[TOC]
# 快速參數化
參數化過程是指把 SQL 查詢中的常量變成變量的過程。
同一條 SQL 語句在每次執行時可能會使用不同的參數,將這些參數做參數化處理,可以得到與具體參數無關的 SQL 字符串,并使用該字符串作為計劃緩存的鍵值,用于在計劃緩存中獲取執行計劃,從而達到參數不同的 SQL 能夠共用相同的計劃目的。
由于傳統數據庫在進行參數化時一般是對語法樹進行參數化,然后使用參數化后的語法樹作為鍵值在計劃緩存中獲取計劃,而 OceanBase 數據庫使用的詞法分析對文本串直接參數化后作為計劃緩存的鍵值,因此叫做快速參數化。
OceanBase 數據庫支持自適應計劃共享(Adaptive Cursor Sharing)功能以支持不同參數條件下的計劃選擇。
基于快速參數化而獲取執行計劃的流程如下圖所示:
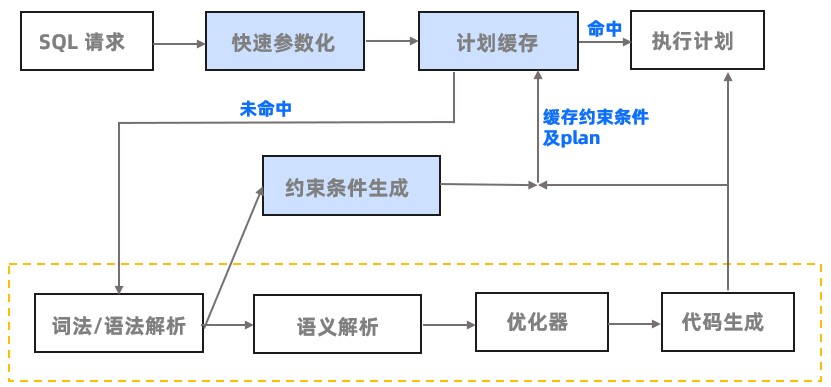
**示例解析**
~~~
obclient>SELECT * FROM T1 WHERE c1 = 5 AND c2 ='oceanbase';
~~~
上述示例中的 SQL 查詢參數化后結果如下所示,常量 5 和 oceanbase 被參數化后變成了變量 @1 和 @2:
~~~
obclient>SELECT * FROM T1 WHERE c1 = @1 AND c2 = @2;
~~~
但在計劃匹配中,不是所有常量都可以被參數化,例如 ORDER BY 后面的常量,表示按照 SELECT 投影列中第幾列進行排序,所以不可以被參數化。
如下例所示,表 t1 中含 c1、c2 列,其中 c1 為主鍵列,SQL 查詢的結果按照 c1 列進行排序,由于 c1 作為主鍵列是有序的,所以使用主鍵訪問可以免去排序。
~~~
obclient>CREATE TABLE t1(c1 INT PRIMARY KEY,c2 INT);
Query OK, 0 rows affected (0.06 sec)
obclient>INSERT INTO t1 VALUES (1,2);
Query OK, 1 row affected (0.01 sec)
obclient>INSERT INTO t1 VALUES (2,1);
Query OK, 1 row affected (0.01 sec)
obclient>INSERT INTO t1 VALUES (3,1);
Query OK, 1 row affected (0.01 sec)
obclient>SELECT c1, c2 FROM t1 ORDER BY 1;
+----+------+
| C1 | C2 |
+----+------+
| 1 | 2 |
| 2 | 1 |
| 3 | 1 |
+----+------+
3 rows in set (0.00 sec)
obclient>EXPLAIN SELECT c1, c2 FROM t1 ORDER BY 1\G;
*************************** 1. row ***************************
Query Plan:
| ===================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
-----------------------------------
|0 |TABLE SCAN|t1 |1000 |1381|
===================================
Outputs & filters:
-------------------------------------
0 - output([T1.C1], [T1.C2]), filter(nil),
access([T1.C1], [T1.C2]), partitions(p0)
~~~
但如果執行如下命令:
~~~
obclient>SELECT c1, c2 FROM t1 ORDER BY 2;
+----+------+
| C1 | C2 |
+----+------+
| 2 | 1 |
| 3 | 1 |
| 1 | 2 |
+----+------+
3 rows in set (0.00 sec)
~~~
則結果需要對 c2 排序,因此需要執行顯示的排序操作,執行計劃如下例所示:
~~~
obclient>EXPLAIN SELECT c1, c2 FROM t1 ORDER BY 2\G;
*************************** 1. row ***************************
Query Plan:
| ====================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
------------------------------------
|0 |SORT | |1000 |1886|
|1 | TABLE SCAN|t1 |1000 |1381|
====================================
Outputs & filters:
-------------------------------------
0 - output([T1.C1], [T1.C2]), filter(nil), sort_keys([T1.C2, ASC])
1 - output([T1.C1], [T1.C2]), filter(nil),
access([T1.C1], [T1.C2]), partitions(p0)
~~~
因此,如果將 ORDER BY 后面的常量參數化,不同 ORDER BY 的值具有相同的參數化后的 SQL,從而導致命中錯誤的計劃。除此之外,如下場景中的常量均不能參數化(即參數化的約束條件):
* 所有 ORDER BY 后常量(例如`ORDER BY 1,2;`)
* 所有 GROUP BY 后常量(例如`GROUP BY 1,2;`)
* LIMIT 后常量(例如`LIMIT 5;`)
* 作為格式串的字符串常量(例如`SELECT DATE_FORMAT('2006-06-00', '%d');`里面的`%d`)
* 函數輸入參數中,影響函數結果并最終影響執行計劃的常量(例如`CAST(999.88 as NUMBER(2,1))`中的`NUMBER(2,1)`,或者`SUBSTR('abcd', 1, 2)`中的 1 和 2)
* 函數輸入參數中,帶有隱含信息并最終影響執行計劃的常量(例如`SELECT UNIX_TIMESTAMP('2015-11-13 10:20:19.012');`里面的“2015-11-13 10:20:19.012”,指定輸入時間戳的同時,隱含指定了函數處理的精度值為毫秒)
為了解決上面這種可能存在的誤匹配問題,在硬解析生成執行計劃過程中會對 SQL 請求使用分析語法樹的方法進行參數化,并獲取相應的不一致的信息。例如,某語句對應的信息是“快速參數化參數數組的第 3 項必須為數字 3”,可將其稱為“約束條件”。
對于下例所示的 Q1 查詢:
~~~
Q1:
obclient>SELECT c1, c2, c3 FROM t1
WHERE c1 = 1 AND c2 LIKE 'senior%' ORDER BY 3;
~~~
經過詞法分析,可以得到參數化后的 SQL 語句如下例所示:
~~~
obclient>SELECT c1, c2, c3 FROM t1
WHERE c1 = @1 AND c2 LIKE @2 ORDER BY @3 ;
/*參數化數組為 {1,‘senior%’ ,3}*/
~~~
當 ORDER BY 后面的常量不同時,不能共用相同的執行計劃,因此在通過分析語法樹進行參數化時會獲得另一種參數化結果,如下例所示:
~~~
obclient>SELECT c1, c2, c3 FROM t1
WHERE c1 = @1 AND c2 LIKE @2 ORDER BY 3 ;
/*參數化數組為{1, ‘senior’}
約束條件為“快速參數化參數數組的第 3 項必須為數字 3”*/
~~~
Q1 請求新生成的參數化后的文本及約束條件和執行計劃均會存入計劃緩存中。
當用戶再次發出如下 Q2 請求命令:
~~~
Q2:
obclient>SELECT c1, c2, c3 FROM t1
WHERE c1 = 1 AND c2 LIKE 'senior%' ORDER BY 2;
~~~
經過快速參數化后結果如下例所示:
~~~
obclient>SELECT c1, c2, c3 FROM t1
WHERE c1 = @1 and c2 like @2 ORDER BY @3;
/*參數化數組為 {1,'senior%' ,2}*/
~~~
這與 Q1 請求快速參數化后 SQL 結果一樣,但由于不滿足“快速參數化參數數組的第 3 項必須為數字 3”這個約束條件,無法匹配該計劃。此時 Q2 會通過硬解析生成新的執行計劃及約束條件(即“快速參數化參數數組的第 3 項必須為數字 2”),并將新的計劃和約束條件加入到緩存中,這樣在下次執行 Q1 和 Q2 時均可命中對應正確的執行計劃。
基于快速參數化的執行計劃緩存優點如下:
* 節省了語法分析過程。
* 查找 HASH MAP 時,可以將對參數化后語法樹的 HASH 和比較操作,替換為對文本串進行 HASH 和 MEMCMP 操作,以提高執行效率。
- 前言
- 1.說明
- 2.文檔更新說明
- docker
- 01.docker安裝
- 02.docker加速器
- 03.docker基本使用
- 04.docker 鏡像與容器
- 05.Dockerfile
- 06.docker阿里鏡像倉庫
- 07.docker私有鏡像倉庫harbor
- 08.docker網絡
- 09.docker項目實戰01
- 10.docker項目實戰02
- 11.docker componse
- 12.docker-compose常用命令
- 13.docker compose 案例
- 14.docker swarm集群
- 15.docker swarm常用命令
- 16.docker swarm 案例
- 17.volume
- 18.network
- 19.idea中部署項目到docker
- 20.docker目錄方式掛載sqlite
- 21.docker常用命令補充
- 22.nginx容器代理靜態文件403解決
- 23.docker集群管理平臺
- k8s
- 01.Kubernetes介紹
- 02.K8s基本概念
- 03.K8s架構圖
- 04.Minikube單節點環境搭建
- 05.kubeadm集群安裝1.14.0
- 06.虛擬機靜態網絡配置
- 07.kubeadm高可用集群安裝1.14.0
- 08 高可用VIP配置(keepalived+haproxy)
- 09.高可用免密登錄
- 10.kubeadm init流程
- 11.k8s體驗
- 12.網絡插件
- 13.Ingress
- 14.Ingress分類
- 15.Dashboard
- 16.存儲
- 01.Volumes
- 02.nfs
- 03.PV PVC
- 04.StorageClass
- 17.基礎組件
- 01.Pod
- 02.Service
- 03.ReplicaSet(RS)
- 04.Deployment
- 06.Namespace
- 02.DaemonSet
- 03.StatefulSet
- 04.ReplicationController(RC)
- 06.Job
- 09.PetSet
- 10.StatefulSets
- 11.Federation
- 12.Secret
- 05.Resources
- 13.UserAccount/ServiceAccount
- 14.RBAC
- 18.核心組件
- Master組件
- 01.kube-apiserver
- 02.etcd
- 03.kube-controller-manager
- 04.cloud-controller-manager
- 05.kube-scheduler
- 06.DNS
- Node組件
- 01.kubelet
- 02.kube-proxy
- 03.docker
- 04.RKT
- 05.supervisord
- 06.fluentd
- kubectl
- 19.K8S服務更新部署
- 20.CI/CD
- 01.java安裝
- 02.maven安裝
- 03.gitlab安裝
- 04.git安裝
- 05.jenkins安裝
- 06.k8s集群
- 07.DockerHub
- 08.實戰
- 21.日志
- 01.不同組件日志
- 02.LogPilot+ES+Kibana
- 22.監控
- 23.k8s部署ocp項目[mysql]
- 01.ocp介紹
- 02.環境準備
- 03.鏡像準備
- 04.部署說明
- 05.eureka-server
- 06.mysql
- 07.redis
- 08.auth-server
- 09.user-center
- 10.new-api-gateway
- 11.back-center
- 飛致云kubeoperator
- 01.kubeoperator介紹
- 02.kubeoperator安裝
- 飛致云DataEase
- 項目介紹
- 系統架構
- 安裝部署
- 在線安裝
- 離線安裝
- 用戶手冊
- 通用功能
- 數據源
- 數據集
- 視圖
- 儀表板
- 系統管理
- 用戶管理
- 飛致云JumpServer
- TIDB
- 網絡
- 交換機
- ISO/OSI協議模型詳解
- 交換CCNP
- RSTP快速生成樹協議
- MST多生成樹協議
- 以太網信道【應用廣泛】
- 廣播和多播抑制
- 多層交換
- ARP地址解析協議抑制
- VLAN間路由
- 熱備份路由協議HSRP【思科私有】
- 虛擬路由器冗余協議VRRP
- linux
- 01.時間同步
- linux時間不能同步
- Linux掛載磁盤
- 安裝ftp
- linux環境ftp賬號
- HTTP狀態碼
- 寶塔
- Centos安裝vsftp
- nginx ssl 配置
- datax
- 1.geom類型遷移擴展
- python安裝
- 消息中間件
- 1.RocketMQ
- 1.RocketMQ單機環境安裝
- 前端
- node踩坑之npm
- 數據庫
- Mysql安裝
- ClickHouse
- OceanBase數據庫
- OceanBase介紹
- OceanBase數據庫整體架構
- 快速入門
- 資源準備
- 安裝 OBD部署 OceanBase 數據庫
- 基本操作
- 數據庫操作
- 表操作
- 索引操作
- 插入數據
- 刪除數據
- 更新數據
- 提交事務
- 回滾事務
- 安裝部署
- 使用 RPM 包安裝 OceanBase 數據庫
- 使用源碼構建 OceanBase 數據庫
- 設置無密碼 SSH 登錄
- 配置時鐘源
- 數據分布
- 集群管理
- 租戶與資源管理
- 數據分布1
- 數據副本與服務
- 數據均衡
- 數據模型
- 多租戶架構
- 系統租戶
- 普通租戶
- 表格和表組
- 二級索引
- 無主鍵表
- 視圖
- 高可用
- 高可用方案
- 部署模式
- redo 日志管理控制
- 事務管理
- 隔離級別
- 并發控制
- 全局時間戳服務
- 本地事務
- 分布式事務
- 分布式查詢
- 存儲架構
- LSM Tree 架構
- 內存表 MemTable
- 塊存儲 SSTable
- 轉儲和合并
- 緩存機制
- 讀寫流程
- DDL
- SQL 引擎
- SQL 請求執行流程
- 查詢改寫
- 基于規則的查詢改寫
- 基于代價的查詢改寫
- 查詢優化
- 訪問路徑
- 基于規則的路徑選擇
- 基于代價的路徑選擇
- 聯接算法
- 聯接算法
- 聯接順序
- SQL 執行計劃
- 執行計劃算子
- TABLE SCAN
- TABLE LOOKUP
- JOIN
- COUNT
- GROUP BY
- WINDOW FUNCTION
- SUBPLAN FILTER
- DISTINCT
- SEQUENCE
- MATERIAL
- SORT
- LIMIT
- FOR UPDATE
- SELECT INTO
- SUBPLAN SCAN
- UNION
- INTERSECT
- EXCEPT/MINUS
- INSERT
- DELETE
- UPDATE
- MERGE
- EXCHANGE
- GI
- 執行計劃緩存
- 快速參數化
- 實時執行計劃展示
- 分布式執行計劃
- 分布式執行和并行查詢
- 分布式計劃的生成
- 分布式執行計劃調度
- 分布式執行計劃管理
- 并行查詢的執行
- 并行查詢的參數調優
- 備份與恢復
- 備份架構
- 恢復架構
- Backup Set
- Archive Log Round
- 管理員指南
- 數據庫基礎組件介紹
- 數據庫管理工具介紹
- OceanBase 客戶端
- MySQL 客戶端
- 數據庫基礎管理
- OceanBase 集群管理
- 集群參數管理
- 查詢集群參數
- 修改集群參數
- Zone 管理
- 增加或刪除 Zone
- 啟動或停止 Zone
- 修改 Zone
- OBServer 管理
- 查看 OBServer 狀態
- 停止 OBServer
- 啟動 OBServer
- 管理 OBServer 節點狀態
- 資源管理
- 創建資源單元
- 查看資源單元
- 修改資源單元
- 刪除資源單元
- 創建資源池
- 查看資源配置
- 修改資源池
- 刪除資源池
- 租戶管理
- 創建用戶租戶
- 新建租戶
- 查看租戶
- 修改租戶
- 刪除租戶
- 查看租戶會話
- 終止租戶會話
- 租戶管理變量
- 內存管理
- OceanBase 內存結構
- OceanBase 數據庫內存上限
- 系統內部內存管理
- 租戶內部內存管理
- 執行計劃緩存
- 常見內存問題
- 數據庫對象管理
- 管理表
- 關于表
- 創建表
- 定義自增列
- 定義列的約束類型
- 查看表的定義
- 更改表
- 清空表
- 刪除表
- 管理表組
- 關于表組
- 表組管理命令
- 管理索引
- 關于索引
- 創建索引
- 查看索引
- 刪除索引
- 視圖和同義詞管理
- 管理視圖
- 管理同義詞
- 數據分布和鏈路管理
- 分區表和分區索引管理
- 關于分區
- 分區策略
- 創建分區表
- 一級分區表
- 二級分區表
- 維護分區表
- 一級分區表
- 二級分區表
- 分區裁剪
- 分區命名與查詢
- 在分區表上建立索引
- 局部索引
- 全局索引
- 使用索引
- 副本管理
- 表級副本的使用
- Locality 管理
- 修改租戶的 Locality
- 事務管理
- 提交事務
- 回滾事務
- 事務隔離級別
- 用戶權限管理
- 創建用戶
- 修改用戶權限
- 查看白名單
- 鎖定和解鎖用戶
- 刪除用戶
- 數據高可用
- 回收站管理
- 回收站支持的對象
- 數據庫、表和索引級回收站
- 租戶級回收站
- 物理備份與恢復管理
- 部署 NFS
- 備份數據
- 通過命令行備份
- 查看備份進度
- 停止備份
- 刪除過期的備份
- 清理備份數據
- 取消清理備份數據
- 恢復數據
- 執行恢復
- 查看恢復進度和結果
- 備份維護
- 開發者指南
- 關于OceanBase數據庫
- OceanBase 集群簡介
- OceanBase 租戶簡介
- MySQL 租戶數據庫對象
- MySQL 客戶端
- OceanBase 客戶端(obclient)
- 關于結構化查詢語言
- Java 數據庫連接驅動(JDBC)
- 連接OceanBase數據庫
- 通過 MySQL 客戶端連接 OceanBase 租戶
- 通過 obclient 連接 OceanBase 租戶
- 創建 OceanBase 示例數據庫 TPCC
- 通過 obclient 探索 OceanBase MySQL 租戶
- 查詢表數據
- 關于查詢語句
- 查詢表里符合特定搜索條件的數據
- 對查詢的結果進行排序
- 從多個表里查詢數據
- 在查詢中使用操作符和函數
- 查看查詢執行計劃
- 在查詢中使用 SQL Hint
- 關于查詢超時設計
- 關于 DML 語句和事務
- 關于 DML 語句
- 關于 INSERT 語句
- 關于 UPDATE 語句
- 關于 DELETE 語句
- 關于 REPLACE INTO 語句
- 關于事務控制語句
- 提交事務
- 回滾事務
- 事務保存點
- 關于事務超時
- 創建和管理數據庫對象
- 關于 DDL 語句
- 創建數據庫
- 創建和管理表
- 關于 SQL 數據類型
- 創建表
- 關于自增列
- 關于列的約束類型
- 關于表的索引
- 閃回被刪除的表
- 創建和管理分區表
- 分區路由
- 分區策略
- 分區表的索引
- 分區表使用建議
- 創建和管理表組
- 關于表組
- 創建表時指定表組
- 查看表組信息
- 向表組中增加表
- 刪除表組
- 創建和管理視圖
- 創建視圖
- 修改視圖
- 刪除視圖
- 向 OceanBase 遷移數據
- DataX
- 不同數據源的 DataX 讀寫插件示例
- OceanBase 數據加載技術
- 附錄
- OceanBase 常用參數和變量
- OceanBase 常用 SQL
- SQL參考
- 基本元素
- 運算符
- 函數
- 函數
- 聚集函數
- 分析函數
- 信息函數
- 其它函數
- 查詢和子查詢
- 連接
- 集合
- SQL語句
- 通用語法
- ALTER DATABASE
- ALTER OUTLINE
- ALTER RESOURCE POOL
- ALTER RESOURCE UNIT
- ALTER SYSTEM
- ALTER TABLE
- ALTER TABLEGROUP
- ALTER TENANT
- ALTER USER
- CREATE DATABASE
- CREATE INDEX
- CREATE OUTLINE
- CREATE RESOURCE POOL
- CREATE RESOURCE UNIT
- CREATE RESTORE POINT
- CREATE SYNONYM
- CREATE TABLE
- CREATE TABLEGROUP
- CREATE TENANT
- CREATE USER
- CREATE VIEW
- DELETE
- DROP DATABASE
- DROP INDEX
- DROP OUTLINE
- DROP RESOURCE POOL
- DROP RESOURCE UNIT
- DROP RESTORE POINT
- DROP TABLE
- DROP TABLEGROUP
- DROP TENANT
- DROP SYNONYM
- DROP USER
- DROP VIEW
- EXPLAIN
- FLASHBACK DATABASE
- FLASHBACK TABLE
- FLASHBACK TENANT
- GRANT
- INSERT
- KILL
- PURGE DATABASE
- PURGE INDEX
- PURGE RECYCLEBIN
- PURGE TABLE
- PURGE TENANT
- RENAME TABLE
- RENAME USER
- REPLACE
- REVOKE
- SAVEPOINT
- SCHEMA
- SELECT
- SESSION
- SET PASSWORD
- SHOW GRANTS
- SHOW RECYCLEBIN
- TRANSACTION
- TRUNCATE TABLE
- UPDATE
- SQL調優指南
- SQL請求執行流程
- SQL 執行計劃
- SQL 執行計劃簡介
- 執行計劃算子
- TABLE SCAN
- TABLE LOOKUP
- JOIN
- COUNT
- GROUP BY
- WINDOW FUNCTION
- SUBPLAN FILTER
- DISTINCT
- SEQUENCE
- MATERIAL
- SORT
- LIMIT
- FOR UPDATE
- SELECT INTO
- SUBPLAN SCAN
- UNION
- INTERSECT
- EXCEPT/MINUS
- INSERT
- DELETE
- UPDATE
- MERGE
- EXCHANGE
- GI
- 執行計劃緩存
- 快速參數化
- 實時執行計劃展示
- 分布式執行計劃
- 分布式執行和并行查詢
- 分布式計劃的生成
- 分布式執行計劃調度
- 分布式執行計劃管理
- 并行查詢的執行
- 并行查詢的參數調優
- 參考指南
- 系統視圖
- 概述
- 字典視圖
- mysql.help_topic
- mysql.help_category
- mysql.help_keyword
- mysql.help_relation
- mysql.db
- mysql.proc
- mysql.time_zone
- mysql.time_zone_name
- mysql.time_zone_transition
- mysql.time_zone_transition_type
- mysql.user
- information_schema.CHARACTER_SETS
- information_schema.COLLATIONS
- information_schema.COLLATION_CHARACTER_SET_APPLICABILITY
- information_schema.COLUMNS
- information_schema.DBA_OUTLINES
- information_schema.ENGINES
- information_schema.GLOBAL_STATUS
- information_schema.GLOBAL_VARIABLES
- information_schema.KEY_COLUMN_USAGE
- information_schema.PARAMETERS
- information_schema.PARTITIONS
- information_schema.PROCESSLIST
- information_schema.REFERENTIAL_CONSTRAINTS
- information_schema.ROUTINES
- information_schema.SCHEMATA
- information_schema.SCHEMA_PRIVILEGES
- information_schema.SESSION_STATUS
- information_schema.SESSION_VARIABLES
- information_schema.STATISTICS
- information_schema.TABLES
- information_schema.TABLE_CONSTRAINTS
- information_schema.TABLE_PRIVILEGES
- information_schema.USER_PRIVILEGES
- information_schema.USER_RECYCLEBIN
- information_schema.VIEWS
- oceanbase.CDB_OB_BACKUP_ARCHIVELOG_SUMMARY
- oceanbase.CDB_OB_BACKUP_JOB_DETAILS
- oceanbase.CDB_OB_BACKUP_SET_DETAILS
- oceanbase.CDB_OB_BACKUP_PROGRESS
- oceanbase.CDB_OB_BACKUP_SET_EXPIRED
- oceanbase.CDB_OB_BACKUP_ARCHIVELOG_PROGRESS
- oceanbase.CDB_OB_BACKUP_CLEAN_HISTORY
- oceanbase.CDB_OB_BACKUP_TASK_CLEAN_HISTORY
- oceanbase.CDB_OB_RESTORE_PROGRESS
- oceanbase.CDB_OB_RESTORE_HISTORY
- oceanbase.CDB_CKPT_HISTORY
- oceanbase.CDB_OB_BACKUP_VALIDATION_JOB
- oceanbase.CDB_OB_BACKUP_VALIDATION_JOB_HISTORY
- oceanbase.CDB_OB_TENANT_BACKUP_VALIDATION_TASK
- oceanbase.CDB_OB_BACKUP_VALIDATION_TASK_HISTORY
- oceanbase.CDB_OB_BACKUP_BACKUP_ARCHIVELOG_SUMMARY
- oceanbase.CDB_OB_BACKUP_BACKUPSET_TASK_HISTORY
- oceanbase.CDB_OB_BACKUP_BACKUPSET_TASK
- oceanbase.CDB_OB_BACKUP_BACKUPSET_JOB_HISTORY
- oceanbase.CDB_OB_BACKUP_BACKUPSET_JOB
- oceanbase.CDB_OB_BACKUP_SET_OBSOLETE
- 性能視圖
- gv$plan_cache_stat
- gv$plan_cache_plan_stat
- gv$session_event
- gv$session_wait
- gv$session_wait_history
- gv$system_event
- gv$sesstat
- gv$sysstat
- gv$sql_audit
- gv$latch
- gv$memory
- gv$memstore
- gv$memstore_info
- gv$plan_cache_plan_explain
- gv$obrpc_outgoing
- gv$obrpc_incoming
- gv$sql
- gv$sql_plan_monitor
- gv$outline
- gv$concurrent_limit_sql
- gv$sql_plan_statistics
- gv$server_memstore
- gv$unit_load_balance_event_history
- gv$tenant
- gv$database
- gv$table
- gv$unit
- gv$partition
- gv$lock_wait_stat
- gv$session_longops
- gv$tenant_memstore_allocator_info
- gv$minor_merge_info
- gv$tenant_px_worker_stat
- gv$partition_audit
- gv$ps_stat
- gv$ps_item_info
- gv$sql_workarea
- gv$sql_workarea_histogram
- gv$ob_sql_workarea_memory_info
- gv$server_schema_info
- gv$merge_info
- gv$lock
- gv$sstable
- gv$ob_trans_table_status
- v$statname
- v$event_name
- v$session_event
- v$session_wait
- v$session_wait_history
- v$sesstat
- v$sysstat
- v$system_event
- v$memory
- v$memstore
- v$memstore_info
- v$plan_cache_stat
- v$plan_cache_plan_stat
- v$plan_cache_plan_explain
- v$sql_audit
- v$obrpc_outgoing
- v$obrpc_incoming
- v$sql
- v$sql_monitor
- v$sql_plan_monitor
- v$sql_plan_statistics
- v$unit
- v$partition
- v$lock_wait_stat
- v$session_longops
- v$latch
- v$tenant_memstore_allocator_info
- v$tenant_px_worker_stat
- v$partition_audit
- v$ob_cluster
- v$ob_standby_status
- v$ob_cluster_stats
- v$ob_cluster_event_history
- v$ps_stat
- v$ps_item_info
- v$sql_workarea
- v$sql_workarea_active
- v$sql_workarea_histogram
- v$ob_sql_workarea_memory_info
- v$ob_timestamp_service
- v$server_schema_info
- v$merge_info
- v$lock
- v$sql_monitor_statname
- v$restore_point
- v$ob_cluster_failover_info
- v$encrypted_tables
- v$encrypted_tablespaces
- v$sstable
- v$ob_trans_table_status
- 系統變量
- 系統變量概述
- auto_increment_increment
- auto_increment_offset
- autocommit
- character_set_client
- character_set_connection
- character_set_database
- character_set_results
- character_set_server
- character_set_system
- collation_connection
- collation_database
- collation_server
- interactive_timeout
- last_insert_id
- max_allowed_packet
- sql_mode
- time_zone
- tx_isolation
- version_comment
- wait_timeout
- binlog_row_image
- character_set_filesystem
- connect_timeout
- datadir
- debug_sync
- div_precision_increment
- explicit_defaults_for_timestamp
- group_concat_max_len
- identity
- lower_case_table_names
- net_read_timeout
- net_write_timeout
- read_only
- sql_auto_is_null
- sql_select_limit
- timestamp
- tx_read_only
- version
- sql_warnings
- max_user_connections
- init_connect
- license
- net_buffer_length
- system_time_zone
- query_cache_size
- query_cache_type
- sql_quote_show_create
- max_sp_recursion_depth
- sql_safe_updates
- ob_proxy_partition_hit
- ob_log_level
- ob_max_parallel_degree
- ob_query_timeout
- ob_read_consistency
- ob_enable_transformation
- ob_trx_timeout
- ob_enable_plan_cache
- ob_enable_index_direct_select
- ob_proxy_set_trx_executed
- ob_enable_aggregation_pushdown
- ob_last_schema_version
- ob_global_debug_sync
- ob_proxy_global_variables_version
- ob_enable_trace_log
- ob_enable_hash_group_by
- ob_enable_blk_nestedloop_join
- ob_bnl_join_cache_size
- ob_org_cluster_id
- ob_plan_cache_percentage
- ob_plan_cache_evict_high_percentage
- ob_plan_cache_evict_low_percentage
- recyclebin
- ob_capability_flag
- ob_stmt_parallel_degree
- is_result_accurate
- error_on_overlap_time
- ob_compatibility_mode
- ob_create_table_strict_mode
- ob_sql_work_area_percentage
- ob_route_policy
- ob_enable_transmission_checksum
- foreign_key_checks
- ob_enable_truncate_flashback
- ob_tcp_invited_nodes
- sql_throttle_current_priority
- sql_throttle_priority
- sql_throttle_rt
- sql_throttle_network
- auto_increment_cache_size
- ob_enable_jit
- ob_timestamp_service
- plugin_dir
- undo_retention
- ob_sql_audit_percentage
- ob_enable_sql_audit
- optimizer_use_sql_plan_baselines
- optimizer_capture_sql_plan_baselines
- parallel_max_servers
- parallel_servers_target
- ob_trx_idle_timeout
- block_encryption_mode
- ob_reserved_meta_memory_percentage
- ob_check_sys_variable
- tracefile_identifier
- transaction_isolation
- ob_trx_lock_timeout
- validate_password_check_user_name
- validate_password_length
- validate_password_mixed_case_count
- validate_password_number_count
- validate_password_policy
- validate_password_special_char_count
- default_password_lifetime
- ob_trace_info
- secure_file_priv
- ob_pl_block_timeout
- performance_schema
- transaction_read_only
- resource_manager_plan
- 系統配置項
- 系統配置項概述
- auto_leader_switch_interval
- auto_delete_expired_backup
- autoinc_cache_refresh_interval
- audit_sys_operations
- audit_trail
- balancer_idle_time
- balancer_log_interval
- balancer_timeout_check_interval
- balancer_task_timeout
- balancer_tolerance_percentage
- balancer_emergency_percentage
- balance_blacklist_failure_threshold
- balance_blacklist_retry_interval
- backup_concurrency
- backup_dest
- backup_net_limit
- backup_recovery_window
- backup_region
- builtin_db_data_verify_cycle
- bf_cache_miss_count_threshold
- bf_cache_priority
- cache_wash_threshold
- clog_cache_priority
- clog_sync_time_warn_threshold
- clog_disk_usage_limit_percentage
- clog_transport_compress_all
- clog_transport_compress_func
- clog_persistence_compress_func
- clog_max_unconfirmed_log_count
- cluster
- cluster_id
- cpu_count
- cpu_quota_concurrency
- cpu_reserved
- config_additional_dir
- data_copy_concurrency
- data_dir
- datafile_disk_percentage
- dtl_buffer_size
- datafile_size
- debug_sync_timeout
- default_compress_func
- default_compress
- default_progressive_merge_num
- default_row_format
- devname
- data_disk_usage_limit_percentage
- disk_io_thread_count
- dead_socket_detection_timeout
- enable_clog_persistence_compress
- election_cpu_quota
- enable_one_phase_commit
- enable_sys_unit_standalone
- enable_pg
- enable_smooth_leader_switch
- election_blacklist_interval
- enable_election_group
- enable_auto_leader_switch
- enable_global_freeze_trigger
- enable_manual_merge
- enable_merge_by_turn
- enable_perf_event
- enable_rebalance
- enable_record_trace_log
- enable_record_trace_id
- enable_early_lock_release
- enable_rereplication
- enable_rich_error_msg
- enable_rootservice_standalone
- enable_sql_audit
- enable_sql_operator_dump
- enable_async_syslog
- enable_syslog_recycle
- enable_syslog_wf
- enable_upgrade_mode
- enable_separate_sys_clog
- enable_ddl
- enable_major_freeze
- enable_rebuild_on_purpose
- enable_log_archive
- enable_monotonic_weak_read
- external_kms_info
- freeze_trigger_percentage
- flush_log_at_trx_commit
- fuse_row_cache_priority
- force_refresh_location_cache_interval
- force_refresh_location_cache_threshold
- get_leader_candidate_rpc_timeout
- global_major_freeze_residual_memory
- global_write_halt_residual_memory
- ignore_replay_checksum_error
- global_index_build_single_replica_timeout
- high_priority_net_thread_count
- ignore_replica_checksum_error
- ignore_replay_checksum_error
- index_cache_priority
- index_clog_cache_priority
- index_info_block_cache_priority
- internal_sql_execute_timeout
- large_query_worker_percentage
- large_query_threshold
- leak_mod_to_check
- lease_time
- location_cache_cpu_quota
- location_cache_expire_time
- location_cache_priority
- location_cache_refresh_min_interval
- location_fetch_concurrency
- location_refresh_thread_count
- log_archive_checkpoint_interval
- log_archive_concurrency
- log_restore_concurrency
- major_freeze_duty_time
- max_kept_major_version_number
- max_string_print_length
- max_syslog_file_count
- merge_stat_sampling_ratio
- major_compact_trigger
- memory_chunk_cache_size
- memory_limit
- memory_limit_percentage
- memory_reserved
- merge_thread_count
- merger_check_interval
- merger_completion_percentage
- merger_switch_leader_duration_time
- merger_warm_up_duration_time
- max_px_worker_count
- migration_disable_time
- min_observer_version
- minor_deferred_gc_time
- minor_freeze_times
- minor_warm_up_duration_time
- mysql_port
- minor_merge_concurrency
- multiblock_read_gap_size
- multiblock_read_size
- micro_block_merge_verify_level
- migrate_concurrency
- minor_compact_trigger
- memstore_limit_percentage
- net_thread_count
- obconfig_url
- ob_enable_batched_multi_statement
- partition_table_check_interval
- partition_table_scan_batch_count
- plan_cache_evict_interval
- px_task_size
- px_workers_per_cpu_quota
- replica_safe_remove_time
- resource_hard_limit
- resource_soft_limit
- rootservice_async_task_queue_size
- rootservice_async_task_thread_count
- rootservice_list
- rootservice_ready_check_interval
- row_compaction_update_limit
- row_purge_thread_count
- rpc_port
- rpc_timeout
- restore_concurrency
- rootservice_memory_limit
- rebuild_replica_data_lag_threshold
- schema_history_expire_time
- ssl_client_authentication
- server_check_interval
- server_data_copy_in_concurrency
- server_data_copy_out_concurrency
- server_permanent_offline_time
- stack_size
- server_balance_critical_disk_waterlevel
- server_balance_disk_tolerance_percent
- system_memory
- server_balance_cpu_mem_tolerance_percent
- server_cpu_quota_max
- server_cpu_quota_min
- sql_audit_memory_limit
- sys_bkgd_io_high_percentage
- sys_bkgd_io_low_percentage
- sys_bkgd_io_timeout
- sys_bkgd_net_percentage
- sys_bkgd_migration_change_member_list_timeout
- sys_bkgd_migration_retry_num
- syslog_level
- switchover_process_thread_count
- system_cpu_quota
- sys_cpu_limit_trigger
- syslog_io_bandwidth_limit
- tablet_size
- tableapi_transport_compress_func
- tenant_task_queue_size
- tenant_groups
- trace_log_slow_query_watermark
- trace_log_sampling_interval
- trx_2pc_retry_interval
- trx_force_kill_threshold
- tde_method
- token_reserved_percentage
- unit_balance_resource_weight
- user_block_cache_priority
- user_row_cache_priority
- user_tab_col_stat_cache_priority
- user_iort_up_percentage
- use_large_pages
- virtual_table_location_cache_expire_time
- workers_per_cpu_quota
- wait_leader_batch_count
- writing_throttling_maximum_duration
- writing_throttling_trigger_percentage
- weak_read_version_refresh_interval
- workarea_size_policy
- zone
- zone_merge_concurrency
- zone_merge_order
- zone_merge_timeout
- ob_ssl_invited_common_names
- ssl_external_kms_info
- ob_event_history_recycle_interval
- backup_log_archive_checkpoint_interval
- plsql_ccflags
- plsql_code_type
- plsql_debug
- plsql_optimize_level
- plsql_v2_compatibility
- plsql_warnings
- recyclebin_object_expire_time
- log_archive_batch_buffer_limit
- clog_disk_utilization_threshold
- backup_backup_archive_log_batch_count
- backup_backup_archivelog_retry_interval
- backup_backupset_batch_count
- backup_backupset_retry_interval
- open_cursors
- fast_recovery_concurrency
- 預留關鍵字
- 部署實踐
- 設置無密碼 SSH 登錄
- 單機安裝
- 本地安裝
- 分布式安裝
- 創建租戶
- OceanBaseDeploy(OBD)常用命令
- 大數據
- 數據倉庫分層
- 數據倉庫分層實踐
- hive安裝
- hive命令
- hadoop安裝
- jdk安裝
- 應龍inlong
- 網關
- apisix
- apisix2.7源碼安裝
- apisix rpm2.6安裝
- apisix-dashboard2.7 rpm安裝
- apisix-dashboard使用
- apisix-dashboard進階