
[toc]
## ???每日一句
> **最美好的生活方式是和一群志同道合的人,一起奔跑在理想的路上,回頭有一路的故事,低頭有堅定的腳步,抬頭有清晰的遠方!**
* * *
## ??? Sentinel存在的意義
### ??? Sentinel出現的前提背景
> 在前面[Redis技術系列](https://my.oschina.net/liboware?tab=newest&catalogId=7253332 "Redis技術系列")的章節中,我們介紹了相關[Redis持久化機制](https://my.oschina.net/liboware/blog/5038117 "Redis持久化機制")和[Redis主從架構](https://my.oschina.net/liboware/blog/5048445 "Redis主從架構")的探究。兩者的相輔相成實現了Redis的數據高可用性以及**服務的可擴展性和負載性**,但是只依靠持久化方案和主從復制能力(**負載和數據的榮譽**),在出現服務宕機的時候,**故障切換無法自動去實現**,還需要手工,這對人工成本造成了巨大的損失以及不穩定性。
### ??? 持久化+主從復制后的仍存在的痛點
> 當**主服務器下線后無法恢復服務使用主從復制**,在master節點下線后,只能夠手動將 slave 節點切換為 master,但是不能自動完成故障轉移。
### ??? Sentinel的加入才夠完整
> Sentinel(哨兵)是Redis的高可用性解決方案:**由一個或多個Sentinel實例組成的Sentinel系統可以監視任意多個主服務器**,以及這些主服務器屬下的所有從服務器,并在被監視的主服務器進入下線狀態時,**自動將下線主服務器屬下的某個從服務器升級為新的主服務器**。
**主從持久化機制與加入哨兵之后的對比:**
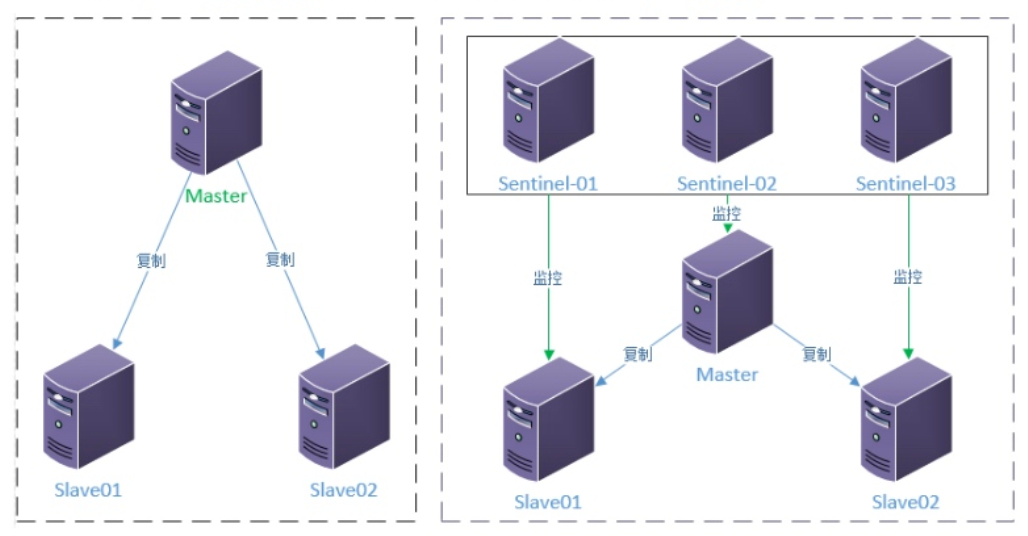
* * *
## ???Sentinel的主要功能
> **Redis Sentinel為Redis提供了完整的高可用解決方案。實際上這意味著使用Sentinel可以部署一套Redis,在沒有人為干預的情況下去應付各種各樣的失敗事件。同時提供了一些其他的功能,例如:監控、通知、并為client提供配置**。
### ???Sentinel的概念定義
> **Redis-Sentinel是Redis官方推薦的高可用性(HA)解決方案**,當用Redis做Master-slave的高可用方案時,假如master宕機了,**Redis本身(包括它的很多客戶端)都沒有實現自動進行主備切換,而Redis-sentinel本身也是一個獨立運行的進程,它能監控多個master-slave集群**,發現master宕機后能進行自動切換。
> **Redis從 2.8發布了一個穩定版本的Redis Sentinel 。當前版本的 Sentinel稱為Sentinel 2。它是使用更強大和更簡單的預測算法來重寫初始Sentinel實現。(Redis2.6版本提供Sentinel 1版本,但是有 一些問題)。**
* * *
### ???Sentinel的功能分布
* **監控(Monitoring)**:**Sentinel會不斷的檢查你的主節點和從節點是否正常工作**。
* **通知(Notification):被監控的Redis實例如果出現問題,Sentinel可以通過API(pub)通知系統管理員或者其他程序。**
* **自動故障轉移(Automatic failover):如果一個主節點沒有按照預期工作,Sentinel 會開始進行故障轉移,把一個從節點提升為主節點,并重新配置其他的從節點使用新的主節點,其他的從節點會開始復制新的主節點,并且使用Redis服務的應用程序在連接的時候也被通知新的地址。**
* **配置提供(Configuration provider):客戶端可以把 Sentinel 作為權威的配置發布者來獲得最新的maste 地址。如果發生了故障轉移,Sentinel集群會通知客戶端新的master地址,并刷新 Redis 的配置。**(sentinel會返回最新的master地址)
### ???Sentinel的分布特性

* **如果只使用單個sentinel進程來監控redis集群是不可靠的**,當sentinel進程宕掉后(sentinel本身也有單點問題,single-point-of-failure)整個集群系統將**無法按照預期的方式運行**。所以有必要將sentinel集群。
* **Redis Sentinel是一個分布式系統,Sentinel運行在有許多Sentinel進程互相合作的環境下,它本身就是這樣被設計的**。有許多Sentinel進程互相合作的優點如下:
1. **當多個Sentinel同意一個master不再可用的時候,就執行故障檢測。這明顯降低了錯誤概率**。
2. **即使并非全部的Sentinel都在工作,Sentinel也可以正常工作,這種特性,讓系統非常的健康(最好是奇數個,因為不容易選舉成為同票)**。
**分布方式總體深入下圖所示**:

## ???Sentinel的基本原理
> 總體而言:多個 Sentinel 進程(progress), 這些進程使用**流言協議(gossip protocols)來**接收關于主服務器是否下線的信息, 并使用投票協議(agreement protocols)來決定是否執行自動故障遷移, 以及選擇哪個從服務器作為新的主服務器。
### ???Sentinel的主觀下線(SDOWN)
一個服務器必須在 master-down-after-milliseconds 毫秒內, 一直返回無效回復才會被 Sentinel 標記為主觀下線。
* **在Sentinel哨兵的運行階段,(其會向其他的Sentinel哨兵、master和slave發送消息確認其是否存活),如果在指定的時間內未收到正常回應,暫時認為對方掛起了(被標記為主觀宕機–SDOWN)**。
* 【**注意:當只有單個sentinel實例對redis實例做出無響應的判斷,此時進入主觀判斷,不會觸發自動故障轉移等操作。**】
* 【**注意:一個服務器必須在 master-down-after-milliseconds 毫秒內, 一直返回無效回復才會被 Sentinel 標記為主觀下線**】
### ???Sentinel的客觀下線(ODOWN)
* **當多個Sentinel哨兵(數量由quorum參數設定)都報告同一個master沒有響應了,通過投票算法(Raft算法),系統判斷其已死亡(被標記為客觀宕機–ODOWN)**。
* **多個 Sentinel 實例在對同一個服務器做出 SDOWN 判斷, 并且通過 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服務器下線判斷**。
* **Sentinel可以通過向另一個 Sentinel 發送 SENTINEL is-master-down-by-addr 命令來詢問對方是否認為給定的服務器已下線**。
### ???Sentinel下線操作
* 從主觀下線狀態切換到客觀下線狀態并沒有使用嚴格的法定人數算法(strong quorum algorithm), 而是使用了流言協議:**如果 Sentinel 在給定的時間范圍內(master\_down\_after\_milliseconds), 從其他 Sentinel 那里接收到了足夠數量的主服務器下線報告**, 那么 Sentinel**就會將主服務器的狀態從主觀下線改變為客觀下線**。**如果之后其他 Sentinel 不再報告主服務器已下線, 那么客觀下線狀態就會被移除。**
* **客觀下線條件只適用于主服務器: 對于任何其他類型的 Redis 實例(其他sentinel和slave服務節點)**, Sentinel 在將它們判斷為下線前不需要進行協商,**所以從服務器Slave或者其他 Sentinel 永遠不會達到客觀下線條件**。
### ???Sentinel的主從切換
* **此時Sentinel集群會選取領頭的哨兵(leader)進行故障恢復,從現有slave節點中選出(算法后續有介紹)一個提升為Master,并把剩余Slave都指向新的Master,繼續維護主從關系**。
### ???Sentinel自動發現機制
* 那么,Sentinel集群的機器是如何發現集群中的其他機器呢?
* **使用廣播?很顯然不合適,既然是redis的產品,自然要充分運用redis功能,Sentinel集群節點利用了Redis master的發布/訂閱機制去自動發現其它節點**。
每個Sentinel使用發布/訂閱的方式**持續地傳播master的配置版本信息**,配置傳播的**發布/訂閱管道是: sentinel:hello,我們可以通過訂閱其頻道查看頻道中的消息**,如下:

#### ??? Sentinel 利用 pub/sub(發布/訂閱):
> 訂閱了每個 master 和 slave 數據節點的**sentinel**:hello 頻道,去自動發現其它也監控了統一 master 的 sentinel 節點,Sentinel 向每 1s 向**sentinel**:hello 中發送一條消息,包含了其當前維護的最新的master 配置。

* **如果某個sentinel發現自己的配置版本低于接收到的配置版本,則會用新的配置更新自己的 master 配置與發現的 Sentinel 之間相互建立命令連接**,**之后會通過這個命令連接來交換對于 master 數據節點的看法**。
* **sentinel**的狀態會被持久化地寫入**sentinel**的配置文件中。每次當收到一個新的配置時,或者新創建一個配置時,**配置會被持久化到硬盤中,并帶上配置的版本戳**。這意味著,可以安全的停止和重啟sentinel進程。
### ???Sentinel的發現方式
> 原理中提及到了,當sentinel發現主庫客觀下線時候會進行**領頭哨兵選舉**(**超過半數切大于閾值**)進行故障恢復,**其選舉算法采用Raft算法**,這也為什么說其設計思想類似與zookpeer,選舉過程大體如下:
* **發現主庫客觀下線的哨兵節點(這里稱為A)向每個哨兵節點發送命令要求對方選舉自己為領頭哨兵(leader)**;
* **如果目標哨兵沒有選舉過其他人,則同意將A選舉為領頭哨兵**;
* **如果A發現有超過半數且超過quorum參數值的哨兵節點同意選自己成為領頭哨兵,則A哨兵成功選舉為領頭哨兵**。
* 【**sentinel集群執行故障轉移時需要選舉leader,此時涉及到majority,majority 代表 sentinel 集群中大部分 sentinel 節點的個數,只有大于等于 max(quorum, majority) 個節點給某個 sentinel 節點投票,才能確定該sentinel節點為leader,majority 的計算方式為:num(sentinels) / 2 + 1**】
* **當有多個哨兵節點同時參與領頭哨兵選舉時,出現沒有任何節點當選可能,此時每個參選節點等待一個隨機時間進行下一輪選舉,直到選出領頭哨兵**。
### ???故障恢復時從Slave中間選出Master的算法
* **按照slave優先級進行排序**,**slave-priority越低,優先級就越高**;
* **如果slave priority相同,那么比較復制偏移量,offset越靠后(越大)則表明和舊的主庫數據同步越接近,優先級就越高**;
* **如果上面兩個條件都相同,那么選擇一個run id最小的從庫**;
> 主要根據slave-priority進行排序做控制選舉,先比較slave\_offset值越大優先級越高,如果相等在獲取runid最小的(代表啟動時間越早)。
## ???Sentinel(哨兵)的運作流程
1. **每個Sentinel以每秒鐘一次的頻率向它所知的Master,Slave以及其他 Sentinel 實例發送一個 PING 命令**。(**心跳機制**)
2. **如果一個實例(instance)距離最后一次有效回復 PING 命令的時間超過 down-after-milliseconds 選項所指定的值, 則這個實例會被 Sentinel 標記為主觀下線**。
3. **如果一個Master被標記為主觀下線,則正在監視這個Master的所有 Sentinel 要以每秒一次的頻率確認Master的確進入了主觀下線狀態**。(**確認投票下線**)
4. **當有足夠數量的 Sentinel(大于等于配置文件指定的值)在指定的時間范圍內確認Master的確進入了主觀下線狀態, 則Master會被標記為客觀下線**。
5. **在一般情況下, 每個 Sentinel 會以每 10 秒一次的頻率向它已知的所有Master,Slave發送 INFO 命令**。(同步數據)
6. **當Master被 Sentinel 標記為客觀下線時,Sentinel 向下線的 Master 的所有 Slave 發送 INFO 命令的頻率會從 10 秒一次改為每秒一次**。
7. **若沒有足夠數量的 Sentinel 同意 Master 已經下線, Master 的客觀下線狀態就會被移除**。
8. **若 Master 重新向 Sentinel 的 PING 命令返回有效回復, Master 的主觀下線狀態就會被移除**。
* * *
## ???Sentinel部署配置
* **redis源碼中提供了 sentinel 配置的模板:sentinel.conf**
* **Sentinel部署很簡單,只需要配置一下/etc/redis-sentinel.conf配置文件就可以了,如下**
~~~
#工作端口
port 26379
#工作目錄
dir "/var/lib/redis/sentinel"
#sentinel id ,建議注釋掉,會自動生成
#sentinel myid 827f0104ad153f34db5a29b8cbb51ef21a31d6d5
#配置要監控的master名字和地址,最后一個2代表當sentinel集群中有2個sentinel認為master故障時候才判定master真正不可用。
官方把該參數稱為quorum,在后續選舉領頭哨兵時候會用到
sentinel monitor mymaster 10.130.2.155 6379 2
#配置master密碼:配置主服務器的密碼(如沒設置密碼,可以省略)
sentinel auth-pass mymaster Password
#日志
logfile "/var/log/redis/sentinel.log"
配置完成后,使用systemctl start redis-sentinel啟動即可。
Sentinel可以調整的相關參數
#主觀SDOWN時間,單位毫秒,默認30秒。(心跳檢測)
sentinel down-after-milliseconds mymaster 30000
#在發生failover主備切換時候,最多允許多少個slave同時同步新的master。這個數字越小,完成failover所需的時間就越長,但是如果這個數字越大,就意味著越多的slave因為replication而不可用。可以通過將這個值設為 1 來保證每次只有一個slave處于不能處理命令請求的狀態。
sentinel parallel-syncs mymaster 1
#failover-time超時時間,當failover開始后,在此時間內仍然沒有觸發任何failover操作,當前sentinel將會認為此次failover失敗,單位毫秒。默認3分鐘。
sentinel failover-timeout mymaster 180000
~~~
### ???核心配置
~~~
sentinel monitor <master-name> <ip> <redis-port> <quorum>: 監控的 redis 主節點
#配置主服務器的密碼(如沒設置密碼,可以省略)
sentinel auth-pass mymaster 123456
#修改心跳檢測 5000毫秒
sentinel down-after-milliseconds mymaster 5000
~~~
* **sentinel 是 redis 配置的提供者,而不是代理,客戶端只是從 sentinel 獲取數據節點的配置,因此這里的 ip 必須是 redis 客戶端能夠訪問的。**
### ???Sentinel 啟動
雖然哨兵(sentinel) 釋出為一個單獨的可執行文件 redis-sentinel ,但實際上它只是一個運行在特殊模式下的 Redis 服務器,**你可以在啟動一個普通 Redis 服務器時通過給定 --sentinel 選項來啟動哨兵(sentinel)。**
如果你使用redis-sentinel可執行文件,你可以使用下面的命令來運行Sentinel:
> $ redis-sentinel /path/to/sentinel.conf
當然也可以采用 redis服務的方式啟動:
> $ redis-server sentinel.conf --sentinel &
兩種方式是一樣的。
不管咋樣,使用一個配置文件來運行Sentinel是必須的,這個文件被系統使用來存儲當前狀態,如果重啟,這些狀態會被重新載入。如果沒有配置文件或者配置文件的路徑不對,Sentinel將會拒絕啟動。
默認情況下,Sentinels監聽TCP端口26379,所以為了讓Sentinels運行,你的機器的26379端口必須是打開的,用來接收其他Sentinel實例的連接,否則,Sentinels不能互相交流,也不知道該干什么,也不會執行故障轉移。
~~~
1. 初始化一個普通的redis服務器
2. 加載Sentinel專用配置,例如命令表、參數等,Sentinel 使用 sentinel.c 中的命令表、函數等配置,普通 Redis 則使用 redis.c 中的配置
3. 除了保存服務器一般狀態之外,Sentinel 還會保存 Sentinel 相關狀態
~~~
##### 注意:
1 .當啟動哨兵模式之后,如果你的master服務器宕機之后,哨兵自動會在從redis服務器里面 投票選舉一個master主服務器出來;這個主服務器也可以進行讀寫操作!
2. 如果之前宕機的主服務器已經修好,可以正式運行了。那么這個服務器只能進行讀的操作,會自動跟隨由哨兵選舉出來的新服務器!
3. **大家可以進入./redis-cli,輸入info,查看你的狀態信息**;

## ???Redis截止到現在仍存在的問題
* \[哨兵已解決\]**:一旦主節點宕機,從節點晉升成主節點,同時需要修改應用方的主節點地址,還需要命令所有從節點去復制新的主節點,整個過程需要人工干預**。
* \[集群已解決\] :**節點的寫能力受到單機的限制**。
* \[集群已解決\] :**節點的存儲能力受到單機的限制**。
- 前言
- 第一部分 計算機網絡與操作系統
- 大量的 TIME_WAIT 狀態 TCP 連接,對業務有什么影響?怎么處理?
- 性能占用
- 第二部分 Java基礎
- 2-1 JVM
- JVM整體結構
- 方法區
- JVM的生命周期
- 堆對象結構
- 垃圾回收
- 調優案例
- 類加載機制
- 執行引擎
- 類文件結構
- 2-2 多線程
- 線程狀態
- 鎖與阻塞
- 悲觀鎖與樂觀鎖
- 阻塞隊列
- ConcurrentHashMap
- 線程池
- 線程框架
- 徹底搞懂AQS
- 2-3 Spring框架基礎
- Spring注解
- Spring IoC 和 AOP 的理解
- Spring工作原理
- 2-4 集合框架
- 死磕HashMap
- 第三部分 高級編程
- Socket與NIO
- 緩沖區
- Bybuffer
- BIO、NIO、AIO
- Netty的工作原理
- Netty高性能原因
- Rabbitmq
- mq消息可靠性是怎么保障的?
- 認證授權
- 第四部分 數據存儲
- 第1章 mysql篇
- MySQL主從一致性
- Mysql的數據組織方式
- Mysql性能優化
- 數據庫中的樂觀鎖與悲觀鎖
- 深度分頁
- 從一條SQL語句看Mysql的工作流程
- 第2章 Redis
- Redis緩存
- redis key過期策略
- 數據持久化
- 基于Redis分布式鎖的實現
- Redis高可用
- 第3章 Elasticsearch
- 全文查詢為什么快
- battle with mysql
- 第五部分 數據結構與算法
- 常見算法題
- 基于數組實現的一個隊列
- 第六部分 真實面試案例
- 初級開發面試材料
- 答案部分
- 現場編碼
- 第七部分 面試官角度
- 第八部分 計算機基礎
- 第九部分 微服務
- OpenFeign工作原理