
## Java概述
### 何為編程
* 編程就是讓計算機為解決某個問題而使用某種程序設計語言編寫程序代碼,并最終得到結果的過程。
* 為了使計算機能夠理解人的意圖,人類就必須要將需解決的問題的思路、方法、和手段通過計算機能夠理解的形式告訴計算機,使得計算機能夠根據人的指令一步一步去工作,完成某種特定的任務。這種人和計算機之間交流的過程就是編程。
### 什么是Java
* Java是一門面向對象編程語言,不僅吸收了C++語言的各種優點,還摒棄了C++里難以理解的多繼承、指針等概念,因此Java語言具有功能強大和簡單易用兩個特征。Java語言作為靜態面向對象編程語言的代表,極好地實現了面向對象理論,允許程序員以優雅的思維方式進行復雜的編程 。
### jdk1.5之后的三大版本
* Java SE(J2SE,Java 2 Platform Standard Edition,標準版)
Java SE 以前稱為 J2SE。它允許開發和部署在桌面、服務器、嵌入式環境和實時環境中使用的 Java 應用程序。Java SE 包含了支持 Java Web 服務開發的類,并為Java EE和Java ME提供基礎。
* Java EE(J2EE,Java 2 Platform Enterprise Edition,企業版)
Java EE 以前稱為 J2EE。企業版本幫助開發和部署可移植、健壯、可伸縮且安全的服務器端Java 應用程序。Java EE 是在 Java SE 的基礎上構建的,它提供 Web 服務、組件模型、管理和通信 API,可以用來實現企業級的面向服務體系結構(service-oriented architecture,SOA)和 Web2.0應用程序。2018年2月,Eclipse 宣布正式將 JavaEE 更名為 JakartaEE
* Java ME(J2ME,Java 2 Platform Micro Edition,微型版)
Java ME 以前稱為 J2ME。Java ME 為在移動設備和嵌入式設備(比如手機、PDA、電視機頂盒和打印機)上運行的應用程序提供一個健壯且靈活的環境。Java ME 包括靈活的用戶界面、健壯的安全模型、許多內置的網絡協議以及對可以動態下載的連網和離線應用程序的豐富支持。基于 Java ME 規范的應用程序只需編寫一次,就可以用于許多設備,而且可以利用每個設備的本機功能。
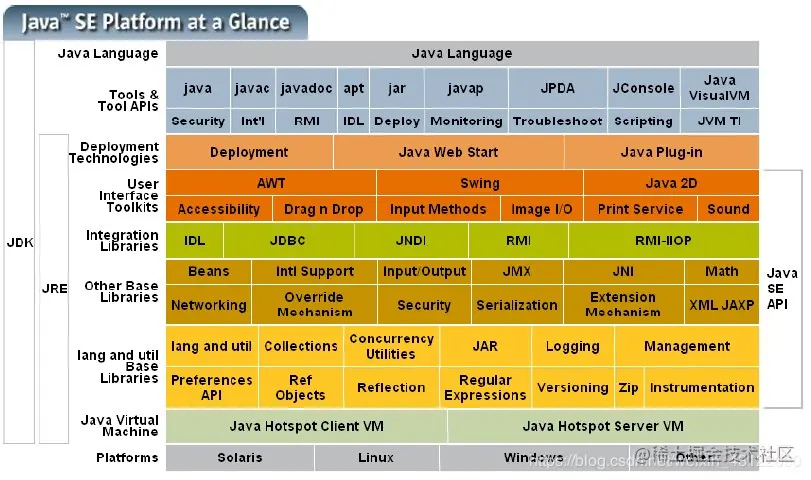
### 3 Jdk和Jre和JVM的區別
`看Java官方的圖片,Jdk中包括了Jre,Jre中包括了JVM`
* JDK :Jdk還包括了一些Jre之外的東西 ,就是這些東西幫我們編譯Java代碼的, 還有就是監控Jvm的一些工具 Java Development Kit是提供給Java開發人員使用的,其中包含了Java的開發工具,也包括了JRE。所以安裝了JDK,就無需再單獨安裝JRE了。其中的開發工具:編譯工具(javac.exe),打包工具(jar.exe)等
* JRE :Jre大部分都是 C 和 C++ 語言編寫的,他是我們在編譯java時所需要的基礎的類庫 Java Runtime Environment包括Java虛擬機和Java程序所需的核心類庫等。核心類庫主要是java.lang包:包含了運行Java程序必不可少的系統類,如基本數據類型、基本數學函數、字符串處理、線程、異常處理類等,系統缺省加載這個包
如果想要運行一個開發好的Java程序,計算機中只需要安裝JRE即可。
* Jvm:在倒數第二層 由他可以在(最后一層的)各種平臺上運行 Java Virtual Machine是Java虛擬機,Java程序需要運行在虛擬機上,不同的平臺有自己的虛擬機,因此Java語言可以實現跨平臺。
### 什么是跨平臺性?原理是什么
* 所謂跨平臺性,是指java語言編寫的程序,一次編譯后,可以在多個系統平臺上運行。
* 實現原理:Java程序是通過java虛擬機在系統平臺上運行的,只要該系統可以安裝相應的java虛擬機,該系統就可以運行java程序。
### Java語言有哪些特點
* 簡單易學(Java語言的語法與C語言和C++語言很接近)
* 面向對象(封裝,繼承,多態)
* 平臺無關性(Java虛擬機實現平臺無關性)
* 支持網絡編程并且很方便(Java語言誕生本身就是為簡化網絡編程設計的)
* 支持多線程(多線程機制使應用程序在同一時間并行執行多項任)
* 健壯性(Java語言的強類型機制、異常處理、垃圾的自動收集等)
* 安全性好
### 什么是字節碼?采用字節碼的最大好處是什么
* **字節碼**:Java源代碼經過虛擬機編譯器編譯后產生的文件(即擴展為.class的文件),它不面向任何特定的處理器,只面向虛擬機。
* **采用字節碼的好處**:
Java語言通過字節碼的方式,在一定程度上解決了傳統解釋型語言執行效率低的問題,同時又保留了解釋型語言可移植的特點。所以Java程序運行時比較高效,而且,由于字節碼并不專對一種特定的機器,因此,Java程序無須重新編譯便可在多種不同的計算機上運行。
* **先看下java中的編譯器和解釋器**:
Java中引入了虛擬機的概念,即在機器和編譯程序之間加入了一層抽象的虛擬機器。這臺虛擬的機器在任何平臺上都提供給編譯程序一個的共同的接口。編譯程序只需要面向虛擬機,生成虛擬機能夠理解的代碼,然后由解釋器來將虛擬機代碼轉換為特定系統的機器碼執行。在Java中,這種供虛擬機理解的代碼叫做字節碼(即擴展為.class的文件),它不面向任何特定的處理器,只面向虛擬機。每一種平臺的解釋器是不同的,但是實現的虛擬機是相同的。Java源程序經過編譯器編譯后變成字節碼,字節碼由虛擬機解釋執行,虛擬機將每一條要執行的字節碼送給解釋器,解釋器將其翻譯成特定機器上的機器碼,然后在特定的機器上運行,這就是上面提到的Java的特點的編譯與解釋并存的解釋。
Java源代碼---->編譯器---->jvm可執行的Java字節碼(即虛擬指令)---->jvm---->jvm中解釋器----->機器可執行的二進制機器碼---->程序運行。
### 什么是Java程序的主類?應用程序和小程序的主類有何不同?
* 一個程序中可以有多個類,但只能有一個類是主類。在Java應用程序中,這個主類是指包含main()方法的類。而在Java小程序中,這個主類是一個繼承自系統類JApplet或Applet的子類。應用程序的主類不一定要求是public類,但小程序的主類要求必須是public類。主類是Java程序執行的入口點。
### Java應用程序與小程序之間有那些差別?
* 簡單說應用程序是從主線程啟動(也就是main()方法)。applet小程序沒有main方法,主要是嵌在瀏覽器頁面上運行(調用init()線程或者run()來啟動),嵌入瀏覽器這點跟flash的小游戲類似。
### Java和C++的區別
`我知道很多人沒學過C++,但是面試官就是沒事喜歡拿咱們Java和C++比呀!沒辦法!!!就算沒學過C++,也要記下來!`
* 都是面向對象的語言,都支持封裝、繼承和多態
* Java不提供指針來直接訪問內存,程序內存更加安全
* Java的類是單繼承的,C++支持多重繼承;雖然Java的類不可以多繼承,但是接口可以多繼承。
* Java有自動內存管理機制,不需要程序員手動釋放無用內存
### Oracle JDK 和 OpenJDK 的對比
1. Oracle JDK版本將每三年發布一次,而OpenJDK版本每三個月發布一次;
2. OpenJDK 是一個參考模型并且是完全開源的,而Oracle JDK是OpenJDK的一個實現,并不是完全開源的;
3. Oracle JDK 比 OpenJDK 更穩定。OpenJDK和Oracle JDK的代碼幾乎相同,但Oracle JDK有更多的類和一些錯誤修復。因此,如果您想開發企業/商業軟件,我建議您選擇Oracle JDK,因為它經過了徹底的測試和穩定。某些情況下,有些人提到在使用OpenJDK 可能會遇到了許多應用程序崩潰的問題,但是,只需切換到Oracle JDK就可以解決問題;
4. 在響應性和JVM性能方面,Oracle JDK與OpenJDK相比提供了更好的性能;
5. Oracle JDK不會為即將發布的版本提供長期支持,用戶每次都必須通過更新到最新版本獲得支持來獲取最新版本;
6. Oracle JDK根據二進制代碼許可協議獲得許可,而OpenJDK根據GPL v2許可獲得許可。
## 基礎語法
### 數據類型
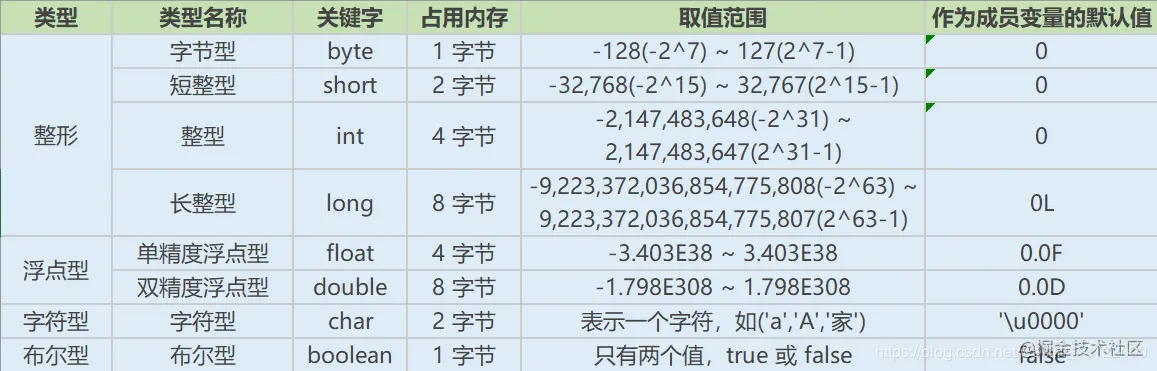
#### Java有哪些數據類型
**定義**:Java語言是強類型語言,對于每一種數據都定義了明確的具體的數據類型,在內存中分配了不同大小的內存空間。
**分類**
* 基本數據類型
* 數值型
* 整數類型(byte,short,int,long)
* 浮點類型(float,double)
* 字符型(char)
* 布爾型(boolean)
* 引用數據類型
* 類(class)
* 接口(interface)
* 數組(\[\])
**Java基本數據類型圖**
#### switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String 上
* 在 Java 5 以前,switch(expr)中,expr 只能是 byte、short、char、int。從 Java5 開始,Java 中引入了枚舉類型,expr 也可以是 enum 類型,從 Java 7 開始,expr 還可以是字符串(String),但是長整型(long)在目前所有的版本中都是不可以的。
#### 用最有效率的方法計算 2 乘以 8
* 2 << 3(左移 3 位相當于乘以 2 的 3 次方,右移 3 位相當于除以 2 的 3 次方)。
#### Math.round(11.5) 等于多少?Math.round(-11.5)等于多少
* Math.round(11.5)的返回值是 12,Math.round(-11.5)的返回值是-11。四舍五入的原理是在參數上加 0.5 然后進行下取整。
#### float f=3.4;是否正確
* 不正確。3.4 是雙精度數,將雙精度型(double)賦值給浮點型(float)屬于下轉型(down-casting,也稱為窄化)會造成精度損失,因此需要強制類型轉換float f =(float)3.4; 或者寫成 float f =3.4F;。
#### short s1 = 1; s1 = s1 + 1;有錯嗎?short s1 = 1; s1 += 1;有錯嗎
* 對于 short s1 = 1; s1 = s1 + 1;由于 1 是 int 類型,因此 s1+1 運算結果也是 int型,需要強制轉換類型才能賦值給 short 型。
* 而 short s1 = 1; s1 += 1;可以正確編譯,因為 s1+= 1;相當于 s1 = (short(s1 + 1);其中有隱含的強制類型轉換。
### 編碼
#### Java語言采用何種編碼方案?有何特點?
* Java語言采用Unicode編碼標準,Unicode(標準碼),它為每個字符制訂了一個唯一的數值,因此在任何的語言,平臺,程序都可以放心的使用。
### 注釋
#### 什么Java注釋
**定義**:用于解釋說明程序的文字
**分類**
* 單行注釋
格式: // 注釋文字
* 多行注釋
格式: /\* 注釋文字 \*/
* 文檔注釋
格式:/\*\* 注釋文字 \*/
**作用**
* 在程序中,尤其是復雜的程序中,適當地加入注釋可以增加程序的可讀性,有利于程序的修改、調試和交流。注釋的內容在程序編譯的時候會被忽視,不會產生目標代碼,注釋的部分不會對程序的執行結果產生任何影響。
`注意事項:多行和文檔注釋都不能嵌套使用。`
### 訪問修飾符
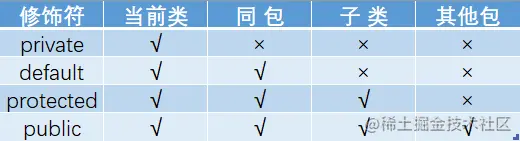
#### 訪問修飾符 public,private,protected,以及不寫(默認)時的區別
* **定義**:Java中,可以使用訪問修飾符來保護對類、變量、方法和構造方法的訪問。Java 支持 4 種不同的訪問權限。
* **分類**
* private : 在同一類內可見。使用對象:變量、方法。 注意:不能修飾類(外部類)
* default (即缺省,什么也不寫,不使用任何關鍵字): 在同一包內可見,不使用任何修飾符。使用對象:類、接口、變量、方法。
* protected : 對同一包內的類和所有子類可見。使用對象:變量、方法。 注意:不能修飾類(外部類)。
* public : 對所有類可見。使用對象:類、接口、變量、方法
**訪問修飾符圖**
### 運算符
#### &和&&的區別
* &運算符有兩種用法:(1)按位與;(2)邏輯與。
* &&運算符是短路與運算。邏輯與跟短路與的差別是非常巨大的,雖然二者都要求運算符左右兩端的布爾值都是true 整個表達式的值才是 true。&&之所以稱為短路運算,是因為如果&&左邊的表達式的值是 false,右邊的表達式會被直接短路掉,不會進行運算。
`注意:邏輯或運算符(|)和短路或運算符(||)的差別也是如此。`
### 關鍵字
#### Java 有沒有 goto
* goto 是 Java 中的保留字,在目前版本的 Java 中沒有使用。
#### final 有什么用?
`用于修飾類、屬性和方法;`
* 被final修飾的類不可以被繼承
* 被final修飾的方法不可以被重寫
* 被final修飾的變量不可以被改變,被final修飾不可變的是變量的引用,而不是引用指向的內容,引用指向的內容是可以改變的
#### final finally finalize區別
* final可以修飾類、變量、方法,修飾類表示該類不能被繼承、修飾方法表示該方法不能被重寫、修飾變量表 示該變量是一個常量不能被重新賦值。
* finally一般作用在try-catch代碼塊中,在處理異常的時候,通常我們將一定要執行的代碼方法finally代碼塊 中,表示不管是否出現異常,該代碼塊都會執行,一般用來存放一些關閉資源的代碼。
* finalize是一個方法,屬于Object類的一個方法,而Object類是所有類的父類,該方法一般由垃圾回收器來調 用,當我們調用System.gc() 方法的時候,由垃圾回收器調用finalize(),回收垃圾,一個對象是否可回收的 最后判斷。
#### this關鍵字的用法
* this是自身的一個對象,代表對象本身,可以理解為:指向對象本身的一個指針。
* this的用法在java中大體可以分為3種:
* 1.普通的直接引用,this相當于是指向當前對象本身。
* 2.形參與成員名字重名,用this來區分:
~~~
public Person(String name, int age) {
this.name = name;
this.age = age;
}
復制代碼
~~~
* 3.引用本類的構造函數
~~~
class Person{
private String name;
private int age;
public Person() {
}
public Person(String name) {
this.name = name;
}
public Person(String name, int age) {
this(name);
this.age = age;
}
}
復制代碼
~~~
#### super關鍵字的用法
* super可以理解為是指向自己超(父)類對象的一個指針,而這個超類指的是離自己最近的一個父類。
* super也有三種用法:
* 1.普通的直接引用
與this類似,super相當于是指向當前對象的父類的引用,這樣就可以用super.xxx來引用父類的成員。
* 2.子類中的成員變量或方法與父類中的成員變量或方法同名時,用super進行區分
~~~
class Person{
protected String name;
public Person(String name) {
this.name = name;
}
}
class Student extends Person{
private String name;
public Student(String name, String name1) {
super(name);
this.name = name1;
}
public void getInfo(){
System.out.println(this.name); //Child
System.out.println(super.name); //Father
}
}
public class Test {
public static void main(String[] args) {
Student s1 = new Student("Father","Child");
s1.getInfo();
}
}
復制代碼
~~~
* 3.引用父類構造函數
* super(參數):調用父類中的某一個構造函數(應該為構造函數中的第一條語句)。
* this(參數):調用本類中另一種形式的構造函數(應該為構造函數中的第一條語句)。
#### this與super的區別
* super:?它引用當前對象的直接父類中的成員(用來訪問直接父類中被隱藏的父類中成員數據或函數,基類與派生類中有相同成員定義時如:super.變量名 super.成員函數據名(實參)
* this:它代表當前對象名(在程序中易產生二義性之處,應使用this來指明當前對象;如果函數的形參與類中的成員數據同名,這時需用this來指明成員變量名)
* super()和this()類似,區別是,super()在子類中調用父類的構造方法,this()在本類內調用本類的其它構造方法。
* super()和this()均需放在構造方法內第一行。
* 盡管可以用this調用一個構造器,但卻不能調用兩個。
* this和super不能同時出現在一個構造函數里面,因為this必然會調用其它的構造函數,其它的構造函數必然也會有super語句的存在,所以在同一個構造函數里面有相同的語句,就失去了語句的意義,編譯器也不會通過。
* this()和super()都指的是對象,所以,均不可以在static環境中使用。包括:static變量,static方法,static語句塊。
* 從本質上講,this是一個指向本對象的指針, 然而super是一個Java關鍵字。
#### static存在的主要意義
* static的主要意義是在于創建獨立于具體對象的域變量或者方法。**以致于即使沒有創建對象,也能使用屬性和調用方法**!
* static關鍵字還有一個比較關鍵的作用就是 **用來形成靜態代碼塊以優化程序性能**。static塊可以置于類中的任何地方,類中可以有多個static塊。在類初次被加載的時候,會按照static塊的順序來執行每個static塊,并且只會執行一次。
* 為什么說static塊可以用來優化程序性能,是因為它的特性:只會在類加載的時候執行一次。因此,很多時候會將一些只需要進行一次的初始化操作都放在static代碼塊中進行。
#### static的獨特之處
* 1、被static修飾的變量或者方法是獨立于該類的任何對象,也就是說,這些變量和方法**不屬于任何一個實例對象,而是被類的實例對象所共享**。
> 怎么理解 “被類的實例對象所共享” 這句話呢?就是說,一個類的靜態成員,它是屬于大伙的【大伙指的是這個類的多個對象實例,我們都知道一個類可以創建多個實例!】,所有的類對象共享的,不像成員變量是自個的【自個指的是這個類的單個實例對象】…我覺得我已經講的很通俗了,你明白了咩?
* 2、在該類被第一次加載的時候,就會去加載被static修飾的部分,而且只在類第一次使用時加載并進行初始化,注意這是第一次用就要初始化,后面根據需要是可以再次賦值的。
* 3、static變量值在類加載的時候分配空間,以后創建類對象的時候不會重新分配。賦值的話,是可以任意賦值的!
* 4、被static修飾的變量或者方法是優先于對象存在的,也就是說當一個類加載完畢之后,即便沒有創建對象,也可以去訪問。
#### static應用場景
* 因為static是被類的實例對象所共享,因此如果**某個成員變量是被所有對象所共享的,那么這個成員變量就應該定義為靜態變量**。
* 因此比較常見的static應用場景有:
> 1、修飾成員變量 2、修飾成員方法 3、靜態代碼塊 4、修飾類【只能修飾內部類也就是靜態內部類】 5、靜態導包
#### static注意事項
* 1、靜態只能訪問靜態。
* 2、非靜態既可以訪問非靜態的,也可以訪問靜態的。
### 流程控制語句
#### break ,continue ,return 的區別及作用
* break 跳出總上一層循環,不再執行循環(結束當前的循環體)
* continue 跳出本次循環,繼續執行下次循環(結束正在執行的循環 進入下一個循環條件)
* return 程序返回,不再執行下面的代碼(結束當前的方法 直接返回)
#### 在 Java 中,如何跳出當前的多重嵌套循環
* 在Java中,要想跳出多重循環,可以在外面的循環語句前定義一個標號,然后在里層循環體的代碼中使用帶有標號的break 語句,即可跳出外層循環。例如:
~~~
public static void main(String[] args) {
ok:
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
System.out.println("i=" + i + ",j=" + j);
if (j == 5) {
break ok;
}
}
}
}
復制代碼
~~~
## 面向對象
### 面向對象概述
#### 面向對象和面向過程的區別
* **面向過程**:
* 優點:性能比面向對象高,因為類調用時需要實例化,開銷比較大,比較消耗資源;比如單片機、嵌入式開發、Linux/Unix等一般采用面向過程開發,性能是最重要的因素。
* 缺點:沒有面向對象易維護、易復用、易擴展
* **面向對象**:
* 優點:易維護、易復用、易擴展,由于面向對象有封裝、繼承、多態性的特性,可以設計出低耦合的系統,使系統更加靈活、更加易于維護
* 缺點:性能比面向過程低
`面向過程是具體化的,流程化的,解決一個問題,你需要一步一步的分析,一步一步的實現。`
`面向對象是模型化的,你只需抽象出一個類,這是一個封閉的盒子,在這里你擁有數據也擁有解決問題的方法。需要什么功能直接使用就可以了,不必去一步一步的實現,至于這個功能是如何實現的,管我們什么事?我們會用就可以了。`
`面向對象的底層其實還是面向過程,把面向過程抽象成類,然后封裝,方便我們使用的就是面向對象了。`
### 面向對象三大特性
#### 面向對象的特征有哪些方面
**面向對象的特征主要有以下幾個方面**:
* **抽象**:抽象是將一類對象的共同特征總結出來構造類的過程,包括數據抽象和行為抽象兩方面。抽象只關注對象有哪些屬性和行為,并不關注這些行為的細節是什么。
* **封裝**把一個對象的屬性私有化,同時提供一些可以被外界訪問的屬性的方法,如果屬性不想被外界訪問,我們大可不必提供方法給外界訪問。但是如果一個類沒有提供給外界訪問的方法,那么這個類也沒有什么意義了。
* **繼承**是使用已存在的類的定義作為基礎建立新類的技術,新類的定義可以增加新的數據或新的功能,也可以用父類的功能,但不能選擇性地繼承父類。通過使用繼承我們能夠非常方便地復用以前的代碼。
* 關于繼承如下 3 點請記住:
* 子類擁有父類非 private 的屬性和方法。
* 子類可以擁有自己屬性和方法,即子類可以對父類進行擴展。
* 子類可以用自己的方式實現父類的方法。(以后介紹)。
* **多態**:父類或接口定義的引用變量可以指向子類或具體實現類的實例對象。提高了程序的拓展性。在Java中有兩種形式可以實現多態:繼承(多個子類對同一方法的重寫)和接口(實現接口并覆蓋接口中同一方法)。
#### 什么是多態機制?Java語言是如何實現多態的?
* 所謂多態就是指程序中定義的引用變量所指向的具體類型和通過該引用變量發出的方法調用在編程時并不確定,而是在程序運行期間才確定,即一個引用變量倒底會指向哪個類的實例對象,該引用變量發出的方法調用到底是哪個類中實現的方法,必須在由程序運行期間才能決定。因為在程序運行時才確定具體的類,這樣,不用修改源程序代碼,就可以讓引用變量綁定到各種不同的類實現上,從而導致該引用調用的具體方法隨之改變,即不修改程序代碼就可以改變程序運行時所綁定的具體代碼,讓程序可以選擇多個運行狀態,這就是多態性。
* 多態分為編譯時多態和運行時多態。其中編輯時多態是靜態的,主要是指方法的重載,它是根據參數列表的不同來區分不同的函數,通過編輯之后會變成兩個不同的函數,在運行時談不上多態。而運行時多態是動態的,它是通過動態綁定來實現的,也就是我們所說的多態性。
**多態的實現**
* Java實現多態有三個必要條件:繼承、重寫、向上轉型。
* 繼承:在多態中必須存在有繼承關系的子類和父類。
* 重寫:子類對父類中某些方法進行重新定義,在調用這些方法時就會調用子類的方法。
* 向上轉型:在多態中需要將子類的引用賦給父類對象,只有這樣該引用才能夠具備技能調用父類的方法和子類的方法。
`只有滿足了上述三個條件,我們才能夠在同一個繼承結構中使用統一的邏輯實現代碼處理不同的對象,從而達到執行不同的行為。`
`對于Java而言,它多態的實現機制遵循一個原則:當超類對象引用變量引用子類對象時,被引用對象的類型而不是引用變量的類型決定了調用誰的成員方法,但是這個被調用的方法必須是在超類中定義過的,也就是說被子類覆蓋的方法。`
#### 面向對象五大基本原則是什么(可選)
* 單一職責原則SRP(Single Responsibility Principle)
類的功能要單一,不能包羅萬象,跟雜貨鋪似的。
* 開放封閉原則OCP(Open-Close Principle)
一個模塊對于拓展是開放的,對于修改是封閉的,想要增加功能熱烈歡迎,想要修改,哼,一萬個不樂意。
* 里式替換原則LSP(the Liskov Substitution Principle LSP)
子類可以替換父類出現在父類能夠出現的任何地方。比如你能代表你爸去你姥姥家干活。哈哈~~
* 依賴倒置原則DIP(the Dependency Inversion Principle DIP)
高層次的模塊不應該依賴于低層次的模塊,他們都應該依賴于抽象。抽象不應該依賴于具體實現,具體實現應該依賴于抽象。就是你出國要說你是中國人,而不能說你是哪個村子的。比如說中國人是抽象的,下面有具體的xx省,xx市,xx縣。你要依賴的抽象是中國人,而不是你是xx村的。
* 接口分離原則ISP(the Interface Segregation Principle ISP)
設計時采用多個與特定客戶類有關的接口比采用一個通用的接口要好。就比如一個手機擁有打電話,看視頻,玩游戲等功能,把這幾個功能拆分成不同的接口,比在一個接口里要好的多。
### 類與接口
#### 抽象類和接口的對比
* 抽象類是用來捕捉子類的通用特性的。接口是抽象方法的集合。
* 從設計層面來說,抽象類是對類的抽象,是一種模板設計,接口是行為的抽象,是一種行為的規范。
**相同點**
* 接口和抽象類都不能實例化
* 都位于繼承的頂端,用于被其他實現或繼承
* 都包含抽象方法,其子類都必須覆寫這些抽象方法
**不同點**
| 參數 | 抽象類 | 接口 |
| --- | --- | --- |
| 聲明 | 抽象類使用abstract關鍵字聲明 | 接口使用interface關鍵字聲明 |
| 實現 | 子類使用extends關鍵字來繼承抽象類。如果子類不是抽象類的話,它需要提供抽象類中所有聲明的方法的實現 | 子類使用implements關鍵字來實現接口。它需要提供接口中所有聲明的方法的實現 |
| 構造器 | 抽象類可以有構造器 | 接口不能有構造器 |
| 訪問修飾符 | 抽象類中的方法可以是任意訪問修飾符 | 接口方法默認修飾符是public。并且不允許定義為 private 或者 protected |
| 多繼承 | 一個類最多只能繼承一個抽象類 | 一個類可以實現多個接口 |
| 字段聲明 | 抽象類的字段聲明可以是任意的 | 接口的字段默認都是 static 和 final 的 |
**備注**:Java8中接口中引入默認方法和靜態方法,以此來減少抽象類和接口之間的差異。
`現在,我們可以為接口提供默認實現的方法了,并且不用強制子類來實現它。`
* 接口和抽象類各有優缺點,在接口和抽象類的選擇上,必須遵守這樣一個原則:
* 行為模型應該總是通過接口而不是抽象類定義,所以通常是優先選用接口,盡量少用抽象類。
* 選擇抽象類的時候通常是如下情況:需要定義子類的行為,又要為子類提供通用的功能。
#### 普通類和抽象類有哪些區別?
* 普通類不能包含抽象方法,抽象類可以包含抽象方法。
* 抽象類不能直接實例化,普通類可以直接實例化。
#### 抽象類能使用 final 修飾嗎?
* 不能,定義抽象類就是讓其他類繼承的,如果定義為 final 該類就不能被繼承,這樣彼此就會產生矛盾,所以 final 不能修飾抽象類
#### 創建一個對象用什么關鍵字?對象實例與對象引用有何不同?
* new關鍵字,new創建對象實例(對象實例在堆內存中),對象引用指向對象實例(對象引用存放在棧內存中)。一個對象引用可以指向0個或1個對象(一根繩子可以不系氣球,也可以系一個氣球);一個對象可以有n個引用指向它(可以用n條繩子系住一個氣球)
### 變量與方法
#### 成員變量與局部變量的區別有哪些
* 變量:在程序執行的過程中,在某個范圍內其值可以發生改變的量。從本質上講,變量其實是內存中的一小塊區域
* 成員變量:方法外部,類內部定義的變量
* 局部變量:類的方法中的變量。
* 成員變量和局部變量的區別
**作用域**
* 成員變量:針對整個類有效。
* 局部變量:只在某個范圍內有效。(一般指的就是方法,語句體內)
**存儲位置**
* 成員變量:隨著對象的創建而存在,隨著對象的消失而消失,存儲在堆內存中。
* 局部變量:在方法被調用,或者語句被執行的時候存在,存儲在棧內存中。當方法調用完,或者語句結束后,就自動釋放。
**生命周期**
* 成員變量:隨著對象的創建而存在,隨著對象的消失而消失
* 局部變量:當方法調用完,或者語句結束后,就自動釋放。
**初始值**
* 成員變量:有默認初始值。
* 局部變量:沒有默認初始值,使用前必須賦值。
#### 在Java中定義一個不做事且沒有參數的構造方法的作用
* Java程序在執行子類的構造方法之前,如果沒有用super()來調用父類特定的構造方法,則會調用父類中“沒有參數的構造方法”。因此,如果父類中只定義了有參數的構造方法,而在子類的構造方法中又沒有用super()來調用父類中特定的構造方法,則編譯時將發生錯誤,因為Java程序在父類中找不到沒有參數的構造方法可供執行。解決辦法是在父類里加上一個不做事且沒有參數的構造方法。
#### 在調用子類構造方法之前會先調用父類沒有參數的構造方法,其目的是?
* 幫助子類做初始化工作。
#### 一個類的構造方法的作用是什么?若一個類沒有聲明構造方法,改程序能正確執行嗎?為什么?
* 主要作用是完成對類對象的初始化工作。可以執行。因為一個類即使沒有聲明構造方法也會有默認的不帶參數的構造方法。
#### 構造方法有哪些特性?
* 名字與類名相同;
* 沒有返回值,但不能用void聲明構造函數;
* 生成類的對象時自動執行,無需調用。
#### 靜態變量和實例變量區別
* 靜態變量: 靜態變量由于不屬于任何實例對象,屬于類的,所以在內存中只會有一份,在類的加載過程中,JVM只為靜態變量分配一次內存空間。
* 實例變量: 每次創建對象,都會為每個對象分配成員變量內存空間,實例變量是屬于實例對象的,在內存中,創建幾次對象,就有幾份成員變量。
#### 靜態變量與普通變量區別
* static變量也稱作靜態變量,靜態變量和非靜態變量的區別是:靜態變量被所有的對象所共享,在內存中只有一個副本,它當且僅當在類初次加載時會被初始化。而非靜態變量是對象所擁有的,在創建對象的時候被初始化,存在多個副本,各個對象擁有的副本互不影響。
* 還有一點就是static成員變量的初始化順序按照定義的順序進行初始化。
#### 靜態方法和實例方法有何不同?
`靜態方法和實例方法的區別主要體現在兩個方面:`
* 在外部調用靜態方法時,可以使用"類名.方法名"的方式,也可以使用"對象名.方法名"的方式。而實例方法只有后面這種方式。也就是說,調用靜態方法可以無需創建對象。
* 靜態方法在訪問本類的成員時,只允許訪問靜態成員(即靜態成員變量和靜態方法),而不允許訪問實例成員變量和實例方法;實例方法則無此限制
#### 在一個靜態方法內調用一個非靜態成員為什么是非法的?
* 由于靜態方法可以不通過對象進行調用,因此在靜態方法里,不能調用其他非靜態變量,也不可以訪問非靜態變量成員。
#### 什么是方法的返回值?返回值的作用是什么?
* 方法的返回值是指我們獲取到的某個方法體中的代碼執行后產生的結果!(前提是該方法可能產生結果)。返回值的作用:接收出結果,使得它可以用于其他的操作!
### 內部類
#### 什么是內部類?
* 在Java中,可以將一個類的定義放在另外一個類的定義內部,這就是**內部類**。內部類本身就是類的一個屬性,與其他屬性定義方式一致。
#### 內部類的分類有哪些
`內部類可以分為四種:**成員內部類、局部內部類、匿名內部類和靜態內部類**。`
##### 靜態內部類
* 定義在類內部的靜態類,就是靜態內部類。
~~~
public class Outer {
private static int radius = 1;
static class StaticInner {
public void visit() {
System.out.println("visit outer static variable:" + radius);
}
}
}
復制代碼
~~~
* 靜態內部類可以訪問外部類所有的靜態變量,而不可訪問外部類的非靜態變量;靜態內部類的創建方式,`new 外部類.靜態內部類()`,如下:
~~~
Outer.StaticInner inner = new Outer.StaticInner();
inner.visit();
復制代碼
~~~
##### 成員內部類
* 定義在類內部,成員位置上的非靜態類,就是成員內部類。
~~~
public class Outer {
private static int radius = 1;
private int count =2;
class Inner {
public void visit() {
System.out.println("visit outer static variable:" + radius);
System.out.println("visit outer variable:" + count);
}
}
}
復制代碼
~~~
* 成員內部類可以訪問外部類所有的變量和方法,包括靜態和非靜態,私有和公有。成員內部類依賴于外部類的實例,它的創建方式`外部類實例.new 內部類()`,如下:
~~~
Outer outer = new Outer();
Outer.Inner inner = outer.new Inner();
inner.visit();
復制代碼
~~~
##### 局部內部類
* 定義在方法中的內部類,就是局部內部類。
~~~
public class Outer {
private int out_a = 1;
private static int STATIC_b = 2;
public void testFunctionClass(){
int inner_c =3;
class Inner {
private void fun(){
System.out.println(out_a);
System.out.println(STATIC_b);
System.out.println(inner_c);
}
}
Inner inner = new Inner();
inner.fun();
}
public static void testStaticFunctionClass(){
int d =3;
class Inner {
private void fun(){
// System.out.println(out_a); 編譯錯誤,定義在靜態方法中的局部類不可以訪問外部類的實例變量
System.out.println(STATIC_b);
System.out.println(d);
}
}
Inner inner = new Inner();
inner.fun();
}
}
復制代碼
~~~
* 定義在實例方法中的局部類可以訪問外部類的所有變量和方法,定義在靜態方法中的局部類只能訪問外部類的靜態變量和方法。局部內部類的創建方式,在對應方法內,`new 內部類()`,如下:
~~~
public static void testStaticFunctionClass(){
class Inner {
}
Inner inner = new Inner();
}
復制代碼
~~~
##### 匿名內部類
* 匿名內部類就是沒有名字的內部類,日常開發中使用的比較多。
~~~
public class Outer {
private void test(final int i) {
new Service() {
public void method() {
for (int j = 0; j < i; j++) {
System.out.println("匿名內部類" );
}
}
}.method();
}
}
//匿名內部類必須繼承或實現一個已有的接口
interface Service{
void method();
}
復制代碼
~~~
* 除了沒有名字,匿名內部類還有以下特點:
* 匿名內部類必須繼承一個抽象類或者實現一個接口。
* 匿名內部類不能定義任何靜態成員和靜態方法。
* 當所在的方法的形參需要被匿名內部類使用時,必須聲明為 final。
* 匿名內部類不能是抽象的,它必須要實現繼承的類或者實現的接口的所有抽象方法。
* 匿名內部類創建方式:
~~~
new 類/接口{
//匿名內部類實現部分
}
復制代碼
~~~
#### 內部類的優點
`我們為什么要使用內部類呢?因為它有以下優點:`
* 一個內部類對象可以訪問創建它的外部類對象的內容,包括私有數據!
* 內部類不為同一包的其他類所見,具有很好的封裝性;
* 內部類有效實現了“多重繼承”,優化 java 單繼承的缺陷。
* 匿名內部類可以很方便的定義回調。
#### 內部類有哪些應用場景
1. 一些多算法場合
2. 解決一些非面向對象的語句塊。
3. 適當使用內部類,使得代碼更加靈活和富有擴展性。
4. 當某個類除了它的外部類,不再被其他的類使用時。
#### 局部內部類和匿名內部類訪問局部變量的時候,為什么變量必須要加上final?
* 局部內部類和匿名內部類訪問局部變量的時候,為什么變量必須要加上final呢?它內部原理是什么呢?先看這段代碼:
~~~
public class Outer {
void outMethod(){
final int a =10;
class Inner {
void innerMethod(){
System.out.println(a);
}
}
}
}
復制代碼
~~~
* 以上例子,為什么要加final呢?是因為**生命周期不一致**, 局部變量直接存儲在棧中,當方法執行結束后,非final的局部變量就被銷毀。而局部內部類對局部變量的引用依然存在,如果局部內部類要調用局部變量時,就會出錯。加了final,可以確保局部內部類使用的變量與外層的局部變量區分開,解決了這個問題。
#### 內部類相關,看程序說出運行結果
~~~
public class Outer {
private int age = 12;
class Inner {
private int age = 13;
public void print() {
int age = 14;
System.out.println("局部變量:" + age);
System.out.println("內部類變量:" + this.age);
System.out.println("外部類變量:" + Outer.this.age);
}
}
public static void main(String[] args) {
Outer.Inner in = new Outer().new Inner();
in.print();
}
}
復制代碼
~~~
運行結果:
~~~
局部變量:14
內部類變量:13
外部類變量:12
復制代碼
~~~
### 重寫與重載
#### 構造器(constructor)是否可被重寫(override)
* 構造器不能被繼承,因此不能被重寫,但可以被重載。
#### 重載(Overload)和重寫(Override)的區別。重載的方法能否根據返回類型進行區分?
* 方法的重載和重寫都是實現多態的方式,區別在于前者實現的是編譯時的多態性,而后者實現的是運行時的多態性。
* 重載:發生在同一個類中,方法名相同參數列表不同(參數類型不同、個數不同、順序不同),與方法返回值和訪問修飾符無關,即重載的方法不能根據返回類型進行區分
* 重寫:發生在父子類中,方法名、參數列表必須相同,返回值小于等于父類,拋出的異常小于等于父類,訪問修飾符大于等于父類(里氏代換原則);如果父類方法訪問修飾符為private則子類中就不是重寫。
### 對象相等判斷
#### \== 和 equals 的區別是什么
* **\==** : 它的作用是判斷兩個對象的地址是不是相等。即,判斷兩個對象是不是同一個對象。(基本數據類型 == 比較的是值,引用數據類型 == 比較的是內存地址)
* **equals()** : 它的作用也是判斷兩個對象是否相等。但它一般有兩種使用情況:
* 情況1:類沒有覆蓋 equals() 方法。則通過 equals() 比較該類的兩個對象時,等價于通過“==”比較這兩個對象。
* 情況2:類覆蓋了 equals() 方法。一般,我們都覆蓋 equals() 方法來兩個對象的內容相等;若它們的內容相等,則返回 true (即,認為這兩個對象相等)。
* **舉個例子:**
~~~
public class test1 {
public static void main(String[] args) {
String a = new String("ab"); // a 為一個引用
String b = new String("ab"); // b為另一個引用,對象的內容一樣
String aa = "ab"; // 放在常量池中
String bb = "ab"; // 從常量池中查找
if (aa == bb) // true
System.out.println("aa==bb");
if (a == b) // false,非同一對象
System.out.println("a==b");
if (a.equals(b)) // true
System.out.println("aEQb");
if (42 == 42.0) { // true
System.out.println("true");
}
}
}
復制代碼
~~~
* **說明:**
* String中的equals方法是被重寫過的,因為object的equals方法是比較的對象的內存地址,而String的equals方法比較的是對象的值。
* 當創建String類型的對象時,虛擬機會在常量池中查找有沒有已經存在的值和要創建的值相同的對象,如果有就把它賦給當前引用。如果沒有就在常量池中重新創建一個String對象。
#### hashCode 與 equals (重要)
* HashSet如何檢查重復
* 兩個對象的 hashCode() 相同,則 equals() 也一定為 true,對嗎?
* hashCode和equals方法的關系
* 面試官可能會問你:“你重寫過 hashcode 和 equals 么,為什么重寫equals時必須重寫hashCode方法?”
**hashCode()介紹**
* hashCode() 的作用是獲取哈希碼,也稱為散列碼;它實際上是返回一個int整數。這個哈希碼的作用是確定該對象在哈希表中的索引位置。hashCode() 定義在JDK的Object.java中,這就意味著Java中的任何類都包含有hashCode()函數。
* 散列表存儲的是鍵值對(key-value),它的特點是:能根據“鍵”快速的檢索出對應的“值”。這其中就利用到了散列碼!(可以快速找到所需要的對象)
**為什么要有 hashCode**
`我們以“HashSet 如何檢查重復”為例子來說明為什么要有 hashCode:`
* 當你把對象加入 HashSet 時,HashSet 會先計算對象的 hashcode 值來判斷對象加入的位置,同時也會與其他已經加入的對象的 hashcode 值作比較,如果沒有相符的hashcode,HashSet會假設對象沒有重復出現。但是如果發現有相同 hashcode 值的對象,這時會調用 equals()方法來檢查 hashcode 相等的對象是否真的相同。如果兩者相同,HashSet 就不會讓其加入操作成功。如果不同的話,就會重新散列到其他位置。(摘自我的Java啟蒙書《Head first java》第二版)。這樣我們就大大減少了 equals 的次數,相應就大大提高了執行速度。
**hashCode()與equals()的相關規定**
* 如果兩個對象相等,則hashcode一定也是相同的
* 兩個對象相等,對兩個對象分別調用equals方法都返回true
* 兩個對象有相同的hashcode值,它們也不一定是相等的
`因此,equals 方法被覆蓋過,則 hashCode 方法也必須被覆蓋`
`hashCode() 的默認行為是對堆上的對象產生獨特值。如果沒有重寫 hashCode(),則該 class 的兩個對象無論如何都不會相等(即使這兩個對象指向相同的數據)`
#### 對象的相等與指向他們的引用相等,兩者有什么不同?
* 對象的相等 比的是內存中存放的內容是否相等而 引用相等 比較的是他們指向的內存地址是否相等。
### 值傳遞
#### 當一個對象被當作參數傳遞到一個方法后,此方法可改變這個對象的屬性,并可返回變化后的結果,那么這里到底是值傳遞還是引用傳遞
* 是值傳遞。Java 語言的方法調用只支持參數的值傳遞。當一個對象實例作為一個參數被傳遞到方法中時,參數的值就是對該對象的引用。對象的屬性可以在被調用過程中被改變,但對對象引用的改變是不會影響到調用者的
#### 為什么 Java 中只有值傳遞
* 首先回顧一下在程序設計語言中有關將參數傳遞給方法(或函數)的一些專業術語。**按值調用(call by value)表示方法接收的是調用者提供的值,而按引用調用(call by reference)表示方法接收的是調用者提供的變量地址。一個方法可以修改傳遞引用所對應的變量值,而不能修改傳遞值調用所對應的變量值。** 它用來描述各種程序設計語言(不只是Java)中方法參數傳遞方式。
* **Java程序設計語言總是采用按值調用。也就是說,方法得到的是所有參數值的一個拷貝,也就是說,方法不能修改傳遞給它的任何參數變量的內容。**
* **下面通過 3 個例子來給大家說明**
##### example 1
~~~
public static void main(String[] args) {
int num1 = 10;
int num2 = 20;
swap(num1, num2);
System.out.println("num1 = " + num1);
System.out.println("num2 = " + num2);
}
public static void swap(int a, int b) {
int temp = a;
a = b;
b = temp;
System.out.println("a = " + a);
System.out.println("b = " + b);
}
復制代碼
~~~
* 結果:
a = 20 b = 10 num1 = 10 num2 = 20
* 解析:

* 在swap方法中,a、b的值進行交換,并不會影響到 num1、num2。因為,a、b中的值,只是從 num1、num2 的復制過來的。也就是說,a、b相當于num1、num2 的副本,副本的內容無論怎么修改,都不會影響到原件本身。
`通過上面例子,我們已經知道了一個方法不能修改一個基本數據類型的參數,而對象引用作為參數就不一樣,請看 example.`
##### example 2
~~~
public static void main(String[] args) {
int[] arr = { 1, 2, 3, 4, 5 };
System.out.println(arr[0]);
change(arr);
System.out.println(arr[0]);
}
public static void change(int[] array) {
// 將數組的第一個元素變為0
array[0] = 0;
}
復制代碼
~~~
* 結果:
1 0
* 解析:
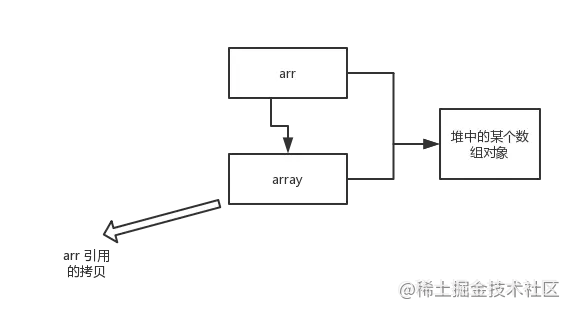
* array 被初始化 arr 的拷貝也就是一個對象的引用,也就是說 array 和 arr 指向的時同一個數組對象。 因此,外部對引用對象的改變會反映到所對應的對象上。
`通過 example2 我們已經看到,實現一個改變對象參數狀態的方法并不是一件難事。理由很簡單,方法得到的是對象引用的拷貝,對象引用及其他的拷貝同時引用同一個對象。`
`很多程序設計語言(特別是,C++和Pascal)提供了兩種參數傳遞的方式:值調用和引用調用。有些程序員(甚至本書的作者)認為Java程序設計語言對對象采用的是引用調用,實際上,這種理解是不對的。由于這種誤解具有一定的普遍性,所以下面給出一個反例來詳細地闡述一下這個問題。`
##### example 3
~~~
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
Student s1 = new Student("小張");
Student s2 = new Student("小李");
Test.swap(s1, s2);
System.out.println("s1:" + s1.getName());
System.out.println("s2:" + s2.getName());
}
public static void swap(Student x, Student y) {
Student temp = x;
x = y;
y = temp;
System.out.println("x:" + x.getName());
System.out.println("y:" + y.getName());
}
}
復制代碼
~~~
* 結果:
x:小李 y:小張 s1:小張 s2:小李
* 解析:
* 交換之前:
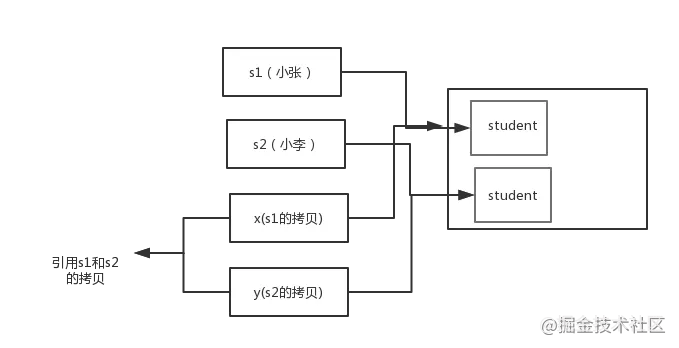
* 交換之后:
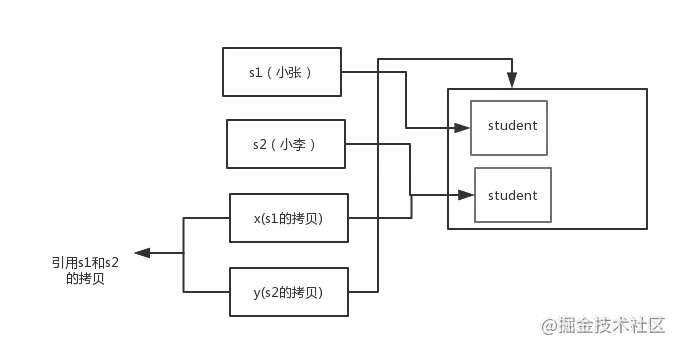
* 通過上面兩張圖可以很清晰的看出:`方法并沒有改變存儲在變量 s1 和 s2 中的對象引用。swap方法的參數x和y被初始化為兩個對象引用的拷貝,這個方法交換的是這兩個拷貝`
* 總結
* `Java程序設計語言對對象采用的不是引用調用,實際上,對象引用是按值傳遞的。`
* 下面再總結一下Java中方法參數的使用情況:
* 一個方法不能修改一個基本數據類型的參數(即數值型或布爾型》
* 一個方法可以改變一個對象參數的狀態。
* 一個方法不能讓對象參數引用一個新的對象。
#### 值傳遞和引用傳遞有什么區別
* 值傳遞:指的是在方法調用時,傳遞的參數是按值的拷貝傳遞,傳遞的是值的拷貝,也就是說傳遞后就互不相關了。
* 引用傳遞:指的是在方法調用時,傳遞的參數是按引用進行傳遞,其實傳遞的引用的地址,也就是變量所對應的內存空間的地址。傳遞的是值的引用,也就是說傳遞前和傳遞后都指向同一個引用(也就是同一個內存空間)。
### Java包
#### JDK 中常用的包有哪些
* java.lang:這個是系統的基礎類;
* java.io:這里面是所有輸入輸出有關的類,比如文件操作等;
* java.nio:為了完善 io 包中的功能,提高 io 包中性能而寫的一個新包;
* java.net:這里面是與網絡有關的類;
* java.util:這個是系統輔助類,特別是集合類;
* java.sql:這個是數據庫操作的類。
#### import java和javax有什么區別
* 剛開始的時候 JavaAPI 所必需的包是 java 開頭的包,javax 當時只是擴展 API 包來說使用。然而隨著時間的推移,javax 逐漸的擴展成為 Java API 的組成部分。但是,將擴展從 javax 包移動到 java 包將是太麻煩了,最終會破壞一堆現有的代碼。因此,最終決定 javax 包將成為標準API的一部分。
`所以,實際上java和javax沒有區別。這都是一個名字。`
## IO流
### java 中 IO 流分為幾種?
* 按照流的流向分,可以分為輸入流和輸出流;
* 按照操作單元劃分,可以劃分為字節流和字符流;
* 按照流的角色劃分為節點流和處理流。
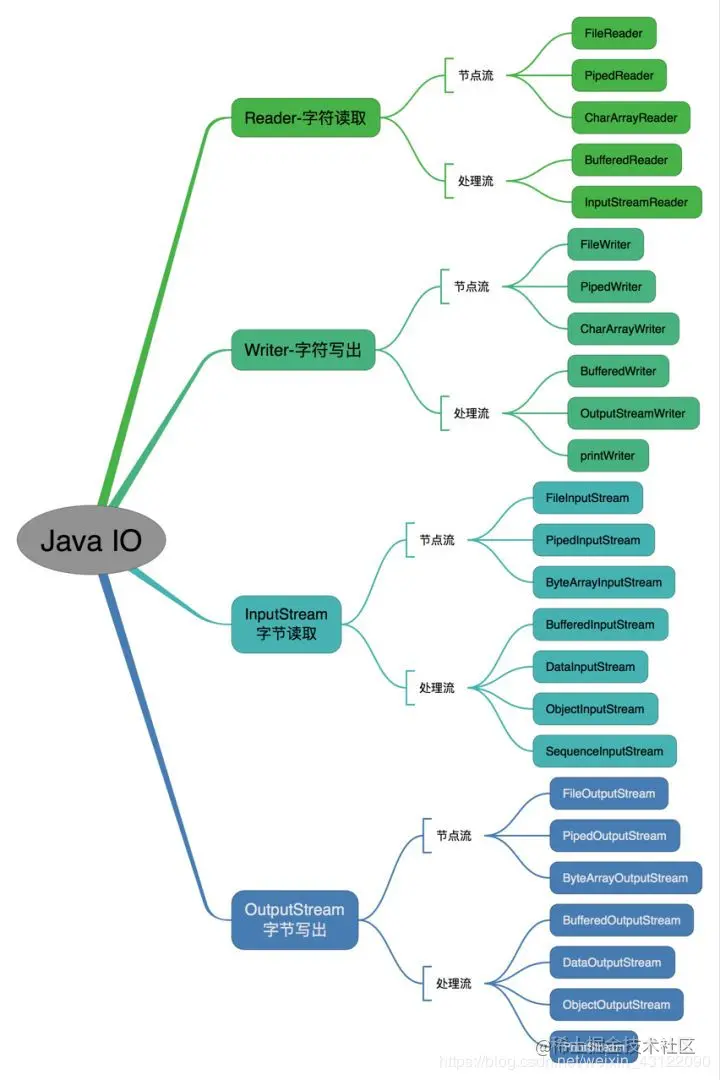
`Java Io流共涉及40多個類,這些類看上去很雜亂,但實際上很有規則,而且彼此之間存在非常緊密的聯系, Java I0流的40多個類都是從如下4個抽象類基類中派生出來的。`
* InputStream/Reader: 所有的輸入流的基類,前者是字節輸入流,后者是字符輸入流。
* OutputStream/Writer: 所有輸出流的基類,前者是字節輸出流,后者是字符輸出流。
`按操作方式分類結構圖:`
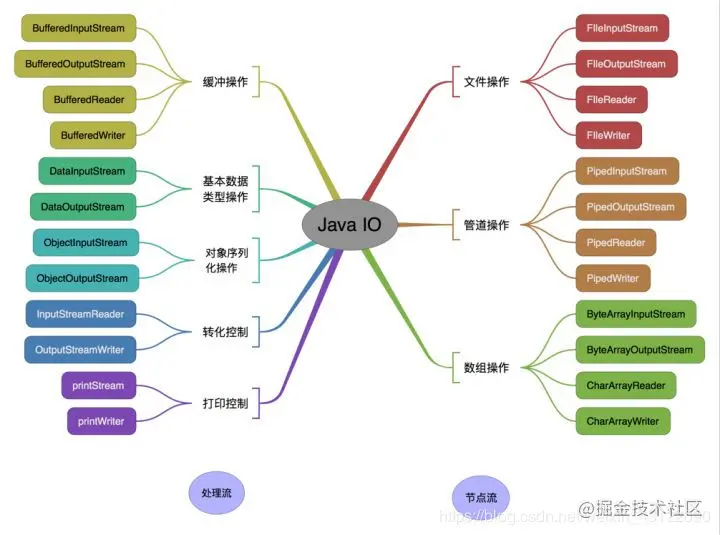
`按操作對象分類結構圖:`
### BIO,NIO,AIO 有什么區別?
* 簡答
* BIO:Block IO 同步阻塞式 IO,就是我們平常使用的傳統 IO,它的特點是模式簡單使用方便,并發處理能力低。
* NIO:Non IO 同步非阻塞 IO,是傳統 IO 的升級,客戶端和服務器端通過 Channel(通道)通訊,實現了多路復用。
* AIO:Asynchronous IO 是 NIO 的升級,也叫 NIO2,實現了異步非堵塞 IO ,異步 IO 的操作基于事件和回調機制。
* 詳細回答
* **BIO (Blocking I/O):** 同步阻塞I/O模式,數據的讀取寫入必須阻塞在一個線程內等待其完成。在活動連接數不是特別高(小于單機1000)的情況下,這種模型是比較不錯的,可以讓每一個連接專注于自己的 I/O 并且編程模型簡單,也不用過多考慮系統的過載、限流等問題。線程池本身就是一個天然的漏斗,可以緩沖一些系統處理不了的連接或請求。但是,當面對十萬甚至百萬級連接的時候,傳統的 BIO 模型是無能為力的。因此,我們需要一種更高效的 I/O 處理模型來應對更高的并發量。
* **NIO (New I/O):** NIO是一種同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,對應 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解為Non-blocking,不單純是New。它支持面向緩沖的,基于通道的I/O操作方法。 NIO提供了與傳統BIO模型中的 `Socket` 和 `ServerSocket` 相對應的 `SocketChannel` 和 `ServerSocketChannel` 兩種不同的套接字通道實現,兩種通道都支持阻塞和非阻塞兩種模式。阻塞模式使用就像傳統中的支持一樣,比較簡單,但是性能和可靠性都不好;非阻塞模式正好與之相反。對于低負載、低并發的應用程序,可以使用同步阻塞I/O來提升開發速率和更好的維護性;對于高負載、高并發的(網絡)應用,應使用 NIO 的非阻塞模式來開發
* **AIO (Asynchronous I/O):** AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改進版 NIO 2,它是異步非阻塞的IO模型。異步 IO 是基于事件和回調機制實現的,也就是應用操作之后會直接返回,不會堵塞在那里,當后臺處理完成,操作系統會通知相應的線程進行后續的操作。AIO 是異步IO的縮寫,雖然 NIO 在網絡操作中,提供了非阻塞的方法,但是 NIO 的 IO 行為還是同步的。對于 NIO 來說,我們的業務線程是在 IO 操作準備好時,得到通知,接著就由這個線程自行進行 IO 操作,IO操作本身是同步的。查閱網上相關資料,我發現就目前來說 AIO 的應用還不是很廣泛,Netty 之前也嘗試使用過 AIO,不過又放棄了。
### Files的常用方法都有哪些?
* Files. exists():檢測文件路徑是否存在。
* Files. createFile():創建文件。
* Files. createDirectory():創建文件夾。
* Files. delete():刪除一個文件或目錄。
* Files. copy():復制文件。
* Files. move():移動文件。
* Files. size():查看文件個數。
* Files. read():讀取文件。
* Files. write():寫入文件。
## 反射
### 什么是反射機制?
* JAVA反射機制是在運行狀態中,對于任意一個類,都能夠知道這個類的所有屬性和方法;對于任意一個對象,都能夠調用它的任意一個方法和屬性;這種動態獲取的信息以及動態調用對象的方法的功能稱為java語言的反射機制。
* 靜態編譯和動態編譯
* 靜態編譯:在編譯時確定類型,綁定對象
* 動態編譯:運行時確定類型,綁定對象
### 反射機制優缺點
* **優點:** 運行期類型的判斷,動態加載類,提高代碼靈活度。
* **缺點:** 性能瓶頸:反射相當于一系列解釋操作,通知 JVM 要做的事情,性能比直接的java代碼要慢很多。
### 反射機制的應用場景有哪些?
* 反射是框架設計的靈魂。
* 在我們平時的項目開發過程中,基本上很少會直接使用到反射機制,但這不能說明反射機制沒有用,實際上有很多設計、開發都與反射機制有關,例如模塊化的開發,通過反射去調用對應的字節碼;動態代理設計模式也采用了反射機制,還有我們日常使用的 Spring/Hibernate 等框架也大量使用到了反射機制。
* 舉例:①我們在使用JDBC連接數據庫時使用Class.forName()通過反射加載數據庫的驅動程序;②Spring框架也用到很多反射機制,最經典的就是xml的配置模式。Spring 通過 XML 配置模式裝載 Bean 的過程:1) 將程序內所有 XML 或 Properties 配置文件加載入內存中; 2)Java類里面解析xml或properties里面的內容,得到對應實體類的字節碼字符串以及相關的屬性信息; 3)使用反射機制,根據這個字符串獲得某個類的Class實例; 4)動態配置實例的屬性
### Java獲取反射的三種方法
1.通過new對象實現反射機制 2.通過路徑實現反射機制 3.通過類名實現反射機制
~~~
public class Student {
private int id;
String name;
protected boolean sex;
public float score;
}
public class Get {
//獲取反射機制三種方式
public static void main(String[] args) throws ClassNotFoundException {
//方式一(通過建立對象)
Student stu = new Student();
Class classobj1 = stu.getClass();
System.out.println(classobj1.getName());
//方式二(所在通過路徑-相對路徑)
Class classobj2 = Class.forName("fanshe.Student");
System.out.println(classobj2.getName());
//方式三(通過類名)
Class classobj3 = Student.class;
System.out.println(classobj3.getName());
}
}
復制代碼
~~~
## 常用API
### String相關
#### 字符型常量和字符串常量的區別
1. 形式上: 字符常量是單引號引起的一個字符 字符串常量是雙引號引起的若干個字符
2. 含義上: 字符常量相當于一個整形值(ASCII值),可以參加表達式運算 字符串常量代表一個地址值(該字符串在內存中存放位置)
3. 占內存大小 字符常量只占一個字節 字符串常量占若干個字節(至少一個字符結束標志)
#### 什么是字符串常量池?
* 字符串常量池位于堆內存中,專門用來存儲字符串常量,可以提高內存的使用率,避免開辟多塊空間存儲相同的字符串,在創建字符串時 JVM 會首先檢查字符串常量池,如果該字符串已經存在池中,則返回它的引用,如果不存在,則實例化一個字符串放到池中,并返回其引用。
#### String 是最基本的數據類型嗎
* 不是。Java 中的基本數據類型只有 8 個 :byte、short、int、long、float、double、char、boolean;除了基本類型(primitive type),剩下的都是引用類型(referencetype),Java 5 以后引入的枚舉類型也算是一種比較特殊的引用類型。
`這是很基礎的東西,但是很多初學者卻容易忽視,Java 的 8 種基本數據類型中不包括 String,基本數據類型中用來描述文本數據的是 char,但是它只能表示單個字符,比如 ‘a’,‘好’ 之類的,如果要描述一段文本,就需要用多個 char 類型的變量,也就是一個 char 類型數組,比如“你好” 就是長度為2的數組 char\[\] chars = {‘你’,‘好’};`
`但是使用數組過于麻煩,所以就有了 String,String 底層就是一個 char 類型的數組,只是使用的時候開發者不需要直接操作底層數組,用更加簡便的方式即可完成對字符串的使用。`
#### String有哪些特性
* 不變性:String 是只讀字符串,是一個典型的 immutable 對象,對它進行任何操作,其實都是創建一個新的對象,再把引用指向該對象。不變模式的主要作用在于當一個對象需要被多線程共享并頻繁訪問時,可以保證數據的一致性。
* 常量池優化:String 對象創建之后,會在字符串常量池中進行緩存,如果下次創建同樣的對象時,會直接返回緩存的引用。
* final:使用 final 來定義 String 類,表示 String 類不能被繼承,提高了系統的安全性。
#### String為什么是不可變的嗎?
* 簡單來說就是String類利用了final修飾的char類型數組存儲字符,源碼如下圖所以:
/\*\* The value is used for character storage. \*/ private final char value\[\];
#### String真的是不可變的嗎?
* 我覺得如果別人問這個問題的話,回答不可變就可以了。 下面只是給大家看兩個有代表性的例子:
**1 String不可變但不代表引用不可以變**
~~~
String str = "Hello";
str = str + " World";
System.out.println("str=" + str);
復制代碼
~~~
* 結果:
str=Hello World
* 解析:
* 實際上,原來String的內容是不變的,只是str由原來指向"Hello"的內存地址轉為指向"Hello World"的內存地址而已,也就是說多開辟了一塊內存區域給"Hello World"字符串。
**2.通過反射是可以修改所謂的“不可變”對象**
~~~
// 創建字符串"Hello World", 并賦給引用s
String s = "Hello World";
System.out.println("s = " + s); // Hello World
// 獲取String類中的value字段
Field valueFieldOfString = String.class.getDeclaredField("value");
// 改變value屬性的訪問權限
valueFieldOfString.setAccessible(true);
// 獲取s對象上的value屬性的值
char[] value = (char[]) valueFieldOfString.get(s);
// 改變value所引用的數組中的第5個字符
value[5] = '_';
System.out.println("s = " + s); // Hello_World
復制代碼
~~~
* 結果:
s = Hello World s = Hello\_World
* 解析:
* 用反射可以訪問私有成員, 然后反射出String對象中的value屬性, 進而改變通過獲得的value引用改變數組的結構。但是一般我們不會這么做,這里只是簡單提一下有這個東西。
#### 是否可以繼承 String 類
* String 類是 final 類,不可以被繼承。
#### String str="i"與 String str=new String(“i”)一樣嗎?
* 不一樣,因為內存的分配方式不一樣。String str="i"的方式,java 虛擬機會將其分配到常量池中;而 String str=new String(“i”) 則會被分到堆內存中。
#### String s = new String(“xyz”);創建了幾個字符串對象
* 兩個對象,一個是靜態區的"xyz",一個是用new創建在堆上的對象。
String str1 = "hello"; //str1指向靜態區 String str2 = new String("hello"); //str2指向堆上的對象 String str3 = "hello"; String str4 = new String("hello"); System.out.println(str1.equals(str2)); //true System.out.println(str2.equals(str4)); //true System.out.println(str1 == str3); //true System.out.println(str1 == str2); //false System.out.println(str2 == str4); //false System.out.println(str2 == "hello"); //false str2 = str1; System.out.println(str2 == "hello"); //true
#### 如何將字符串反轉?
* 使用 StringBuilder 或者 stringBuffer 的 reverse() 方法。
* 示例代碼:
// StringBuffer reverse StringBuffer stringBuffer = new StringBuffer(); stringBuffer. append("abcdefg"); System. out. println(stringBuffer. reverse()); // gfedcba // StringBuilder reverse StringBuilder stringBuilder = new StringBuilder(); stringBuilder. append("abcdefg"); System. out. println(stringBuilder. reverse()); // gfedcba
#### 數組有沒有 length()方法?String 有沒有 length()方法
* 數組沒有 length()方法 ,有 length 的屬性。String 有 length()方法。JavaScript中,獲得字符串的長度是通過 length 屬性得到的,這一點容易和 Java 混淆。
#### String 類的常用方法都有那些?
* indexOf():返回指定字符的索引。
* charAt():返回指定索引處的字符。
* replace():字符串替換。
* trim():去除字符串兩端空白。
* split():分割字符串,返回一個分割后的字符串數組。
* getBytes():返回字符串的 byte 類型數組。
* length():返回字符串長度。
* toLowerCase():將字符串轉成小寫字母。
* toUpperCase():將字符串轉成大寫字符。
* substring():截取字符串。
* equals():字符串比較。
#### 在使用 HashMap 的時候,用 String 做 key 有什么好處?
* HashMap 內部實現是通過 key 的 hashcode 來確定 value 的存儲位置,因為字符串是不可變的,所以當創建字符串時,它的 hashcode 被緩存下來,不需要再次計算,所以相比于其他對象更快。
#### String和StringBuffer、StringBuilder的區別是什么?String為什么是不可變的
**可變性**
* String類中使用字符數組保存字符串,private?final?char?value\[\],所以string對象是不可變的。StringBuilder與StringBuffer都繼承自AbstractStringBuilder類,在AbstractStringBuilder中也是使用字符數組保存字符串,char\[\] value,這兩種對象都是可變的。
**線程安全性**
* String中的對象是不可變的,也就可以理解為常量,線程安全。AbstractStringBuilder是StringBuilder與StringBuffer的公共父類,定義了一些字符串的基本操作,如expandCapacity、append、insert、indexOf等公共方法。StringBuffer對方法加了同步鎖或者對調用的方法加了同步鎖,所以是線程安全的。StringBuilder并沒有對方法進行加同步鎖,所以是非線程安全的。
**性能**
* 每次對String 類型進行改變的時候,都會生成一個新的String對象,然后將指針指向新的String 對象。StringBuffer每次都會對StringBuffer對象本身進行操作,而不是生成新的對象并改變對象引用。相同情況下使用StirngBuilder 相比使用StringBuffer 僅能獲得10%~15% 左右的性能提升,但卻要冒多線程不安全的風險。
**對于三者使用的總結**
* 如果要操作少量的數據用 = String
* 單線程操作字符串緩沖區 下操作大量數據 = StringBuilder
* 多線程操作字符串緩沖區 下操作大量數據 = StringBuffer
### Date相關
### 包裝類相關
#### 自動裝箱與拆箱
* **裝箱**:將基本類型用它們對應的引用類型包裝起來;
* **拆箱**:將包裝類型轉換為基本數據類型;
#### int 和 Integer 有什么區別
* Java 是一個近乎純潔的面向對象編程語言,但是為了編程的方便還是引入了基本數據類型,但是為了能夠將這些基本數據類型當成對象操作,Java 為每一個基本數據類型都引入了對應的包裝類型(wrapper class),int 的包裝類就是 Integer,從 Java 5 開始引入了自動裝箱/拆箱機制,使得二者可以相互轉換。
* Java 為每個原始類型提供了包裝類型:
* 原始類型: boolean,char,byte,short,int,long,float,double
* 包裝類型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
#### Integer a= 127 與 Integer b = 127相等嗎
* 對于對象引用類型:==比較的是對象的內存地址。
* 對于基本數據類型:==比較的是值。
`如果整型字面量的值在-128到127之間,那么自動裝箱時不會new新的Integer對象,而是直接引用常量池中的Integer對象,超過范圍 a1==b1的結果是false`
~~~
public static void main(String[] args) {
Integer a = new Integer(3);
Integer b = 3; // 將3自動裝箱成Integer類型
int c = 3;
System.out.println(a == b); // false 兩個引用沒有引用同一對象
System.out.println(a == c); // true a自動拆箱成int類型再和c比較
System.out.println(b == c); // true
Integer a1 = 128;
Integer b1 = 128;
System.out.println(a1 == b1); // false
Integer a2 = 127;
Integer b2 = 127;
System.out.println(a2 == b2); // true
}
復制代碼
~~~
- 常見面試題
- 一.Java常見面試題
- 1.Java基礎
- 3.面向對象概念
- 10.Java面試題
- Java基礎知識面試題(總結最全面的面試題)
- 設計模式面試題(總結最全面的面試題)
- Java集合面試題(總結最全面的面試題)
- JavaIO、BIO、NIO、AIO、Netty面試題(總結最全面的面試題)
- Java并發編程面試題(總結最全面的面試題)
- Java異常面試題(總結最全面的面試題)
- Java虛擬機(JVM)面試題(總結最全面的面試題)
- Spring面試題(總結最全面的面試題)
- Spring MVC面試題(總結最全面的面試題)
- Spring Boot面試題(總結最全面的面試題)
- Spring Cloud面試題(總結最全面的面試題)
- Redis面試題(總結最全面的面試題)
- MyBatis面試題(總結最全面的面試題)
- TCP、UDP、Socket、HTTP面試題(總結最全面的面試題)
- 二、MySQL面試題
- 1.基礎部分
- MySQL面試題(總結最全面的面試題)
- HBase相關面試題整理
- Nginx面試題(總結最全面的面試題)
- RabbitMQ面試題(總結最全面的面試題)
- Dubbo面試題(總結最全面的面試題)
- ZooKeeper面試題(總結最全面的面試題)
- Tomcat面試題(總結最全面的面試題)
- Linux面試題(總結最全面的面試題)
- 超詳細的Django面試題
- SSM面試題
- 15個高頻微信小程序面試題
- VUE面試題
- Python面試題
- 二、常見問題解答列表
- 1.查看端口及殺死進程
- 三、學習電子書