
[toc]
## ConcurrentHashMap的實現原理是什么?
### JDK7
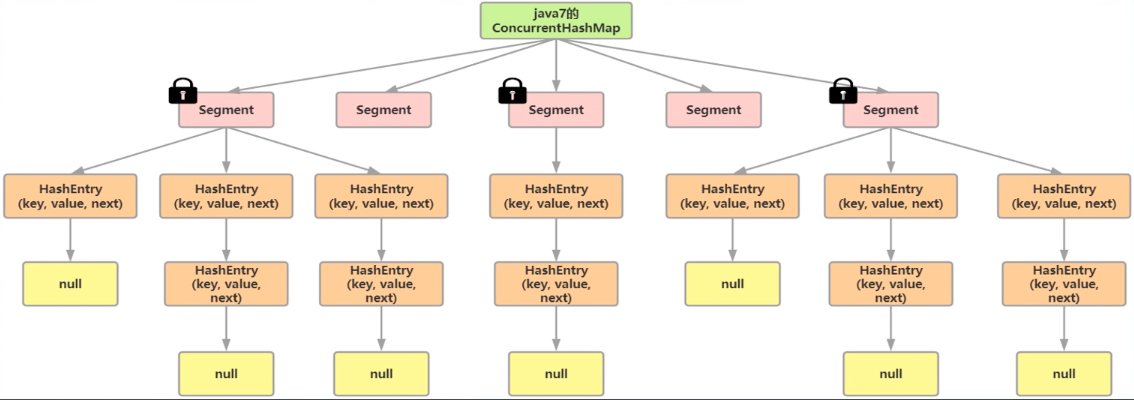
1. 結構上,JDK7中的ConcurrentHashMap由`Segment`和`HashEntry`組成,即ConcurrentHashMap把哈希桶數組切分成小數組(Segment) ,每個小數組有n個HashEntry組成。
2. 鎖實現上,將數據分為一段一段的存儲,然后給每一段數據配一把鎖,當一個線程占用鎖訪問其中一段數據時,其他段的數據也能被其他線程訪問,實現并發訪問。
#### Segment源碼解讀

Segment是ConcurrentHashMap的一個內部類主要的組成,繼承自`ReentrantLock`。volatile修飾`HashEntry<K, V>[] table`可以保證在數組擴容時的可見性。
#### HashEntry<K,V>源碼
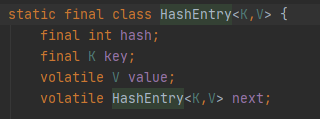
volatile修飾HashEntry的數據value和下一個節點next, 保證了多線程環境下數據獲取時的可見性!
### JDK8
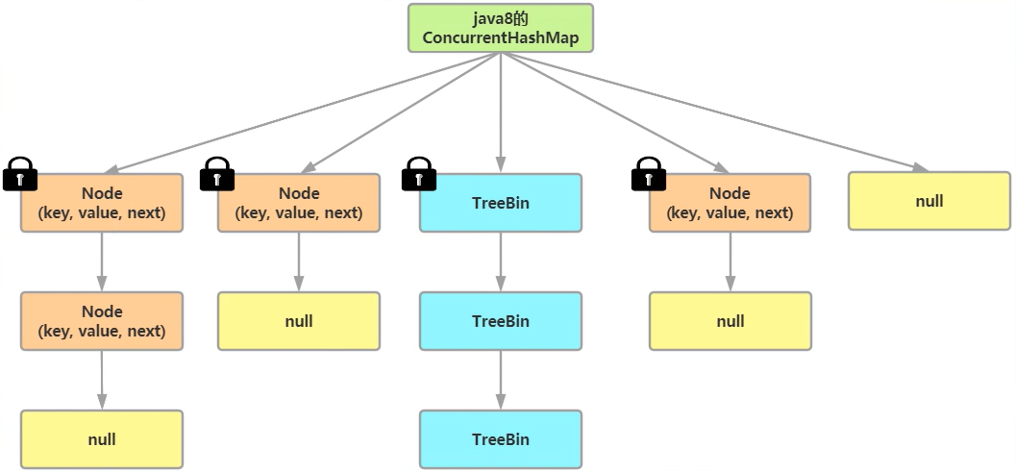
1. 結構上,JDK8中的ConcurrentHashMap選擇了與HashMap相同的Node數組+鏈表+紅黑樹結構;
2. 在鎖的實現上,拋棄了原有的Segment分段鎖,采用`CAS` + `synchronized`實現更加細粒度的鎖。將鎖的級別控制在了更細粒度的哈希桶數組元素級別,只需要鎖住這個鏈表頭節點(紅黑樹的根節點),就不會影響其他的哈希桶數組元素的讀寫,大大提高了并發度。
#### Node<K,V>

### JDK7和JDK8中ConcurrentHashMap的區別是什么?
- 底層**數據結構**: JDK7底層數據結構是使用Segment組織的數組+鏈表,JDK8中取而代之的是數組+鏈表+紅黑樹的結構,在鏈表節點數量大于8 (且數據總量大于等于64)時,會將鏈表轉化為紅黑樹進行存儲。
- 查詢**時間復雜度**:從JDK7的遍歷鏈表0(n),JDK8 變成遍歷紅黑樹0(logN)。
- 保證**線程安全機制**: JDK7 采用Segment的分段鎖機制實現線程安全,其中Segment繼承自ReentrantLock。
JDK8采用CAS+synchronized保證線程安全。
- **鎖的粒度**: JDK7 是對需要進行數據操作的Segment加鎖,JDK8 調整為對每個數組元素的頭節點加鎖。
## 基本特點
### ConcurrentHashMap的get方法需要加鎖嗎?為什么?
get過程不需要加鎖,除非讀到值是空值的時候才需要加鎖重讀。JDK8中,因為Node和HashEntry的**元素value**和**指針next**是用`volatile`修飾的,在多線程環境下線程A修改節點的value或者新增節點的時候是對線程B可見的。
> jdk7,get方法將要使用的共享變量都定義成volatile類型,如用于統計當前Segement大小的count字段和用于存儲值的HashEntry的value。
#### 復習一下volatile的內存語義:
定義成volatile的變量,能夠在線程之間保持可見性,能夠被多線程同時讀,并且保證不會讀到過期的值,但是只能被單線程寫(有一種情況可以被多線程寫,就是寫入的值不依賴于原值),在get操作里只需要讀不需要寫共享變量count和value,所以可以不用加鎖。之所以不會讀到過期的值,是因為根據Java內存模型的`happen before原則`,對volatile字段的**寫入操作先于讀操作**,即使兩個線程同時修改和獲取volatile變量,get操作也能拿到最新的值,這是用**volatile替換鎖的經典應用場景**。
### ConcurrentHashMap不支持key或value為null的原因是什么?
因為ConcorrentHashMap工作于多線程環境,如果ConcurrentHashMap.get(key)返回null, 就無法判斷值是null,還是沒有該key;而單線程的HashMap卻可以用containsKey(key)判斷是否包含了這個key。
```
/**
* Created by Mr.zihan on 2021/12/23.
* connect to cowboy2014@qq.com
*/
public class ConcurrentHashMapTest {
public static void main(String[] args) {
ConcurrentHashMap<String, Object> map = new ConcurrentHashMap<>();
// map.put(null, "hello"); //java.lang.NullPointerException
map.put("hello", "world");
map.put("world", null); //java.lang.NullPointerException
// System.out.println(map.contains(null));//java.lang.NullPointerException
System.out.println(map.containsKey("hello"));
System.out.println(map.contains("world"));
}
}
```
特點:key和value均不能為空;
### ConcurrentHashMap迭代器是強一致性還是弱一 致性?
與HashMap迭代器是強一致性不同, ConcurrentHashMap 迭代器是弱一致性。
ConcurrentHashMap的**迭代器**創建后,就會按照哈希表結構遍歷每個元素,但在遍歷過程中,內部元素可能會發生變化,如果變化發生在已遍歷過的部分,迭代器就不會反映出來,而如果變化發生在未遍歷過的部分,迭代器就會發現并反映出來,這就是**弱一致性**。
這樣迭代器線程可以使用原來老的數據,而寫線程也可以并發的完成改變,保證了多個線程并發執行的連續性和擴展性,是性能提升的關鍵。
### JDK8中為什么使用synchronized替換Reentrantlock?
1. synchronized性能提升,在JDK6中對synchronized鎖的實現引入了大量的優化,會從無鎖->偏向鎖-> 輕量級鎖
->重量級鎖一步步轉換就是鎖膨脹的優化。以及有鎖的粗化鎖消除自適應自旋等優化。
2. 提升并發度和減少內存開銷,CAS + synchronized方式時加鎖的對象是每個鏈條的頭結點,相對Segment再次提
高了并發度。如果使用可重入鎖達到同樣的效果,則需要大量繼承自ReentrantLock的對象,造成巨大內存浪費。
### ConcurrentHashMap的并發度是怎么設計的?
**并發度概念**:可以理解為程序運行時能夠同時更新ConccurentHashMap且不產生鎖競爭的最大線程數。
1. 在JDK7中,實際上就是ConcurrentHashMap中的分段鎖個數,即Segment[]的數組長度, 默認是16, 這個值可以
在構造函數中設置。
2. 如果自己設置了并發度,ConcurrentHashMap 會使用大于等于該值的最小的2的冪指數作為實際并發度。如果并
發度設置的過小,會帶來嚴重的鎖競爭問題;如果并發度設置的過大,原本位于同一個Segment內的訪問會擴散
到不同的Segment中,從而引起程序性能下降。
3. 在JDK8中,已經摒棄了Segment的概念,選擇了Node數組+鏈表+紅黑樹結構,并發度大小依賴于數組的大小。
### ConcurrentHashMap和Hashtable的效率哪個更高?為什么?
ConcurrentHashMap的效率要高于Hashtable。
1. 因為Hashtable給整個哈希表加鎖從而實現線程安全。
2. 而ConcurrentHashMap的鎖粒度更低:
在JDK7中采用Segment鎖(分段鎖)實現線程安全
在JDK8中采用CAS+synchronized實現線程安全。
### 多線程下安全的操作Map還有其它方法嗎?
可以使用Collections.synchronizedMap(Map類型的對象)方法進行加同步鎖。把對象轉換成SynchronizedMap<K, V>類型。
如果傳入的是HashMap對象,其實也是對HashMap做的方法做了一層包裝,里面使用**對象鎖**(mutex)來保證多線程場景下,線程安全,本質也是對HashMap進行全表鎖。在競爭激烈的多線程環境下性能依然也非常差,不推薦使用!
`java.util.Collections.SynchronizedMap`:
```
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
}
```
- 前言
- 第一部分 計算機網絡與操作系統
- 大量的 TIME_WAIT 狀態 TCP 連接,對業務有什么影響?怎么處理?
- 性能占用
- 第二部分 Java基礎
- 2-1 JVM
- JVM整體結構
- 方法區
- JVM的生命周期
- 堆對象結構
- 垃圾回收
- 調優案例
- 類加載機制
- 執行引擎
- 類文件結構
- 2-2 多線程
- 線程狀態
- 鎖與阻塞
- 悲觀鎖與樂觀鎖
- 阻塞隊列
- ConcurrentHashMap
- 線程池
- 線程框架
- 徹底搞懂AQS
- 2-3 Spring框架基礎
- Spring注解
- Spring IoC 和 AOP 的理解
- Spring工作原理
- 2-4 集合框架
- 死磕HashMap
- 第三部分 高級編程
- Socket與NIO
- 緩沖區
- Bybuffer
- BIO、NIO、AIO
- Netty的工作原理
- Netty高性能原因
- Rabbitmq
- mq消息可靠性是怎么保障的?
- 認證授權
- 第四部分 數據存儲
- 第1章 mysql篇
- MySQL主從一致性
- Mysql的數據組織方式
- Mysql性能優化
- 數據庫中的樂觀鎖與悲觀鎖
- 深度分頁
- 從一條SQL語句看Mysql的工作流程
- 第2章 Redis
- Redis緩存
- redis key過期策略
- 數據持久化
- 基于Redis分布式鎖的實現
- Redis高可用
- 第3章 Elasticsearch
- 全文查詢為什么快
- battle with mysql
- 第五部分 數據結構與算法
- 常見算法題
- 基于數組實現的一個隊列
- 第六部分 真實面試案例
- 初級開發面試材料
- 答案部分
- 現場編碼
- 第七部分 面試官角度
- 第八部分 計算機基礎
- 第九部分 微服務
- OpenFeign工作原理