
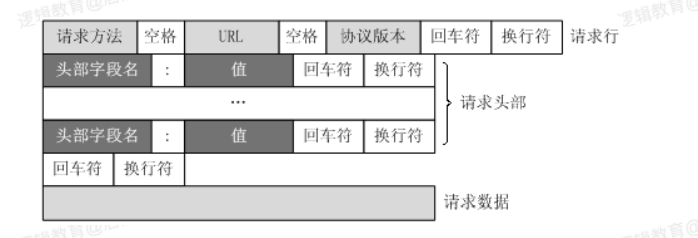
URL只是標識資源的位置,?HTTP是?來提交和獲取資源。客戶端發送?個 HTTP請求到服務器的請求消息,包括以下格式: 請求?、請求頭部、空?、請求數據 四個部分組成,下圖給出了請求報?的?般格式。
:-: 
**?個典型的HTTP請求示例**
```
GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.3
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/web
Sec-Fetch-Site: same-origin
Referer: https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=bai
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: BIDUPSID=4049831E3DB8DE890DFFCA6103FF02C1;
```
**請求?法**
根據HTTP標準,HTTP請求可以使?多種請求?法。<br/>
HTTP 0.9:只有基本的?本 GET 功能。
HTTP 1.0:完善的請求/響應模型,并將協議補充完整,定義了三種請求?法: GET, POST 和 HEAD?法。
HTTP 1.1:在 1.0 基礎上進?更新,新增了五種請求?法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT ?法。
HTTP 2.0(未普及):請求/響應?部的定義基本沒有改變,只是所有?部鍵 必須全部?寫,?且請求?要獨?為 :method、:scheme、:host、:path這些 鍵值對。
<br/>
:-: **HTTP請求方法類型**
| 序號 | ?法 | 描述 |
| --- | --- | --- |
| 1 | GET | 請求指定的??信息,并返回實 體主體。 |
| 2 | HEAD | 類似于get請求,只不過返回的 響應中沒有具體的內容,?于獲 取報頭 |
| 3 | POST | 向指定資源提交數據進?處理請 求(例如提交表單或者上傳? 件),數據被包含在請求體中。 POST請求可能會導致新的資源 的建?和/或已有資源的修改。 |
| 4 | PUT | 從客戶端向服務器傳送的數據取 代指定的?檔的內容。 |
| 5 | DELETE | 請求服務器刪除指定的??。 |
| 6 | CONNECT | HTTP/1.1協議中預留給能夠將連 接改為管道?式的代理服務器。 |
| 7 | OPTIONS | 允許客戶端查看服務器的性能。 |
| 8 | TRACE | 回顯服務器收到的請求,主要? 于測試或診斷。 |
**HTTP請求主要分為Get和Post兩種?法**
* GET是從服務器上獲取數據,POST是向服務器傳送數據
* GET請求參數顯示,都顯示在瀏覽器?址上,HTTP服務器根據該請求所 包含URL中的參數來產?響應內容,即Get請求的參數是URL的?部 分。 例如: http://www.baidu.com/s?wd=Chinese
* POST請求參數在請求體當中,消息?度沒有限制?且以隱式的?式進? 發送,通常?來向HTTP服務器提交量?較?的數據(?如請求中包含許 多參數或者?件上傳操作等),請求的參數包含在“Content-Type”消息 頭?,指明該消息體的媒體類型和編碼
**常?的請求報頭:**
**1. Host (主機和端?號)**
Host:對應?址URL中的Web名稱和端?號,?于指定被請求資源的Internet 主機和端?號,通常屬于URL的?部分。<br/>
**2. Connection (鏈接類型)**
Connection:表示客戶端與服務連接類型
(1)Client 發起?個包含 Connection:keep-alive 的請求,HTTP/1.1使 ? keep-alive 為默認值。
(2)Server收到請求后:
* 如果 Server ?持 keep-alive,回復?個包含 Connection:keep- alive 的響應,不關閉連接;
* 如果 Server 不?持 keep-alive,回復?個包含 Connection:close 的響應,關閉連接。
(3)如果client收到包含 Connection:keep-alive 的響應,向同?個連接 發送下?個請求,直到??主動關閉連接。<br/>
**3. Upgrade-Insecure-Requests (升級為HTTPS請求)**
Upgrade-Insecure-Requests:升級不安全的請求,意思是會在加載 http 資 源時?動替換成 https 請求,讓瀏覽器不再顯示https??中的http請求警報。<br/>
**4. User-Agent (瀏覽器名稱)**
User-Agent:是客戶瀏覽器的名稱<br/>
**5. Accept (傳輸?件類型)**
Accept:指瀏覽器或其他客戶端可以接受的MIME(Multipurpose Internet Mail Extensions(多?途互聯?郵件擴展))?件類型,服務器可以根據它判 斷并返回適當的?件格式。
`Accept: */* `:表示什么都可以接收。
`Accept:image/gif` :表明客戶端希望接受GIF圖像格式的資源;
`Accept:text/html` :表明客戶端希望接受html?本。
`Accept: text/html, application/xhtml+xml;q=0.9, image/*;q=0.8` :表示瀏覽器?持的 MIME 類型分別是 html?本、xhtml和 xml?檔、所有的圖像格式資源。<br/>
**6. Referer (??跳轉處)**
Referer:表明產?請求的??來?于哪個URL,?戶是從該 Referer??訪問 到當前請求的??。這個屬性可以?來跟蹤Web請求來?哪個??,是從什么?站來的等。<br/>
**7. Accept-Encoding(?件編解碼格式)**
Accept-Encoding:指出瀏覽器可以接受的編碼?式。編碼?式不同于?件格 式,它是為了壓縮?件并加速?件傳遞速度。瀏覽器在接收到Web響應之后先 解碼,然后再檢查?件格式,許多情形下這可以減少?量的下載時間。<br/>
**8. Accept-Language(語?種類)**
Accept-Langeuage:指出瀏覽器可以接受的語?種類,如en或en-us指英 語,zh或者zh-cn指中?,當服務器能夠提供?種以上的語?版本時要?到。<br/>
**9. Accept-Charset(字符編碼)**
Accept-Charset:指出瀏覽器可以接受的字符編碼。 <br/>
**10. Cookie (Cookie)**
Cookie:瀏覽器?這個屬性向服務器發送Cookie。Cookie是在瀏覽器中寄存 的?型數據體,它可以記載和服務器相關的?戶信息。<br/>
**11. Content-Type (POST數據類型)**
Content-Type:POST請求??來表示的內容類型。
- 爬蟲基本概念
- 爬蟲介紹
- 通用爬蟲與聚焦爬蟲
- 通用爬蟲
- 聚焦爬蟲
- HTTP與HTTPS協議
- HTTP協議簡介
- HTTP的請求與響應
- 客戶端HTTP請求
- 服務端HTTP響應
- requests庫
- requests庫簡介
- requests簡單使用
- 發送帶header的請求
- 發送帶參數的請求
- 案例:下載百度貼吧頁面
- 發送POST請求
- 使用代理
- 為什么要使用代理?
- 正反向代理
- 代理服務器分類
- 使用代理
- cookie和session
- cookie和session的區別
- 爬蟲處理cookie和session
- 使用session登錄網站
- 使用cookie登錄網站
- cookiejar
- 超時和重試
- verify參數忽略CA證書
- URL地址的解碼和編碼
- 數據處理
- json數據處理
- json數據處理方案
- json模塊處理json數據
- jsonpath處理json數據
- 正則表達式
- lxml
- xpath與lxml介紹
- xpathhelper插件
- 案例
- Beautiful Soup
- Beautiful Soup介紹
- 解析器
- CSS選擇器
- 案例
- 四大對象
- 爬蟲與反爬蟲
- 爬蟲與反爬蟲的斗爭
- 服務器反爬的原因
- 什么樣的爬蟲會被反爬
- 反爬領域常見概念
- 反爬的三個方向
- 基于身份識別進行反爬
- 基于爬蟲行為進行反爬
- 基于數據加密進行反爬
- js解析
- chrome瀏覽器使用
- 定位js
- 設置斷點
- js2py
- hashlib
- 有道翻譯案例
- 動態爬取HTML
- 動態HTML
- 獲取Ajax數據的方式
- selenium+driver
- driver定位
- 表單元素操作
- 行為鏈
- cookie操作
- 頁面等待
- 多窗口與頁面切換
- 配置對象
- 拉勾網案例
- 圖片驗證碼識別
- 圖形驗證碼識別技術簡介
- Tesseract
- pytesseract處理圖形驗證碼
- 打碼平臺
- 登錄打碼平臺
- 驗證碼種類
- 多任務-線程
- 繼承Thread創建線程
- 查看線程數量
- 資源共享
- 互斥鎖
- 死鎖
- 避免死鎖
- Queue線程
- 多線程爬蟲
- 多任務-進程
- 創建進程
- 進程池
- 進程間的通信
- Python GIL
- scrapy框架
- scrapy是什么?
- scrapy爬蟲流程
- 創建scrapy項目
- Selector選擇器
- logging
- scrapy shell
- 保存數據
- Item數據建模
- 翻頁請求
- Request
- CrawlSpider
- settings
- 模擬登錄
- 保存文件
- 內置Pipeline
- 自定義Pipeline
- 中間件
- selenium動態加載
- 防止反爬
- 隨機User-Agent
- 隨機IP代理
- settings中的參數
- 隨機延遲
- request.meta常用參數
- 分布式爬蟲
- 分布式原理
- scrapy_redis
- 去重問題
- 分布式爬蟲編寫流程
- CrawSpider改寫成分布式
- scrapy_splash
- scrapy_splash是什么?
- scrapy_splash環境搭建
- APP抓取
- Android模擬器
- appium
- appium是什么?
- appium環境搭建
- appium環境聯調測試
- appium的使用
- 演示項目-抓取抖音app
- 抖音app與appium的聯調測試
- 元素定位
- 抖音appium代碼
- 抓包軟件
- url去重處理