
實驗平臺:Win7,VS2013 Community,GCC 4.8.3(在線版)
所謂元編程就是編寫直接生成或操縱程序的程序,C++ 模板給 C++ 語言提供了元編程的能力,模板使 C++ 編程變得異常靈活,能實現很多高級動態語言才有的特性(語法上可能比較丑陋,一些歷史原因見下文)。普通用戶對 C++ 模板的使用可能不是很頻繁,大致限于泛型編程,但一些系統級的代碼,尤其是對通用性、性能要求極高的基礎庫(如 STL、Boost)幾乎不可避免的都大量地使用 C++ 模板,一個稍有規模的大量使用模板的程序,不可避免的要涉及元編程(如類型計算)。
本文就是要剖析 C++ 模板元編程的機制。
**C++模板的語法**
函數模板(function template)和類模板(class template)的簡單示例如下:
~~~
#include <iostream>
~~~
程序輸出如下:
~~~
1
~~~
關于模板(函數模板、類模板)的**模板參數**(詳見文獻\[1\]第3章):
* 類型參數(type template parameter),用 typename 或 class 標記;
* 非類型參數(non-type template parameter)可以是:整數及枚舉類型、對象或函數的指針、對象或函數的引用、對象的成員指針,非類型參數是模板實例的常量;
* 模板型參數(template template parameter),如“template class A> someclass {};”;
* 模板參數可以有默認值(函數模板參數默認是從 C++11 開始支持);
* 函數模板的和函數參數類型有關的模板參數可以自動推導,類模板參數不存在推導機制;
* C++11 引入變長模板參數,請見下文。
**模板特例化**(template specialization,又稱特例、特化)的簡單示例如下:
~~~
// 實現一個向量類
~~~
所謂模板特例化即對于通例中的某種或某些情況做單獨專門實現,最簡單的情況是對每個模板參數指定一個具體值,這成為完全特例化(full specialization),另外,可以限制模板參數在一個范圍取值或滿足一定關系等,這稱為部分特例化(partial specialization),用數學上集合的概念,通例模板參數所有可取的值組合構成全集U,完全特例化對U中某個元素進行專門定義,部分特例化對U的某個真子集進行專門定義。
更多模板特例化的例子如下(參考了文獻\[1\]第44頁):
~~~
template<typename T, int i> class cp00; // 用于模板型模板參數
~~~
關于模板特例化(詳見文獻\[1\]第4章):
* 在定義模板特例之前必須已經有模板通例(primary template)的聲明;
* 模板特例并不要求一定與通例有相同的接口,但為了方便使用(體會特例的語義)一般都相同;
* 匹配規則,在模板實例化時如果有模板通例、特例加起來多個模板版本可以匹配,則依據如下規則:對版本AB,如果 A 的模板參數取值集合是B的真子集,則優先匹配 A,如果 AB 的模板參數取值集合是“交叉”關系(AB 交集不為空,且不為包含關系),則發生編譯錯誤,對于函數模板,用函數重載分辨(overload resolution)規則和上述規則結合并優先匹配非模板函數。
對模板的多個實例,**類型等價**(type equivalence)判斷規則(詳見文獻\[2\] 13.2.4):同一個模板(模板名及其參數類型列表構成的模板簽名(template signature)相同,函數模板可以重載,類模板不存在重載)且指定的模板實參等價(類型參數是等價類型,非類型參數值相同)。如下例子:
~~~
#include <iostream>
~~~
~~~
1
~~~
關于**模板實例化**(template instantiation)(詳見文獻\[4\]模板):
* 指在編譯或鏈接時生成函數模板或類模板的具體實例源代碼,即用使用模板時的實參類型替換模板類型參數(還有非類型參數和模板型參數);
* 隱式實例化(implicit instantiation):當使用實例化的模板時自動地在當前代碼單元之前插入模板的實例化代碼,模板的成員函數一直到引用時才被實例化;
* 顯式實例化(explicit instantiation):直接聲明模板實例化,模板所有成員立即都被實例化;
* 實例化也是一種特例化,被稱為實例化的特例(instantiated (or generated) specialization)。
隱式實例化時,成員只有被引用到才會進行實例化,這被稱為推遲實例化(lazy instantiation),由此可能帶來的問題如下面的例子(文獻\[6\],文獻\[7\]):
~~~
#include <iostream>
~~~
所以模板代碼寫完后最好寫個諸如顯示實例化的測試代碼,更深入一些,可以插入一些模板調用代碼使得編譯器及時發現錯誤,而不至于報出無限長的錯誤信息。另一個例子如下(GCC 4.8 下編譯的輸出信息,VS2013 編譯輸出了 500 多行錯誤信息):
~~~
#include <iostream>
~~~
~~~
sh-4.2# g++ -std=c++11 -o main *.cpp
~~~
上面的錯誤是因為,當編譯 aTMP 時,并不判斷 N==0,而僅僅知道其依賴 aTMP(lazy instantiation),從而產生無限遞歸,糾正方法是使用模板特例化,如下:
~~~
#include <iostream>
~~~
~~~
3228800
~~~
關于模板的**編譯和鏈接**(詳見文獻\[1\] 1.3、文獻\[4\]模板):
* 包含模板編譯模式:編譯器生成每個編譯單元中遇到的所有的模板實例,并存放在相應的目標文件中;鏈接器合并等價的模板實例,生成可執行文件,要求實例化時模板定義可見,不能使用系統鏈接器;
* 分離模板編譯模式(使用 export 關鍵字):不重復生成模板實例,編譯器設計要求高,可以使用系統鏈接器;
* 包含編譯模式是主流,C++11 已經棄用 export 關鍵字(對模板引入 extern 新用法),一般將模板的全部實現代碼放在同一個頭文件中并在用到模板的地方用 #include 包含頭文件,以防止出現實例不一致(如下面緊接著例子);
實例化,編譯鏈接的簡單例子如下(參考了文獻\[1\]第10頁):
~~~
// file: a.cpp
~~~
~~~
// file: b.cpp
~~~
~~~
a.cpp: 1
~~~
上例中,由于 a.cpp 和 b.cpp 中的 print 實例等價(模板實例的二進制代碼在編譯生成的對象文件 a.obj、b.obj 中),故鏈接時消除了一個(消除哪個沒有規定,上面消除了 b.cpp 中的)。
關于?**template**、**typename**、**this**關鍵字的使用(文獻\[4\]模板,文獻\[5\]):
* 依賴于模板參數(template parameter,形式參數,實參英文為 argument)的名字被稱為依賴名字(dependent name),C++標準規定,如果解析器在一個模板中遇到一個嵌套依賴名字,它假定那個名字不是一個類型,除非顯式用 typename 關鍵字前置修飾該名字;
* 和上一條 typename 用法類似,template 用于指明嵌套類型或函數為模板;
* this 用于指定查找基類中的成員(當基類是依賴模板參數的類模板實例時,由于實例化總是推遲,這時不依賴模板參數的名字不在基類中查找,文獻\[1\]第 166 頁)。
一個例子如下(需要 GCC 編譯,GCC 對 C++11 幾乎全面支持,VS2013 此處總是在基類中查找名字,且函數模板前不需要 template):
~~~
#include <iostream>
~~~
~~~
global f()
~~~
**C++11 關于模板的新特性**(詳見文獻\[1\]第15章,文獻\[4\]C++11):
* “>>” 根據上下文自動識別正確語義;
* 函數模板參數默認值;
* 變長模板參數(擴展 sizeof...() 獲取參數個數);
* 模板別名(擴展 using 關鍵字);
* 外部模板實例(拓展 extern 關鍵字),棄用 export template。
在本文中,如無特別聲明將不使用 C++11 的特性(除了 “>>”)。
**2**
****模板元編程概述****
如果對 C++ 模板不熟悉(光熟悉語法還不算熟悉),可以先跳過本節,往下看完例子再回來。
C++ 模板最初是為實現泛型編程設計的,但人們發現模板的能力遠遠不止于那些設計的功能。一個重要的理論結論就是:C++ 模板是**圖靈完備**的(Turing-complete),其證明過程請見文獻\[8\](就是用 C++ 模板模擬圖靈機),理論上說 C++ 模板可以執行任何計算任務,但實際上因為模板是編譯期計算,其能力受到具體編譯器實現的限制(如遞歸嵌套深度,C++11 要求至少 1024,C++98 要求至少 17)。C++ 模板元編程是“意外”功能,而不是設計的功能,這也是 C++ 模板元編程語法丑陋的根源。
C++ 模板是圖靈完備的,這使得 C++ 成為**兩層次語言**(two-level languages,中文暫且這么翻譯,文獻\[9\]),其中,執行編譯計算的代碼稱為靜態代碼(static code),執行運行期計算的代碼稱為動態代碼(dynamic code),C++ 的靜態代碼由模板實現(預處理的宏也算是能進行部分靜態計算吧,也就是能進行部分元編程,稱為宏元編程,見 Boost 元編程庫即 BCCL,文獻\[16\]和文獻\[1\] 10.4)。
具體來說 C++ 模板可以做以下事情:編譯期數值計算、類型計算、代碼計算(如循環展開),其中數值計算實際不太有意義,而類型計算和代碼計算可以使得代碼更加通用,更加易用,性能更好(也更難閱讀,更難調試,有時也會有代碼膨脹問題)。編譯期計算在編譯過程中的位置請見下圖(取自文獻\[10\]),可以看到關鍵是模板的機制在編譯具體代碼(模板實例)前執行:
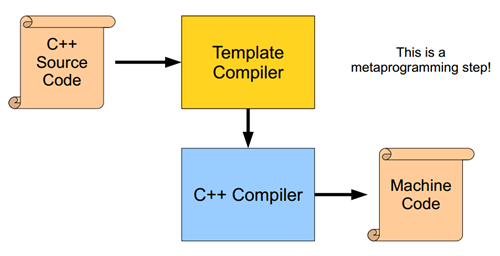
從編程范型(programming paradigm)上來說,C++ 模板是**函數式編程**(functional programming),它的主要特點是:函數調用不產生任何副作用(沒有可變的存儲),用遞歸形式實現循環結構的功能。C++ 模板的特例化提供了條件判斷能力,而模板遞歸嵌套提供了循環的能力,這兩點使得其具有和普通語言一樣通用的能力(圖靈完備性)。
從**編程形式**來看,模板的“<>”中的模板參數相當于函數調用的輸入參數,模板中的 typedef 或 static const 或 enum 定義函數返回值(類型或數值,數值僅支持整型,如果需要可以通過編碼計算浮點數),代碼計算是通過類型計算進而選擇類型的函數實現的(C++ 屬于靜態類型語言,編譯器對類型的操控能力很強)。代碼示意如下:
~~~
#include <iostream>
~~~
~~~
8
~~~
C++ 模板元編程**概覽框圖**如下(取自文獻\[9\]):

下面我們將對圖中的每個框進行深入討論。
**3**
**編譯器數值計算**
**第一個 C++ 模板元程序**是 Erwin Unruh 在 1994 年寫的(文獻\[14\]),這個程序計算小于給定數 N 的全部素數(又叫質數),程序并不運行(都不能通過編譯),而是讓編譯器在錯誤信息中顯示結果(直觀展現了是編譯期計算結果,C++ 模板元編程不是設計的功能,更像是在戲弄編譯器,當然 C++11 有所改變),由于年代久遠,原來的程序用現在的編譯器已經不能編譯了,下面的代碼在原來程序基礎上稍作了修改(GCC 4.8 下使用 -fpermissvie,只顯示警告信息):
~~~
// Prime number computation by Erwin Unruh
~~~
~~~
sh-4.2# g++ -std=c++11 -fpermissive -o main *.cpp
~~~
上面的編譯輸出信息只給出了前一部分,雖然信息很雜,但還是可以看到其中有 10?以內全部素數:2、3、5、7(已經加粗顯示關鍵行)。
到目前為止,雖然已經看到了階乘、求和等遞歸數值計算,但都沒涉及原理,下面以求和為例講解 C++?模板編譯期數值計算的原理:
~~~
#include <iostream>
~~~
~~~
15
~~~
當編譯器遇到 sumt 時,試圖實例化之,sumt 引用了 sumt 即 sumt,試圖實例化 sumt,以此類推,直到 sumt,sumt 匹配模板特例,sumt::ret 為 0,sumt::ret 為 sumt::ret+1 為 1,以此類推,sumt::ret 為 15。值得一提的是,雖然對用戶來說程序只是輸出了一個編譯期常量 sumt::ret,但在背后,編譯器其實至少處理了 sumt 到 sumt 共 6 個類型。
從這個例子我們也可以窺探 C++ 模板元編程的函數式編程范型,對比結構化求和程序:for(i=0,sum=0; i::ret,sumt::ret,...,sumt::ret 。函數式編程看上去似乎效率低下(因為它和數學接近,而不是和硬件工作方式接近),但有自己的優勢:描述問題更加簡潔清晰(前提是熟悉這種方式),沒有可變的變量就沒有數據依賴,方便進行并行化。
**4**
**模板下的控制結構**
模板實現的條件?**if**和**while 語句**如下(文獻\[9\]):
~~~
// 通例為空,若不匹配特例將報錯,很好的調試手段(這里是 bool 就無所謂了)
~~~
IF\_<> 的使用示例見下面:
~~~
const int len = 4;
~~~
~~~
4
~~~
WHILE\_<> 的使用示例見下面:
~~~
// 計算 1^e+2^e+...+n^e
~~~
~~~
385
~~~
為了展現編譯期數值計算的強大能力,下面是一個更復雜的計算:最大公約數(Greatest Common Divisor,GCD)和最小公倍數(Lowest Common Multiple,LCM),經典的輾轉相除算法:
~~~
// 最小公倍數,普通函數
~~~
~~~
900
~~~
上面例子中,定義一個類的整型常量,可以用 enum,也可以用 static const int,需要注意的是 enum 定義的常量的字節數不會超過 sizeof(int) (文獻\[2\])。
**5**
**循環展開**
文獻\[11\]展示了一個**循環展開**(loop unrolling)的例子 -- 冒泡排序:
~~~
#include <utility> // std::swap
~~~
對循環次數固定且比較小的循環語句,對其進行展開并內聯可以避免函數調用以及執行循環語句中的分支,從而可以提高性能,對上述代碼做如下測試,代碼在 VS2013 的 Release 下編譯運行:
~~~
#include <iostream>
~~~
~~~
2.38643 0.926521
~~~
上述結果表明,模板元編程實現的循環展開能夠達到和手動循環展開相近的性能(90% 以上),并且性能是循環版本的 2 倍多(如果扣除 memcpy 函數占據的部分加速比將更高,根據 Amdahl 定律)。這里可能有人會想,既然循環次數固定,為什么不直接手動循環展開呢,難道就為了使用模板嗎?當然不是,有時候循環次數確實是編譯期固定值,但對用戶并不是固定的,比如要實現數學上向量計算的類,因為可能是 2、3、4 維,所以寫成模板,把維度作為 int 型模板參數,這時因為不知道具體是幾維的也就不得不用循環,不過因為維度信息在模板實例化時是編譯期常量且較小,所以編譯器很可能在代碼優化時進行循環展開,但我們想讓這一切發生的更可控一些。
上面用三個函數模板 IntSwap()、 IntBubbleSort()、 IntBubbleSort<>() 嵌入其他模板內部,因為函數不允許嵌套,我們只能用類模板:
~~~
// 整合成一個類模板實現,看著好,但引入了 代碼膨脹
~~~
上面代碼看似很好,不僅整合了代碼,借助類成員的訪問控制,還隱藏了實現細節。不過它存在著很大問題,如果實例化 IntBubbleSortC、 IntBubbleSortC、 IntBubbleSortC,將實例化成員函數 IntBubbleSortC::IntSwap()、 IntBubbleSortC::IntSwap()、 IntBubbleSortC::IntSwap()、 IntBubbleSortC::IntSwap()、 IntBubbleSortC::IntSwap()、 IntBubbleSortC::IntSwap(),而在原來的看著分散的代碼中 IntSwap() 只有一個。這將導致**代碼膨脹**(code bloat),即生成的可執行文件體積變大(代碼膨脹另一含義是源代碼增大,見文獻\[1\]第11章)。不過這里使用了內聯(inline),如果編譯器確實內聯展開代碼則不會導致代碼膨脹(除了循環展開本身會帶來的代碼膨脹),但因為重復編譯原本可以復用的模板實例,會增加編譯時間。在上一節的例子中,因為只涉及編譯期常量計算,并不涉及函數(函數模板,或類模板的成員函數,函數被編譯成具體的機器二進制代碼),并不會出現代碼膨脹。
為了清晰證明上面的論述,我們去掉所有 inline 并將函數實現放到類外面(類里面實現的成員函數都是內聯的,因為函數實現可能被包含多次,見文獻\[2\] 10.2.9,不過現在的編譯器優化能力很強,很多時候加不加 inline 并不影響編譯器自己對內聯的選擇...),分別編譯分散版本和類模板封裝版本的冒泡排序代碼編譯生成的目標文件(VS2013 下是 .obj 文件)的大小,代碼均在 VS2013 Debug 模式下編譯(防止編譯器優化),比較 main.obj (源文件是 main.cpp)大小。
類模板封裝版本代碼如下,注意將成員函數在外面定義的寫法:
~~~
#include <iostream>
~~~
分散定義函數模板版本代碼如下,為了更具可比性,也將函數放在類里面作為成員函數:
~~~
#include <iostream>
~~~
程序中條件編譯都未打開時(#if 0),main.obj 大小分別為 264 KB 和 211 KB,條件編譯打開時(#if 1),main.obj 大小分別為 1073 KB 和 620 KB。可以看到,類模板封裝版的對象文件不但絕對大小更大,而且增長更快,這和之前分析是一致的。
**6**
**表達式模板,向量運算**
文獻\[12\]展示了一個**表達式模板**(Expression Templates)的例子:、
~~~
#include <iostream> // std::cout
~~~
~~~
-0 -0.707107 -1.1547 -1.5 -1.78885 -2.04124 -2.26779 -2.47487 -2.66667 -2.84605
~~~
代碼有點長(我已經盡量壓縮行數),請先看最下面的 main() 函數,表達式模板允許我們以 “-x / sqrt( 1.0 + x )” 這種類似數學表達式的方式傳參數,在 evaluate() 內部,將 0-10 的數依次賦給自變量 x 對表達式進行求值,這是通過在 template<> DExpr 類模板內部重載 operator() 實現的。我們來看看這一切是如何發生的。
在 main() 中調用 evaluate() 時,編譯器根據全局重載的加號、sqrt、除號、負號推斷“-x / sqrt( 1.0 + x )” 的類型是 Dexpr, DApNeg>>,Dexpr, Dexpr, DApAdd>>, DApSqrt>>, DApDiv>>(即將每個表達式編碼到一種類型,設這個類型為 ultimateExprType),并用此類型實例化函數模板 evaluate(),類型的推導見下圖。在 evaluate() 中,對表達式進行求值 expr(i),調用 ultimateExprType 的 operator(),這引起一系列的 operator() 和 Op::apply() 的調用,最終遇到基礎類型 “表達式類型” DExprLiteral 和 DExprIdentity,這個過程見下圖。總結就是,請看下圖,從下到上類型推斷,從上到下 operator() 表達式求值。
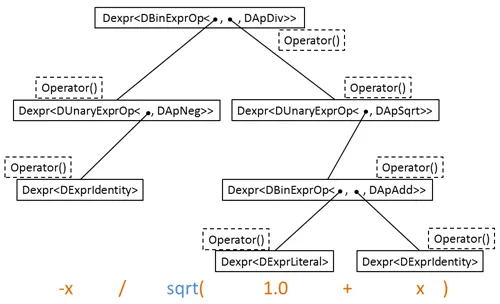
上面代碼函數實現寫在類的內部,即內聯,如果編譯器對內聯支持的好的話,上面代碼幾乎等價于如下代碼:
~~~
#include <iostream> // std::cout
~~~
~~~
-0 -0.707107 -1.1547 -1.5 -1.78885 -2.04124 -2.26779 -2.47487 -2.66667 -2.84605
~~~
和表達式模板類似的技術還可以用到向量計算中,以避免產生臨時向量變量,見文獻\[4\] Expression templates 和文獻\[12\]的后面。傳統向量計算如下:
~~~
class DoubleVec; // DoubleVec 重載了 + - * / 等向量元素之間的計算
~~~
模板代碼實現向量計算如下:
~~~
template<class A> DVExpr;
~~~
不過值得一提的是,傳統代碼可以用 C++11 的右值引用提升性能,C++11 新特性我們以后再詳細討論。
我們這里看下文獻\[4\] Expression templates 實現的版本,它用到了**編譯期多態**,編譯期多態示意代碼如下(關于這種代碼形式有個名字叫 curiously recurring template pattern, CRTP,見文獻\[4\]):
~~~
// 模板基類,定義接口,具體實現由模板參數,即子類實現
~~~
簡化后(向量長度固定為1000,元素類型為 double)的向量計算代碼如下:
~~~
#include <iostream> // std::cout
~~~
~~~
18
~~~
“alpha\*(u - v)” 的類型推斷過程如下圖所示,其中有子類到基類的隱式類型轉換:

這里可以看到基類的作用:提供統一的接口,讓 operator- 和 operator\* 可以寫成統一的模板形式。
**7**
**特性、策略、標簽**
利用迭代器,我們可以實現很多通用算法,迭代器在容器與算法之間搭建了一座橋梁。求和函數模板如下:
~~~
#include <iostream> // std::cout
~~~
~~~
4950
~~~
我們想讓 mysum() 對指針參數也能工作,畢竟迭代器就是模擬指針,但指針沒有嵌套類型 value\_type,可以定義 mysum() 對指針類型的特例,但更好的辦法是在函數參數和 value\_type 之間多加一層 --?特性(traits)(參考了文獻\[1\]第72頁,特性詳見文獻\[1\] 12.1):
~~~
// 特性,traits
~~~
~~~
10
~~~
其實,C++ 標準定義了類似的 traits:std::iterator\_trait(另一個經典例子是 std::numeric\_limits) 。特性對類型的信息(如 value\_type、 reference)進行包裝,使得上層代碼可以以統一的接口訪問這些信息。C++ 模板元編程會涉及大量的類型計算,很多時候要提取類型的信息(typedef、 常量值等),如果這些類型的信息的訪問方式不一致(如上面的迭代器和指針),我們將不得不定義特例,這會導致大量重復代碼的出現(另一種代碼膨脹),而通過加一層特性可以很好的解決這一問題。另外,特性不僅可以對類型的信息進行包裝,還可以提供更多信息,當然,因為加了一層,也帶來復雜性。特性是一種提供元信息的手段。
**策略**(policy)一般是一個類模板,典型的策略是 STL 容器(如 std::vector> class vector;)的分配器(這個參數有默認參數,即默認存儲策略),策略類將模板的經常變化的那一部分子功能塊集中起來作為模板參數,這樣模板便可以更為通用,這和特性的思想是類似的(詳見文獻\[1\] 12.3)。
**標簽**(tag)一般是一個空類,其作用是作為一個獨一無二的類型名字用于標記一些東西,典型的例子是 STL 迭代器的五種類型的名字(input\_iterator\_tag, output\_iterator\_tag, forward\_iterator\_tag, bidirectional\_iterator\_tag, random\_access\_iterator\_tag),std::vector::iterator::iterator\_category 就是 random\_access\_iterator\_tag,可以用第1節判斷類型是否等價的模板檢測這一點:
~~~
#include <iostream>
~~~
~~~
1
~~~
有了這樣的判斷,還可以根據判斷結果做更復雜的元編程邏輯(如一個算法以迭代器為參數,根據迭代器標簽進行特例化以對某種迭代器特殊處理)。標簽還可以用來分辨函數重載,第5節中就用到了這樣的標簽(recursion)(標簽詳見文獻\[1\] 12.1)。
**8**
**更多類型計算**
在第1節我們講類型等價的時候,已經見到了一個可以判斷兩個類型是否等價的模板,這一節我們給出更多例子,下面是判斷一個類型是否可以隱式轉換到另一個類型的模板(參考了文獻\[6\] Static interface checking):
~~~
#include <iostream> // std::cout
~~~
~~~
1
~~~
下面這個例子檢查某個類型是否含有某個嵌套類型定義(參考了文獻\[4\] Substitution failure is not an erro (SFINAE)),這個例子是個內省(反射的一種):
~~~
#include <iostream>
~~~
~~~
1
~~~
這個例子是有缺陷的,因為不存在引用的指針,所以不用用來檢測引用類型定義。可以看到,因為只涉及類型推斷,都是編譯期的計算,不涉及任何可執行代碼,所以類的成員函數根本不需要具體實現。
**9**
**元容器**
文獻\[1\]第 13 章講了元容器,所謂元容器,就是類似于 std::vector<> 那樣的容器,不過它存儲的是元數據 -- 類型,有了元容器,我們就可以判斷某個類型是否屬于某個元容器之類的操作。
在講元容器之前,我們先來看看**偽變長參數模板**(文獻\[1\] 12.4),一個可以存儲小于某個數(例子中為 4 個)的任意個數,任意類型數據的元組(tuple)的例子如下(參考了文獻\[1\] 第 225~227 頁):
~~~
#include <iostream>
~~~
~~~
10 m 1.2
~~~
C++11 引入了變長模板參數,其背后的原理也是模板遞歸(文獻\[1\]第 230 頁)。
利用和上面例子類似的模板參數移位遞歸的原理,我們可以構造一個存儲“類型”的元組,即**元容器**,其代碼如下(和文獻\[1\]第 237 頁的例子不同):
~~~
#include <iostream>
~~~
~~~
3
~~~
上面例子已經實現了存儲類型的元容器,和元容器上的查找算法,但還有一個小問題,就是它不能處理模板,編譯器對模板的操縱能力遠不如對類型的操縱能力強(提示:類模板實例是類型),我們可以一種間接方式實現存儲“模板元素”,即用模板的一個代表實例(如全用 int 為參數的實例)來代表這個模板,這樣對任意模板實例,只需判斷其模板的代表實例是否在容器中即可,這需要進行**類型過濾**:對任意模板的實例將其替換為指定模板參數的代表實例,類型過濾實例代碼如下(參考了文獻\[1\]第 241 頁):
~~~
// 類型過濾,meta_filter 使用時只用一個參數,設置四個模板參數是因為,模板通例的參數列表
~~~
現在,只需將上面元容器和元容器查找函數修改為:對模板實例將其換為代表實例,即修改 meta\_container::ret\_type type;”,修改 find::ret\_type”。修改后,下面代碼的執行結果是:
~~~
template<typename, typename> class my_tmp_2;
~~~
~~~
2
~~~
**10**
**總結**
博文比較長,總結一下所涉及的東西:
* C++ 模板包括函數模板和類模板,模板參數形式有:類型、模板型、非類型(整型、指針);
* 模板的特例化分完全特例化和部分特例化,實例將匹配參數集合最小的特例;
* 用實例參數替換模板形式參數稱為實例化,實例化的結果是產生具體類型(類模板)或函數(函數模板),同一模板實參完全等價將產生等價的實例類型或函數;
* 模板一般在頭文件中定義,可能被包含多次,編譯和鏈接時會消除等價模板實例;
* template、typename、this 關鍵字用來消除歧義,避免編譯錯誤或產生不符預期的結果;
* C++11 對模板引入了新特性:“>>”、函數模板也可以有默認參數、變長模板參數、外部模板實例(extern),并棄用 export template;
* C++ 模板是圖靈完備的,模板編程是函數編程風格,特點是:沒有可變的存儲、遞歸,以“<>”為輸入,typedef 或靜態常量為輸出;
* 編譯期數值計算雖然實際意義不大,但可以很好證明 C++ 模板的能力,可以用模板實現類似普通程序中的 if 和 while 語句;
* 一個實際應用是循環展開,雖然編譯器可以自動循環展開,但我們可以讓這一切更可控;
* C++ 模板編程的兩個問題是:難調試,會產生冗長且難以閱讀的編譯錯誤信息、代碼膨脹(源代碼膨脹、二進制對象文件膨脹),改進的方法是:增加一些檢查代碼,讓編譯器及時報錯,使用特性、策略等讓模板更通用,可能的話合并一些模板實例(如將代碼提出去做成單獨模板);
* 表達式模板和向量計算是另一個可加速程序的例子,它們將計算表達式編碼到類型,這是通過模板嵌套參數實現的;
* 特性,策略,標簽是模板編程常用技巧,它們可以是模板變得更加通用;
* 模板甚至可以獲得類型的內部信息(是否有某個 typedef),這是反射中的內省,C++ 在語言層面對反射支持很少(typeid),這不利于模板元編程;
* 可以用遞歸實現偽變長參數模板,C++11 變長參數模板背后的原理也是模板遞歸;
* 元容器存儲元信息(如類型)、類型過濾過濾某些類型,它們是元編程的高級特性。
- C++基礎
- 什么是 POD 數據類型?
- 面向對象三大特性五大原則
- 低耦合高內聚
- C++類型轉換
- c++仿函數
- C++仿函數了解一下?
- C++對象內存模型
- C++11新特性
- 智能指針
- 動手實現C++的智能指針
- C++ 智能指針 shared_ptr 詳解與示例
- 現代 C++:一文讀懂智能指針
- Lamda
- c++11多線程
- std::thread
- std::async
- std::promise
- std::future
- C++11 的內存模型
- 初始化列表
- std::bind
- std::tuple
- auto自動類型推導
- 可變參數模板
- 右值引用與移動語義
- 完美轉發
- 基于范圍的for循環
- C++11之POD類型
- std::enable_if
- C++14/17
- C++20
- 協成
- 模塊
- Ranges
- Boost
- boost::circular_buffer
- 使用Boost.Asio編寫通信程序
- Boost.Asio C++ 網絡編程
- 模板
- 模板特化/偏特化
- C++模板、類模板、函數模板詳解都在這里了
- 泛化之美--C++11可變模版參數的妙用
- 模板元編程
- 這是我見過最好的模板元編程文章!