
## 基礎知識
#### 為什么要使用并發編程
* 提升多核CPU的利用率:一般來說一臺主機上的會有多個CPU核心,我們可以創建多個線程,理論上講操作系統可以將多個線程分配給不同的CPU去執行,每個CPU執行一個線程,這樣就提高了CPU的使用效率,如果使用單線程就只能有一個CPU核心被使用。
* 比如當我們在網上購物時,為了提升響應速度,需要拆分,減庫存,生成訂單等等這些操作,就可以進行拆分利用多線程的技術完成。面對復雜業務模型,并行程序會比串行程序更適應業務需求,而并發編程更能吻合這種業務拆分 。
* 簡單來說就是:
* 充分利用多核CPU的計算能力;
* 方便進行業務拆分,提升應用性能
#### 多線程應用場景
* 例如: 迅雷多線程下載、數據庫連接池、分批發送短信等。
#### 并發編程有什么缺點
* 并發編程的目的就是為了能提高程序的執行效率,提高程序運行速度,但是并發編程并不總是能提高程序運行速度的,而且并發編程可能會遇到很多問題,比如:內存泄漏、上下文切換、線程安全、死鎖等問題。
#### 并發編程三個必要因素是什么?
* 原子性:原子,即一個不可再被分割的顆粒。原子性指的是一個或多個操作要么全部執行成功要么全部執行失敗。
* 可見性:一個線程對共享變量的修改,另一個線程能夠立刻看到。(synchronized,volatile)
* 有序性:程序執行的順序按照代碼的先后順序執行。(處理器可能會對指令進行重排序)
#### 在 Java 程序中怎么保證多線程的運行安全?
* 出現線程安全問題的原因一般都是三個原因:
* 線程切換帶來的原子性問題 解決辦法:使用多線程之間同步synchronized或使用鎖(lock)。
* 緩存導致的可見性問題 解決辦法:synchronized、volatile、LOCK,可以解決可見性問題
* 編譯優化帶來的有序性問題 解決辦法:Happens-Before 規則可以解決有序性問題
#### 并行和并發有什么區別?
* 并發:多個任務在同一個 CPU 核上,按細分的時間片輪流(交替)執行,從邏輯上來看那些任務是同時執行。
* 并行:單位時間內,多個處理器或多核處理器同時處理多個任務,是真正意義上的“同時進行”。
* 串行:有n個任務,由一個線程按順序執行。由于任務、方法都在一個線程執行所以不存在線程不安全情況,也就不存在臨界區的問題。
**做一個形象的比喻:**
* 并發 = 倆個人用一臺電腦。
* 并行 = 倆個人分配了倆臺電腦。
* 串行 = 倆個人排隊使用一臺電腦。
#### 什么是多線程
* 多線程:多線程是指程序中包含多個執行流,即在一個程序中可以同時運行多個不同的線程來執行不同的任務。
#### 多線程的好處
* 可以提高 CPU 的利用率。在多線程程序中,一個線程必須等待的時候,CPU 可以運行其它的線程而不是等待,這樣就大大提高了程序的效率。也就是說允許單個程序創建多個并行執行的線程來完成各自的任務。
#### 多線程的劣勢:
* 線程也是程序,所以線程需要占用內存,線程越多占用內存也越多;
* 多線程需要協調和管理,所以需要 CPU 時間跟蹤線程;
* 線程之間對共享資源的訪問會相互影響,必須解決競用共享資源的問題。
#### 線程和進程區別
* 什么是線程和進程?
* 進程
一個在內存中運行的應用程序。 每個正在系統上運行的程序都是一個進程
* 線程
進程中的一個執行任務(控制單元), 它負責在程序里獨立執行。
`一個進程至少有一個線程,一個進程可以運行多個線程,多個線程可共享數據。`
* 進程與線程的區別
* 根本區別:進程是操作系統資源分配的基本單位,而線程是處理器任務調度和執行的基本單位
* 資源開銷:每個進程都有獨立的代碼和數據空間(程序上下文),程序之間的切換會有較大的開銷;線程可以看做輕量級的進程,同一類線程共享代碼和數據空間,每個線程都有自己獨立的運行棧和程序計數器(PC),線程之間切換的開銷小。
* 包含關系:如果一個進程內有多個線程,則執行過程不是一條線的,而是多條線(線程)共同完成的;線程是進程的一部分,所以線程也被稱為輕權進程或者輕量級進程。
* 內存分配:同一進程的線程共享本進程的地址空間和資源,而進程與進程之間的地址空間和資源是相互獨立的
* 影響關系:一個進程崩潰后,在保護模式下不會對其他進程產生影響,但是一個線程崩潰有可能導致整個進程都死掉。所以多進程要比多線程健壯。
* 執行過程:每個獨立的進程有程序運行的入口、順序執行序列和程序出口。但是線程不能獨立執行,必須依存在應用程序中,由應用程序提供多個線程執行控制,兩者均可并發執行
#### 什么是上下文切換?
* 多線程編程中一般線程的個數都大于 CPU 核心的個數,而一個 CPU 核心在任意時刻只能被一個線程使用,為了讓這些線程都能得到有效執行,CPU 采取的策略是為每個線程分配時間片并輪轉的形式。當一個線程的時間片用完的時候就會重新處于就緒狀態讓給其他線程使用,這個過程就屬于一次上下文切換。
* 概括來說就是:當前任務在執行完 CPU 時間片切換到另一個任務之前會先保存自己的狀態,以便下次再切換回這個任務時,可以再加載這個任務的狀態。任務從保存到再加載的過程就是一次上下文切換。
* 上下文切換通常是計算密集型的。也就是說,它需要相當可觀的處理器時間,在每秒幾十上百次的切換中,每次切換都需要納秒量級的時間。所以,上下文切換對系統來說意味著消耗大量的 CPU 時間,事實上,可能是操作系統中時間消耗最大的操作。
* Linux 相比與其他操作系統(包括其他類 Unix 系統)有很多的優點,其中有一項就是,其上下文切換和模式切換的時間消耗非常少。
#### 守護線程和用戶線程有什么區別呢?
* 用戶 (User) 線程:運行在前臺,執行具體的任務,如程序的主線程、連接網絡的子線程等都是用戶線程
* 守護 (Daemon) 線程:運行在后臺,為其他前臺線程服務。也可以說守護線程是 JVM 中非守護線程的 “傭人”。一旦所有用戶線程都結束運行,守護線程會隨 JVM 一起結束工作
#### 如何在 Windows 和 Linux 上查找哪個線程cpu利用率最高?
* windows上面用任務管理器看,linux下可以用 top 這個工具看。
* 找出cpu耗用厲害的進程pid, 終端執行top命令,然后按下shift+p (shift+m是找出消耗內存最高)查找出cpu利用最厲害的pid號
* 根據上面第一步拿到的pid號,top -H -p pid 。然后按下shift+p,查找出cpu利用率最厲害的線程號,比如top -H -p 1328
* 將獲取到的線程號轉換成16進制,去百度轉換一下就行
* 使用jstack工具將進程信息打印輸出,jstack pid號 > /tmp/t.dat,比如jstack 31365 > /tmp/t.dat
* 編輯/tmp/t.dat文件,查找線程號對應的信息
`或者直接使用JDK自帶的工具查看“jconsole” 、“visualVm”,這都是JDK自帶的,可以直接在JDK的bin目錄下找到直接使用`
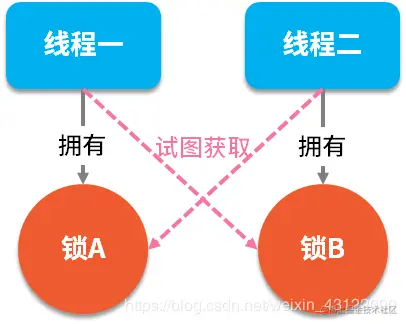
#### 什么是線程死鎖
* 死鎖是指兩個或兩個以上的進程(線程)在執行過程中,由于競爭資源或者由于彼此通信而造成的一種阻塞的現象,若無外力作用,它們都將無法推進下去。此時稱系統處于死鎖狀態或系統產生了死鎖,這些永遠在互相等待的進程(線程)稱為死鎖進程(線程)。
* 多個線程同時被阻塞,它們中的一個或者全部都在等待某個資源被釋放。由于線程被無限期地阻塞,因此程序不可能正常終止。
* 如下圖所示,線程 A 持有資源 2,線程 B 持有資源 1,他們同時都想申請對方的資源,所以這兩個線程就會互相等待而進入死鎖狀態。
#### 形成死鎖的四個必要條件是什么
* 互斥條件:在一段時間內某資源只由一個進程占用。如果此時還有其它進程請求資源,就只能等待,直至占有資源的進程用畢釋放。
* 占有且等待條件:指進程已經保持至少一個資源,但又提出了新的資源請求,而該資源已被其它進程占有,此時請求進程阻塞,但又對自己已獲得的其它資源保持不放。
* 不可搶占條件:別人已經占有了某項資源,你不能因為自己也需要該資源,就去把別人的資源搶過來。
* 循環等待條件:若干進程之間形成一種頭尾相接的循環等待資源關系。(比如一個進程集合,A在等B,B在等C,C在等A)
#### 如何避免線程死鎖
1. 避免一個線程同時獲得多個鎖
2. 避免一個線程在鎖內同時占用多個資源,盡量保證每個鎖只占用一個資源
3. 嘗試使用定時鎖,使用lock.tryLock(timeout)來替代使用內部鎖機制
#### 創建線程的四種方式
* 繼承 Thread 類;
~~~
public class MyThread extends Thread {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " run()方法正在執行...");
}
復制代碼
~~~
* 實現 Runnable 接口;
~~~
public class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " run()方法執行中...");
}
復制代碼
~~~
* 實現 Callable 接口;
~~~
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
System.out.println(Thread.currentThread().getName() + " call()方法執行中...");
return 1;
}
復制代碼
~~~
* 使用匿名內部類方式
~~~
public class CreateRunnable {
public static void main(String[] args) {
//創建多線程創建開始
Thread thread = new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("i:" + i);
}
}
});
thread.start();
}
}
復制代碼
~~~
#### 說一下 runnable 和 callable 有什么區別
**相同點:**
* 都是接口
* 都可以編寫多線程程序
* 都采用Thread.start()啟動線程
**主要區別:**
* Runnable 接口 run 方法無返回值;Callable 接口 call 方法有返回值,是個泛型,和Future、FutureTask配合可以用來獲取異步執行的結果
* Runnable 接口 run 方法只能拋出運行時異常,且無法捕獲處理;Callable 接口 call 方法允許拋出異常,可以獲取異常信息 注:Callalbe接口支持返回執行結果,需要調用FutureTask.get()得到,此方法會阻塞主進程的繼續往下執行,如果不調用不會阻塞。
#### 線程的 run()和 start()有什么區別?
* 每個線程都是通過某個特定Thread對象所對應的方法run()來完成其操作的,run()方法稱為線程體。通過調用Thread類的start()方法來啟動一個線程。
* start() 方法用于啟動線程,run() 方法用于執行線程的運行時代碼。run() 可以重復調用,而 start() 只能調用一次。
* start()方法來啟動一個線程,真正實現了多線程運行。調用start()方法無需等待run方法體代碼執行完畢,可以直接繼續執行其他的代碼; 此時線程是處于就緒狀態,并沒有運行。 然后通過此Thread類調用方法run()來完成其運行狀態, run()方法運行結束, 此線程終止。然后CPU再調度其它線程。
* run()方法是在本線程里的,只是線程里的一個函數,而不是多線程的。 如果直接調用run(),其實就相當于是調用了一個普通函數而已,直接待用run()方法必須等待run()方法執行完畢才能執行下面的代碼,所以執行路徑還是只有一條,根本就沒有線程的特征,所以在多線程執行時要使用start()方法而不是run()方法。
#### 為什么我們調用 start() 方法時會執行 run() 方法,為什么我們不能直接調用 run() 方法?
這是另一個非常經典的 java 多線程面試問題,而且在面試中會經常被問到。很簡單,但是很多人都會答不上來!
* new 一個 Thread,線程進入了新建狀態。調用 start() 方法,會啟動一個線程并使線程進入了就緒狀態,當分配到`時間片`后就可以開始運行了。 start() 會執行線程的相應準備工作,然后自動執行 run() 方法的內容,這是真正的多線程工作。
* 而直接執行 run() 方法,會把 run 方法當成一個 main 線程下的普通方法去執行,并不會在某個線程中執行它,所以這并不是多線程工作。
總結: 調用 start 方法方可啟動線程并使線程進入就緒狀態,而 run 方法只是 thread 的一個普通方法調用,還是在主線程里執行。
#### 什么是 Callable 和 Future?
* Callable 接口類似于 Runnable,從名字就可以看出來了,但是 Runnable 不會返回結果,并且無法拋出返回結果的異常,而 Callable 功能更強大一些,被線程執行后,可以返回值,這個返回值可以被 Future 拿到,也就是說,Future 可以拿到異步執行任務的返回值。
* Future 接口表示異步任務,是一個可能還沒有完成的異步任務的結果。所以說 Callable用于產生結果,Future 用于獲取結果。
#### 什么是 FutureTask
* FutureTask 表示一個異步運算的任務。FutureTask 里面可以傳入一個 Callable 的具體實現類,可以對這個異步運算的任務的結果進行等待獲取、判斷是否已經完成、取消任務等操作。只有當運算完成的時候結果才能取回,如果運算尚未完成 get 方法將會阻塞。一個 FutureTask 對象可以對調用了 Callable 和 Runnable 的對象進行包裝,由于 FutureTask 也是Runnable 接口的實現類,所以 FutureTask 也可以放入線程池中。
#### 線程的狀態
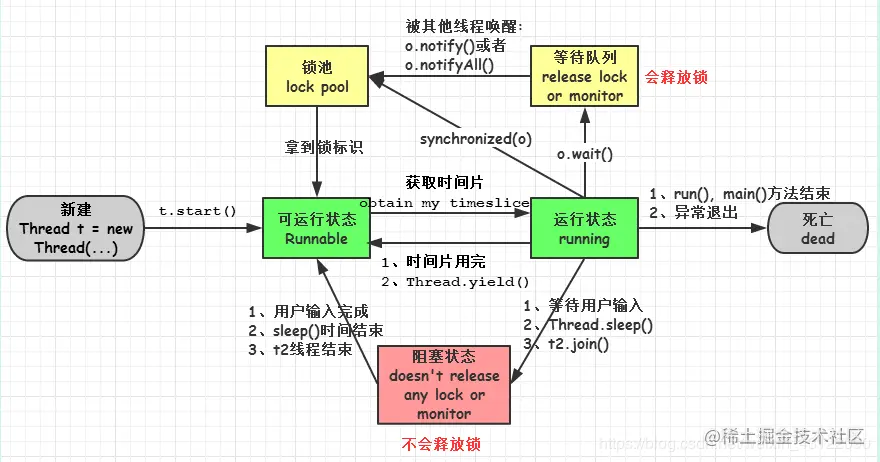
* 新建(new):新創建了一個線程對象。
* 就緒(可運行狀態)(runnable):線程對象創建后,當調用線程對象的 start()方法,該線程處于就緒狀態,等待被線程調度選中,獲取cpu的使用權。
* 運行(running):可運行狀態(runnable)的線程獲得了cpu時間片(timeslice),執行程序代碼。注:就緒狀態是進入到運行狀態的唯一入口,也就是說,線程要想進入運行狀態執行,首先必須處于就緒狀態中;
* 阻塞(block):處于運行狀態中的線程由于某種原因,暫時放棄對 CPU的使用權,停止執行,此時進入阻塞狀態,直到其進入到就緒狀態,才 有機會再次被 CPU 調用以進入到運行狀態。
* 阻塞的情況分三種:
* (一). 等待阻塞:運行狀態中的線程執行 wait()方法,JVM會把該線程放入等待隊列(waitting queue)中,使本線程進入到等待阻塞狀態;
* (二). 同步阻塞:線程在獲取 synchronized 同步鎖失敗(因為鎖被其它線程所占用),,則JVM會把該線程放入鎖池(lock pool)中,線程會進入同步阻塞狀態;
* (三). 其他阻塞: 通過調用線程的 sleep()或 join()或發出了 I/O 請求時,線程會進入到阻塞狀態。當 sleep()狀態超時、join()等待線程終止或者超時、或者 I/O 處理完畢時,線程重新轉入就緒狀態。
* 死亡(dead)(結束):線程run()、main()方法執行結束,或者因異常退出了run()方法,則該線程結束生命周期。死亡的線程不可再次復生。
#### Java 中用到的線程調度算法是什么?
* 計算機通常只有一個 CPU,在任意時刻只能執行一條機器指令,每個線程只有獲得CPU 的使用權才能執行指令。所謂多線程的并發運行,其實是指從宏觀上看,各個線程輪流獲得 CPU 的使用權,分別執行各自的任務。在運行池中,會有多個處于就緒狀態的線程在等待 CPU,JAVA 虛擬機的一項任務就是負責線程的調度,線程調度是指按照特定機制為多個線程分配 CPU 的使用權。(Java是由JVM中的線程計數器來實現線程調度)
* 有兩種調度模型:分時調度模型和搶占式調度模型。
* 分時調度模型是指讓所有的線程輪流獲得 cpu 的使用權,并且平均分配每個線程占用的 CPU 的時間片這個也比較好理解。
* Java虛擬機采用搶占式調度模型,是指優先讓可運行池中優先級高的線程占用CPU,如果可運行池中的線程優先級相同,那么就隨機選擇一個線程,使其占用CPU。處于運行狀態的線程會一直運行,直至它不得不放棄 CPU。
#### 線程的調度策略
`線程調度器選擇優先級最高的線程運行,但是,如果發生以下情況,就會終止線程的運行:`
* (1)線程體中調用了 yield 方法讓出了對 cpu 的占用權利
* (2)線程體中調用了 sleep 方法使線程進入睡眠狀態
* (3)線程由于 IO 操作受到阻塞
* (4)另外一個更高優先級線程出現
* (5)在支持時間片的系統中,該線程的時間片用完
#### 什么是線程調度器(Thread Scheduler)和時間分片(Time Slicing )?
* 線程調度器是一個操作系統服務,它負責為 Runnable 狀態的線程分配 CPU 時間。一旦我們創建一個線程并啟動它,它的執行便依賴于線程調度器的實現。
* 時間分片是指將可用的 CPU 時間分配給可用的 Runnable 線程的過程。分配 CPU 時間可以基于線程優先級或者線程等待的時間。
* 線程調度并不受到 Java 虛擬機控制,所以由應用程序來控制它是更好的選擇(也就是說不要讓你的程序依賴于線程的優先級)。
#### 請說出與線程同步以及線程調度相關的方法。
* (1) wait():使一個線程處于等待(阻塞)狀態,并且釋放所持有的對象的鎖;
* (2)sleep():使一個正在運行的線程處于睡眠狀態,是一個靜態方法,調用此方法要處理 InterruptedException 異常;
* (3)notify():喚醒一個處于等待狀態的線程,當然在調用此方法的時候,并不能確切的喚醒某一個等待狀態的線程,而是由 JVM 確定喚醒哪個線程,而且與優先級無關;
* (4)notityAll():喚醒所有處于等待狀態的線程,該方法并不是將對象的鎖給所有線程,而是讓它們競爭,只有獲得鎖的線程才能進入就緒狀態;
#### sleep() 和 wait() 有什么區別?
`兩者都可以暫停線程的執行`
* 類的不同:sleep() 是 Thread線程類的靜態方法,wait() 是 Object類的方法。
* 是否釋放鎖:sleep() 不釋放鎖;wait() 釋放鎖。
* 用途不同:Wait 通常被用于線程間交互/通信,sleep 通常被用于暫停執行。
* 用法不同:wait() 方法被調用后,線程不會自動蘇醒,需要別的線程調用同一個對象上的 notify() 或者 notifyAll() 方法。sleep() 方法執行完成后,線程會自動蘇醒。或者可以使用wait(long timeout)超時后線程會自動蘇醒。
#### 你是如何調用 wait() 方法的?使用 if 塊還是循環?為什么?
* 處于等待狀態的線程可能會收到錯誤警報和偽喚醒,如果不在循環中檢查等待條件,程序就會在沒有滿足結束條件的情況下退出。
* wait() 方法應該在循環調用,因為當線程獲取到 CPU 開始執行的時候,其他條件可能還沒有滿足,所以在處理前,循環檢測條件是否滿足會更好。下面是一段標準的使用 wait 和 notify 方法的代碼:
~~~
synchronized (monitor) {
// 判斷條件謂詞是否得到滿足
while(!locked) {
// 等待喚醒
monitor.wait();
}
// 處理其他的業務邏輯
}
復制代碼
~~~
#### 為什么線程通信的方法 wait(), notify()和 notifyAll()被定義在 Object 類里?
* 因為Java所有類的都繼承了Object,Java想讓任何對象都可以作為鎖,并且 wait(),notify()等方法用于等待對象的鎖或者喚醒線程,在 Java 的線程中并沒有可供任何對象使用的鎖,所以任意對象調用方法一定定義在Object類中。
* 有的人會說,既然是線程放棄對象鎖,那也可以把wait()定義在Thread類里面啊,新定義的線程繼承于Thread類,也不需要重新定義wait()方法的實現。然而,這樣做有一個非常大的問題,一個線程完全可以持有很多鎖,你一個線程放棄鎖的時候,到底要放棄哪個鎖?當然了,這種設計并不是不能實現,只是管理起來更加復雜。
#### 為什么 wait(), notify()和 notifyAll()必須在同步方法或者同步塊中被調用?
* 當一個線程需要調用對象的 wait()方法的時候,這個線程必須擁有該對象的鎖,接著它就會釋放這個對象鎖并進入等待狀態直到其他線程調用這個對象上的 notify()方法。同樣的,當一個線程需要調用對象的 notify()方法時,它會釋放這個對象的鎖,以便其他在等待的線程就可以得到這個對象鎖。由于所有的這些方法都需要線程持有對象的鎖,這樣就只能通過同步來實現,所以他們只能在同步方法或者同步塊中被調用。
#### Thread 類中的 yield 方法有什么作用?
* 使當前線程從執行狀態(運行狀態)變為可執行態(就緒狀態)。
* 當前線程到了就緒狀態,那么接下來哪個線程會從就緒狀態變成執行狀態呢?可能是當前線程,也可能是其他線程,看系統的分配了。
#### 為什么 Thread 類的 sleep()和 yield ()方法是靜態的?
* Thread 類的 sleep()和 yield()方法將在當前正在執行的線程上運行。所以在其他處于等待狀態的線程上調用這些方法是沒有意義的。這就是為什么這些方法是靜態的。它們可以在當前正在執行的線程中工作,并避免程序員錯誤的認為可以在其他非運行線程調用這些方法。
#### 線程的 sleep()方法和 yield()方法有什么區別?
* (1) sleep()方法給其他線程運行機會時不考慮線程的優先級,因此會給低優先級的線程以運行的機會;yield()方法只會給相同優先級或更高優先級的線程以運行的機會;
* (2) 線程執行 sleep()方法后轉入阻塞(blocked)狀態,而執行 yield()方法后轉入就緒(ready)狀態;
* (3)sleep()方法聲明拋出 InterruptedException,而 yield()方法沒有聲明任何異常;
* (4)sleep()方法比 yield()方法(跟操作系統 CPU 調度相關)具有更好的可移植性,通常不建議使用yield()方法來控制并發線程的執行。
#### 如何停止一個正在運行的線程?
* 在java中有以下3種方法可以終止正在運行的線程:
* 使用退出標志,使線程正常退出,也就是當run方法完成后線程終止。
* 使用stop方法強行終止,但是不推薦這個方法,因為stop和suspend及resume一樣都是過期作廢的方法。
* 使用interrupt方法中斷線程。
#### Java 中 interrupted 和 isInterrupted 方法的區別?
* interrupt:用于中斷線程。調用該方法的線程的狀態為將被置為”中斷”狀態。
注意:線程中斷僅僅是置線程的中斷狀態位,不會停止線程。需要用戶自己去監視線程的狀態為并做處理。支持線程中斷的方法(也就是線程中斷后會拋出interruptedException 的方法)就是在監視線程的中斷狀態,一旦線程的中斷狀態被置為“中斷狀態”,就會拋出中斷異常。
* interrupted:是靜態方法,查看當前中斷信號是true還是false并且清除中斷信號。如果一個線程被中斷了,第一次調用 interrupted 則返回 true,第二次和后面的就返回 false 了。
* isInterrupted:是可以返回當前中斷信號是true還是false,與interrupt最大的差別
#### 什么是阻塞式方法?
* 阻塞式方法是指程序會一直等待該方法完成期間不做其他事情,ServerSocket 的accept()方法就是一直等待客戶端連接。這里的阻塞是指調用結果返回之前,當前線程會被掛起,直到得到結果之后才會返回。此外,還有異步和非阻塞式方法在任務完成前就返回。
#### Java 中你怎樣喚醒一個阻塞的線程?
* 首先 ,wait()、notify() 方法是針對對象的,調用任意對象的 wait()方法都將導致線程阻塞,阻塞的同時也將釋放該對象的鎖,相應地,調用任意對象的 notify()方法則將隨機解除該對象阻塞的線程,但它需要重新獲取該對象的鎖,直到獲取成功才能往下執行;
* 其次,wait、notify 方法必須在 synchronized 塊或方法中被調用,并且要保證同步塊或方法的鎖對象與調用 wait、notify 方法的對象是同一個,如此一來在調用 wait 之前當前線程就已經成功獲取某對象的鎖,執行 wait 阻塞后當前線程就將之前獲取的對象鎖釋放。
#### notify() 和 notifyAll() 有什么區別?
* 如果線程調用了對象的 wait()方法,那么線程便會處于該對象的等待池中,等待池中的線程不會去競爭該對象的鎖。
* notifyAll() 會喚醒所有的線程,notify() 只會喚醒一個線程。
* notifyAll() 調用后,會將全部線程由等待池移到鎖池,然后參與鎖的競爭,競爭成功則繼續執行,如果不成功則留在鎖池等待鎖被釋放后再次參與競爭。而 notify()只會喚醒一個線程,具體喚醒哪一個線程由虛擬機控制。
#### 如何在兩個線程間共享數據?
* 在兩個線程間共享變量即可實現共享。
`一般來說,共享變量要求變量本身是線程安全的,然后在線程內使用的時候,如果有對共享變量的復合操作,那么也得保證復合操作的線程安全性。`
#### Java 如何實現多線程之間的通訊和協作?
* 可以通過中斷 和 共享變量的方式實現線程間的通訊和協作
* 比如說最經典的生產者-消費者模型:當隊列滿時,生產者需要等待隊列有空間才能繼續往里面放入商品,而在等待的期間內,生產者必須釋放對臨界資源(即隊列)的占用權。因為生產者如果不釋放對臨界資源的占用權,那么消費者就無法消費隊列中的商品,就不會讓隊列有空間,那么生產者就會一直無限等待下去。因此,一般情況下,當隊列滿時,會讓生產者交出對臨界資源的占用權,并進入掛起狀態。然后等待消費者消費了商品,然后消費者通知生產者隊列有空間了。同樣地,當隊列空時,消費者也必須等待,等待生產者通知它隊列中有商品了。這種互相通信的過程就是線程間的協作。
* Java中線程通信協作的最常見方式:
* 一.syncrhoized加鎖的線程的Object類的wait()/notify()/notifyAll()
* 二.ReentrantLock類加鎖的線程的Condition類的await()/signal()/signalAll()
* 線程間直接的數據交換:
* 三.通過管道進行線程間通信:字節流、字符流
#### 同步方法和同步塊,哪個是更好的選擇?
* 同步塊是更好的選擇,因為它不會鎖住整個對象(當然你也可以讓它鎖住整個對象)。同步方法會鎖住整個對象,哪怕這個類中有多個不相關聯的同步塊,這通常會導致他們停止執行并需要等待獲得這個對象上的鎖。
* 同步塊更要符合開放調用的原則,只在需要鎖住的代碼塊鎖住相應的對象,這樣從側面來說也可以避免死鎖。
`請知道一條原則:同步的范圍越小越好。`
#### 什么是線程同步和線程互斥,有哪幾種實現方式?
* 當一個線程對共享的數據進行操作時,應使之成為一個”原子操作“,即在沒有完成相關操作之前,不允許其他線程打斷它,否則,就會破壞數據的完整性,必然會得到錯誤的處理結果,這就是線程的同步。
* 在多線程應用中,考慮不同線程之間的數據同步和防止死鎖。當兩個或多個線程之間同時等待對方釋放資源的時候就會形成線程之間的死鎖。為了防止死鎖的發生,需要通過同步來實現線程安全。
* 線程互斥是指對于共享的進程系統資源,在各單個線程訪問時的排它性。當有若干個線程都要使用某一共享資源時,任何時刻最多只允許一個線程去使用,其它要使用該資源的線程必須等待,直到占用資源者釋放該資源。線程互斥可以看成是一種特殊的線程同步。
* 線程間的同步方法大體可分為兩類:用戶模式和內核模式。顧名思義,內核模式就是指利用系統內核對象的單一性來進行同步,使用時需要切換內核態與用戶態,而用戶模式就是不需要切換到內核態,只在用戶態完成操作。
* 用戶模式下的方法有:原子操作(例如一個單一的全局變量),臨界區。內核模式下的方法有:事件,信號量,互斥量。
* 實現線程同步的方法
* 同步代碼方法:sychronized 關鍵字修飾的方法
* 同步代碼塊:sychronized 關鍵字修飾的代碼塊
* 使用特殊變量域volatile實現線程同步:volatile關鍵字為域變量的訪問提供了一種免鎖機制
* 使用重入鎖實現線程同步:reentrantlock類是可沖入、互斥、實現了lock接口的鎖他與sychronized方法具有相同的基本行為和語義
#### 在監視器(Monitor)內部,是如何做線程同步的?程序應該做哪種級別的同步?
* 在 java 虛擬機中,監視器和鎖在Java虛擬機中是一塊使用的。監視器監視一塊同步代碼塊,確保一次只有一個線程執行同步代碼塊。每一個監視器都和一個對象引用相關聯。線程在獲取鎖之前不允許執行同步代碼。
* 一旦方法或者代碼塊被 synchronized 修飾,那么這個部分就放入了監視器的監視區域,確保一次只能有一個線程執行該部分的代碼,線程在獲取鎖之前不允許執行該部分的代碼
* 另外 java 還提供了顯式監視器( Lock )和隱式監視器( synchronized )兩種鎖方案
#### 如果你提交任務時,線程池隊列已滿,這時會發生什么
* 有倆種可能:
(1)如果使用的是無界隊列 LinkedBlockingQueue,也就是無界隊列的話,沒關系,繼續添加任務到阻塞隊列中等待執行,因為 LinkedBlockingQueue 可以近乎認為是一個無窮大的隊列,可以無限存放任務
(2)如果使用的是有界隊列比如 ArrayBlockingQueue,任務首先會被添加到ArrayBlockingQueue 中,ArrayBlockingQueue 滿了,會根據maximumPoolSize 的值增加線程數量,如果增加了線程數量還是處理不過來,ArrayBlockingQueue 繼續滿,那么則會使用拒絕策略RejectedExecutionHandler 處理滿了的任務,默認是 AbortPolicy
#### 什么叫線程安全?servlet 是線程安全嗎?
* 線程安全是編程中的術語,指某個方法在多線程環境中被調用時,能夠正確地處理多個線程之間的共享變量,使程序功能正確完成。
* Servlet 不是線程安全的,servlet 是單實例多線程的,當多個線程同時訪問同一個方法,是不能保證共享變量的線程安全性的。
* Struts2 的 action 是多實例多線程的,是線程安全的,每個請求過來都會 new 一個新的 action 分配給這個請求,請求完成后銷毀。
* SpringMVC 的 Controller 是線程安全的嗎?不是的,和 Servlet 類似的處理流程。
* Struts2 好處是不用考慮線程安全問題;Servlet 和 SpringMVC 需要考慮線程安全問題,但是性能可以提升不用處理太多的 gc,可以使用 ThreadLocal 來處理多線程的問題。
#### 在 Java 程序中怎么保證多線程的運行安全?
* 方法一:使用安全類,比如 java.util.concurrent 下的類,使用原子類AtomicInteger
* 方法二:使用自動鎖 synchronized。
* 方法三:使用手動鎖 Lock。
* 手動鎖 Java 示例代碼如下:
~~~
Lock lock = new ReentrantLock();
lock. lock();
try {
System. out. println("獲得鎖");
} catch (Exception e) {
// TODO: handle exception
} finally {
System. out. println("釋放鎖");
lock. unlock();
}
復制代碼
~~~
#### 你對線程優先級的理解是什么?
* 每一個線程都是有優先級的,一般來說,高優先級的線程在運行時會具有優先權,但這依賴于線程調度的實現,這個實現是和操作系統相關的(OS dependent)。我們可以定義線程的優先級,但是這并不能保證高優先級的線程會在低優先級的線程前執行。線程優先級是一個 int 變量(從 1-10),1 代表最低優先級,10 代表最高優先級。
* Java 的線程優先級調度會委托給操作系統去處理,所以與具體的操作系統優先級有關,如非特別需要,一般無需設置線程優先級。
* 當然,如果你真的想設置優先級可以通過setPriority()方法設置,但是設置了不一定會該變,這個是不準確的
#### 線程類的構造方法、靜態塊是被哪個線程調用的
* 這是一個非常刁鉆和狡猾的問題。請記住:線程類的構造方法、靜態塊是被 new這個線程類所在的線程所調用的,而 run 方法里面的代碼才是被線程自身所調用的。
* 如果說上面的說法讓你感到困惑,那么我舉個例子,假設 Thread2 中 new 了Thread1,main 函數中 new 了 Thread2,那么:
(1)Thread2 的構造方法、靜態塊是 main 線程調用的,Thread2 的 run()方法是Thread2 自己調用的
(2)Thread1 的構造方法、靜態塊是 Thread2 調用的,Thread1 的 run()方法是Thread1 自己調用的
#### Java 中怎么獲取一份線程 dump 文件?你如何在 Java 中獲取線程堆棧?
* Dump文件是進程的內存鏡像。可以把程序的執行狀態通過調試器保存到dump文件中。
* 在 Linux 下,你可以通過命令 kill -3 PID (Java 進程的進程 ID)來獲取 Java應用的 dump 文件。
* 在 Windows 下,你可以按下 Ctrl + Break 來獲取。這樣 JVM 就會將線程的 dump 文件打印到標準輸出或錯誤文件中,它可能打印在控制臺或者日志文件中,具體位置依賴應用的配置。
#### 一個線程運行時發生異常會怎樣?
* 如果異常沒有被捕獲該線程將會停止執行。Thread.UncaughtExceptionHandler是用于處理未捕獲異常造成線程突然中斷情況的一個內嵌接口。當一個未捕獲異常將造成線程中斷的時候,JVM 會使用 Thread.getUncaughtExceptionHandler()來查詢線程的 UncaughtExceptionHandler 并將線程和異常作為參數傳遞給 handler 的 uncaughtException()方法進行處理。
#### Java 線程數過多會造成什么異常?
* 線程的生命周期開銷非常高
* 消耗過多的 CPU
資源如果可運行的線程數量多于可用處理器的數量,那么有線程將會被閑置。大量空閑的線程會占用許多內存,給垃圾回收器帶來壓力,而且大量的線程在競爭 CPU資源時還將產生其他性能的開銷。
* 降低穩定性JVM
在可創建線程的數量上存在一個限制,這個限制值將隨著平臺的不同而不同,并且承受著多個因素制約,包括 JVM 的啟動參數、Thread 構造函數中請求棧的大小,以及底層操作系統對線程的限制等。如果破壞了這些限制,那么可能拋出OutOfMemoryError 異常。
#### 多線程的常用方法
| 方法 名 | 描述 |
| --- | --- |
| sleep() | 強迫一個線程睡眠N毫秒 |
| isAlive() | 判斷一個線程是否存活。 |
| join() | 等待線程終止。 |
| activeCount() | 程序中活躍的線程數。 |
| enumerate() | 枚舉程序中的線程。 |
| currentThread() | 得到當前線程。 |
| isDaemon() | 一個線程是否為守護線程。 |
| setDaemon() | 設置一個線程為守護線程。 |
| setName() | 為線程設置一個名稱。 |
| wait() | 強迫一個線程等待。 |
| notify() | 通知一個線程繼續運行。 |
| setPriority() | 設置一個線程的優先級。 |
## 并發理論
#### Java中垃圾回收有什么目的?什么時候進行垃圾回收?
* 垃圾回收是在內存中存在沒有引用的對象或超過作用域的對象時進行的。
* 垃圾回收的目的是識別并且丟棄應用不再使用的對象來釋放和重用資源。
#### 線程之間如何通信及線程之間如何同步
* 在并發編程中,我們需要處理兩個關鍵問題:線程之間如何通信及線程之間如何同步。通信是指線程之間以如何來交換信息。一般線程之間的通信機制有兩種:共享內存和消息傳遞。
* Java的并發采用的是共享內存模型,Java線程之間的通信總是隱式進行,整個通信過程對程序員完全透明。如果編寫多線程程序的Java程序員不理解隱式進行的線程之間通信的工作機制,很可能會遇到各種奇怪的內存可見性問題。
#### Java內存模型
* 共享內存模型指的就是Java內存模型(簡稱JMM),JMM決定一個線程對共享變量的寫入時,能對另一個線程可見。從抽象的角度來看,JMM定義了線程和主內存之間的抽象關系:線程之間的共享變量存儲在主內存(main memory)中,每個線程都有一個私有的本地內存(local memory),本地內存中存儲了該線程以讀/寫共享變量的副本。本地內存是JMM的一個抽象概念,并不真實存在。它涵蓋了緩存,寫緩沖區,寄存器以及其他的硬件和編譯器優化。
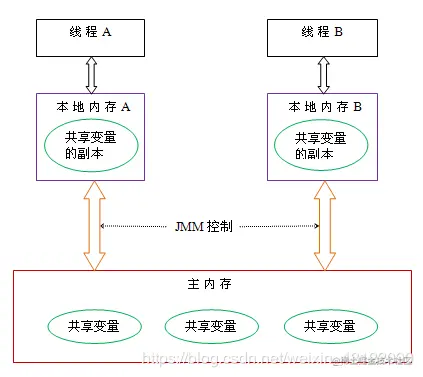
* 從上圖來看,線程A與線程B之間如要通信的話,必須要經歷下面2個步驟:
1. 首先,線程A把本地內存A中更新過的共享變量刷新到主內存中去。
2. 然后,線程B到主內存中去讀取線程A之前已更新過的共享變量。
**下面通過示意圖來說明線程之間的通信**
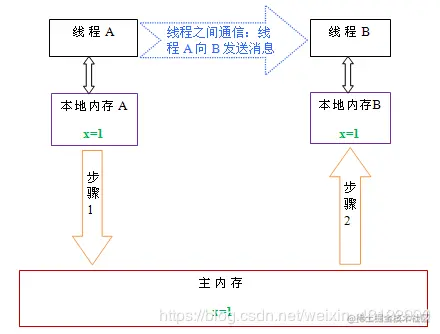
* 總結:什么是Java內存模型:java內存模型簡稱jmm,定義了一個線程對另一個線程可見。共享變量存放在主內存中,每個線程都有自己的本地內存,當多個線程同時訪問一個數據的時候,可能本地內存沒有及時刷新到主內存,所以就會發生線程安全問題。
#### 如果對象的引用被置為null,垃圾收集器是否會立即釋放對象占用的內存?
* 不會,在下一個垃圾回調周期中,這個對象將是被可回收的。
* 也就是說并不會立即被垃圾收集器立刻回收,而是在下一次垃圾回收時才會釋放其占用的內存。
#### finalize()方法什么時候被調用?析構函數(finalization)的目的是什么?
* 1.垃圾回收器(garbage colector)決定回收某對象時,就會運行該對象的finalize()方法; finalize是Object類的一個方法,該方法在Object類中的聲明protected void finalize() throws Throwable { } 在垃圾回收器執行時會調用被回收對象的finalize()方法,可以覆蓋此方法來實現對其資源的回收。注意:一旦垃圾回收器準備釋放對象占用的內存,將首先調用該對象的finalize()方法,并且下一次垃圾回收動作發生時,才真正回收對象占用的內存空間
* 2. GC本來就是內存回收了,應用還需要在finalization做什么呢? 答案是大部分時候,什么都不用做(也就是不需要重載)。只有在某些很特殊的情況下,比如你調用了一些native的方法(一般是C寫的),可以要在finaliztion里去調用C的釋放函數。
* Finalizetion主要用來釋放被對象占用的資源(不是指內存,而是指其他資源,比如文件(File Handle)、端口(ports)、數據庫連接(DB Connection)等)。然而,它不能真正有效地工作。
#### 什么是重排序
* 程序執行的順序按照代碼的先后順序執行。
* 一般來說處理器為了提高程序運行效率,可能會對輸入代碼進行優化,進行重新排序(重排序),它不保證程序中各個語句的執行先后順序同代碼中的順序一致,但是它會保證程序最終執行結果和代碼順序執行的結果是一致的。
~~~
int a = 5; //語句1
int r = 3; //語句2
a = a + 2; //語句3
r = a*a; //語句4
復制代碼
~~~
* 則因為重排序,他還可能執行順序為(這里標注的是語句的執行順序) 2-1-3-4,1-3-2-4 但絕不可能 2-1-4-3,因為這打破了依賴關系。
* 顯然重排序對單線程運行是不會有任何問題,但是多線程就不一定了,所以我們在多線程編程時就得考慮這個問題了。
#### 重排序實際執行的指令步驟

1. 編譯器優化的重排序。編譯器在不改變單線程程序語義的前提下,可以重新安排語句的執行順序。
2. 指令級并行的重排序。現代處理器采用了指令級并行技術(ILP)來將多條指令重疊執行。如果不存在數據依賴性,處理器可以改變語句對應機器指令的執行順序。
3. 內存系統的重排序。由于處理器使用緩存和讀/寫緩沖區,這使得加載和存儲操作看上去可能是在亂序執行。
* 這些重排序對于單線程沒問題,但是多線程都可能會導致多線程程序出現內存可見性問題。
#### 重排序遵守的規則
* as-if-serial:
1. 不管怎么排序,結果不能改變
2. 不存在數據依賴的可以被編譯器和處理器重排序
3. 一個操作依賴兩個操作,這兩個操作如果不存在依賴可以重排序
4. 單線程根據此規則不會有問題,但是重排序后多線程會有問題
#### as-if-serial規則和happens-before規則的區別
* as-if-serial語義保證單線程內程序的執行結果不被改變,happens-before關系保證正確同步的多線程程序的執行結果不被改變。
* as-if-serial語義給編寫單線程程序的程序員創造了一個幻境:單線程程序是按程序的順序來執行的。happens-before關系給編寫正確同步的多線程程序的程序員創造了一個幻境:正確同步的多線程程序是按happens-before指定的順序來執行的。
* as-if-serial語義和happens-before這么做的目的,都是為了在不改變程序執行結果的前提下,盡可能地提高程序執行的并行度。
#### 并發關鍵字 synchronized ?
* 在 Java 中,synchronized 關鍵字是用來控制線程同步的,就是在多線程的環境下,控制 synchronized 代碼段不被多個線程同時執行。synchronized 可以修飾類、方法、變量。
* 另外,在 Java 早期版本中,synchronized屬于重量級鎖,效率低下,因為監視器鎖(monitor)是依賴于底層的操作系統的 Mutex Lock 來實現的,Java 的線程是映射到操作系統的原生線程之上的。如果要掛起或者喚醒一個線程,都需要操作系統幫忙完成,而操作系統實現線程之間的切換時需要從用戶態轉換到內核態,這個狀態之間的轉換需要相對比較長的時間,時間成本相對較高,這也是為什么早期的 synchronized 效率低的原因。慶幸的是在 Java 6 之后 Java 官方對從 JVM 層面對synchronized 較大優化,所以現在的 synchronized 鎖效率也優化得很不錯了。JDK1.6對鎖的實現引入了大量的優化,如自旋鎖、適應性自旋鎖、鎖消除、鎖粗化、偏向鎖、輕量級鎖等技術來減少鎖操作的開銷。
#### 說說自己是怎么使用 synchronized 關鍵字,在項目中用到了嗎
**synchronized關鍵字最主要的三種使用方式:**
* 修飾實例方法: 作用于當前對象實例加鎖,進入同步代碼前要獲得當前對象實例的鎖
* 修飾靜態方法: 也就是給當前類加鎖,會作用于類的所有對象實例,因為靜態成員不屬于任何一個實例對象,是類成員( static 表明這是該類的一個靜態資源,不管new了多少個對象,只有一份)。所以如果一個線程A調用一個實例對象的非靜態 synchronized 方法,而線程B需要調用這個實例對象所屬類的靜態 synchronized 方法,是允許的,不會發生互斥現象,因為訪問靜態 synchronized 方法占用的鎖是當前類的鎖,而訪問非靜態 synchronized 方法占用的鎖是當前實例對象鎖。
* 修飾代碼塊: 指定加鎖對象,對給定對象加鎖,進入同步代碼庫前要獲得給定對象的鎖。
`總結: synchronized 關鍵字加到 static 靜態方法和 synchronized(class)代碼塊上都是是給 Class 類上鎖。synchronized 關鍵字加到實例方法上是給對象實例上鎖。盡量不要使用 synchronized(String a) 因為JVM中,字符串常量池具有緩存功能!`
#### 單例模式了解嗎?給我解釋一下雙重檢驗鎖方式實現單例模式!”
**雙重校驗鎖實現對象單例(線程安全)**
**說明:**
* 雙鎖機制的出現是為了解決前面同步問題和性能問題,看下面的代碼,簡單分析下確實是解決了多線程并行進來不會出現重復new對象,而且也實現了懶加載
~~~
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {}
public static Singleton getUniqueInstance() {
//先判斷對象是否已經實例過,沒有實例化過才進入加鎖代碼
if (uniqueInstance == null) {
//類對象加鎖
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
復制代碼
~~~
}
`另外,需要注意 uniqueInstance 采用 volatile 關鍵字修飾也是很有必要。`
* uniqueInstance 采用 volatile 關鍵字修飾也是很有必要的, uniqueInstance = new Singleton(); 這段代碼其實是分為三步執行:
1. 為 uniqueInstance 分配內存空間
2. 初始化 uniqueInstance
3. 將 uniqueInstance 指向分配的內存地址
`但是由于 JVM 具有指令重排的特性,執行順序有可能變成 1->3->2。指令重排在單線程環境下不會出現問題,但是在多線程環境下會導致一個線程獲得還沒有初始化的實例。例如,線程 T1 執行了 1 和 3,此時 T2 調用 getUniqueInstance() 后發現 uniqueInstance 不為空,因此返回 uniqueInstance,但此時 uniqueInstance 還未被初始化。`
`使用 volatile 可以禁止 JVM 的指令重排,保證在多線程環境下也能正常運行。`
#### 說一下 synchronized 底層實現原理?
* Synchronized的語義底層是通過一個monitor(監視器鎖)的對象來完成,
* 每個對象有一個監視器鎖(monitor)。每個Synchronized修飾過的代碼當它的monitor被占用時就會處于鎖定狀態并且嘗試獲取monitor的所有權 ,過程:
1、如果monitor的進入數為0,則該線程進入monitor,然后將進入數設置為1,該線程即為monitor的所有者。
2、如果線程已經占有該monitor,只是重新進入,則進入monitor的進入數加1.
3、如果其他線程已經占用了monitor,則該線程進入阻塞狀態,直到monitor的進入數為0,再重新嘗試獲取monitor的所有權。
`synchronized是可以通過 反匯編指令 javap命令,查看相應的字節碼文件。`
#### synchronized可重入的原理
* 重入鎖是指一個線程獲取到該鎖之后,該線程可以繼續獲得該鎖。底層原理維護一個計數器,當線程獲取該鎖時,計數器加一,再次獲得該鎖時繼續加一,釋放鎖時,計數器減一,當計數器值為0時,表明該鎖未被任何線程所持有,其它線程可以競爭獲取鎖。
#### 什么是自旋
* 很多 synchronized 里面的代碼只是一些很簡單的代碼,執行時間非常快,此時等待的線程都加鎖可能是一種不太值得的操作,因為線程阻塞涉及到用戶態和內核態切換的問題。既然 synchronized 里面的代碼執行得非常快,不妨讓等待鎖的線程不要被阻塞,而是在 synchronized 的邊界做忙循環,這就是自旋。如果做了多次循環發現還沒有獲得鎖,再阻塞,這樣可能是一種更好的策略。
* 忙循環:就是程序員用循環讓一個線程等待,不像傳統方法wait(), sleep() 或 yield() 它們都放棄了CPU控制,而忙循環不會放棄CPU,它就是在運行一個空循環。這么做的目的是為了保留CPU緩存,在多核系統中,一個等待線程醒來的時候可能會在另一個內核運行,這樣會重建緩存。為了避免重建緩存和減少等待重建的時間就可以使用它了。
#### 多線程中 synchronized 鎖升級的原理是什么?
* synchronized 鎖升級原理:在鎖對象的對象頭里面有一個 threadid 字段,在第一次訪問的時候 threadid 為空,jvm 讓其持有偏向鎖,并將 threadid 設置為其線程 id,再次進入的時候會先判斷 threadid 是否與其線程 id 一致,如果一致則可以直接使用此對象,如果不一致,則升級偏向鎖為輕量級鎖,通過自旋循環一定次數來獲取鎖,執行一定次數之后,如果還沒有正常獲取到要使用的對象,此時就會把鎖從輕量級升級為重量級鎖,此過程就構成了 synchronized 鎖的升級。
`鎖的升級的目的:鎖升級是為了減低了鎖帶來的性能消耗。在 Java 6 之后優化 synchronized 的實現方式,使用了偏向鎖升級為輕量級鎖再升級到重量級鎖的方式,從而減低了鎖帶來的性能消耗。`
* 偏向鎖,顧名思義,它會偏向于第一個訪問鎖的線程,如果在運行過程中,同步鎖只有一個線程訪問,不存在多線程爭用的情況,則線程是不需要觸發同步的,減少加鎖/解鎖的一些CAS操作(比如等待隊列的一些CAS操作),這種情況下,就會給線程加一個偏向鎖。 如果在運行過程中,遇到了其他線程搶占鎖,則持有偏向鎖的線程會被掛起,JVM會消除它身上的偏向鎖,將鎖恢復到標準的輕量級鎖。
* 輕量級鎖是由偏向所升級來的,偏向鎖運行在一個線程進入同步塊的情況下,當第二個線程加入鎖爭用的時候,輕量級鎖就會升級為重量級鎖;
* 重量級鎖是synchronized ,是 Java 虛擬機中最為基礎的鎖實現。在這種狀態下,Java 虛擬機會阻塞加鎖失敗的線程,并且在目標鎖被釋放的時候,喚醒這些線程。
#### 線程 B 怎么知道線程 A 修改了變量
* (1)volatile 修飾變量
* (2)synchronized 修飾修改變量的方法
* (3)wait/notify
* (4)while 輪詢
#### 當一個線程進入一個對象的 synchronized 方法 A 之后,其它線程是否可進入此對象的 synchronized 方法 B?
* 不能。其它線程只能訪問該對象的非同步方法,同步方法則不能進入。因為非靜態方法上的 synchronized 修飾符要求執行方法時要獲得對象的鎖,如果已經進入A 方法說明對象鎖已經被取走,那么試圖進入 B 方法的線程就只能在等鎖池(注意不是等待池哦)中等待對象的鎖。
#### synchronized、volatile、CAS 比較
* (1)synchronized 是悲觀鎖,屬于搶占式,會引起其他線程阻塞。
* (2)volatile 提供多線程共享變量可見性和禁止指令重排序優化。
* (3)CAS 是基于沖突檢測的樂觀鎖(非阻塞)
#### synchronized 和 Lock 有什么區別?
* 首先synchronized是Java內置關鍵字,在JVM層面,Lock是個Java類;
* synchronized 可以給類、方法、代碼塊加鎖;而 lock 只能給代碼塊加鎖。
* synchronized 不需要手動獲取鎖和釋放鎖,使用簡單,發生異常會自動釋放鎖,不會造成死鎖;而 lock 需要自己加鎖和釋放鎖,如果使用不當沒有 unLock()去釋放鎖就會造成死鎖。
* 通過 Lock 可以知道有沒有成功獲取鎖,而 synchronized 卻無法辦到。
#### synchronized 和 ReentrantLock 區別是什么?
* synchronized 是和 if、else、for、while 一樣的關鍵字,ReentrantLock 是類,這是二者的本質區別。既然 ReentrantLock 是類,那么它就提供了比synchronized 更多更靈活的特性,可以被繼承、可以有方法、可以有各種各樣的類變量
* synchronized 早期的實現比較低效,對比 ReentrantLock,大多數場景性能都相差較大,但是在 Java 6 中對 synchronized 進行了非常多的改進。
* 相同點:兩者都是可重入鎖
兩者都是可重入鎖。“可重入鎖”概念是:自己可以再次獲取自己的內部鎖。比如一個線程獲得了某個對象的鎖,此時這個對象鎖還沒有釋放,當其再次想要獲取這個對象的鎖的時候還是可以獲取的,如果不可鎖重入的話,就會造成死鎖。同一個線程每次獲取鎖,鎖的計數器都自增1,所以要等到鎖的計數器下降為0時才能釋放鎖。
* 主要區別如下:
* ReentrantLock 使用起來比較靈活,但是必須有釋放鎖的配合動作;
* ReentrantLock 必須手動獲取與釋放鎖,而 synchronized 不需要手動釋放和開啟鎖;
* ReentrantLock 只適用于代碼塊鎖,而 synchronized 可以修飾類、方法、變量等。
* 二者的鎖機制其實也是不一樣的。ReentrantLock 底層調用的是 Unsafe 的park 方法加鎖,synchronized 操作的應該是對象頭中 mark word
* Java中每一個對象都可以作為鎖,這是synchronized實現同步的基礎:
* 普通同步方法,鎖是當前實例對象
* 靜態同步方法,鎖是當前類的class對象
* 同步方法塊,鎖是括號里面的對象
#### volatile 關鍵字的作用
* 對于可見性,Java 提供了 volatile 關鍵字來保證可見性和禁止指令重排。 volatile 提供 happens-before 的保證,確保一個線程的修改能對其他線程是可見的。當一個共享變量被 volatile 修飾時,它會保證修改的值會立即被更新到主內存中,當有其他線程需要讀取時,它會去內存中讀取新值。
* 從實踐角度而言,volatile 的一個重要作用就是和 CAS 結合,保證了原子性,詳細的可以參見 java.util.concurrent.atomic 包下的類,比如 AtomicInteger。
* volatile 常用于多線程環境下的單次操作(單次讀或者單次寫)。
#### Java 中能創建 volatile 數組嗎?
* 能,Java 中可以創建 volatile 類型數組,不過只是一個指向數組的引用,而不是整個數組。意思是,如果改變引用指向的數組,將會受到 volatile 的保護,但是如果多個線程同時改變數組的元素,volatile 標示符就不能起到之前的保護作用了。
#### volatile 變量和 atomic 變量有什么不同?
* volatile 變量可以確保先行關系,即寫操作會發生在后續的讀操作之前, 但它并不能保證原子性。例如用 volatile 修飾 count 變量,那么 count++ 操作就不是原子性的。
* 而 AtomicInteger 類提供的 atomic 方法可以讓這種操作具有原子性如getAndIncrement()方法會原子性的進行增量操作把當前值加一,其它數據類型和引用變量也可以進行相似操作。
#### volatile 能使得一個非原子操作變成原子操作嗎?
* 關鍵字volatile的主要作用是使變量在多個線程間可見,但無法保證原子性,對于多個線程訪問同一個實例變量需要加鎖進行同步。
* 雖然volatile只能保證可見性不能保證原子性,但用volatile修飾long和double可以保證其操作原子性。
**所以從Oracle Java Spec里面可以看到:**
* 對于64位的long和double,如果沒有被volatile修飾,那么對其操作可以不是原子的。在操作的時候,可以分成兩步,每次對32位操作。
* 如果使用volatile修飾long和double,那么其讀寫都是原子操作
* 對于64位的引用地址的讀寫,都是原子操作
* 在實現JVM時,可以自由選擇是否把讀寫long和double作為原子操作
* 推薦JVM實現為原子操作
#### synchronized 和 volatile 的區別是什么?
* synchronized 表示只有一個線程可以獲取作用對象的鎖,執行代碼,阻塞其他線程。
* volatile 表示變量在 CPU 的寄存器中是不確定的,必須從主存中讀取。保證多線程環境下變量的可見性;禁止指令重排序。
**區別**
* volatile 是變量修飾符;synchronized 可以修飾類、方法、變量。
* volatile 僅能實現變量的修改可見性,不能保證原子性;而 synchronized 則可以保證變量的修改可見性和原子性。
* volatile 不會造成線程的阻塞;synchronized 可能會造成線程的阻塞。
* volatile標記的變量不會被編譯器優化;synchronized標記的變量可以被編譯器優化。
* volatile關鍵字是線程同步的輕量級實現,所以volatile性能肯定比synchronized關鍵字要好。但是volatile關鍵字只能用于變量而synchronized關鍵字可以修飾方法以及代碼塊。synchronized關鍵字在JavaSE1.6之后進行了主要包括為了減少獲得鎖和釋放鎖帶來的性能消耗而引入的偏向鎖和輕量級鎖以及其它各種優化之后執行效率有了顯著提升,實際開發中使用 synchronized 關鍵字的場景還是更多一些。
#### final不可變對象,它對寫并發應用有什么幫助?
* 不可變對象(Immutable Objects)即對象一旦被創建它的狀態(對象的數據,也即對象屬性值)就不能改變,反之即為可變對象(Mutable Objects)。
* 不可變對象的類即為不可變類(Immutable Class)。Java 平臺類庫中包含許多不可變類,如 String、基本類型的包裝類、BigInteger 和 BigDecimal 等。
* 只有滿足如下狀態,一個對象才是不可變的;
* 它的狀態不能在創建后再被修改;
* 所有域都是 final 類型;并且,它被正確創建(創建期間沒有發生 this 引用的逸出)。
`不可變對象保證了對象的內存可見性,對不可變對象的讀取不需要進行額外的同步手段,提升了代碼執行效率。`
#### Lock 接口和synchronized 對比同步它有什么優勢?
* Lock 接口比同步方法和同步塊提供了更具擴展性的鎖操作。他們允許更靈活的結構,可以具有完全不同的性質,并且可以支持多個相關類的條件對象。
* 它的優勢有:
* (1)可以使鎖更公平
* (2)可以使線程在等待鎖的時候響應中斷
* (3)可以讓線程嘗試獲取鎖,并在無法獲取鎖的時候立即返回或者等待一段時間
* (4)可以在不同的范圍,以不同的順序獲取和釋放鎖
* 整體上來說 Lock 是 synchronized 的擴展版,Lock 提供了無條件的、可輪詢的(tryLock 方法)、定時的(tryLock 帶參方法)、可中斷的(lockInterruptibly)、可多條件隊列的(newCondition 方法)鎖操作。另外 Lock 的實現類基本都支持非公平鎖(默認)和公平鎖,synchronized 只支持非公平鎖,當然,在大部分情況下,非公平鎖是高效的選擇。
#### 樂觀鎖和悲觀鎖的理解及如何實現,有哪些實現方式?
* 悲觀鎖:總是假設最壞的情況,每次去拿數據的時候都認為別人會修改,所以每次在拿數據的時候都會上鎖,這樣別人想拿這個數據就會阻塞直到它拿到鎖。傳統的關系型數據庫里邊就用到了很多這種鎖機制,比如行鎖,表鎖等,讀鎖,寫鎖等,都是在做操作之前先上鎖。再比如 Java 里面的同步原語 synchronized 關鍵字的實現也是悲觀鎖。
* 樂觀鎖:顧名思義,就是很樂觀,每次去拿數據的時候都認為別人不會修改,所以不會上鎖,但是在更新的時候會判斷一下在此期間別人有沒有去更新這個數據,可以使用版本號等機制。樂觀鎖適用于多讀的應用類型,這樣可以提高吞吐量,像數據庫提供的類似于 write\_condition 機制,其實都是提供的樂觀鎖。在 Java中 java.util.concurrent.atomic 包下面的原子變量類就是使用了樂觀鎖的一種實現方式 CAS 實現的。
#### 什么是 CAS
* CAS 是 compare and swap 的縮寫,即我們所說的比較交換。
* cas 是一種基于鎖的操作,而且是樂觀鎖。在 java 中鎖分為樂觀鎖和悲觀鎖。悲觀鎖是將資源鎖住,等一個之前獲得鎖的線程釋放鎖之后,下一個線程才可以訪問。而樂觀鎖采取了一種寬泛的態度,通過某種方式不加鎖來處理資源,比如通過給記錄加 version 來獲取數據,性能較悲觀鎖有很大的提高。
* CAS 操作包含三個操作數 —— 內存位置(V)、預期原值(A)和新值(B)。如果內存地址里面的值和 A 的值是一樣的,那么就將內存里面的值更新成 B。CAS是通過無限循環來獲取數據的,若果在第一輪循環中,a 線程獲取地址里面的值被b 線程修改了,那么 a 線程需要自旋,到下次循環才有可能機會執行。
`java.util.concurrent.atomic 包下的類大多是使用 CAS 操作來實現的(AtomicInteger,AtomicBoolean,AtomicLong)`
#### CAS 的會產生什么問題?
* 1、ABA 問題:
比如說一個線程 one 從內存位置 V 中取出 A,這時候另一個線程 two 也從內存中取出 A,并且 two 進行了一些操作變成了 B,然后 two 又將 V 位置的數據變成 A,這時候線程 one 進行 CAS 操作發現內存中仍然是 A,然后 one 操作成功。盡管線程 one 的 CAS 操作成功,但可能存在潛藏的問題。從 Java1.5 開始 JDK 的 atomic包里提供了一個類 AtomicStampedReference 來解決 ABA 問題。
* 2、循環時間長開銷大:
對于資源競爭嚴重(線程沖突嚴重)的情況,CAS 自旋的概率會比較大,從而浪費更多的 CPU 資源,效率低于 synchronized。
* 3、只能保證一個共享變量的原子操作:
當對一個共享變量執行操作時,我們可以使用循環 CAS 的方式來保證原子操作,但是對多個共享變量操作時,循環 CAS 就無法保證操作的原子性,這個時候就可以用鎖。
#### 什么是原子類
* java.util.concurrent.atomic包:是原子類的小工具包,支持在單個變量上解除鎖的線程安全編程 原子變量類相當于一種泛化的 volatile 變量,能夠支持原子的和有條件的讀-改-寫操作。
* 比如:AtomicInteger 表示一個int類型的值,并提供了 get 和 set 方法,這些 Volatile 類型的int變量在讀取和寫入上有著相同的內存語義。它還提供了一個原子的 compareAndSet 方法(如果該方法成功執行,那么將實現與讀取/寫入一個 volatile 變量相同的內存效果),以及原子的添加、遞增和遞減等方法。AtomicInteger 表面上非常像一個擴展的 Counter 類,但在發生競爭的情況下能提供更高的可伸縮性,因為它直接利用了硬件對并發的支持。
`簡單來說就是原子類來實現CAS無鎖模式的算法`
#### 原子類的常用類
* AtomicBoolean
* AtomicInteger
* AtomicLong
* AtomicReference
#### 說一下 Atomic的原理?
* Atomic包中的類基本的特性就是在多線程環境下,當有多個線程同時對單個(包括基本類型及引用類型)變量進行操作時,具有排他性,即當多個線程同時對該變量的值進行更新時,僅有一個線程能成功,而未成功的線程可以向自旋鎖一樣,繼續嘗試,一直等到執行成功。
#### 死鎖與活鎖的區別,死鎖與饑餓的區別?
* 死鎖:是指兩個或兩個以上的進程(或線程)在執行過程中,因爭奪資源而造成的一種互相等待的現象,若無外力作用,它們都將無法推進下去。
* 活鎖:任務或者執行者沒有被阻塞,由于某些條件沒有滿足,導致一直重復嘗試,失敗,嘗試,失敗。
* 活鎖和死鎖的區別在于,處于活鎖的實體是在不斷的改變狀態,這就是所謂的“活”, 而處于死鎖的實體表現為等待;活鎖有可能自行解開,死鎖則不能。
* 饑餓:一個或者多個線程因為種種原因無法獲得所需要的資源,導致一直無法執行的狀態。
Java 中導致饑餓的原因:
* 1、高優先級線程吞噬所有的低優先級線程的 CPU 時間。
* 2、線程被永久堵塞在一個等待進入同步塊的狀態,因為其他線程總是能在它之前持續地對該同步塊進行訪問。
* 3、線程在等待一個本身也處于永久等待完成的對象(比如調用這個對象的 wait 方法),因為其他線程總是被持續地獲得喚醒。
## 線程池
#### 什么是線程池?
* Java中的線程池是運用場景最多的并發框架,幾乎所有需要異步或并發執行任務的程序都可以使用線程池。在開發過程中,合理地使用線程池能夠帶來許多好處。
* 降低資源消耗。通過重復利用已創建的線程降低線程創建和銷毀造成的消耗。
* 提高響應速度。當任務到達時,任務可以不需要等到線程創建就能立即執行。
* 提高線程的可管理性。線程是稀缺資源,如果無限制地創建,不僅會消耗系統資源,還會降低系統的穩定性,使用線程池可以進行統一分配、調優和監控。但是,要做到合理利用
#### 線程池作用?
* 線程池是為突然大量爆發的線程設計的,通過有限的幾個固定線程為大量的操作服務,減少了創建和銷毀線程所需的時間,從而提高效率。
* 如果一個線程所需要執行的時間非常長的話,就沒必要用線程池了(不是不能作長時間操作,而是不宜。本來降低線程創建和銷毀,結果你那么久我還不好控制還不如直接創建線程),況且我們還不能控制線程池中線程的開始、掛起、和中止。
#### 線程池有什么優點?
* 降低資源消耗:重用存在的線程,減少對象創建銷毀的開銷。
* 提高響應速度。可有效的控制最大并發線程數,提高系統資源的使用率,同時避免過多資源競爭,避免堵塞。當任務到達時,任務可以不需要的等到線程創建就能立即執行。
* 提高線程的可管理性。線程是稀缺資源,如果無限制的創建,不僅會消耗系統資源,還會降低系統的穩定性,使用線程池可以進行統一的分配,調優和監控。
* 附加功能:提供定時執行、定期執行、單線程、并發數控制等功能。
#### 什么是ThreadPoolExecutor?
* **ThreadPoolExecutor就是線程池**
ThreadPoolExecutor其實也是JAVA的一個類,我們一般通過Executors工廠類的方法,通過傳入不同的參數,就可以構造出適用于不同應用場景下的ThreadPoolExecutor(線程池)
構造參數圖:
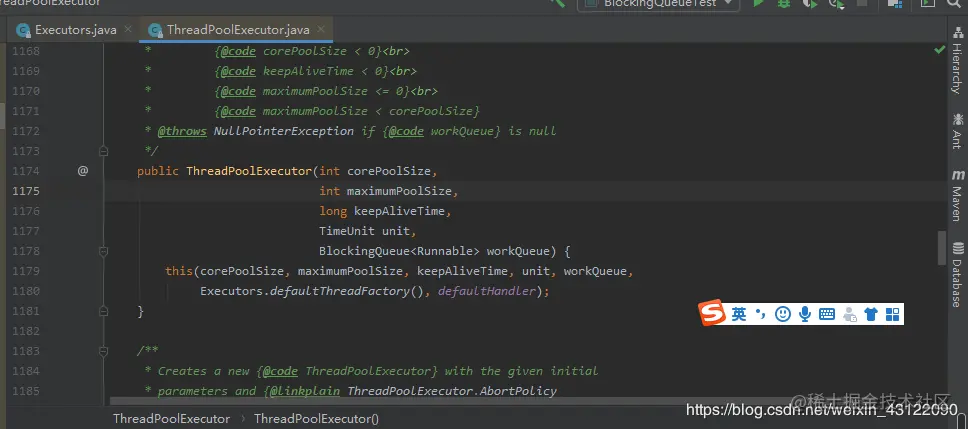
`構造參數參數介紹:`
~~~
corePoolSize 核心線程數量
maximumPoolSize 最大線程數量
keepAliveTime 線程保持時間,N個時間單位
unit 時間單位(比如秒,分)
workQueue 阻塞隊列
threadFactory 線程工廠
handler 線程池拒絕策略
復制代碼
~~~
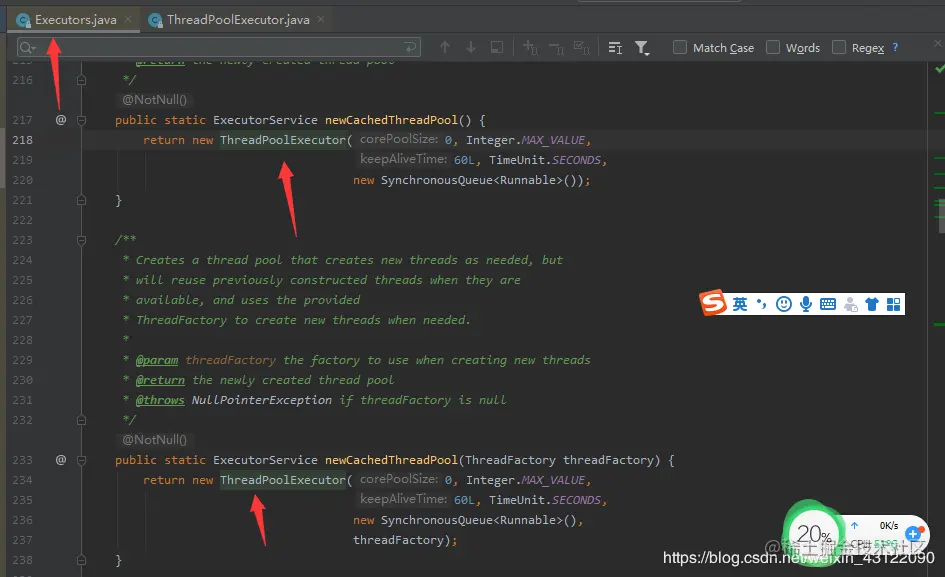
#### 什么是Executors?
* **Executors框架實現的就是線程池的功能。**
Executors工廠類中提供的newCachedThreadPool、newFixedThreadPool 、newScheduledThreadPool 、newSingleThreadExecutor 等方法其實也只是ThreadPoolExecutor的構造函數參數不同而已。通過傳入不同的參數,就可以構造出適用于不同應用場景下的線程池,
Executor工廠類如何創建線程池圖:
#### 線程池四種創建方式?
* **Java通過Executors(jdk1.5并發包)提供四種線程池,分別為:**
1. newCachedThreadPool創建一個可緩存線程池,如果線程池長度超過處理需要,可靈活回收空閑線程,若無可回收,則新建線程。
2. newFixedThreadPool 創建一個定長線程池,可控制線程最大并發數,超出的線程會在隊列中等待。
3. newScheduledThreadPool 創建一個定長線程池,支持定時及周期性任務執行。
4. newSingleThreadExecutor 創建一個單線程化的線程池,它只會用唯一的工作線程來執行任務,保證所有任務按照指定順序(FIFO, LIFO, 優先級)執行。
#### 在 Java 中 Executor 和 Executors 的區別?
* Executors 工具類的不同方法按照我們的需求創建了不同的線程池,來滿足業務的需求。
* Executor 接口對象能執行我們的線程任務。
* ExecutorService 接口繼承了 Executor 接口并進行了擴展,提供了更多的方法我們能獲得任務執行的狀態并且可以獲取任務的返回值。
* 使用 ThreadPoolExecutor 可以創建自定義線程池。
#### 四種構建線程池的區別及特點?
##### 1\. newCachedThreadPool
* **特點**:newCachedThreadPool創建一個可緩存線程池,如果當前線程池的長度超過了處理的需要時,它可以靈活的回收空閑的線程,當需要增加時, 它可以靈活的添加新的線程,而不會對池的長度作任何限制
* **缺點**:他雖然可以無線的新建線程,但是容易造成堆外內存溢出,因為它的最大值是在初始化的時候設置為 Integer.MAX\_VALUE,一般來說機器都沒那么大內存給它不斷使用。當然知道可能出問題的點,就可以去重寫一個方法限制一下這個最大值
* **總結**:線程池為無限大,當執行第二個任務時第一個任務已經完成,會復用執行第一個任務的線程,而不用每次新建線程。
* **代碼示例:**
~~~
package com.lijie;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestNewCachedThreadPool {
public static void main(String[] args) {
// 創建無限大小線程池,由jvm自動回收
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int temp = i;
newCachedThreadPool.execute(new Runnable() {
public void run() {
try {
Thread.sleep(100);
} catch (Exception e) {
}
System.out.println(Thread.currentThread().getName() + ",i==" + temp);
}
});
}
}
}
復制代碼
~~~
##### 2.newFixedThreadPool
* **特點**:創建一個定長線程池,可控制線程最大并發數,超出的線程會在隊列中等待。定長線程池的大小最好根據系統資源進行設置。
* **缺點**:線程數量是固定的,但是阻塞隊列是無界隊列。如果有很多請求積壓,阻塞隊列越來越長,容易導致OOM(超出內存空間)
* **總結**:請求的擠壓一定要和分配的線程池大小匹配,定線程池的大小最好根據系統資源進行設置。如Runtime.getRuntime().availableProcessors()
`Runtime.getRuntime().availableProcessors()方法是查看電腦CPU核心數量)`
* **代碼示例:**
~~~
package com.lijie;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestNewFixedThreadPool {
public static void main(String[] args) {
ExecutorService newFixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
final int temp = i;
newFixedThreadPool.execute(new Runnable() {
public void run() {
System.out.println(Thread.currentThread().getName() + ",i==" + temp);
}
});
}
}
}
復制代碼
~~~
##### 3.newScheduledThreadPool
* **特點**:創建一個固定長度的線程池,而且支持定時的以及周期性的任務執行,類似于Timer(Timer是Java的一個定時器類)
* **缺點**:由于所有任務都是由同一個線程來調度,因此所有任務都是串行執行的,同一時間只能有一個任務在執行,前一個任務的延遲或異常都將會影響到之后的任務(比如:一個任務出錯,以后的任務都無法繼續)。
* **代碼示例:**
~~~
package com.lijie;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class TestNewScheduledThreadPool {
public static void main(String[] args) {
//定義線程池大小為3
ScheduledExecutorService newScheduledThreadPool = Executors.newScheduledThreadPool(3);
for (int i = 0; i < 10; i++) {
final int temp = i;
newScheduledThreadPool.schedule(new Runnable() {
public void run() {
System.out.println("i:" + temp);
}
}, 3, TimeUnit.SECONDS);//這里表示延遲3秒執行。
}
}
}
復制代碼
~~~
##### 4.newSingleThreadExecutor
* **特點**:創建一個單線程化的線程池,它只會用唯一的工作線程來執行任務,如果這個唯一的線程因為異常結束,那么會有一個新的線程來替代它,他必須保證前一項任務執行完畢才能執行后一項。保證所有任務按照指定順序(FIFO, LIFO, 優先級)執行。
* **缺點**:缺點的話,很明顯,他是單線程的,高并發業務下有點無力
* **總結**:保證所有任務按照指定順序執行的,如果這個唯一的線程因為異常結束,那么會有一個新的線程來替代它
* **代碼示例:**
~~~
package com.lijie;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestNewSingleThreadExecutor {
public static void main(String[] args) {
ExecutorService newSingleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index = i;
newSingleThreadExecutor.execute(new Runnable() {
public void run() {
System.out.println(Thread.currentThread().getName() + " index:" + index);
try {
Thread.sleep(200);
} catch (Exception e) {
}
}
});
}
}
}
復制代碼
~~~
#### 線程池都有哪些狀態?
* RUNNING:這是最正常的狀態,接受新的任務,處理等待隊列中的任務。
* SHUTDOWN:不接受新的任務提交,但是會繼續處理等待隊列中的任務。
* STOP:不接受新的任務提交,不再處理等待隊列中的任務,中斷正在執行任務的線程。
* TIDYING:所有的任務都銷毀了,workCount 為 0,線程池的狀態在轉換為 TIDYING 狀態時,會執行鉤子方法 terminated()。
* TERMINATED:terminated()方法結束后,線程池的狀態就會變成這個。
#### 線程池中 submit() 和 execute() 方法有什么區別?
* 相同點:
* 相同點就是都可以開啟線程執行池中的任務。
* 不同點:
* 接收參數:execute()只能執行 Runnable 類型的任務。submit()可以執行 Runnable 和 Callable 類型的任務。
* 返回值:submit()方法可以返回持有計算結果的 Future 對象,而execute()沒有
* 異常處理:submit()方便Exception處理
#### 什么是線程組,為什么在 Java 中不推薦使用?
* ThreadGroup 類,可以把線程歸屬到某一個線程組中,線程組中可以有線程對象,也可以有線程組,組中還可以有線程,這樣的組織結構有點類似于樹的形式。
* 線程組和線程池是兩個不同的概念,他們的作用完全不同,前者是為了方便線程的管理,后者是為了管理線程的生命周期,復用線程,減少創建銷毀線程的開銷。
* 為什么不推薦使用線程組?因為使用有很多的安全隱患吧,沒有具體追究,如果需要使用,推薦使用線程池。
#### ThreadPoolExecutor飽和策略有哪些?
`如果當前同時運行的線程數量達到最大線程數量并且隊列也已經被放滿了任時,ThreadPoolTaskExecutor 定義一些策略:`
* ThreadPoolExecutor.AbortPolicy:拋出 RejectedExecutionException來拒絕新任務的處理。
* ThreadPoolExecutor.CallerRunsPolicy:調用執行自己的線程運行任務。您不會任務請求。但是這種策略會降低對于新任務提交速度,影響程序的整體性能。另外,這個策略喜歡增加隊列容量。如果您的應用程序可以承受此延遲并且你不能任務丟棄任何一個任務請求的話,你可以選擇這個策略。
* ThreadPoolExecutor.DiscardPolicy:不處理新任務,直接丟棄掉。
* ThreadPoolExecutor.DiscardOldestPolicy: 此策略將丟棄最早的未處理的任務請求。
#### 如何自定義線程線程池?
* 先看ThreadPoolExecutor(線程池)這個類的構造參數
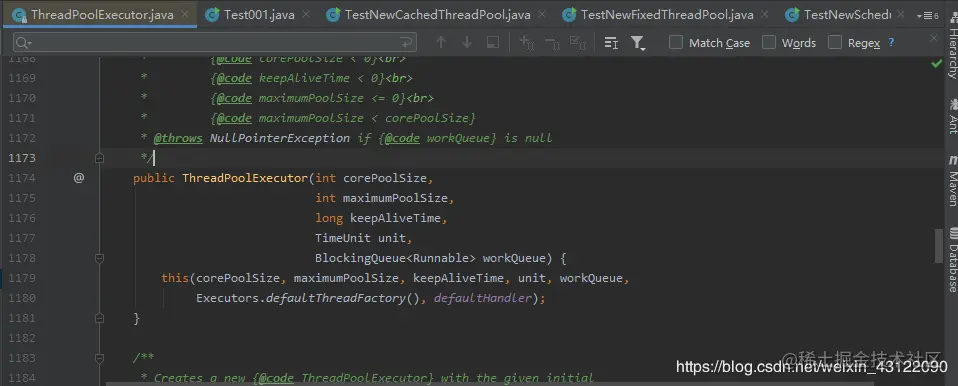
構造參數參數介紹:
~~~
corePoolSize 核心線程數量
maximumPoolSize 最大線程數量
keepAliveTime 線程保持時間,N個時間單位
unit 時間單位(比如秒,分)
workQueue 阻塞隊列
threadFactory 線程工廠
handler 線程池拒絕策略
復制代碼
~~~
* 代碼示例:
~~~
package com.lijie;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class Test001 {
public static void main(String[] args) {
//創建線程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 2, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<>(3));
for (int i = 1; i <= 6; i++) {
TaskThred t1 = new TaskThred("任務" + i);
//executor.execute(t1);是執行線程方法
executor.execute(t1);
}
//executor.shutdown()不再接受新的任務,并且等待之前提交的任務都執行完再關閉,阻塞隊列中的任務不會再執行。
executor.shutdown();
}
}
class TaskThred implements Runnable {
private String taskName;
public TaskThred(String taskName) {
this.taskName = taskName;
}
public void run() {
System.out.println(Thread.currentThread().getName() + taskName);
}
}
復制代碼
~~~
#### 線程池的執行原理?
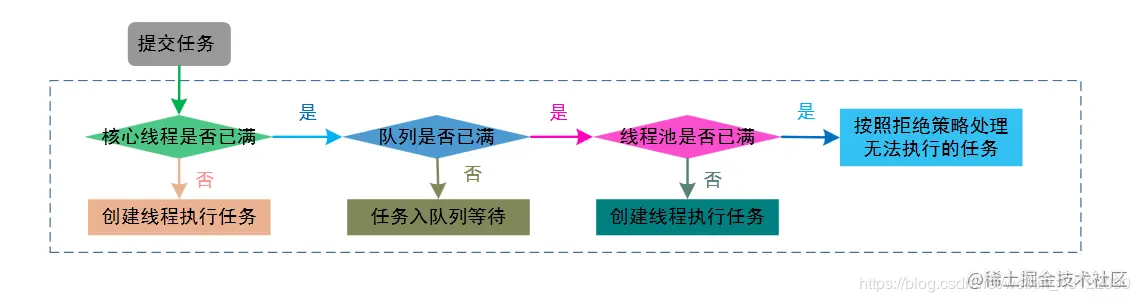
* 提交一個任務到線程池中,線程池的處理流程如下:
1. 判斷線程池里的核心線程是否都在執行任務,如果不是(核心線程空閑或者還有核心線程沒有被創建)則創建一個新的工作線程來執行任務。如果核心線程都在執行任務,則進入下個流程。
2. 線程池判斷工作隊列是否已滿,如果工作隊列沒有滿,則將新提交的任務存儲在這個工作隊列里。如果工作隊列滿了,則進入下個流程。
3. 判斷線程池里的線程是否都處于工作狀態,如果沒有,則創建一個新的工作線程來執行任務。如果已經滿了,則交給飽和策略來處理這個任務。
#### 如何合理分配線程池大小?
* 要合理的分配線程池的大小要根據實際情況來定,簡單的來說的話就是根據CPU密集和IO密集來分配
##### 什么是CPU密集
* CPU密集的意思是該任務需要大量的運算,而沒有阻塞,CPU一直全速運行。
* CPU密集任務只有在真正的多核CPU上才可能得到加速(通過多線程),而在單核CPU上,無論你開幾個模擬的多線程,該任務都不可能得到加速,因為CPU總的運算能力就那樣。
##### 什么是IO密集
* IO密集型,即該任務需要大量的IO,即大量的阻塞。在單線程上運行IO密集型的任務會導致浪費大量的CPU運算能力浪費在等待。所以在IO密集型任務中使用多線程可以大大的加速程序運行,即時在單核CPU上,這種加速主要就是利用了被浪費掉的阻塞時間。
##### 分配CPU和IO密集:
1. CPU密集型時,任務可以少配置線程數,大概和機器的cpu核數相當,這樣可以使得每個線程都在執行任務
2. IO密集型時,大部分線程都阻塞,故需要多配置線程數,2\*cpu核數
##### 精確來說的話的話:
* 從以下幾個角度分析任務的特性:
* 任務的性質:CPU密集型任務、IO密集型任務、混合型任務。
* 任務的優先級:高、中、低。
* 任務的執行時間:長、中、短。
* 任務的依賴性:是否依賴其他系統資源,如數據庫連接等。
**可以得出一個結論:**
* 線程等待時間比CPU執行時間比例越高,需要越多線程。
* 線程CPU執行時間比等待時間比例越高,需要越少線程。
## 并發容器
#### 你經常使用什么并發容器,為什么?
* 答:Vector、ConcurrentHashMap、HasTable
* 一般軟件開發中容器用的最多的就是HashMap、ArrayList,LinkedList ,等等
* 但是在多線程開發中就不能亂用容器,如果使用了未加鎖(非同步)的的集合,你的數據就會非常的混亂。由此在多線程開發中需要使用的容器必須是加鎖(同步)的容器。
#### 什么是Vector
* Vector與ArrayList一樣,也是通過數組實現的,不同的是它支持線程的同步,即某一時刻只有一個線程能夠寫Vector,避免多線程同時寫而引起的不一致性,但實現同步需要很高的花費,訪問它比訪問ArrayList慢很多
(`ArrayList是最常用的List實現類,內部是通過數組實現的,它允許對元素進行快速隨機訪問。當從ArrayList的中間位置插入或者刪除元素時,需要對數組進行復制、移動、代價比較高。因此,它適合隨機查找和遍歷,不適合插入和刪除。ArrayList的缺點是每個元素之間不能有間隔。`)
#### ArrayList和Vector有什么不同之處?
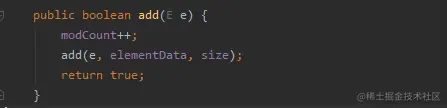
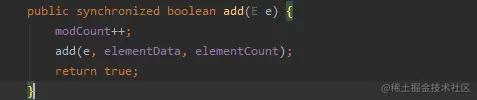
* Vector方法帶上了synchronized關鍵字,是線程同步的
1. ArrayList添加方法源碼
2. Vector添加源碼(加鎖了synchronized關鍵字)
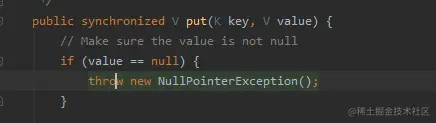
#### 為什么HashTable是線程安全的?
* 因為HasTable的內部方法都被synchronized修飾了,所以是線程安全的。其他的都和HashMap一樣
4. HashMap添加方法的源碼

5. HashTable添加方法的源碼
#### 用過ConcurrentHashMap,講一下他和HashTable的不同之處?
* ConcurrentHashMap是Java5中支持高并發、高吞吐量的線程安全HashMap實現。它由Segment數組結構和HashEntry數組結構組成。Segment數組在ConcurrentHashMap里扮演鎖的角色,HashEntry則用于存儲鍵-值對數據。一個ConcurrentHashMap里包含一個Segment數組,Segment的結構和HashMap類似,是一種數組和鏈表結構;一個Segment里包含一個HashEntry數組,每個HashEntry是一個鏈表結構的元素;每個Segment守護著一個HashEntry數組里的元素,當對HashEntry數組的數據進行修改時,必須首先獲得它對應的Segment鎖。
* 看不懂???很正常,我也看不懂
* 總結:
1. HashTable就是實現了HashMap加上了synchronized,而ConcurrentHashMap底層采用分段的數組+鏈表實現,線程安全
2. ConcurrentHashMap通過把整個Map分為N個Segment,可以提供相同的線程安全,但是效率提升N倍,默認提升16倍。
3. 并且讀操作不加鎖,由于HashEntry的value變量是 volatile的,也能保證讀取到最新的值。
4. Hashtable的synchronized是針對整張Hash表的,即每次鎖住整張表讓線程獨占,ConcurrentHashMap允許多個修改操作并發進行,其關鍵在于使用了鎖分離技術
5. 擴容:段內擴容(段內元素超過該段對應Entry數組長度的75%觸發擴容,不會對整個Map進行擴容),插入前檢測需不需要擴容,有效避免無效擴容
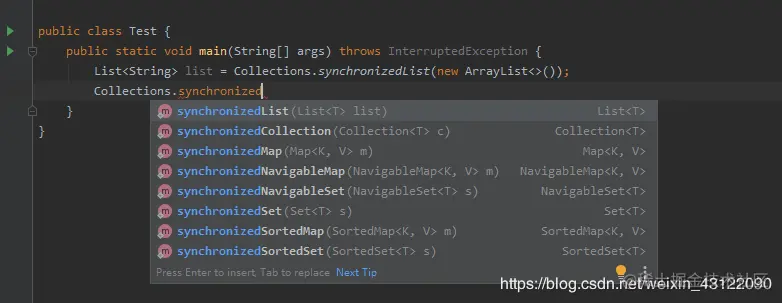
#### Collections.synchronized \* 是什么?
`注意:* 號代表后面是還有內容的`
* 此方法是干什么的呢,他完完全全的可以把List、Map、Set接口底下的集合變成線程安全的集合
* Collections.synchronized \* :原理是什么,我猜的話是代理模式:[Java代理模式理解](https://link.juejin.cn?target=https%3A%2F%2Fblog.csdn.net%2Fweixin_43122090%2Farticle%2Fdetails%2F104883274 "https://blog.csdn.net/weixin_43122090/article/details/104883274")
#### Java 中 ConcurrentHashMap 的并發度是什么?
* ConcurrentHashMap 把實際 map 劃分成若干部分來實現它的可擴展性和線程安全。這種劃分是使用并發度獲得的,它是 ConcurrentHashMap 類構造函數的一個可選參數,默認值為 16,這樣在多線程情況下就能避免爭用。
* 在 JDK8 后,它摒棄了 Segment(鎖段)的概念,而是啟用了一種全新的方式實現,利用 CAS 算法。同時加入了更多的輔助變量來提高并發度,具體內容還是查看源碼吧。
#### 什么是并發容器的實現?
* 何為同步容器:可以簡單地理解為通過 synchronized 來實現同步的容器,如果有多個線程調用同步容器的方法,它們將會串行執行。比如 Vector,Hashtable,以及 Collections.synchronizedSet,synchronizedList 等方法返回的容器。可以通過查看 Vector,Hashtable 等這些同步容器的實現代碼,可以看到這些容器實現線程安全的方式就是將它們的狀態封裝起來,并在需要同步的方法上加上關鍵字 synchronized。
* 并發容器使用了與同步容器完全不同的加鎖策略來提供更高的并發性和伸縮性,例如在 ConcurrentHashMap 中采用了一種粒度更細的加鎖機制,可以稱為分段鎖,在這種鎖機制下,允許任意數量的讀線程并發地訪問 map,并且執行讀操作的線程和寫操作的線程也可以并發的訪問 map,同時允許一定數量的寫操作線程并發地修改 map,所以它可以在并發環境下實現更高的吞吐量。
#### Java 中的同步集合與并發集合有什么區別?
* 同步集合與并發集合都為多線程和并發提供了合適的線程安全的集合,不過并發集合的可擴展性更高。在 Java1.5 之前程序員們只有同步集合來用且在多線程并發的時候會導致爭用,阻礙了系統的擴展性。Java5 介紹了并發集合像ConcurrentHashMap,不僅提供線程安全還用鎖分離和內部分區等現代技術提高了可擴展性。
#### SynchronizedMap 和 ConcurrentHashMap 有什么區別?
* SynchronizedMap 一次鎖住整張表來保證線程安全,所以每次只能有一個線程來訪為 map。
* ConcurrentHashMap 使用分段鎖來保證在多線程下的性能。
* ConcurrentHashMap 中則是一次鎖住一個桶。ConcurrentHashMap 默認將hash 表分為 16 個桶,諸如 get,put,remove 等常用操作只鎖當前需要用到的桶。
* 這樣,原來只能一個線程進入,現在卻能同時有 16 個寫線程執行,并發性能的提升是顯而易見的。
* 另外 ConcurrentHashMap 使用了一種不同的迭代方式。在這種迭代方式中,當iterator 被創建后集合再發生改變就不再是拋出ConcurrentModificationException,取而代之的是在改變時 new 新的數據從而不影響原有的數據,iterator 完成后再將頭指針替換為新的數據 ,這樣 iterator線程可以使用原來老的數據,而寫線程也可以并發的完成改變。
#### CopyOnWriteArrayList 是什么?
* CopyOnWriteArrayList 是一個并發容器。有很多人稱它是線程安全的,我認為這句話不嚴謹,缺少一個前提條件,那就是非復合場景下操作它是線程安全的。
* CopyOnWriteArrayList(免鎖容器)的好處之一是當多個迭代器同時遍歷和修改這個列表時,不會拋出 ConcurrentModificationException。在CopyOnWriteArrayList 中,寫入將導致創建整個底層數組的副本,而源數組將保留在原地,使得復制的數組在被修改時,讀取操作可以安全地執行。
#### CopyOnWriteArrayList 的使用場景?
* 合適讀多寫少的場景。
#### CopyOnWriteArrayList 的缺點?
* 由于寫操作的時候,需要拷貝數組,會消耗內存,如果原數組的內容比較多的情況下,可能導致 young gc 或者 full gc。
* 不能用于實時讀的場景,像拷貝數組、新增元素都需要時間,所以調用一個 set 操作后,讀取到數據可能還是舊的,雖然CopyOnWriteArrayList 能做到最終一致性,但是還是沒法滿足實時性要求。
* 由于實際使用中可能沒法保證 CopyOnWriteArrayList 到底要放置多少數據,萬一數據稍微有點多,每次 add/set 都要重新復制數組,這個代價實在太高昂了。在高性能的互聯網應用中,這種操作分分鐘引起故障。
#### CopyOnWriteArrayList 的設計思想?
* 讀寫分離,讀和寫分開
* 最終一致性
* 使用另外開辟空間的思路,來解決并發沖突
## 并發隊列
#### 什么是并發隊列:
* 消息隊列很多人知道:消息隊列是分布式系統中重要的組件,是系統與系統直接的通信
* 并發隊列是什么:并發隊列多個線程以有次序共享數據的重要組件
#### 并發隊列和并發集合的區別:
`那就有可能要說了,我們并發集合不是也可以實現多線程之間的數據共享嗎,其實也是有區別的:`
* 隊列遵循“先進先出”的規則,可以想象成排隊檢票,隊列一般用來解決大數據量采集處理和顯示的。
* 并發集合就是在多個線程中共享數據的
#### 怎么判斷并發隊列是阻塞隊列還是非阻塞隊列
* 在并發隊列上JDK提供了Queue接口,一個是以Queue接口下的BlockingQueue接口為代表的阻塞隊列,另一個是高性能(無堵塞)隊列。
#### 阻塞隊列和非阻塞隊列區別
* 當隊列阻塞隊列為空的時,從隊列中獲取元素的操作將會被阻塞。
* 或者當阻塞隊列是滿時,往隊列里添加元素的操作會被阻塞。
* 或者試圖從空的阻塞隊列中獲取元素的線程將會被阻塞,直到其他的線程往空的隊列插入新的元素。
* 試圖往已滿的阻塞隊列中添加新元素的線程同樣也會被阻塞,直到其他的線程使隊列重新變得空閑起來
#### 常用并發列隊的介紹:
1. **非堵塞隊列:**
1. **ArrayDeque, (數組雙端隊列)**
ArrayDeque (非堵塞隊列)是JDK容器中的一個雙端隊列實現,內部使用數組進行元素存儲,不允許存儲null值,可以高效的進行元素查找和尾部插入取出,是用作隊列、雙端隊列、棧的絕佳選擇,性能比LinkedList還要好。
2. **PriorityQueue, (優先級隊列)**
PriorityQueue (非堵塞隊列) 一個基于優先級的無界優先級隊列。優先級隊列的元素按照其自然順序進行排序,或者根據構造隊列時提供的 Comparator 進行排序,具體取決于所使用的構造方法。該隊列不允許使用 null 元素也不允許插入不可比較的對象
3. **ConcurrentLinkedQueue, (基于鏈表的并發隊列)**
ConcurrentLinkedQueue (非堵塞隊列): 是一個適用于高并發場景下的隊列,通過無鎖的方式,實現了高并發狀態下的高性能。ConcurrentLinkedQueue的性能要好于BlockingQueue接口,它是一個基于鏈接節點的無界線程安全隊列。該隊列的元素遵循先進先出的原則。該隊列不允許null元素。
2. **堵塞隊列:**
1. **DelayQueue, (基于時間優先級的隊列,延期阻塞隊列)**
DelayQueue是一個沒有邊界BlockingQueue實現,加入其中的元素必需實現Delayed接口。當生產者線程調用put之類的方法加入元素時,會觸發Delayed接口中的compareTo方法進行排序,也就是說隊列中元素的順序是按到期時間排序的,而非它們進入隊列的順序。排在隊列頭部的元素是最早到期的,越往后到期時間赿晚。
2. **ArrayBlockingQueue, (基于數組的并發阻塞隊列)**
ArrayBlockingQueue是一個有邊界的阻塞隊列,它的內部實現是一個數組。有邊界的意思是它的容量是有限的,我們必須在其初始化的時候指定它的容量大小,容量大小一旦指定就不可改變。ArrayBlockingQueue是以先進先出的方式存儲數據
3. **LinkedBlockingQueue, (基于鏈表的FIFO阻塞隊列)**
LinkedBlockingQueue阻塞隊列大小的配置是可選的,如果我們初始化時指定一個大小,它就是有邊界的,如果不指定,它就是無邊界的。說是無邊界,其實是采用了默認大小為Integer.MAX\_VALUE的容量 。它的內部實現是一個鏈表。
4. **LinkedBlockingDeque, (基于鏈表的FIFO雙端阻塞隊列)**
LinkedBlockingDeque是一個由鏈表結構組成的雙向阻塞隊列,即可以從隊列的兩端插入和移除元素。雙向隊列因為多了一個操作隊列的入口,在多線程同時入隊時,也就減少了一半的競爭。
相比于其他阻塞隊列,LinkedBlockingDeque多了addFirst、addLast、peekFirst、peekLast等方法,以first結尾的方法,表示插入、獲取獲移除雙端隊列的第一個元素。以last結尾的方法,表示插入、獲取獲移除雙端隊列的最后一個元素。
LinkedBlockingDeque是可選容量的,在初始化時可以設置容量防止其過度膨脹,如果不設置,默認容量大小為Integer.MAX\_VALUE。
5. **PriorityBlockingQueue, (帶優先級的無界阻塞隊列)**
priorityBlockingQueue是一個無界隊列,它沒有限制,在內存允許的情況下可以無限添加元素;它又是具有優先級的隊列,是通過構造函數傳入的對象來判斷,傳入的對象必須實現comparable接口。
6. **SynchronousQueue (并發同步阻塞隊列)**
SynchronousQueue是一個內部只能包含一個元素的隊列。插入元素到隊列的線程被阻塞,直到另一個線程從隊列中獲取了隊列中存儲的元素。同樣,如果線程嘗試獲取元素并且當前不存在任何元素,則該線程將被阻塞,直到線程將元素插入隊列。
將這個類稱為隊列有點夸大其詞。這更像是一個點。
#### 并發隊列的常用方法
`不管是那種列隊,是那個類,當是他們使用的方法都是差不多的`
| 方法名 | 描述 |
| --- | --- |
| add() | 在不超出隊列長度的情況下插入元素,可以立即執行,成功返回true,如果隊列滿了就拋出異常。 |
| offer() | 在不超出隊列長度的情況下插入元素的時候則可以立即在隊列的尾部插入指定元素,成功時返回true,如果此隊列已滿,則返回false。 |
| put() | 插入元素的時候,如果隊列滿了就進行等待,直到隊列可用。 |
| take() | 從隊列中獲取值,如果隊列中沒有值,線程會一直阻塞,直到隊列中有值,并且該方法取得了該值。 |
| poll(long timeout, TimeUnit unit) | 在給定的時間里,從隊列中獲取值,如果沒有取到會拋出異常。 |
| remainingCapacity() | 獲取隊列中剩余的空間。 |
| remove(Object o) | 從隊列中移除指定的值。 |
| contains(Object o) | 判斷隊列中是否擁有該值。 |
| drainTo(Collection c) | 將隊列中值,全部移除,并發設置到給定的集合中。 |
## 并發工具類
#### 常用的并發工具類有哪些?
* CountDownLatch
CountDownLatch 類位于java.util.concurrent包下,利用它可以實現類似計數器的功能。比如有一個任務A,它要等待其他3個任務執行完畢之后才能執行,此時就可以利用CountDownLatch來實現這種功能了。
* CyclicBarrier (回環柵欄) CyclicBarrier它的作用就是會讓所有線程都等待完成后才會繼續下一步行動。
CyclicBarrier初始化時規定一個數目,然后計算調用了CyclicBarrier.await()進入等待的線程數。當線程數達到了這個數目時,所有進入等待狀態的線程被喚醒并繼續。
CyclicBarrier初始時還可帶一個Runnable的參數, 此Runnable任務在CyclicBarrier的數目達到后,所有其它線程被喚醒前被執行。
* Semaphore (信號量) Semaphore 是 synchronized 的加強版,作用是控制線程的并發數量(允許自定義多少線程同時訪問)。就這一點而言,單純的synchronized 關鍵字是實現不了的。
Semaphore是一種基于計數的信號量。它可以設定一個閾值,基于此,多個線程競爭獲取許可信號,做自己的申請后歸還,超過閾值后,線程申請許可信號將會被阻塞。Semaphore可以用來構建一些對象池,資源池之類的,比如數據庫連接池,我們也可以創建計數為1的Semaphore,將其作為一種類似互斥鎖的機制,這也叫二元信號量,表示兩種互斥狀態。
作者:小杰要吃蛋
鏈接:https://juejin.cn/post/6844904125755293710
來源:稀土掘金
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。
- 常見面試題
- 一.Java常見面試題
- 1.Java基礎
- 3.面向對象概念
- 10.Java面試題
- Java基礎知識面試題(總結最全面的面試題)
- 設計模式面試題(總結最全面的面試題)
- Java集合面試題(總結最全面的面試題)
- JavaIO、BIO、NIO、AIO、Netty面試題(總結最全面的面試題)
- Java并發編程面試題(總結最全面的面試題)
- Java異常面試題(總結最全面的面試題)
- Java虛擬機(JVM)面試題(總結最全面的面試題)
- Spring面試題(總結最全面的面試題)
- Spring MVC面試題(總結最全面的面試題)
- Spring Boot面試題(總結最全面的面試題)
- Spring Cloud面試題(總結最全面的面試題)
- Redis面試題(總結最全面的面試題)
- MyBatis面試題(總結最全面的面試題)
- TCP、UDP、Socket、HTTP面試題(總結最全面的面試題)
- 二、MySQL面試題
- 1.基礎部分
- MySQL面試題(總結最全面的面試題)
- HBase相關面試題整理
- Nginx面試題(總結最全面的面試題)
- RabbitMQ面試題(總結最全面的面試題)
- Dubbo面試題(總結最全面的面試題)
- ZooKeeper面試題(總結最全面的面試題)
- Tomcat面試題(總結最全面的面試題)
- Linux面試題(總結最全面的面試題)
- 超詳細的Django面試題
- SSM面試題
- 15個高頻微信小程序面試題
- VUE面試題
- Python面試題
- 二、常見問題解答列表
- 1.查看端口及殺死進程
- 三、學習電子書