## **HTTP/1.1詳解:**
HTTP/1.1是HTTP協議的第三個版本,是目前主流的HTTP協議版本
HTTP 1.1引入了許多關鍵性能優化:***keepalive連接***,***請求流水線***,***chunked編碼傳輸***,**字節范圍請求**等
* 1、Persistent Connection(keepalive連接)
允許HTTP設備在事務處理結束之后將TCP連接保持在打開的狀態,以便未來的HTTP請求重用現在的連接,直到客戶端或服務器端決定將其關閉為止。
HTTP1.1對比HTTP1.0?在HTTP1.0中使用長連接需要添加請求頭 Connection: Keep-Alive,而在HTTP 1.1 所有的連接默認都是長連接,除非特殊聲明不支持( HTTP請求報文首部加上Connection: close )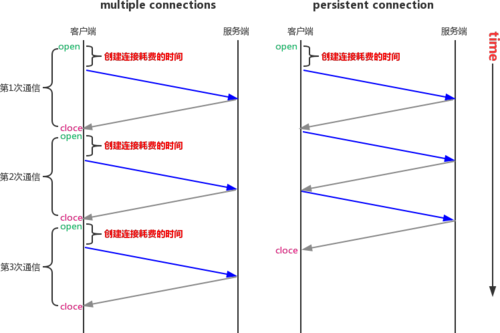
* 2、Pipelining(請求流水線)
支持持久連接的客戶端可以“流水線”它的請求(即,發送多個請求而無需等待每個響應)。服務器必須按照與收到請求的相同順序來向這些請求發送響應。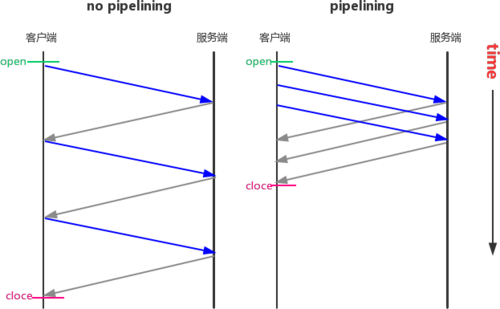客戶端發送請求之后,不需要等收到返回結果,可以直接在發送第二次請求,但是先發送的請求肯定是先收到返回結果,就像生產流水線一樣,不可能只生產一樣東西,那么這個工廠不得廢了???
* 3、chunked編碼傳輸
*****
#1、介紹該編碼將實體分塊傳送并逐塊標明長度,直到長度為0塊表示傳輸結束, 這在實體長度未知時特別有用(比如由數據庫動態產生的數據)
#2、傳輸編碼和分塊編碼當響應頭里包含Transfer-Encoding: chunked,代表分塊編碼,會把「報文」分割成若干個大小已知的塊,塊之間是緊挨著發送的,這樣就不需要在發送之前知道整個報文的大小了,也意味著不需要寫回Content-Length首部了。
#3、分塊傳輸的應用當使用持久連接時,在服務器發送主體內容之前,必須計算出主體內容的大小,然后放到響應頭里(Content-Length:主體的字節數)發送給客戶端。 如果服務器動態創建內容,可能在發送之前無法知道主體大小,分塊編碼就是為了解決這種情況:服務器把主體逐塊發送,說明每一塊的大小。服務器再用大小為0的塊作為結束塊。,為下一個響應做準備,此時響應頭里便不再需要Content-Length了 除非使用了分塊編碼Transfer-Encoding: chunked,否則響應頭首部必須使用Content-Length首部。
#4、關于Content-Length首部:如果請求頭包含Accept-Encoding': 'gzip',則服務端會將內容壓縮后返回,內容的Content-Length長度是壓縮后的長度,如果請求頭不包含Accept-Encoding': 'gzip',服務器就不會采取gzip壓縮,同時我司服務器設定也不進行分塊編碼。所以返回響應頭的Content-Length首部是必須的,但是這個值的大小肯定是沒有進行過壓縮的文件大小。
*****
* 4、字節范圍請求
HTTP1.1支持傳送內容的一部分。比方說,當客戶端已經有內容的一部分,為了節省帶寬,可以只向服務器請求一部分。該功能通過在請求消息中引入了range頭域來實現,它允許只請求資源的某個部分。在響應消息中Content-Range頭域聲明了返回的這部分對象的偏移值和長度。如果服務器相應地返回了對象所請求范圍的內容,則響應碼206(Partial Content)
