# 3 處理原始文本
文本的最重要來源無疑是網絡。探索現成的文本集合,如我們在前面章節中看到的語料庫,是很方便的。然而,在你心中可能有你自己的文本來源,需要學習如何訪問它們。
本章的目的是要回答下列問題:
1. 我們怎樣才能編寫程序訪問本地和網絡上的文件,從而獲得無限的語言材料?
2. 我們如何把文檔分割成單獨的詞和標點符號,這樣我們就可以開始像前面章節中在文本語料上做的那樣的分析?
3. 我們怎樣編程程序產生格式化的輸出,并把結果保存在一個文件中?
為了解決這些問題,我們將講述 NLP 中的關鍵概念,包括分詞和詞干提取。在此過程中,你會鞏固你的 Python 知識并且了解關于字符串、文件和正則表達式知識。既然這些網絡上的文本都是 HTML 格式的,我們也將看到如何去除 HTML 標記。
注意
**重點:** 從本章開始往后我們的例子程序將假設你以下面的導入語句開始你的交互式會話或程序:
```py
>>> from __future__ import division # Python 2 users only
>>> import nltk, re, pprint
>>> from nltk import word_tokenize
```
## 3.1 從網絡和硬盤訪問文本
### 電子書
NLTK 語料庫集合中有古騰堡項目的一小部分樣例文本。然而,你可能對分析古騰堡項目的其它文本感興趣。你可以在`http://www.gutenberg.org/catalog/`上瀏覽 25,000 本免費在線書籍的目錄,獲得 ASCII 碼文本文件的 URL。雖然 90%的古騰堡項目的文本是英語的,它還包括超過 50 種語言的材料,包括加泰羅尼亞語、中文、荷蘭語、芬蘭語、法語、德語、意大利語、葡萄牙語和西班牙語(每種語言都有超過 100 個文本)。
編號 2554 的文本是 _《罪與罰》_ 的英文翻譯,我們可以如下方式訪問它。
```py
>>> from urllib import request
>>> url = "http://www.gutenberg.org/files/2554/2554.txt"
>>> response = request.urlopen(url)
>>> raw = response.read().decode('utf8')
>>> type(raw)
<class 'str'>
>>> len(raw)
1176893
>>> raw[:75]
'The Project Gutenberg EBook of Crime and Punishment, by Fyodor Dostoevsky\r\n'
```
注意
`read()`過程將需要幾秒鐘來下載這本大書。如果你使用的 Internet 代理 Python 不能正確檢測出來,你可能需要在使用`urlopen`之前用下面的方法手動指定代理:
```py
>>> proxies = {'http': 'http://www.someproxy.com:3128'}
>>> request.ProxyHandler(proxies)
```
變量`raw`包含一個有 1,176,893 個字符的字符串。(我們使用`type(raw)`可以看到它是一個字符串。)這是這本書原始的內容,包括很多我們不感興趣的細節,如空格、換行符和空行。請注意,文件中行尾的`\r`和`\n`,這是 Python 用來顯示特殊的回車和換行字符的方式(這個文件一定是在 Windows 機器上創建的)。對于語言處理,我們要將字符串分解為詞和標點符號,正如我們在[1.](./ch01.html#chap-introduction)中所看到的。這一步被稱為分詞,它產生我們所熟悉的結構,一個詞匯和標點符號的列表。
```py
>>> tokens = word_tokenize(raw)
>>> type(tokens)
<class 'list'>
>>> len(tokens)
254354
>>> tokens[:10]
['The', 'Project', 'Gutenberg', 'EBook', 'of', 'Crime', 'and', 'Punishment', ',', 'by']
```
請注意,分詞需要 NLTK,但所有前面的打開一個 URL 以及讀入一個字符串的任務都不需要。如果我們現在采取進一步的步驟從這個列表創建一個 NLTK 文本,我們可以進行我們在[1.](./ch01.html#chap-introduction)中看到的所有的其他語言的處理,也包括常規的列表操作例如切片:
```py
>>> text = nltk.Text(tokens)
>>> type(text)
<class 'nltk.text.Text'>
>>> text[1024:1062]
['CHAPTER', 'I', 'On', 'an', 'exceptionally', 'hot', 'evening', 'early', 'in',
'July', 'a', 'young', 'man', 'came', 'out', 'of', 'the', 'garret', 'in',
'which', 'he', 'lodged', 'in', 'S.', 'Place', 'and', 'walked', 'slowly',
',', 'as', 'though', 'in', 'hesitation', ',', 'towards', 'K.', 'bridge', '.']
>>> text.collocations()
Katerina Ivanovna; Pyotr Petrovitch; Pulcheria Alexandrovna; Avdotya
Romanovna; Rodion Romanovitch; Marfa Petrovna; Sofya Semyonovna; old
woman; Project Gutenberg-tm; Porfiry Petrovitch; Amalia Ivanovna;
great deal; Nikodim Fomitch; young man; Ilya Petrovitch; n't know;
Project Gutenberg; Dmitri Prokofitch; Andrey Semyonovitch; Hay Market
```
請注意,Project Gutenberg 以一個搭配出現。這是因為從古騰堡項目下載的每個文本都包含一個首部,里面有文本的名稱、作者、掃描和校對文本的人的名字、許可證等信息。有時這些信息出現在文件末尾頁腳處。我們不能可靠地檢測出文本內容的開始和結束,因此在從`原始`文本中挑出正確內容且沒有其它內容之前,我們需要手工檢查文件以發現標記內容開始和結尾的獨特的字符串:
```py
>>> raw.find("PART I")
5338
>>> raw.rfind("End of Project Gutenberg's Crime")
1157743
>>> raw = raw[5338:1157743] ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> raw.find("PART I")
0
```
方法`find()`和`rfind()`(反向的 find)幫助我們得到字符串切片需要用到的正確的索引值[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch03.html#raw-slice)。我們用這個切片重新給`raw`賦值,所以現在它以“PART I”開始一直到(但不包括)標記內容結尾的句子。
這是我們第一次接觸到網絡的實際內容:在網絡上找到的文本可能含有不必要的內容,并沒有一個自動的方法來去除它。但只需要少量的額外工作,我們就可以提取出我們需要的材料。
### 處理 HTML
網絡上的文本大部分是 HTML 文件的形式。你可以使用網絡瀏覽器將網頁作為文本保存為本地文件,然后按照下面關于文件的小節描述的那樣來訪問它。不過,如果你要經常這樣做,最簡單的辦法是直接讓 Python 來做這份工作。第一步是像以前一樣使用`urlopen`。為了好玩,我們將挑選一個被稱為 _Blondes to die out in 200 years_ 的 BBC 新聞故事,一個都市傳奇被 BBC 作為確立的科學事實流傳下來:
```py
>>> url = "http://news.bbc.co.uk/2/hi/health/2284783.stm"
>>> html = request.urlopen(url).read().decode('utf8')
>>> html[:60]
'<!doctype html public "-//W3C//DTD HTML 4.0 Transitional//EN'
```
你可以輸入`print(html)`來查看 HTML 的全部內容,包括 meta 元標簽、圖像標簽、map 標簽、JavaScript、表單和表格。
要得到 HTML 的文本,我們將使用一個名為 _BeautifulSoup_ 的 Python 庫,可從 `http://www.crummy.com/software/BeautifulSoup/` 訪問︰
```py
>>> from bs4 import BeautifulSoup
>>> raw = BeautifulSoup(html).get_text()
>>> tokens = word_tokenize(raw)
>>> tokens
['BBC', 'NEWS', '|', 'Health', '|', 'Blondes', "'to", 'die', 'out', ...]
```
它仍然含有不需要的內容,包括網站導航及有關報道等。通過一些嘗試和出錯你可以找到內容索引的開始和結尾,并選擇你感興趣的詞符,按照前面講的那樣初始化一個文本。
```py
>>> tokens = tokens[110:390]
>>> text = nltk.Text(tokens)
>>> text.concordance('gene')
Displaying 5 of 5 matches:
hey say too few people now carry the gene for blondes to last beyond the next
blonde hair is caused by a recessive gene . In order for a child to have blond
have blonde hair , it must have the gene on both sides of the family in the g
ere is a disadvantage of having that gene or by chance . They do n't disappear
des would disappear is if having the gene was a disadvantage and I do not thin
```
### 處理搜索引擎的結果
網絡可以被看作未經標注的巨大的語料庫。網絡搜索引擎提供了一個有效的手段,搜索大量文本作為有關的語言學的例子。搜索引擎的主要優勢是規模:因為你正在尋找這樣龐大的一個文件集,會更容易找到你感興趣語言模式。而且,你可以使用非常具體的模式,僅僅在較小的范圍匹配一兩個例子,但在網絡上可能匹配成千上萬的例子。網絡搜索引擎的第二個優勢是非常容易使用。因此,它是一個非常方便的工具,可以快速檢查一個理論是否合理。
表 3.1:
搭配的谷歌命中次數:absolutely 或 definitely 后面跟著 adore, love, like 或 prefer 的搭配的命中次數。(Liberman, in _LanguageLog_, 2005)。
```py
>>> import feedparser
>>> llog = feedparser.parse("http://languagelog.ldc.upenn.edu/nll/?feed=atom")
>>> llog['feed']['title']
'Language Log'
>>> len(llog.entries)
15
>>> post = llog.entries[2]
>>> post.title
"He's My BF"
>>> content = post.content[0].value
>>> content[:70]
'<p>Today I was chatting with three of our visiting graduate students f'
>>> raw = BeautifulSoup(content).get_text()
>>> word_tokenize(raw)
['Today', 'I', 'was', 'chatting', 'with', 'three', 'of', 'our', 'visiting',
'graduate', 'students', 'from', 'the', 'PRC', '.', 'Thinking', 'that', 'I',
'was', 'being', 'au', 'courant', ',', 'I', 'mentioned', 'the', 'expression',
'DUI4XIANG4', '\u5c0d\u8c61', '("', 'boy', '/', 'girl', 'friend', '"', ...]
```
伴隨著一些更深入的工作,我們可以編寫程序創建一個博客帖子的小語料庫,并以此作為我們 NLP 的工作基礎。
### 讀取本地文件
為了讀取本地文件,我們需要使用 Python 內置的`open()`函數,然后是`read()`方法。假設你有一個文件`document.txt`,你可以像這樣加載它的內容:
```py
>>> f = open('document.txt')
>>> raw = f.read()
```
注意
**輪到你來:** 使用文本編輯器創建一個名為`document.txt`的文件,然后輸入幾行文字,保存為純文本。如果你使用 IDLE,在 _File_ 菜單中選擇 _New Window_ 命令,在新窗口中輸入所需的文本,然后在 IDLE 提供的彈出式對話框中的文件夾內保存文件為`document.txt`。然后在 Python 解釋器中使用`f = open('document.txt')`打開這個文件,并使用`print(f.read())`檢查其內容。
當你嘗試這樣做時可能會出各種各樣的錯誤。如果解釋器無法找到你的文件,你會看到類似這樣的錯誤:
```py
>>> f = open('document.txt')
Traceback (most recent call last):
File "<pyshell#7>", line 1, in -toplevel-
f = open('document.txt')
IOError: [Errno 2] No such file or directory: 'document.txt'
```
要檢查你正試圖打開的文件是否在正確的目錄中,使用 IDLE _File_ 菜單上的 _Open_ 命令;另一種方法是在 Python 中檢查當前目錄:
```py
>>> import os
>>> os.listdir('.')
```
另一個你在訪問一個文本文件時可能遇到的問題是換行的約定,這個約定因操作系統不同而不同。內置的`open()`函數的第二個參數用于控制如何打開文件:`open('document.txt', 'rU')` —— `'r'`意味著以只讀方式打開文件(默認),`'U'`表示“通用”,它讓我們忽略不同的換行約定。
假設你已經打開了該文件,有幾種方法可以閱讀此文件。`read()`方法創建了一個包含整個文件內容的字符串:
```py
>>> f.read()
'Time flies like an arrow.\nFruit flies like a banana.\n'
```
回想一`'\n'`字符是換行符;這相當于按鍵盤上的 _Enter_ 開始一個新行。
我們也可以使用一個`for`循環一次讀文件中的一行:
```py
>>> f = open('document.txt', 'rU')
>>> for line in f:
... print(line.strip())
Time flies like an arrow.
Fruit flies like a banana.
```
在這里,我們使用`strip()`方法刪除輸入行結尾的換行符。
NLTK 中的語料庫文件也可以使用這些方法來訪問。我們只需使用`nltk.data.find()`來獲取語料庫項目的文件名。然后就可以使用我們剛才講的方式打開和閱讀它:
```py
>>> path = nltk.data.find('corpora/gutenberg/melville-moby_dick.txt')
>>> raw = open(path, 'rU').read()
```
### 從 PDF、MS Word 及其他二進制格式中提取文本
ASCII 碼文本和 HTML 文本是人可讀的格式。文字常常以二進制格式出現,如 PDF 和 MSWord,只能使用專門的軟件打開。第三方函數庫如`pypdf`和`pywin32`提供了對這些格式的訪問。從多列文檔中提取文本是特別具有挑戰性的。一次性轉換幾個文件,會比較簡單些,用一個合適的應用程序打開文件,以文本格式保存到本地驅動器,然后以如下所述的方式訪問它。如果該文檔已經在網絡上,你可以在 Google 的搜索框輸入它的 URL。搜索結果通常包括這個文檔的 HTML 版本的鏈接,你可以將它保存為文本。
### 捕獲用戶輸入
有時我們想捕捉用戶與我們的程序交互時輸入的文本。調用 Python 函數`input()`提示用戶輸入一行數據。保存用戶輸入到一個變量后,我們可以像其他字符串那樣操縱它。
```py
>>> s = input("Enter some text: ")
Enter some text: On an exceptionally hot evening early in July
>>> print("You typed", len(word_tokenize(s)), "words.")
You typed 8 words.
```
### NLP 的流程
[3.1](./ch03.html#fig-pipeline1)總結了我們在本節涵蓋的內容,包括我們在[1.](./ch01.html#chap-introduction).中所看到的建立一個詞匯表的過程。(其中一個步驟,規范化,將在[3.6](./ch03.html#sec-normalizing-text)討論。)

圖 3.1:處理流程:打開一個 URL,讀里面 HTML 格式的內容,去除標記,并選擇字符的切片;然后分詞,是否轉換為`nltk.Text`對象是可選擇的;我們也可以將所有詞匯小寫并提取詞匯表。
在這條流程后面還有很多操作。要正確理解它,這樣有助于明確其中提到的每個變量的類型。使用`type(x)`我們可以找出任一 Python 對象`x`的類型,如`type(1)`是`<int>`因為`1`是一個整數。
當我們載入一個 URL 或文件的內容時,或者當我們去掉 HTML 標記時,我們正在處理字符串,也就是 Python 的`<str>`數據類型。(在[3.2](./ch03.html#sec-strings)節,我們將學習更多有關字符串的內容):
```py
>>> raw = open('document.txt').read()
>>> type(raw)
<class 'str'>
```
當我們將一個字符串分詞,會產生一個(詞的)列表,這是 Python 的`<list>`類型。規范化和排序列表產生其它列表:
```py
>>> tokens = word_tokenize(raw)
>>> type(tokens)
<class 'list'>
>>> words = [w.lower() for w in tokens]
>>> type(words)
<class 'list'>
>>> vocab = sorted(set(words))
>>> type(vocab)
<class 'list'>
```
一個對象的類型決定了它可以執行哪些操作。比如我們可以追加一個鏈表,但不能追加一個字符串:
```py
>>> vocab.append('blog')
>>> raw.append('blog')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'str' object has no attribute 'append'
```
同樣的,我們可以連接字符串與字符串,列表與列表,但我們不能連接字符串與列表:
```py
>>> query = 'Who knows?'
>>> beatles = ['john', 'paul', 'george', 'ringo']
>>> query + beatles
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot concatenate 'str' and 'list' objects
```
## 3.2 字符串:最底層的文本處理
現在是時候研究一個之前我們一直故意避開的基本數據類型了。在前面的章節中,我們側重于將文本作為一個詞列表。我們并沒有細致的探討詞匯以及它們是如何在編程語言中被處理的。通過使用 NLTK 中的語料庫接口,我們可以忽略這些文本所在的文件。一個詞的內容,一個文件的內容在編程語言中是由一個叫做字符串的基本數據類型來表示的。在本節中,我們將詳細探討字符串,并展示字符串與詞匯、文本和文件之間的聯系。
### 字符串的基本操作
可以使用單引號[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch03.html#single-quotes)或雙引號[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch03.html#double-quotes)來指定字符串,如下面的例子代碼所示。如果一個字符串中包含一個單引號,我們必須在單引號前加反斜杠[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch03.html#backslash-escape)讓 Python 知道這是字符串中的單引號,或者也可以將這個字符串放入雙引號中[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch03.html#double-quotes)。否則,字符串內的單引號[![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)](./ch03.html#unescaped-quote)將被解釋為字符串結束標志,Python 解釋器會報告一個語法錯誤:
```py
>>> monty = 'Monty Python' ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> monty
'Monty Python'
>>> circus = "Monty Python's Flying Circus" ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> circus
"Monty Python's Flying Circus"
>>> circus = 'Monty Python\'s Flying Circus' ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
>>> circus
"Monty Python's Flying Circus"
>>> circus = 'Monty Python's Flying Circus' ![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)
File "<stdin>", line 1
circus = 'Monty Python's Flying Circus'
^
SyntaxError: invalid syntax
```
有時字符串跨好幾行。Python 提供了多種方式表示它們。在下面的例子中,一個包含兩個字符串的序列被連接為一個字符串。我們需要使用反斜杠[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch03.html#string-backslash)或者括號[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch03.html#string-parentheses),這樣解釋器就知道第一行的表達式不完整。
```py
>>> couplet = "Shall I compare thee to a Summer's day?"\
... "Thou are more lovely and more temperate:" ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> print(couplet)
Shall I compare thee to a Summer's day?Thou are more lovely and more temperate:
>>> couplet = ("Rough winds do shake the darling buds of May,"
... "And Summer's lease hath all too short a date:") ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> print(couplet)
Rough winds do shake the darling buds of May,And Summer's lease hath all too short a date:
```
不幸的是,這些方法并沒有展現給我們十四行詩的兩行之間的換行。為此,我們可以使用如下所示的三重引號的字符串:
```py
>>> couplet = """Shall I compare thee to a Summer's day?
... Thou are more lovely and more temperate:"""
>>> print(couplet)
Shall I compare thee to a Summer's day?
Thou are more lovely and more temperate:
>>> couplet = '''Rough winds do shake the darling buds of May,
... And Summer's lease hath all too short a date:'''
>>> print(couplet)
Rough winds do shake the darling buds of May,
And Summer's lease hath all too short a date:
```
現在我們可以定義字符串,也可以在上面嘗試一些簡單的操作。首先,讓我們來看看`+`操作,被稱為連接 [![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch03.html#string-concatenation)。此操作產生一個新字符串,它是兩個原始字符串首尾相連粘貼在一起而成。請注意,連接不會做一些比較聰明的事,例如在詞匯之間插入空格。我們甚至可以對字符串用乘法[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch03.html#string-multiplication):
```py
>>> 'very' + 'very' + 'very' ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
'veryveryvery'
>>> 'very' * 3 ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
'veryveryvery'
```
注意
**輪到你來:** 試運行下面的代碼,然后嘗試使用你對字符串`+`和`*`操作的理解,弄清楚它是如何運作的。要小心區分字符串`' '`,這是一個空格符,和字符串`''`,這是一個空字符串。
```py
>>> a = [1, 2, 3, 4, 5, 6, 7, 6, 5, 4, 3, 2, 1]
>>> b = [' ' * 2 * (7 - i) + 'very' * i for i in a]
>>> for line in b:
... print(line)
```
我們已經看到加法和乘法運算不僅僅適用于數字也適用于字符串。但是,請注意,我們不能對字符串用減法或除法:
```py
>>> 'very' - 'y'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for -: 'str' and 'str'
>>> 'very' / 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for /: 'str' and 'int'
```
這些錯誤消息是 Python 的另一個例子,告訴我們的數據類型混亂。第一種情況告訴我們減法操作(即`-`) 不能適用于`str`(字符串)對象類型,而第二種情況告訴我們除法的兩個操作數不能分別為`str`和`int`。
### 輸出字符串
到目前為止,當我們想看看變量的內容或想看到計算的結果,我們就把變量的名稱輸入到解釋器。我們還可以使用`print`語句來看一個變量的內容:
```py
>>> print(monty)
Monty Python
```
請注意這次是沒有引號的。當我們通過輸入變量的名字到解釋器中來檢查它時,解釋器輸出 Python 中的變量的值。因為它是一個字符串,結果被引用。然而,當我們告訴解釋器`print`這個變量時,我們沒有看到引號字符,因為字符串的內容里面沒有引號。
`print`語句可以多種方式將多個元素顯示在一行,就像這樣:
```py
>>> grail = 'Holy Grail'
>>> print(monty + grail)
Monty PythonHoly Grail
>>> print(monty, grail)
Monty Python Holy Grail
>>> print(monty, "and the", grail)
Monty Python and the Holy Grail
```
### 訪問單個字符
正如我們在[2](./ch01.html#sec-a-closer-look-at-python-texts-as-lists-of-words)看到的列表,字符串也是被索引的,從零開始。當我們索引一個字符串時,我們得到它的一個字符(或字母)。一個單獨的字符并沒有什么特別,它只是一個長度為`1`的字符串。
```py
>>> monty[0]
'M'
>>> monty[3]
't'
>>> monty[5]
' '
```
與列表一樣,如果我們嘗試訪問一個超出字符串范圍的索引時,會得到了一個錯誤:
```py
>>> monty[20]
Traceback (most recent call last):
File "<stdin>", line 1, in ?
IndexError: string index out of range
```
也與列表一樣,我們可以使用字符串的負數索引,其中`-1`是最后一個字符的索引[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch03.html#last-character)。正數和負數的索引給我們兩種方式指示一個字符串中的任何位置。在這種情況下,當一個字符串長度為 12 時,索引`5`和`-7`都指示相同的字符(一個空格)。(請注意,`5 = len(monty) - 7`。)
```py
>>> monty[-1] ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
'n'
>>> monty[5]
' '
>>> monty[-7]
' '
```
我們可以寫一個`for`循環,遍歷字符串中的字符。`print`函數包含可選的`end=' '`參數,這是為了告訴 Python 不要在行尾輸出換行符。
```py
>>> sent = 'colorless green ideas sleep furiously'
>>> for char in sent:
... print(char, end=' ')
...
c o l o r l e s s g r e e n i d e a s s l e e p f u r i o u s l y
```
我們也可以計數單個字符。通過將所有字符小寫來忽略大小寫的區分,并過濾掉非字母字符。
```py
>>> from nltk.corpus import gutenberg
>>> raw = gutenberg.raw('melville-moby_dick.txt')
>>> fdist = nltk.FreqDist(ch.lower() for ch in raw if ch.isalpha())
>>> fdist.most_common(5)
[('e', 117092), ('t', 87996), ('a', 77916), ('o', 69326), ('n', 65617)]
>>> [char for (char, count) in fdist.most_common()]
['e', 't', 'a', 'o', 'n', 'i', 's', 'h', 'r', 'l', 'd', 'u', 'm', 'c', 'w',
'f', 'g', 'p', 'b', 'y', 'v', 'k', 'q', 'j', 'x', 'z']
```
```py
>>> monty[6:10]
'Pyth'
```
在這里,我們看到的字符是`'P'`, `'y'`, `'t'`和`'h'`,它們分別對應于`monty[6]` ... `monty[9]`而不包括`monty[10]`。這是因為切片開始于第一個索引,但結束于最后一個索引的前一個。
我們也可以使用負數索引切片——也是同樣的規則,從第一個索引開始到最后一個索引的前一個結束;在這里是在空格字符前結束。
```py
>>> monty[-12:-7]
'Monty'
```
與列表切片一樣,如果我們省略了第一個值,子字符串將從字符串的開頭開始。如果我們省略了第二個值,則子字符串直到字符串的結尾結束:
```py
>>> monty[:5]
'Monty'
>>> monty[6:]
'Python'
```
我們使用`in`操作符測試一個字符串是否包含一個特定的子字符串,如下所示:
```py
>>> phrase = 'And now for something completely different'
>>> if 'thing' in phrase:
... print('found "thing"')
found "thing"
```
我們也可以使用`find()`找到一個子字符串在字符串內的位置:
```py
>>> monty.find('Python')
6
```
注意
**輪到你來:** 造一句話,將它分配給一個變量, 例如,`sent = 'my sentence...'`。寫切片表達式抽取個別詞。(這顯然不是一種方便的方式來處理文本中的詞!)
### 更多的字符串操作
Python 對處理字符串的支持很全面。[3.2](./ch03.html#tab-string-methods).所示是一個總結,其中包括一些我們還沒有看到的操作。關于字符串的更多信息,可在 Python 提示符下輸入`help(str)`。
表 3.2:
有用的字符串方法:[4.2](./ch01.html#tab-word-tests)中字符串測試之外的字符串上的操作;所有的方法都產生一個新的字符串或列表
```py
>>> query = 'Who knows?'
>>> beatles = ['John', 'Paul', 'George', 'Ringo']
>>> query[2]
'o'
>>> beatles[2]
'George'
>>> query[:2]
'Wh'
>>> beatles[:2]
['John', 'Paul']
>>> query + " I don't"
"Who knows? I don't"
>>> beatles + 'Brian'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate list (not "str") to list
>>> beatles + ['Brian']
['John', 'Paul', 'George', 'Ringo', 'Brian']
```
當我們在一個 Python 程序中打開并讀入一個文件,我們得到一個對應整個文件內容的字符串。如果我們使用一個`for`循環來處理這個字符串元素,所有我們可以挑選出的只是單個的字符——我們不選擇粒度。相比之下,列表中的元素可以很大也可以很小,只要我們喜歡:例如,它們可能是段落、句子、短語、單詞、字符。所以,列表的優勢是我們可以靈活的決定它包含的元素,相應的后續的處理也變得靈活。因此,我們在一段 NLP 代碼中可能做的第一件事情就是將一個字符串分詞放入一個字符串列表中([3.7](./ch03.html#sec-tokenization))。相反,當我們要將結果寫入到一個文件或終端,我們通常會將它們格式化為一個字符串([3.9](./ch03.html#sec-formatting))。
列表與字符串沒有完全相同的功能。列表具有增強的能力使你可以改變其中的元素:
```py
>>> beatles[0] = "John Lennon"
>>> del beatles[-1]
>>> beatles
['John Lennon', 'Paul', 'George']
```
另一方面,如果我們嘗試在一個 _ 字符串 _ 上這么做——將`query`的第 0 個字符修改為`'F'`——我們得到:
```py
>>> query[0] = 'F'
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: object does not support item assignment
```
這是因為字符串是不可變的:一旦你創建了一個字符串,就不能改變它。然而,列表是可變的,其內容可以隨時修改。作為一個結論,列表支持修改原始值的操作,而不是產生一個新的值。
注意
**輪到你來:** 通過嘗試本章結尾的一些練習,鞏固你的字符串知識。
## 3.3 使用 Unicode 進行文字處理
我們的程序經常需要處理不同的語言和不同的字符集。“純文本”的概念是虛構的。如果你住在講英語國家,你可能在使用 ASCII 碼而沒有意識到這一點。如果你住在歐洲,你可能使用一種擴展拉丁字符集,包含丹麥語和挪威語中的“?”,匈牙利語中的“?”,西班牙和布列塔尼語中的“?”,捷克語和斯洛伐克語中的“ň”。在本節中,我們將概述如何使用 Unicode 處理使用非 ASCII 字符集的文本。
### 什么是 Unicode?
Unicode 支持超過一百萬種字符。每個字符分配一個編號,稱為編碼點。在 Python 中,編碼點寫作`\u`_XXXX_ 的形式,其中 _XXXX_ 是四位十六進制形式數。
在一個程序中,我們可以像普通字符串那樣操縱 Unicode 字符串。然而,當 Unicode 字符被存儲在文件或在終端上顯示,它們必須被編碼為字節流。一些編碼(如 ASCII 和 Latin-2)中每個編碼點使用單字節,所以它們可以只支持 Unicode 的一個小的子集,足夠單個語言使用了。其它的編碼(如 UTF-8)使用多個字節,可以表示全部的 Unicode 字符。
文件中的文本都是有特定編碼的,所以我們需要一些機制來將文本翻譯成 Unicode——翻譯成 Unicode 叫做解碼。相對的,要將 Unicode 寫入一個文件或終端,我們首先需要將 Unicode 轉化為合適的編碼——這種將 Unicode 轉化為其它編碼的過程叫做編碼,如[3.3](./ch03.html#fig-unicode)所示。

圖 3.3:Unicode 解碼和編碼
從 Unicode 的角度來看,字符是可以實現一個或多個字形的抽象的實體。只有字形可以出現在屏幕上或被打印在紙上。一個字體是一個字符到字形映射。
### 從文件中提取已編碼文本
假設我們有一個小的文本文件,我們知道它是如何編碼的。例如,`polish-lat2.txt`顧名思義是波蘭語的文本片段(來源波蘭語 Wikipedia;可以在`http://pl.wikipedia.org/wiki/Biblioteka_Pruska`中看到)。此文件是 Latin-2 編碼的,也稱為 ISO-8859-2。`nltk.data.find()`函數為我們定位文件。
```py
>>> path = nltk.data.find('corpora/unicode_samples/polish-lat2.txt')
```
Python 的`open()`函數可以讀取編碼的數據為 Unicode 字符串,并寫出 Unicode 字符串的編碼形式。它采用一個參數來指定正在讀取或寫入的文件的編碼。因此,讓我們使用編碼 `'latin2'`打開我們波蘭語文件,并檢查該文件的內容︰
```py
>>> f = open(path, encoding='latin2')
>>> for line in f:
... line = line.strip()
... print(line)
Pruska Biblioteka Państwowa. Jej dawne zbiory znane pod nazw?
"Berlinka" to skarb kultury i sztuki niemieckiej. Przewiezione przez
Niemców pod koniec II wojny ?wiatowej na Dolny ?l?sk, zosta?y
odnalezione po 1945 r. na terytorium Polski. Trafi?y do Biblioteki
Jagiellońskiej w Krakowie, obejmuj? ponad 500 tys. zabytkowych
archiwaliów, m.in. manuskrypty Goethego, Mozarta, Beethovena, Bacha.
```
如果這不能在你的終端正確顯示,或者我們想要看到字符的底層數值(或"代碼點"),那么我們可以將所有的非 ASCII 字符轉換成它們兩位數`\x`_XX_ 和四位數 `\u`_XXXX_ 表示法︰
```py
>>> f = open(path, encoding='latin2')
>>> for line in f:
... line = line.strip()
... print(line.encode('unicode_escape'))
b'Pruska Biblioteka Pa\\u0144stwowa. Jej dawne zbiory znane pod nazw\\u0105'
b'"Berlinka" to skarb kultury i sztuki niemieckiej. Przewiezione przez'
b'Niemc\\xf3w pod koniec II wojny \\u015bwiatowej na Dolny \\u015al\\u0105sk, zosta\\u0142y'
b'odnalezione po 1945 r. na terytorium Polski. Trafi\\u0142y do Biblioteki'
b'Jagiello\\u0144skiej w Krakowie, obejmuj\\u0105 ponad 500 tys. zabytkowych'
b'archiwali\\xf3w, m.in. manuskrypty Goethego, Mozarta, Beethovena, Bacha.'
```
上面輸出的第一行有一個以`\u`轉義字符串開始的 Unicode 轉義字符串,即`\u0144`。相關的 Unicode 字符在屏幕上將顯示為字形ń。在前面例子中的第三行中,我們看到`\xf3`,對應字形為ó,在 128-255 的范圍內。
在 Python 3 中,源代碼默認使用 UTF-8 編碼,如果你使用的 IDLE 或另一個支持 Unicode 的程序編輯器,你可以在字符串中包含 Unicode 字符。可以使用`\u`_XXXX_ 轉義序列包含任意的 Unicode 字符。我們使用`ord()`找到一個字符的整數序數。例如︰
```py
>>> ord('ń')
324
```
324 的 4 位十六進制數字的形式是 0144(輸入 `hex(324)` 可以發現這點),我們可以定義一個具有適當轉義序列的字符串。
```py
>>> nacute = '\u0144'
>>> nacute
'ń'
```
注意
決定屏幕上顯示的字形的因素很多。如果你確定你的編碼正確但你的 Python 代碼仍然未能顯示出你預期的字形,你應該檢查你的系統上是否安裝了所需的字體。可能需要配置你的區域設置來渲染 UTF-8 編碼的字符,然后使用`print(nacute.encode('utf8'))`才能在你的終端看到ń顯示。
我們還可以看到這個字符在一個文本文件內是如何表示為字節序列的︰
```py
>>> nacute.encode('utf8')
b'\xc5\x84'
```
`unicodedata`模塊使我們可以檢查 Unicode 字符的屬性。在下面的例子中,我們選擇超出 ASCII 范圍的波蘭語文本的第三行中的所有字符,輸出它們的 UTF-8 轉義值,然后是使用標準 Unicode 約定的它們的編碼點整數(即以`U+`為前綴的十六進制數字),隨后是它們的 Unicode 名稱。
```py
>>> import unicodedata
>>> lines = open(path, encoding='latin2').readlines()
>>> line = lines[2]
>>> print(line.encode('unicode_escape'))
b'Niemc\\xf3w pod koniec II wojny \\u015bwiatowej na Dolny \\u015al\\u0105sk, zosta\\u0142y\\n'
>>> for c in line: ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... if ord(c) > 127:
... print('{} U+{:04x} {}'.format(c.encode('utf8'), ord(c), unicodedata.name(c)))
b'\xc3\xb3' U+00f3 LATIN SMALL LETTER O WITH ACUTE
b'\xc5\x9b' U+015b LATIN SMALL LETTER S WITH ACUTE
b'\xc5\x9a' U+015a LATIN CAPITAL LETTER S WITH ACUTE
b'\xc4\x85' U+0105 LATIN SMALL LETTER A WITH OGONEK
b'\xc5\x82' U+0142 LATIN SMALL LETTER L WITH STROKE
```
如果你使用`c`替換掉[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch03.html#unicode-info)中的`c.encode('utf8')`,如果你的系統支持 UTF-8,你應該看到類似下面的輸出:
ó U+00f3 LATIN SMALL LETTER O WITH ACUTE? U+015b LATIN SMALL LETTER S WITH ACUTE? U+015a LATIN CAPITAL LETTER S WITH ACUTE? U+0105 LATIN SMALL LETTER A WITH OGONEK? U+0142 LATIN SMALL LETTER L WITH STROKE
另外,根據你的系統的具體情況,你可能需要用`'latin2'`替換示例中的編碼`'utf8'`。
下一個例子展示 Python 字符串函數和`re`模塊是如何能夠與 Unicode 字符一起工作的。(我們會在下面一節中仔細看看`re` 模塊。`\w`匹配一個"單詞字符",參見[3.4](./ch03.html#tab-re-symbols))。
```py
>>> line.find('zosta\u0142y')
54
>>> line = line.lower()
>>> line
'niemców pod koniec ii wojny ?wiatowej na dolny ?l?sk, zosta?y\n'
>>> line.encode('unicode_escape')
b'niemc\\xf3w pod koniec ii wojny \\u015bwiatowej na dolny \\u015bl\\u0105sk, zosta\\u0142y\\n'
>>> import re
>>> m = re.search('\u015b\w*', line)
>>> m.group()
'\u015bwiatowej'
```
NLTK 分詞器允許 Unicode 字符串作為輸入,并輸出相應地 Unicode 字符串。
```py
>>> word_tokenize(line)
['niemców', 'pod', 'koniec', 'ii', 'wojny', '?wiatowej', 'na', 'dolny', '?l?sk', ',', 'zosta?y']
```
### 在 Python 中使用本地編碼
如果你習慣了使用特定的本地編碼字符,你可能希望能夠在一個 Python 文件中使用你的字符串輸入及編輯的標準方法。為了做到這一點,你需要在你的文件的第一行或第二行中包含字符串:`'# -*- coding: <coding> -*-'`。請注意 _<coding>_ 必須是像`'latin-1'`, `'big5'`或`'utf-8'`這樣的字符串 (見 [3.4](./ch03.html#fig-polish-utf8))。
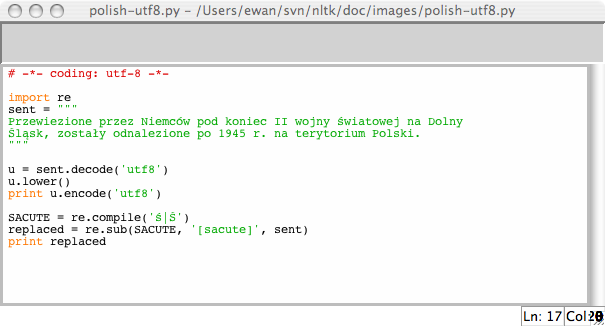
圖 3.4:Unicode 與 IDLE:IDLE 編輯器中 UTF-8 編碼的字符串字面值;這需要在 IDLE 屬性中設置了相應的字體;這里我們選擇 Courier CE。
上面的例子還說明了正規表達式是如何可以使用編碼的字符串的。
## 3.4 使用正則表達式檢測詞組搭配
許多語言處理任務都涉及模式匹配。例如:我們可以使用`endswith('ed')`找到以 ed 結尾的詞。在[4.2](./ch01.html#tab-word-tests)中我們看到過各種這樣的“詞測試”。正則表達式給我們一個更加強大和靈活的方法描述我們感興趣的字符模式。
注意
介紹正則表達式的其他出版物有很多,它們圍繞正則表達式的語法組織,應用于搜索文本文件。我們不再贅述這些,只專注于在語言處理的不同階段如何使用正則表達式。像往常一樣,我們將采用基于問題的方式,只在解決實際問題需要時才介紹新特性。在我們的討論中,我們將使用箭頭來表示正則表達式,就像這樣:?`patt`?。
在 Python 中使用正則表達式,需要使用`import re`導入`re`庫。我們還需要一個用于搜索的詞匯列表;我們再次使用詞匯語料庫([4](./ch02.html#sec-lexical-resources))。我們將對它進行預處理消除某些名稱。
```py
>>> import re
>>> wordlist = [w for w in nltk.corpus.words.words('en') if w.islower()]
```
### 使用基本的元字符
讓我們使用正則表達式?`ed 我們將使用函數`re.search(p, s)`檢查字符串`s`中是否有模式`p`。我們需要指定感興趣的字符,然后使用美元符號,它是正則表達式中有特殊用途的符號,用來匹配單詞的末尾:
```py
>>> [w for w in wordlist if re.search('ed$', w)]
['abaissed', 'abandoned', 'abased', 'abashed', 'abatised', 'abed', 'aborted', ...]
```
`.`通配符匹配任何單個字符。假設我們有一個 8 個字母組成的詞的字謎室,j 是其第三個字母,t 是其第六個字母。空白單元格中的每個地方,我們用一個句點:
```py
>>> [w for w in wordlist if re.search('^..j..t..$', w)]
['abjectly', 'adjuster', 'dejected', 'dejectly', 'injector', 'majestic', ...]
```
注意
**輪到你來:** 駝字符`^`匹配字符串的開始,就像`如果我們不用這兩個符號而使用?`..j..t..`?搜索,剛才例子中我們會得到什么樣的結果?
最后,`?`符合表示前面的字符是可選的。因此?`^e-?mail 我們可以使用`sum(1 for w in text if re.search('^e-?mail/font>, w))`計數一個文本中這個詞(任一拼寫形式)出現的總次數。
### 范圍與閉包
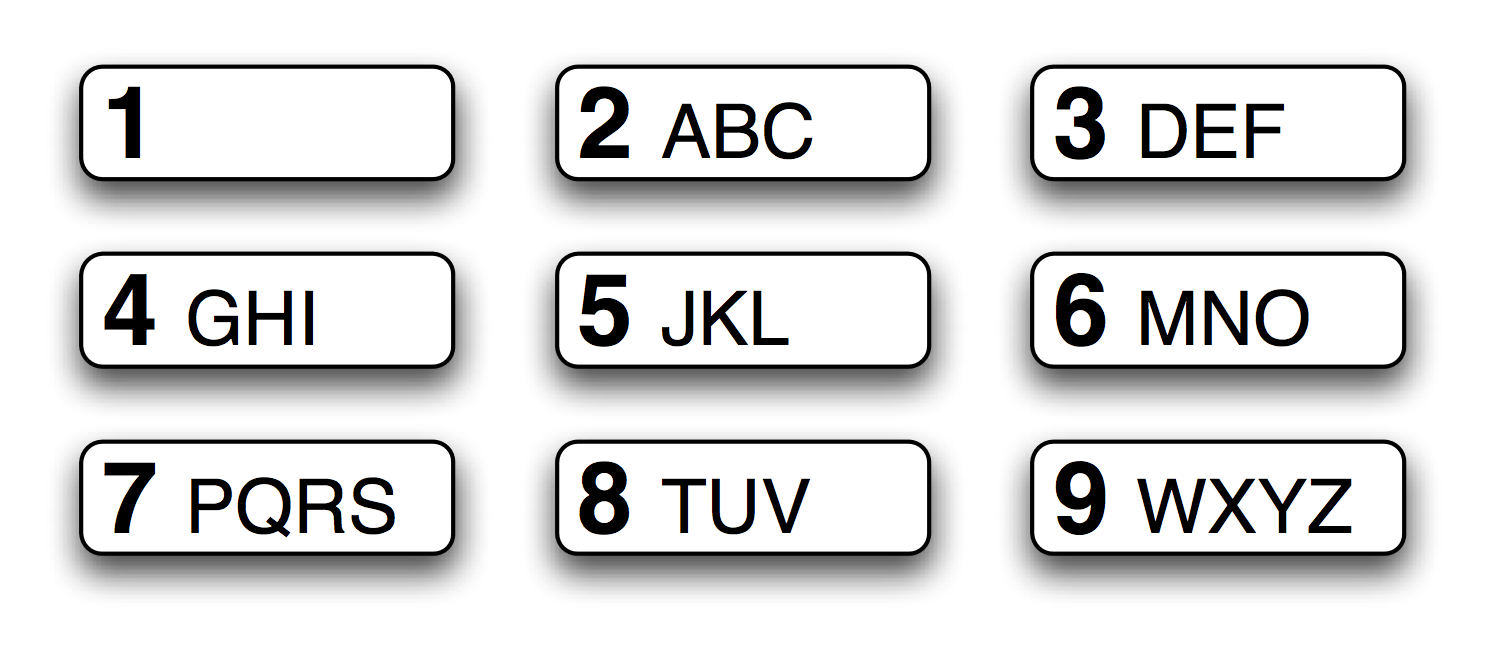
圖 3.5:T9:9 個鍵上的文本
T9 系統用于在手機上輸入文本(見[3.5](./ch03.html#fig-t9)))。兩個或兩個以上以相同擊鍵順序輸入的詞匯,叫做 textonyms。例如,hole 和 golf 都是通過序列 4653 輸入。還有哪些其它詞匯由相同的序列產生?這里我們使用正則表達式?`^[ghi][mno][jlk][def]
```py
>>> [w for w in wordlist if re.search('^[ghi][mno][jlk][def]$', w)]
['gold', 'golf', 'hold', 'hole']
```
表達式的第一部分?`^[ghi]`?匹配以 g, h 或 i 開始的詞。表達式的下一部分,?`[mno]`?限制了第二個字符是 m, n 或 o。第三部分和第四部分同樣被限制。只有 4 個單詞滿足這些限制。注意,方括號內的字符的順序是沒有關系的,所以我們可以寫成?`^[hig][nom][ljk][fed]
注意
**輪到你來:** 來看一些“手指繞口令”,只用一部分數字鍵盤搜索詞匯。例如?`^[ghijklmno]+`-`和`+`表示什么意思?
讓我們進一步探索`+`符號。請注意,它可以適用于單個字母或括號內的字母集:
```py
>>> chat_words = sorted(set(w for w in nltk.corpus.nps_chat.words()))
>>> [w for w in chat_words if re.search('^m+i+n+e+$', w)]
['miiiiiiiiiiiiinnnnnnnnnnneeeeeeeeee', 'miiiiiinnnnnnnnnneeeeeeee', 'mine',
'mmmmmmmmiiiiiiiiinnnnnnnnneeeeeeee']
>>> [w for w in chat_words if re.search('^[ha]+$', w)]
['a', 'aaaaaaaaaaaaaaaaa', 'aaahhhh', 'ah', 'ahah', 'ahahah', 'ahh',
'ahhahahaha', 'ahhh', 'ahhhh', 'ahhhhhh', 'ahhhhhhhhhhhhhh', 'h', 'ha', 'haaa',
'hah', 'haha', 'hahaaa', 'hahah', 'hahaha', 'hahahaa', 'hahahah', 'hahahaha', ...]
```
很顯然,`+`簡單地表示“前面的項目的一個或多個實例”,它可以是單獨的字母如`m`,可以是一個集合如`[fed]`或者一個范圍如`[d-f]`。現在讓我們用`*`替換`+`,它表示“前面的項目的零個或多個實例”。正則表達式?`^m*i*n*e*me, min 和 mmmmm。請注意`+`和`*`符號有時被稱為的 Kleene 閉包,或者干脆閉包。
運算符`^`當它出現在方括號內的第一個字符位置時有另外的功能。例如,?`[^aeiouAEIOU]`?匹配除元音字母之外的所有字母。我們可以搜索 NPS 聊天語料庫中完全由非元音字母組成的詞匯,使用?`^[^aeiouAEIOU]+請注意其中包含非字母字符。
下面是另外一些正則表達式的例子,用來尋找匹配特定模式的詞符,這些例子演示如何使用一些新的符號:`\`, `{}`, `()`和`|`。
```py
>>> wsj = sorted(set(nltk.corpus.treebank.words()))
>>> [w for w in wsj if re.search('^[0-9]+\.[0-9]+$', w)]
['0.0085', '0.05', '0.1', '0.16', '0.2', '0.25', '0.28', '0.3', '0.4', '0.5',
'0.50', '0.54', '0.56', '0.60', '0.7', '0.82', '0.84', '0.9', '0.95', '0.99',
'1.01', '1.1', '1.125', '1.14', '1.1650', '1.17', '1.18', '1.19', '1.2', ...]
>>> [w for w in wsj if re.search('^[A-Z]+\$$', w)]
['C$', 'US$']
>>> [w for w in wsj if re.search('^[0-9]{4}$', w)]
['1614', '1637', '1787', '1901', '1903', '1917', '1925', '1929', '1933', ...]
>>> [w for w in wsj if re.search('^[0-9]+-[a-z]{3,5}$', w)]
['10-day', '10-lap', '10-year', '100-share', '12-point', '12-year', ...]
>>> [w for w in wsj if re.search('^[a-z]{5,}-[a-z]{2,3}-[a-z]{,6}$', w)]
['black-and-white', 'bread-and-butter', 'father-in-law', 'machine-gun-toting',
'savings-and-loan']
>>> [w for w in wsj if re.search('(ed|ing)$', w)]
['62%-owned', 'Absorbed', 'According', 'Adopting', 'Advanced', 'Advancing', ...]
```
注意
**輪到你來:** 研究前面的例子,在你繼續閱讀之前嘗試弄清楚`\`, `{}`, `()`和`|` 這些符號的功能。
你可能已經知道反斜杠表示其后面的字母不再有特殊的含義而是按照字面的表示匹配詞中特定的字符。因此,雖然`.`很特別,但是`\.`只匹配一個句號。大括號表達式,如`{3,5}`, 表示前面的項目重復指定次數。管道字符表示從其左邊的內容和右邊的內容中選擇一個。圓括號表示一個操作符的范圍,它們可以與管道(或叫析取)符號一起使用,如?`w(i|e|ai|oo)t`?,匹配 wit, wet, wait 和 woot。你可以省略這個例子里的最后一個表達式中的括號,使用?`ed|ing
我們已經看到的元字符總結在[3.3](./ch03.html#tab-regexp-meta-characters1)中:
表 3.3:
正則表達式基本元字符,其中包括通配符,范圍和閉包
```py
>>> word = 'supercalifragilisticexpialidocious'
>>> re.findall(r'[aeiou]', word)
['u', 'e', 'a', 'i', 'a', 'i', 'i', 'i', 'e', 'i', 'a', 'i', 'o', 'i', 'o', 'u']
>>> len(re.findall(r'[aeiou]', word))
16
```
讓我們來看看一些文本中的兩個或兩個以上的元音序列,并確定它們的相對頻率:
```py
>>> wsj = sorted(set(nltk.corpus.treebank.words()))
>>> fd = nltk.FreqDist(vs for word in wsj
... for vs in re.findall(r'[aeiou]{2,}', word))
>>> fd.most_common(12)
[('io', 549), ('ea', 476), ('ie', 331), ('ou', 329), ('ai', 261), ('ia', 253),
('ee', 217), ('oo', 174), ('ua', 109), ('au', 106), ('ue', 105), ('ui', 95)]
```
注意
**輪到你來:** 在 W3C 日期時間格式中,日期像這樣表示:2009-12-31。Replace the `?` in the following Python code with a regular expression, in order to convert the string `'2009-12-31'` to a list of integers `[2009, 12, 31]`:
`[int(n) for n in re.findall(?, '2009-12-31')]`
### 在單詞片段上做更多事情
一旦我們會使用`re.findall()`從單詞中提取素材,就可以在這些片段上做一些有趣的事情,例如將它們粘貼在一起或用它們繪圖。
英文文本是高度冗余的,忽略掉詞內部的元音仍然可以很容易的閱讀,有些時候這很明顯。例如,declaration 變成 dclrtn,inalienable 變成 inlnble,保留所有詞首或詞尾的元音序列。在我們的下一個例子中,正則表達式匹配詞首元音序列,詞尾元音序列和所有的輔音;其它的被忽略。這三個析取從左到右處理,如果詞匹配三個部分中的一個,正則表達式后面的部分將被忽略。我們使用`re.findall()`提取所有匹配的詞中的字符,然后使`''.join()`將它們連接在一起(更多連接操作參見[3.9](./ch03.html#sec-formatting))。
```py
>>> regexp = r'^[AEIOUaeiou]+|[AEIOUaeiou]+$|[^AEIOUaeiou]'
>>> def compress(word):
... pieces = re.findall(regexp, word)
... return ''.join(pieces)
...
>>> english_udhr = nltk.corpus.udhr.words('English-Latin1')
>>> print(nltk.tokenwrap(compress(w) for w in english_udhr[:75]))
Unvrsl Dclrtn of Hmn Rghts Prmble Whrs rcgntn of the inhrnt dgnty and
of the eql and inlnble rghts of all mmbrs of the hmn fmly is the fndtn
of frdm , jstce and pce in the wrld , Whrs dsrgrd and cntmpt fr hmn
rghts hve rsltd in brbrs acts whch hve outrgd the cnscnce of mnknd ,
and the advnt of a wrld in whch hmn bngs shll enjy frdm of spch and
```
接下來,讓我們將正則表達式與條件頻率分布結合起來。在這里,我們將從羅托卡特語詞匯中提取所有輔音-元音序列,如 ka 和 si。因為每部分都是成對的,它可以被用來初始化一個條件頻率分布。然后我們為每對的頻率畫出表格:
```py
>>> rotokas_words = nltk.corpus.toolbox.words('rotokas.dic')
>>> cvs = [cv for w in rotokas_words for cv in re.findall(r'[ptksvr][aeiou]', w)]
>>> cfd = nltk.ConditionalFreqDist(cvs)
>>> cfd.tabulate()
a e i o u
k 418 148 94 420 173
p 83 31 105 34 51
r 187 63 84 89 79
s 0 0 100 2 1
t 47 8 0 148 37
v 93 27 105 48 49
```
考查 s 行和 t 行,我們看到它們是部分的“互補分布”,這個證據表明它們不是這種語言中的獨特音素。從而我們可以令人信服的從羅托卡特語字母表中去除 s,簡單加入一個發音規則:當字母 t 跟在 i 后面時發 s 的音。(注意單獨的條目 _su_ 即 _kasuari_,‘cassowary’是從英語中借來的)。
如果我們想要檢查表格中數字背后的詞匯,有一個索引允許我們迅速找到包含一個給定的輔音-元音對的單詞的列表將會有幫助,例如,`cv_index['su']`應該給我們所有含有 su 的詞匯。下面是我們如何能做到這一點:
```py
>>> cv_word_pairs = [(cv, w) for w in rotokas_words
... for cv in re.findall(r'[ptksvr][aeiou]', w)]
>>> cv_index = nltk.Index(cv_word_pairs)
>>> cv_index['su']
['kasuari']
>>> cv_index['po']
['kaapo', 'kaapopato', 'kaipori', 'kaiporipie', 'kaiporivira', 'kapo', 'kapoa',
'kapokao', 'kapokapo', 'kapokapo', 'kapokapoa', 'kapokapoa', 'kapokapora', ...]
```
這段代碼依次處理每個詞`w`,對每一個詞找出匹配正則表達式?`[ptksvr][aeiou]`?的所有子字符串。對于詞 kasuari,它找到 ka, su 和 ri。因此,`cv_word_pairs`將包含`('ka', 'kasuari')`, `('su', 'kasuari')`和`('ri', 'kasuari')`。更進一步使用`nltk.Index()`轉換成有用的索引。
### 查找詞干
在使用網絡搜索引擎時,我們通常不介意(甚至沒有注意到)文檔中的詞匯與我們的搜索條件的后綴形式是否相同。查詢 laptops 會找到含有 laptop 的文檔,反之亦然。事實上,laptop 與 laptops 只是詞典中的同一個詞(或詞條)的兩種形式。對于一些語言處理任務,我們想忽略詞語結尾,只是處理詞干。
抽出一個詞的詞干的方法有很多種。這里的是一種簡單直觀的方法,直接去掉任何看起來像一個后綴的字符:
```py
>>> def stem(word):
... for suffix in ['ing', 'ly', 'ed', 'ious', 'ies', 'ive', 'es', 's', 'ment']:
... if word.endswith(suffix):
... return word[:-len(suffix)]
... return word
```
雖然我們最終將使用 NLTK 中內置的詞干提取器,看看我們如何能夠使用正則表達式處理這個任務是有趣的。我們的第一步是建立一個所有后綴的連接。我們需要把它放在括號內以限制這個析取的范圍。
```py
>>> re.findall(r'^.*(ing|ly|ed|ious|ies|ive|es|s|ment)$', 'processing')
['ing']
```
在這里,盡管正則表達式匹配整個單詞,`re.findall()`只是給我們后綴。這是因為括號有第二個功能:選擇要提取的子字符串。如果我們要使用括號來指定析取的范圍,但不想選擇要輸出的字符串,必須添加`?:`,它是正則表達式許多神秘奧妙的地方之一。下面是改進后的版本。
```py
>>> re.findall(r'^.*(?:ing|ly|ed|ious|ies|ive|es|s|ment)$', 'processing')
['processing']
```
然而,實際上,我們會想將詞分成詞干和后綴。所以,我們應該用括號括起正則表達式的這兩個部分:
```py
>>> re.findall(r'^(.*)(ing|ly|ed|ious|ies|ive|es|s|ment)$', 'processing')
[('process', 'ing')]
```
這看起來很有用途,但仍然有一個問題。讓我們來看看另外的詞,processes:
```py
>>> re.findall(r'^(.*)(ing|ly|ed|ious|ies|ive|es|s|ment)$', 'processes')
[('processe', 's')]
```
正則表達式錯誤地找到了后綴-s,而不是后綴-es。這表明另一個微妙之處:星號操作符是“貪婪的”,所以表達式的`.*`部分試圖盡可能多的匹配輸入的字符串。如果我們使用“非貪婪”版本的“*”操作符,寫成`*?`,我們就得到我們想要的:
```py
>>> re.findall(r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)$', 'processes')
[('process', 'es')]
```
我們甚至可以通過使第二個括號中的內容變成可選,來得到空后綴:
```py
>>> re.findall(r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)?$', 'language')
[('language', '')]
```
這種方法仍然有許多問題,(你能發現它們嗎?)但我們仍將繼續定義一個函數來獲取詞干,并將它應用到整個文本:
```py
>>> def stem(word):
... regexp = r'^(.*?)(ing|ly|ed|ious|ies|ive|es|s|ment)?$'
... stem, suffix = re.findall(regexp, word)[0]
... return stem
...
>>> raw = """DENNIS: Listen, strange women lying in ponds distributing swords
... is no basis for a system of government. Supreme executive power derives from
... a mandate from the masses, not from some farcical aquatic ceremony."""
>>> tokens = word_tokenize(raw)
>>> [stem(t) for t in tokens]
['DENNIS', ':', 'Listen', ',', 'strange', 'women', 'ly', 'in', 'pond', 'distribut',
'sword', 'i', 'no', 'basi', 'for', 'a', 'system', 'of', 'govern', '.', 'Supreme',
'execut', 'power', 'deriv', 'from', 'a', 'mandate', 'from', 'the', 'mass', ',',
'not', 'from', 'some', 'farcical', 'aquatic', 'ceremony', '.']
```
請注意我們的正則表達式不但將 ponds 的 s 刪除,也將 is 和 basis 的刪除。它產生一些非詞如 distribut 和 deriv,但這些在一些應用中是可接受的詞干。
### 搜索已分詞文本
你可以使用一種特殊的正則表達式搜索一個文本中多個詞(這里的文本是一個詞符列表)。例如,`"<a> <man>"`找出文本中所有 a man 的實例。尖括號用于標記詞符的邊界,尖括號之間的所有空白都被忽略(這只對 NLTK 中的`findall()`方法處理文本有效)。在下面的例子中,我們使用`<.*>`[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch03.html#single-token-wildcard),它將匹配所有單個詞符,將它括在括號里,于是只匹配詞(例如 monied)而不匹配短語(例如,a monied man)會生成。第二個例子找出以詞 bro 結尾的三個詞組成的短語[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch03.html#three-word-phrases)。最后一個例子找出以字母 l 開始的三個或更多詞組成的序列[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch03.html#letter-l)。
```py
>>> from nltk.corpus import gutenberg, nps_chat
>>> moby = nltk.Text(gutenberg.words('melville-moby_dick.txt'))
>>> moby.findall(r"<a> (<.*>) <man>") ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
monied; nervous; dangerous; white; white; white; pious; queer; good;
mature; white; Cape; great; wise; wise; butterless; white; fiendish;
pale; furious; better; certain; complete; dismasted; younger; brave;
brave; brave; brave
>>> chat = nltk.Text(nps_chat.words())
>>> chat.findall(r"<.*> <.*> <bro>") ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
you rule bro; telling you bro; u twizted bro
>>> chat.findall(r"<l.*>{3,}") ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
lol lol lol; lmao lol lol; lol lol lol; la la la la la; la la la; la
la la; lovely lol lol love; lol lol lol.; la la la; la la la
```
注意
**輪到你來:**鞏固你對正則表達式模式與替換的理解,使用`nltk.re_show(`_p, s_`)`,它能標注字符串 _s_ 中所有匹配模式 _p_ 的地方,以及`nltk.app.nemo()`,它能提供一個探索正則表達式的圖形界面。更多的練習,可以嘗試本章尾的正則表達式的一些練習。
當我們研究的語言現象與特定詞語相關時建立搜索模式是很容易的。在某些情況下,一個小小的創意可能會花很大功夫。例如,在大型文本語料庫中搜索 x and other ys 形式的表達式能讓我們發現上位詞(見[5](./ch02.html#sec-wordnet)):
```py
>>> from nltk.corpus import brown
>>> hobbies_learned = nltk.Text(brown.words(categories=['hobbies', 'learned']))
>>> hobbies_learned.findall(r"<\w*> <and> <other> <\w*s>")
speed and other activities; water and other liquids; tomb and other
landmarks; Statues and other monuments; pearls and other jewels;
charts and other items; roads and other features; figures and other
objects; military and other areas; demands and other factors;
abstracts and other compilations; iron and other metals
```
只要有足夠多的文本,這種做法會給我們一整套有用的分類標準信息,而不需要任何手工勞動。然而,我們的搜索結果中通常會包含誤報,即我們想要排除的情況。例如,結果 demands and other factors 暗示 demand 是類型 factor 的一個實例,但是這句話實際上是關于要求增加工資的。盡管如此,我們仍可以通過手工糾正這些搜索的結果來構建自己的英語概念的本體。
注意
這種自動和人工處理相結合的方式是最常見的建造新的語料庫的方式。我們將在[11.](./ch11.html#chap-data)繼續講述這些。
搜索語料也會有遺漏的問題,即漏掉了我們想要包含的情況。僅僅因為我們找不到任何一個搜索模式的實例,就斷定一些語言現象在一個語料庫中不存在,是很冒險的。也許我們只是沒有足夠仔細的思考合適的模式。
注意
**輪到你來:** 查找模式 as x as y 的實例以發現實體及其屬性信息。
## 3.6 規范化文本
在前面的程序例子中,我們在處理文本詞匯前經常要將文本轉換為小寫,即`set(w.lower() for w in text)`。通過使用`lower()`我們將文本規范化為小寫,這樣一來 The 與 the 的區別被忽略。我們常常想比這走得更遠,去掉所有的詞綴以及提取詞干的任務等。更進一步的步驟是確保結果形式是字典中確定的詞,即叫做詞形歸并的任務。我們依次討論這些。首先,我們需要定義我們將在本節中使用的數據:
```py
>>> raw = """DENNIS: Listen, strange women lying in ponds distributing swords
... is no basis for a system of government. Supreme executive power derives from
... a mandate from the masses, not from some farcical aquatic ceremony."""
>>> tokens = word_tokenize(raw)
```
### 詞干提取器
NLTK 中包括幾個現成的詞干提取器,如果你需要一個詞干提取器,你應該優先使用它們中的一個,而不是使用正則表達式制作自己的詞干提取器,因為 NLTK 中的詞干提取器能處理的不規則的情況很廣泛。Porter 和 Lancaster 詞干提取器按照它們自己的規則剝離詞綴。請看 Porter 詞干提取器正確處理了詞 lying(將它映射為 lie),而 Lancaster 詞干提取器并沒有處理好。
```py
>>> porter = nltk.PorterStemmer()
>>> lancaster = nltk.LancasterStemmer()
>>> [porter.stem(t) for t in tokens]
['DENNI', ':', 'Listen', ',', 'strang', 'women', 'lie', 'in', 'pond',
'distribut', 'sword', 'is', 'no', 'basi', 'for', 'a', 'system', 'of', 'govern',
'.', 'Suprem', 'execut', 'power', 'deriv', 'from', 'a', 'mandat', 'from',
'the', 'mass', ',', 'not', 'from', 'some', 'farcic', 'aquat', 'ceremoni', '.']
>>> [lancaster.stem(t) for t in tokens]
['den', ':', 'list', ',', 'strange', 'wom', 'lying', 'in', 'pond', 'distribut',
'sword', 'is', 'no', 'bas', 'for', 'a', 'system', 'of', 'govern', '.', 'suprem',
'execut', 'pow', 'der', 'from', 'a', 'mand', 'from', 'the', 'mass', ',', 'not',
'from', 'som', 'farc', 'aqu', 'ceremony', '.']
```
詞干提取過程沒有明確定義,我們通常選擇心目中最適合我們的應用的詞干提取器。如果你要索引一些文本和使搜索支持不同詞匯形式的話,Porter 詞干提取器是一個很好的選擇([3.6](./ch03.html#code-stemmer-indexing) 所示,它采用 _ 面向對象 _ 編程技術,這超出了本書的范圍,字符串格式化技術將在[3.9](./ch03.html#sec-formatting)講述,`enumerate()`函數將在[4.2](./ch04.html#sec-sequences)解釋)。
```py
class IndexedText(object):
def __init__(self, stemmer, text):
self._text = text
self._stemmer = stemmer
self._index = nltk.Index((self._stem(word), i)
for (i, word) in enumerate(text))
def concordance(self, word, width=40):
key = self._stem(word)
wc = int(width/4) # words of context
for i in self._index[key]:
lcontext = ' '.join(self._text[i-wc:i])
rcontext = ' '.join(self._text[i:i+wc])
ldisplay = '{:>{width}}'.format(lcontext[-width:], width=width)
rdisplay = '{:{width}}'.format(rcontext[:width], width=width)
print(ldisplay, rdisplay)
def _stem(self, word):
return self._stemmer.stem(word).lower()
```
### 詞形歸并
WordNet 詞形歸并器只在產生的詞在它的詞典中時才刪除詞綴。這個額外的檢查過程使詞形歸并器比剛才提到的詞干提取器要慢。請注意,它并沒有處理 lying,但它將 women 轉換為 woman。
```py
>>> wnl = nltk.WordNetLemmatizer()
>>> [wnl.lemmatize(t) for t in tokens]
['DENNIS', ':', 'Listen', ',', 'strange', 'woman', 'lying', 'in', 'pond',
'distributing', 'sword', 'is', 'no', 'basis', 'for', 'a', 'system', 'of',
'government', '.', 'Supreme', 'executive', 'power', 'derives', 'from', 'a',
'mandate', 'from', 'the', 'mass', ',', 'not', 'from', 'some', 'farcical',
'aquatic', 'ceremony', '.']
```
如果你想編譯一些文本的詞匯,或者想要一個有效詞條(或中心詞)列表,WordNet 詞形歸并器是一個不錯的選擇。
注意
另一個規范化任務涉及識別非標準詞,包括數字、縮寫、日期以及映射任何此類詞符到一個特殊的詞匯。例如,每一個十進制數可以被映射到一個單獨的標識符`0.0`,每首字母縮寫可以映射為`AAA`。這使詞匯量變小,提高了許多語言建模任務的準確性。
## 3.7 用正則表達式為文本分詞
分詞是將字符串切割成可識別的構成一塊語言數據的語言單元。雖然這是一項基礎任務,我們能夠一直拖延到現在為止才講,是因為許多語料庫已經分過詞了,也因為 NLTK 中包括一些分詞器。現在你已經熟悉了正則表達式,你可以學習如何使用它們來為文本分詞,并對此過程中有更多的掌控權。
### 分詞的簡單方法
文本分詞的一種非常簡單的方法是在空格符處分割文本。考慮以下摘自 _《愛麗絲夢游仙境》_ 中的文本:
```py
>>> raw = """'When I'M a Duchess,' she said to herself, (not in a very hopeful tone
... though), 'I won't have any pepper in my kitchen AT ALL. Soup does very
... well without--Maybe it's always pepper that makes people hot-tempered,'..."""
```
我們可以使用`raw.split()`在空格符處分割原始文本。使用正則表達式能做同樣的事情,匹配字符串中的所有空格符[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch03.html#split-space)是不夠的,因為這將導致分詞結果包含`\n`換行符;我們需要匹配任何數量的空格符、制表符或換行符[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch03.html#split-whitespace):
```py
>>> re.split(r' ', raw) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
["'When", "I'M", 'a', "Duchess,'", 'she', 'said', 'to', 'herself,', '(not', 'in',
'a', 'very', 'hopeful', 'tone\nthough),', "'I", "won't", 'have', 'any', 'pepper',
'in', 'my', 'kitchen', 'AT', 'ALL.', 'Soup', 'does', 'very\nwell', 'without--Maybe',
"it's", 'always', 'pepper', 'that', 'makes', 'people', "hot-tempered,'..."]
>>> re.split(r'[ \t\n]+', raw) ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
["'When", "I'M", 'a', "Duchess,'", 'she', 'said', 'to', 'herself,', '(not', 'in',
'a', 'very', 'hopeful', 'tone', 'though),', "'I", "won't", 'have', 'any', 'pepper',
'in', 'my', 'kitchen', 'AT', 'ALL.', 'Soup', 'does', 'very', 'well', 'without--Maybe',
"it's", 'always', 'pepper', 'that', 'makes', 'people', "hot-tempered,'..."]
```
正則表達式?`[ \t\n]+`?匹配一個或多個空格、制表符(`\t`)或換行符(`\n`)。其他空白字符,如回車和換頁符,實際上應該也包含。于是,我們將使用一個`re`庫內置的縮寫`\s`,它表示匹配所有空白字符。前面的例子中第二條語句可以改寫為`re.split(r'\s+', raw)`。
注意
**要點:** 記住在正則表達式前加字母`r`(表示"原始的"),它告訴 Python 解釋器按照字面表示對待字符串,而不去處理正則表達式中包含的反斜杠字符。
在空格符處分割文本給我們如`'(not'`和`'herself,'`這樣的詞符。另一種方法是使用 Python 提供給我們的字符類`\w`匹配詞中的字符,相當于`[a-zA-Z0-9_]`。它還定義了這個類的補集`\W`,即所有字母、數字和下劃線以外的字符。我們可以在一個簡單的正則表達式中用`\W`來分割所有單詞字符 _ 以外 _ 的輸入:
```py
>>> re.split(r'\W+', raw)
['', 'When', 'I', 'M', 'a', 'Duchess', 'she', 'said', 'to', 'herself', 'not', 'in',
'a', 'very', 'hopeful', 'tone', 'though', 'I', 'won', 't', 'have', 'any', 'pepper',
'in', 'my', 'kitchen', 'AT', 'ALL', 'Soup', 'does', 'very', 'well', 'without',
'Maybe', 'it', 's', 'always', 'pepper', 'that', 'makes', 'people', 'hot', 'tempered',
'']
```
可以看到,在開始和結尾都給了我們一個空字符串(要了解原因請嘗試`'xx'.split('x')`)。通過`re.findall(r'\w+', raw)`使用模式匹配詞匯而不是空白符號,我們得到相同的標識符,但沒有空字符串。現在,我們正在匹配詞匯,我們處在擴展正則表達式覆蓋更廣泛的情況的位置。正則表達式?`\w+|\S\w*`?將首先嘗試匹配詞中字符的所有序列。如果沒有找到匹配的,它會嘗試匹配后面跟著詞中字符的任何 _ 非 _ 空白字符(`\S`是`\s`的補)。這意味著標點會與跟在后面的字母(如's)在一起,但兩個或兩個以上的標點字符序列會被分割。
```py
>>> re.findall(r'\w+|\S\w*', raw)
["'When", 'I', "'M", 'a', 'Duchess', ',', "'", 'she', 'said', 'to', 'herself', ',',
'(not', 'in', 'a', 'very', 'hopeful', 'tone', 'though', ')', ',', "'I", 'won', "'t",
'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL', '.', 'Soup', 'does',
'very', 'well', 'without', '-', '-Maybe', 'it', "'s", 'always', 'pepper', 'that',
'makes', 'people', 'hot', '-tempered', ',', "'", '.', '.', '.']
```
讓我們擴展前面表達式中的`\w+`,允許連字符和撇號:?`\w+([-']\w+)*`?。這個表達式表示`\w+`后面跟零個或更多`[-']\w+`的實例;它會匹配 hot-tempered 和 it's。(我們需要在這個表達式中包含`?:`,原因前面已經討論過。)我們還將添加一個模式來匹配引號字符,讓它們與它們包括的文字分開。
```py
>>> print(re.findall(r"\w+(?:[-']\w+)*|'|[-.(]+|\S\w*", raw))
["'", 'When', "I'M", 'a', 'Duchess', ',', "'", 'she', 'said', 'to', 'herself', ',',
'(', 'not', 'in', 'a', 'very', 'hopeful', 'tone', 'though', ')', ',', "'", 'I',
"won't", 'have', 'any', 'pepper', 'in', 'my', 'kitchen', 'AT', 'ALL', '.', 'Soup',
'does', 'very', 'well', 'without', '--', 'Maybe', "it's", 'always', 'pepper',
'that', 'makes', 'people', 'hot-tempered', ',', "'", '...']
```
上面的表達式也包括?`[-.(]+`?,這會使雙連字符、省略號和左括號被單獨分詞。
[3.4](./ch03.html#tab-re-symbols)列出了我們已經在本節中看到的正則表達式字符類符號,以及一些其他有用的符號。
表 3.4:
正則表達式符號
```py
>>> text = 'That U.S.A. poster-print costs $12.40...'
>>> pattern = r'''(?x) # set flag to allow verbose regexps
... ([A-Z]\.)+ # abbreviations, e.g. U.S.A.
... | \w+(-\w+)* # words with optional internal hyphens
... | \$?\d+(\.\d+)?%? # currency and percentages, e.g. $12.40, 82%
... | \.\.\. # ellipsis
... | [][.,;"'?():-_`] # these are separate tokens; includes ], [
... '''
>>> nltk.regexp_tokenize(text, pattern)
['That', 'U.S.A.', 'poster-print', 'costs', '$12.40', '...']
```
使用 verbose 標志時,不可以再使用`' '`來匹配一個空格字符;使用`\s`代替。`regexp_tokenize()`函數有一個可選的`gaps`參數。設置為`True`時,正則表達式指定標識符間的距離,就像使用`re.split()`一樣。
注意
我們可以使用`set(tokens).difference(wordlist)`通過比較分詞結果與一個詞表,然后報告任何沒有在詞表出現的標識符,來評估一個分詞器。你可能想先將所有標記變成小寫。
### 分詞的進一步問題
分詞是一個比你可能預期的要更為艱巨的任務。沒有單一的解決方案能在所有領域都行之有效,我們必須根據應用領域的需要決定那些是詞符。
在開發分詞器時,訪問已經手工分詞的原始文本是有益的,這可以讓你的分詞器的輸出結果與高品質(或稱“黃金標準”)的詞符進行比較。NLTK 語料庫集合包括賓州樹庫的數據樣本,包括《華爾街日報》原始文本(`nltk.corpus.treebank_raw.raw()`)和分好詞的版本(`nltk.corpus.treebank.words()`)。
分詞的最后一個問題是縮寫的存在,如 didn't。如果我們想分析一個句子的意思,將這種形式規范化為兩個獨立的形式:did 和 n't(或 not)可能更加有用。我們可以通過查表來做這項工作。
## 3.8 分割
本節將討論更高級的概念,你在第一次閱讀本章時可能更愿意跳過本節。
分詞是一個更普遍的分割問題的一個實例。在本節中,我們將看到這個問題的另外兩個實例,它們使用與到目前為止我們已經在本章看到的完全不同的技術。
### 斷句
在詞級水平處理文本通常假定能夠將文本劃分成單個句子。正如我們已經看到,一些語料庫已經提供句子級別的訪問。在下面的例子中,我們計算布朗語料庫中每個句子的平均詞數:
```py
>>> len(nltk.corpus.brown.words()) / len(nltk.corpus.brown.sents())
20.250994070456922
```
在其他情況下,文本可能只是作為一個字符流。在將文本分詞之前,我們需要將它分割成句子。NLTK 通過包含 Punkt 句子分割器[(Kiss & Strunk, 2006)](./bibliography.html#kissstrunk2006)使得這個功能便于使用。這里是使用它為一篇小說文本斷句的例子。(請注意,如果在你讀到這篇文章時分割器內部數據已經更新過,你會看到不同的輸出):
```py
>>> text = nltk.corpus.gutenberg.raw('chesterton-thursday.txt')
>>> sents = nltk.sent_tokenize(text)
>>> pprint.pprint(sents[79:89])
['"Nonsense!"',
'said Gregory, who was very rational when anyone else\nattempted paradox.',
'"Why do all the clerks and navvies in the\n'
'railway trains look so sad and tired, so very sad and tired?',
'I will\ntell you.',
'It is because they know that the train is going right.',
'It\n'
'is because they know that whatever place they have taken a ticket\n'
'for that place they will reach.',
'It is because after they have\n'
'passed Sloane Square they know that the next station must be\n'
'Victoria, and nothing but Victoria.',
'Oh, their wild rapture!',
'oh,\n'
'their eyes like stars and their souls again in Eden, if the next\n'
'station were unaccountably Baker Street!"',
'"It is you who are unpoetical," replied the poet Syme.']
```
請注意,這個例子其實是一個單獨的句子,報道 Lucian Gregory 先生的演講。然而,引用的演講包含幾個句子,這些已經被分割成幾個單獨的字符串。這對于大多數應用程序是合理的行為。
斷句是困難的,因為句號會被用來標記縮寫而另一些句號同時標記縮寫和句子結束,就像發生在縮寫如 U.S.A.上的那樣。
斷句的另一種方法見[2](./ch06.html#sec-further-examples-of-supervised-classification)節。
### 分詞
對于一些書寫系統,由于沒有詞的可視邊界表示這一事實,文本分詞變得更加困難。例如,在中文中,三個字符的字符串:愛國人(ai4 “love” [verb], guo3 “country”,ren2 “person”) 可以被分詞為“愛國/人”,“country-loving person”,或者“愛/國人”,“love country-person”。
類似的問題在口語語言處理中也會出現,聽者必須將連續的語音流分割成單個的詞匯。當我們事先不認識這些詞時,這個問題就演變成一個特別具有挑戰性的版本。語言學習者會面對這個問題,例如小孩聽父母說話。考慮下面的人為構造的例子,單詞的邊界已被去除:
```py
>>> text = "doyouseethekittyseethedoggydoyoulikethekittylikethedoggy"
>>> seg1 = "0000000000000001000000000010000000000000000100000000000"
>>> seg2 = "0100100100100001001001000010100100010010000100010010000"
```
觀察由 0 和 1 組成的分詞表示字符串。它們比源文本短一個字符,因為長度為 n 文本可以在 n-1 個地方被分割。[3.7](./ch03.html#code-segment)中的`segment()`函數演示了我們可以從這個表示回到初始分詞的文本。
```py
def segment(text, segs):
words = []
last = 0
for i in range(len(segs)):
if segs[i] == '1':
words.append(text[last:i+1])
last = i+1
words.append(text[last:])
return words
```
現在分詞的任務變成了一個搜索問題:找到將文本字符串正確分割成詞匯的字位串。我們假定學習者接收詞,并將它們存儲在一個內部詞典中。給定一個合適的詞典,是能夠由詞典中的詞的序列來重構源文本的。根據[(Brent, 1995)](./bibliography.html#brent1995),我們可以定義一個目標函數,一個打分函數,我們將基于詞典的大小和從詞典中重構源文本所需的信息量盡力優化它的值。我們在[3.8](./ch03.html#fig-brent)中說明了這些。
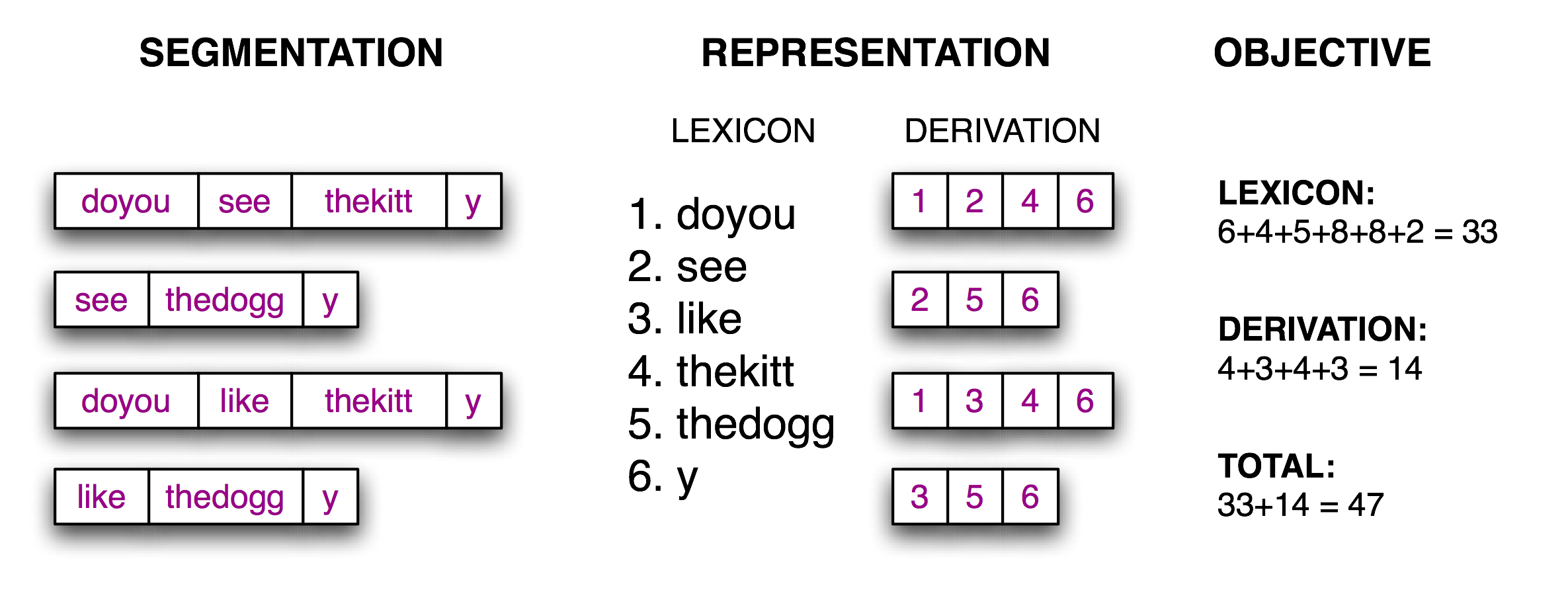
圖 3.8:計算目標函數:給定一個假設的源文本的分詞(左),推導出一個詞典和推導表,它能讓源文本重構,然后合計每個詞項(包括邊界標志)與推導表的字符數,作為分詞質量的得分;得分值越小表明分詞越好。
實現這個目標函數是很簡單的,如例子[3.9](./ch03.html#code-evaluate)所示。
```py
def evaluate(text, segs):
words = segment(text, segs)
text_size = len(words)
lexicon_size = sum(len(word) + 1 for word in set(words))
return text_size + lexicon_size
```
最后一步是尋找最小化目標函數值的 0 和 1 的模式,如[3.10](./ch03.html#code-anneal)所示。請注意,最好的分詞包括像 thekitty 這樣的“詞”,因為數據中沒有足夠的證據進一步分割這個詞。
```py
from random import randint
def flip(segs, pos):
return segs[:pos] + str(1-int(segs[pos])) + segs[pos+1:]
def flip_n(segs, n):
for i in range(n):
segs = flip(segs, randint(0, len(segs)-1))
return segs
def anneal(text, segs, iterations, cooling_rate):
temperature = float(len(segs))
while temperature > 0.5:
best_segs, best = segs, evaluate(text, segs)
for i in range(iterations):
guess = flip_n(segs, round(temperature))
score = evaluate(text, guess)
if score < best:
best, best_segs = score, guess
score, segs = best, best_segs
temperature = temperature / cooling_rate
print(evaluate(text, segs), segment(text, segs))
print()
return segs
```
有了足夠的數據,就可能以一個合理的準確度自動將文本分割成詞匯。這種方法可用于為那些詞的邊界沒有任何視覺表示的書寫系統分詞。
## 3.9 格式化:從列表到字符串
我們經常會寫程序來匯報一個單獨的數據項例如一個語料庫中滿足一些復雜的標準的特定的元素,或者一個單獨的總數統計例如一個詞計數器或一個標注器的性能。更多的時候,我們寫程序來產生一個結構化的結果;例如:一個數字或語言形式的表格,或原始數據的格式變換。當要表示的結果是語言時,文字輸出通常是最自然的選擇。然而當結果是數值時,可能最好是圖形輸出。在本節中,你將會學到呈現程序輸出的各種方式。
### 從列表到字符串
我們用于文本處理的最簡單的一種結構化對象是詞列表。當我們希望把這些輸出到顯示器或文件時,必須把這些詞列表轉換成字符串。在 Python 做這些,我們使用`join()`方法,并指定字符串作為使用的“膠水”。
```py
>>> silly = ['We', 'called', 'him', 'Tortoise', 'because', 'he', 'taught', 'us', '.']
>>> ' '.join(silly)
'We called him Tortoise because he taught us .'
>>> ';'.join(silly)
'We;called;him;Tortoise;because;he;taught;us;.'
>>> ''.join(silly)
'WecalledhimTortoisebecausehetaughtus.'
```
所以`' '.join(silly)`的意思是:取出`silly`中的所有項目,將它們連接成一個大的字符串,使用`' '`作為項目之間的間隔符。即`join()`是一個你想要用來作為膠水的字符串的一個方法。(許多人感到`join()`的這種表示方法是違反直覺的。)`join()`方法只適用于一個字符串的列表——我們一直把它叫做一個文本——在 Python 中享有某些特權的一個復雜類型。
### 字符串與格式
我們已經看到了有兩種方式顯示一個對象的內容:
```py
>>> word = 'cat'
>>> sentence = """hello
... world"""
>>> print(word)
cat
>>> print(sentence)
hello
world
>>> word
'cat'
>>> sentence
'hello\nworld'
```
`print`命令讓 Python 努力以人最可讀的形式輸出的一個對象的內容。第二種方法——叫做變量提示——向我們顯示可用于重新創建該對象的字符串。重要的是要記住這些都僅僅是字符串,為了你用戶的方便而顯示的。它們并不會給我們實際對象的內部表示的任何線索。
還有許多其他有用的方法來將一個對象作為字符串顯示。這可能是為了人閱讀的方便,或是因為我們希望導出我們的數據到一個特定的能被外部程序使用的文件格式。
格式化輸出通常包含變量和預先指定的字符串的一個組合,例如給定一個頻率分布`fdist`,我們可以這樣做:
```py
>>> fdist = nltk.FreqDist(['dog', 'cat', 'dog', 'cat', 'dog', 'snake', 'dog', 'cat'])
>>> for word in sorted(fdist):
... print(word, '->', fdist[word], end='; ')
cat -> 3; dog -> 4; snake -> 1;
```
輸出包含變量和常量交替出現的表達式是難以閱讀和維護的。一個更好的解決辦法是使用字符串格式化表達式。
```py
>>> for word in sorted(fdist):
... print('{}->{};'.format(word, fdist[word]), end=' ')
cat->3; dog->4; snake->1;
```
要了解這里發生了什么事情,讓我們在字符串格式化表達式上面測試一下。(現在,這將是你探索新語法的常用方法。)
```py
>>> '{}->{};'.format ('cat', 3)
'cat->3;'
```
花括號`'{}'`標記一個替換字段的出現:它作為傳遞給`str.format()`方法的對象的字符串值的占位符。我們可以將`'{}'`嵌入到一個字符串的內部,然后以適當的參數調用`format()`來讓字符串替換它們。包含替換字段的字符串叫做格式字符串。
讓我們更深入的解開這段代碼,以便更仔細的觀察它的行為:
```py
>>> '{}->'.format('cat')
'cat->'
>>> '{}'.format(3)
'3'
>>> 'I want a {} right now'.format('coffee')
'I want a coffee right now'
```
我們可以有任意個數目的占位符,但`str.format`方法必須以數目完全相同的參數來調用。
```py
>>> '{} wants a {} {}'.format ('Lee', 'sandwich', 'for lunch')
'Lee wants a sandwich for lunch'
>>> '{} wants a {} {}'.format ('sandwich', 'for lunch')
Traceback (most recent call last):
...
'{} wants a {} {}'.format ('sandwich', 'for lunch')
IndexError: tuple index out of range
```
從左向右取用給`format()`的參數,任何多余的參數都會被簡單地忽略。
System Message: ERROR/3 (`ch03.rst2`, line 2265)
Unexpected indentation.
```py
>>> '{} wants a {}'.format ('Lee', 'sandwich', 'for lunch')
'Lee wants a sandwich'
```
格式字符串中的替換字段可以以一個數值開始,它表示`format()`的位置參數。`'from {} to {}'`這樣的語句等同于`'from {0} to {1}'`,但是我們使用數字來得到非默認的順序:
```py
>>> 'from {1} to {0}'.format('A', 'B')
'from B to A'
```
我們還可以間接提供值給占位符。下面是使用`for`循環的一個例子:
```py
>>> template = 'Lee wants a {} right now'
>>> menu = ['sandwich', 'spam fritter', 'pancake']
>>> for snack in menu:
... print(template.format(snack))
...
Lee wants a sandwich right now
Lee wants a spam fritter right now
Lee wants a pancake right now
```
### 對齊
到目前為止,我們的格式化字符串可以在頁面(或屏幕)上輸出任意的寬度。我們可以通過插入一個冒號`':'`跟隨一個整數來添加空白以獲得指定寬帶的輸出。所以`{:6}`表示我們想讓字符串對齊到寬度 6。數字默認表示右對齊[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch03.html#right-justified),單我們可以在寬度指示符前面加上`'<'`對齊選項來讓數字左對齊[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch03.html#left-justified)。
```py
>>> '{:6}'.format(41) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
' 41'
>>> '{:<6}' .format(41) ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
'41 '
```
字符串默認是左對齊,但可以通過`'>'`對齊選項右對齊。
System Message: ERROR/3 (`ch03.rst2`, line 2313)
Unexpected indentation.
```py
>>> '{:6}'.format('dog') ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
'dog '
>>> '{:>6}'.format('dog') ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
' dog'
```
其它控制字符可以用于指定浮點數的符號和精度;例如`{:.4f}`表示浮點數的小數點后面應該顯示 4 個數字。
```py
>>> import math
>>> '{:.4f}'.format(math.pi)
'3.1416'
```
字符串格式化很聰明,能夠知道如果你包含一個`'%'`在你的格式化字符串中,那么你想表示這個值為百分數;不需要乘以 100。
```py
>>> count, total = 3205, 9375
>>> "accuracy for {} words: {:.4%}".format(total, count / total)
'accuracy for 9375 words: 34.1867%'
```
格式化字符串的一個重要用途是用于數據制表。回想一下,在[1](./ch02.html#sec-extracting-text-from-corpora)中,我們看到從條件頻率分布中制表的數據。讓我們自己來制表,行使對標題和列寬的完全控制,如[3.11](./ch03.html#code-modal-tabulate)所示。注意語言處理工作與結果制表之間是明確分離的。
```py
def tabulate(cfdist, words, categories):
print('{:16}'.format('Category'), end=' ') # column headings
for word in words:
print('{:>6}'.format(word), end=' ')
print()
for category in categories:
print('{:16}'.format(category), end=' ') # row heading
for word in words: # for each word
print('{:6}'.format(cfdist[category][word]), end=' ') # print table cell
print() # end the row
>>> from nltk.corpus import brown
>>> cfd = nltk.ConditionalFreqDist(
... (genre, word)
... for genre in brown.categories()
... for word in brown.words(categories=genre))
>>> genres = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor']
>>> modals = ['can', 'could', 'may', 'might', 'must', 'will']
>>> tabulate(cfd, modals, genres)
Category can could may might must will
news 93 86 66 38 50 389
religion 82 59 78 12 54 71
hobbies 268 58 131 22 83 264
science_fiction 16 49 4 12 8 16
romance 74 193 11 51 45 43
humor 16 30 8 8 9 13
```
回想一下[3.6](./ch03.html#code-stemmer-indexing)中的列表, 我們使用格式字符串`'{:{width}}'`并綁定一個值給 `format()`中的`width`參數。這我們使用變量知道字段的寬度。
```py
>>> '{:{width}}' % ("Monty Python", width=15)
'Monty Python '
```
我們可以使用`width = max(len(w) for w in words)`自動定制列的寬度,使其足夠容納所有的詞。
### 將結果寫入文件
我們已經看到了如何讀取文本文件([3.1](./ch03.html#sec-accessing-text))。將輸出寫入文件往往也很有用。下面的代碼打開可寫文件`output.txt`,將程序的輸出保存到文件。
```py
>>> output_file = open('output.txt', 'w')
>>> words = set(nltk.corpus.genesis.words('english-kjv.txt'))
>>> for word in sorted(words):
... print(word, file=output_file)
```
當我們將非文本數據寫入文件時,我們必須先將它轉換為字符串。正如我們前面所看到的,可以使用格式化字符串來做這一轉換。讓我們把總詞數寫入我們的文件:
```py
>>> len(words)
2789
>>> str(len(words))
'2789'
>>> print(str(len(words)), file=output_file)
```
小心!
你應該避免包含空格字符的文件名例如`output file.txt`,和除了大小寫外完全相同的文件名,例如`Output.txt`和`output.TXT`。
### 文本換行
當程序的輸出是文檔式的而不是像表格時,通常會有必要包裝一下以便可以方便地顯示它。考慮下面的輸出,它的行尾溢出了,且使用了一個復雜的`print`語句:
```py
>>> saying = ['After', 'all', 'is', 'said', 'and', 'done', ',',
... 'more', 'is', 'said', 'than', 'done', '.']
>>> for word in saying:
... print(word, '(' + str(len(word)) + '),', end=' ')
After (5), all (3), is (2), said (4), and (3), done (4), , (1), more (4), is (2), said (4), than (4), done (4), . (1),
```
我們可以在 Python 的`textwrap`模塊的幫助下采取換行。為了最大程度的清晰,我們將每一個步驟分在一行:
```py
>>> from textwrap import fill
>>> format = '%s (%d),'
>>> pieces = [format % (word, len(word)) for word in saying]
>>> output = ' '.join(pieces)
>>> wrapped = fill(output)
>>> print(wrapped)
After (5), all (3), is (2), said (4), and (3), done (4), , (1), more
(4), is (2), said (4), than (4), done (4), . (1),
```
請注意,在`more`與其下面的數字之間有一個換行符。如果我們希望避免這種情況,可以重新定義格式化字符串,使它不包含空格(例如`'%s_(%d),'`,然后不輸出`wrapped`的值,我們可以輸出`wrapped.replace('_', ' ')`。
## 3.10 小結
* 在本書中,我們將文本作為一個單詞列表。“原始文本”是一個潛在的長字符串,其中包含文字和用于設置格式的空白字符,也是我們通常存儲和可視化文本的方式。
* 在 Python 中指定一個字符串使用單引號或雙引號:`'Monty Python'`,`"Monty Python"`。
* 字符串中的字符是使用索引來訪問的,索引從零計數:`'Monty Python'[0]`給出的值是`M`。字符串的長度使用`len()`得到。
* 子字符串使用切片符號來訪問: `'Monty Python'[1:5]` 給出的值是`onty`。如果省略起始索引,子字符串從字符串的開始處開始;如果省略結尾索引,切片會一直到字符串的結尾處結束。
* 字符串可以被分割成列表:`'Monty Python'.split()`給出`['Monty', 'Python']`。列表可以連接成字符串:`'/'.join(['Monty', 'Python'])`給出`'Monty/Python'`。
* 我們可以使用`text = open('input.txt').read()`從一個文件`input.txt`讀取文本。可以使用`text = request.urlopen(url).read().decode('utf8')`從一個`url`讀取文本。我們可以使用`for line in open(f)`遍歷一個文本文件的每一行。
* 我們可以通過打開一個用于寫入的文件`output_file = open('output.txt', 'w')`來向文件寫入文本,然后添加內容到文件中`print("Monty Python", file=output_file)`。
* 在網上找到的文本可能包含不需要的內容(如頁眉、頁腳和標記),在我們做任何語言處理之前需要去除它們。
* 分詞是將文本分割成基本單位或詞符,例如詞和標點符號等。基于空格符的分詞對于許多應用程序都是不夠的,因為它會捆綁標點符號和詞。NLTK 提供了一個現成的分詞器`nltk.word_tokenize()`。
* 詞形歸并是一個過程,將一個詞的各種形式(如 appeared,appears)映射到這個詞標準的或引用的形式,也稱為詞位或詞元(如 appear)。
* 正則表達式是用來指定模式的一種強大而靈活的方法。一旦我們導入`re`模塊,我們就可以使用`re.findall()`來找到一個字符串中匹配一個模式的所有子字符串。
* 如果一個正則表達式字符串包含一個反斜杠,你應該使用帶有一個`r`前綴的原始字符串:`r'regexp'`,來告訴 Python 不要預處理這個字符串。
* 當某些字符前使用了反斜杠時,例如`\n`, 處理時會有特殊的含義(換行符);然而,當反斜杠用于正則表達式通配符和操作符之前時,如`\.`, `\|`, `\
* 一個字符串格式化表達式`template % arg_tuple`包含一個格式字符串`template`,它由如`%-6s`和`%0.2d`這樣的轉換標識符符組成。
## 7 深入閱讀
本章的附加材料發布在`http://nltk.org/`,包括網絡上免費提供的資源的鏈接。記得咨詢`http://docs.python.org/`上的的參考材料。(例如:此文檔涵蓋“通用換行符支持”,解釋了各種操作系統如何規定不同的換行符。)
更多的使用 NLTK 處理詞匯的例子請參閱`http://nltk.org/howto`上的分詞、詞干提取以及語料庫 HOWTO 文檔。[(Jurafsky & Martin, 2008)](./bibliography.html#jurafskymartin2008)的第 2、3 章包含正則表達式和形態學的更高級的材料。Python 文本處理更廣泛的討論請參閱[(Mertz, 2003)](./bibliography.html#mertz2003tpp)。規范非標準詞的信息請參閱[(Sproat et al, 2001)](./bibliography.html#sproat2001nor)
關于正則表達式的參考材料很多,無論是理論的還是實踐的。在 Python 中使用正則表達式的一個入門教程,請參閱 Kuchling 的 _Regular Expression HOWTO_,`http://www.amk.ca/python/howto/regex/`。關于使用正則表達式的全面而詳細的手冊,請參閱[(Friedl, 2002)](./bibliography.html#friedl2002mre),其中涵蓋包括 Python 在內大多數主要編程語言的語法。其他材料還包括[(Jurafsky & Martin, 2008)](./bibliography.html#jurafskymartin2008)的第 2.1 節,[(Mertz, 2003)](./bibliography.html#mertz2003tpp)的第 3 章。
網上有許多關于 Unicode 的資源。以下是與處理 Unicode 的 Python 的工具有關的有益的討論:
* Ned Batchelder, _Pragmatic Unicode_, `http://nedbatchelder.com/text/unipain.html`
* _Unicode HOWTO_, Python Documentation, `http://docs.python.org/3/howto/unicode.html`
* David Beazley, Mastering Python 3 I/O, `http://pyvideo.org/video/289/pycon-2010--mastering-python-3-i-o`
* Joel Spolsky, _The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)_, `http://www.joelonsoftware.com/articles/Unicode.html`
SIGHAN,ACL 中文語言處理特別興趣小組`http://sighan.org/`,重點關注中文文本分詞的問題。我們分割英文文本的方法依據[(Brent, 1995)](./bibliography.html#brent1995);這項工作屬于語言獲取領域[(Niyogi, 2006)](./bibliography.html#niyogi2006)。
搭配是多詞表達式的一種特殊情況。一個多詞表達式是一個小短語,僅從它的詞匯不能預測它的意義和其他屬性,例如 part of speech [(Baldwin & Kim, 2010)](./bibliography.html#baldwinkim2010)。
模擬退火是一種啟發式算法,找尋在一個大型的離散的搜索空間上的一個函數的最佳值的最好近似,基于對金屬冶煉中的退火的模擬。該技術在許多人工智能文本中都有描述。
[(Hearst, 1992)](./bibliography.html#hearst1992hyp)描述了使用如 x and other ys 的搜索模式發現文本中下位詞的方法。
## 3.12 練習
1. ? 定義一個字符串`s = 'colorless'`。寫一個 Python 語句將其變為“colourless”,只使用切片和連接操作。
2. ? 我們可以使用切片符號刪除詞匯形態上的結尾。例如,`'dogs'[:-1]`刪除了`dogs`的最后一個字符,留下`dog`。使用切片符號刪除下面這些詞的詞綴(我們插入了一個連字符指示詞綴的邊界,請在你的字符串中省略掉連字符): `dish-es`, `run-ning`, `nation-ality`, `un-do`, `pre-heat`。
3. ? 我們看到如何通過索引超出一個字符串的末尾產生一個`IndexError`。構造一個向左走的太遠走到字符串的前面的索引,這有可能嗎?
4. ? 我們可以為分片指定一個“步長”。下面的表達式間隔一個字符返回一個片內字符:`monty[6:11:2]`。也可以反向進行:`monty[10:5:-2]`。自己嘗試一下,然后實驗不同的步長。
5. ? 如果你讓解釋器處理`monty[::-1]`會發生什么?解釋為什么這是一個合理的結果。
6. ? 說明以下的正則表達式匹配的字符串類。
1. `[a-zA-Z]+`
2. `[A-Z][a-z]*`
3. `p[aeiou]{,2}t`
4. `\d+(\.\d+)?`
5. `([^aeiou][aeiou][^aeiou])*`
6. `\w+|[^\w\s]+`
使用`nltk.re_show()`測試你的答案。
7. ? 寫正則表達式匹配下面字符串類:
> 1. 一個單獨的限定符(假設只有 a, an 和 the 為限定符)。
> 2. 整數加法和乘法的算術表達式,如`2*3+8`。
8. ? 寫一個工具函數以 URL 為參數,返回刪除所有的 HTML 標記的 URL 的內容。使用`from urllib import request`和`request.urlopen('http://nltk.org/').read().decode('utf8')`來訪問 URL 的內容。
9. ? 將一些文字保存到文件`corpus.txt`。定義一個函數`load(f)`以要讀取的文件名為其唯一參數,返回包含文件中文本的字符串。
1. 使用`nltk.regexp_tokenize()`創建一個分詞器分割這個文本中的各種標點符號。使用一個多行的正則表達式,使用 verbose 標志`(?x)`帶有行內注釋。
2. 使用`nltk.regexp_tokenize()`創建一個分詞器分割以下幾種表達式:貨幣金額;日期;個人和組織的名稱。
10. ? 將下面的循環改寫為列表推導:
```py
>>> sent = ['The', 'dog', 'gave', 'John', 'the', 'newspaper']
>>> result = []
>>> for word in sent:
... word_len = (word, len(word))
... result.append(word_len)
>>> result
[('The', 3), ('dog', 3), ('gave', 4), ('John', 4), ('the', 3), ('newspaper', 9)]
```
11. ? 定義一個字符串`raw`包含你自己選擇的句子。現在,以空格以外的其它字符例如`'s'`分割`raw`。
12. ? 寫一個`for`循環輸出一個字符串的字符,每行一個。
13. ? 在字符串上調用不帶參數的`split`與以`' '`作為參數的區別是什么,即`sent.split()`與`sent.split(' ')`相比?當被分割的字符串包含制表符、連續的空格或一個制表符與空格的序列會發生什么?(在 IDLE 中你將需要使用`'\t'`來輸入制表符。)
14. ? 創建一個變量`words`,包含一個詞列表。實驗`words.sort()`和`sorted(words)`。它們有什么區別?
15. ? 通過在 Python 提示符輸入以下表達式,探索字符串和整數的區別:`"3" * 7`和`3 * 7`。嘗試使用`int("3")`和`str(3)`進行字符串和整數之間的轉換。
16. ? 使用文本編輯器創建一個文件`prog.py`,包含單獨的一行`monty = 'Monty Python'`。接下來,打開一個新的 Python 會話,并在提示符下輸入表達式`monty`。你會從解釋器得到一個錯誤。現在,請嘗試以下代碼(注意你要丟棄文件名中的`.py`):
```py
>>> from prog import monty
>>> monty
```
這一次,Python 應該返回一個值。你也可以嘗試`import prog`,在這種情況下,Python 應該能夠處理提示符處的表達式`prog.monty`。
17. ? 格式化字符串`%6s`與`%-6s`用來顯示長度大于 6 個字符的字符串時,會發生什么?
18. ? 閱讀語料庫中的一些文字,為它們分詞,輸出其中出現的所有 wh-類型詞的列表。(英語中的 wh-類型詞被用在疑問句,關系從句和感嘆句:who, which, what 等。)按順序輸出它們。在這個列表中有因為有大小寫或標點符號的存在而重復的詞嗎?
19. ? 創建一個文件,包含詞匯和(任意指定)頻率,其中每行包含一個詞,一個空格和一個正整數,如`fuzzy 53`。使用`open(filename).readlines()`將文件讀入一個 Python 列表。接下來,使用`split()`將每一行分成兩個字段,并使用`int()`將其中的數字轉換為一個整數。結果應該是一個列表形式:`[['fuzzy', 53], ...]`。
20. ? 編寫代碼來訪問喜愛的網頁,并從中提取一些文字。例如,訪問一個天氣網站,提取你所在的城市今天的最高溫度預報。
21. ? 寫一個函數`unknown()`,以一個 URL 為參數,返回一個那個網頁出現的未知詞列表。為了做到這一點,請提取所有由小寫字母組成的子字符串(使用`re.findall()`),并去除所有在 Words 語料庫(`nltk.corpus.words`)中出現的項目。嘗試手動分類這些詞,并討論你的發現。
22. ? 使用上面建議的正則表達式處理網址 `http://news.bbc.co.uk/`,檢查處理結果。你會看到那里仍然有相當數量的非文本數據,特別是 JavaScript 命令。你可能還會發現句子分割沒有被妥善保留。定義更深入的正則表達式,改善此網頁文本的提取。
23. ? 你能寫一個正則表達式以這樣的方式來分詞嗎,將詞 don't 分為 do 和 n't?解釋為什么這個正則表達式無法正常工作:?`n't|\w+`?。
24. ? 嘗試編寫代碼將文本轉換成 _hAck3r_,使用正則表達式和替換,其中`e` → `3`, `i` → `1`, `o` → `0`, `l` → `|`, `s` → `5`, `.`→ `5w33t!`, `ate` → `8`。在轉換之前將文本規范化為小寫。自己添加更多的替換。現在嘗試將`s`映射到兩個不同的值:詞開頭的`s`映射為`
25. ? _Pig Latin_ 是英語文本的一個簡單的變換。文本中每個詞的按如下方式變換:將出現在詞首的所有輔音(或輔音群)移到詞尾,然后添加 ay,例如 string → ingstray, idle → idleay。`http://en.wikipedia.org/wiki/Pig_Latin`
1. 寫一個函數轉換一個詞為 Pig Latin。
2. 寫代碼轉換文本而不是單個的詞。
3. 進一步擴展它,保留大寫字母,將`qu`保持在一起(例如這樣`quiet`會變成`ietquay`),并檢測`y`是作為一個輔音(如`yellow`)還是一個元音(如`style`)。
26. ? 下載一種包含元音和諧的語言(如匈牙利語)的一些文本,提取詞匯的元音序列,并創建一個元音二元語法表。
27. ? Python 的`random`模塊包括函數`choice()`,它從一個序列中隨機選擇一個項目,例如`choice("aehh ")`會產生四種可能的字符中的一個,字母`h`的幾率是其它字母的兩倍。寫一個表達式產生器,從字符串`"aehh "`產生 500 個隨機選擇的字母的序列,并將這個表達式寫入函數`''.join()`調用中,將它們連接成一個長字符串。你得到的結果應該看起來像失去控制的噴嚏或狂笑:`he haha ee heheeh eha`。使用`split()`和`join()`再次規范化這個字符串中的空格。
28. ? 考慮下面的摘自 MedLine 語料庫的句子中的數字表達式:The corresponding free cortisol fractions in these sera were 4.53 +/- 0.15% and 8.16 +/- 0.23%, respectively.我們應該說數字表達式 4.53 +/- 0.15%是三個詞嗎?或者我們應該說它是一個單獨的復合詞?或者我們應該說它實際上是 _ 九 _ 個詞,因為它讀作“four point five three,plus or minus fifteen percent”?或者我們應該說這不是一個“真正的”詞,因為它不會出現在任何詞典中?討論這些不同的可能性。你能想出產生這些答案中至少兩個以上可能性的應用領域嗎?
29. ? 可讀性測量用于為一個文本的閱讀難度打分,給語言學習者挑選適當難度的文本。在一個給定的文本中,讓我們定義μ<sub>w</sub>為每個詞的平均字母數,μ<sub>s</sub>為每個句子的平均詞數。文本自動可讀性指數(ARI)被定義為: `4.71` μ<sub>w</sub> `+ 0.5` μ<sub>s</sub> `- 21.43`。計算布朗語料庫各部分的 ARI 得分,包括 `f`(lore)和`j`(learned)部分。利用`nltk.corpus.brown.words()`產生一個詞匯序列,`nltk.corpus.brown.sents()`產生一個句子的序列的事實。
30. ? 使用 Porter 詞干提取器規范化一些已標注的文本,對每個詞調用提取詞干器。用 Lancaster 詞干提取器做同樣的事情,看看你是否能觀察到一些差別。
31. ? 定義變量`saying`包含列表`['After', 'all', 'is', 'said', 'and', 'done', ',', 'more', 'is', 'said', 'than', 'done', '.']`。使用`for`循環處理這個列表,并將結果存儲在一個新的鏈表`lengths` 中。提示:使用`lengths = []`,從分配一個空列表給`lengths`開始。然后每次循環中用`append()`添加另一個長度值到列表中。現在使用列表推導做同樣的事情。
32. ? 定義一個變量`silly`包含字符串:`'newly formed bland ideas are inexpressible in an infuriating way'`。(這碰巧是合法的解釋,講英語西班牙語雙語者可以適用于喬姆斯基著名的無意義短語,colorless green ideas sleep furiously,來自維基百科)。編寫代碼執行以下任務:
1. 分割`silly`為一個字符串列表,每一個詞一個字符串,使用 Python 的`split()`操作,并保存到叫做`bland`的變量中。
2. 提取`silly`中每個詞的第二個字母,將它們連接成一個字符串,得到`'eoldrnnnna'`'。
3. 使用`join()`將`bland`中的詞組合回一個單獨的字符串。確保結果字符串中的詞以空格隔開。
4. 按字母順序輸出`silly`中的詞,每行一個。
33. ? `index()`函數可用于查找序列中的項目。例如,`'inexpressible'.index('e')`告訴我們字母`e`的第一個位置的索引值。
1. 當你查找一個子字符串會發生什么,如`'inexpressible'.index('re')`?
2. 定義一個變量`words`,包含一個詞列表。現在使用`words.index()`來查找一個單獨的詞的位置。
3. 定義上一個練習中的變量`silly`。使用`index()`函數結合列表切片,建立一個包括`silly`中`in`之前(但不包括)的所有的詞的列表`phrase`。
34. ? 編寫代碼,將國家的形容詞轉換為它們對應的名詞形式,如將 Canadian 和 Australian 轉換為 Canada 和 Australia(見`http://en.wikipedia.org/wiki/List_of_adjectival_forms_of_place_names`)。
35. ? 閱讀 LanguageLog 中關于短語的 as best as p can 和 as best p can 形式的帖子,其中 p 是一個代名詞。在一個語料庫和[3.5](./ch03.html#sec-useful-applications-of-regular-expressions)中描述的搜索已標注的文本的`findall()`方法的幫助下,調查這一現象。`http://itre.cis.upenn.edu/~myl/languagelog/archives/002733.html`
36. ? 研究《創世記》的 lolcat 版本,使用`nltk.corpus.genesis.words('lolcat.txt')`可以訪問,和`http://www.lolcatbible.com/index.php?title=How_to_speak_lolcat`上將文本轉換為 lolspeak 的規則。定義正則表達式將英文詞轉換成相應的 lolspeak 詞。
37. ? 使用`help(re.sub)`和參照本章的深入閱讀,閱讀有關`re.sub()`函數來使用正則表達式進行字符串替換。使用`re.sub`編寫代碼從一個 HTML 文件中刪除 HTML 標記,規范化空格。
38. ★ 分詞的一個有趣的挑戰是已經被分割的跨行的詞。例如如果 _long-term_ 被分割,我們就得到字符串`long-\nterm`。
1. 寫一個正則表達式,識別連字符連結的跨行處的詞匯。這個表達式將需要包含`\n`字符。
2. 使用`re.sub()`從這些詞中刪除`\n`字符。
3. 你如何確定一旦換行符被刪除后不應該保留連字符的詞匯,如`'encyclo-\npedia'`?
39. ★ 閱讀維基百科 _Soundex_ 條目。用 Python 實現這個算法。
40. ★ 獲取兩個或多個文體的原始文本,計算它們各自的在前面關于閱讀難度的練習中描述的閱讀難度得分。例如,比較 ABC 農村新聞和 ABC 科學新聞(`nltk.corpus.abc`)。使用 Punkt 處理句子分割。
41. ★ 將下面的嵌套循環重寫為嵌套列表推導:
> ```py
> >>> words = ['attribution', 'confabulation', 'elocution',
> ... 'sequoia', 'tenacious', 'unidirectional']
> >>> vsequences = set()
> >>> for word in words:
> ... vowels = []
> ... for char in word:
> ... if char in 'aeiou':
> ... vowels.append(char)
> ... vsequences.add(''.join(vowels))
> >>> sorted(vsequences)
> ['aiuio', 'eaiou', 'eouio', 'euoia', 'oauaio', 'uiieioa']
> ```
42. ★ 使用 WordNet 為一個文本集合創建語義索引。擴展例[3.6](./ch03.html#code-stemmer-indexing)中的一致性搜索程序,使用它的第一個同義詞集偏移索引每個詞,例如`wn.synsets('dog')[0].offset`offset(或者使用上位詞層次中的一些祖先的偏移,這是可選的)。
43. ★ 在多語言語料庫如世界人權宣言語料庫(`nltk.corpus.udhr`),和 NLTK 的頻率分布和關系排序的功能(`nltk.FreqDist`, `nltk.spearman_correlation`)的幫助下,開發一個系統,猜測未知文本。為簡單起見,使用一個單一的字符編碼和少幾種語言。
44. ★ 寫一個程序處理文本,發現一個詞以一種新的意義被使用的情況。對于每一個詞計算這個詞所有同義詞集與這個詞的上下文的所有同義詞集之間的 WordNet 相似性。(請注意,這是一個粗略的辦法;要做的很好是困難的,開放性研究問題。)
45. ★ 閱讀關于規范化非標準詞的文章[(Sproat et al, 2001)](./bibliography.html#sproat2001nor),實現一個類似的文字規范系統。
關于本文檔...
針對 NLTK 3.0 作出更新。本章來自于 _Natural Language Processing with Python_,[Steven Bird](http://estive.net/), [Ewan Klein](http://homepages.inf.ed.ac.uk/ewan/) 和[Edward Loper](http://ed.loper.org/),Copyright ? 2014 作者所有。本章依據 _Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License_ [[http://creativecommons.org/licenses/by-nc-nd/3.0/us/](http://creativecommons.org/licenses/by-nc-nd/3.0/us/)] 條款,與 _ 自然語言工具包 _ [`http://nltk.org/`] 3.0 版一起發行。
本文檔構建于星期三 2015 年 7 月 1 日 12:30:05 AEST
