# 4 編寫結構化程序
現在,你對 Python 編程語言處理自然語言的能力已經有了體會。不過,如果你是 Python 或者編程新手,你可能仍然要努力對付 Python,而尚未感覺到你在完全控制它。在這一章中,我們將解決以下問題:
1. 怎么能寫出結構良好、可讀的程序,你和其他人將能夠很容易的重新使用它?
2. 基本結構塊,如循環、函數以及賦值,是如何執行的?
3. Python 編程的陷阱有哪些,你怎么能避免它們嗎?
一路上,你將鞏固基本編程結構的知識,了解更多關于以一種自然和簡潔的方式使用 Python 語言特征的內容,并學習一些有用的自然語言數據可視化技術。如前所述,本章包含許多例子和練習(和以前一樣,一些練習會引入新材料)。編程新手的讀者應仔細做完它們,并在需要時查詢其他編程介紹;有經驗的程序員可以快速瀏覽本章。
在這本書的其他章節中,為了講述 NLP 的需要,我們已經組織了一些編程的概念。在這里,我們回到一個更傳統的方法,材料更緊密的與編程語言的結構聯系在一起。這里不會完整的講述編程語言,我們只關注對 NLP 最重要的語言結構和習慣用法。
## 4.1 回到基礎
### 賦值
賦值似乎是最基本的編程概念,不值得單獨討論。不過,也有一些令人吃驚的微妙之處。思考下面的代碼片段:
```py
>>> foo = 'Monty'
>>> bar = foo ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> foo = 'Python' ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> bar
'Monty'
```
這個結果與預期的完全一樣。當我們在上面的代碼中寫`bar = foo`時[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#assignment1),`foo`的值(字符串`'Monty'`)被賦值給`bar`。也就是說,`bar`是`foo`的一個副本,所以當我們在第[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#assignment2)行用一個新的字符串`'Python'`覆蓋`foo`時,`bar`的值不會受到影響。
然而,賦值語句并不總是以這種方式復制副本。賦值總是一個表達式的值的復制,但值并不總是你可能希望的那樣。特別是結構化對象的“值”,例如一個列表,實際上是一個對象的引用。在下面的例子中,[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#assignment3)將`foo`的引用分配給新的變量`bar`。現在,當我們在[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#assignment4)行修改`foo`內的東西,我們可以看到`bar`的內容也已改變。
```py
>>> foo = ['Monty', 'Python']
>>> bar = foo ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> foo[1] = 'Bodkin' ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> bar
['Monty', 'Bodkin']
```
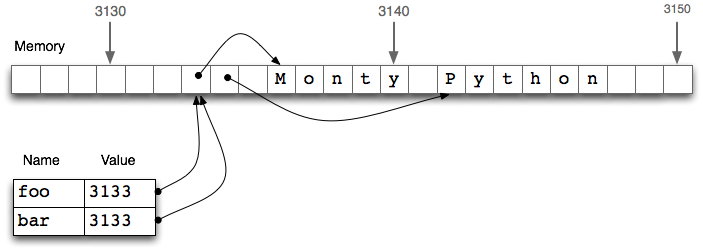
圖 4.1:列表賦值與計算機內存:兩個列表對象`foo`和`bar`引用計算機內存中的相同的位置;更新`foo`將同樣修改`bar`,反之亦然。
`bar = foo`[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#assignment3)行并不會復制變量的內容,只有它的“引用對象”。要了解這里發生了什么事,我們需要知道列表是如何存儲在計算機內存的。在[4.1](./ch04.html#fig-array-memory)中,我們看到一個列表`foo`是對存儲在位置 3133 處的一個對象的引用(它自身是一個指針序列,其中的指針指向其它保存字符串的位置)。當我們賦值`bar = foo`時,僅僅是 3133 位置處的引用被復制。這種行為延伸到語言的其他方面,如參數傳遞([4.4](./ch04.html#sec-functions))。
讓我們做更多的實驗,通過創建一個持有空列表的變量`empty`,然后在下一行使用它三次。
```py
>>> empty = []
>>> nested = [empty, empty, empty]
>>> nested
[[], [], []]
>>> nested[1].append('Python')
>>> nested
[['Python'], ['Python'], ['Python']]
```
請看,改變列表中嵌套列表內的一個項目,它們全改變了。這是因為三個元素中的每一個實際上都只是一個內存中的同一列表的引用。
注意
**輪到你來:** 用乘法創建一個列表的列表:`nested = [[]] * 3`。現在修改列表中的一個元素,觀察所有的元素都改變了。使用 Python 的`id()`函數找出任一對象的數字標識符, 并驗證`id(nested[0])`,`id(nested[1])`與`id(nested[2])`是一樣的。
現在請注意,當我們分配一個新值給列表中的一個元素時,它并不會傳送給其他元素:
```py
>>> nested = [[]] * 3
>>> nested[1].append('Python')
>>> nested[1] = ['Monty']
>>> nested
[['Python'], ['Monty'], ['Python']]
```
我們一開始用含有 3 個引用的列表,每個引用指向一個空列表對象。然后,我們通過給它追加`'Python'`修改這個對象,結果變成包含 3 個到一個列表對象`['Python']`的引用的列表。下一步,我們使用到一個新對象`['Monty']`的引用來 _ 覆蓋 _ 三個元素中的一個。這最后一步修改嵌套列表內的 3 個對象引用中的 1 個。然而,`['Python']`對象并沒有改變,仍然是在我們的嵌套列表的列表中的兩個位置被引用。關鍵是要明白通過一個對象引用修改一個對象與通過覆蓋一個對象引用之間的區別。
注意
**重要:** 要從列表`foo`復制項目到一個新的列表`bar`,你可以寫`bar = foo[:]`。這會復制列表中的對象引用。若要復制結構而不復制任何對象引用,請使用`copy.deepcopy()`。
### 等式
Python 提供兩種方法來檢查一對項目是否相同。`is`操作符測試對象的 ID。我們可以用它來驗證我們早先的對對象的觀察。首先,我們創建一個列表,其中包含同一對象的多個副本,證明它們不僅對于`==`完全相同,而且它們是同一個對象:
```py
>>> size = 5
>>> python = ['Python']
>>> snake_nest = [python] * size
>>> snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4]
True
>>> snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4]
True
```
現在,讓我們將一個新的 python 放入嵌套中。我們可以很容易地表明這些對象不完全相同:
```py
>>> import random
>>> position = random.choice(range(size))
>>> snake_nest[position] = ['Python']
>>> snake_nest
[['Python'], ['Python'], ['Python'], ['Python'], ['Python']]
>>> snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4]
True
>>> snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4]
False
```
你可以再做幾對測試,發現哪個位置包含闖入者,函數`id()`使檢測更加容易:
```py
>>> [id(snake) for snake in snake_nest]
[4557855488, 4557854763, 4557855488, 4557855488, 4557855488]
```
這表明列表中的第二個項目有一個獨特的標識符。如果你嘗試自己運行這段代碼,請期望看到結果列表中的不同數字,以及闖入者可能在不同的位置。
有兩種等式可能看上去有些奇怪。然而,這真的只是類型與標識符式的區別,與自然語言相似,這里在一種編程語言中呈現出來。
### 條件
在`if`語句的條件部分,一個非空字符串或列表被求值為真,而一個空字符串或列表的被求值為假。
```py
>>> mixed = ['cat', '', ['dog'], []]
>>> for element in mixed:
... if element:
... print(element)
...
cat
['dog']
```
也就是說,我們 _ 不必 _ 在條件中寫`if len(element) > 0:`。
使用`if...elif`而不是在一行中使用兩個`if`語句有什么區別?嗯,考慮以下情況:
```py
>>> animals = ['cat', 'dog']
>>> if 'cat' in animals:
... print(1)
... elif 'dog' in animals:
... print(2)
...
1
```
因為表達式中`if`子句條件滿足,Python 就不會求值`elif`子句,所以我們永遠不會得到輸出`2`。相反,如果我們用一個`if`替換`elif`,那么我們將會輸出`1`和`2`。所以`elif`子句比單獨的`if`子句潛在地給我們更多信息;當它被判定為真時,告訴我們不僅條件滿足而且前面的`if`子句條件 _ 不 _ 滿足。
`all()`函數和`any()`函數可以應用到一個列表(或其他序列),來檢查是否全部或任一項目滿足某個條件:
```py
>>> sent = ['No', 'good', 'fish', 'goes', 'anywhere', 'without', 'a', 'porpoise', '.']
>>> all(len(w) > 4 for w in sent)
False
>>> any(len(w) > 4 for w in sent)
True
```
## 4.2 序列
到目前為止,我們已經看到了兩種序列對象:字符串和列表。另一種序列被稱為元組。元組由逗號操作符[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#create-tuple)構造,而且通常使用括號括起來。實際上,我們已經在前面的章節中看到過它們,它們有時也被稱為“配對”,因為總是有兩名成員。然而,元組可以有任何數目的成員。與列表和字符串一樣,元組可以被索引[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#index-tuple)和切片[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch04.html#slice-tuple),并有長度[![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)](./ch04.html#length-tuple)。
```py
>>> t = 'walk', 'fem', 3 ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> t
('walk', 'fem', 3)
>>> t[0] ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
'walk'
>>> t[1:] ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
('fem', 3)
>>> len(t) ![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)
3
```
小心!
元組使用逗號操作符來構造。括號是一個 Python 語法的一般功能,設計用于分組。定義一個包含單個元素`'snark'`的元組是通過添加一個尾隨的逗號,像這樣:"`'snark',`"。空元組是一個特殊的情況下,使用空括號`()`定義。
讓我們直接比較字符串、列表和元組,在各個類型上做索引、切片和長度操作:
```py
>>> raw = 'I turned off the spectroroute'
>>> text = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> pair = (6, 'turned')
>>> raw[2], text[3], pair[1]
('t', 'the', 'turned')
>>> raw[-3:], text[-3:], pair[-3:]
('ute', ['off', 'the', 'spectroroute'], (6, 'turned'))
>>> len(raw), len(text), len(pair)
(29, 5, 2)
```
請注意在此代碼示例中,我們在一行代碼中計算多個值,中間用逗號分隔。這些用逗號分隔的表達式其實就是元組——如果沒有歧義,Python 允許我們忽略元組周圍的括號。當我們輸出一個元組時,括號始終顯示。通過以這種方式使用元組,我們隱式的將這些項目聚集在一起。
### 序列類型上的操作
我們可以用多種有用的方式遍歷一個序列`s`中的項目,如[4.1](./ch04.html#tab-python-sequence)所示。
表 4.1:
遍歷序列的各種方式
```py
>>> raw = 'Red lorry, yellow lorry, red lorry, yellow lorry.'
>>> text = word_tokenize(raw)
>>> fdist = nltk.FreqDist(text)
>>> sorted(fdist)
[',', '.', 'Red', 'lorry', 'red', 'yellow']
>>> for key in fdist:
... print(key + ':', fdist[key], end='; ')
...
lorry: 4; red: 1; .: 1; ,: 3; Red: 1; yellow: 2
```
在接下來的例子中,我們使用元組重新安排我們的列表中的內容。(可以省略括號,因為逗號比賦值的優先級更高。)
```py
>>> words = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> words[2], words[3], words[4] = words[3], words[4], words[2]
>>> words
['I', 'turned', 'the', 'spectroroute', 'off']
```
這是一種地道和可讀的移動列表內的項目的方式。它相當于下面的傳統方式不使用元組做上述任務(注意這種方法需要一個臨時變量`tmp`)。
```py
>>> tmp = words[2]
>>> words[2] = words[3]
>>> words[3] = words[4]
>>> words[4] = tmp
```
正如我們已經看到的,Python 有序列處理函數,如`sorted()`和`reversed()`,它們重新排列序列中的項目。也有修改序列結構的函數,可以很方便的處理語言。因此,`zip()`接收兩個或兩個以上的序列中的項目,將它們“壓縮”打包成單個的配對列表。給定一個序列`s`,`enumerate(s)`返回一個包含索引和索引處項目的配對。
```py
>>> words = ['I', 'turned', 'off', 'the', 'spectroroute']
>>> tags = ['noun', 'verb', 'prep', 'det', 'noun']
>>> zip(words, tags)
<zip object at ...>
>>> list(zip(words, tags))
[('I', 'noun'), ('turned', 'verb'), ('off', 'prep'),
('the', 'det'), ('spectroroute', 'noun')]
>>> list(enumerate(words))
[(0, 'I'), (1, 'turned'), (2, 'off'), (3, 'the'), (4, 'spectroroute')]
```
注意
只在需要的時候進行計算(或者叫做“惰性計算”特性),這是 Python 3 和 NLTK 3 的一個普遍特點。當你期望看到一個序列時,如果你看到的卻是類似`<zip object at 0x10d005448>`這樣的結果, 你可以強制求值這個對象,只要把它放在一個期望序列的上下文中,比如`list(`x`)`或`for item in` x。
對于一些 NLP 任務,有必要將一個序列分割成兩個或兩個以上的部分。例如,我們可能需要用 90%的數據來“訓練”一個系統,剩余 10%進行測試。要做到這一點,我們指定想要分割數據的位置[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#cut-location),然后在這個位置分割序列[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#cut-sequence)。
```py
>>> text = nltk.corpus.nps_chat.words()
>>> cut = int(0.9 * len(text)) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> training_data, test_data = text[:cut], text[cut:] ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> text == training_data + test_data ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
True
>>> len(training_data) / len(test_data) ![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)
9.0
```
我們可以驗證在此過程中的原始數據沒有丟失,也沒有重復[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch04.html#cut-preserve)。我們也可以驗證兩塊大小的比例是我們預期的[![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)](./ch04.html#cut-ratio)。
### 合并不同類型的序列
讓我們綜合關于這三種類型的序列的知識,一起使用列表推導處理一個字符串中的詞,按它們的長度排序。
```py
>>> words = 'I turned off the spectroroute'.split() ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> wordlens = [(len(word), word) for word in words] ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> wordlens.sort() ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
>>> ' '.join(w for (_, w) in wordlens) ![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)
'I off the turned spectroroute'
```
上述代碼段中每一行都包含一個顯著的特征。一個簡單的字符串實際上是一個其上定義了方法如`split()` [![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#string-object)的對象。我們使用列表推導建立一個元組的列表[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#tuple-comprehension),其中每個元組由一個數字(詞長)和這個詞組成,例如`(3, 'the')`。我們使用`sort()`方法[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch04.html#sort-method)就地排序列表。最后,丟棄長度信息,并將這些詞連接回一個字符串[![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)](./ch04.html#discard-length)。(下劃線[![[4]](https://img.kancloud.cn/cc/20/cc20c265de5e95a94eb351ef368f3277_15x15.jpg)](./ch04.html#discard-length)只是一個普通的 Python 變量,我們約定可以用下劃線表示我們不會使用其值的變量。)
我們開始談論這些序列類型的共性,但上面的代碼說明了這些序列類型的重要的區別。首先,字符串出現在開頭和結尾:這是很典型的,我們的程序先讀一些文本,最后產生輸出給我們看。列表和元組在中間,但使用的目的不同。一個鏈表是一個典型的具有相同類型的對象的序列,它的長度是任意的。我們經常使用列表保存詞序列。相反,一個元組通常是不同類型的對象的集合,長度固定。我們經常使用一個元組來保存一個紀錄,與一些實體相關的不同字段的集合。使用列表與使用元組之間的區別需要一些時間來習慣,所以這里是另一個例子:
```py
>>> lexicon = [
... ('the', 'det', ['Di:', 'D@']),
... ('off', 'prep', ['Qf', 'O:f'])
... ]
```
在這里,用一個列表表示詞典,因為它是一個單一類型的對象的集合——詞匯條目——沒有預定的長度。個別條目被表示為一個元組,因為它是一個有不同的解釋的對象的集合,例如正確的拼寫形式、詞性、發音(以 SAMPA 計算機可讀的拼音字母表示,`http://www.phon.ucl.ac.uk/home/sampa/`)。請注意,這些發音都是用列表存儲的。(為什么呢?)
注意
決定何時使用元組還是列表的一個好辦法是看一個項目的內容是否取決與它的位置。例如,一個已標注的詞標識符由兩個具有不同解釋的字符串組成,我們選擇解釋第一項為詞標識符,第二項為標注。因此,我們使用這樣的元組:`('grail', 'noun')`;一個形式為`('noun', 'grail')`的元組將是無意義的,因為這將是一個詞`noun`被標注為`grail`。相反,一個文本中的元素都是詞符, 位置并不重要。因此, 我們使用這樣的列表:`['venetian', 'blind']`;一個形式為`['blind', 'venetian']`的列表也同樣有效。詞的語言學意義可能會有所不同,但作為詞符的列表項的解釋是不變的。
列表和元組之間的使用上的區別已經講過了。然而,還有一個更加基本的區別:在 Python 中,列表是可變的,而元組是不可變的。換句話說,列表可以被修改,而元組不能。這里是一些在列表上的操作,就地修改一個列表。
```py
>>> lexicon.sort()
>>> lexicon[1] = ('turned', 'VBD', ['t3:nd', 't3`nd'])
>>> del lexicon[0]
```
注意
**輪到你來:**使用`lexicon = tuple(lexicon)`將`lexicon`轉換為一個元組,然后嘗試上述操作,確認它們都不能運用在元組上。
### 生成器表達式
我們一直在大量使用列表推導,因為用它處理文本結構緊湊和可讀性好。下面是一個例子,分詞和規范化一個文本:
```py
>>> text = '''"When I use a word," Humpty Dumpty said in rather a scornful tone,
... "it means just what I choose it to mean - neither more nor less."'''
>>> [w.lower() for w in word_tokenize(text)]
['``', 'when', 'i', 'use', 'a', 'word', ',', "''", 'humpty', 'dumpty', 'said', ...]
```
假設我們現在想要進一步處理這些詞。我們可以將上面的表達式插入到一些其他函數的調用中[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#max-comprehension),Python 允許我們省略方括號[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#max-generator)。
```py
>>> max([w.lower() for w in word_tokenize(text)]) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
'word'
>>> max(w.lower() for w in word_tokenize(text)) ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
'word'
```
第二行使用了生成器表達式。這不僅僅是標記方便:在許多語言處理的案例中,生成器表達式會更高效。在[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#max-comprehension)中,列表對象的存儲空間必須在 max()的值被計算之前分配。如果文本非常大的,這將會很慢。在[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#max-generator)中,數據流向調用它的函數。由于調用的函數只是簡單的要找最大值——按字典順序排在最后的詞——它可以處理數據流,而無需存儲迄今為止的最大值以外的任何值。
## 4.3 風格的問題
編程是作為一門科學的藝術。無可爭議的程序設計的“圣經”,Donald Knuth 的 2500 頁的多卷作品,叫做《計算機程序設計藝術》。已經有許多書籍是關于文學化編程的,它們認為人類,不只是電腦,必須閱讀和理解程序。在這里,我們挑選了一些編程風格的問題,它們對你的代碼的可讀性,包括代碼布局、程序與聲明的風格、使用循環變量都有重要的影響。
### Python 代碼風格
編寫程序時,你會做許多微妙的選擇:名稱、間距、注釋等等。當你在看別人編寫的代碼時,風格上的不必要的差異使其難以理解。因此,Python 語言的設計者發表了 Python 代碼風格指南,http`http://www.python.org/dev/peps/pep-0008/`。風格指南中提出的基本價值是一致性,目的是最大限度地提高代碼的可讀性。我們在這里簡要回顧一下它的一些主要建議,并請讀者閱讀完整的指南,里面有對實例的詳細的討論。
代碼布局中每個縮進級別應使用 4 個空格。你應該確保當你在一個文件中寫 Python 代碼時,避免使用 tab 縮進,因為它可能由于不同的文本編輯器的不同解釋而產生混亂。每行應少于 80 個字符長;如果必要的話,你可以在圓括號、方括號或花括號內換行,因為 Python 能夠探測到該行與下一行是連續的。如果你需要在圓括號、方括號或大括號中換行,通常可以添加額外的括號,也可以在行尾需要換行的地方添加一個反斜杠:
```py
>>> if (len(syllables) > 4 and len(syllables[2]) == 3 and
... syllables[2][2] in [aeiou] and syllables[2][3] == syllables[1][3]):
... process(syllables)
>>> if len(syllables) > 4 and len(syllables[2]) == 3 and \
... syllables[2][2] in [aeiou] and syllables[2][3] == syllables[1][3]:
... process(syllables)
```
注意
鍵入空格來代替制表符很快就會成為一件苦差事。許多程序編輯器內置對 Python 的支持,能自動縮進代碼,突出任何語法錯誤(包括縮進錯誤)。關于 Python 編輯器列表,請見`http://wiki.python.org/moin/PythonEditors`。
### 過程風格與聲明風格
我們剛才已經看到可以不同的方式執行相同的任務,其中蘊含著對執行效率的影響。另一個影響程序開發的因素是 _ 編程風格 _。思考下面的計算布朗語料庫中詞的平均長度的程序:
```py
>>> tokens = nltk.corpus.brown.words(categories='news')
>>> count = 0
>>> total = 0
>>> for token in tokens:
... count += 1
... total += len(token)
>>> total / count
4.401545438271973
```
在這段程序中,我們使用變量`count`跟蹤遇到的詞符的數量,`total`儲存所有詞的長度的總和。這是一個低級別的風格,與機器代碼,即計算機的 CPU 所執行的基本操作,相差不遠。兩個變量就像 CPU 的兩個寄存器,積累許多中間環節產生的值,和直到最才有意義的值。我們說,這段程序是以 _ 過程 _ 風格編寫,一步一步口授機器操作。現在,考慮下面的程序,計算同樣的事情:
```py
>>> total = sum(len(t) for t in tokens)
>>> print(total / len(tokens))
4.401...
```
第一行使用生成器表達式累加標示符的長度,第二行像前面一樣計算平均值。每行代碼執行一個完整的、有意義的工作,可以高級別的屬性,如:“`total`是標識符長度的總和”,的方式來理解。實施細節留給 Python 解釋器。第二段程序使用內置函數,在一個更抽象的層面構成程序;生成的代碼是可讀性更好。讓我們看一個極端的例子:
```py
>>> word_list = []
>>> i = 0
>>> while i < len(tokens):
... j = 0
... while j < len(word_list) and word_list[j] <= tokens[i]:
... j += 1
... if j == 0 or tokens[i] != word_list[j-1]:
... word_list.insert(j, tokens[i])
... i += 1
...
```
等效的聲明版本使用熟悉的內置函數,可以立即知道代碼的目的:
```py
>>> word_list = sorted(set(tokens))
```
另一種情況,對于每行輸出一個計數值,一個循環計數器似乎是必要的。然而,我們可以使用`enumerate()`處理序列`s`,為`s`中每個項目產生一個`(i, s[i])`形式的元組,以`(0, s[0])`開始。下面我們枚舉頻率分布的值,生成嵌套的`(rank, (word, count))`元組。按照產生排序項列表時的需要,輸出`rank+1`使計數從`1`開始。
```py
>>> fd = nltk.FreqDist(nltk.corpus.brown.words())
>>> cumulative = 0.0
>>> most_common_words = [word for (word, count) in fd.most_common()]
>>> for rank, word in enumerate(most_common_words):
... cumulative += fd.freq(word)
... print("%3d %6.2f%% %s" % (rank + 1, cumulative * 100, word))
... if cumulative > 0.25:
... break
...
1 5.40% the
2 10.42% ,
3 14.67% .
4 17.78% of
5 20.19% and
6 22.40% to
7 24.29% a
8 25.97% in
```
到目前為止,使用循環變量存儲最大值或最小值,有時很誘人。讓我們用這種方法找出文本中最長的詞。
```py
>>> text = nltk.corpus.gutenberg.words('milton-paradise.txt')
>>> longest = ''
>>> for word in text:
... if len(word) > len(longest):
... longest = word
>>> longest
'unextinguishable'
```
然而,一個更加清楚的解決方案是使用兩個列表推導,它們的形式現在應該很熟悉:
```py
>>> maxlen = max(len(word) for word in text)
>>> [word for word in text if len(word) == maxlen]
['unextinguishable', 'transubstantiate', 'inextinguishable', 'incomprehensible']
```
請注意,我們的第一個解決方案找到第一個長度最長的詞,而第二種方案找到 _ 所有 _ 最長的詞(通常是我們想要的)。雖然有兩個解決方案之間的理論效率的差異,主要的開銷是到內存中讀取數據;一旦數據準備好,第二階段處理數據可以瞬間高效完成。我們還需要平衡我們對程序的效率與程序員的效率的關注。一種快速但神秘的解決方案將是更難理解和維護的。
### 計數器的一些合理用途
在有些情況下,我們仍然要在列表推導中使用循環變量。例如:我們需要使用一個循環變量中提取列表中連續重疊的 n-grams:
```py
>>> sent = ['The', 'dog', 'gave', 'John', 'the', 'newspaper']
>>> n = 3
>>> [sent[i:i+n] for i in range(len(sent)-n+1)]
[['The', 'dog', 'gave'],
['dog', 'gave', 'John'],
['gave', 'John', 'the'],
['John', 'the', 'newspaper']]
```
確保循環變量范圍的正確相當棘手的。因為這是 NLP 中的常見操作,NLTK 提供了支持函數`bigrams(text)`、`trigrams(text)`和一個更通用的`ngrams(text, n)`。
下面是我們如何使用循環變量構建多維結構的一個例子。例如,建立一個 _m_ 行 _n_ 列的數組,其中每個元素是一個集合,我們可以使用一個嵌套的列表推導:
```py
>>> m, n = 3, 7
>>> array = [[set() for i in range(n)] for j in range(m)]
>>> array[2][5].add('Alice')
>>> pprint.pprint(array)
[[set(), set(), set(), set(), set(), set(), set()],
[set(), set(), set(), set(), set(), set(), set()],
[set(), set(), set(), set(), set(), {'Alice'}, set()]]
```
請看循環變量`i`和`j`在產生對象過程中沒有用到,它們只是需要一個語法正確的`for` 語句。這種用法的另一個例子,請看表達式`['very' for i in range(3)]`產生一個包含三個`'very'`實例的列表,沒有整數。
請注意,由于我們前面所討論的有關對象復制的原因,使用乘法做這項工作是不正確的。
```py
>>> array = [[set()] * n] * m
>>> array[2][5].add(7)
>>> pprint.pprint(array)
[[{7}, {7}, {7}, {7}, {7}, {7}, {7}],
[{7}, {7}, {7}, {7}, {7}, {7}, {7}],
[{7}, {7}, {7}, {7}, {7}, {7}, {7}]]
```
迭代是一個重要的編程概念。采取其他語言中的習慣用法是很誘人的。然而, Python 提供一些優雅和高度可讀的替代品,正如我們已經看到。
## 4.4 函數:結構化編程的基礎
函數提供了程序代碼打包和重用的有效途徑,已經在[3](./ch02.html#sec-reusing-code)中解釋過。例如,假設我們發現我們經常要從 HTML 文件讀取文本。這包括以下幾個步驟,打開文件,將它讀入,規范化空白符號,剝離 HTML 標記。我們可以將這些步驟收集到一個函數中,并給它一個名字,如`get_text()`,如[4.2](./ch04.html#code-get-text)所示。
```py
import re
def get_text(file):
"""Read text from a file, normalizing whitespace and stripping HTML markup."""
text = open(file).read()
text = re.sub(r'<.*?>', ' ', text)
text = re.sub('\s+', ' ', text)
return text
```
現在,任何時候我們想從一個 HTML 文件得到干凈的文字,都可以用文件的名字作為唯一的參數調用`get_text()`。它會返回一個字符串,我們可以將它指定給一個變量,例如:`contents = get_text("test.html")`。每次我們要使用這一系列的步驟,只需要調用這個函數。
使用函數可以為我們的程序節約空間。更重要的是,我們為函數選擇名稱可以提高程序 _ 可讀性 _。在上面的例子中,只要我們的程序需要從文件讀取干凈的文本,我們不必弄亂這四行代碼的程序,只需要調用`get_text()`。這種命名方式有助于提供一些“語義解釋”——它可以幫助我們的程序的讀者理解程序的“意思”。
請注意,上面的函數定義包含一個字符串。函數定義內的第一個字符串被稱為文檔字符串。它不僅為閱讀代碼的人記錄函數的功能,從文件加載這段代碼的程序員也能夠訪問:
```py
| >>> help(get_text)
| Help on function get_text in module __main__:
|
| get(text)
| Read text from a file, normalizing whitespace and stripping HTML markup.
```
我們首先定義函數的兩個參數,`msg`和`num` [![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#fun-def)。然后調用函數,并傳遞給它兩個參數,`monty`和`3` [![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#fun-call);這些參數填補了參數提供的“占位符”,為函數體中出現的`msg`和`num`提供值。
我們看到在下面的例子中不需要有任何參數:
```py
>>> def monty():
... return "Monty Python"
>>> monty()
'Monty Python'
```
函數通常會通過`return`語句將其結果返回給調用它的程序,正如我們剛才看到的。對于調用程序,它看起來就像函數調用已被函數結果替代,例如:
```py
>>> repeat(monty(), 3)
'Monty Python Monty Python Monty Python'
>>> repeat('Monty Python', 3)
'Monty Python Monty Python Monty Python'
```
一個 Python 函數并不是一定需要有一個 return 語句。有些函數做它們的工作的同時會附帶輸出結果、修改文件或者更新參數的內容。(這種函數在其他一些編程語言中被稱為“過程”)。
考慮以下三個排序函數。第三個是危險的,因為程序員可能沒有意識到它已經修改了給它的輸入。一般情況下,函數應該修改參數的內容(`my_sort1()`)或返回一個值(`my_sort2()`),而不是兩個都做(`my_sort3()`)。
```py
>>> def my_sort1(mylist): # good: modifies its argument, no return value
... mylist.sort()
>>> def my_sort2(mylist): # good: doesn't touch its argument, returns value
... return sorted(mylist)
>>> def my_sort3(mylist): # bad: modifies its argument and also returns it
... mylist.sort()
... return mylist
```
### 參數傳遞
早在[4.1](./ch04.html#sec-back-to-the-basics)節中,你就已經看到了賦值操作,而一個結構化對象的值是該對象的引用。函數也是一樣的。Python 按它的值來解釋函數的參數(這被稱為按值調用)。在下面的代碼中,`set_up()`有兩個參數,都在函數內部被修改。我們一開始將一個空字符串分配給`w`,將一個空列表分配給`p`。調用該函數后,`w`沒有變,而`p`改變了:
```py
>>> def set_up(word, properties):
... word = 'lolcat'
... properties.append('noun')
... properties = 5
...
>>> w = ''
>>> p = []
>>> set_up(w, p)
>>> w
''
>>> p
['noun']
```
請注意,`w`沒有被函數改變。當我們調用`set_up(w, p)`時,`w`(空字符串)的值被分配到一個新的變量`word`。在函數內部`word`值被修改。然而,這種變化并沒有傳播給`w`。這個參數傳遞過程與下面的賦值序列是一樣的:
```py
>>> w = ''
>>> word = w
>>> word = 'lolcat'
>>> w
''
```
讓我們來看看列表`p`上發生了什么。當我們調用`set_up(w, p)`,`p`的值(一個空列表的引用)被分配到一個新的本地變量`properties`,所以現在這兩個變量引用相同的內存位置。函數修改`properties`,而這種變化也反映在`p`值上,正如我們所看到的。函數也分配給 properties 一個新的值(數字`5`);這并不能修改該內存位置上的內容,而是創建了一個新的局部變量。這種行為就好像是我們做了下列賦值序列:
```py
>>> p = []
>>> properties = p
>>> properties.append('noun')
>>> properties = 5
>>> p
['noun']
```
因此,要理解 Python 按值傳遞參數,只要了解它是如何賦值的就足夠了。記住,你可以使用`id()`函數和`is`操作符來檢查每個語句執行之后你對對象標識符的理解。
### 變量的作用域
函數定義為變量創建了一個新的局部的作用域。當你在函數體內部分配一個新的變量時,這個名字只在該函數內部被定義。函數體外或者在其它函數體內,這個名字是不可見的。這一行為意味著你可以選擇變量名而不必擔心它與你的其他函數定義中使用的名稱沖突。
當你在一個函數體內部使用一個現有的名字時,Python 解釋器先嘗試按照函數本地的名字來解釋。如果沒有發現,解釋器檢查它是否是一個模塊內的全局名稱。最后,如果沒有成功,解釋器會檢查是否是 Python 內置的名字。這就是所謂的名稱解析的 LGB 規則:本地(local),全局(global),然后內置(built-in)。
小心!
一個函數可以使用`global`聲明創建一個新的全局變量。然而,這種做法應盡可能避免。在函數內部定義全局變量會導致上下文依賴性而限制函數的可移植性(或重用性)。一般來說,你應該使用參數作為函數的輸入,返回值作為函數的輸出。
### 參數類型檢查
我們寫程序時,Python 不會強迫我們聲明變量的類型,這允許我們定義參數類型靈活的函數。例如,我們可能希望一個標注只是一個詞序列,而不管這個序列被表示為一個列表、元組(或是迭代器,一種新的序列類型,超出了當前的討論范圍)。
然而,我們常常想寫一些能被他人利用的程序,并希望以一種防守的風格,當函數沒有被正確調用時提供有益的警告。下面的`tag()`函數的作者假設其參數將始終是一個字符串。
```py
>>> def tag(word):
... if word in ['a', 'the', 'all']:
... return 'det'
... else:
... return 'noun'
...
>>> tag('the')
'det'
>>> tag('knight')
'noun'
>>> tag(["'Tis", 'but', 'a', 'scratch']) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
'noun'
```
該函數對參數`'the'`和`'knight'`返回合理的值,傳遞給它一個列表[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#list-arg),看看會發生什么——它沒有抱怨,雖然它返回的結果顯然是不正確的。此函數的作者可以采取一些額外的步驟來確保`tag()`函數的參數`word`是一個字符串。一種直白的做法是使用`if not type(word) is str`檢查參數的類型,如果`word`不是一個字符串,簡單地返回 Python 特殊的空值`None`。這是一個略微的改善,因為該函數在檢查參數類型,并試圖對錯誤的輸入返回一個“特殊的”診斷結果。然而,它也是危險的,因為調用程序可能不會檢測`None`是故意設定的“特殊”值,這種診斷的返回值可能被傳播到程序的其他部分產生不可預測的后果。如果這個詞是一個 Unicode 字符串這種方法也會失敗。因為它的類型是`unicode`而不是`str`。這里有一個更好的解決方案,使用`assert`語句和 Python 的`basestring`的類型一起,它是`unicode`和`str`的共同類型。
```py
>>> def tag(word):
... assert isinstance(word, basestring), "argument to tag() must be a string"
... if word in ['a', 'the', 'all']:
... return 'det'
... else:
... return 'noun'
```
如果`assert`語句失敗,它會產生一個不可忽視的錯誤而停止程序執行。此外,該錯誤信息是容易理解的。程序中添加斷言能幫助你找到邏輯錯誤,是一種防御性編程。一個更根本的方法是在本節后面描述的使用文檔字符串為每個函數記錄參數的文檔。
### 功能分解
結構良好的程序通常都廣泛使用函數。當一個程序代碼塊增長到超過 10-20 行,如果將代碼分成一個或多個函數,每一個有明確的目的,這將對可讀性有很大的幫助。這類似于好文章被劃分成段,每段話表示一個主要思想。
函數提供了一種重要的抽象。它們讓我們將多個動作組合成一個單一的復雜的行動,并給它關聯一個名稱。(比較我們組合動作 go 和 bring back 為一個單一的更復雜的動作 fetch。)當我們使用函數時,主程序可以在一個更高的抽象水平編寫,使其結構更透明,例如
```py
>>> data = load_corpus()
>>> results = analyze(data)
>>> present(results)
```
適當使用函數使程序更具可讀性和可維護性。另外,重新實現一個函數已成為可能——使用更高效的代碼替換函數體——不需要關心程序的其余部分。
思考[4.3](./ch04.html#code-freq-words1)中`freq_words`函數。它更新一個作為參數傳遞進來的頻率分布的內容,并輸出前 n 個最頻繁的詞的列表。
```py
from urllib import request
from bs4 import BeautifulSoup
def freq_words(url, freqdist, n):
html = request.urlopen(url).read().decode('utf8')
raw = BeautifulSoup(html).get_text()
for word in word_tokenize(raw):
freqdist[word.lower()] += 1
result = []
for word, count in freqdist.most_common(n):
result = result + [word]
print(result)
```
這個函數有幾個問題。該函數有兩個副作用:它修改了第二個參數的內容,并輸出它已計算的結果的經過選擇的子集。如果我們在函數內部初始化`FreqDist()`對象(在它被處理的同一個地方),并且去掉選擇集而將結果顯示給調用程序的話,函數會更容易理解和更容易在其他地方重用。考慮到它的任務是找出頻繁的一個詞,它應該只應該返回一個列表,而不是整個頻率分布。在[4.4](./ch04.html#code-freq-words2)中,我們重構此函數,并通過去掉`freqdist`參數簡化其接口。
```py
from urllib import request
from bs4 import BeautifulSoup
def freq_words(url, n):
html = request.urlopen(url).read().decode('utf8')
text = BeautifulSoup(html).get_text()
freqdist = nltk.FreqDist(word.lower() for word in word_tokenize(text))
return [word for (word, _) in fd.most_common(n)]
```
`freq_words`函數的可讀性和可用性得到改進。
注意
我們將`_`用作變量名。這是對任何其他變量沒有什么不同,除了它向讀者發出信號,我們沒有使用它保存的信息。
### 編寫函數的文檔
如果我們已經將工作分解成函數分解的很好了,那么應該很容易使用通俗易懂的語言描述每個函數的目的,并且在函數的定義頂部的文檔字符串中提供這些描述。這個說明不應該解釋函數是如何實現的;實際上,應該能夠不改變這個說明,使用不同的方法,重新實現這個函數。
對于最簡單的函數,一個單行的文檔字符串通常就足夠了(見[4.2](./ch04.html#code-get-text))。你應該提供一個在一行中包含一個完整的句子的三重引號引起來的字符串。對于不尋常的函數,你還是應該在第一行提供一個一句話總結,因為很多的文檔字符串處理工具會索引這個字符串。它后面應該有一個空行,然后是更詳細的功能說明(見`http://www.python.org/dev/peps/pep-0257/`的文檔字符串約定的更多信息)。
文檔字符串可以包括一個 doctest 塊,說明使用的函數和預期的輸出。這些都可以使用 Python 的`docutils`模塊自動測試。文檔字符串應當記錄函數的每個參數的類型和返回類型。至少可以用純文本來做這些。然而,請注意,NLTK 使用 Sphinx 標記語言來記錄參數。這種格式可以自動轉換成富結構化的 API 文檔(見`http://nltk.org/`),并包含某些“字段”的特殊處理,例如`param`,允許清楚地記錄函數的輸入和輸出。[4.5](./ch04.html#code-sphinx)演示了一個完整的文檔字符串。
```py
def accuracy(reference, test):
"""
Calculate the fraction of test items that equal the corresponding reference items.
Given a list of reference values and a corresponding list of test values,
return the fraction of corresponding values that are equal.
In particular, return the fraction of indexes
{0<i<=len(test)} such that C{test[i] == reference[i]}.
>>> accuracy(['ADJ', 'N', 'V', 'N'], ['N', 'N', 'V', 'ADJ'])
0.5
:param reference: An ordered list of reference values
:type reference: list
:param test: A list of values to compare against the corresponding
reference values
:type test: list
:return: the accuracy score
:rtype: float
:raises ValueError: If reference and length do not have the same length
"""
if len(reference) != len(test):
raise ValueError("Lists must have the same length.")
num_correct = 0
for x, y in zip(reference, test):
if x == y:
num_correct += 1
return float(num_correct) / len(reference)
```
## 4.5 更多關于函數
本節將討論更高級的特性,你在第一次閱讀本章時可能更愿意跳過此節。
### 作為參數的函數
到目前為止,我們傳遞給函數的參數一直都是簡單的對象,如字符串或列表等結構化對象。Python 也允許我們傳遞一個函數作為另一個函數的參數。現在,我們可以抽象出操作,對相同數據進行不同操作。正如下面的例子表示的,我們可以傳遞內置函數`len()`或用戶定義的函數`last_letter()`作為另一個函數的參數:
```py
>>> sent = ['Take', 'care', 'of', 'the', 'sense', ',', 'and', 'the',
... 'sounds', 'will', 'take', 'care', 'of', 'themselves', '.']
>>> def extract_property(prop):
... return [prop(word) for word in sent]
...
>>> extract_property(len)
[4, 4, 2, 3, 5, 1, 3, 3, 6, 4, 4, 4, 2, 10, 1]
>>> def last_letter(word):
... return word[-1]
>>> extract_property(last_letter)
['e', 'e', 'f', 'e', 'e', ',', 'd', 'e', 's', 'l', 'e', 'e', 'f', 's', '.']
```
對象`len`和`last_letter`可以像列表和字典那樣被傳遞。請注意,只有在我們調用該函數時,才在函數名后使用括號;當我們只是將函數作為一個對象,括號被省略。
Python 提供了更多的方式來定義函數作為其他函數的參數,即所謂的 lambda 表達式。試想在很多地方沒有必要使用上述的`last_letter()`函數,因此沒有必要給它一個名字。我們可以等價地寫以下內容:
```py
>>> extract_property(lambda w: w[-1])
['e', 'e', 'f', 'e', 'e', ',', 'd', 'e', 's', 'l', 'e', 'e', 'f', 's', '.']
```
我們的下一個例子演示傳遞一個函數給`sorted()`函數。當我們用唯一的參數(需要排序的鏈表)調用后者,它使用內置的比較函數`cmp()`。然而,我們可以提供自己的排序函數,例如按長度遞減排序。
```py
>>> sorted(sent)
[',', '.', 'Take', 'and', 'care', 'care', 'of', 'of', 'sense', 'sounds',
'take', 'the', 'the', 'themselves', 'will']
>>> sorted(sent, cmp)
[',', '.', 'Take', 'and', 'care', 'care', 'of', 'of', 'sense', 'sounds',
'take', 'the', 'the', 'themselves', 'will']
>>> sorted(sent, lambda x, y: cmp(len(y), len(x)))
['themselves', 'sounds', 'sense', 'Take', 'care', 'will', 'take', 'care',
'the', 'and', 'the', 'of', 'of', ',', '.']
```
### 累計函數
這些函數以初始化一些存儲開始,迭代和處理輸入的數據,最后返回一些最終的對象(一個大的結構或匯總的結果)。做到這一點的一個標準的方式是初始化一個空鏈表,累計材料,然后返回這個鏈表,如[4.6](./ch04.html#code-search-examples)中所示函數`search1()`。
```py
def search1(substring, words):
result = []
for word in words:
if substring in word:
result.append(word)
return result
def search2(substring, words):
for word in words:
if substring in word:
yield word
```
函數`search2()`是一個生成器。第一次調用此函數,它運行到`yield`語句然后停下來。調用程序獲得第一個詞,完成任何必要的處理。一旦調用程序對另一個詞做好準備,函數會從停下來的地方繼續執行,直到再次遇到`yield`語句。這種方法通常更有效,因為函數只產生調用程序需要的數據,并不需要分配額外的內存來存儲輸出(參見前面關于生成器表達式的討論)。
下面是一個更復雜的生成器的例子,產生一個詞列表的所有排列。為了強制`permutations()`函數產生所有它的輸出,我們將它包裝在`list()`調用中[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#listperm)。
```py
>>> def permutations(seq):
... if len(seq) <= 1:
... yield seq
... else:
... for perm in permutations(seq[1:]):
... for i in range(len(perm)+1):
... yield perm[:i] + seq[0:1] + perm[i:]
...
>>> list(permutations(['police', 'fish', 'buffalo'])) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
[['police', 'fish', 'buffalo'], ['fish', 'police', 'buffalo'],
['fish', 'buffalo', 'police'], ['police', 'buffalo', 'fish'],
['buffalo', 'police', 'fish'], ['buffalo', 'fish', 'police']]
```
注意
`permutations`函數使用了一種技術叫遞歸,將在下面[4.7](./ch04.html#sec-algorithm-design)討論。產生一組詞的排列對于創建測試一個語法的數據十分有用([8.](./ch08.html#chap-parse))。
### 高階函數
Python 提供一些具有函數式編程語言如 Haskell 標準特征的高階函數。我們將在這里演示它們,與使用列表推導的相對應的表達一起。
讓我們從定義一個函數`is_content_word()`開始,它檢查一個詞是否來自一個開放的實詞類。我們使用此函數作為`filter()`的第一個參數,它對作為它的第二個參數的序列中的每個項目運用該函數,只保留該函數返回`True`的項目。
```py
>>> def is_content_word(word):
... return word.lower() not in ['a', 'of', 'the', 'and', 'will', ',', '.']
>>> sent = ['Take', 'care', 'of', 'the', 'sense', ',', 'and', 'the',
... 'sounds', 'will', 'take', 'care', 'of', 'themselves', '.']
>>> list(filter(is_content_word, sent))
['Take', 'care', 'sense', 'sounds', 'take', 'care', 'themselves']
>>> [w for w in sent if is_content_word(w)]
['Take', 'care', 'sense', 'sounds', 'take', 'care', 'themselves']
```
另一個高階函數是`map()`,將一個函數運用到一個序列中的每一項。它是我們在[4.5](./ch04.html#sec-doing-more-with-functions)看到的函數`extract_property()`的一個通用版本。這里是一個簡單的方法找出布朗語料庫新聞部分中的句子的平均長度,后面跟著的是使用列表推導計算的等效版本:
```py
>>> lengths = list(map(len, nltk.corpus.brown.sents(categories='news')))
>>> sum(lengths) / len(lengths)
21.75081116158339
>>> lengths = [len(sent) for sent in nltk.corpus.brown.sents(categories='news')]
>>> sum(lengths) / len(lengths)
21.75081116158339
```
在上面的例子中,我們指定了一個用戶定義的函數`is_content_word()` 和一個內置函數`len()`。我們還可以提供一個 lambda 表達式。這里是兩個等效的例子,計數每個詞中的元音的數量。
```py
>>> list(map(lambda w: len(filter(lambda c: c.lower() in "aeiou", w)), sent))
[2, 2, 1, 1, 2, 0, 1, 1, 2, 1, 2, 2, 1, 3, 0]
>>> [len(c for c in w if c.lower() in "aeiou") for w in sent]
[2, 2, 1, 1, 2, 0, 1, 1, 2, 1, 2, 2, 1, 3, 0]
```
列表推導為基礎的解決方案通常比基于高階函數的解決方案可讀性更好,我們在整個這本書的青睞于使用前者。
### 命名的參數
當有很多參數時,很容易混淆正確的順序。我們可以通過名字引用參數,甚至可以給它們分配默認值以供調用程序沒有提供該參數時使用。現在參數可以按任意順序指定,也可以省略。
```py
>>> def repeat(msg='<empty>', num=1):
... return msg * num
>>> repeat(num=3)
'<empty><empty><empty>'
>>> repeat(msg='Alice')
'Alice'
>>> repeat(num=5, msg='Alice')
'AliceAliceAliceAliceAlice'
```
這些被稱為關鍵字參數。如果我們混合使用這兩種參數,就必須確保未命名的參數在命名的參數前面。必須是這樣,因為未命名參數是根據位置來定義的。我們可以定義一個函數,接受任意數量的未命名和命名參數,并通過一個就地的參數列表`*args`和一個就地的關鍵字參數字典`**kwargs`來訪問它們。(字典將在[3](./ch05.html#sec-dictionaries)中講述。)
```py
>>> def generic(*args, **kwargs):
... print(args)
... print(kwargs)
...
>>> generic(1, "African swallow", monty="python")
(1, 'African swallow')
{'monty': 'python'}
```
當`*args`作為函數參數時,它實際上對應函數所有的未命名參數。下面是另一個這方面的 Python 語法的演示,處理可變數目的參數的函數`zip()`。我們將使用變量名`*song`來表示名字`*args`并沒有什么特別的。
```py
>>> song = [['four', 'calling', 'birds'],
... ['three', 'French', 'hens'],
... ['two', 'turtle', 'doves']]
>>> list(zip(song[0], song[1], song[2]))
[('four', 'three', 'two'), ('calling', 'French', 'turtle'), ('birds', 'hens', 'doves')]
>>> list(zip(*song))
[('four', 'three', 'two'), ('calling', 'French', 'turtle'), ('birds', 'hens', 'doves')]
```
應該從這個例子中明白輸入`*song`僅僅是一個方便的記號,相當于輸入了`song[0], song[1], song[2]`。
下面是另一個在函數的定義中使用關鍵字參數的例子,有三種等效的方法來調用這個函數:
```py
>>> def freq_words(file, min=1, num=10):
... text = open(file).read()
... tokens = word_tokenize(text)
... freqdist = nltk.FreqDist(t for t in tokens if len(t) >= min)
... return freqdist.most_common(num)
>>> fw = freq_words('ch01.rst', 4, 10)
>>> fw = freq_words('ch01.rst', min=4, num=10)
>>> fw = freq_words('ch01.rst', num=10, min=4)
```
命名參數的另一個作用是它們允許選擇性使用參數。因此,我們可以在我們高興使用默認值的地方省略任何參數:`freq_words('ch01.rst', min=4)`, `freq_words('ch01.rst', 4)`。可選參數的另一個常見用途是作為標志使用。這里是同一個的函數的修訂版本,如果設置了`verbose`標志將會報告其進展情況:
```py
>>> def freq_words(file, min=1, num=10, verbose=False):
... freqdist = FreqDist()
... if verbose: print("Opening", file)
... text = open(file).read()
... if verbose: print("Read in %d characters" % len(file))
... for word in word_tokenize(text):
... if len(word) >= min:
... freqdist[word] += 1
... if verbose and freqdist.N() % 100 == 0: print(".", sep="")
... if verbose: print
... return freqdist.most_common(num)
```
小心!
注意不要使用可變對象作為參數的默認值。這個函數的一系列調用將使用同一個對象,有時會出現離奇的結果,就像我們稍后會在關于調試的討論中看到的那樣。
小心!
如果你的程序將使用大量的文件,它是一個好主意來關閉任何一旦不再需要的已經打開的文件。如果你使用`with`語句,Python 會自動關閉打開的文件︰
```py
>>> with open("lexicon.txt") as f:
... data = f.read()
... # process the data
```
## 4.6 程序開發
編程是一種技能,需要獲得幾年的各種編程語言和任務的經驗。關鍵的高層次能力是 _ 算法設計 _ 及其在 _ 結構化編程 _ 中的實現。關鍵的低層次的能力包括熟悉語言的語法結構,以及排除故障的程序(不能表現預期的行為的程序)的各種診斷方法的知識。
本節描述一個程序模塊的內部結構,以及如何組織一個多模塊的程序。然后描述程序開發過程中出現的各種錯誤,你可以做些什么來解決這些問題,更好的是,從一開始就避免它們。
### Python 模塊的結構
程序模塊的目的是把邏輯上相關的定義和函數結合在一起,以方便重用和更高層次的抽象。Python 模塊只是一些單獨的`.py`文件。例如,如果你在處理一種特定的語料格式,讀取和寫入這種格式的函數可以放在一起。這兩種格式所使用的常量,如字段分隔符或一個`EXTN = ".inf"`文件擴展名,可以共享。如果要更新格式,你就會知道只有一個文件需要改變。類似地,一個模塊可以包含用于創建和操縱一種特定的數據結構如語法樹的代碼,或執行特定的處理任務如繪制語料統計圖表的代碼。
當你開始編寫 Python 模塊,有一些例子來模擬是有益的。你可以使用變量`__file__`定位你的系統中任一 NLTK 模塊的代碼,例如:
```py
>>> nltk.metrics.distance.__file__
'/usr/lib/python2.5/site-packages/nltk/metrics/distance.pyc'
```
這將返回模塊已編譯`.pyc`文件的位置,在你的機器上你可能看到的位置不同。你需要打開的文件是對應的`.py`源文件,它和`.pyc`文件放在同一目錄下。另外,你可以在網站上查看該模塊的最新版本`http://code.google.com/p/nltk/source/browse/trunk/nltk/nltk/metrics/distance.py`。
與其他 NLTK 的模塊一樣,`distance.py`以一組注釋行開始,包括一行模塊標題和作者信息。(由于代碼會被發布,也包括代碼可用的 URL、版權聲明和許可信息。)接下來是模塊級的文檔字符串,三重引號的多行字符串,其中包括當有人輸入`help(nltk.metrics.distance)`將被輸出的關于模塊的信息。
```py
# Natural Language Toolkit: Distance Metrics
#
# Copyright (C) 2001-2013 NLTK Project
# Author: Edward Loper <edloper@gmail.com>
# Steven Bird <stevenbird1@gmail.com>
# Tom Lippincott <tom@cs.columbia.edu>
# URL: <http://nltk.org/>
# For license information, see LICENSE.TXT
#
"""
Distance Metrics.
Compute the distance between two items (usually strings).
As metrics, they must satisfy the following three requirements:
1\. d(a, a) = 0
2\. d(a, b) >= 0
3\. d(a, c) <= d(a, b) + d(b, c)
"""
```
### 多模塊程序
一些程序匯集多種任務,例如從語料庫加載數據、對數據進行一些分析、然后將其可視化。我們可能已經有了穩定的模塊來加載數據和實現數據可視化。我們的工作可能會涉及到那些分析任務的編碼,只是從現有的模塊調用一些函數。[4.7](./ch04.html#fig-multi-module)描述了這種情景。

圖 4.7:一個多模塊程序的結構:主程序`my_program.py`從其他兩個模塊導入函數;獨特的分析任務在主程序本地進行,而一般的載入和可視化任務被分離開以便可以重用和抽象。
通過將我們的工作分成幾個模塊和使用`import`語句訪問別處定義的函數,我們可以保持各個模塊簡單,易于維護。這種做法也將導致越來越多的模塊的集合,使我們有可能建立復雜的涉及模塊間層次結構的系統。設計這樣的系統是一個復雜的軟件工程任務,這超出了本書的范圍。
### 錯誤源頭
掌握編程技術取決于當程序不按預期運作時各種解決問題的技能的總結。一些瑣碎的東西,如放錯位置的符號,可能導致程序的行為異常。我們把這些叫做“bugs”,因為它們與它們所導致的損害相比較小。它們不知不覺的潛入我們的代碼,只有在很久以后,我們在一些新的數據上運行程序時才會發現它們的存在。有時,一個錯誤的修復僅僅是暴露出另一個,于是我們得到了鮮明的印象,bug 在移動。我們唯一的安慰是 bugs 是自發的而不是程序員的錯誤。
繁瑣浮躁不談,調試代碼是很難的,因為有那么多的方式出現故障。我們對輸入數據、算法甚至編程語言的理解可能是錯誤的。讓我們分別來看看每種情況的例子。
首先,輸入的數據可能包含一些意想不到的字符。例如,WordNet 的同義詞集名稱的形式是`tree.n.01`,由句號分割成 3 個部分。最初 NLTK 的 WordNet 模塊使用`split('.')`分解這些名稱。然而,當有人試圖尋找詞 PhD 時,這種方法就不能用了,它的同義集名稱是`ph.d..n.01`,包含 4 個逗號而不是預期的 2 個。解決的辦法是使用`rsplit('.', 2)`利用最右邊的句號最多分割兩次,留下字符串`ph.d.`不變。雖然在模塊發布之前已經測試過,但就在幾個星期前有人檢測到這個問題(見`http://code.google.com/p/nltk/issues/detail?id=297`)。
第二,提供的函數可能不會像預期的那樣運作。例如,在測試 NLTK 中的 WordNet 接口時,一名作者注意到沒有同義詞集定義了反義詞,而底層數據庫提供了大量的反義詞的信息。這看著像是 WordNet 接口中的一個錯誤,結果卻是對 WordNet 本身的誤解:反義詞在詞條中定義,而不是在義詞集中。唯一的“bug”是對接口的一個誤解(參見`http://code.google.com/p/nltk/issues/detail?id=98`)。
第三,我們對 Python 語義的理解可能出錯。很容易做出關于兩個操作符的相對范圍的錯誤的假設。例如,`"%s.%s.%02d" % "ph.d.", "n", 1`產生一個運行時錯誤`TypeError: not enough arguments for format string`。這是因為百分號操作符優先級高于逗號運算符。解決辦法是添加括號強制限定所需的范圍。作為另一個例子,假設我們定義一個函數來收集一個文本中給定長度的所有詞符。該函數有文本和詞長作為參數,還有一個額外的參數,允許指定結果的初始值作為參數:
```py
>>> def find_words(text, wordlength, result=[]):
... for word in text:
... if len(word) == wordlength:
... result.append(word)
... return result
>>> find_words(['omg', 'teh', 'lolcat', 'sitted', 'on', 'teh', 'mat'], 3) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
['omg', 'teh', 'teh', 'mat']
>>> find_words(['omg', 'teh', 'lolcat', 'sitted', 'on', 'teh', 'mat'], 2, ['ur']) ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
['ur', 'on']
>>> find_words(['omg', 'teh', 'lolcat', 'sitted', 'on', 'teh', 'mat'], 3) ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
['omg', 'teh', 'teh', 'mat', 'omg', 'teh', 'teh', 'mat']
```
我們第一次調用`find_words()`[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#find-words-1),我們得到所有預期的三個字母的詞。第二次,我們為 result 指定一個初始值,一個單元素列表`['ur']`,如預期,結果中有這個詞連同我們的文本中的其他雙字母的詞。現在,我們再次使用[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#find-words-1)中相同的參數調用`find_words()`[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch04.html#find-words-3),但我們得到了不同的結果!我們每次不使用第三個參數調用`find_words()`,結果都只會延長前次調用的結果,而不是以在函數定義中指定的空鏈表 result 開始。程序的行為并不如預期,因為我們錯誤地認為在函數被調用時會創建默認值。然而,它只創建了一次,在 Python 解釋器加載這個函數時。這一個列表對象會被使用,只要沒有給函數提供明確的值。
### 調試技術
由于大多數代碼錯誤是因為程序員的不正確的假設,你檢測 bug 要做的第一件事是檢查你的假設。通過給程序添加`print`語句定位問題,顯示重要的變量的值,并顯示程序的進展程度。
如果程序產生一個“異常”——運行時錯誤——解釋器會輸出一個堆棧跟蹤,精確定位錯誤發生時程序執行的位置。如果程序取決于輸入數據,盡量將它減少到能產生錯誤的最小尺寸。
一旦你已經將問題定位在一個特定的函數或一行代碼,你需要弄清楚是什么出了錯誤。使用交互式命令行重現錯誤發生時的情況往往是有益的。定義一些變量,然后復制粘貼可能出錯的代碼行到會話中,看看會發生什么。檢查你對代碼的理解,通過閱讀一些文檔和測試與你正在試圖做的事情相同的其他代碼示例。嘗試將你的代碼解釋給別人聽,也許他們會看出出錯的地方。
Python 提供了一個調試器,它允許你監視程序的執行,指定程序暫停運行的行號(即斷點),逐步調試代碼段和檢查變量的值。你可以如下方式在你的代碼中調用調試器:
```py
>>> import pdb
>>> import mymodule
>>> pdb.run('mymodule.myfunction()')
```
它會給出一個提示`(Pdb)`,你可以在那里輸入指令給調試器。輸入`help`來查看命令的完整列表。輸入`step`(或只輸入`s`)將執行當前行然后停止。如果當前行調用一個函數,它將進入這個函數并停止在第一行。輸入`next`(或只輸入`n`)是類似的,但它會在當前函數中的下一行停止執行。`break`(或`b`)命令可用于創建或列出斷點。輸入`continue`(或`c`)會繼續執行直到遇到下一個斷點。輸入任何變量的名稱可以檢查它的值。
我們可以使用 Python 調試器來查找`find_words()` 函數的問題。請記住問題是在第二次調用函數時產生的。我們一開始將不使用調試器而調用該函數[first-run_](./ch04.html#id9),使用可能的最小輸入。第二次我們使用調試器調用它[second-run_](./ch04.html#id11)。.. doctest-ignore:
```py
>>> import pdb
>>> find_words(['cat'], 3) # [_first-run]
['cat']
>>> pdb.run("find_words(['dog'], 3)") # [_second-run]
> <string>(1)<module>()
(Pdb) step
--Call--
> <stdin>(1)find_words()
(Pdb) args
text = ['dog']
wordlength = 3
result = ['cat']
```
### 防御性編程
為了避免一些調試的痛苦,養成防御性的編程習慣是有益的。不要寫 20 行程序然后測試它,而是自下而上的打造一些明確可以運作的小的程序片。每次你將這些程序片組合成更大的單位都要仔細的看它是否能如預期的運作。考慮在你的代碼中添加`assert`語句,指定變量的屬性,例如`assert(isinstance(text, list))`。如果`text`的值在你的代碼被用在一些較大的環境中時變為了一個字符串,將產生一個`AssertionError`,于是你會立即得到問題的通知。
一旦你覺得你發現了錯誤,作為一個假設查看你的解決方案。在重新運行該程序之前嘗試預測你修正錯誤的影響。如果 bug 不能被修正,不要陷入盲目修改代碼希望它會奇跡般地重新開始運作的陷阱。相反,每一次修改都要嘗試闡明錯誤是什么和為什么這樣修改會解決這個問題的假設。如果這個問題沒有解決就撤消這次修改。
當你開發你的程序時,擴展其功能,并修復所有 bug,維護一套測試用例是有益的。這被稱為回歸測試,因為它是用來檢測代碼“回歸”的地方——修改代碼后會帶來一個意想不到的副作用是以前能運作的程序不運作了的地方。Python 以`doctest`模塊的形式提供了一個簡單的回歸測試框架。這個模塊搜索一個代碼或文檔文件查找類似與交互式 Python 會話這樣的文本塊,這種形式你已經在這本書中看到了很多次。它執行找到的 Python 命令,測試其輸出是否與原始文件中所提供的輸出匹配。每當有不匹配時,它會報告預期值和實際值。有關詳情,請查詢在 documentation at `http://docs.python.org/library/doctest.html`上的`doctest`文檔。除了回歸測試它的值,`doctest`模塊有助于確保你的軟件文檔與你的代碼保持同步。
也許最重要的防御性編程策略是要清楚的表述你的代碼,選擇有意義的變量和函數名,并通過將代碼分解成擁有良好文檔的接口的函數和模塊盡可能的簡化代碼。
## 4.7 算法設計
本節將討論更高級的概念,你在第一次閱讀本章時可能更愿意跳過本節。
解決算法問題的一個重要部分是為手頭的問題選擇或改造一個合適的算法。有時會有幾種選擇,能否選擇最好的一個取決于對每個選擇隨數據增長如何執行的知識。關于這個話題的書很多,我們只介紹一些關鍵概念和精心描述在自然語言處理中最普遍的做法。
最有名的策略被稱為分而治之。我們解決一個大小為 _n_ 的問題通過將其分成兩個大小為 _n/2_ 的問題,解決這些問題,組合它們的結果成為原問題的結果。例如,假設我們有一堆卡片,每張卡片上寫了一個詞。我們可以排序這一堆卡片,通過將它分成兩半分別給另外兩個人來排序(他們又可以做同樣的事情)。然后,得到兩個排好序的卡片堆,將它們并成一個單一的排序堆就是一項容易的任務了。參見[4.8](./ch04.html#fig-mergesort)這個過程的說明。
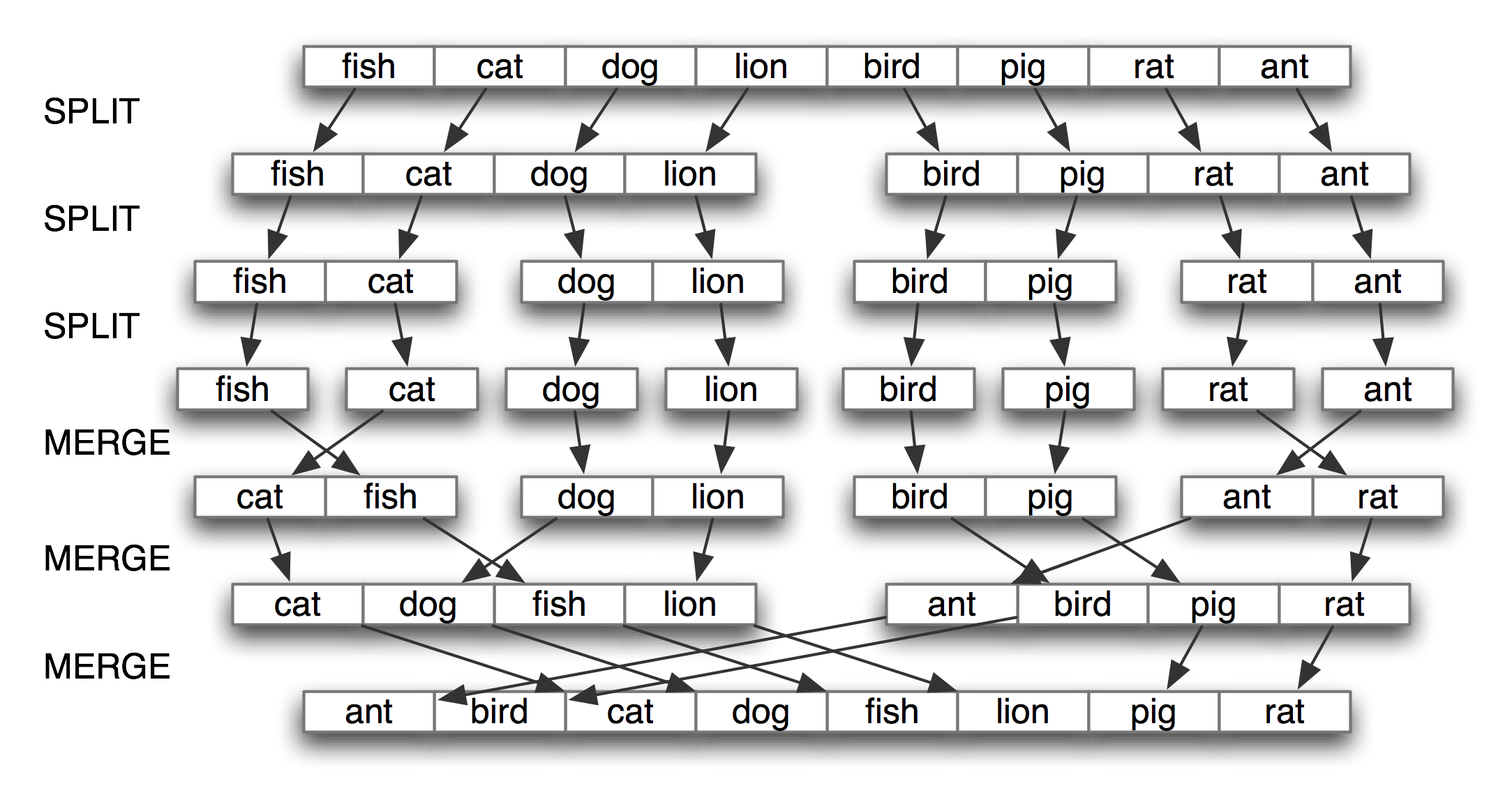
圖 4.8:通過分而治之排序:對一個數組排序,我們將其分成兩半并對每一半進行排序(遞歸);將每個排好序的一半合并成一個完整的鏈表(再次遞歸);這個算法被稱為“歸并排序“。
另一個例子是在詞典中查找一個詞的過程。我們打開在書的中部附近的一個地方,比較我們的詞與當前頁面上的詞。如果它在詞典中的詞前面,我們就在詞典的前一半重復上面的過程;如果它在后面,我們就使用詞典的后一半。這種搜索方法被稱為二分查找,因為它的每一步都將問題分裂成一半。
算法設計的另一種方法,我們解決問題通過將它轉化為一個我們已經知道如何解決的問題的一個實例。例如,為了檢測列表中的重復項,我們可以預排序這個列表,然后通過一次掃描檢查是否有相鄰的兩個元素是相同的。
### 遞歸
上面的關于排序和搜索的例子有一個引人注目的特征:解決一個大小為 n 的問題,可以將其分成兩半,然后處理一個或多個大小為 n/2 的問題。實現這種方法的一種常見方式是使用遞歸。我們定義一個函數 f,從而簡化了問題,并調用自身來解決一個或多個同樣問題的更簡單的實例。然后組合它們的結果成為原問題的解答。
例如,假設我們有 n 個詞,要計算出它們結合在一起有多少不同的方式能組成一個詞序列。如果我們只有一個詞(n=1),只是一種方式組成一個序列。如果我們有 2 個詞,就有 2 種方式將它們組成一個序列。3 個詞有 6 種可能性。一般的,n 個詞有 n × n-1 × … × 2 × 1 種方式(即 n 的階乘)。我們可以將這些編寫成如下代碼:
```py
>>> def factorial1(n):
... result = 1
... for i in range(n):
... result *= (i+1)
... return result
```
但是,也可以使用一種遞歸算法來解決這個問題,該算法基于以下觀察。假設我們有辦法為 n-1 不同的詞構建所有的排列。然后對于每個這樣的排列,有 n 個地方我們可以插入一個新詞:開始、結束或任意兩個詞之間的 n-2 個空隙。因此,我們簡單的將 n-1 個詞的解決方案數乘以 n 的值。我們還需要基礎案例,也就是說,如果我們有一個詞,只有一個順序。我們可以將這些編寫成如下代碼:
```py
>>> def factorial2(n):
... if n == 1:
... return 1
... else:
... return n * factorial2(n-1)
```
這兩種算法解決同樣的問題。一個使用迭代,而另一個使用遞歸。我們可以用遞歸處理深層嵌套的對象,例如 WordNet 的上位詞層次。讓我們計數給定同義詞集 s 為根的上位詞層次的大小。我們會找到 s 的每個下位詞的大小,然后將它們加到一起(我們也將加 1 表示同義詞集本身)。下面的函數`size1()`做這項工作;注意函數體中包括`size1()`的遞歸調用:
```py
>>> def size1(s):
... return 1 + sum(size1(child) for child in s.hyponyms())
```
我們也可以設計一種這個問題的迭代解決方案處理層的層次結構。第一層是同義詞集本身[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#first-layer),然后是同義詞集所有的下位詞,之后是所有下位詞的下位詞。每次循環通過查找上一層的所有下位詞計算下一層[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch04.html#update-layer)。它也保存了到目前為止遇到的同義詞集的總數[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#update-total)。
```py
>>> def size2(s):
... layer = [s] ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
... total = 0
... while layer:
... total += len(layer) ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
... layer = [h for c in layer for h in c.hyponyms()] ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
... return total
```
迭代解決方案不僅代碼更長而且更難理解。它迫使我們程序式的思考問題,并跟蹤`layer`和`total`隨時間變化發生了什么。讓我們滿意的是兩種解決方案均給出了相同的結果。我們將使用 import 語句的一個新的形式,允許我們縮寫名稱`wordnet`為`wn`:
```py
>>> from nltk.corpus import wordnet as wn
>>> dog = wn.synset('dog.n.01')
>>> size1(dog)
190
>>> size2(dog)
190
```
作為遞歸的最后一個例子,讓我們用它來構建一個深嵌套的對象。一個字母查找樹是一種可以用來索引詞匯的數據結構,一次一個字母。(這個名字來自于單詞 retrieval)。例如,如果`trie`包含一個字母的查找樹,那么`trie['c']`是一個較小的查找樹,包含所有以 c 開頭的詞。[4.9](./ch04.html#code-trie)演示了使用 Python 字典([3](./ch05.html#sec-dictionaries))構建查找樹的遞歸過程。若要插入詞 chien(dog 的法語),我們將 c 分類,遞歸的摻入 hien 到`trie['c']`子查找樹中。遞歸繼續直到詞中沒有剩余的字母,于是我們存儲的了預期值(本例中是詞 dog)。
```py
def insert(trie, key, value):
if key:
first, rest = key[0], key[1:]
if first not in trie:
trie[first] = {}
insert(trie[first], rest, value)
else:
trie['value'] = value
```
小心!
盡管遞歸編程結構簡單,但它是有代價的。每次函數調用時,一些狀態信息需要推入堆棧,這樣一旦函數執行完成可以從離開的地方繼續執行。出于這個原因,迭代的解決方案往往比遞歸解決方案的更高效。
### 權衡空間與時間
我們有時可以顯著的加快程序的執行,通過建設一個輔助的數據結構,例如索引。[4.10](./ch04.html#code-search-documents)實現一個簡單的電影評論語料庫的全文檢索系統。通過索引文檔集合,它提供更快的查找。
```py
def raw(file):
contents = open(file).read()
contents = re.sub(r'<.*?>', ' ', contents)
contents = re.sub('\s+', ' ', contents)
return contents
def snippet(doc, term):
text = ' '*30 + raw(doc) + ' '*30
pos = text.index(term)
return text[pos-30:pos+30]
print("Building Index...")
files = nltk.corpus.movie_reviews.abspaths()
idx = nltk.Index((w, f) for f in files for w in raw(f).split())
query = ''
while query != "quit":
query = input("query> ") # use raw_input() in Python 2
if query in idx:
for doc in idx[query]:
print(snippet(doc, query))
else:
print("Not found")
```
一個更微妙的空間與時間折中的例子涉及使用整數標識符替換一個語料庫的詞符。我們為語料庫創建一個詞匯表,每個詞都被存儲一次的列表,然后轉化這個列表以便我們能通過查找任意詞來找到它的標識符。每個文檔都進行預處理,使一個詞列表變成一個整數列表。現在所有的語言模型都可以使用整數。見[4.11](./ch04.html#code-strings-to-ints)中的內容,如何為一個已標注的語料庫做這個的例子的列表。
```py
def preprocess(tagged_corpus):
words = set()
tags = set()
for sent in tagged_corpus:
for word, tag in sent:
words.add(word)
tags.add(tag)
wm = dict((w, i) for (i, w) in enumerate(words))
tm = dict((t, i) for (i, t) in enumerate(tags))
return [[(wm[w], tm[t]) for (w, t) in sent] for sent in tagged_corpus]
```
空間時間權衡的另一個例子是維護一個詞匯表。如果你需要處理一段輸入文本檢查所有的詞是否在現有的詞匯表中,詞匯表應存儲為一個集合,而不是一個列表。集合中的元素會自動索引,所以測試一個大的集合的成員將遠遠快于測試相應的列表的成員。
我們可以使用`timeit`模塊測試這種說法。`Timer`類有兩個參數:一個是多次執行的語句,一個是只在開始執行一次的設置代碼。我們將分別使用一個整數的列表[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#vocab-list)和一個整數的集合[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#vocab-set)模擬 10 萬個項目的詞匯表。測試語句將產生一個隨機項,它有 50%的機會在詞匯表中[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch04.html#vocab-statement)。
```py
>>> from timeit import Timer
>>> vocab_size = 100000
>>> setup_list = "import random; vocab = range(%d)" % vocab_size ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> setup_set = "import random; vocab = set(range(%d))" % vocab_size ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> statement = "random.randint(0, %d) in vocab" % (vocab_size * 2) ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
>>> print(Timer(statement, setup_list).timeit(1000))
2.78092288971
>>> print(Timer(statement, setup_set).timeit(1000))
0.0037260055542
```
執行 1000 次鏈表成員資格測試總共需要 2.8 秒,而在集合上的等效試驗僅需 0.0037 秒,也就是說快了三個數量級!
### 動態規劃
動態規劃是一種自然語言處理中被廣泛使用的算法設計的一般方法。“programming”一詞的用法與你可能想到的感覺不同,是規劃或調度的意思。動態規劃用于解決包含多個重疊的子問題的問題。不是反復計算這些子問題,而是簡單的將它們的計算結果存儲在一個查找表中。在本節的余下部分,我們將介紹動態規劃,在一個相當不同的背景下來句法分析。
Pingala 是大約生活在公元前 5 世紀的印度作家,作品有被稱為 _《Chandas Shastra》_ 的梵文韻律專著。Virahanka 大約在公元 6 世紀延續了這項工作,研究短音節和長音節組合產生一個長度為 _n_ 的旋律的組合數。短音節,標記為 _S_,占一個長度單位,而長音節,標記為 _L_,占 2 個長度單位。例如,Pingala 發現,有 5 種方式構造一個長度為 4 的旋律:_V_<sub>4</sub> = _{LL, SSL, SLS, LSS, SSSS}_。請看,我們可以將 _V_<sub>4</sub>分成兩個子集,以 _L_ 開始的子集和以 _S_ 開始的子集,如[(1)](./ch04.html#ex-v4)所示。
```py
V4 =
LL, LSS
i.e. L prefixed to each item of V2 = {L, SS}
SSL, SLS, SSSS
i.e. S prefixed to each item of V3 = {SL, LS, SSS}
```
有了這個觀察結果,我們可以寫一個小的遞歸函數稱為`virahanka1()`來計算這些旋律,如[4.12](./ch04.html#code-virahanka)所示。請注意,要計算 _V_<sub>4</sub>,我們先要計算 _V_<sub>3</sub>和 _V_<sub>2</sub>。但要計算 _V_<sub>3</sub>,我們先要計算 _V_<sub>2</sub>和 _V_<sub>1</sub>。在[(2)](./ch04.html#ex-call-structure)中描述了這種調用結構。
```py
from numpy import arange
from matplotlib import pyplot
colors = 'rgbcmyk' # red, green, blue, cyan, magenta, yellow, black
def bar_chart(categories, words, counts):
"Plot a bar chart showing counts for each word by category"
ind = arange(len(words))
width = 1 / (len(categories) + 1)
bar_groups = []
for c in range(len(categories)):
bars = pyplot.bar(ind+c*width, counts[categories[c]], width,
color=colors[c % len(colors)])
bar_groups.append(bars)
pyplot.xticks(ind+width, words)
pyplot.legend([b[0] for b in bar_groups], categories, loc='upper left')
pyplot.ylabel('Frequency')
pyplot.title('Frequency of Six Modal Verbs by Genre')
pyplot.show()
```
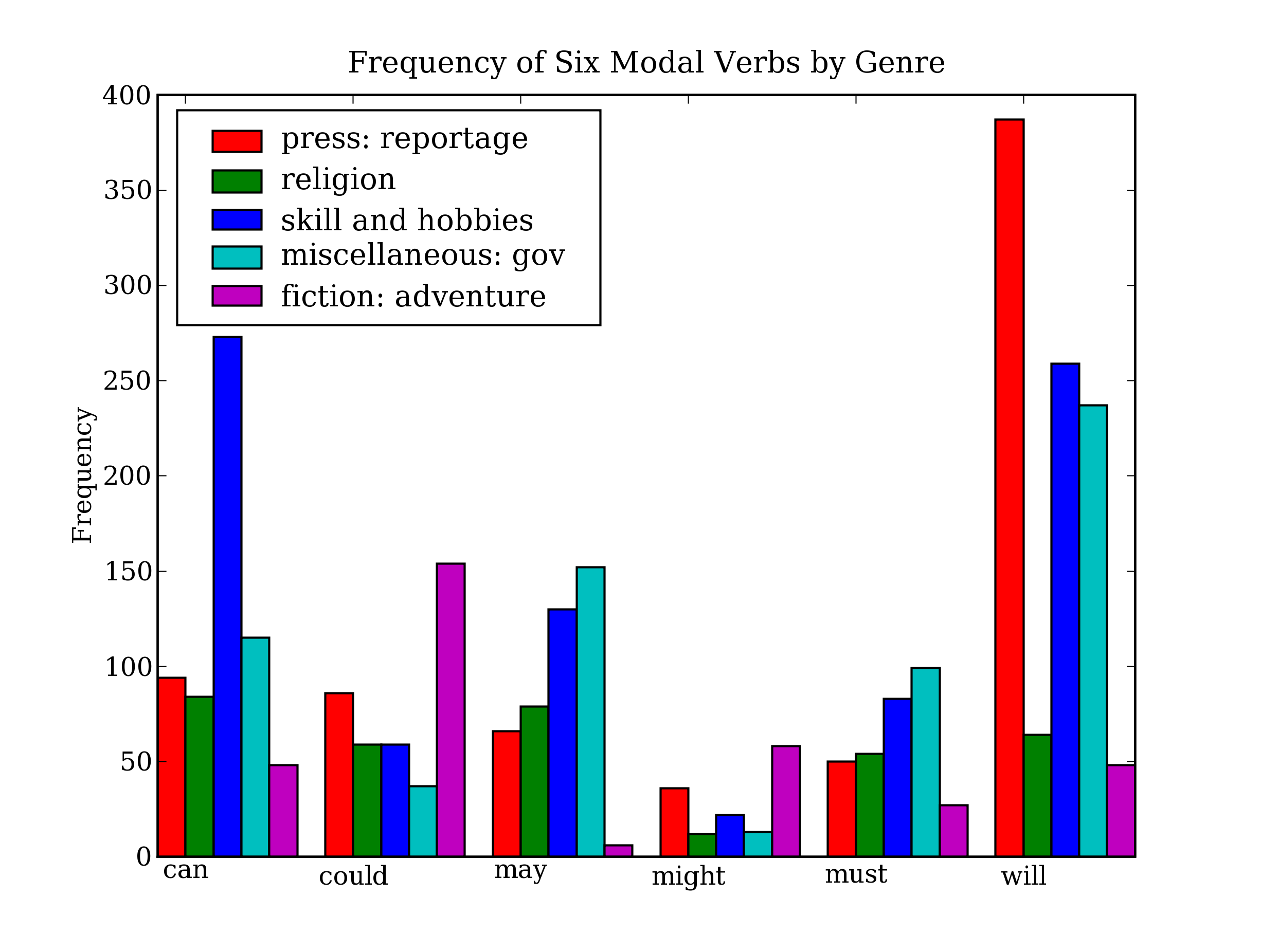
圖 4.14:條形圖顯示布朗語料庫中不同部分的情態動詞頻率:這個可視化圖形由[4.13](./ch04.html#code-modal-plot)中的程序產生。
從該柱狀圖可以立即看出 may 和 must 有幾乎相同的相對頻率。could 和 might 也一樣。
也可以動態的產生這些數據的可視化圖形。例如,一個使用表單輸入的網頁可以允許訪問者指定搜索參數,提交表單,看到一個動態生成的可視化圖形。要做到這一點,我們必須為`matplotlib`指定`Agg`后臺,它是一個產生柵格(像素)圖像的庫[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#agg-backend)。下一步,我們像以前一樣使用相同的 Matplotlib 方法,但不是用`pyplot.show()`顯示結果在圖形終端,而是使用`pyplot.savefig()`把它保存到一個文件[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#pyplot-savefig)。我們指定文件名,然后輸出一些 HTML 標記指示網頁瀏覽器來加載該文件。
```py
>>> from matplotlib import use, pyplot
>>> use('Agg') ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> pyplot.savefig('modals.png') ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
>>> print('Content-Type: text/html')
>>> print()
>>> print('<html><body>')
>>> print('<img src="modals.png"/>')
>>> print('</body></html>')
```
### NetworkX
NetworkX 包定義和操作被稱為圖的由節點和邊組成的結構。它可以從`https://networkx.lanl.gov/`得到。NetworkX 可以和 Matplotlib 結合使用可視化如 WordNet 的網絡結構(語義網絡,我們在[5](./ch02.html#sec-wordnet)介紹過)。[4.15](./ch04.html#code-networkx)中的程序初始化一個空的圖[![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)](./ch04.html#define-graph),然后遍歷 WordNet 上位詞層次為圖添加邊[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#add-edge)。請注意,遍歷是遞歸的[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#recursive-traversal),使用在[4.7](./ch04.html#sec-algorithm-design)討論的編程技術。結果顯示在[4.16](./ch04.html#fig-dog-graph)。
```py
import networkx as nx
import matplotlib
from nltk.corpus import wordnet as wn
def traverse(graph, start, node):
graph.depth[node.name] = node.shortest_path_distance(start)
for child in node.hyponyms():
graph.add_edge(node.name, child.name) ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
traverse(graph, start, child) ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
def hyponym_graph(start):
G = nx.Graph() ![[3]](https://img.kancloud.cn/69/fc/69fcb1188781ff9f726d82da7988a139_15x15.jpg)
G.depth = {}
traverse(G, start, start)
return G
def graph_draw(graph):
nx.draw_graphviz(graph,
node_size = [16 * graph.degree(n) for n in graph],
node_color = [graph.depth[n] for n in graph],
with_labels = False)
matplotlib.pyplot.show()
```
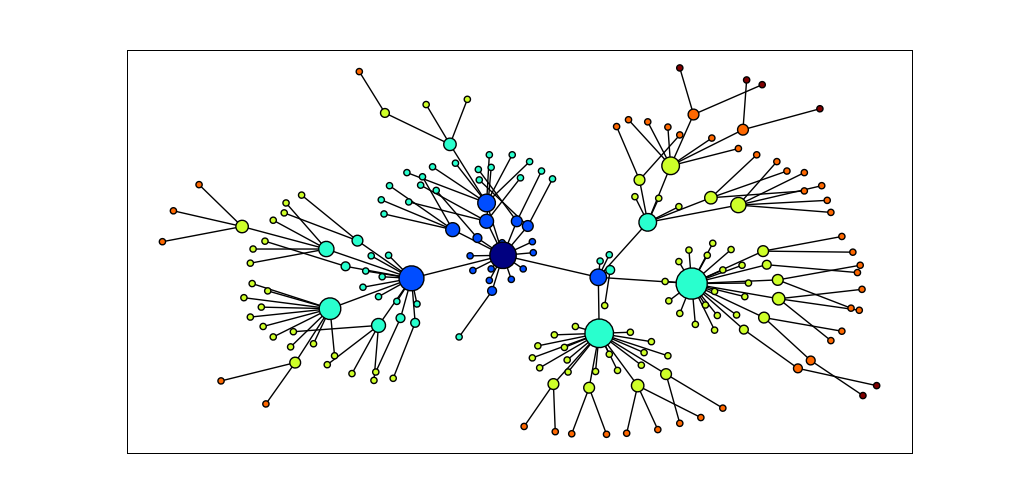
圖 4.16:使用 NetworkX 和 Matplotlib 可視化數據:WordNet 的上位詞層次的部分顯示,開始于`dog.n.01`(中間最黑的節點);節點的大小對應節點的孩子的數目,顏色對應節點到`dog.n.01`的距離;此可視化圖形由[4.15](./ch04.html#code-networkx)中的程序產生。
### csv
語言分析工作往往涉及數據統計表,包括有關詞項的信息、試驗研究的參與者名單或從語料庫提取的語言特征。這里有一個 CSV 格式的簡單的詞典片段:
sleep, sli:p, v.i, a condition of body and mind ...walk, wo:k, v.intr, progress by lifting and setting down each foot ...wake, weik, intrans, cease to sleep
我們可以使用 Python 的 CSV 庫讀寫這種格式存儲的文件。例如,我們可以打開一個叫做`lexicon.csv`的 CSV 文件[![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)](./ch04.html#open-csv),并遍歷它的行[![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)](./ch04.html#iterate-csv):
```py
>>> import csv
>>> input_file = open("lexicon.csv", "rb") ![[1]](https://img.kancloud.cn/97/aa/97aa34f1d446f0c464068d0711295a9a_15x15.jpg)
>>> for row in csv.reader(input_file): ![[2]](https://img.kancloud.cn/c7/9c/c79c435fbd088cae010ca89430cd9f0c_15x15.jpg)
... print(row)
['sleep', 'sli:p', 'v.i', 'a condition of body and mind ...']
['walk', 'wo:k', 'v.intr', 'progress by lifting and setting down each foot ...']
['wake', 'weik', 'intrans', 'cease to sleep']
```
每一行是一個字符串列表。如果字段包含有數值數據,它們將作為字符串出現,所以都必須使用`int()`或`float()`轉換。
### NumPy
NumPy 包對 Python 中的數值處理提供了大量的支持。NumPy 有一個多維數組對象,它可以很容易初始化和訪問:
```py
>>> from numpy import array
>>> cube = array([ [[0,0,0], [1,1,1], [2,2,2]],
... [[3,3,3], [4,4,4], [5,5,5]],
... [[6,6,6], [7,7,7], [8,8,8]] ])
>>> cube[1,1,1]
4
>>> cube[2].transpose()
array([[6, 7, 8],
[6, 7, 8],
[6, 7, 8]])
>>> cube[2,1:]
array([[7, 7, 7],
[8, 8, 8]])
```
NumPy 包括線性代數函數。在這里我們進行矩陣的奇異值分解,潛在語義分析中使用的操作,它能幫助識別一個文檔集合中的隱含概念。
```py
>>> from numpy import linalg
>>> a=array([[4,0], [3,-5]])
>>> u,s,vt = linalg.svd(a)
>>> u
array([[-0.4472136 , -0.89442719],
[-0.89442719, 0.4472136 ]])
>>> s
array([ 6.32455532, 3.16227766])
>>> vt
array([[-0.70710678, 0.70710678],
[-0.70710678, -0.70710678]])
```
NLTK 中的聚類包`nltk.cluster`中廣泛使用 NumPy 數組,支持包括 k-means 聚類、高斯 EM 聚類、組平均凝聚聚類以及聚類分析圖。有關詳細信息,請輸入`help(nltk.cluster)`。
### 其他 Python 庫
還有許多其他的 Python 庫,你可以使用`http://pypi.python.org/`處的 Python 包索引找到它們。許多庫提供了外部軟件接口,例如關系數據庫(如`mysql-python`)和大數據集合(如`PyLucene`)。許多其他庫能訪問各種文件格式,如 PDF、MSWord 和 XML(`pypdf`, `pywin32`, `xml.etree`)、RSS 源(如`feedparser`)以及電子郵箱(如`imaplib`, `email`)。
## 6 小結
* Python 賦值和參數傳遞使用對象引用,例如如果`a`是一個列表,我們分配`b = a`,然后任何`a`上的操作都將修改`b`,反之亦然。
* `is`操作測試是否兩個對象是相同的內部對象,而`==`測試是否兩個對象是相等的。兩者的區別和詞符與詞類型的區別相似。
* 字符串、列表和元組是不同類型的序列對象,支持常見的操作如:索引、切片、`len()`、`sorted()`和使用`in`的成員測試。
* 聲明式的編程風格通常會產生更簡潔更可讀的代碼;手動遞增循環變量通常是不必要的;枚舉一個序列,使用`enumerate()`。
* 函數是一個重要的編程抽象,需要理解的關鍵概念有:參數傳遞、變量的作用域和文檔字符串。
* 函數作為一個命名空間:函數內部定義的名稱在該函數外不可見,除非這些名稱被宣布為是全局的。
* 模塊允許將材料與本地的文件邏輯的關聯起來。一個模塊作為一個命名空間:在一個模塊中定義的名稱——如變量和函數——在其他模塊中不可見,除非這些名稱被導入。
* 動態規劃是一種在 NLP 中廣泛使用的算法設計技術,它存儲以前的計算結果,以避免不必要的重復計算。
## 4.10 深入閱讀
本章已經觸及編程中的許多主題,一些是 Python 特有的,一些是相當普遍的。我們只是觸及了表面,你可能想要閱讀更多有關這些主題的內容,可以從`http://nltk.org/`處的本章深入閱讀材料開始。
Python 網站提供大量文檔。理解內置的函數和標準類型是很重要的,在`http://docs.python.org/library/functions.html`和`http://docs.python.org/library/stdtypes.html`處有描述。我們已經學習了生成器以及它們對提高效率的重要性;關于迭代器的信息,一個密切相關的話題請看`http://docs.python.org/library/itertools.html`。查詢你喜歡的 Python 書籍中這些主題的更多信息。使用 Python 進行多媒體處理包括聲音文件的一個優秀的資源是[(Guzdial, 2005)](./bibliography.html#guzdial2005)。
使用在線 Python 文檔時,要注意你安裝的版本可能與你正在閱讀的文檔的版本不同。你可以使用`import sys; sys.version`松地查詢你有的是什么版本。特定版本的文檔在`http://www.python.org/doc/versions/`處。
算法設計是計算機科學中一個豐富的領域。一些很好的出發點是[(Harel, 2004)](./bibliography.html#harel2004), [(Levitin, 2004)](./bibliography.html#levitin2004), [(Knuth, 2006)](./bibliography.html#knuth2006trees)。[(Hunt & Thomas, 2000)](./bibliography.html#hunt2000)和[(McConnell, 2004)](./bibliography.html#mcconnell2004)為軟件開發實踐提供了有益的指導。
## 4.11 練習
1. ? 使用 Python 的幫助功能,找出更多關于序列對象的內容。在解釋器中輸入`help(str)`,`help(list)`和`help(tuple)`。這會給你一個每種類型支持的函數的完整列表。一些函數名字有些特殊,兩側有下劃線;正如幫助文檔顯示的那樣,每個這樣的函數對應于一些較為熟悉的東西。例如`x.__getitem__(y)`僅僅是以長篇大論的方式使用`x[y]`。
2. ? 確定三個同時在元組和鏈表上都可以執行的操作。確定三個不能在元組上執行的列表操作。命名一段使用列表替代元組會產生一個 Python 錯誤的代碼。
3. ? 找出如何創建一個由單個項目組成的元組。至少有兩種方法可以做到這一點。
4. ? 創建一個列表`words = ['is', 'NLP', 'fun', '?']`。使用一系列賦值語句(如`words[1] = words[2]`)和臨時變量`tmp`將這個列表轉換為列表`['NLP', 'is', 'fun', '!']`。現在,使用元組賦值做相同的轉換。
5. ? 通過輸入`help(cmp)`閱讀關于內置的比較函數`cmp`的內容。它與比較運算符在行為上有何不同?
6. ? 創建一個 n-grams 的滑動窗口的方法在下面兩種極端情況下是否正確:n = 1 和 n = `len(sent)`?
7. ? 我們指出當空字符串和空鏈表出現在`if`從句的條件部分時,它們的判斷結果是`False`。在這種情況下,它們被說成出現在一個布爾上下文中。實驗各種不同的布爾上下文中的非布爾表達式,看它們是否被判斷為`True`或`False`。
8. ? 使用不等號比較字符串,如`'Monty' < 'Python'`。當你做`'Z' < 'a'`時會發生什么?嘗試具有共同前綴的字符串對,如`'Monty' < 'Montague'`。閱讀有關“字典排序”的內容以便了解這里發生了什么事。嘗試比較結構化對象,如`('Monty', 1) < ('Monty', 2)`。這與預期一樣嗎?
9. ? 寫代碼刪除字符串開頭和結尾處的空白,并規范化詞之間的空格為一個單獨的空格字符。
1. 使用`split()`和`join()`做這個任務
2. 使用正則表達式替換做這個任務
10. ? 寫一個程序按長度對詞排序。定義一個輔助函數`cmp_len`,它在詞長上使用`cmp`比較函數。
11. ? 創建一個詞列表并將其存儲在變量`sent1`。現在賦值`sent2 = sent1`。修改`sent1`中的一個項目,驗證`sent2`改變了。
1. 現在嘗試同樣的練習,但使用`sent2 = sent1[:]`賦值。再次修改`sent1`看看`sent2`會發生什么。解釋。
2. 現在定義`text1`為一個字符串列表的列表(例如表示由多個句子組成的文本)。現在賦值`text2 = text1[:]`,分配一個新值給其中一個詞,例如`text1[1][1] = 'Monty'`。檢查這對`text2`做了什么。解釋。
3. 導入 Python 的`deepcopy()`函數(即`from copy import deepcopy`),查詢其文檔,使用它生成任一對象的新副本。
12. ? 使用列表乘法初始化 _n_-by-_m_ 的空字符串列表的咧表,例如`word_table = [[''] * n] * m`。當你設置其中一個值時會發生什么事,例如`word_table[1][2] = "hello"`?解釋為什么會出現這種情況。現在寫一個表達式,使用`range()`構造一個列表,表明它沒有這個問題。
13. ? 寫代碼初始化一個稱為`word_vowels`的二維數組的集合,處理一個詞列表,添加每個詞到`word_vowels[l][v]`,其中`l`是詞的長度,`v`是它包含的元音的數量。
14. ? 寫一個函數`novel10(text)`輸出所有在一個文本最后 10%出現而之前沒有遇到過的詞。
15. ? 寫一個程序將一個句子表示成一個單獨的字符串,分割和計數其中的詞。讓它輸出每一個詞和詞的頻率,每行一個,按字母順序排列。
16. ? 閱讀有關 Gematria 的內容,它是一種方法,分配一個數字給詞匯,具有相同數字的詞之間映射以發現文本隱藏的含義(`http://en.wikipedia.org/wiki/Gematria`, `http://essenes.net/gemcal.htm`)。
1. 寫一個函數`gematria()`,根據`letter_vals`中的字母值,累加一個詞的字母的數值:
```py
>>> letter_vals = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5, 'f':80, 'g':3, 'h':8,
... 'i':10, 'j':10, 'k':20, 'l':30, 'm':40, 'n':50, 'o':70, 'p':80, 'q':100,
... 'r':200, 's':300, 't':400, 'u':6, 'v':6, 'w':800, 'x':60, 'y':10, 'z':7}
```
2. 處理一個語料庫(`nltk.corpus.state_union`)對每個文檔計數它有多少詞的字母數值為 666。
3. 寫一個函數`decode()`來處理文本,隨機替換詞匯為它們的 Gematria 等值的詞,以發現文本的“隱藏的含義”。
17. ? 寫一個函數`shorten(text, n)`處理文本,省略文本中前 n 個最頻繁出現的詞。它的可讀性會如何?
18. ? 寫代碼輸出詞匯的索引,允許別人根據其含義查找詞匯(或它們的發言;詞匯條目中包含的任何屬性)。
19. ? 寫一個列表推導排序 WordNet 中與給定同義詞集接近的同義詞集的列表。例如,給定同義詞集`minke_whale.n.01`, `orca.n.01`, `novel.n.01`和`tortoise.n.01`,按照它們與`right_whale.n.01`的`shortest_path_distance()`對它們進行排序。
20. ? 寫一個函數處理一個詞列表(含重復項),返回一個按照頻率遞減排序的詞列表(沒有重復項)。例如如果輸入列表中包含詞`table`的 10 個實例,`chair`的 9 個實例,那么在輸出列表中`table`會出現在`chair`前面。
21. ? 寫一個函數以一個文本和一個詞匯表作為它的參數,返回在文本中出現但不在詞匯表中的一組詞。兩個參數都可以表示為字符串列表。你能使用`set.difference()`在一行代碼中做這些嗎?
22. ? 從 Python 標準庫的`operator`模塊導入`itemgetter()`函數(即`from operator import itemgetter`)。創建一個包含幾個詞的列表`words`。現在嘗試調用:`sorted(words, key=itemgetter(1))`和`sorted(words, key=itemgetter(-1))`。解釋`itemgetter()`正在做什么。
23. ? 寫一個遞歸函數`lookup(trie, key)`在查找樹中查找一個關鍵字,返回找到的值。擴展這個函數,當一個詞由其前綴唯一確定時返回這個詞(例如`vanguard`是以`vang-`開頭的唯一的詞,所以`lookup(trie, 'vang')`應該返回與`lookup(trie, 'vanguard')`相同的內容)。
24. ? 閱讀關于“關鍵字聯動”的內容([(Scott & Tribble, 2006)](./bibliography.html#scott2006)的第 5 章)。從 NLTK 的莎士比亞語料庫中提取關鍵字,使用 NetworkX 包,畫出關鍵字聯動網絡。
25. ? 閱讀有關字符串編輯距離和 Levenshtein 算法的內容。嘗試`nltk.edit_distance()`提供的實現。這用的是動態規劃的何種方式?它使用的是自下而上還是自上而下的方法?[另見`http://norvig.com/spell-correct.html`]
26. ? Catalan 數出現在組合數學的許多應用中,包括解析樹的計數([6](./ch08.html#sec-grammar-development))。該級數可以定義如下:C<sub>0</sub> = 1, and C<sub>n+1</sub> = Σ<sub>0..n</sub> (C<sub>i</sub>C<sub>n-i</sub>)。
1. 編寫一個遞歸函數計算第 n 個 Catalan 數 C<sub>n</sub>。
2. 現在寫另一個函數使用動態規劃做這個計算。
3. 使用`timeit`模塊比較當 n 增加時這些函數的性能。
27. ★ 重現有關著作權鑒定的[(Zhao & Zobel, 2007)](./bibliography.html#zhao07)中的一些結果。
28. ★ 研究性別特異詞匯選擇,看你是否可以重現一些`http://www.clintoneast.com/articles/words.php`的結果
29. ★ 寫一個遞歸函數漂亮的按字母順序排列輸出一個查找樹,例如:
```py
chair: 'flesh'
---t: 'cat'
--ic: 'stylish'
---en: 'dog'
```
## Docutils System Messages
System Message: ERROR/3 (`ch04.rst2`, line 1791); _[backlink](./ch04.html#id10)_
Unknown target name: "first-run".
System Message: ERROR/3 (`ch04.rst2`, line 1791); _[backlink](./ch04.html#id12)_
Unknown target name: "second-run".
