> 本課是"Google ML速成課程"-"概念"的筆記。
> 旨在對ML的基本概念有個**快速了解**,第一遍學習時,理解不透徹沒有關系,可以在以后的學習過程中經常回頭。
> [課程鏈接](https://developers.google.cn/machine-learning/crash-course/ml-intro)
> [術語庫](https://developers.google.cn/machine-learning/crash-course/glossary)
> 本課學習時長評估:12~24個小時。
> 針對速成課程,略過我的筆記,直接學習以上課程鏈接。
## 問題構建 (Framing)
監督式學習、非監督式學習
標簽:Label
特征:Feature
樣本:有標簽樣本(labeled example)、無標簽樣本(unlabeled example)
模型:Model,模型定義了特征與標簽之間的關系
訓練:Training,是指創建或學習模型
推斷:Inference,是指將訓練后的模型應用于無標簽樣本
回歸:Regression,回歸模型可預測連續值,比如房價、概率
分類:Classifier,分類模型可預測離散值,比如是否垃圾郵件、圖像是狗、貓還是老鼠
## 線性回歸(Linear Regression)
經驗風險最小化:檢查多個樣本并嘗試找出可最大限度地減少損失的模型,這一過程稱為“經驗風險最小化”。
損失:損失是對糟糕預測的懲罰。損失是一個數值,完全準確,損失為0。
訓練模型的目標是從所有樣本中找到一組平均損失“較小”的權重和變差。
平方損失:一種常見的損失函數,又稱L2損失。
均方誤差(MSE):指的是每個樣本的平均平方損失。

## 降低損失(Reducing Loss)
迭代(Iterations)方法降低損失。通常,您可以不斷迭代,直到總體損失不再變化或至少變化極其緩慢為止。這時候,我們可以說該模型已收斂。
通過計算整個數據集中 每個可能值的損失函數來找到收斂點這種方法效率太低。
對于我們一直在研究的回歸問題,損失函數是凸函數,可以用梯度下降法降低損失。梯度是偏導數的矢量。導數是函數的變化速度。
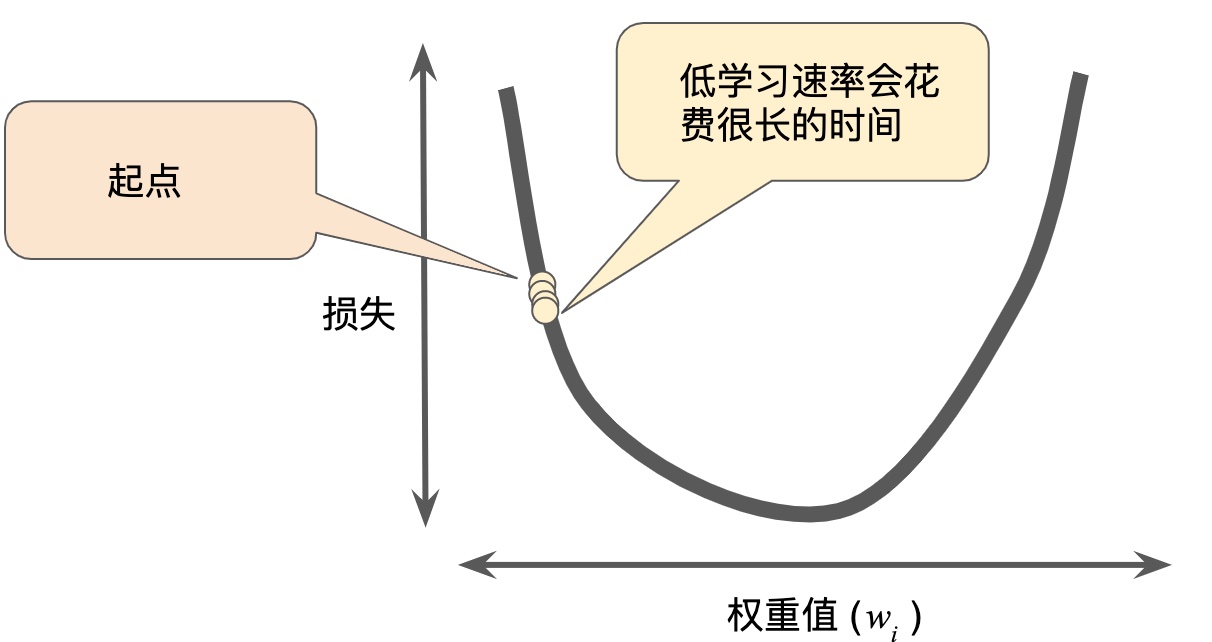
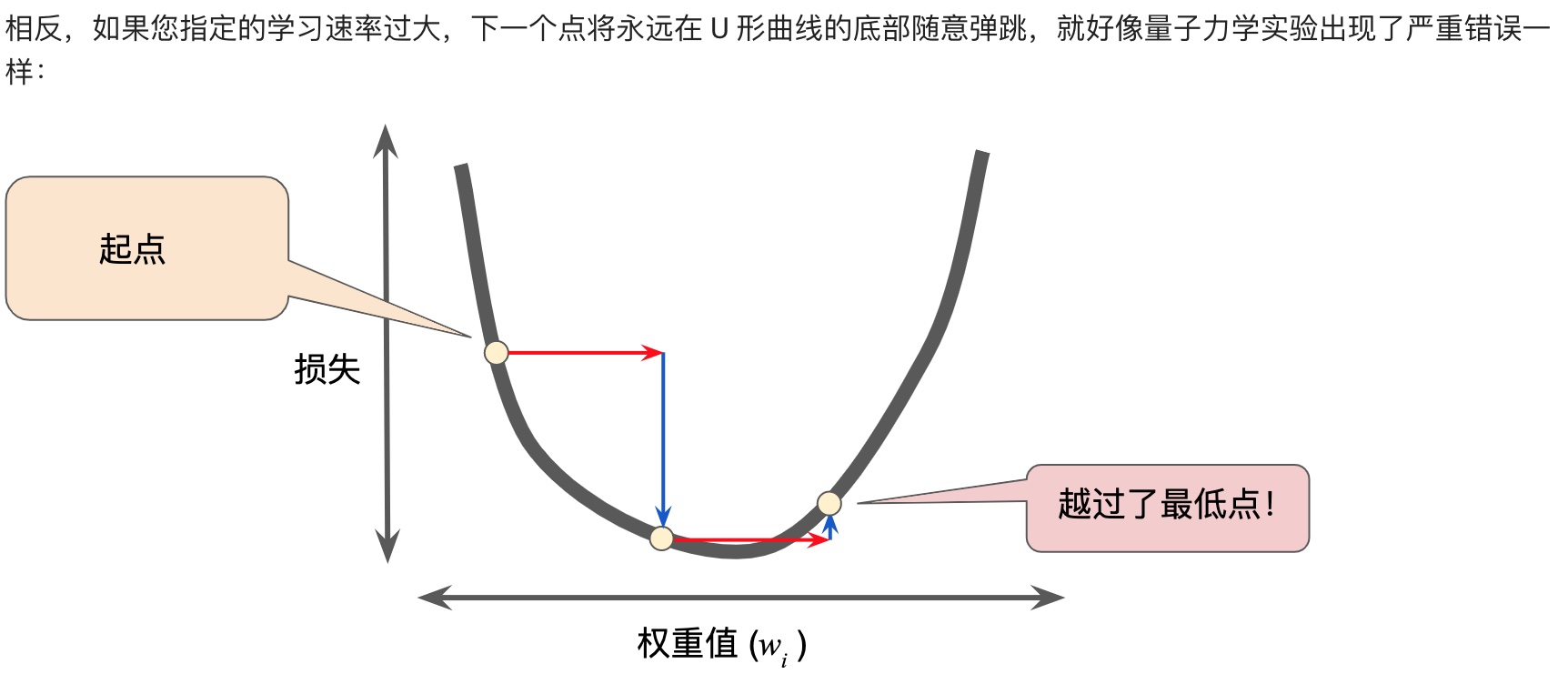
梯度下降法,用梯度乘以一個稱為學習速率(有時也稱為步長)的標量,以確定下一個點的位置。
超參數是編程人員在機器學習算法中用于調整的旋鈕。步長就是超參數。步長選擇太大太小都會有問題。
## 隨機梯度下降(stochastic gradient descent)
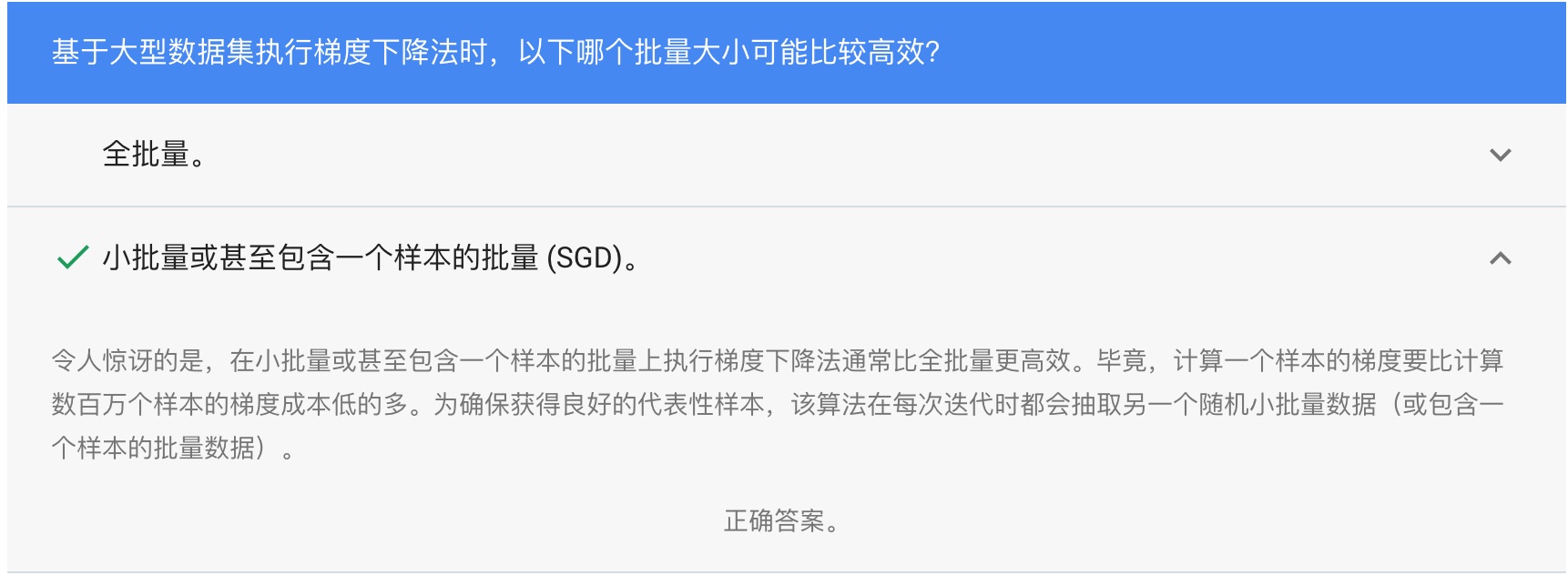
****這塊要理解一下,因為損失函數是凸函數,橫坐標是權重,縱坐標是損失,而損失是在一個批量(可以是總數據集、小批量、單個樣本)上,按照某種算法(比如就用均方誤差:MSE)計算出來的。****
**所以,批量越大,計算越慢,一個批量就用一個樣本,每次迭代最快。**
SGD、小批量SGD。

## 使用TF的基本步驟
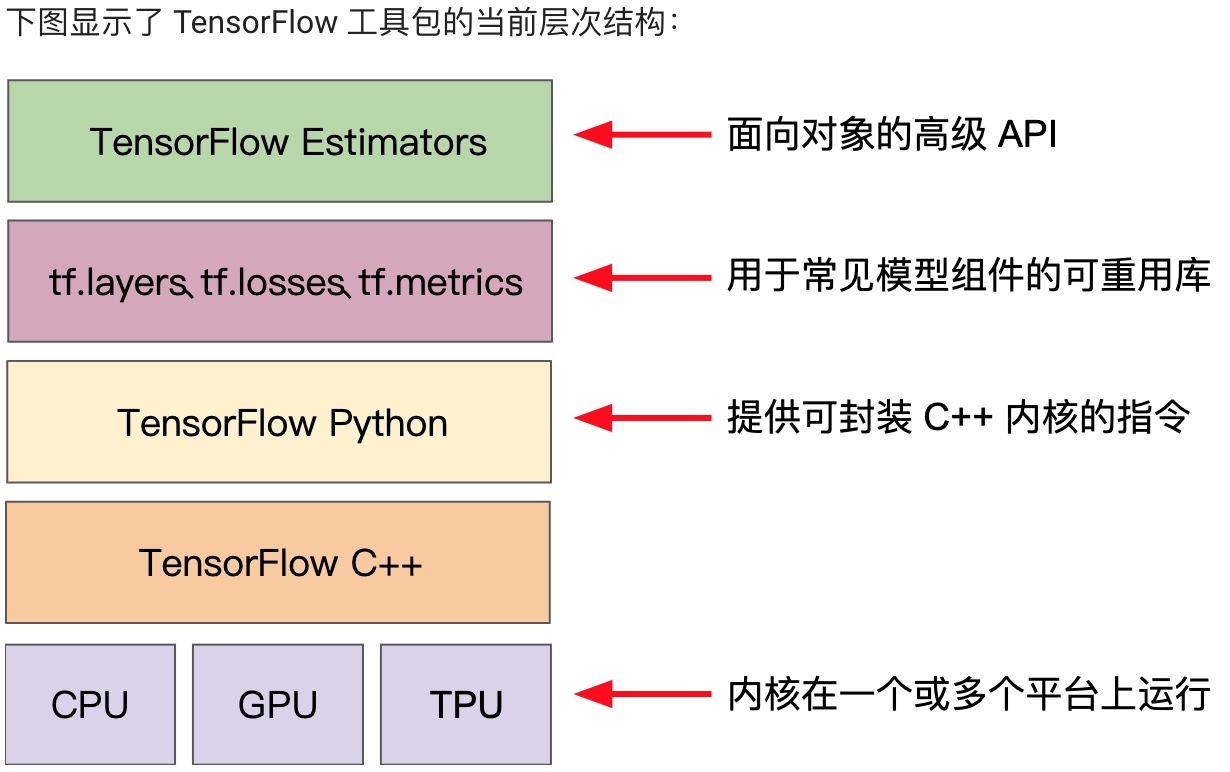
安裝jupyter notebook,學習:intro\_to\_pandas、線性回歸、合成特征以及輸入離群值帶來的影響,這3個練習。
關于jupyter的安裝,可以按照google介紹的pip方式。
我是使用機器學習特訓營介紹的anaconda方式:
1、下載安裝anaconda;
2、source ~/.bash\_profile 或者重啟,讓anaconda增加的環境變量生效
3、conda install jupyter notebook
**第一個練習:Pandas**
Pandas是用于數據分析和建模的重要庫,可以進行數據存取/加載/修改/reindex/繪圖等,很多學習框架都支持將pandas數據結構作為輸入。

**第二個練習:first\_steps\_with\_tensor\_flow**
演示一個用LinearRegressor構建模型,進行預測的完整例子。
完整代碼包含:
* 定義并配置特征列
* 定義目標
* 配置LinearRegressor及其超參數
* 定義輸入函數
* 訓練模型
* 評估模型
然后練習調整模型超參數,以及嘗試使用其他feature進行預測。
**第三個練習:synthetic\_features\_and\_outliers**
合成特征以及輸入離群值帶來的影響
## 泛化 (Generalization)
泛化是指模型很好地擬合以前未見過的新數據(從用于創建該模型的同一分布中抽取)的能力。
過擬合是由于模型的復雜程度超出所需程度而造成的。機器學習的基本沖突是適當擬合我們的數據,但也要盡可能簡單地擬合數據。
**奧卡姆剃刀定律:**
機器學習模型越簡單,良好的實證結果就越有可能不僅僅基于樣本的特性。
現今,我們已將奧卡姆剃刀定律正式應用于統計學習理論和計算學習理論領域。
雖然理論分析在理想化假設下可提供正式保證,但在實踐中卻很難應用。機器學習速成課程則側重于實證評估,以評判模型泛化到新數據的能力。
一種方法是將您的數據集分成兩個子集:訓練集、測試集。
一般來說,在測試集上表現是否良好是衡量能否在新數據上表現良好的有用指標,前提是:
1、測試集足夠大。
2、您不會反復使用相同的測試集來作假。
## 訓練集和測試集
練習:拆分訓練集和測試集,調整學習速率,調整批次大小
## 驗證(Validation)
多次重復執行訓練流程可能導致我們不知不覺地擬合我們的特定測試集的特性。當進行多輪超參數調整時,僅使用兩類數據可能不太夠。
更好的方法,增加驗證集:
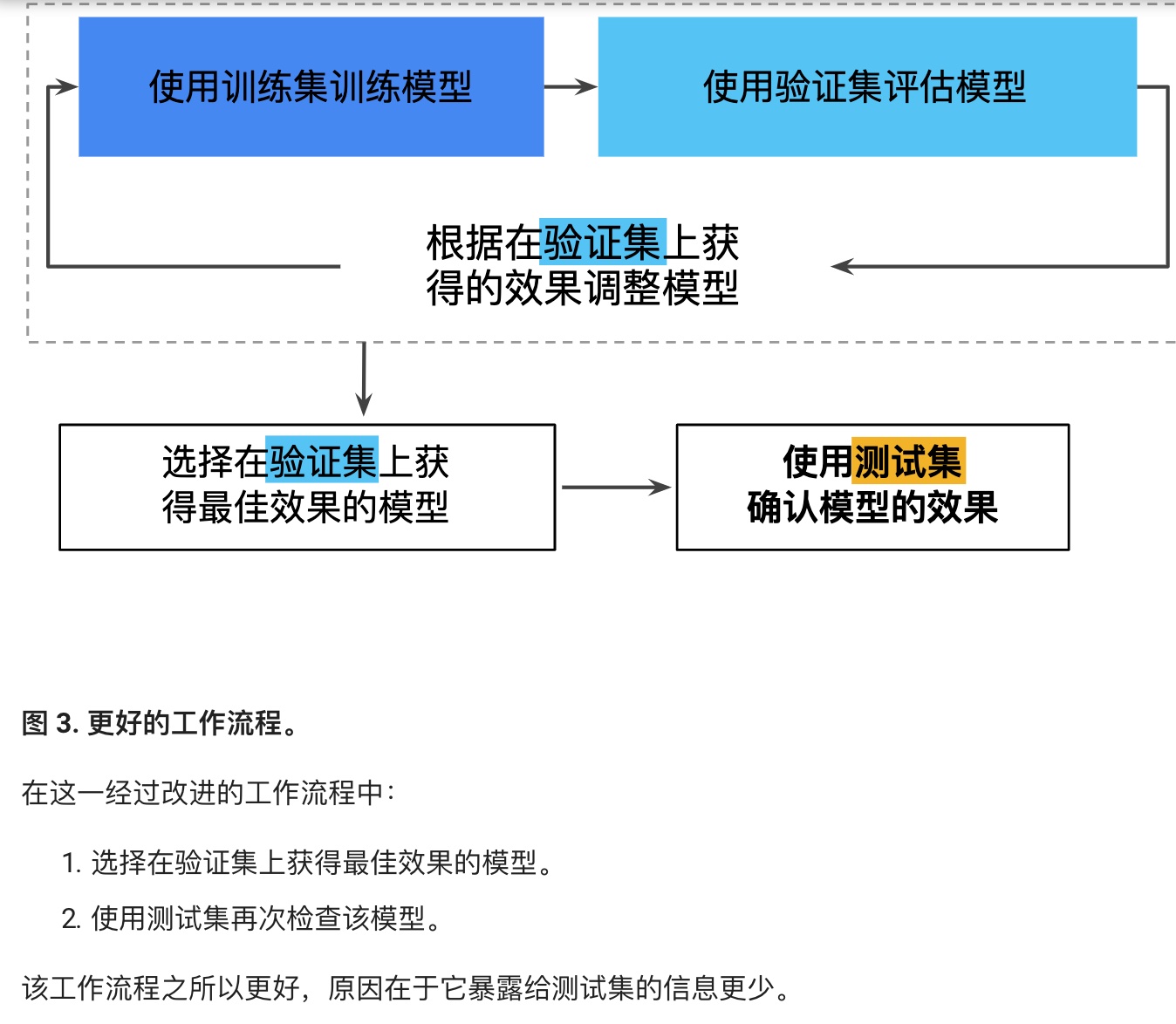
實際生產中,可能采用更多驗證集,更多測試集。
課后練習:Validation.ipynb
## 表示 (Representation):特征工程
特征工程指的是將原始數據轉換為特征矢量。進行特征工程預計需要大量時間。
許多機器學習模型都必須將特征表示為實數向量,因為特征值必須與模型權重相乘。
**字符型特征的處理:通過獨熱編碼進行映射。**
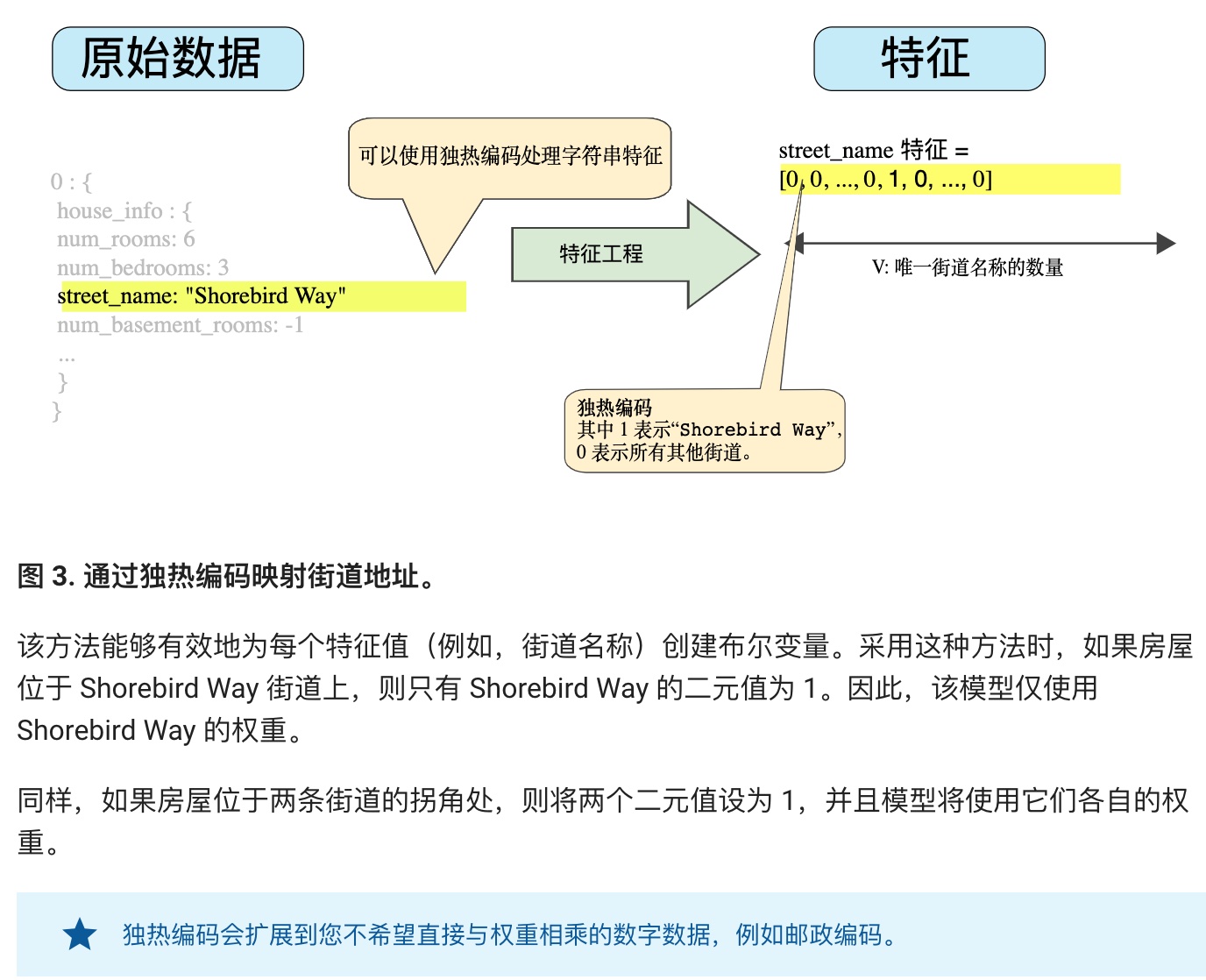

**良好特征的特點:**
* 避免很少使用的離散特征值。至少出現5次以上,比如ID就不適合做特征,學習不到任何規律。
* 具有清晰明細的含義。user\_age:27 is ok. user\_age:32234 and user\_age:277 is not ok.
* 實際數據內不要摻入特殊值。比如一個特征具有0~1的浮點數。如果有默認值-1,則需要解決。
* 考慮上游的不穩定性。
**清理數據:**
作為一名機器學習工程師,您將花費大量的時間挑出壞樣本并加工可以挽救的樣本。
比如:縮放特征值、處理極端集群值、分箱、清查。


**處理極端集群值:**
* 一種辦法是取對數
* 或者限制最大值,超過的都是最大值。
分箱:比如經緯度這種數字和房價沒有線性關系,我們可以分箱稱若干個分類。百分比分箱和分位數分箱。分位數分箱無需擔心離群值。
清查:遺漏值、重復樣本、不良標簽、不良特征值。

## 特征組合 (Feature Crosses)
Synthetic feature or feature cross
**對非線性規律進行編碼:**

**組合獨熱矢量:**



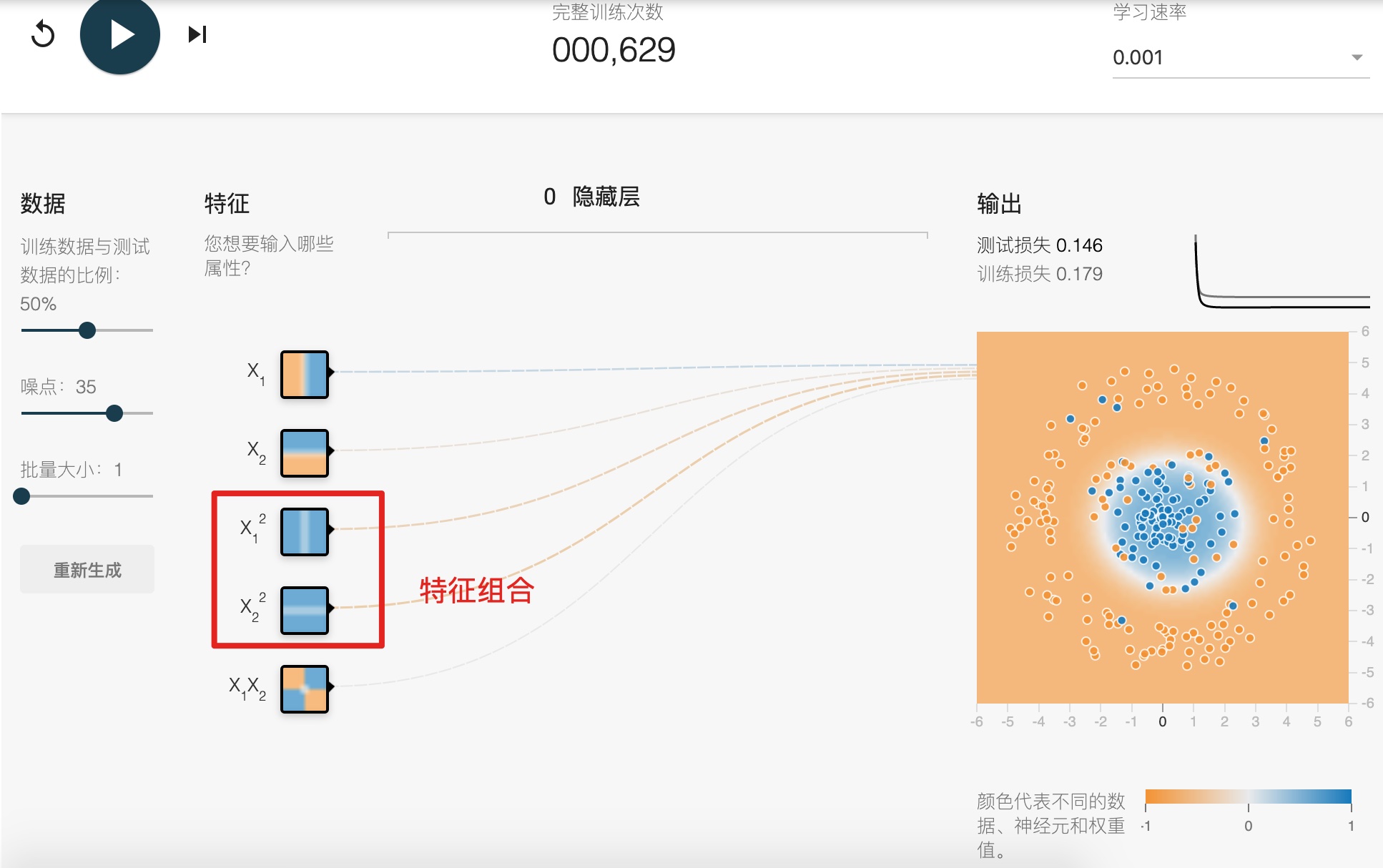

**一定要看這個代碼演示:feature\_crosses.ipynb**
## 正則化:簡單性(Regularization of simplicty)
**組合過度:**

**L2正則化:**

**Lambda:**

**我們可以了解到,訓練模型的目標有二:擬合度高,復雜度小。**
## 邏輯回歸(Logistic Regression)

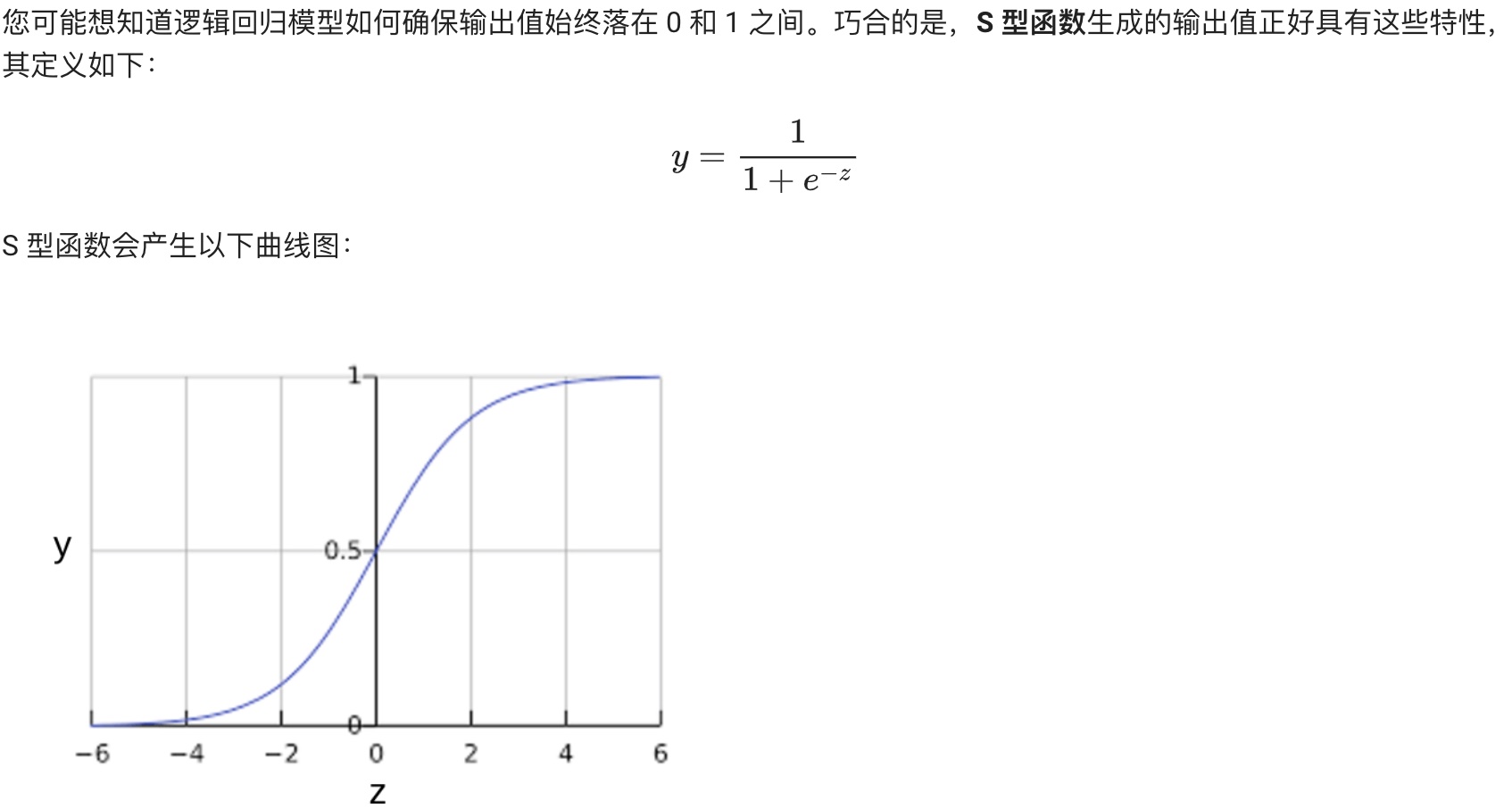
**邏輯回歸的損失函數:對數損失:**

**邏輯回歸中的正則化:**

**總結:**

## 分類(Classfication)
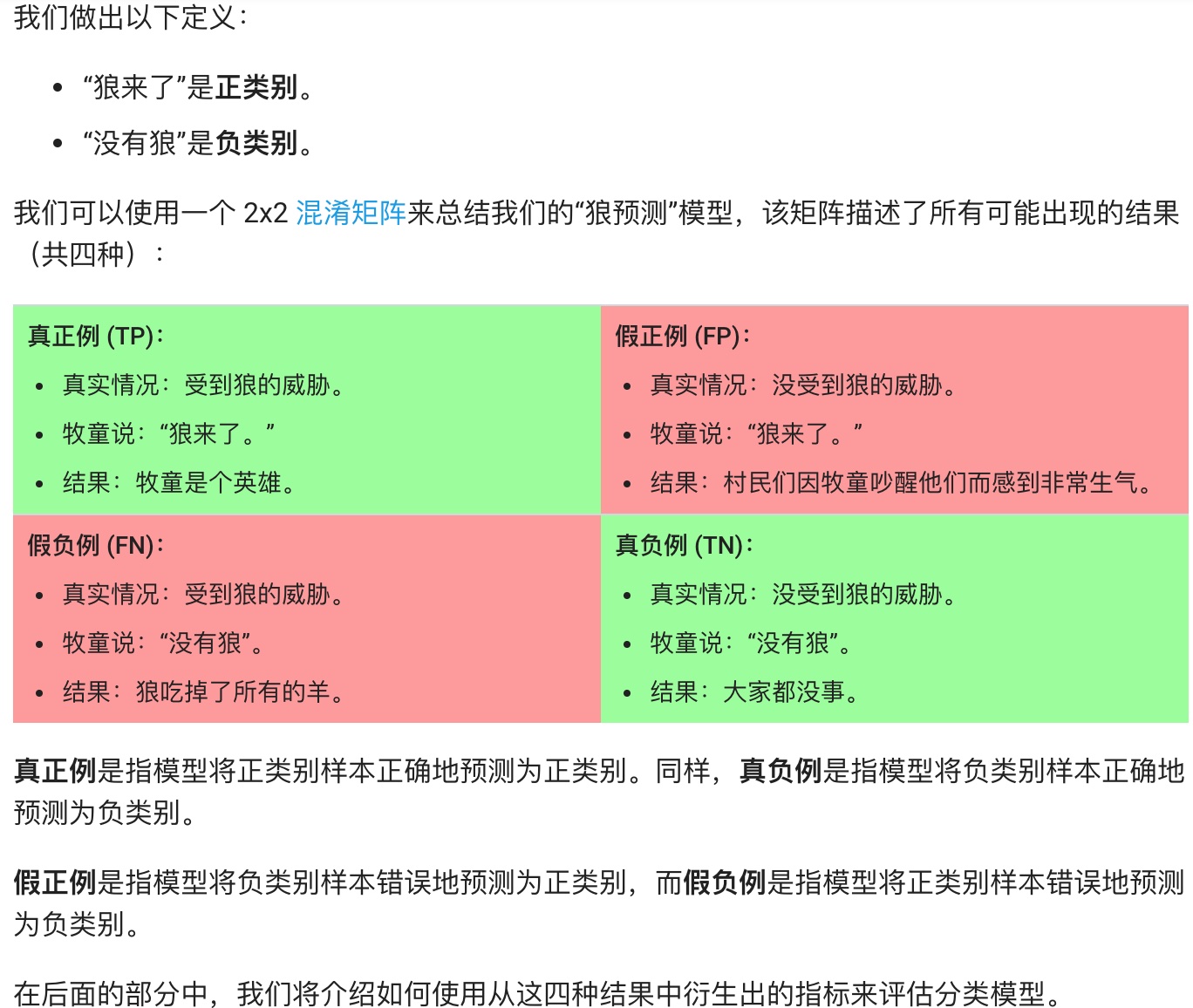
**準確率(Accuracy):**

當數據不平衡時呢,比如雖然準確率很高,但是9個惡性腫瘤只預測了一個。

**精確率(Precision):**

**召回率(Recall):**

**Precision&Recall總結:**

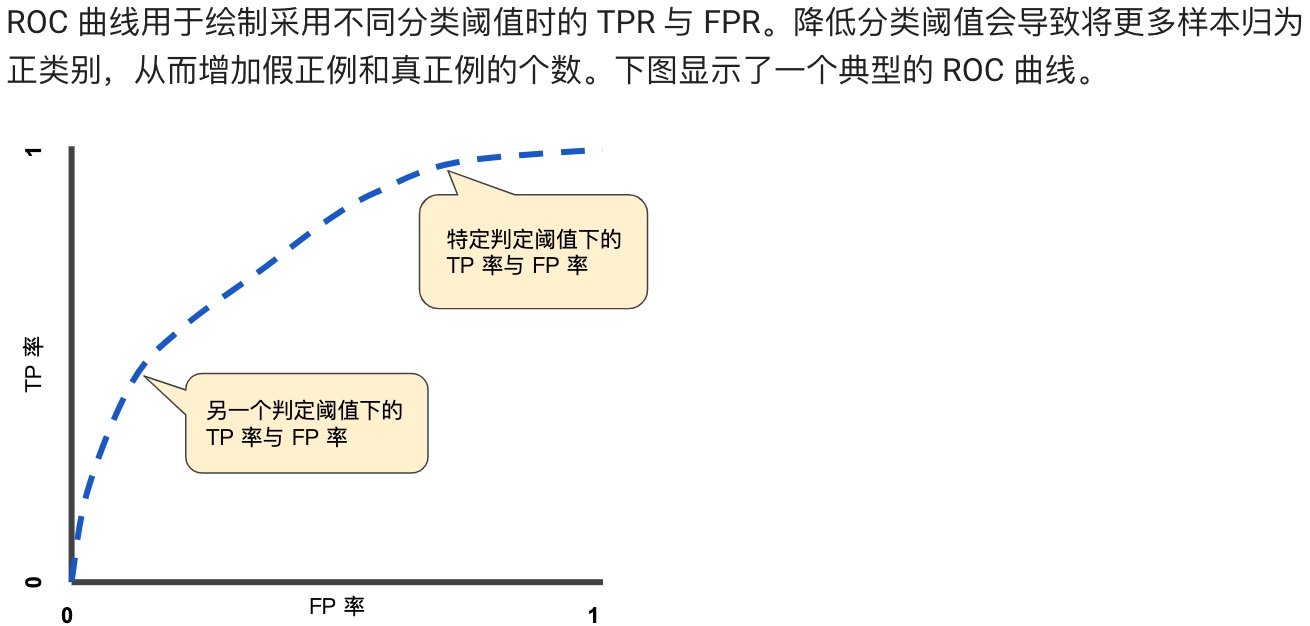
**ROC 曲線(接收者操作特征曲線)是一種顯示分類模型在所有分類閾值下的效果的圖表。**
**預測偏差:**

## 正則化:稀疏性(Regularization of sparsity)
臨時跳過。。。
## 神經網絡簡介(Neural network)
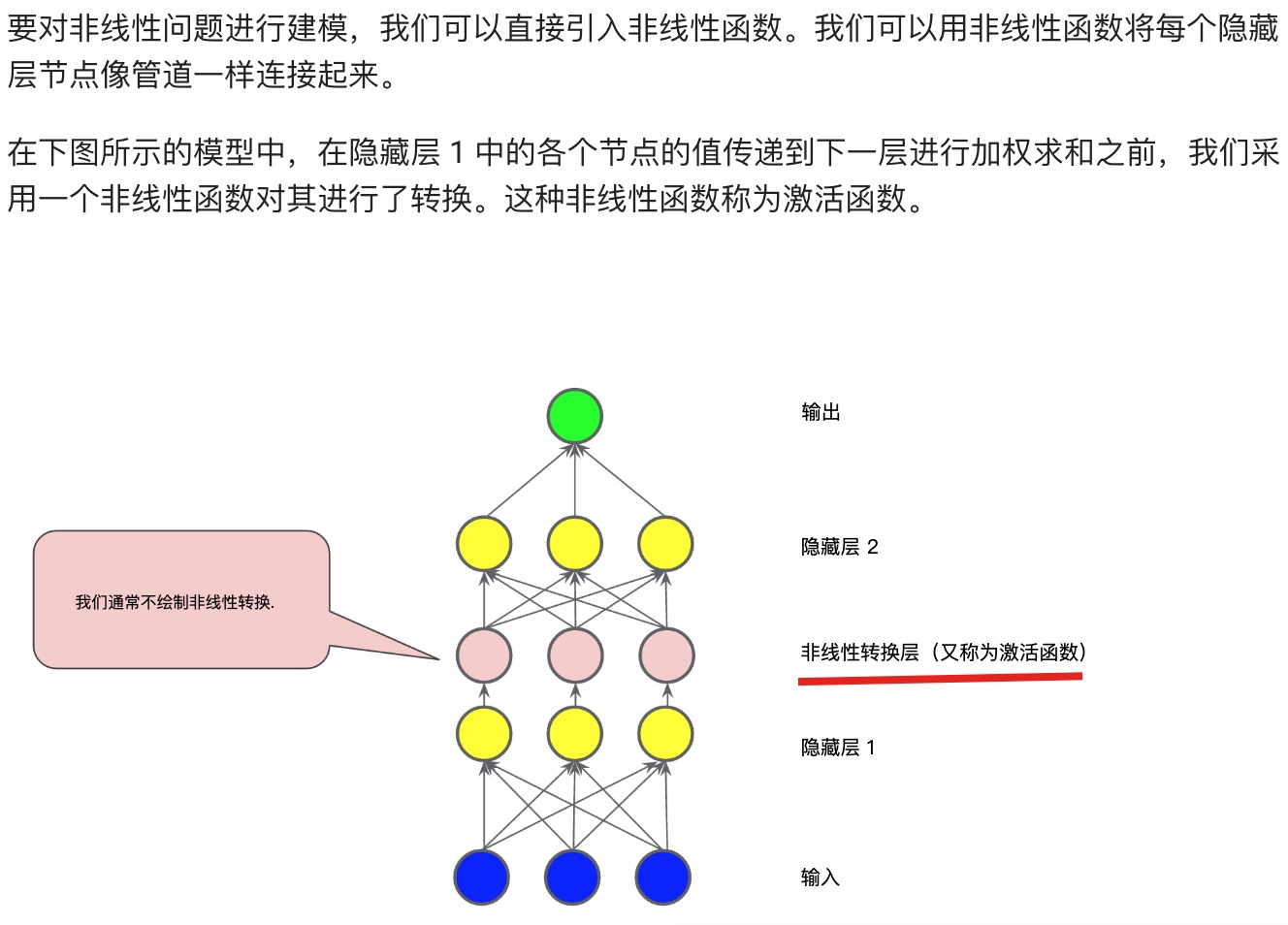
**常見的激活函數:S型函數、ReLU(修正線性單元)函數。**

## 訓練神經網絡(Training Neural Networks)
back propagation:反向傳播。dropout:丟棄。

關于反向傳播,有以下重要的事情需要了解:



## 多類別神經網絡
臨時跳過。。。
## 嵌套 (Embedding)
臨時跳過。。。
