="940" data-rawheight="736" class="origin_image zh-lightbox-thumb" width="940" data-original="https://pic1.zhimg.com/v2-8521e1fa289e08dbbab5aa63b6527bd4_r.png">
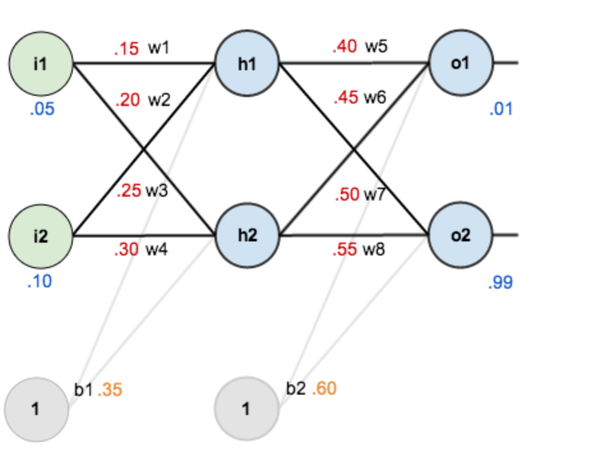
圖4
<img src="https://pic4.zhimg.com/v2-ef5ad0d06a316f762f0625b2468e2f43_b.png" data-rawwidth="776" data-rawheight="174" class="origin_image zh-lightbox-thumb" width="776" data-original="https://pic4.zhimg.com/v2-ef5ad0d06a316f762f0625b2468e2f43_r.png">
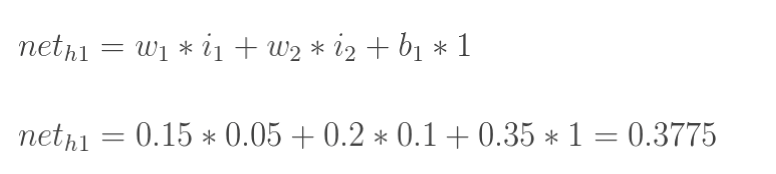
圖5
我們知道,像上面這樣,從左至右容易算出來。但反過來呢,我們上面講到,測試集有圖片,也有預期的正確答案,要反過來求w1,w2......,怎么辦?
繞了半天,終于該求偏導出場了。目前的情況是:
1.我們假定一個神經網絡已經定義好,比如有多少層,都什么類型,每層有多少個節點,激活函數(后面講)用什么等。這個沒辦法,剛開始得有一個初始設置(大部分框架都需要define-and-run,也有部分是define-by-run)。你喜歡一個美女,她也不是剛從娘胎里出來的,也是帶有各種默認設置的。至于怎么調教,那就得求偏導。
2.我們已知正確答案,比如圖2和3里的r,訓練的時候,是從左至右計算,得出的結果為y,r與y一般來說是不一樣的。那么他們之間的差距,就是圖2和3里的E。這個差距怎么算?當然,直接相減是一個辦法,尤其是對于只有一個輸出的情況,比如圖2; 但很多時候,其實像圖3里的那樣,那么這個差距,一般可以這樣算,當然,還可以有其他的評估辦法,只是函數不同而已,作用是類似的:
<img src="https://pic4.zhimg.com/v2-e5ddd26d65aa04ed82f2a51fc8212427_b.png" data-rawwidth="484" data-rawheight="102" class="origin_image zh-lightbox-thumb" width="484" data-original="https://pic4.zhimg.com/v2-e5ddd26d65aa04ed82f2a51fc8212427_r.png">
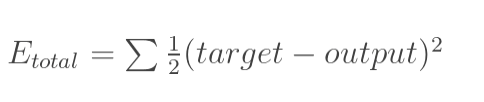
不得不說,理想跟現實還是有差距的,我們當然是希望差距越小越好,怎么才能讓差距越來越小呢?得調整參數唄,因為輸入(圖像)確定的情況下,只有調整參數才能改變輸出的值。怎么調整,怎么磨合?剛才我們講到,每個參數都有一個默認值,我們就對每個參數加上一定的數值?,然后看看結果如何?如果參數調大,差距也變大,你懂的,那就得減小?,因為我們的目標是要讓差距變小;反之亦然。所以為了把參數調整到最佳,我們需要了解誤差對每個參數的變化率,這不就是求誤差對于該參數的偏導數嘛。
關鍵是怎么求偏導。圖2和圖3分別給了推導的方法,其實很簡單,從右至左挨個求偏導就可以。相鄰層的求偏導其實很簡單,因為是線性的,所以偏導數其實就是參數本身嘛,就跟求解x?的偏導類似。然后把各個偏導相乘就可以了。
這里有兩個點:
這里有兩個點:一個是激活函數,這主要是為了讓整個網絡具有非線性特征,因為我們前面也提到了,很多情況下,線性函數沒辦法對輸入進行適當的分類(很多情況下識別主要是做分類),那么就要讓網絡學出來一個非線性函數,這里就需要激活函數,因為它本身就是非線性的,所以讓整個網絡也具有非線性特征。另外,激活函數也讓每個節點的輸出值在一個可控的范圍內,這樣計算也方便。
貌似這樣解釋還是很不通俗,其實還可以用撩妹來打比方;女生都不喜歡白開水一樣的日子,因為這是線性的,生活中當然需要一些浪漫情懷了,這個激活函數嘛,我感覺類似于生活中的小浪漫,小驚喜,是不是?相處的每個階段,需要時不時激活一下,制造點小浪漫,小驚喜,比如;一般女生見了可愛的小杯子,瓷器之類都邁不開步子,那就在她生日的時候送一個特別樣式,要讓她感動得想哭。前面講到男人要幽默,這是為了讓她笑;適當的時候還要讓她激動得哭。一哭一笑,多整幾個回合,她就離不開你了。因為你的非線性特征太強了。
當然,過猶不及,小驚喜也不是越多越好,但完全沒有就成白開水了。就好比每個layer都可以加激活函數,當然,不見得每層都要加激活函數,但完全沒有,那是不行的。
由于激活函數的存在,所以在求偏導的時候,也要把它算進去,激活函數,一般用sigmoid,也可以用Relu等。激活函數的求導其實也非常簡單:
<img src="https://pic2.zhimg.com/v2-a9311523c35a3558844d1edc22cee9ed_b.jpg" data-rawwidth="257" data-rawheight="159" class="content_image" width="257">
求導: f'(x)=f(x)*[1-f(x)] 這個方面,有時間可以翻看一下高數,沒時間,直接記住就行了。 至于Relu,那就更簡單了,就是f(x) 當x<0的時候y等于0,其他時候,y等于x。 當然,你也可以定義你自己的Relu函數,比如x大于等于0的時候,y等于0.01x,也可以。
另一個是學習系數,為什么叫學習系數?剛才我們上面講到?增量,到底每次增加多少合適?是不是等同于偏導數(變化率)?經驗告訴我們,需要乘以一個百分比,這個就是學習系數,而且,隨著訓練的深入,這個系數是可以變的。
當然,還有一些很重要的基本知識,比如SGD(隨機梯度下降),mini batch 和 epoch(用于訓練集的選擇),限于篇幅,以后再侃吧。其實參考李宏毅的那篇文章就可以了。
這篇拙文,算是對我另一個回答的補充吧: [深度學習入門必看的書和論文?有哪些必備的技能需學習? - jacky yang 的回答](https://www.zhihu.com/question/31785984/answer/129108774?from=profile_answer_card)
其實上面描述的,主要是關于怎么調整參數,屬于初級階段。上面其實也提到,在調參之前,都有默認的網絡模型和參數,如何定義最初始的模型和參數?就需要進一步深入了解。 不過對于一般做工程而言,只需要在默認的網絡上調參就可以了,相當于用算法; 對于學者和科學家而言,他們會發明算法,難度還是不小的。向他們致敬!
寫得很辛苦,覺得好就給我點個贊吧:)
------------------------------------------------------------------------------------------------
關于求偏導的推導過程,我盡快抽時間,把數學公式用通俗易懂的語言詳細描述一下,前一段時間比較忙,抱歉:)
- 15張圖閱盡人工智能現狀
- LeCun臺大演講:AI最大缺陷是缺乏常識,無監督學習突破困境
- Google首席科學家談Google是怎么做深度學習的
- 為你的深度學習任務挑選性價比最高GPU
- 史上最全面的深度學習硬件指南
- 機器學習
- 普通程序員如何向人工智能靠攏?
- 從機器學習談起
- 普通程序員如何轉向AI方向
- 機器學習6大算法,優勢劣勢全解析
- 除了 Python ,這些語言寫的機器學習項目也很牛(二)
- 五個鮮為人知,但又不可不知的機器學習開源項目
- 機器學習入門算法:從線性模型到神經網絡
- 機器學習常見算法分類匯總
- 最實用的機器學習算法Top5
- NLP
- Lucene的原理和應用
- 理解和使用自然語言處理之終極指南(Python編碼)(經典收藏版12k字,附數據簡化籌技術人員)
- 神經網絡
- 曾經歷過兩次低谷的人工神經網絡,還會迎來下一個低谷么?
- 人工神經網絡——維基
- 深度學習——維基
- A Neural Network in 11 lines of Python (Part 1)
- 深度學習
- 基于深度學習的機器翻譯
- 谷歌研究員2萬字批駁上海交大用深度學習推斷犯罪分子
- 理解這25個概念,你的「深度學習」才算入門!
- Deep Learning(深度學習)學習筆記整理系列
- 概述、背景、人腦視覺機理
- 特征
- Deep Learning
- Deep Learning 訓練
- Deep Learning(中文)
- 第1章 引言
- 深度學習如何入門?——知乎
- 文章收錄
- 神經系統