
*****
## 為什么要學習scrapy
## 什么是Scrapy
Scrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架,我們只需要實現少量的代碼,就能夠快速的抓取
Scrapy使用了Twisted異步網絡框架,可以加快我們的下載速度
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
## 異步和非阻塞的區別

異步:調用在發出之后,這個調用就直接返回,不管有無結果
非阻塞:關注的是程序在等待調用結果時的狀態,指在不能立刻得到結果之前,該調用不會阻塞當前線程。
## Scrapy工作流程
**回顧之前的爬蟲流程**
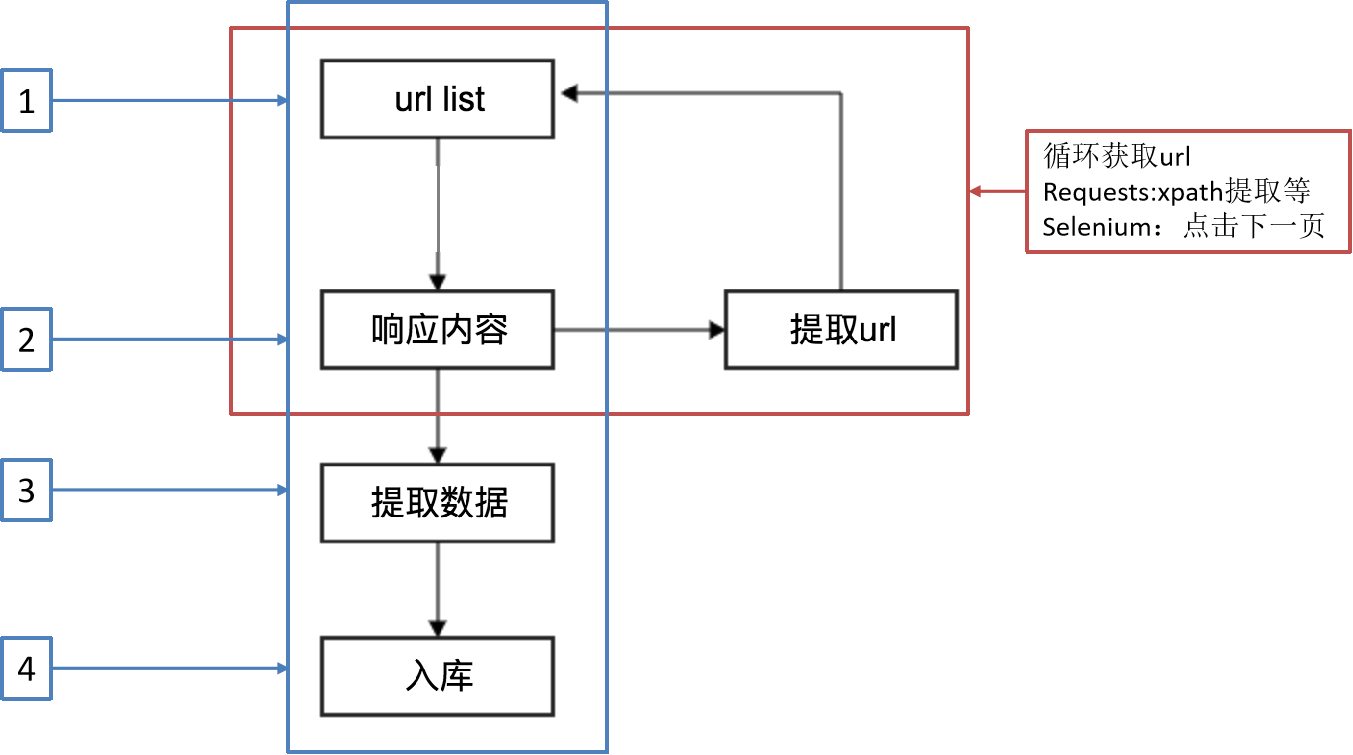
**另外一種爬蟲方式**
*****
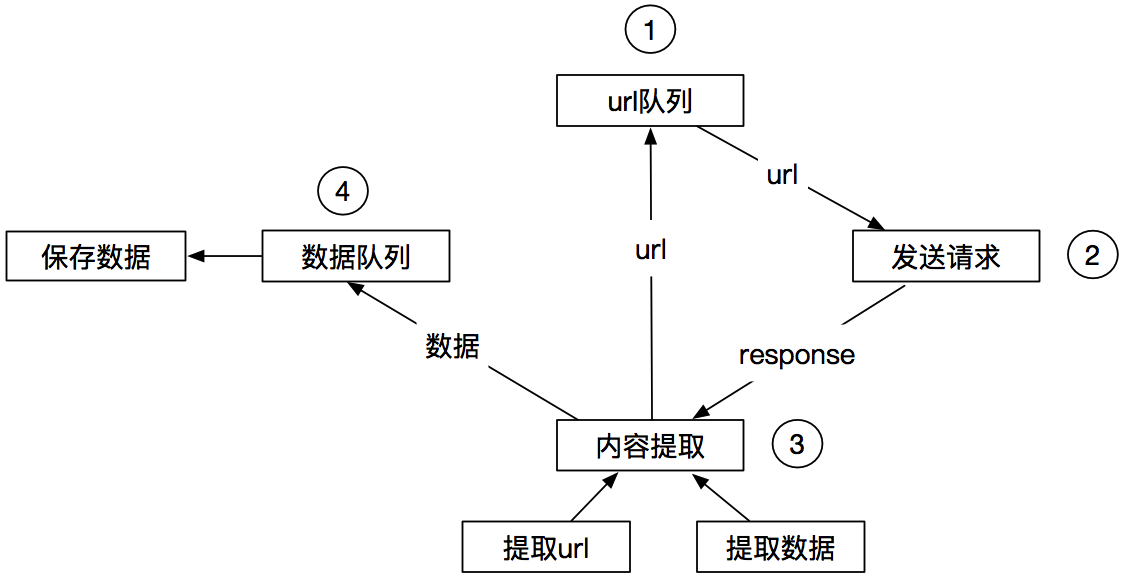
**Scrapy的爬蟲流程**
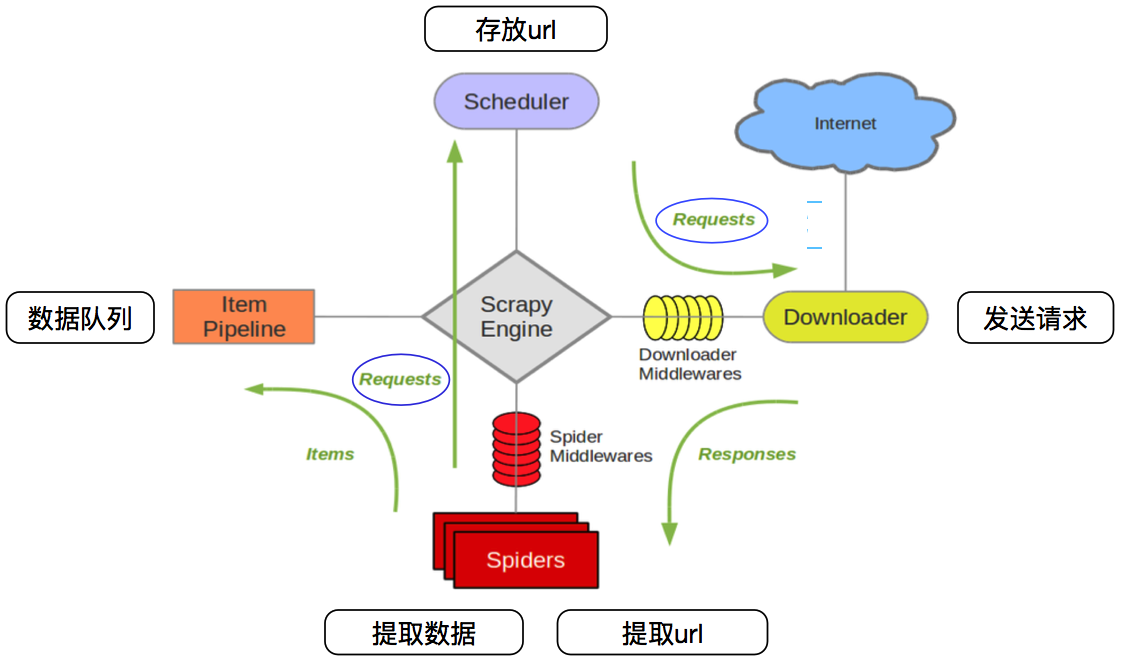
| Scrapy engine(引擎) | 總指揮:負責數據和信號的在不同模塊間的傳遞 | scrapy已經實現 |
|--- | --- | --- |
| Scheduler(調度器) | 一個隊列,存放引擎發過來的request請求 | scrapy已經實現|
| Downloader(下載器) | 下載把引擎發過來的requests請求,并返回給引擎 | scrapy已經實現|
| Spider(爬蟲) | 處理引擎發來的response,提取數據,提取url,并交給引擎 | 需要手寫|
| Item Pipline(管道) | 處理引擎傳過來的數據,比如存儲 | 需要手寫|
| Downloader Middlewares(下載中間件) | 可以自定義的下載擴展,比如設置代理 | 一般不用手寫|
| Spider Middlewares(中間件) | 可以自定義requests請求和進行response過濾 | 一般不用手寫|
## Scrapy入門
```
1 創建一個scrapy項目
scrapy startproject mySpider
2 生成一個爬蟲
scrapy genspider demo "demo.cn"
3 提取數據
完善spider 使用xpath等
4 保存數據
pipeline中保存數據
```
## 創建一個scrapy項目
