# TCP面試題
點擊關注本[公眾號](http://www.hmoore.net/book/dsh225/javascript_vue_css/edit#_118)獲取文檔最新更新,并可以領取配套于本指南的《**前端面試手冊**》以及**最標準的簡歷模板**.
TCP的面試題通常情況下前端不會涉及太多,此章主要面對node.js工程師。
[TOC]
## TCP 的特性
* TCP 提供一種面向連接的、可靠的字節流服務
* 在一個 TCP 連接中,僅有兩方進行彼此通信。廣播和多播不能用于 TCP
* TCP 使用校驗和,確認和重傳機制來保證可靠傳輸
* TCP 給數據分節進行排序,并使用累積確認保證數據的順序不變和非重復
* TCP 使用滑動窗口機制來實現流量控制,通過動態改變窗口的大小進行擁塞控制
## 請簡述TCP\\UDP的區別
| 協議 | 連接性 | 雙工性 | 可靠性 | 有序性 | 有界性 | 擁塞控制 | 傳輸速度 | 量級 | 頭部大小 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| TCP | 面向連接
(Connection oriented) | 全雙工(1:1) | 可靠
(重傳機制) | 有序
(通過SYN排序) | 無, 有[粘包情況](https://www.cxymsg.com/guide/tcp.html#%E7%B2%98%E5%8C%85) | 有 | 慢 | 低 | 20~60字節 |
| UDP | 無連接
(Connection less) | n:m | 不可靠
(丟包后數據丟失) | 無序 | 有消息邊界,**無粘包** | 無 | 快 | 高 | 8字節 |
UDP socket 支持 n 對 m 的連接狀態, 在[官方文檔](https://nodejs.org/dist/latest-v6.x/docs/api/dgram.html)中有寫到在`dgram.createSocket(options[, callback])`中的 option 可以指定`reuseAddr`即`SO_REUSEADDR`標志. 通過`SO_REUSEADDR`可以簡單的實現 n 對 m 的多播特性 (不過僅在支持多播的系統上才有).
## TCP粘包是怎么回事,如何處理? ?
默認情況下, TCP 連接會啟用延遲傳送算法 (Nagle 算法), 在數據發送之前緩存他們. 如果短時間有多個數據發送, 會緩沖到一起作一次發送 (緩沖大小見?`socket.bufferSize`), 這樣可以減少 IO 消耗提高性能.
如果是傳輸文件的話, 那么根本不用處理粘包的問題, 來一個包拼一個包就好了. 但是如果是多條消息, 或者是別的用途的數據那么就需要處理粘包.
可以參見網上流傳比較廣的一個例子, 連續調用兩次 send 分別發送兩段數據 data1 和 data2, 在接收端有以下幾種常見的情況:
* A. 先接收到 data1, 然后接收到 data2 .
* B. 先接收到 data1 的部分數據, 然后接收到 data1 余下的部分以及 data2 的全部.
* C. 先接收到了 data1 的全部數據和 data2 的部分數據, 然后接收到了 data2 的余下的數據.
* D. 一次性接收到了 data1 和 data2 的全部數據.
其中的 BCD 就是我們常見的粘包的情況. 而對于處理粘包的問題, 常見的解決方案有:
1. 多次發送之前間隔一個等待時間
2. 關閉 Nagle 算法
3. 進行封包/拆包
***方案1***
只需要等上一段時間再進行下一次 send 就好, 適用于交互頻率特別低的場景. 缺點也很明顯, 對于比較頻繁的場景而言傳輸效率實在太低. 不過幾乎不用做什么處理.
***方案2***
關閉 Nagle 算法, 在 Node.js 中你可以通過?[`socket.setNoDelay()`](https://nodejs.org/dist/latest-v6.x/docs/api/net.html#net_socket_setnodelay_nodelay)?方法來關閉 Nagle 算法, 讓每一次 send 都不緩沖直接發送.
該方法比較適用于每次發送的數據都比較大 (但不是文件那么大), 并且頻率不是特別高的場景. 如果是每次發送的數據量比較小, 并且頻率特別高的, 關閉 Nagle 純屬自廢武功.
另外, 該方法不適用于網絡較差的情況, 因為 Nagle 算法是在服務端進行的包合并情況, 但是如果短時間內客戶端的網絡情況不好, 或者應用層由于某些原因不能及時將 TCP 的數據 recv, 就會造成多個包在客戶端緩沖從而粘包的情況. (如果是在穩定的機房內部通信那么這個概率是比較小可以選擇忽略的)
***方案3***
封包/拆包是目前業內常見的解決方案了. 即給每個數據包在發送之前, 于其前/后放一些有特征的數據, 然后收到數據的時候根據特征數據分割出來各個數據包.
## 為什么udp不會粘包?
1.TCP協議是面向流的協議,UDP是面向消息的協議
UDP段都是一條消息,應用程序必須以消息為單位提取數據,不能一次提取任意字節的數據
2.UDP具有保護消息邊界,在每個UDP包中就有了消息頭(消息來源地址,端口等信息),這樣對于接收端來說就容易進行區分處理了。傳輸協議把數據當作一條獨立的消息在網上傳輸,接收端只能接收獨立的消息。接收端一次只能接收發送端發出的一個數據包,如果一次接受數據的大小小于發送端一次發送的數據大小,就會丟失一部分數據,即使丟失,接受端也不會分兩次去接收
## 如何理解 TCP backlog?
> 本文來自[How TCP backlog works in Linux](http://veithen.io/2014/01/01/how-tcp-backlog-works-in-linux.html)
當應用程序調用`listen`系統調用讓一個`socket`進入`LISTEN`狀態時,需要指定一個參數:`backlog`。這個參數經常被描述為,新連接隊列的長度限制。

tcp-state-diagram.png
由于`TCP`建立連接需要進行3次握手,一個新連接在到達`ESTABLISHED`狀態可以被`accept`系統調用返回給應用程序前,必須經過一個中間狀態`SYN RECEIVED`(見上圖)。這意味著,`TCP/IP`協議棧在實現`backlog`隊列時,有兩種不同的選擇:
1. 僅使用一個隊列,隊列規模由`listen`系統調用`backlog`參數指定。當協議棧收到一個`SYN`包時,響應`SYN/ACK`包并且將連接加進該隊列。當相應的`ACK`響應包收到后,連接變為`ESTABLISHED`狀態,可以向應用程序返回。這意味著隊列里的連接可以有兩種不同的狀態:`SEND RECEIVED`和`ESTABLISHED`。只有后一種連接才能被`accept`系統調用返回給應用程序。
2. 使用兩個隊列——`SYN`隊列(待完成連接隊列)和`accept`隊列(已完成連接隊列)。狀態為`SYN RECEIVED`的連接進入`SYN`隊列,后續當狀態變更為`ESTABLISHED`時移到`accept`隊列(即收到3次握手中最后一個`ACK`包)。顧名思義,`accept`系統調用就只是簡單地從`accept`隊列消費新連接。在這種情況下,`listen`系統調用`backlog`參數決定`accept`隊列的最大規模。
歷史上,起源于`BSD`的`TCP`實現使用第一種方法。這個方案意味著,但`backlog`限制達到,系統將停止對`SYN`包響應`SYN/ACK`包。通常,協議棧只是丟棄`SYN`包(而不是回一個`RST`包)以便客戶端可以重試(而不是異常退出)。
`TCP/IP詳解 卷3`第`14.5`節中有提到這一點。書中作者提到,`BSD`實現雖然使用了兩個獨立的隊列,但是行為跟使用一個隊列并沒什么區別。
在`Linux`上,情況有所不同,情況`listen`系統調用`man`文檔頁:
> The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp\_max\_syn\_backlog. When syncookies are enabled there is no logical maximum length and this setting is ignored. 意思是,`backlog`參數的行為在`Linux`2.2之后有所改變。現在,它指定了等待`accept`系統調用的已建立連接隊列的長度,而不是待完成連接請求數。待完成連接隊列長度由`/proc/sys/net/ipv4/tcp_max_syn_backlog`指定;在`syncookies`啟用的情況下,邏輯上沒有最大值限制,這個設置便被忽略。
也就是說,當前版本的`Linux`實現了第二種方案,使用兩個隊列——一個`SYN`隊列,長度系統級別可設置以及一個`accept`隊列長度由應用程序指定。
現在,一個需要考慮的問題是在`accept`隊列已滿而一個已完成新連接需要用`SYN`隊列移動到`accept`隊列(收到3次握手中最后一個`ACK`包),這個實現方案是什么行為。這種情況下,由`net/ipv4/tcp_minisocks.c`中`tcp_check_req`函數處理:
~~~
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
if (child == NULL)
goto listen_overflow;
~~~
對于`IPv4`,第一行代碼實際上調用的是`net/ipv4/tcp_ipv4.c`中的`tcp_v4_syn_recv_sock`函數,代碼如下:
~~~
if (sk_acceptq_is_full(sk))
goto exit_overflow;
~~~
可以看到,這里會檢查`accept`隊列的長度。如果隊列已滿,跳到`exit_overflow`標簽執行一些清理工作、更新`/proc/net/netstat`中的統計項`ListenOverflows`和`ListenDrops`,最后返回`NULL`。這會觸發`tcp_check_req`函數跳到`listen_overflow`標簽執行代碼。
~~~
listen_overflow:
if (!sysctl_tcp_abort_on_overflow) {
inet_rsk(req)->acked = 1;
return NULL;
}
~~~
很顯然,除非`/proc/sys/net/ipv4/tcp_abort_on_overflow`被設置為`1`(這種情況下發送一個`RST`包),實現什么都沒做。
總結一下:`Linux`內核協議棧在收到3次握手最后一個`ACK`包,確認一個新連接已完成,而`accept`隊列已滿的情況下,會忽略這個包。一開始您可能會對此感到奇怪——別忘了`SYN RECEIVED`狀態下有一個計時器實現:如果`ACK`包沒有收到(或者是我們討論的忽略),協議棧會重發`SYN/ACK`包(重試次數由`/proc/sys/net/ipv4/tcp_synack_retries`決定)。
看以下抓包結果就非常明顯——一個客戶正嘗試連接一個已經達到其最大`backlog`的`socket`:
~~~
0.000 127.0.0.1 -> 127.0.0.1 TCP 74 53302 > 9999 [SYN] Seq=0 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 66 53302 > 9999 [ACK] Seq=1 Ack=1 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 71 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
0.207 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
0.623 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
1.199 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
1.199 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 6#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
1.455 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
3.123 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
3.399 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
3.399 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 10#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
6.459 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
7.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
7.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 13#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
13.131 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
15.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
15.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 16#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
26.491 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
31.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
31.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 19#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
53.179 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
106.491 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
106.491 127.0.0.1 -> 127.0.0.1 TCP 54 9999 > 53302 [RST] Seq=1 Len=0
~~~
由于客戶端的`TCP`實現在收到多個`SYN/ACK`包時,認為`ACK`包已經丟失了并且重傳它。如果在`SYN/ACK`重試次數達到限制前,服務端應用從`accept`隊列接收連接,使得`backlog`減少,那么協議棧會處理這些重傳的`ACK`包,將連接狀態從`SYN RECEIVED`變更到`ESTABLISHED`并且將其加入`accept`隊列。否則,正如以上包跟蹤所示,客戶讀會收到一個`RST`包宣告連接失敗。
在客戶端看來,第一次收到`SYN/ACK`包之后,連接就會進入`ESTABLISHED`狀態。如果這時客戶端首先開始發送數據,那么數據也會被重傳。好在`TCP`有慢啟動機制,在服務端還沒進入`ESTABLISHED`之前,客戶端能發送的數據非常有限。
相反,如果客戶端一開始就在等待服務端,而服務端`backlog`沒能減少,那么最后的結果是連接在客戶端看來是`ESTABLISHED`狀態,但在服務端看來是`CLOSED`狀態。這也就是所謂的半開連接。
有一點還沒討論的是:`man listen`中提到每次收到新`SYN`包,內核往`SYN`隊列追加一個新連接(除非該隊列已滿)。事實并非如此,`net/ipv4/tcp_ipv4.c`中`tcp_v4_conn_request`函數負責處理`SYN`包,請看以下代碼:
~~~
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
~~~
可以看到,在`accept`隊列已滿的情況下,內核會強制限制`SYN`包的接收速率。如果有大量`SYN`包待處理,它們其中的一些會被丟棄。這樣看來,就完全依靠客戶端重傳`SYN`包了,這種行為跟`BSD`實現一樣。
下結論前,需要再研究以下`Linux`這種實現方式跟`BSD`相比有什么優勢。`Stevens`是這樣說的:
> 在`accept`隊列已滿或者`SYN`隊列已滿的情況下,`backlog`會達到限制。第一種情況經常發生在服務器或者服務器進程非常繁忙的情況下,進程沒法足夠快地調用`accept`系統調用從中取出已完成連接。后者是`HTTP`服務器經常面臨的問題,在服務端客戶端往返時間非常長的時候(相對于連接到達速率),因為新`SYN`包在往返時間內都會占據一個連接對象。 大多數情況下`accept`隊列都是空的,因為一旦有一個新連接進入隊列,阻塞等待的`accept`系統調用將返回,然后連接從隊列中取出。
`Stevens`建議的解決方案是簡單地調大`backlog`。但有個問題是,應用程序在調優`backlog`參數時,不僅需要考慮自身對新連接的處理邏輯,還需要考慮網絡狀況,包括往返時間等。Linux實現實際上分成兩部分:應用程序只負責調解`backlog`參數,確保`accept`調用足夠快以免`accept`隊列被塞滿;系統管理員則根據網絡狀況調節`/proc/sys/net/ipv4/tcp_max_syn_backlog`,各司其職。
## 常用端口號與對應的服務
| 端口 | 作用說明 |
| --- | --- |
| 21 | 21端口主要用于FTP(File Transfer Protocol,文件傳輸協議)服務。 |
| 23 | 23端口主要用于Telnet(遠程登錄)服務,是Internet上普遍采用的登錄和仿真程序。 |
| 25 | 25端口為SMTP(Simple Mail Transfer Protocol,簡單郵件傳輸協議)服務器所開放,主要用于發送郵件,如今絕大多數郵件服務器都使用該協議。 |
| 53 | 53端口為DNS(Domain Name Server,域名服務器)服務器所開放,主要用于域名解析,DNS服務在NT系統中使用的最為廣泛。 |
| 67、68 | 67、68端口分別是為Bootp服務的Bootstrap Protocol Server(引導程序協議服務端)和Bootstrap Protocol Client(引導程序協議客戶端)開放的端口。 |
| 69 | TFTP是Cisco公司開發的一個簡單文件傳輸協議,類似于FTP。 |
| 79 | 79端口是為Finger服務開放的,主要用于查詢遠程主機在線用戶、操作系統類型以及是否緩沖區溢出等用戶的詳細信息。 |
| 80 | 80端口是為HTTP(HyperText Transport Protocol,超文本傳輸協議)開放的,這是上網沖浪使用最多的協議,主要用于在WWW(World WideWeb,萬維網)服務上傳輸信息的協議。 |
| 99 | 99端口是用于一個名為“Metagram Relay”(亞對策延時)的服務,該服務比較少見,一般是用不到的。 |
| 109、110 | 109端口是為POP2(Post Office Protocol Version 2,郵局協議2)服務開放的,110端口是為POP3(郵件協議3)服務開放的,POP2、POP3都是主要用于接收郵件的。 |
| 111 | 111端口是SUN公司的RPC(Remote ProcedureCall,遠程過程調用)服務所開放的端口,主要用于分布式系統中不同計算機的內部進程通信,RPC在多種網絡服務中都是很重要的組件。 |
| 113 | 113端口主要用于Windows的“Authentication Service”(驗證服務)。 119端口:119端口是為“Network News TransferProtocol”(網絡新聞組傳輸協議,簡稱NNTP)開放的。 |
| 135 | 135端口主要用于使用RPC(Remote Procedure Call,遠程過程調用)協議并提供DCOM(分布式組件對象模型)服務。 |
| 137 | 137端口主要用于“NetBIOS Name Service”(NetBIOS名稱服務)。 |
| 139 | 139端口是為“NetBIOS Session Service”提供的,主要用于提供Windows文件和打印機共享以及Unix中的Samba服務。 |
| 143 | 143端口主要是用于“Internet Message Access Protocol”v2(Internet消息訪問協議,簡稱IMAP)。 |
| 161 | 161端口是用于“Simple Network Management Protocol”(簡單網絡管理協議,簡稱SNMP)。 |
| 443 | 443端口即網頁瀏覽端口,主要是用于HTTPS服務,是提供加密和通過安全端口傳輸的另一種HTTP。 |
| 554 | 554端口默認情況下用于“Real Time Streaming Protocol”(實時流協議,簡稱RTSP)。 |
| 1024 | 1024端口一般不固定分配給某個服務,在英文中的解釋是“Reserved”(保留)。 |
| 1080 | 1080端口是Socks代理服務使用的端口,大家平時上網使用的WWW服務使用的是HTTP協議的代理服務。 |
| 1755 | 1755端口默認情況下用于“Microsoft Media Server”(微軟媒體服務器,簡稱MMS)。 |
| 4000 | 4000端口是用于大家經常使用的QQ聊天工具的,再細說就是為QQ客戶端開放的端口,QQ服務端使用的端口是8000。 |
| 5554 | 在今年4月30日就報道出現了一種針對微軟lsass服務的新蠕蟲病毒——震蕩波(Worm.Sasser),該病毒可以利用TCP 5554端口開啟一個FTP服務,主要被用于病毒的傳播。 |
| 5632 | 5632端口是被大家所熟悉的遠程控制軟件pcAnywhere所開啟的端口。 |
| 8080 | 8080端口同80端口,是被用于WWW代理服務的,可以實現網頁。 |
## 說一說OSI七層模型
## 講一下三次握手??
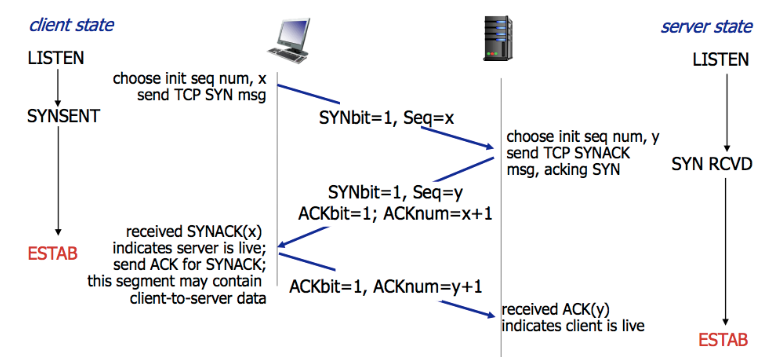
所謂三次握手(Three-way Handshake),是指建立一個 TCP 連接時,需要客戶端和服務器總共發送3個包。
三次握手的目的是連接服務器指定端口,建立 TCP 連接,并同步連接雙方的序列號和確認號,交換 TCP 窗口大小信息。在 socket 編程中,客戶端執行?`connect()`?時。將觸發三次握手。
* 第一次握手(SYN=1, seq=x):
客戶端發送一個 TCP 的 SYN 標志位置1的包,指明客戶端打算連接的服務器的端口,以及初始序號 X,保存在包頭的序列號(Sequence Number)字段里。
發送完畢后,客戶端進入?`SYN_SEND`?狀態。
* 第二次握手(SYN=1, ACK=1, seq=y, ACKnum=x+1):
服務器發回確認包(ACK)應答。即 SYN 標志位和 ACK 標志位均為1。服務器端選擇自己 ISN 序列號,放到 Seq 域里,同時將確認序號(Acknowledgement Number)設置為客戶的 ISN 加1,即X+1。 發送完畢后,服務器端進入?`SYN_RCVD`?狀態。
* 第三次握手(ACK=1,ACKnum=y+1)
客戶端再次發送確認包(ACK),SYN 標志位為0,ACK 標志位為1,并且把服務器發來 ACK 的序號字段+1,放在確定字段中發送給對方,并且在數據段放寫ISN的+1
發送完畢后,客戶端進入?`ESTABLISHED`?狀態,當服務器端接收到這個包時,也進入?`ESTABLISHED`?狀態,TCP 握手結束。
三次握手的過程的示意圖如下:
## 講一下四次握手??
TCP 的連接的拆除需要發送四個包,因此稱為四次揮手(Four-way handshake),也叫做改進的三次握手。客戶端或服務器均可主動發起揮手動作,在 socket 編程中,任何一方執行?`close()`?操作即可產生揮手操作。
* 第一次揮手(FIN=1,seq=x)
假設客戶端想要關閉連接,客戶端發送一個 FIN 標志位置為1的包,表示自己已經沒有數據可以發送了,但是仍然可以接受數據。
發送完畢后,客戶端進入?`FIN_WAIT_1`?狀態。
* 第二次揮手(ACK=1,ACKnum=x+1)
服務器端確認客戶端的 FIN 包,發送一個確認包,表明自己接受到了客戶端關閉連接的請求,但還沒有準備好關閉連接。
發送完畢后,服務器端進入?`CLOSE_WAIT`?狀態,客戶端接收到這個確認包之后,進入?`FIN_WAIT_2`?狀態,等待服務器端關閉連接。
* 第三次揮手(FIN=1,seq=y)
服務器端準備好關閉連接時,向客戶端發送結束連接請求,FIN 置為1。
發送完畢后,服務器端進入?`LAST_ACK`?狀態,等待來自客戶端的最后一個ACK。
* 第四次揮手(ACK=1,ACKnum=y+1)
客戶端接收到來自服務器端的關閉請求,發送一個確認包,并進入?`TIME_WAIT`狀態,等待可能出現的要求重傳的 ACK 包。
服務器端接收到這個確認包之后,關閉連接,進入?`CLOSED`?狀態。
客戶端等待了某個固定時間(兩個最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,沒有收到服務器端的 ACK ,認為服務器端已經正常關閉連接,于是自己也關閉連接,進入?`CLOSED`?狀態。
四次揮手的示意圖如下:

* * *
## 一文搞懂TCP的三次握手和四次揮手
https://blog.csdn.net/m0_38106923/article/details/108292454
參考:
1. [餓了么面試](https://github.com/ElemeFE/node-interview/blob/master/sections/zh-cn/network.md#net)
2. [TCP](https://hit-alibaba.github.io/interview/basic/network/TCP.html)
* * *
## 公眾號
想要實時關注筆者最新的文章和最新的文檔更新請關注公眾號**程序員面試官**,后續的文章會優先在公眾號更新.
**簡歷模板**:關注公眾號回復「模板」獲取
**《前端面試手冊》**:配套于本指南的突擊手冊,關注公眾號回復「fed」獲取

- 前言
- 指南使用手冊
- 為什么會有這個項目
- 面試技巧
- 面試官到底想看什么樣的簡歷?
- 面試回答問題的技巧
- 如何通過HR面
- 推薦
- 書籍/課程推薦
- 前端基礎
- HTML基礎
- CSS基礎
- JavaScript基礎
- 瀏覽器與新技術
- DOM
- 前端基礎筆試
- HTTP筆試部分
- JavaScript筆試部分
- 前端原理詳解
- JavaScript的『預解釋』與『變量提升』
- Event Loop詳解
- 實現不可變數據
- JavaScript內存管理
- 實現深克隆
- 如何實現一個Event
- JavaScript的運行機制
- 計算機基礎
- HTTP協議
- TCP面試題
- 進程與線程
- 數據結構與算法
- 算法面試題
- 字符串類面試題
- 前端框架
- 關于前端框架的面試須知
- Vue面試題
- React面試題
- 框架原理詳解
- 虛擬DOM原理
- Proxy比defineproperty優劣對比?
- setState到底是異步的還是同步的?
- 前端路由的實現
- redux原理全解
- React Fiber 架構解析
- React組件復用指南
- React-hooks 抽象組件
- 框架實戰技巧
- 如何搭建一個組件庫的開發環境
- 組件設計原則
- 實現輪播圖組件
- 性能優化
- 前端性能優化-加載篇
- 前端性能優化-執行篇
- 工程化
- webpack面試題
- 前端工程化
- Vite
- 安全
- 前端安全面試題
- npm
- 工程化原理
- 如何寫一個babel
- Webpack HMR 原理解析
- webpack插件編寫
- webpack 插件化設計
- Webpack 模塊機制
- webpack loader實現
- 如何開發Babel插件
- git
- 比較
- 查看遠程倉庫地址
- git flow
- 比較分支的不同并保存壓縮文件
- Tag
- 回退
- 前端項目經驗
- 確定用戶是否在當前頁面
- 前端下載文件
- 只能在微信中訪問
- 打開新頁面-被瀏覽器攔截
- textarea高度隨內容變化 vue版
- 去掉ios原始播放大按鈕
- nginx在MAC上的安裝、啟動、重啟和關閉
- 解析latex格式的數學公式
- 正則-格式化a鏈接
- 封裝的JQ插件庫
- 打包問題總結
- NPM UI插件
- 帶你入門前端工程
- webWorker+indexedDB性能優化
- 多個相鄰元素切換效果出現邊框重疊問題的解決方法
- 監聽前端storage變化