# 7\. 從文本提取信息
對于任何給定的問題,很可能已經有人把答案寫在某個地方了。以電子形式提供的自然語言文本的數量真的驚人,并且與日俱增。然而,自然語言的復雜性使訪問這些文本中的信息非常困難。NLP 目前的技術水平仍然有很長的路要走才能夠從不受限制的文本對意義建立通用的表示。如果我們不是集中我們的精力在問題或“實體關系”的有限集合,例如:“不同的設施位于何處”或“誰被什么公司雇用”上,我們就能取得重大進展。本章的目的是要回答下列問題:
1. 我們如何能構建一個系統,從非結構化文本中提取結構化數據如表格?
2. 有哪些穩健的方法識別一個文本中描述的實體和關系?
3. 哪些語料庫適合這項工作,我們如何使用它們來訓練和評估我們的模型?
一路上,我們將應用前面兩章中的技術來解決分塊和命名實體識別。
## 1 信息提取
信息有很多種形狀和大小。一個重要的形式是結構化數據:實體和關系的可預測的規范的結構。例如,我們可能對公司和地點之間的關系感興趣。給定一個公司,我們希望能夠確定它做業務的位置;反過來,給定位置,我們會想發現哪些公司在該位置做業務。如果我們的數據是表格形式,如[1.1](./ch07.html#tab-db-locations)中的例子,那么回答這些問題就很簡單了。
表 1.1:
位置數據
```py
>>> locs = [('Omnicom', 'IN', 'New York'),
... ('DDB Needham', 'IN', 'New York'),
... ('Kaplan Thaler Group', 'IN', 'New York'),
... ('BBDO South', 'IN', 'Atlanta'),
... ('Georgia-Pacific', 'IN', 'Atlanta')]
>>> query = [e1 for (e1, rel, e2) in locs if e2=='Atlanta']
>>> print(query)
['BBDO South', 'Georgia-Pacific']
```
表 1.2:
在亞特蘭大運營的公司
```py
>>> def ie_preprocess(document):
... sentences = nltk.sent_tokenize(document) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... sentences = [nltk.word_tokenize(sent) for sent in sentences] ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
... sentences = [nltk.pos_tag(sent) for sent in sentences] ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
```
注意
請記住我們的例子程序假設你以`import nltk, re, pprint`開始交互式會話或程序。
接下來,命名實體識別中,我們分割和標注可能組成一個有趣關系的實體。通常情況下,這些將被定義為名詞短語,例如 the knights who say "ni"或者適當的名稱如 Monty Python。在一些任務中,同時考慮不明確的名詞或名詞塊也是有用的,如<cite>every student</cite>或<cite>cats</cite>,這些不必要一定與確定的`NP`s 和適當名稱一樣的方式指示實體。
最后,在提取關系時,我們搜索對文本中出現在附近的實體對之間的特殊模式,并使用這些模式建立元組記錄實體之間的關系。
## 2 詞塊劃分
我們將用于實體識別的基本技術是詞塊劃分,它分割和標注多詞符的序列,如[2.1](./ch07.html#fig-chunk-segmentation)所示。小框顯示詞級分詞和詞性標注,大框顯示高級別的詞塊劃分。每個這種較大的框叫做一個詞塊。就像分詞忽略空白符,詞塊劃分通常選擇詞符的一個子集。同樣像分詞一樣,詞塊劃分器生成的片段在源文本中不能重疊。
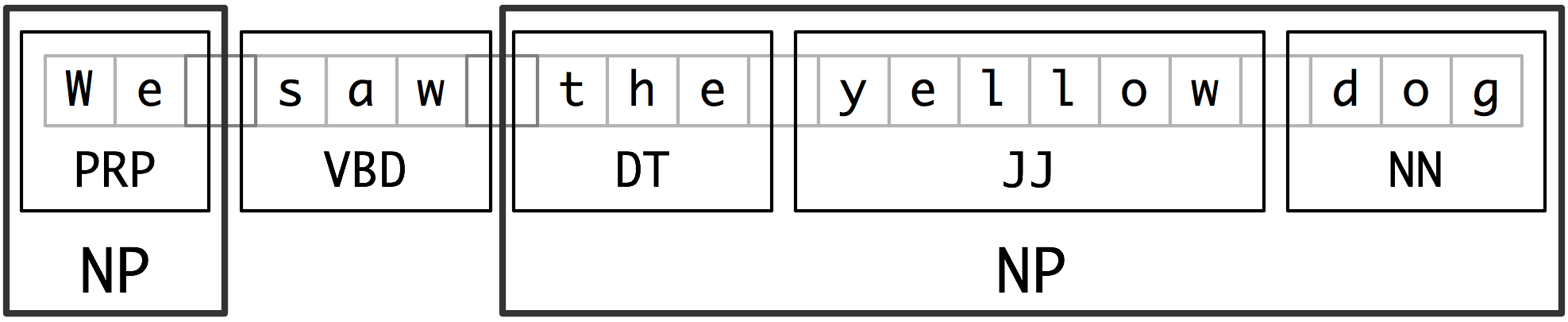
圖 2.1:詞符和詞塊級別的分割與標注
在本節中,我們將在較深的層面探討詞塊劃分,以詞塊的定義和表示開始。我們將看到正則表達式和 N-gram 的方法來詞塊劃分,使用 CoNLL-2000 詞塊劃分語料庫開發和評估詞塊劃分器。我們將在[(5)](./ch07.html#sec-ner)和[6](./ch07.html#sec-relextract)回到命名實體識別和關系抽取的任務。
## 2.1 名詞短語詞塊劃分
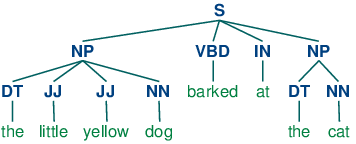
我們將首先思考名詞短語詞塊劃分或 NP 詞塊劃分任務,在那里我們尋找單獨名詞短語對應的詞塊。例如,這里是一些《華爾街日報》文本,其中的`NP`詞塊用方括號標記:
```py
>>> sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"), ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... ("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]
>>> grammar = "NP: {<DT>?<JJ>*<NN>}" ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> cp = nltk.RegexpParser(grammar) ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
>>> result = cp.parse(sentence) ![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)
>>> print(result) ![[5]](https://img.kancloud.cn/06/76/0676c0b71e61211d1e72c60abc3ea39e_15x15.jpg)
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))
>>> result.draw() ![[6]](https://img.kancloud.cn/97/d4/97d4ad210d7c27ce4f2986f9467d33e6_15x15.jpg)
```
## 2.2 標記模式
組成一個詞塊語法的規則使用標記模式來描述已標注的詞的序列。一個標記模式是一個詞性標記序列,用尖括號分隔,如`<DT>?<JJ>*<NN>`。標記模式類似于正則表達式模式([3.4](./ch03.html#sec-regular-expressions-word-patterns))。現在,思考下面的來自《華爾街日報》的名詞短語:
```py
another/DT sharp/JJ dive/NN
trade/NN figures/NNS
any/DT new/JJ policy/NN measures/NNS
earlier/JJR stages/NNS
Panamanian/JJ dictator/NN Manuel/NNP Noriega/NNP
```
## 2.3 用正則表達式進行詞塊劃分
要找到一個給定的句子的詞塊結構,`RegexpParser`詞塊劃分器以一個沒有詞符被劃分的平面結構開始。詞塊劃分規則輪流應用,依次更新詞塊結構。一旦所有的規則都被調用,返回生成的詞塊結構。
[2.3](./ch07.html#code-chunker1)顯示了一個由 2 個規則組成的簡單的詞塊語法。第一條規則匹配一個可選的限定詞或所有格代名詞,零個或多個形容詞,然后跟一個名詞。第二條規則匹配一個或多個專有名詞。我們還定義了一個進行詞塊劃分的例句[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch07.html#code-chunker1-ex),并在此輸入上運行這個詞塊劃分器[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch07.html#code-chunker1-run)。
```py
grammar = r"""
NP: {<DT|PP\$>?<JJ>*<NN>} # chunk determiner/possessive, adjectives and noun
{<NNP>+} # chunk sequences of proper nouns
"""
cp = nltk.RegexpParser(grammar)
sentence = [("Rapunzel", "NNP"), ("let", "VBD"), ("down", "RP"), ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
("her", "PP$"), ("long", "JJ"), ("golden", "JJ"), ("hair", "NN")]
```
注意
`
如果標記模式匹配位置重疊,最左邊的匹配優先。例如,如果我們應用一個匹配兩個連續的名詞文本的規則到一個包含三個連續的名詞的文本,則只有前兩個名詞將被劃分:
```py
>>> nouns = [("money", "NN"), ("market", "NN"), ("fund", "NN")]
>>> grammar = "NP: {<NN><NN>} # Chunk two consecutive nouns"
>>> cp = nltk.RegexpParser(grammar)
>>> print(cp.parse(nouns))
(S (NP money/NN market/NN) fund/NN)
```
一旦我們創建了 money market 詞塊,我們就已經消除了允許 fund 被包含在一個詞塊中的上下文。這個問題可以避免,使用一種更加寬容的塊規則,如`NP: {<NN>+}`。
注意
我們已經為每個塊規則添加了一個注釋。這些是可選的;當它們的存在時,詞塊劃分器將它作為其跟蹤輸出的一部分輸出這些注釋。
## 2.4 探索文本語料庫
在[2](./ch05.html#sec-tagged-corpora)中,我們看到了我們如何在已標注的語料庫中提取匹配的特定的詞性標記序列的短語。我們可以使用詞塊劃分器更容易的做同樣的工作,如下:
```py
>>> cp = nltk.RegexpParser('CHUNK: {<V.*> <TO> <V.*>}')
>>> brown = nltk.corpus.brown
>>> for sent in brown.tagged_sents():
... tree = cp.parse(sent)
... for subtree in tree.subtrees():
... if subtree.label() == 'CHUNK': print(subtree)
...
(CHUNK combined/VBN to/TO achieve/VB)
(CHUNK continue/VB to/TO place/VB)
(CHUNK serve/VB to/TO protect/VB)
(CHUNK wanted/VBD to/TO wait/VB)
(CHUNK allowed/VBN to/TO place/VB)
(CHUNK expected/VBN to/TO become/VB)
...
(CHUNK seems/VBZ to/TO overtake/VB)
(CHUNK want/VB to/TO buy/VB)
```
注意
**輪到你來:**將上面的例子封裝在函數`find_chunks()`內,以一個如`"CHUNK: {<V.*> <TO> <V.*>}"`的詞塊字符串作為參數。Use it to search the corpus for several other patterns, such as four or more nouns in a row, e.g. `"NOUNS: {<N.*>{4,}}"`
## 2.5 詞縫加塞
有時定義我們想從一個詞塊中排除什么比較容易。我們可以定義詞縫為一個不包含在詞塊中的一個詞符序列。在下面的例子中,`barked/VBD at/IN`是一個詞縫:
```py
[ the/DT little/JJ yellow/JJ dog/NN ] barked/VBD at/IN [ the/DT cat/NN ]
```
## 2.6 詞塊的表示:標記與樹
作為標注和分析之間的中間狀態([8.](./ch08.html#chap-parse),詞塊結構可以使用標記或樹來表示。最廣泛的文件表示使用 IOB 標記。在這個方案中,每個詞符被三個特殊的詞塊標記之一標注,`I`(內部),`O`(外部)或`B`(開始)。一個詞符被標注為`B`,如果它標志著一個詞塊的開始。塊內的詞符子序列被標注為`I`。所有其他的詞符被標注為`O`。`B`和`I`標記后面跟著詞塊類型,如`B-NP`, `I-NP`。當然,沒有必要指定出現在詞塊外的詞符類型,所以這些都只標注為`O`。這個方案的例子如[2.5](./ch07.html#fig-chunk-tagrep)所示。

圖 2.5:詞塊結構的標記表示形式
IOB 標記已成為文件中表示詞塊結構的標準方式,我們也將使用這種格式。下面是[2.5](./ch07.html#fig-chunk-tagrep)中的信息如何出現在一個文件中的:
```py
We PRP B-NP
saw VBD O
the DT B-NP
yellow JJ I-NP
dog NN I-NP
```
注意
NLTK 使用樹作為詞塊的內部表示,并提供這些樹與 IOB 格式互換的方法。
## 3 開發和評估詞塊劃分器
現在你對分塊的作用有了一些了解,但我們并沒有解釋如何評估詞塊劃分器。和往常一樣,這需要一個合適的已標注語料庫。我們一開始尋找將 IOB 格式轉換成 NLTK 樹的機制,然后是使用已化分詞塊的語料庫如何在一個更大的規模上做這個。我們將看到如何為一個詞塊劃分器相對一個語料庫的準確性打分,再看看一些數據驅動方式搜索 NP 詞塊。我們整個的重點在于擴展一個詞塊劃分器的覆蓋范圍。
## 3.1 讀取 IOB 格式與 CoNLL2000 語料庫
使用`corpus`模塊,我們可以加載已經標注并使用 IOB 符號劃分詞塊的《華爾街日報》文本。這個語料庫提供的詞塊類型有`NP`,`VP`和`PP`。正如我們已經看到的,每個句子使用多行表示,如下所示:
```py
he PRP B-NP
accepted VBD B-VP
the DT B-NP
position NN I-NP
...
```

我們可以使用 NLTK 的 corpus 模塊訪問較大量的已經劃分詞塊的文本。CoNLL2000 語料庫包含 27 萬詞的《華爾街日報文本》,分為“訓練”和“測試”兩部分,標注有詞性標記和 IOB 格式詞塊標記。我們可以使用`nltk.corpus.conll2000`訪問這些數據。下面是一個讀取語料庫的“訓練”部分的第 100 個句子的例子:
```py
>>> from nltk.corpus import conll2000
>>> print(conll2000.chunked_sents('train.txt')[99])
(S
(PP Over/IN)
(NP a/DT cup/NN)
(PP of/IN)
(NP coffee/NN)
,/,
(NP Mr./NNP Stone/NNP)
(VP told/VBD)
(NP his/PRP$ story/NN)
./.)
```
正如你看到的,CoNLL2000 語料庫包含三種詞塊類型:`NP`詞塊,我們已經看到了;`VP`詞塊如 has already delivered;`PP`塊如 because of。因為現在我們唯一感興趣的是`NP`詞塊,我們可以使用`chunk_types`參數選擇它們:
```py
>>> print(conll2000.chunked_sents('train.txt', chunk_types=['NP'])[99])
(S
Over/IN
(NP a/DT cup/NN)
of/IN
(NP coffee/NN)
,/,
(NP Mr./NNP Stone/NNP)
told/VBD
(NP his/PRP$ story/NN)
./.)
```
## 3.2 簡單的評估和基準
現在,我們可以訪問一個已劃分詞塊語料,可以評估詞塊劃分器。我們開始為沒有什么意義的詞塊解析器`cp`建立一個基準,它不劃分任何詞塊:
```py
>>> from nltk.corpus import conll2000
>>> cp = nltk.RegexpParser("")
>>> test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP'])
>>> print(cp.evaluate(test_sents))
ChunkParse score:
IOB Accuracy: 43.4%
Precision: 0.0%
Recall: 0.0%
F-Measure: 0.0%
```
IOB 標記準確性表明超過三分之一的詞被標注為`O`,即沒有在`NP`詞塊中。然而,由于我們的標注器沒有找到 _ 任何 _ 詞塊,其精度、召回率和 F-度量均為零。現在讓我們嘗試一個初級的正則表達式詞塊劃分器,查找以名詞短語標記的特征字母開頭的標記(如`CD`, `DT`和`JJ`)。
```py
>>> grammar = r"NP: {<[CDJNP].*>+}"
>>> cp = nltk.RegexpParser(grammar)
>>> print(cp.evaluate(test_sents))
ChunkParse score:
IOB Accuracy: 87.7%
Precision: 70.6%
Recall: 67.8%
F-Measure: 69.2%
```
正如你看到的,這種方法達到相當好的結果。但是,我們可以采用更多數據驅動的方法改善它,在這里我們使用訓練語料找到對每個詞性標記最有可能的塊標記(`I`, `O`或`B`)。換句話說,我們可以使用 _ 一元標注器 _([4](./ch05.html#sec-automatic-tagging))建立一個詞塊劃分器。但不是嘗試確定每個詞的正確的詞性標記,而是根據每個詞的詞性標記,嘗試確定正確的詞塊標記。
在[3.1](./ch07.html#code-unigram-chunker)中,我們定義了`UnigramChunker`類,使用一元標注器給句子加詞塊標記。這個類的大部分代碼只是用來在 NLTK 的`ChunkParserI`接口使用的詞塊樹表示和嵌入式標注器使用的 IOB 表示之間鏡像轉換。類定義了兩個方法:一個構造函數[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch07.html#code-unigram-chunker-constructor),當我們建立一個新的 UnigramChunker 時調用;以及`parse`方法[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch07.html#code-unigram-chunker-parse),用來給新句子劃分詞塊。
```py
class UnigramChunker(nltk.ChunkParserI):
def __init__(self, train_sents): ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
train_data = [[(t,c) for w,t,c in nltk.chunk.tree2conlltags(sent)]
for sent in train_sents]
self.tagger = nltk.UnigramTagger(train_data) ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
def parse(self, sentence): ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
pos_tags = [pos for (word,pos) in sentence]
tagged_pos_tags = self.tagger.tag(pos_tags)
chunktags = [chunktag for (pos, chunktag) in tagged_pos_tags]
conlltags = [(word, pos, chunktag) for ((word,pos),chunktag)
in zip(sentence, chunktags)]
return nltk.chunk.conlltags2tree(conlltags)
```
構造函數[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch07.html#code-unigram-chunker-constructor)需要訓練句子的一個列表,這將是詞塊樹的形式。它首先將訓練數據轉換成適合訓練標注器的形式,使用`tree2conlltags`映射每個詞塊樹到一個`word,tag,chunk`三元組的列表。然后使用轉換好的訓練數據訓練一個一元標注器,并存儲在`self.tagger`供以后使用。
`parse`方法[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch07.html#code-unigram-chunker-parse)接收一個已標注的句子作為其輸入,以從那句話提取詞性標記開始。它然后使用在構造函數中訓練過的標注器`self.tagger`,為詞性標記標注 IOB 詞塊標記。接下來,它提取詞塊標記,與原句組合,產生`conlltags`。最后,它使用`conlltags2tree`將結果轉換成一個詞塊樹。
現在我們有了`UnigramChunker`,可以使用 CoNLL2000 語料庫訓練它,并測試其表現:
```py
>>> test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP'])
>>> train_sents = conll2000.chunked_sents('train.txt', chunk_types=['NP'])
>>> unigram_chunker = UnigramChunker(train_sents)
>>> print(unigram_chunker.evaluate(test_sents))
ChunkParse score:
IOB Accuracy: 92.9%
Precision: 79.9%
Recall: 86.8%
F-Measure: 83.2%
```
這個分塊器相當不錯,達到整體 F-度量 83%的得分。讓我們來看一看通過使用一元標注器分配一個標記給每個語料庫中出現的詞性標記,它學到了什么:
```py
>>> postags = sorted(set(pos for sent in train_sents
... for (word,pos) in sent.leaves()))
>>> print(unigram_chunker.tagger.tag(postags))
[('#', 'B-NP'), ('$', 'B-NP'), ("''", 'O'), ('(', 'O'), (')', 'O'),
(',', 'O'), ('.', 'O'), (':', 'O'), ('CC', 'O'), ('CD', 'I-NP'),
('DT', 'B-NP'), ('EX', 'B-NP'), ('FW', 'I-NP'), ('IN', 'O'),
('JJ', 'I-NP'), ('JJR', 'B-NP'), ('JJS', 'I-NP'), ('MD', 'O'),
('NN', 'I-NP'), ('NNP', 'I-NP'), ('NNPS', 'I-NP'), ('NNS', 'I-NP'),
('PDT', 'B-NP'), ('POS', 'B-NP'), ('PRP', 'B-NP'), ('PRP$', 'B-NP'),
('RB', 'O'), ('RBR', 'O'), ('RBS', 'B-NP'), ('RP', 'O'), ('SYM', 'O'),
('TO', 'O'), ('UH', 'O'), ('VB', 'O'), ('VBD', 'O'), ('VBG', 'O'),
('VBN', 'O'), ('VBP', 'O'), ('VBZ', 'O'), ('WDT', 'B-NP'),
('WP', 'B-NP'), ('WP$', 'B-NP'), ('WRB', 'O'), ('``', 'O')]
```
它已經發現大多數標點符號出現在 NP 詞塊外,除了兩種貨幣符號`#`和`它也發現限定詞(`DT`)和所有格(`PRP
建立了一個一元分塊器,很容易建立一個二元分塊器:我們只需要改變類的名稱為`BigramChunker`,修改[3.1](./ch07.html#code-unigram-chunker)行[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch07.html#code-unigram-chunker-buildit)構造一個`BigramTagger`而不是`UnigramTagger`。由此產生的詞塊劃分器的性能略高于一元詞塊劃分器:
```py
>>> bigram_chunker = BigramChunker(train_sents)
>>> print(bigram_chunker.evaluate(test_sents))
ChunkParse score:
IOB Accuracy: 93.3%
Precision: 82.3%
Recall: 86.8%
F-Measure: 84.5%
```
## 3.3 訓練基于分類器的詞塊劃分器
無論是基于正則表達式的詞塊劃分器還是 n-gram 詞塊劃分器,決定創建什么詞塊完全基于詞性標記。然而,有時詞性標記不足以確定一個句子應如何劃分詞塊。例如,考慮下面的兩個語句:
```py
class ConsecutiveNPChunkTagger(nltk.TaggerI): ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
def __init__(self, train_sents):
train_set = []
for tagged_sent in train_sents:
untagged_sent = nltk.tag.untag(tagged_sent)
history = []
for i, (word, tag) in enumerate(tagged_sent):
featureset = npchunk_features(untagged_sent, i, history) ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
train_set.append( (featureset, tag) )
history.append(tag)
self.classifier = nltk.MaxentClassifier.train( ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
train_set, algorithm='megam', trace=0)
def tag(self, sentence):
history = []
for i, word in enumerate(sentence):
featureset = npchunk_features(sentence, i, history)
tag = self.classifier.classify(featureset)
history.append(tag)
return zip(sentence, history)
class ConsecutiveNPChunker(nltk.ChunkParserI): ![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)
def __init__(self, train_sents):
tagged_sents = [[((w,t),c) for (w,t,c) in
nltk.chunk.tree2conlltags(sent)]
for sent in train_sents]
self.tagger = ConsecutiveNPChunkTagger(tagged_sents)
def parse(self, sentence):
tagged_sents = self.tagger.tag(sentence)
conlltags = [(w,t,c) for ((w,t),c) in tagged_sents]
return nltk.chunk.conlltags2tree(conlltags)
```
留下來唯一需要填寫的是特征提取器。首先,我們定義一個簡單的特征提取器,它只是提供了當前詞符的詞性標記。使用此特征提取器,我們的基于分類器的詞塊劃分器的表現與一元詞塊劃分器非常類似:
```py
>>> def npchunk_features(sentence, i, history):
... word, pos = sentence[i]
... return {"pos": pos}
>>> chunker = ConsecutiveNPChunker(train_sents)
>>> print(chunker.evaluate(test_sents))
ChunkParse score:
IOB Accuracy: 92.9%
Precision: 79.9%
Recall: 86.7%
F-Measure: 83.2%
```
我們還可以添加一個特征表示前面詞的詞性標記。添加此特征允許詞塊劃分器模擬相鄰標記之間的相互作用,由此產生的詞塊劃分器與二元詞塊劃分器非常接近。
```py
>>> def npchunk_features(sentence, i, history):
... word, pos = sentence[i]
... if i == 0:
... prevword, prevpos = "<START>", "<START>"
... else:
... prevword, prevpos = sentence[i-1]
... return {"pos": pos, "prevpos": prevpos}
>>> chunker = ConsecutiveNPChunker(train_sents)
>>> print(chunker.evaluate(test_sents))
ChunkParse score:
IOB Accuracy: 93.6%
Precision: 81.9%
Recall: 87.2%
F-Measure: 84.5%
```
下一步,我們將嘗試為當前詞增加特征,因為我們假設這個詞的內容應該對詞塊劃有用。我們發現這個特征確實提高了詞塊劃分器的表現,大約 1.5 個百分點(相應的錯誤率減少大約 10%)。
```py
>>> def npchunk_features(sentence, i, history):
... word, pos = sentence[i]
... if i == 0:
... prevword, prevpos = "<START>", "<START>"
... else:
... prevword, prevpos = sentence[i-1]
... return {"pos": pos, "word": word, "prevpos": prevpos}
>>> chunker = ConsecutiveNPChunker(train_sents)
>>> print(chunker.evaluate(test_sents))
ChunkParse score:
IOB Accuracy: 94.5%
Precision: 84.2%
Recall: 89.4%
F-Measure: 86.7%
```
最后,我們嘗試用多種附加特征擴展特征提取器,例如預取特征[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch07.html#chunk-fe-lookahead)、配對特征[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch07.html#chunk-fe-paired)和復雜的語境特征[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch07.html#chunk-fe-complex)。這最后一個特征,稱為`tags-since-dt`,創建一個字符串,描述自最近的限定詞以來遇到的所有詞性標記,或如果沒有限定詞則在索引`i`之前自語句開始以來遇到的所有詞性標記。
```py
>>> def npchunk_features(sentence, i, history):
... word, pos = sentence[i]
... if i == 0:
... prevword, prevpos = "<START>", "<START>"
... else:
... prevword, prevpos = sentence[i-1]
... if i == len(sentence)-1:
... nextword, nextpos = "<END>", "<END>"
... else:
... nextword, nextpos = sentence[i+1]
... return {"pos": pos,
... "word": word,
... "prevpos": prevpos,
... "nextpos": nextpos, ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... "prevpos+pos": "%s+%s" % (prevpos, pos), ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
... "pos+nextpos": "%s+%s" % (pos, nextpos),
... "tags-since-dt": tags_since_dt(sentence, i)} ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
```
```py
>>> def tags_since_dt(sentence, i):
... tags = set()
... for word, pos in sentence[:i]:
... if pos == 'DT':
... tags = set()
... else:
... tags.add(pos)
... return '+'.join(sorted(tags))
```
```py
>>> chunker = ConsecutiveNPChunker(train_sents)
>>> print(chunker.evaluate(test_sents))
ChunkParse score:
IOB Accuracy: 96.0%
Precision: 88.6%
Recall: 91.0%
F-Measure: 89.8%
```
注意
**輪到你來:**嘗試為特征提取器函數`npchunk_features`增加不同的特征,看看是否可以進一步改善 NP 詞塊劃分器的表現。
## 4 語言結構中的遞歸
## 4.1 用級聯詞塊劃分器構建嵌套結構
到目前為止,我們的詞塊結構一直是相對平的。已標注詞符組成的樹在如`NP`這樣的詞塊節點下任意組合。然而,只需創建一個包含遞歸規則的多級的詞塊語法,就可以建立任意深度的詞塊結構。[4.1](./ch07.html#code-cascaded-chunker)是名詞短語、介詞短語、動詞短語和句子的模式。這是一個四級詞塊語法器,可以用來創建深度最多為 4 的結構。
```py
grammar = r"""
NP: {<DT|JJ|NN.*>+} # Chunk sequences of DT, JJ, NN
PP: {<IN><NP>} # Chunk prepositions followed by NP
VP: {<VB.*><NP|PP|CLAUSE>+$} # Chunk verbs and their arguments
CLAUSE: {<NP><VP>} # Chunk NP, VP
"""
cp = nltk.RegexpParser(grammar)
sentence = [("Mary", "NN"), ("saw", "VBD"), ("the", "DT"), ("cat", "NN"),
("sit", "VB"), ("on", "IN"), ("the", "DT"), ("mat", "NN")]
```
不幸的是,這一結果丟掉了 saw 為首的`VP`。它還有其他缺陷。當我們將此詞塊劃分器應用到一個有更深嵌套的句子時,讓我們看看會發生什么。請注意,它無法識別[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch07.html#saw-vbd)開始的`VP`詞塊。
```py
>>> sentence = [("John", "NNP"), ("thinks", "VBZ"), ("Mary", "NN"),
... ("saw", "VBD"), ("the", "DT"), ("cat", "NN"), ("sit", "VB"),
... ("on", "IN"), ("the", "DT"), ("mat", "NN")]
>>> print(cp.parse(sentence))
(S
(NP John/NNP)
thinks/VBZ
(NP Mary/NN)
saw/VBD # [_saw-vbd]
(CLAUSE
(NP the/DT cat/NN)
(VP sit/VB (PP on/IN (NP the/DT mat/NN)))))
```
這些問題的解決方案是讓詞塊劃分器在它的模式中循環:嘗試完所有模式之后,重復此過程。我們添加一個可選的第二個參數`loop`指定這套模式應該循環的次數:
```py
>>> cp = nltk.RegexpParser(grammar, loop=2)
>>> print(cp.parse(sentence))
(S
(NP John/NNP)
thinks/VBZ
(CLAUSE
(NP Mary/NN)
(VP
saw/VBD
(CLAUSE
(NP the/DT cat/NN)
(VP sit/VB (PP on/IN (NP the/DT mat/NN)))))))
```
注意
這個級聯過程使我們能創建深層結構。然而,創建和調試級聯過程是困難的,關鍵點是它能更有效地做全面的分析(見第[8.](./ch08.html#chap-parse)章)。另外,級聯過程只能產生固定深度的樹(不超過級聯級數),完整的句法分析這是不夠的。
## 4.2 Trees
tree 是一組連接的加標簽節點,從一個特殊的根節點沿一條唯一的路徑到達每個節點。下面是一棵樹的例子(注意它們標準的畫法是顛倒的):
```py
(S
(NP Alice)
(VP
(V chased)
(NP
(Det the)
(N rabbit))))
```
雖然我們將只集中關注語法樹,樹可以用來編碼任何同構的超越語言形式序列的層次結構(如形態結構、篇章結構)。一般情況下,葉子和節點值不一定要是字符串。
在 NLTK 中,我們通過給一個節點添加標簽和一系列的孩子創建一棵樹:
```py
>>> tree1 = nltk.Tree('NP', ['Alice'])
>>> print(tree1)
(NP Alice)
>>> tree2 = nltk.Tree('NP', ['the', 'rabbit'])
>>> print(tree2)
(NP the rabbit)
```
我們可以將這些不斷合并成更大的樹,如下所示:
```py
>>> tree3 = nltk.Tree('VP', ['chased', tree2])
>>> tree4 = nltk.Tree('S', [tree1, tree3])
>>> print(tree4)
(S (NP Alice) (VP chased (NP the rabbit)))
```
下面是樹對象的一些的方法:
```py
>>> print(tree4[1])
(VP chased (NP the rabbit))
>>> tree4[1].label()
'VP'
>>> tree4.leaves()
['Alice', 'chased', 'the', 'rabbit']
>>> tree4[1][1][1]
'rabbit'
```
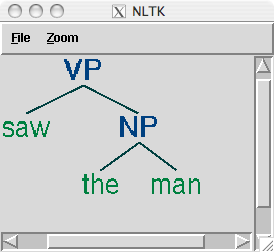
復雜的樹用括號表示難以閱讀。在這些情況下,`draw`方法是非常有用的。它會打開一個新窗口,包含樹的一個圖形表示。樹顯示窗口可以放大和縮小,子樹可以折疊和展開,并將圖形表示輸出為一個 postscript 文件(包含在一個文檔中)。
```py
>>> tree3.draw()
```
## 4.3 樹遍歷
使用遞歸函數來遍歷樹是標準的做法。[4.2](./ch07.html#code-traverse)中的內容進行了演示。
```py
def traverse(t):
try:
t.label()
except AttributeError:
print(t, end=" ")
else:
# Now we know that t.node is defined
print('(', t.label(), end=" ")
for child in t:
traverse(child)
print(')', end=" ")
>>> t = nltk.Tree('(S (NP Alice) (VP chased (NP the rabbit)))')
>>> traverse(t)
( S ( NP Alice ) ( VP chased ( NP the rabbit ) ) )
```
注意
我們已經使用了一種叫做動態類型的技術,檢測`t`是一棵樹(如定義了`t.label()`)。
## 5 命名實體識別
在本章開頭,我們簡要介紹了命名實體(NE)。命名實體是確切的名詞短語,指示特定類型的個體,如組織、人、日期等。[5.1](./ch07.html#tab-ne-types)列出了一些較常用的 NE 類型。這些應該是不言自明的,除了“FACILITY”:建筑和土木工程領域的人造產品;以及“GPE”:地緣政治實體,如城市、州/省、國家。
表 5.1:
常用命名實體類型
```py
Eddy N B-PER
Bonte N I-PER
is V O
woordvoerder N O
van Prep O
diezelfde Pron O
Hogeschool N B-ORG
. Punc O
```
```py
>>> print(nltk.ne_chunk(sent))
(S
The/DT
(GPE U.S./NNP)
is/VBZ
one/CD
...
according/VBG
to/TO
(PERSON Brooke/NNP T./NNP Mossman/NNP)
...)
```
## 6 關系抽取
一旦文本中的命名實體已被識別,我們就可以提取它們之間存在的關系。如前所述,我們通常會尋找指定類型的命名實體之間的關系。進行這一任務的方法之一是首先尋找所有 _X_, α, _Y_)形式的三元組,其中 _X_ 和 _Y_ 是指定類型的命名實體,α表示 _X_ 和 _Y_ 之間關系的字符串。然后我們可以使用正則表達式從α的實體中抽出我們正在查找的關系。下面的例子搜索包含詞 in 的字符串。特殊的正則表達式`(?!\b.+ing\b)`是一個否定預測先行斷言,允許我們忽略如 success in supervising the transition of 中的字符串,其中 in 后面跟一個動名詞。
```py
>>> IN = re.compile(r'.*\bin\b(?!\b.+ing)')
>>> for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
... for rel in nltk.sem.extract_rels('ORG', 'LOC', doc,
... corpus='ieer', pattern = IN):
... print(nltk.sem.rtuple(rel))
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia']
[ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo']
[ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington']
[ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington']
[ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles']
[ORG: 'Open Text'] ', based in' [LOC: 'Waterloo']
[ORG: 'WGBH'] 'in' [LOC: 'Boston']
[ORG: 'Bastille Opera'] 'in' [LOC: 'Paris']
[ORG: 'Omnicom'] 'in' [LOC: 'New York']
[ORG: 'DDB Needham'] 'in' [LOC: 'New York']
[ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York']
[ORG: 'BBDO South'] 'in' [LOC: 'Atlanta']
[ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']
```
搜索關鍵字 in 執行的相當不錯,雖然它的檢索結果也會誤報,例如`[ORG: House Transportation Committee] , secured the most money in the [LOC: New York]`;一種簡單的基于字符串的方法排除這樣的填充字符串似乎不太可能。
如前文所示,`conll2002`命名實體語料庫的荷蘭語部分不只包含命名實體標注,也包含詞性標注。這允許我們設計對這些標記敏感的模式,如下面的例子所示。`clause()`方法以分條形式輸出關系,其中二元關系符號作為參數`relsym`的值被指定[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch07.html#relsym)。
```py
>>> from nltk.corpus import conll2002
>>> vnv = """
... (
... is/V| # 3rd sing present and
... was/V| # past forms of the verb zijn ('be')
... werd/V| # and also present
... wordt/V # past of worden ('become)
... )
... .* # followed by anything
... van/Prep # followed by van ('of')
... """
>>> VAN = re.compile(vnv, re.VERBOSE)
>>> for doc in conll2002.chunked_sents('ned.train'):
... for r in nltk.sem.extract_rels('PER', 'ORG', doc,
... corpus='conll2002', pattern=VAN):
... print(nltk.sem.clause(r, relsym="VAN")) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
VAN("cornet_d'elzius", 'buitenlandse_handel')
VAN('johan_rottiers', 'kardinaal_van_roey_instituut')
VAN('annie_lennox', 'eurythmics')
```
注意
**輪到你來:**替換最后一行[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch07.html#relsym)為`print(rtuple(rel, lcon=True, rcon=True))`。這將顯示實際的詞表示兩個 NE 之間關系以及它們左右的默認 10 個詞的窗口的上下文。在一本荷蘭語詞典的幫助下,你也許能夠找出為什么結果`VAN('annie_lennox', 'eurythmics')`是個誤報。
## 7 小結
* 信息提取系統搜索大量非結構化文本,尋找特定類型的實體和關系,并用它們來填充有組織的數據庫。這些數據庫就可以用來尋找特定問題的答案。
* 信息提取系統的典型結構以斷句開始,然后是分詞和詞性標注。接下來在產生的數據中搜索特定類型的實體。最后,信息提取系統著眼于文本中提到的相互臨近的實體,并試圖確定這些實體之間是否有指定的關系。
* 實體識別通常采用詞塊劃分器,它分割多詞符序列,并用適當的實體類型給它們加標簽。常見的實體類型包括組織、人員、地點、日期、時間、貨幣、GPE(地緣政治實體)。
* 用基于規則的系統可以構建詞塊劃分器,例如 NLTK 中提供的`RegexpParser`類;或使用機器學習技術,如本章介紹的`ConsecutiveNPChunker`。在這兩種情況中,詞性標記往往是搜索詞塊時的一個非常重要的特征。
* 雖然詞塊劃分器專門用來建立相對平坦的數據結構,其中沒有任何兩個詞塊允許重疊,但它們可以被串聯在一起,建立嵌套結構。
* 關系抽取可以使用基于規則的系統,它通常查找文本中的連結實體和相關的詞的特定模式;或使用機器學習系統,通常嘗試從訓練語料自動學習這種模式。
## 8 深入閱讀
本章的附加材料發布在`http://nltk.org/`,包括網絡上免費提供的資源的鏈接。關于使用 NLTK 詞塊劃分的更多的例子,請看在`http://nltk.org/howto`上的詞塊劃分 HOWTO。
分塊的普及很大一部分是由于 Abney 的開創性的工作,如[(Church, Young, & Bloothooft, 1996)](./bibliography.html#abney1996pst)。`http://www.vinartus.net/spa/97a.pdf`中描述了 Abney 的 Cass 詞塊劃分器器。
根據 Ross 和 Tukey 在 1975 年的論文[(Church, Young, & Bloothooft, 1996)](./bibliography.html#abney1996pst),單詞詞縫最初的意思是一個停用詞序列。
IOB 格式(有時也稱為 BIO 格式)由[(Ramshaw & Marcus, 1995)](./bibliography.html#ramshaw1995tcu)開發用來`NP`劃分詞塊,并被由 _Conference on Natural Language Learning_ 在 1999 年用于`NP`加括號共享任務。CoNLL 2000 采用相同的格式標注了華爾街日報的文本作為一個`NP`詞塊劃分共享任務的一部分。
[(Jurafsky & Martin, 2008)](./bibliography.html#jurafskymartin2008)的 13.5 節包含有關詞塊劃分的一個討論。第 22 章講述信息提取,包括命名實體識別。有關生物學和醫學中的文本挖掘的信息,請參閱[(Ananiadou & McNaught, 2006)](./bibliography.html#ananiadou2006)。
## 9 練習
1. ? IOB 格式分類標注標識符為`I`、`O`和`B`。三個標簽為什么是必要的?如果我們只使用`I`和`O`標記會造成什么問題?
2. ? 寫一個標記模式匹配包含復數中心名詞在內的名詞短語,如"many/JJ researchers/NNS", "two/CD weeks/NNS", "both/DT new/JJ positions/NNS"。通過泛化處理單數名詞短語的標記模式,嘗試做這個。
3. ? 選擇 CoNLL 語料庫中三種詞塊類型之一。研究 CoNLL 語料庫,并嘗試觀察組成這種類型詞塊的詞性標記序列的任何模式。使用正則表達式詞塊劃分器`nltk.RegexpParser`開發一個簡單的詞塊劃分器。討論任何難以可靠劃分詞塊的標記序列。
4. ? _ 詞塊 _ 的早期定義是出現在詞縫之間的內容。開發一個詞塊劃分器以將完整的句子作為一個單獨的詞塊開始,然后其余的工作完全加塞詞縫完成。在你自己的應用程序的幫助下,確定哪些標記(或標記序列)最有可能組成詞縫。相對于完全基于詞塊規則的詞塊劃分器,比較這種方法的表現和易用性。
5. ? 寫一個標記模式,涵蓋包含動名詞在內的名詞短語,如"the/DT receiving/VBG end/NN", "assistant/NN managing/VBG editor/NN"。將這些模式加入到語法,每行一個。用自己設計的一些已標注的句子,測試你的工作。
6. ? 寫一個或多個標記模式處理有連接詞的名詞短語,如"July/NNP and/CC August/NNP", "all/DT your/PRP$ managers/NNS and/CC supervisors/NNS", "company/NN courts/NNS and/CC adjudicators/NNS"。
7. ? 用任何你之前已經開發的詞塊劃分器執行下列評估任務。(請注意,大多數詞塊劃分語料庫包含一些內部的不一致,以至于任何合理的基于規則的方法都將產生錯誤。)
1. 在來自詞塊劃分語料庫的 100 個句子上評估你的詞塊劃分器,報告精度、召回率和 F-量度。
2. 使用`chunkscore.missed()`和`chunkscore.incorrect()`方法識別你的詞塊劃分器的錯誤。討論。
3. 與本章的評估部分討論的基準詞塊劃分器比較你的詞塊劃分器的表現。
8. ? 使用基于正則表達式的詞塊語法`RegexpChunk`,為 CoNLL 語料庫中詞塊類型中的一個開發一個詞塊劃分器。使用詞塊、詞縫、合并或拆分規則的任意組合。
9. ? 有時一個詞的標注不正確,例如"12/CD or/CC so/RB cases/VBZ"中的中心名詞。不用要求手工校正標注器的輸出,好的詞塊劃分器使用標注器的錯誤輸出也能運作。查找使用不正確的標記正確為名詞短語劃分詞塊的其他例子。
10. ? 二元詞塊劃分器的準確性得分約為 90%。研究它的錯誤,并試圖找出它為什么不能獲得 100%的準確率。實驗三元詞塊劃分。你能夠再提高準確性嗎?
11. ★ 在 IOB 詞塊標注上應用 n-gram 和 Brill 標注方法。不是給詞分配詞性標記,在這里我們給詞性標記分配 IOB 標記。例如如果標記`DT`(限定符)經常出現在一個詞塊的開頭,它會被標注為`B`(開始)。相對于本章中講到的正則表達式詞塊劃分方法,評估這些詞塊劃分方法的表現。
12. ★ 在[5.](./ch05.html#chap-tag)中我們看到,通過查找有歧義的 n-grams 可以得到標注準確性的上限,即在訓練數據中有多種可能的方式標注的 n-grams。應用同樣的方法來確定一個 n-gram 詞塊劃分器的上限。
13. ★ 挑選 CoNLL 語料庫中三種詞塊類型之一。編寫函數為你選擇的類型做以下任務:
1. 列出與此詞塊類型的每個實例一起出現的所有標記序列。
2. 計數每個標記序列的頻率,并產生一個按頻率減少的順序排列的列表;每行要包含一個整數(頻率)和一個標記序列。
3. 檢查高頻標記序列。使用這些作為開發一個更好的詞塊劃分器的基礎。
14. ★ 在評估一節中提到的基準詞塊劃分器往往會產生比它應該產生的塊更大的詞塊。例如,短語`[every/DT time/NN] [she/PRP] sees/VBZ [a/DT newspaper/NN]`包含兩個連續的詞塊,我們的基準詞塊劃分器不正確地將前兩個結合: `[every/DT time/NN she/PRP]`。寫一個程序,找出這些通常出現在一個詞塊的開頭的詞塊內部的標記有哪些,然后設計一個或多個規則分裂這些詞塊。將這些與現有的基準詞塊劃分器組合,重新評估它,看看你是否已經發現了一個改進的基準。
15. ★ 開發一個`NP`詞塊劃分器,轉換 POS 標注文本為元組的一個列表,其中每個元組由一個后面跟一個名詞短語和介詞的動詞組成,如`the little cat sat on the mat`變成`('sat', 'on', 'NP')`...
16. ★ 賓州樹庫樣例包含一部分已標注的《華爾街日報》文本,已經按名詞短語劃分詞塊。其格式使用方括號,我們已經在本章遇到它了幾次。該語料可以使用`for sent in nltk.corpus.treebank_chunk.chunked_sents(fileid)`來訪問。這些都是平坦的樹,正如我們使用`nltk.corpus.conll2000.chunked_sents()`得到的一樣。
1. 函數`nltk.tree.pprint()`和`nltk.chunk.tree2conllstr()`可以用來從一棵樹創建樹庫和 IOB 字符串。編寫函數`chunk2brackets()`和`chunk2iob()`,以一個單獨的詞塊樹為它們唯一的參數,返回所需的多行字符串表示。
2. 寫命令行轉換工具`bracket2iob.py`和`iob2bracket.py`,(分別)讀取樹庫或 CoNLL 格式的一個文件,將它轉換為其他格式。(從 NLTK 語料庫獲得一些原始的樹庫或 CoNLL 數據,保存到一個文件,然后使用`for line in open(filename)`從 Python 訪問它。)
17. ★ 一個 n-gram 詞塊劃分器可以使用除當前詞性標記和 n-1 個前面的詞塊的標記以外其他信息。調查其他的上下文模型,如 n-1 個前面的詞性標記,或一個寫前面詞塊標記連同前面和后面的詞性標記的組合。
18. ★ 思考一個 n-gram 標注器使用臨近的標記的方式。現在觀察一個詞塊劃分器可能如何重新使用這個序列信息。例如:這兩個任務將使用名詞往往跟在形容詞后面(英文中)的信息。這會出現相同的信息被保存在兩個地方的情況。隨著規則集規模增長,這會成為一個問題嗎?如果是,推測可能會解決這個問題的任何方式。
關于本文檔...
針對 NLTK 3.0 作出更新。本章來自于 _Natural Language Processing with Python_,[Steven Bird](http://estive.net/), [Ewan Klein](http://homepages.inf.ed.ac.uk/ewan/) 和[Edward Loper](http://ed.loper.org/),Copyright ? 2014 作者所有。本章依據 _Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License_ [[http://creativecommons.org/licenses/by-nc-nd/3.0/us/](http://creativecommons.org/licenses/by-nc-nd/3.0/us/)] 條款,與 _ 自然語言工具包 _ [`http://nltk.org/`] 3.0 版一起發行。
本文檔構建于星期三 2015 年 7 月 1 日 12:30:05 AEST
