
[TOC]
# <span style="font-size:15px">**進程結構** </span>
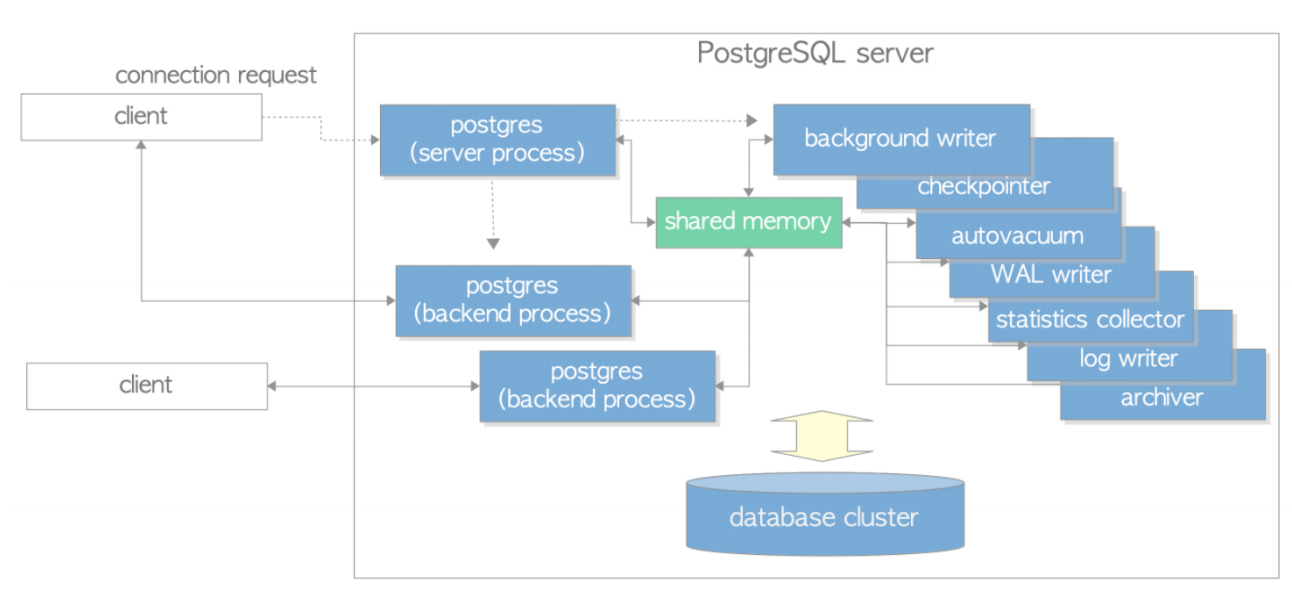
從下面的體系結構圖可以看出來,PG使用經典的C/S架構,進程架構。在服務器端有主進程、服務進程、子進程、共享內存以及文件存儲幾大部分。
```
SIS3.0.60.0 ~ # ps aux | grep postgres
daemon 8384 0.0 0.1 384180 21920 ? Ss Nov10 0:10 /home/fantom/party/pgsql/bin/postmaster -D /data/pgsql/ --config-file=/etc/postgresql-13/postgresql.base.conf
daemon 8489 0.0 0.0 226608 1716 ? Ss Nov10 0:00 postgres: logger
daemon 8607 0.0 0.3 384348 36544 ? Ss Nov10 0:00 postgres: checkpointer
daemon 8608 0.0 0.0 384316 3972 ? Ss Nov10 0:01 postgres: background writer
daemon 8609 0.0 0.0 384180 5920 ? Ss Nov10 0:02 postgres: walwriter
daemon 8610 0.0 0.0 384912 2828 ? Ss Nov10 0:02 postgres: autovacuum launcher
daemon 8611 0.0 0.0 229788 2488 ? Ss Nov10 0:07 postgres: stats collector
daemon 8612 0.0 0.0 384724 2392 ? Ss Nov10 0:00 postgres: logical replication launcher
```
**postmaster**
當PG數據庫啟動時,首先會啟動Postmaster主進程。這個進程是PG數據庫的總控制進程,負責啟動和關閉數據庫實例。實際上Postmaster進程是一個指向postgres命令的鏈接。
```
SIS3.0.60.0 ~ # ll /home/fantom/party/pgsql/bin/postmaster
lrwxrwxrwx 1 daemon daemon 8 May 25 14:21 /home/fantom/party/pgsql/bin/postmaster -> postgres*
```
當用戶和PG數據庫建立連接時,要先與Postmaster進程建立連接,此時客戶端進程會發送身份驗證消息給Postmaster主進程,Postmaster主進程根據消息進行身份驗證,驗證通過后,Postmaster主進程會fork出一個會話服務進程為這個用戶連接服務。可以通過`pg_stat_activity`表來查看服務進程的pid
```
sip=# select pid,usename,client_addr,client_port from pg_stat_activity;
pid | usename | client_addr | client_port
--------+----------+-------------+-------------
43796 | sipadmin | 127.0.0.1 | 45431
25859 | sipadmin | 127.0.0.1 | 32942
23895 | sipadmin | 127.0.0.1 | 56456
...
(26 rows)
```
**background writer**
BgWriter進程是把共享內存中的臟頁寫到磁盤上的進程。它的作用有兩個:一是定期把臟數據從內存緩沖區刷出到磁盤中,減少查詢時的阻塞;二是PG在定期作檢查點時需要把所有臟頁寫出到磁盤,通過BgWriter預先寫出一些臟頁,可以減少設置檢查點(CheckPoint,數據庫恢復技術的一種)時要進行的IO操作,使系統的IO負載趨向平穩。可以通過postgresql.conf文件中以"bgwriter\_"開頭配置參數來控制
```
[root@izwz91quxhnlkan8kjak5hz ~]# cat /www/server/data/postgres/postgresql.conf | grep bgwriter_
#bgwriter_delay = 200ms # 10-10000ms between rounds
#bgwriter_lru_maxpages = 100 # max buffers written/round, 0 disables
#bgwriter_lru_multiplier = 2.0 # 0-10.0 multiplier on buffers scanned/round
#bgwriter_flush_after = 512kB # measured in pages, 0 disables
```
**logger**
Logger系統日志進程通過postmaster進程、服務進程和其余輔助進程收集所有的stderr輸出,并記錄到日志文件中
```
#logging_collector = off # 是否開啟日志收集器,當設置為on時啟動日志功能;否則,系統將不產生系統日志輔助進程。
# These are only used if logging_collector is on:
#log_directory = 'log' # 輸出日志目錄
#log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' # 文件命名規則
#log_file_mode = 0600 # 日志文件的創建模式,
#log_rotation_age = 1d # 自動輪轉日志文件
#log_rotation_size = 10MB # 配置日志文件大小,當前日志文件達到這個大小時會被關閉,然后創建一個新的文件來作為當前日志文件
```
**checkpointer**
檢查點是系統設置的事務序列點,設置檢查點保證檢查點前的日志信息刷到磁盤中。相關參數如下:
```
[root@izwz91quxhnlkan8kjak5hz ~]# cat /www/server/data/postgres/postgresql.conf | grep checkpoint
#checkpoint_timeout = 5min # 生成檢查點的最大的間隔時間
#checkpoint_completion_target = 0.5 # 參數表示checkpoint的完成目標,系統默認值是0.5,也就是說每個checkpoint需要在checkpoints間隔時間的50%內完成
#checkpoint_flush_after = 256kB # measured in pages, 0 disables
#checkpoint_warning = 30s # 0 disables
#log_checkpoints = off
```
**WalWriter**
預寫式日志WAL進程(Write Ahead Log,也稱為Xlog),預寫日志可以保證數據的完整性;在修改數據之前,數據庫會將修改操作記錄到磁盤中。這樣就不必擔心數據未持久化到磁盤導致數據丟失。如果數據庫宕機,重啟后數據庫會讀取WAL日志最后一部分重新執行,將數據庫恢復為宕機時的狀態。WAL日志保存在`$PGDATA/pg_wal`目錄下(在postgresql10之前,是存儲在pg_xlog目錄下)
**autovacuum launcher**
自動垃圾回收進程。在PostgreSQL中,對數據進行UPDATE或者DELETE操作后,數據庫不會立即刪除舊版本的數據,而是標記為刪除狀態。當事務提交后,舊版本的數據已經沒有價值了,數據庫需要清理垃圾數據騰出空間,而清理工作就是AutoVacuum進程進行的。相關參數如下:
```
[root@izwz91quxhnlkan8kjak5hz postgres]# cat /www/server/data/postgres/postgresql.conf | grep autovacuum
#autovacuum_work_mem = -1 # min 1MB, or -1 to use maintenance_work_mem
#autovacuum = on # 是否啟動系統自動清理功能,默認值為on
#log_autovacuum_min_duration = -1 # 在規定時長內未完成的vacuum予以記錄日志,-1表示禁用,0表示所有的,大于0僅記錄超過時間的
#autovacuum_max_workers = 3 # autovacuum最大線程數
#autovacuum_naptime = 1min # vacuum的間隔時間
#autovacuum_vacuum_threshold = 50 # 達到DML操作(增刪改)的最小行數則vacuum
#autovacuum_vacuum_insert_threshold = 1000 # 達到最小新增行數則vacuum
#autovacuum_analyze_threshold = 50 # 激活自動analyze操作的最小行數,analyze有利于對SQL語句進行更精準的plan(這是由于explain用到的pg_class列reltuples and relpages are not updated on-the-fly)
#autovacuum_vacuum_scale_factor = 0.2 # 表示autovacuum的vacuum操作所需的變更量閾值,當這個表的update/delete的tuple總數大于(pg_class.reltuples*autovacuum_vacuum_scale_factor+autovacuum_vacuum_threshold)時, 觸發vacuum操作
#autovacuum_vacuum_insert_scale_factor = 0.2 # fraction of inserts over table
#autovacuum_analyze_scale_factor = 0.1 # 表示autovacuum的analyze操作所需的變更量閾值,當這個表的INSERT/update/delete的tuple總數大于(pg_class.reltuples*autovacuum_analyze_scale_factor+autovacuum_analyze_threshold)時, 觸發analyze操作
#autovacuum_freeze_max_age = 200000000 # 指定表上事務的最大年齡,默認為2億,達到這個閥值將觸發 autovacuum進程,從而避免 wraparound。 表上的事務年齡可以通過 pg\_class.relfrozenxid 查詢
#autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age
#autovacuum_vacuum_cost_delay = 2ms # 運行一次vacuum的時長,如果超過此值則休眠然后起來接著vacuum,當autovacuum進程即將執行時,對vacuum執行cost進行評估,如果超過autovacuum_vacuum_cost_limit的值時,則延遲,這個延遲的時間值即為改成的值.
#autovacuum_vacuum_cost_limit = -1 # autovacuum進程的評估閥值,-1表示使用vacuum_cost_limit值,如果在執行 autovacuum進程期間評估的cost超過autovacuum_vacuum_cost_limit,則autovacuum進程則會休眠
```
**stats collector**
統計信息收集進程。
**logical replication launcher**
Logical Replication屬于邏輯復制,適用于數據庫實例的部分(單個數據庫或者某些表)的復制,目前只支持表復制.
# <span style="font-size:15px">**內存結構** </span>

- PHP
- PHP基礎
- PHP介紹
- 如何理解PHP是弱類型語言
- 超全局變量
- $_SERVER詳解
- 字符串處理函數
- 常用數組函數
- 文件處理函數
- 常用時間函數
- 日歷函數
- 常用url處理函數
- 易混淆函數區別(面試題常見)
- 時間戳
- PHP進階
- PSR規范
- RESTFUL規范
- 面向對象
- 三大基本特征和五大基本原則
- 訪問權限
- static關鍵字
- static關鍵字
- 靜態變量與普通變量
- 靜態方法與普通方法
- const關鍵字
- final關鍵字
- abstract關鍵字
- self、$this、parent::關鍵字
- 接口(interface)
- trait關鍵字
- instanceof關鍵字
- 魔術方法
- 構造函數和析構函數
- 私有屬性的設置獲取
- __toString()方法
- __clone()方法
- __call()方法
- 類的自動加載
- 設計模式詳解
- 關于設計模式的一些建議
- 工廠模式
- 簡單工廠模式
- 工廠方法模式
- 抽象工廠模式
- 區別和適用范圍
- 策略模式
- 單例模式
- HTTP
- 定義
- 特點
- 工作過程
- request
- response
- HTTP狀態碼
- URL
- GET和POST的區別
- HTTPS
- session與cookie
- 排序算法
- 冒泡排序算法
- 二分查找算法
- 直接插入排序算法
- 希爾排序算法
- 選擇排序算法
- 快速排序算法
- 循環算法
- 遞歸與尾遞歸
- 迭代
- 日期相關的類
- DateTimeInterface接口
- DateTime類
- DateTimeImmutable類
- DateInterval類
- DateTimeZone類
- DatePeriod類
- format參數格式
- DateInterval的format格式化參數
- 預定義接口
- ArrayAccess(數組式訪問)接口
- Serializable (序列化)接口
- Traversable(遍歷)接口
- Closure類
- Iterator(迭代器)接口
- IteratorAggregate(聚合迭代器) 接口
- Generator (生成器)接口
- composer
- composer安裝與使用
- python
- python3執行tarfile解壓文件報錯:tarfile.ReadError:file could not be opened successfully
- golang
- 單元測試
- 單元測試框架
- Golang內置testing包
- GoConvey庫
- testify庫
- 打樁與mock
- GoMock框架
- Gomonkey框架
- HTTP Mock
- httpMock
- mux庫/httptest
- 數據庫
- MYSQL
- SQL語言的分類
- 事務(重點)
- 索引
- 存儲過程
- 觸發器
- 視圖
- 導入導出數據庫
- 優化mysql數據庫的方法
- MyISAM與InnoDB區別
- 外連接、內連接的區別
- 物理文件結構
- PostgreSQL
- 編譯安裝
- pgsql常用命令
- pgsql應用目錄(bin目錄)文件結構解析
- pg_ctl
- initdb
- psql
- clusterdb
- cluster命令
- createdb
- dropdb
- createuser
- dropuser
- pg_config
- pg_controldata
- pg_checksums
- pgbench
- pg_basebackup
- pg_dump
- pg_dumpall
- pg_isready
- pg_receivewal
- pg_recvlogical
- pg_resetwal
- pg_restore
- pg_rewind
- pg_test_fsync
- pg_test_timing
- pg_upgrade
- pg_verifybackup
- pg_archivecleanup
- pg_waldump
- postgres
- reindexdb
- vacuumdb
- ecpg
- pgsql數據目錄文件結構解析
- pgsql數據目錄文件結構解析
- postgresql.conf解析
- pgsql系統配置參數說明
- pgsql索引類型
- 四種索引類型解析
- 索引之ctid解析
- 索引相關操作
- pgsql函數解析
- pgsql系統函數解析
- pgsql窗口函數解析
- pgsql聚合函數解析
- pgsql系統表解析
- pg_stat_all_indexes
- pg_stat_all_tables
- pg_statio_all_indexes
- pg_statio_all_tables
- pg_stat_database
- pg_stat_statements
- pg_extension
- pg_available_extensions
- pg_available_extension_versions
- pgsql基本原理
- 進程和內存結構
- 存儲結構
- 數據文件的內部結構
- 垃圾回收機制VACUUM
- 事務日志WAL
- 并發控制
- 介紹
- 事務ID-txid
- 元組結構-Tuple Structure
- 事務狀態記錄-Commit Log (clog)
- 事務快照-Transaction Snapshot
- 事務快照實例
- 事務隔離
- 事務隔離級別
- 讀已提交-Read committed
- 可重復讀-Repeatable read
- 可序列化-Serializable
- 讀未提交-Read uncommitted
- 鎖機制
- 擴展機制解析
- 擴展的定義
- 擴展的安裝方式
- 自定義創建擴展
- 擴展的管理
- 擴展使用實例
- 在pgsql中使用last、first聚合函數
- pgsql模糊查詢不走索引的解決方案
- pgsql的pg_trgm擴展解析與驗證
- 高可用
- LNMP
- LNMP環境搭建
- 一鍵安裝包
- 搭建方法
- 配置文件目錄
- 服務器管理系統
- 寶塔(Linux)
- 安裝與使用
- 開放API
- 自定義apache日志
- 一鍵安裝包LNMP1.5
- LNMP1.5:添加、刪除站點
- LNMP1.5:php多版本切換
- LNMP1.5 部署 thinkphp項目
- Operation not permitted解決方法
- Nginx
- Nginx的產生
- 正向代理和反向代理
- 負載均衡
- Linux常用命令
- 目錄與文件相關命令
- 目錄操作命令
- 文件編輯命令
- 文件查看命令
- 文件查找命令
- 文件權限命令
- 文件上傳下載命令
- 用戶和群組相關命令
- 用戶與用戶組的關系
- 用戶相關的系統配置文件
- 用戶相關命令
- 用戶組相關命令
- 壓縮與解壓相關命令
- .zip格式
- .tar.gz格式
- .gz格式
- .bz2格式
- 查看系統版本
- cpuinfo詳解
- meminfo詳解
- getconf獲取系統信息
- 磁盤空間相關命令
- 查看系統負載情況
- 系統環境變量
- 網絡相關命令
- ip命令詳解
- ip命令格式詳解
- ip address命令詳解
- ip link命令詳解
- ip rule命令詳解
- ip route命令詳解
- nslookup命令詳解
- traceroute命令詳解
- netstat命令詳解
- route命令詳解
- tcpdump命令詳解
- 系統進程相關命令
- ps命令詳解
- pstree命令詳解
- kill命令詳解
- 守護進程-supervisord
- 性能監控相關命令
- top命令詳解
- iostat命令詳解
- pidstat命令詳解
- iotop命令詳解
- mpstat命令詳解
- vmstat命令詳解
- ifstat命令詳解
- sar命令詳解
- iftop命令詳解
- 定時任務相關命令
- ssh登錄遠程主機
- ssh口令登錄
- ssh公鑰登錄
- ssh帶密碼登錄
- ssh端口映射
- ssh配置文件
- ssh安全設置
- 歷史紀錄
- history命令詳解
- linux開啟操作日志記錄
- 拓展
- git
- git初始化本地倉庫-https
- git初始化倉庫-ssh
- git-查看和設置config配置
- docker
- 概念
- docker原理
- docker鏡像原理
- docker Overlay2 文件系統原理
- docker日志原理
- docker日志驅動
- docker容器日志管理
- 原理論證
- 驗證容器的啟動是作為Docker Daemon的子進程
- 驗證syslog類型日志驅動
- 驗證journald類型日志驅動
- 驗證local類型日志驅動
- 修改容器的hostname
- 修改容器的hosts
- 驗證聯合掛載技術
- 驗證啟動多個容器對于磁盤的占用情況
- 驗證寫時復制原理
- 驗證docker內容尋址原理
- docker存儲目錄
- /var/lib/docker目錄
- image目錄
- overlay2目錄
- 數據卷
- 具名掛載和匿名掛載
- 數據卷容器
- Dockerfile詳解
- dockerfile指令詳解
- 實例:構造centos
- 實例:CMD和ENTRYPOINT的區別
- docker網絡詳解
- docker-compose
- 緩存
- redis
- redis的數據類型和應用場景
- redis持久化
- RDB持久化
- AOF持久化
- redis緩存穿透、緩存擊穿、緩存雪崩
- 常見網絡攻擊類型
- CSRF攻擊
- XSS攻擊
- SQL注入
- Cookie攻擊
- 歷史項目經驗
- 圖片上傳項目實例
- 原生php上傳方法實例
- base64圖片流
- tp5的上傳方法封裝實例
- 多級關系的遞歸查詢
- 數組轉樹結構
- thinkphp5.1+ajax實現導出Excel
- JS 刪除數組的某一項
- 判斷是否為索引數組
- ip操作