
## 把分類網絡修改為語義分割的網絡存在下面問題:
1. 分辨率變小(the reduction of signal
resolution incurred by the repeated combination of max-pooling and downsampling (‘striding’) performed at every layer of standard DCNNs)
2. spatial ‘insensitivity’ (invariance)。(relates to the fact that obtaining object-centric decisions from a classifier requires invariance to spatial transformations, inherently limiting the spatial accuracy of the DCNN
model)-- This is
due to the very invariance properties that make DCNNs good for high level tasks
*****
我們來看FCN怎么來解決這兩個問題的?
### 第一個問題解決思路:
使用了稱作空洞卷積的結構,且去除了池化層結構。
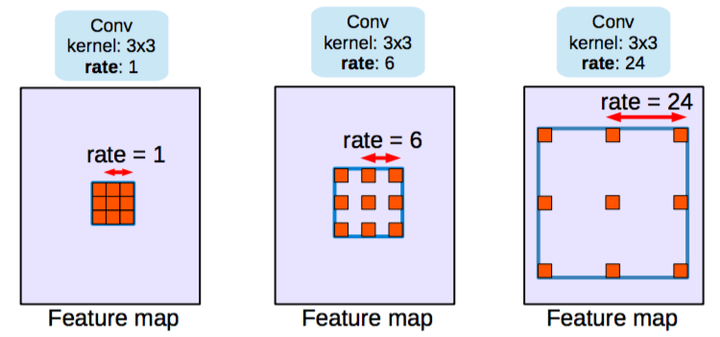
空洞卷積,當比率為1時,即為經典的卷積結構。池化操作增大了感受野,有助于實現分類網絡。同時保證了分類的精度
因此,該論文所提出的空洞卷積層是如此工作的:

### 第二個問題解決思路:
**條件隨機場(Conditional Random Field,CRF)方法通常在后期處理中用于改進分割效果**。CRF方法是一種基于底層圖像像素強度進行“平滑”分割的圖模型,在運行時會將像素強度相似的點標記為同一類別。加入條件隨機場方法可以提高1~2%的最終評分值。
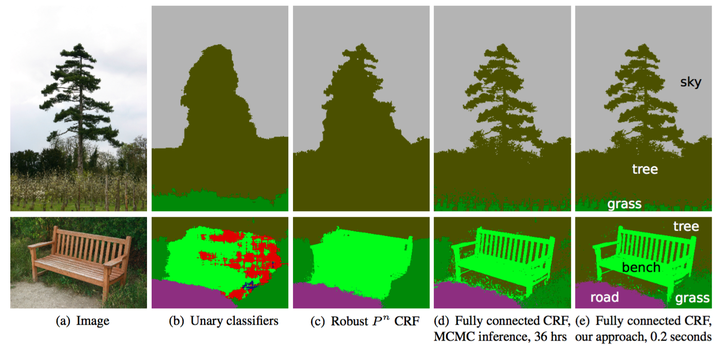
發展中的CRF方法效果。b圖中將一維分類器作為CRF方法的分割輸入;c、d、e圖為CRF方法的三種變體;e圖為廣泛使用的一種CRF結構。
### DeepLab總覽:
**DeepLab(v1和v2)**
論文1:
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
于2014年12月22日提交到Arvix
[https://arxiv.org/abs/1412.7062](http://link.zhihu.com/?target=https%3A//arxiv.org/abs/1412.7062)
論文2:
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
于2016年6月2日提交到Arxiv
[https://arxiv.org/abs/1606.00915](http://link.zhihu.com/?target=https%3A//arxiv.org/abs/1606.00915)
主要貢獻:
* 使用了空洞卷積;
* 提出了在空間維度上實現金字塔型的空洞池化atrous spatial pyramid pooling(ASPP);
* 使用了全連接條件隨機場。
具體解釋:
空洞卷積在不增加參數數量的情況下增大了感受野,按照上文提到的空洞卷積論文的做法,可以改善分割網絡。
我們可以通過將原始圖像的多個重新縮放版本傳遞到CNN網絡的并行分支(即圖像金字塔)中,或是可使用不同采樣率(ASPP)的多個并行空洞卷積層,這兩種方法均可實現多尺度處理。
我們也可通過全連接條件隨機場實現結構化預測,需將條件隨機場的訓練和微調單獨作為一個后期處理步驟。
- 序言
- 第一章 機器學習概述
- 第二章 機器學習環境搭建
- 環境搭建
- 第三章 機器學習之基礎算法
- 第一節:基礎知識
- 第二節:k近鄰算法
- 第三節:決策樹算法
- 第四節:樸素貝葉斯
- 第五節:邏輯斯蒂回歸
- 第六節:支持向量機
- 第四章 機器學習之深度學習算法
- 第一節: CNN
- 4.1.1 CNN介紹
- 4.1.2 CNN反向傳播
- 4.1.3 DNN實例
- 4.1.4 CNN實例
- 第五章 機器學習論文與實踐
- 第一節: 語義分割
- 5.1 FCN
- 5.1.1 FCN--------實現FCN16S
- 5.1.2 FCN--------優化FCN16S
- 5.2 DeepLab
- 5.2.1 DeepLabv2
- 第六章 機器學習在實際項目中的應用