
*****
## 1 使用pipeline
從pipeline的字典形可以看出來,pipeline可以有多個,而且確實pipeline能夠定義多個
為什么需要多個pipeline:
1 可能會有多個spider,不同的pipeline處理不同的item的內容
2 一個spider的內容可以要做不同的操作,比如存入不同的數據庫中
注意:
1 pipeline的權重越小優先級越高
2 pipeline中process\_item方法名不能修改為其他的名稱
## 2 logging模塊的使用
爬蟲文件
```
import scrapy
import logging
logger = logging.getLogger(__name__)
class QbSpider(scrapy.Spider):
name = 'qb'
allowed_domains = ['qiushibaike.com']
start_urls = ['http://qiushibaike.com/']
def parse(self, response):
for i in range(10):
item = {}
item['content'] = "haha"
# logging.warning(item)
logger.warning(item)
yield item
```
pipeline文件
```
import logging
logger = logging.getLogger(__name__)
class MyspiderPipeline(object):
def process_item(self, item, spider):
# print(item)
logger.warning(item)
item['hello'] = 'world'
return item
```
保存到本地,在setting文件中`LOG_FILE = './log.log'`
## 回顧
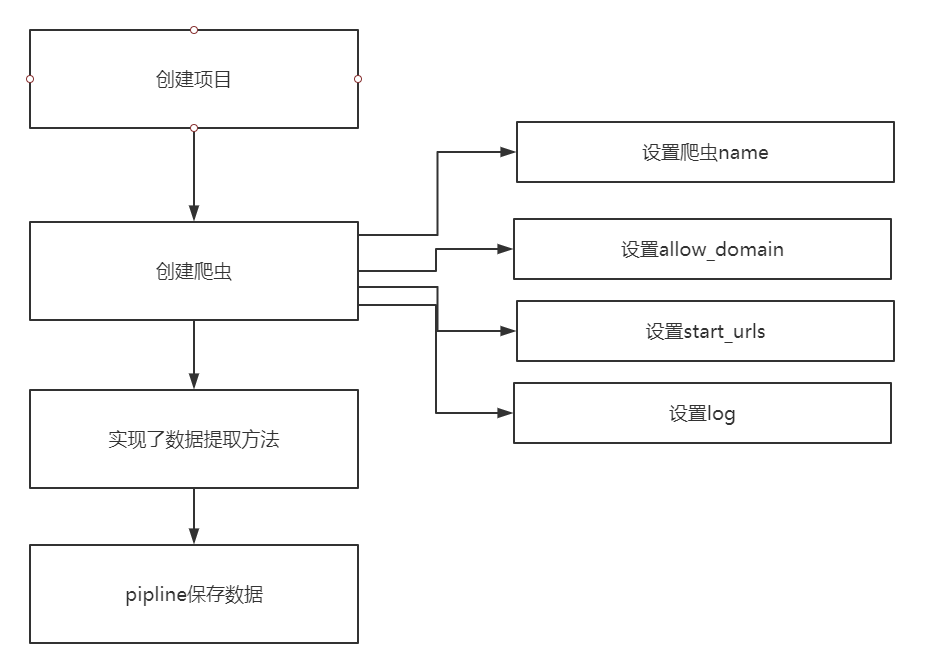
問題來了:如何實現翻頁請求

### 3 騰訊爬蟲
通過爬取騰訊招聘的頁面的招聘信息,學習如何實現翻頁請求
http://hr.tencent.com/position.php
```
創建項目
scrapy startproject tencent
創建爬蟲
scrapy genspider hr tencent.com
```
#### scrapy.Request知識點
```
scrapy.Request(url, callback=None, method='GET', headers=None, body=None,cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None)
常用參數為:
callback:指定傳入的URL交給那個解析函數去處理
meta:實現不同的解析函數中傳遞數據,meta默認會攜帶部分信息,比如下載延遲,請求深度
dont_filter:讓scrapy的去重不會過濾當前URL,scrapy默認有URL去重功能,對需要重復請求的URL有重要用途
```
## 4 item的介紹和使用
```
items.py
import scrapy
class TencentItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
position = scrapy.Field()
date = scrapy.Field()
```
### 5 陽光政務平臺
http://wz.sun0769.com/index.php/question/questionType?type=4&page=0
## 6 debug信息的認識

```
2019-01-19 09:50:48 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: tencent)
2019-01-19 09:50:48 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.0, w3lib 1.19.0, Twisted 18.9.0, Python 3.6.5 (v3
.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0i 14 Aug 2018), cryptography 2.3.1, Platform Windows-10-10.0
.17134-SP0 ### 爬蟲scrpay框架依賴的相關模塊和平臺的信息
2019-01-19 09:50:48 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'tencent', 'NEWSPIDER_MODULE': 'tencent.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MO
DULES': ['tencent.spiders'], 'USER_AGENT': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/53
7.36'} ### 自定義的配置信息哪些被應用了
2019-01-19 09:50:48 [scrapy.middleware] INFO: Enabled extensions: ### 插件信息
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2019-01-19 09:50:48 [scrapy.middleware] INFO: Enabled downloader middlewares: ### 啟動的下載器中間件
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2019-01-19 09:50:48 [scrapy.middleware] INFO: Enabled spider middlewares: ### 啟動的爬蟲中間件
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2019-01-19 09:50:48 [scrapy.middleware] INFO: Enabled item pipelines: ### 啟動的管道
['tencent.pipelines.TencentPipeline']
2019-01-19 09:50:48 [scrapy.core.engine] INFO: Spider opened ### 開始爬去數據
2019-01-19 09:50:48 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-01-19 09:50:48 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2019-01-19 09:50:51 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://hr.tencent.com/robots.txt> (referer: None) ### 抓取robots協議內容
2019-01-19 09:50:51 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://hr.tencent.com/position.php?&start=#a0> (referer: None) ### start_url發起請求
2019-01-19 09:50:51 [scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to 'hr.tencent.com': <GET https://hr.tencent.com/position.php?&start=> ### 提示錯誤,爬蟲中通過yeid交給引擎的請求會經過爬蟲中間件,由于請求的url超出allowed_domain的范圍,被offsitmiddleware 攔截了
2019-01-19 09:50:51 [scrapy.core.engine] INFO: Closing spider (finished) ### 爬蟲關閉
2019-01-19 09:50:51 [scrapy.statscollectors] INFO: Dumping Scrapy stats: ### 本次爬蟲的信息統計
{'downloader/request_bytes': 630,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 4469,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2019, 1, 19, 1, 50, 51, 558634),
'log_count/DEBUG': 4,
'log_count/INFO': 7,
'offsite/domains': 1,
'offsite/filtered': 12,
'request_depth_max': 1,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2019, 1, 19, 1, 50, 48, 628465)}
2019-01-19 09:50:51 [scrapy.core.engine] INFO: Spider closed (finished)
```
## Scrapy深入之scrapy shell
Scrapy shell是一個交互終端,我們可以在未啟動spider的情況下嘗試及調試代碼,也可以用來測試XPath表達式
使用方法:
scrapy shell http://www.itcast.cn/channel/teacher.shtml
```
response.url:當前相應的URL地址
response.request.url:當前相應的請求的URL地址
response.headers:響應頭
response.body:響應體,也就是HTML代碼,默認是byte類型
response.requests.headers:當前響應的請求頭
```
## scrapy settings
為什么需要配置文件:
> 配置文件存放一些公共的變量(比如數據庫的地址,賬號密碼等)
> 方便自己和別人修改
> 一般用全大寫字母命名變量名 SQL\_HOST = '192.168.0.1'
settings文件詳細信息:[https://www.cnblogs.com/cnkai/p/7399573.html](https://www.cnblogs.com/cnkai/p/7399573.html)
