
[TOC]

在[機器學習](https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0 "機器學習")和[認知科學](https://zh.wikipedia.org/wiki/%E8%AE%A4%E7%9F%A5%E7%A7%91%E5%AD%A6 "認知科學")領域,**人工神經網絡**([英文](https://zh.wikipedia.org/wiki/%E8%8B%B1%E6%96%87 "英文"):artificial neural network,縮寫ANN),簡稱**神經網絡**([英文](https://zh.wikipedia.org/wiki/%E8%8B%B1%E6%96%87 "英文"):neural network,縮寫NN)或**類神經網絡**,是一種模仿[生物神經網絡](https://zh.wikipedia.org/wiki/%E7%94%9F%E7%89%A9%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C "生物神經網絡")(動物的[中樞神經系統](https://zh.wikipedia.org/wiki/%E4%B8%AD%E6%A8%9E%E7%A5%9E%E7%B6%93%E7%B3%BB%E7%B5%B1 "中樞神經系統"),特別是[大腦](https://zh.wikipedia.org/wiki/%E5%A4%A7%E8%84%91 "大腦"))的結構和功能的[數學模型](https://zh.wikipedia.org/wiki/%E6%95%B0%E5%AD%A6%E6%A8%A1%E5%9E%8B "數學模型")或[計算模型](https://zh.wikipedia.org/wiki/%E8%AE%A1%E7%AE%97%E6%A8%A1%E5%9E%8B "計算模型"),用于對[函數](https://zh.wikipedia.org/wiki/%E5%87%BD%E6%95%B0 "函數")進行估計或近似。神經網絡由大量的人工神經元聯結進行計算。大多數情況下人工神經網絡能在外界信息的基礎上改變內部結構,是一種[自適應系統](https://zh.wikipedia.org/w/index.php?title=%E8%87%AA%E9%80%82%E5%BA%94%E7%B3%BB%E7%BB%9F&action=edit&redlink=1 "自適應系統(頁面不存在)")。[[來源請求]](https://zh.wikipedia.org/wiki/Wikipedia:%E5%88%97%E6%98%8E%E6%9D%A5%E6%BA%90 "Wikipedia:列明來源")現代神經網絡是一種[非線性](https://zh.wikipedia.org/wiki/%E9%9D%9E%E7%BA%BF%E6%80%A7 "非線性")[統計性數據建模](https://zh.wikipedia.org/w/index.php?title=%E7%BB%9F%E8%AE%A1%E6%80%A7%E6%95%B0%E6%8D%AE%E5%BB%BA%E6%A8%A1&action=edit&redlink=1 "統計性數據建模(頁面不存在)")工具。典型的神經網絡具有以下三個部分:
* **結構**?(**Architecture**) 結構指定了網絡中的變量和它們的拓撲關系。例如,神經網絡中的變量可以是神經元連接的[權重](https://zh.wikipedia.org/wiki/%E6%9D%83%E9%87%8D "權重")(weights)和神經元的激勵值(activities of the neurons)。
* **激勵函數(Activity Rule)**?大部分神經網絡模型具有一個短時間尺度的動力學規則,來定義神經元如何根據其他神經元的活動來改變自己的激勵值。一般激勵函數依賴于網絡中的權重(即該網絡的參數)。
* **學習規則(Learning Rule)** 學習規則指定了網絡中的權重如何隨著時間推進而調整。這一般被看做是一種長時間尺度的動力學規則。一般情況下,學習規則依賴于神經元的激勵值。它也可能依賴于監督者提供的目標值和當前權重的值。
例如,用于[手寫識別](https://zh.wikipedia.org/wiki/%E6%89%8B%E5%86%99%E8%AF%86%E5%88%AB "手寫識別")的一個神經網絡,有一組輸入神經元。輸入神經元會被輸入圖像的數據所激發。在激勵值被加權并通過一個[函數](https://zh.wikipedia.org/wiki/%E5%87%BD%E6%95%B0 "函數")(由網絡的設計者確定)后,這些神經元的激勵值被傳遞到其他神經元。這個過程不斷重復,直到輸出神經元被激發。最后,輸出神經元的激勵值決定了識別出來的是哪個字母。
神經網絡的構筑理念是受到生物(人或其他動物)神經網絡功能的運作啟發而產生的。人工神經網絡通常是通過一個基于數學統計學類型的學習方法(Learning Method)得以優化,所以人工神經網絡也是數學統計學方法的一種實際應用,通過統計學的標準數學方法我們能夠得到大量的可以用函數來表達的局部結構空間,另一方面在人工智能學的人工感知領域,我們通過數學統計學的應用可以來做人工感知方面的決定問題(也就是說通過統計學的方法,人工神經網絡能夠類似人一樣具有簡單的決定能力和簡單的判斷能力),這種方法比起正式的邏輯學推理演算更具有優勢。
和其他[機器學習](https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0 "機器學習")方法一樣,神經網絡已經被用于解決各種各樣的問題,例如[機器視覺](https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E8%A7%86%E8%A7%89 "機器視覺")和[語音識別](https://zh.wikipedia.org/wiki/%E8%AF%AD%E9%9F%B3%E8%AF%86%E5%88%AB "語音識別")。這些問題都是很難被傳統基于規則的編程所解決的。
## 背景[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=1 "編輯小節:背景")]
對人類[中樞神經系統](https://zh.wikipedia.org/wiki/%E4%B8%AD%E6%9E%A2%E7%A5%9E%E7%BB%8F%E7%B3%BB%E7%BB%9F "中樞神經系統")的觀察啟發了人工神經網絡這個概念。在人工神經網絡中,簡單的人工節點,稱作神經元(neurons),連接在一起形成一個類似[生物神經網絡](https://zh.wikipedia.org/wiki/%E7%94%9F%E7%89%A9%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C "生物神經網絡")的網狀結構。
人工神經網絡目前沒有一個統一的正式定義。不過,具有下列特點的[統計模型](https://zh.wikipedia.org/wiki/%E7%BB%9F%E8%AE%A1%E6%A8%A1%E5%9E%8B "統計模型")可以被稱作是“神經化”的:
* 具有一組可以被調節的權重,換言之,被學習算法調節的數值參數,并且
* 可以估計輸入數據的[非線性函數](https://zh.wikipedia.org/w/index.php?title=%E9%9D%9E%E7%BA%BF%E6%80%A7%E5%87%BD%E6%95%B0&action=edit&redlink=1 "非線性函數(頁面不存在)")關系
這些可調節的權重可以被看做神經元之間的連接強度。
人工神經網絡與生物神經網絡的相似之處在于,它可以集體地、并行地計算函數的各個部分,而不需要描述每一個單元的特定任務。神經網絡這個詞一般指[統計學](https://zh.wikipedia.org/wiki/%E7%BB%9F%E8%AE%A1%E5%AD%A6 "統計學")、[認知心理學](https://zh.wikipedia.org/wiki/%E8%AE%A4%E7%9F%A5%E5%BF%83%E7%90%86%E5%AD%A6 "認知心理學")和[人工智能](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD "人工智能")領域使用的模型,而控制中央神經系統的神經網絡屬于[理論神經學](https://zh.wikipedia.org/w/index.php?title=%E7%90%86%E8%AE%BA%E7%A5%9E%E7%BB%8F%E5%AD%A6&action=edit&redlink=1 "理論神經學(頁面不存在)")和[計算神經學](https://zh.wikipedia.org/wiki/%E8%AE%A1%E7%AE%97%E7%A5%9E%E7%BB%8F%E7%A7%91%E5%AD%A6 "計算神經科學")。[[1]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-1)
在神經網絡的現代軟件實現中,被生物學啟發的那種方法已經很大程度上被拋棄了,取而代之的是基于[統計學](https://zh.wikipedia.org/wiki/%E7%BB%9F%E8%AE%A1%E5%AD%A6 "統計學")和[信號處理](https://zh.wikipedia.org/wiki/%E4%BF%A1%E5%8F%B7%E5%A4%84%E7%90%86 "信號處理")的更加實用的方法。在一些軟件系統中,神經網絡或者神經網絡的一部分(例如人工神經元)是大型系統中的一個部分。這些系統結合了適應性的和非適應性的元素。雖然這種系統使用的這種更加普遍的方法更適宜解決現實中的問題,但是這和傳統的連接主義人工智能已經沒有什么關聯了。不過它們還有一些共同點:非線性、分布式、并行化,局部性計算以及適應性。從歷史的角度講,神經網絡模型的應用標志著二十世紀八十年代后期從高度符號化的人工智能(以用條件規則表達知識的[專家系統](https://zh.wikipedia.org/wiki/%E4%B8%93%E5%AE%B6%E7%B3%BB%E7%BB%9F "專家系統")為代表)向低符號化的機器學習(以用動力系統的參數表達知識為代表)的轉變。
## 歷史[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=2 "編輯小節:歷史")]
[沃倫·麥卡洛克](https://zh.wikipedia.org/wiki/%E6%B2%83%E4%BC%A6%C2%B7%E9%BA%A6%E5%8D%A1%E6%B4%9B%E5%85%8B "沃倫·麥卡洛克")和[沃爾特·皮茨](https://zh.wikipedia.org/w/index.php?title=%E6%B2%83%E5%B0%94%E7%89%B9%C2%B7%E7%9A%AE%E8%8C%A8&action=edit&redlink=1 "沃爾特·皮茨(頁面不存在)")(1943)[[2]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-2)基于數學和一種稱為閾值邏輯的算法創造了一種神經網絡的計算模型。這種模型使得神經網絡的研究分裂為兩種不同研究思路。一種主要關注大腦中的生物學過程,另一種主要關注神經網絡在人工智能里的應用。
### 赫布型學習[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=3 "編輯小節:赫布型學習")]
二十世紀40年代后期,心理學家[唐納德·赫布](https://zh.wikipedia.org/wiki/%E5%94%90%E7%BA%B3%E5%BE%B7%C2%B7%E8%B5%AB%E5%B8%83 "唐納德·赫布")根據神經可塑性的機制創造了一種對學習的假說,現在稱作[赫布型學習](https://zh.wikipedia.org/wiki/%E8%B5%AB%E5%B8%83%E5%9E%8B%E5%AD%A6%E4%B9%A0 "赫布型學習")。赫布型學習被認為是一種典型的[非監督式學習](https://zh.wikipedia.org/wiki/%E9%9D%9E%E7%9B%91%E7%9D%A3%E5%BC%8F%E5%AD%A6%E4%B9%A0 "非監督式學習")規則,它后來的變種是[長期增強作用](https://zh.wikipedia.org/wiki/%E9%95%B7%E6%9C%9F%E5%A2%9E%E5%BC%B7%E4%BD%9C%E7%94%A8 "長期增強作用")的早期模型。從1948年開始,研究人員將這種計算模型的思想應用到B型圖靈機上。
法利和[韋斯利·A·克拉克](https://zh.wikipedia.org/w/index.php?title=%E9%9F%A6%E6%96%AF%E5%88%A9%C2%B7A%C2%B7%E5%85%8B%E6%8B%89%E5%85%8B&action=edit&redlink=1 "韋斯利·A·克拉克(頁面不存在)")(1954)[[3]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-3)首次使用計算機,當時稱作計算器,在MIT模擬了一個赫布網絡。
弗蘭克·羅森布拉特(1956)[[4]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-4)創造了感知機。這是一種模式識別算法,用簡單的加減法實現了兩層的計算機學習網絡。羅森布拉特也用數學符號描述了基本感知機里沒有的回路,例如異或回路。這種回路一直無法被神經網絡處理,直到Paul Werbos(1975)創造了[反向傳播算法](https://zh.wikipedia.org/wiki/%E5%8F%8D%E5%90%91%E4%BC%A0%E6%92%AD%E7%AE%97%E6%B3%95 "反向傳播算法")。
在[馬文·明斯基](https://zh.wikipedia.org/wiki/%E9%A9%AC%E6%96%87%C2%B7%E9%97%B5%E6%96%AF%E5%9F%BA "馬文·閔斯基")和[西摩·帕爾特](https://zh.wikipedia.org/w/index.php?title=%E8%A5%BF%E6%91%A9%C2%B7%E5%B8%95%E5%B0%94%E7%89%B9&action=edit&redlink=1 "西摩·帕爾特(頁面不存在)")(1969)發表了一項關于機器學習的研究以后,神經網絡的研究停滯不前。他們發現了神經網絡的兩個關鍵問題。第一是基本感知機無法處理異或回路。第二個重要的問題是電腦沒有足夠的能力來處理大型神經網絡所需要的很長的計算時間。直到計算機具有更強的計算能力之前,神經網絡的研究進展緩慢。
### 反向傳播算法與復興[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=4 "編輯小節:反向傳播算法與復興")]
后來出現的一個關鍵的進展是[反向傳播算法](https://zh.wikipedia.org/wiki/%E5%8F%8D%E5%90%91%E4%BC%A0%E6%92%AD%E7%AE%97%E6%B3%95 "反向傳播算法")(Werbos 1975)。這個算法有效地解決了異或的問題,還有更普遍的訓練多層神經網絡的問題。
在二十世紀80年代中期,[分布式并行處理](https://zh.wikipedia.org/wiki/%E5%88%86%E5%B8%83%E5%BC%8F%E5%B9%B6%E8%A1%8C%E5%A4%84%E7%90%86 "分布式并行處理")(當時稱作[聯結主義](https://zh.wikipedia.org/wiki/%E8%81%94%E7%BB%93%E4%B8%BB%E4%B9%89 "聯結主義"))流行起來。David E. Rumelhart和James McClelland(1986)的教材對于聯結主義在計算機模擬神經活動中的應用提供了全面的論述。
神經網絡傳統上被認為是大腦中的神經活動的簡化模型,雖然這個模型和大腦的生理結構之間的關聯存在爭議。人們不清楚人工神經網絡能多大程度地反映大腦的功能。
[支持向量機](https://zh.wikipedia.org/wiki/%E6%94%AF%E6%8C%81%E5%90%91%E9%87%8F%E6%9C%BA "支持向量機")和其他更簡單的方法(例如[線性分類器](https://zh.wikipedia.org/wiki/%E7%BA%BF%E6%80%A7%E5%88%86%E7%B1%BB%E5%99%A8 "線性分類器"))在機器學習領域的流行度逐漸超過了神經網絡,但是在2000年代后期出現的[深度學習](https://zh.wikipedia.org/wiki/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0 "深度學習")重新激發了人們對神經網絡的興趣。
### 2006年之后的進展[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=5 "編輯小節:2006年之后的進展")]
人們用[CMOS](https://zh.wikipedia.org/wiki/CMOS "CMOS")創造了用于生物物理模擬和神經形態計算的計算裝置。最新的研究顯示了用于大型[主成分分析](https://zh.wikipedia.org/wiki/%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90 "主成分分析")和[卷積神經網絡](https://zh.wikipedia.org/wiki/%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C "卷積神經網絡")的納米裝置[[5]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-5)具有良好的前景。如果成功的話,這會創造出一種新的神經計算裝置[[6]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-6),因為它依賴于學習而不是編程,并且它從根本上就是[模擬](https://zh.wikipedia.org/wiki/%E6%A8%A1%E6%93%AC%E4%BF%A1%E8%99%9F "模擬信號")的而不是[數字化](https://zh.wikipedia.org/wiki/%E6%95%B0%E5%AD%97%E5%8C%96 "數字化")的,雖然它的第一個實例可能是數字化的CMOS裝置。
在2009到2012年之間,Jürgen Schmidhuber在Swiss AI Lab IDSIA的研究小組研發的[遞歸神經網絡](https://zh.wikipedia.org/wiki/%E9%80%92%E5%BD%92%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C "遞歸神經網絡")和深前饋神經網絡贏得了8項關于模式識別和機器學習的國際比賽。[[7]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-7)[[8]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-8)例如,Alex Graves et al.的雙向、多維的LSTM贏得了2009年ICDAR的3項關于連筆字識別的比賽,而且之前并不知道關于將要學習的3種語言的信息。[[9]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-9)[[10]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-10)[[11]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-11)[[12]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-12)
IDSIA的Dan Ciresan和同事根據這個方法編寫的基于GPU的實現贏得了多項模式識別的比賽,包括IJCNN 2011交通標志識別比賽等等。[[13]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-13)[[14]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-14)他們的神經網絡也是第一個在重要的基準測試中(例如IJCNN 2012交通標志識別和NYU的[揚·勒丘恩](https://zh.wikipedia.org/wiki/%E6%89%AC%C2%B7%E5%8B%92%E4%B8%98%E6%81%A9 "揚·勒丘恩")(Yann LeCun)的MNIST手寫數字問題)能達到或超過人類水平的人工模式識別器。
類似1980年Kunihiko Fukushima發明的neocognitron[[15]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-K._Fukushima._Neocognitron_1980-15)和視覺標準結構[[16]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-M_Riesenhuber.2C_1999-16)(由David H. Hubel和Torsten Wiesel在初級視皮層中發現的那些簡單而又復雜的細胞啟發)那樣有深度的、高度非線性的神經結構可以被多倫多大學杰夫·辛頓實驗室的非監督式學習方法所訓練。[[17]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-17)[[18]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-18)[[19]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-19)
## 神經元[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=6 "編輯小節:神經元")]
神經元示意圖:
[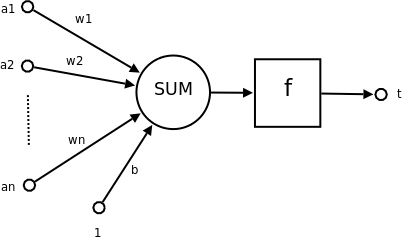](https://zh.wikipedia.org/wiki/File:Ncell.png)
* a1~an為輸入向量的各個分量
* w1~wn為神經元各個突觸的權值
* b為偏置
* f為傳遞函數,通常為非線性函數。一般有traingd(),tansig(),hardlim()。以下默認為hardlim()
* t為神經元輸出
數學表示?{\displaystyle t=f({\vec {W'}}{\vec {A}}+b)}
* {\displaystyle {\vec {W}}}為權向量 ,{\displaystyle {\vec {W'}}}為{\displaystyle {\vec {W}}}的轉置
* {\displaystyle {\vec {A}}}為輸入向量
* {\displaystyle b}為偏置
* {\displaystyle f}為傳遞函數
可見,一個神經元的功能是求得輸入向量與權向量的[內積](https://zh.wikipedia.org/wiki/%E5%86%85%E7%A7%AF "內積")后,經一個非線性傳遞函數得到一個[標量](https://zh.wikipedia.org/wiki/%E6%A0%87%E9%87%8F "標量")結果。
單個神經元的作用:把一個n維向量空間用一個超平面分區成兩部分(稱之為判斷邊界),給定一個輸入向量,神經元可以判斷出這個向量位于超平面的哪一邊。
該超平面的方程:{\displaystyle {\vec {W'}}{\vec {p}}+b=0}
* {\displaystyle {\vec {W}}}權向量
* {\displaystyle b}偏置
* {\displaystyle {\vec {p}}}超平面上的向量
[[20]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-20)
## 神經元網絡[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=7 "編輯小節:神經元網絡")]
### 單層神經元網絡[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=8 "編輯小節:單層神經元網絡")]
是最基本的神經元網絡形式,由有限個神經元構成,所有神經元的輸入向量都是同一個向量。由于每一個神經元都會產生一個標量結果,所以單層神經元的輸出是一個向量,向量的維數等于神經元的數目。
示意圖:
[](https://zh.wikipedia.org/wiki/File:SingleLayerNeuralNetwork_english.png)
### 多層神經元網絡[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=9 "編輯小節:多層神經元網絡")]
## 人工神經網絡的實用性[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=10 "編輯小節:人工神經網絡的實用性")]
人工神經網絡是一個能夠學習,能夠總結歸納的系統,也就是說它能夠通過已知數據的實驗運用來學習和歸納總結。人工神經網絡通過對局部情況的對照比較(而這些比較是基于不同情況下的自動學習和要實際解決問題的復雜性所決定的),它能夠推理產生一個可以自動識別的系統。與之不同的基于符號系統下的學習方法,它們也具有推理功能,只是它們是創建在邏輯算法的基礎上,也就是說它們之所以能夠推理,基礎是需要有一個推理算法則的集合。
## 人工神經元網絡模型[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=11 "編輯小節:人工神經元網絡模型")]
通常來說,一個人工神經元網絡是由一個多層神經元結構組成,每一層神經元擁有輸入(它的輸入是前一層神經元的輸出)和輸出,每一層(我們用符號記做)Layer(i)是由Ni(Ni代表在第i層上的N)個網絡神經元組成,每個Ni上的網絡神經元把對應在Ni-1上的神經元輸出做為它的輸入,我們把神經元和與之對應的神經元之間的連線用生物學的名稱,叫做**突觸**(英語:Synapse),在數學模型中每個突觸有一個加權數值,我們稱做權重,那么要計算第i層上的某個神經元所得到的勢能等于每一個權重乘以第i-1層上對應的神經元的輸出,然后全體求和得到了第i層上的某個神經元所得到的勢能,然后勢能數值通過該神經元上的激活函數(activation function,常是∑函數(英語:Sigmoid function)以控制輸出大小,因為其可微分且連續,方便差量規則(英語:Delta rule)處理。求出該神經元的輸出,注意的是該輸出是一個非線性的數值,也就是說通過激勵函數求的數值根據極限值來判斷是否要激活該神經元,換句話說我們對一個神經元網絡的輸出是否線性不感興趣。
## 基本結構[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=12 "編輯小節:基本結構")]
一種常見的多層結構的前饋網絡(Multilayer Feedforward Network)由三部分組成,
* 輸入層(Input layer),眾多神經元(Neuron)接受大量非線形輸入消息。輸入的消息稱為輸入向量。
* 輸出層(Output layer),消息在神經元鏈接中傳輸、分析、權衡,形成輸出結果。輸出的消息稱為輸出向量。
* 隱藏層(Hidden layer),簡稱“隱層”,是輸入層和輸出層之間眾多神經元和鏈接組成的各個層面。隱層可以有多層,習慣上會用一層。隱層的節點(神經元)數目不定,但數目越多神經網絡的非線性越顯著,從而神經網絡的[強健性(robustness)](https://zh.wikipedia.org/w/index.php?title=%E5%BC%B7%E5%81%A5%E6%80%A7%EF%BC%88robustness%EF%BC%89&action=edit&redlink=1 "強健性(robustness)(頁面不存在)")(控制系統在一定結構、大小等的參數攝動下,維持某些性能的特性。)更顯著。習慣上會選輸入節點1.2至1.5倍的節點。
神經網絡的類型已經演變出很多種,這種分層的結構也并不是對所有的神經網絡都適用。
## 學習過程[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=13 "編輯小節:學習過程")]
通過訓練樣本的校正,對各個層的權重進行校正(learning)而創建模型的過程,稱為自動學習過程(training algorithm)。具體的學習方法則因網絡結構和模型不同而不同,常用[反向傳播算法](https://zh.wikipedia.org/wiki/%E5%8F%8D%E5%90%91%E4%BC%A0%E6%92%AD%E7%AE%97%E6%B3%95 "反向傳播算法")(Backpropagation/倒傳遞/逆傳播,以output利用一次微分[Delta rule](https://zh.wikipedia.org/w/index.php?title=Delta_rule&action=edit&redlink=1)來修正weight)來驗證。
參見:[神經網絡介紹](http://www.ibm.com/developerworks/cn/linux/other/l-neural/index.html)
## 種類[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=14 "編輯小節:種類")]
人工神經網絡分類為以下兩種:
1.依學習策略(Algorithm)分類主要有:
* [監督式學習網絡](https://zh.wikipedia.org/wiki/%E7%9B%A3%E7%9D%A3%E5%BC%8F%E5%AD%B8%E7%BF%92%E7%B6%B2%E8%B7%AF "監督式學習網絡")(Supervised Learning Network)為主
* [無監督式學習網絡](https://zh.wikipedia.org/wiki/%E7%84%A1%E7%9B%A3%E7%9D%A3%E5%BC%8F%E5%AD%B8%E7%BF%92%E7%B6%B2%E8%B7%AF "無監督式學習網絡")(Unsupervised Learning Network)
* [混合式學習網絡](https://zh.wikipedia.org/w/index.php?title=%E6%B7%B7%E5%90%88%E5%BC%8F%E5%AD%B8%E7%BF%92%E7%B6%B2%E8%B7%AF&action=edit&redlink=1 "混合式學習網絡(頁面不存在)")(Hybrid Learning Network)
* [聯想式學習網絡](https://zh.wikipedia.org/w/index.php?title=%E8%81%AF%E6%83%B3%E5%BC%8F%E5%AD%B8%E7%BF%92%E7%B6%B2%E8%B7%AF&action=edit&redlink=1 "聯想式學習網絡(頁面不存在)")(Associate Learning Network)
* [最適化學習網絡](https://zh.wikipedia.org/w/index.php?title=%E6%9C%80%E9%81%A9%E5%8C%96%E5%AD%B8%E7%BF%92%E7%B6%B2%E8%B7%AF&action=edit&redlink=1 "最適化學習網絡(頁面不存在)")(Optimization Application Network)
2.依網絡架構(Connectionism)分類主要有:
* [前向式架構](https://zh.wikipedia.org/w/index.php?title=%E5%89%8D%E5%90%91%E5%BC%8F%E6%9E%B6%E6%A7%8B&action=edit&redlink=1 "前向式架構(頁面不存在)")(Feed Forward Network)
* [回饋式架構](https://zh.wikipedia.org/w/index.php?title=%E5%9B%9E%E9%A5%8B%E5%BC%8F%E6%9E%B6%E6%A7%8B&action=edit&redlink=1 "回饋式架構(頁面不存在)")(Recurrent Network)
* [強化式架構](https://zh.wikipedia.org/w/index.php?title=%E5%BC%BA%E5%8C%96%E5%BC%8F%E6%9E%B6%E6%A7%8B&action=edit&redlink=1 "強化式架構(頁面不存在)")(Reinforcement Network)
## 理論性質[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=15 "編輯小節:理論性質")]
### 計算能力[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=16 "編輯小節:計算能力")]
多層感知器(MLP)是一個通用的函數逼近器,由Cybenko定理證明。然而,證明不是由所要求的神經元數量或權重來推斷的。 Hava Siegelmann和Eduardo D. Sontag的工作證明了,一個具有有理數權重值的特定遞歸結構(與全精度實數權重值相對應)相當于一個具有有限數量的神經元和標準的線性關系的通用圖靈機。[[21]](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_note-21)?他們進一步表明,使用無理數權重值會產生一個超圖靈機。
### 容量[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=17 "編輯小節:容量")]
人工神經網絡模型有一個屬性,稱為“容量”,這大致相當于他們可以塑造任何函數的能力。它與可以被儲存在網絡中的信息的數量和復雜性相關。
### 收斂性[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=18 "編輯小節:收斂性")]
沒有什么通常意義上的收斂,因為它取決于一些因素。首先,函數可能存在許多局部極小值。這取決于成本函數和模型。其次,使用優化方法在遠離局部最小值時可能無法保證收斂。第三,對大量的數據或參數,一些方法變得不切實際。在一般情況下,我們發現,理論保證的收斂不能成為實際應用的一個可靠的指南。
### 綜合統計[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=19 "編輯小節:綜合統計")]
在目標是創建一個普遍系統的應用程序中,過度訓練的問題出現了。這出現在回旋或過度具體的系統中當網絡的容量大大超過所需的自由參數。為了避免這個問題,有兩個方向:第一個是使用交叉驗證和類似的技術來檢查過度訓練的存在和選擇最佳參數如最小化泛化誤差。二是使用某種形式的正規化。這是一個在概率化(貝葉斯)框架里出現的概念,其中的正則化可以通過為簡單模型選擇一個較大的先驗概率模型進行;而且在統計學習理論中,其目的是最大限度地減少了兩個數量:“風險”和“結構風險”,相當于誤差在訓練集和由于過度擬合造成的預測誤差。
## 參見[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=20 "編輯小節:參見")]
* [生物神經網絡](https://zh.wikipedia.org/wiki/%E7%94%9F%E7%89%A9%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C "生物神經網絡")
* [人工智能](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD "人工智能")
* [機器學習](https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0 "機器學習")
* [感知機](https://zh.wikipedia.org/wiki/%E6%84%9F%E7%9F%A5%E6%9C%BA "感知機")
## 外部鏈接[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=21 "編輯小節:外部鏈接")]
* [Performance comparison of neural network algorithms tested on UCI data sets](http://tunedit.org/results?e=&d=UCI%2F&a=neural+rbf+perceptron&n=)
* [A close view to Artificial Neural Networks Algorithms](http://www.learnartificialneuralnetworks.com/)
* [開放式目錄計劃](https://zh.wikipedia.org/wiki/%E5%BC%80%E6%94%BE%E5%BC%8F%E7%9B%AE%E5%BD%95 "開放式目錄")中和[Neural Networks](http://dmoztools.net/Computers/Artificial_Intelligence/Neural_Networks)相關的內容
* [A Brief Introduction to Neural Networks (D. Kriesel)](http://www.dkriesel.com/en/science/neural_networks)?- Illustrated, bilingual manuscript about artificial neural networks; Topics so far: Perceptrons, Backpropagation, Radial Basis Functions, Recurrent Neural Networks, Self Organizing Maps, Hopfield Networks.
* [Neural Networks in Materials Science](http://www.msm.cam.ac.uk/phase-trans/abstracts/neural.review.html)
* [A practical tutorial on Neural Networks](http://www.ai-junkie.com/ann/evolved/nnt1.html)
* [Applications of neural networks](http://www.peltarion.com/doc/index.php?title=Applications_of_adaptive_systems)
* [XOR 實例](http://4rdp.blogspot.tw/2013/10/artificial-neural-network.html)
## 參考文獻[[編輯](https://zh.wikipedia.org/w/index.php?title=%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&action=edit§ion=22 "編輯小節:參考文獻")]
1. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-1)**?Hentrich, Michael William.?[Methodology and Coronary Artery Disease Cure](https://www.researchgate.net/publication/281017979_Methodology_and_Coronary_Artery_Disease_Cure). 2015-08-16.?[doi:10.1709/TIT.2015.1083925](https://dx.doi.org/10.1709%2FTIT.2015.1083925).
2. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-2)**?McCulloch, Warren S.; Pitts, Walter.?[A logical calculus of the ideas immanent in nervous activity](http://link.springer.com/article/10.1007/BF02478259). The bulletin of mathematical biophysics. 1943-12-01,?**5**?(4): 115–133.?[ISSN?0007-4985](https://www.worldcat.org/issn/0007-4985).?[doi:10.1007/BF02478259](https://dx.doi.org/10.1007%2FBF02478259)?(英語).
3. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-3)**?Farley, B.; Clark, W.?[Simulation of self-organizing systems by digital computer](http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=1057468). Transactions of the IRE Professional Group on Information Theory. 1954-09-01,?**4**?(4): 76–84.?[ISSN?2168-2690](https://www.worldcat.org/issn/2168-2690).?[doi:10.1109/TIT.1954.1057468](https://dx.doi.org/10.1109%2FTIT.1954.1057468).
4. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-4)**?Rochester, N.; Holland, J.; Haibt, L.; Duda, W.?[Tests on a cell assembly theory of the action of the brain, using a large digital computer](http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=1056810). IRE Transactions on Information Theory. 1956-09-01,?**2**?(3): 80–93.?[ISSN?0096-1000](https://www.worldcat.org/issn/0096-1000).?[doi:10.1109/TIT.1956.1056810](https://dx.doi.org/10.1109%2FTIT.1956.1056810).
5. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-5)**?Yang, J. J.; Pickett, M. D.; Li, X. M.; Ohlberg, D. A. A.; Stewart, D. R.; Williams, R. S. Memristive switching mechanism for metal/oxide/metal nanodevices. Nat. Nanotechnol. 2008,?**3**: 429–433.?[doi:10.1038/nnano.2008.160](https://dx.doi.org/10.1038%2Fnnano.2008.160).
6. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-6)**?Strukov, D. B.; Snider, G. S.; Stewart, D. R.; Williams, R. S. The missing memristor found. Nature. 2008,?**453**: 80–83.?[PMID?18451858](https://www.ncbi.nlm.nih.gov/pubmed/18451858).?[doi:10.1038/nature06932](https://dx.doi.org/10.1038%2Fnature06932).
7. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-7)**?[2012 Kurzweil AI Interview](http://www.kurzweilai.net/how-bio-inspired-deep-learning-keeps-winning-competitions)?with?[Jürgen Schmidhuber](https://zh.wikipedia.org/w/index.php?title=J%C3%BCrgen_Schmidhuber&action=edit&redlink=1 "Jürgen Schmidhuber(頁面不存在)")?on the eight competitions won by his Deep Learning team 2009–2012
8. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-8)**?[http://www.kurzweilai.net/how-bio-inspired-deep-learning-keeps-winning-competitions](http://www.kurzweilai.net/how-bio-inspired-deep-learning-keeps-winning-competitions)?2012 Kurzweil AI Interview with?[Jürgen Schmidhuber](https://zh.wikipedia.org/w/index.php?title=J%C3%BCrgen_Schmidhuber&action=edit&redlink=1 "Jürgen Schmidhuber(頁面不存在)")?on the eight competitions won by his Deep Learning team 2009–2012
9. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-9)**?Graves, Alex; and Schmidhuber, Jürgen;?*[Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks](http://www.idsia.ch/~juergen/nips2009.pdf)*, in Bengio, Yoshua; Schuurmans, Dale; Lafferty, John; Williams, Chris K. I.; and Culotta, Aron (eds.),?*Advances in Neural Information Processing Systems 22 (NIPS'22), 7–10 December 2009, Vancouver, BC*, Neural Information Processing Systems (NIPS) Foundation, 2009, pp. 545–552.
10. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-10)**?Graves, A.; Liwicki, M.; Fernandez, S.; Bertolami, R.; Bunke, H.;?[Schmidhuber, J.](https://zh.wikipedia.org/w/index.php?title=J%C3%BCrgen_Schmidhuber&action=edit&redlink=1 "Jürgen Schmidhuber(頁面不存在)")?[A Novel Connectionist System for Improved Unconstrained Handwriting Recognition](http://www.idsia.ch/~juergen/tpami_2008.pdf)?(PDF). IEEE Transactions on Pattern Analysis and Machine Intelligence. 2009,?**31**?(5).
11. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-11)**?Graves, Alex; and Schmidhuber, Jürgen;?*Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks*, in Bengio, Yoshua; Schuurmans, Dale; Lafferty, John; Williams, Chris K. I.; and Culotta, Aron (eds.),?*Advances in Neural Information Processing Systems 22 (NIPS'22), December 7th–10th, 2009, Vancouver, BC*, Neural Information Processing Systems (NIPS) Foundation, 2009, pp. 545–552
12. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-12)**?Graves, A.; Liwicki, M.; Fernandez, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2009,?**31**?(5).
13. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-13)**?D. C. Ciresan, U. Meier, J. Masci,?[J. Schmidhuber](https://zh.wikipedia.org/w/index.php?title=J%C3%BCrgen_Schmidhuber&action=edit&redlink=1 "Jürgen Schmidhuber(頁面不存在)"). Multi-Column Deep Neural Network for Traffic Sign Classification. Neural Networks, 2012.
14. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-14)**?D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber. Multi-Column Deep Neural Network for Traffic Sign Classification. Neural Networks, 2012.
15. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-K._Fukushima._Neocognitron_1980_15-0)**?Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics. 1980,?**36**?(4): 93–202.?[PMID?7370364](https://www.ncbi.nlm.nih.gov/pubmed/7370364).?[doi:10.1007/BF00344251](https://dx.doi.org/10.1007%2FBF00344251).
16. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-M_Riesenhuber.2C_1999_16-0)**?M Riesenhuber,?[T Poggio](https://zh.wikipedia.org/w/index.php?title=Tomaso_Poggio&action=edit&redlink=1 "Tomaso Poggio(頁面不存在)"). Hierarchical models of object recognition in cortex. Nature neuroscience, 1999.
17. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-17)**?[Deep belief networks](http://www.scholarpedia.org/article/Deep_belief_networks)?at Scholarpedia.
18. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-18)**?[Hinton, G. E.](https://zh.wikipedia.org/w/index.php?title=Geoff_Hinton&action=edit&redlink=1 "Geoff Hinton(頁面不存在)"); Osindero, S.; Teh, Y. W.?[A Fast Learning Algorithm for Deep Belief Nets](http://www.cs.toronto.edu/~hinton/absps/fastnc.pdf)?(PDF).?[Neural Computation](https://zh.wikipedia.org/w/index.php?title=Neural_Computation_(journal)&action=edit&redlink=1 "Neural Computation (journal)(頁面不存在)"). 2006,?**18**?(7): 1527–1554.?[PMID?16764513](https://www.ncbi.nlm.nih.gov/pubmed/16764513).?[doi:10.1162/neco.2006.18.7.1527](https://dx.doi.org/10.1162%2Fneco.2006.18.7.1527).
19. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-19)**?[Hinton, G. E.](https://zh.wikipedia.org/w/index.php?title=Geoffrey_Hinton&action=edit&redlink=1 "Geoffrey Hinton(頁面不存在)"); Osindero, S.; Teh, Y.?[A fast learning algorithm for deep belief nets](http://www.cs.toronto.edu/~hinton/absps/fastnc.pdf)?(PDF).?[Neural Computation](https://zh.wikipedia.org/w/index.php?title=Neural_Computation_(journal)&action=edit&redlink=1 "Neural Computation (journal)(頁面不存在)"). 2006,?**18**?(7): 1527–1554.?[PMID?16764513](https://www.ncbi.nlm.nih.gov/pubmed/16764513).?[doi:10.1162/neco.2006.18.7.1527](https://dx.doi.org/10.1162%2Fneco.2006.18.7.1527).
20. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-20)**?Hagan, Martin. Neural Network Design. PWS Publishing Company. 1996.?[ISBN?7-111-10841-8](https://zh.wikipedia.org/wiki/Special:%E7%BD%91%E7%BB%9C%E4%B9%A6%E6%BA%90/7-111-10841-8 "Special:網絡書源/7-111-10841-8").
21. **[跳轉^](https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C#cite_ref-21)**?Siegelmann, H.T.; Sontag, E.D.?[Turing computability with neural nets](http://www.math.rutgers.edu/~sontag/FTP_DIR/aml-turing.pdf)?(PDF). Appl. Math. Lett. 1991,?**4**?(6): 77–80.?[doi:10.1016/0893-9659(91)90080-F](https://dx.doi.org/10.1016%2F0893-9659%2891%2990080-F).
- 15張圖閱盡人工智能現狀
- LeCun臺大演講:AI最大缺陷是缺乏常識,無監督學習突破困境
- Google首席科學家談Google是怎么做深度學習的
- 為你的深度學習任務挑選性價比最高GPU
- 史上最全面的深度學習硬件指南
- 機器學習
- 普通程序員如何向人工智能靠攏?
- 從機器學習談起
- 普通程序員如何轉向AI方向
- 機器學習6大算法,優勢劣勢全解析
- 除了 Python ,這些語言寫的機器學習項目也很牛(二)
- 五個鮮為人知,但又不可不知的機器學習開源項目
- 機器學習入門算法:從線性模型到神經網絡
- 機器學習常見算法分類匯總
- 最實用的機器學習算法Top5
- NLP
- Lucene的原理和應用
- 理解和使用自然語言處理之終極指南(Python編碼)(經典收藏版12k字,附數據簡化籌技術人員)
- 神經網絡
- 曾經歷過兩次低谷的人工神經網絡,還會迎來下一個低谷么?
- 人工神經網絡——維基
- 深度學習——維基
- A Neural Network in 11 lines of Python (Part 1)
- 深度學習
- 基于深度學習的機器翻譯
- 谷歌研究員2萬字批駁上海交大用深度學習推斷犯罪分子
- 理解這25個概念,你的「深度學習」才算入門!
- Deep Learning(深度學習)學習筆記整理系列
- 概述、背景、人腦視覺機理
- 特征
- Deep Learning
- Deep Learning 訓練
- Deep Learning(中文)
- 第1章 引言
- 深度學習如何入門?——知乎
- 文章收錄
- 神經系統