# 一、產品介紹
云小蜜(Intelligent Service Robot)是一款基于自然語言處理(NLP)和人工智能(AI)技術,
面向開發者提供智能會話能力的云服務。開發者可以使用云小蜜創建會話機器人,為機器人
配置知識庫以實現智能問答,使用對話工廠配置意圖實現多輪對話與自助服務(如訂單查詢、
物流跟蹤、自助退貨等),并將機器人部署在不同終端上(如網站、移動 APP、智能硬件等)。
具體來說,云小蜜可以進行文本機器人、熱線機器人、實體機器人、輔助助手等產品的開發
與使用,通過知識庫實現單輪問答的智能回復、通過對話工廠實現多輪問答以及系統交互類
業務處理,除此之外,還有機器閱讀、知識圖譜等產品功能供不同場景用戶使用。同時,通
過視角的設置,可以將小蜜進行不同渠道的部署,對每個渠道進行個性化問答。
[官方文檔]([https://help.aliyun.com/document\_detail/60453.html?spm=5176.12818093.0.0.488716d0YIDTM8](https://help.aliyun.com/document_detail/60453.html?spm=5176.12818093.0.0.488716d0YIDTM8))
# 二、開通服務
## 2.1申請開通云小蜜
進入阿里云之后搜索云小蜜,進入小蜜官方產品頁面,點擊獲取使用資格(需要提前進行實
名認證),進入系統審核環節。審核完畢后,會顯示“管理控制臺”按鈕,如下圖:

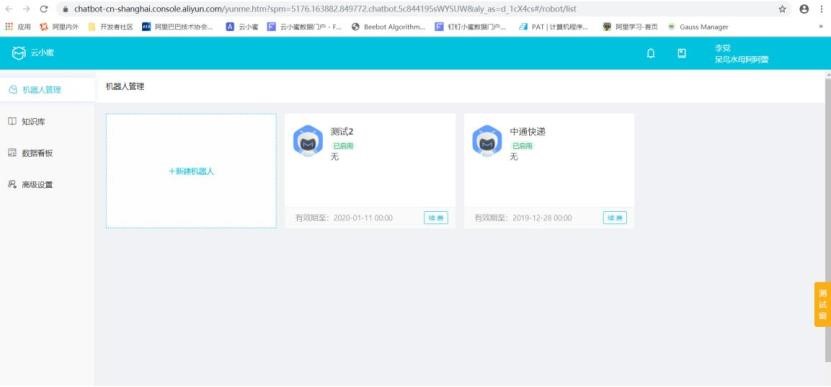
點擊“管理控制臺”按鈕,進入云小蜜控制臺界面,如下圖:
可看到的產品功能介紹如下:
A.機器人管理:對機器人實例(租戶)進行新建、編輯(姓名、注釋)、管理、備注等;
B.知識庫:對現有知識進行管理編輯,增刪改查等;
C.數據看板:對日常數據運營情況進行檢查。
D.高級設置:主要是知識庫設置(視角設置)、權限管理、開發者選項(暫未開放)等功能。
## 2.2創建實例
點擊“新建機器人”,進入購買環節,購買完畢后,進入機器人創建頁面,輸入機器人姓名、
備注,點擊保存,創建完畢。
點擊創建好的機器人,進入機器人頁面,分為機器人配置、會話接口、機器人訓練三個模塊。
A.1.機器人配置:分為機器人信息、綁定知識類目、對話流管理、查件管理等模塊。
2. 機器人信息:包括名稱、備注(可點擊右側編輯修改)、時區、機器人 ID(不可修改);
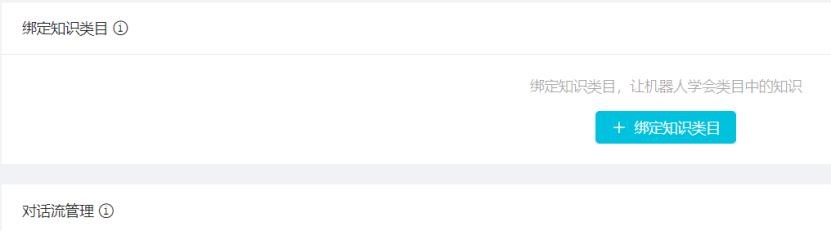
3.綁定知識類目:點擊編輯可以綁定對應知識類目,機器人只有綁定對應類目后,才可以
對對應類目下的知識進行問答。
4.對話流管理:點擊去對話工廠,可以進入對話工廠創建對話流,上線后的對話流可以在
這個模塊看到。
B.1.會話接口:包括視角的編碼、實例 id 信息、AccessKey 信息等。
2.視角編碼:開發者調用對應接口時,需要調用對應的視角編碼,則機器人返回答案為對應視
角的答案(針對 FAQ 而言。對話工廠目前沒有視角概念,需要在對話流里通過函數進行判
斷)
3.實例 ID 信息:調用時候需要用到。
4.AccessKey 信息:調用時候需要用到。
C.機器人訓練:為機器人訓練工具,可以對機器模型算法進行訓練,提升整體問答準確率。
# 三、知識維護
## 3.1 創建類目
### 3.1.1 從知識庫進行類目創建
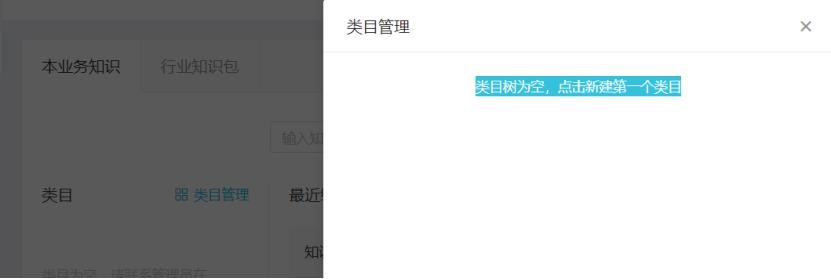
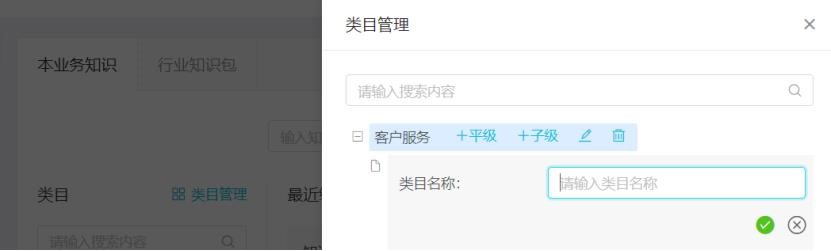
點擊知識庫-類目管理,進入類目創建。點擊:“類目樹為空,點擊新建第一個類目”
輸入類目名稱,點擊勾號,保存對應類目:
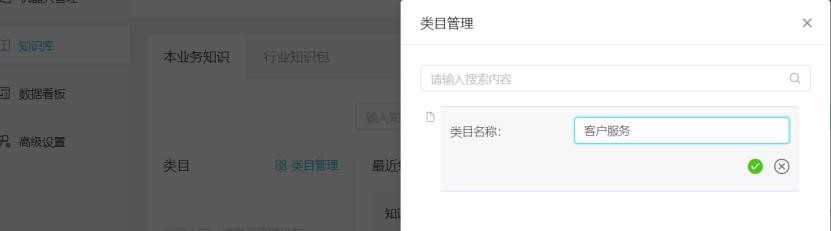
如果在該級類目下需要創建子類目,則點擊類目管理-創建好的類目(例:客戶服務)-子級,進入子類目設置,輸入類目名稱、點擊勾號,保存對應類目。
類目創建完畢后,進入機器人管理-機器人配置-綁定知識類目:
勾選對應類目,點擊確定,則綁定了對應類目,可以問答對應類目下知識。
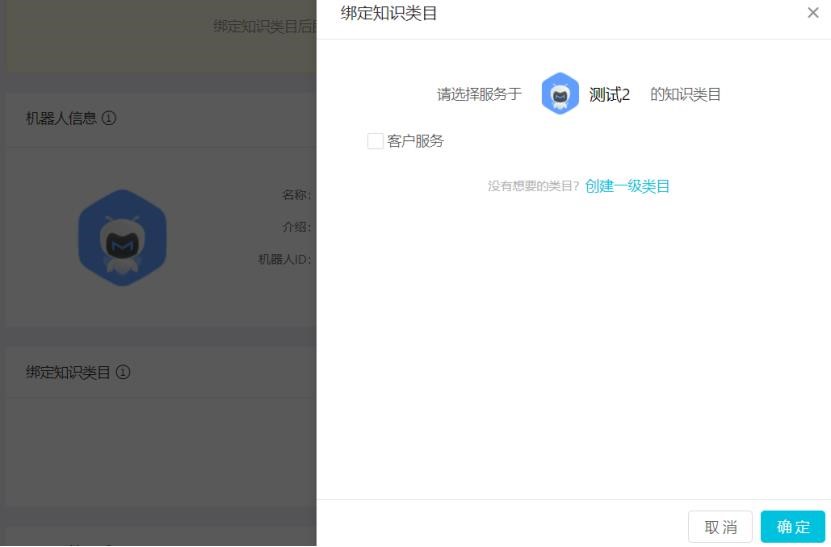
### 3.1.2 從機器人管理進行類目創建
點擊機器人管理-機器人配置-綁定知識類目,在彈出窗口中,點擊“創建一級類目”,可以新
創建一個一級類目,操作與從知識庫操作基本相同,新建類目會默認勾選綁定,我們可以認
為去掉勾選。
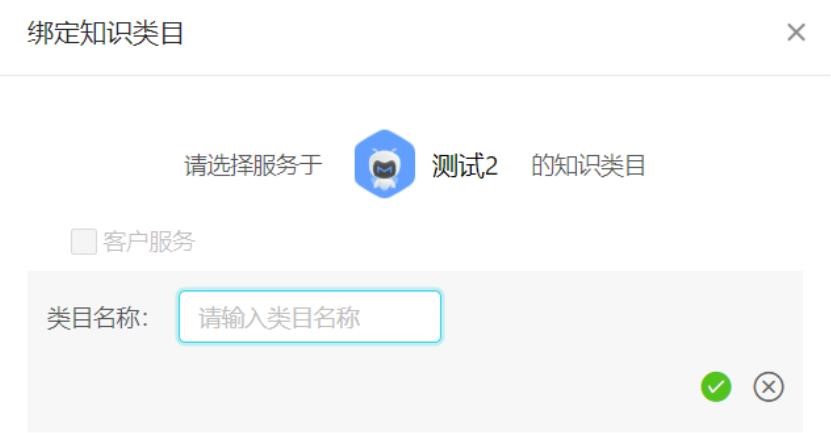
創建完畢后,根據實際需求確認勾選類目,點擊保存,即完成綁定。
## 3.2 創建知識
點擊知識庫,進入知識編輯界面。
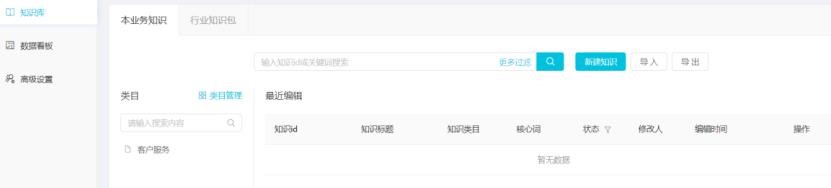
點擊“新建知識”,在彈出的新建知識對話框中,輸入類目路徑、知識標題、核心詞、視角、生效時間、答案。
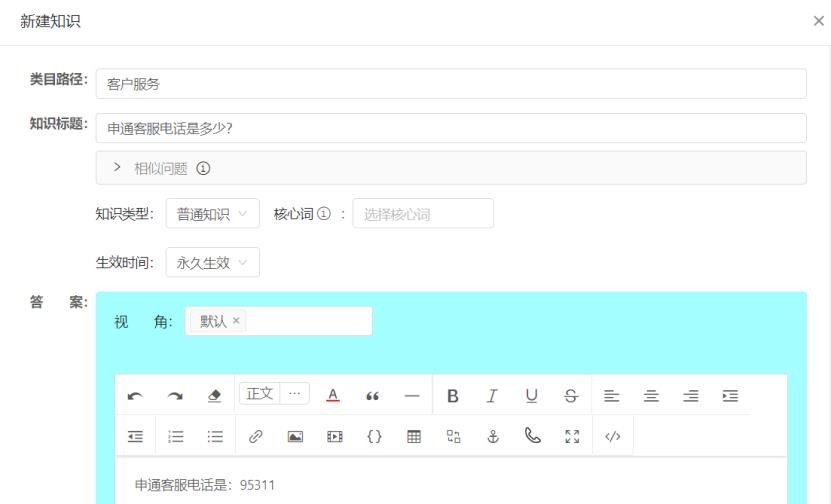
A. 類目路徑:該條知識所歸屬的類目,點擊后選擇對應類目綁定。
B. 知識標題:一般是用戶的常見問法,機器人會把用戶的問法與知識標題進行匹配。
C. 核心詞:該條知識里面最為核心的詞匯,是為了更精確定位問題而產生,它有如下規則:
1.核心詞和知識類目不可混淆,類目只是知識的管理結構,不參與知識搜索匹配。
2.核心詞是知識標題中最核心的部分,一定一字不差的包含在知識標題中;如果有其他表達方式,可以給核心詞添加同義詞。
3.知識標題是用戶最常見的業務問法,核心詞需要包含在大部分的相似標題中;
4.核心詞不能是其他核心詞的同義詞;
5.核心詞之間不可包含;
6.核心詞不可過長或者過短,建議保持合適的詞或者短語粒度;
7.核心詞及其同義詞要合理管理,避免混亂或互相重疊。
D. 生效時間:一些活動類或者其他短暫生效的知識,可以設置一定的生效時間,過了生效時間后知識自動失效。
E. 答案:當機器人知識被觸發后,機器人返回給用戶的答案內容。答案支持按視角回復給用戶(即不同視角,我們可以設置不同答案),
在答案內容上,支持文字(字體、顏色、下劃線、高量、刪除、對齊等操作)、圖片、超鏈、等內容格式。如果有不同的渠道,且渠
道答案不一樣,我們可以在創建完一個答案后,再點擊“新建答案”,創建另一個視角的答案。
以上內容填寫完畢后,點擊保存,即可保存對應答案。
## 3.3 批量操作
如果批量操作的知識量比較大,可以采取批量操作,包括批量導入和批量導出、批量刪除、失效等。
A. 批量導入:
點擊知識庫-批量導入,進入批量導入頁面,下載標準模板進行知識維護。

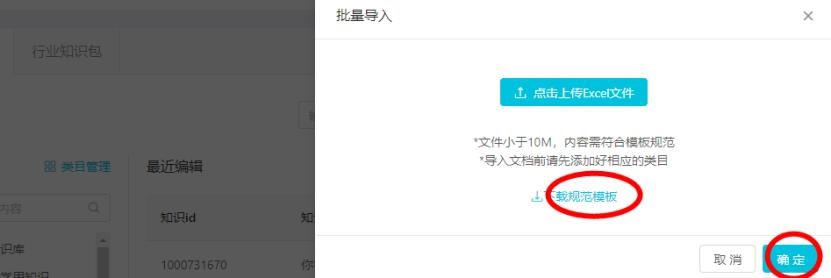
在下載的模板中,依次填入類目路徑(需要提前有這個類目,如果沒有導入會報錯)、核心詞名稱(核心詞定義規則按上文描述,只有一個同義詞)、
核心詞同義詞名稱(核心詞的同義詞,要求必須是英文逗號間隔,中文逗號會報錯,知識標題(只有一條,按上述規則)、相似問法(知識標題的相似問法,
最好包含核心詞和同義詞,相似問之間用換行隔開)、答案(默認是默認視角的答案,可以增加視角以及答案)。填寫完畢后,進行上傳。
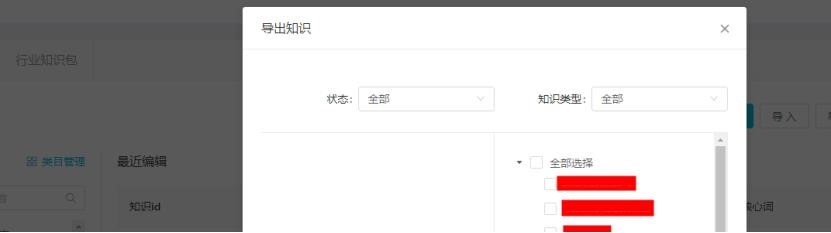
B. 批量導出
點擊知識庫-批量導出,選擇對應導出類目,點擊確定,即可導出對應類目的知識。
C. 批量刪除
目前不支持類目層級的知識刪除。我們可以按類目選擇內容進行刪除。點擊知識庫-某一類目,進入知識界面后,點擊左上角勾選,選擇所有知識,點擊右下角刪除,刪除當頁所有知
識。

D. 批量失效
步驟通批量刪除,點擊類目選擇某些知識,點擊右下角失效按鈕,則全部失效;
E.批量轉移、發布
步驟通批量刪除。
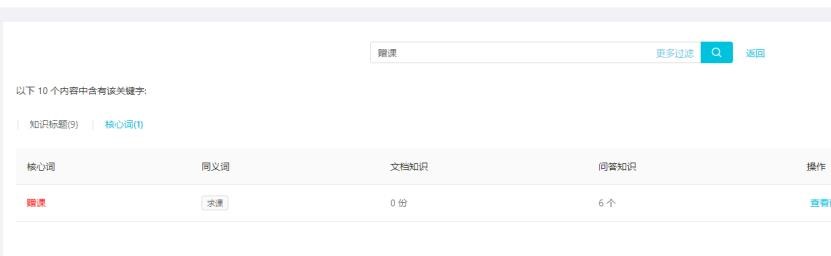
知識新建完畢后,可以通過知識庫進行增刪改查相關知識。如果想修改或者刪除對應核心詞,可進行搜索該核心詞-點擊核心詞-查看詳情,可以編輯核心詞、刪除同義詞、刪除核心詞、
增加同義詞、修改核心詞等,實現核心詞的管理。目前沒有單獨的核心詞管理工具。

# 四、對話工廠
## 4.1 新建對話流
點擊機器人管理-某機器人-對話流管理-去對話工廠,進入對話流管理界面:
點擊“新建對話流單元”,輸入姓名、描述,選擇對話流模板(可以先選空白對話流),進入對話流畫布界面。
在這個畫布頁面就可以進行多種流程、會話的智能化配置和管理。
## 4.2 梳理業務流程
在創建對話流之前,我們會先根據業務需要梳理業務流程。我們以停車費用查詢和天氣查詢為例,進行兩個業務梳理。
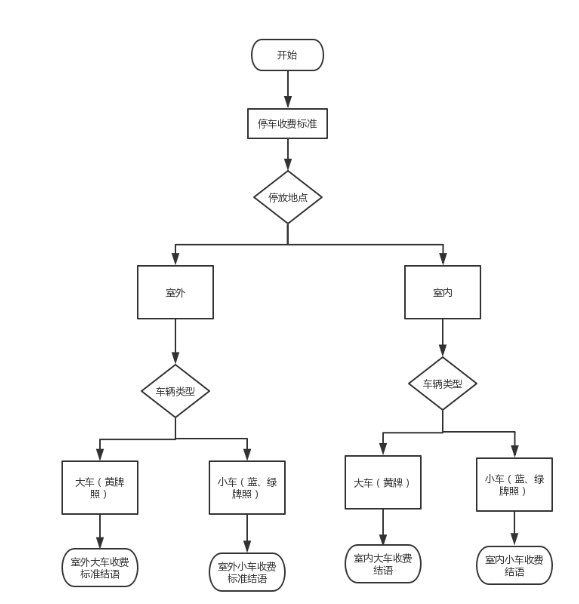
A. 停車費用業務梳理
我們以停車費用做為多輪問答的案例。停車費用需要考慮是室內、室外,車牌顏色等多個場景,每個場景的答案不一樣,最簡單的場景也至少要兩輪問答, 邏輯圖如下:
B. 天氣查詢梳理
我們以天氣查詢作為查詢類業務的案例。天氣查詢需要明確日期、城市才能明確要查詢什么內容,同時還需要調用對應的接口才能實現,我們梳理的業務內容如下:
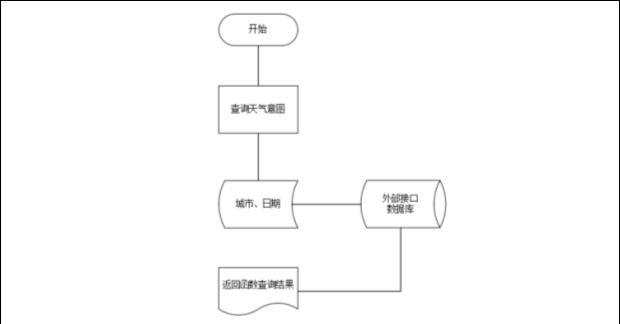
## 4.3 意圖節點
意圖節點是用來綁定用戶的意圖的節點,當觸發用戶意圖的時候,系統觸發當前意圖節點下的動作,例如,當下面為回復節點的時候,觸發機器人播報對應回復內容。意圖節點要綁定對應意圖才能生效。
點擊意圖列表-新建意圖,進入意圖創建環節。
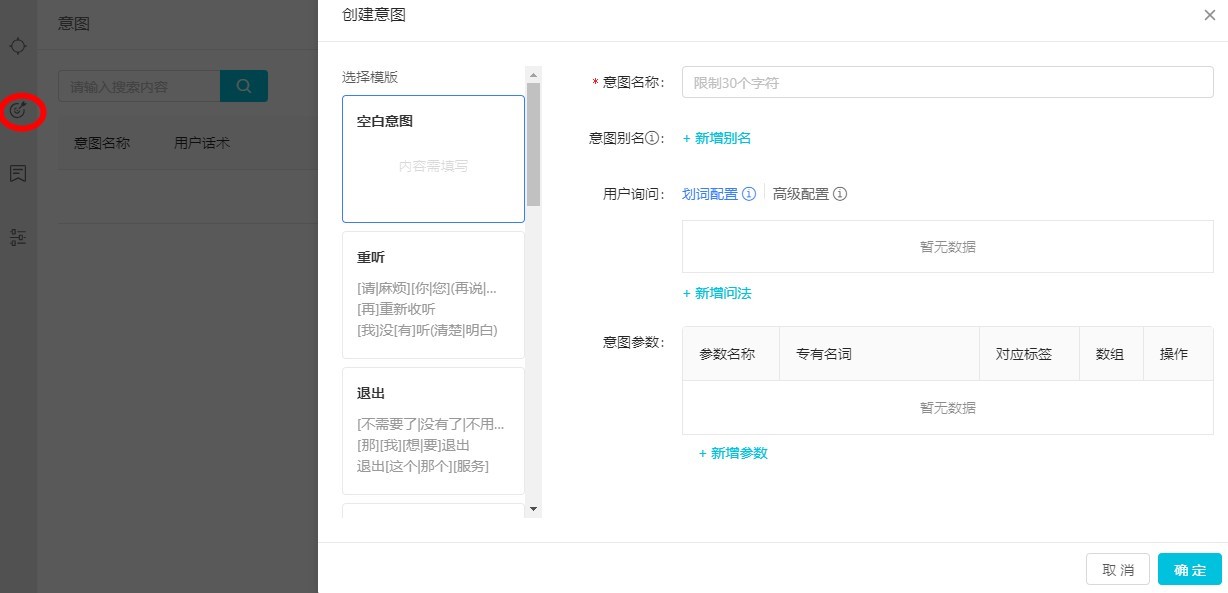
目前支持兩種方式創建意圖節點,包括劃詞配置和高級配置。
A. 劃詞配置:直接輸入用戶的高頻問法,當不勾選嚴格匹配的時候,可以通過算法自動泛化說法。例如,在劃詞配置里面配置:“我想問下停車怎么收費”,則當用戶問“停車收費”時,也可以配到該條意圖。
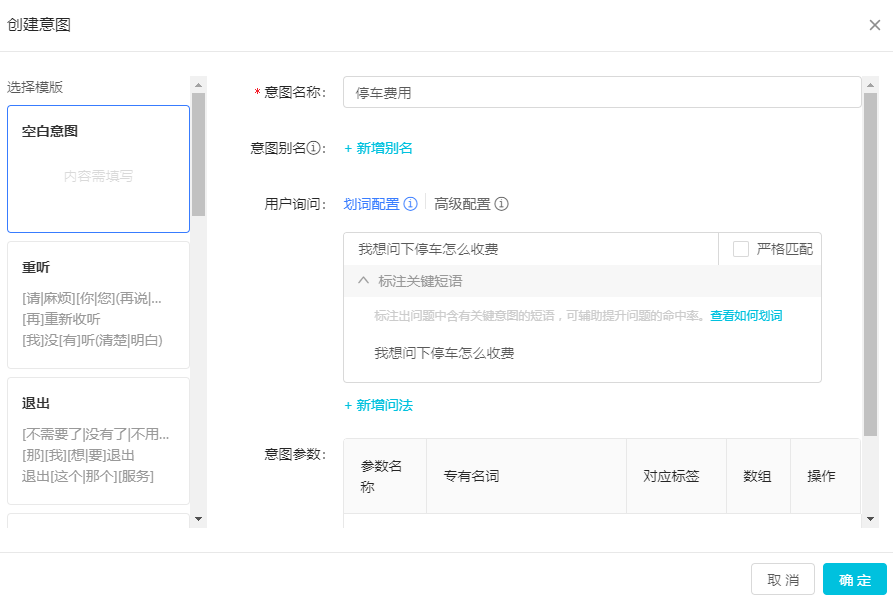
B.高級配置:利用 LGF 規則對用戶說法進行泛化處理。詳見《LGF 規則文檔》。通過 LGF 規則泛化后,當用戶說法符合當前 LGF 規則,則匹配當前意圖。
用戶將意圖節點拉到畫布中,從開始的節點連線到對應意圖節點,命名當前節點,并且把意圖節點綁定用戶意圖(點擊新增 and 條件,選擇對應意圖;如果隨意 N 個意圖都能觸發, 還可以點擊下面的新增 or 條件組,新增其他意圖,這樣不管命中哪一個意圖都會觸發當前節點),則用戶表述相關內容后可以出發當前節點。如果節點下面沒有動作,是無法保存的, 必須有其他的動作節點,比如函數節點、填槽節點、回復節點等。
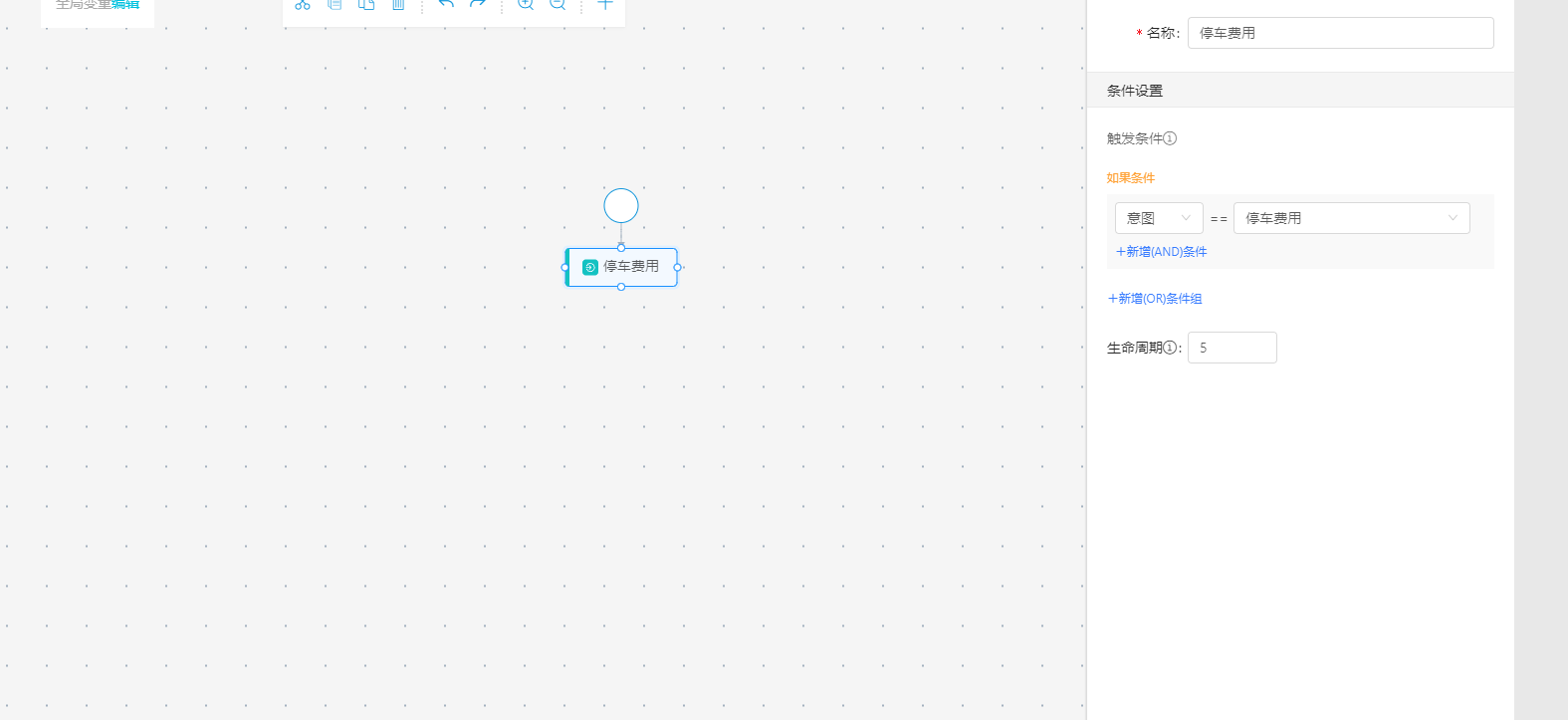
生命周期是指假設現在對話處于這個觸發節點前面的回復節點時,用戶沒有按照流程走,而是跳走了,那么X 輪(X 為你填寫的生命周期)之內還能再接回這個觸發節點。
## 4.4 回復節點
回復節點也就是機器人回復給系統的內容的節點。我們可以通過在回復節點的話術控制,實現整體的VUI 設計。例如,剛剛舉例的停車費用場景,當用戶啟動停車費用意圖后,我們可以通過回復節點的內容讓用戶回復:“請問您是需要停在室內還是室外?”
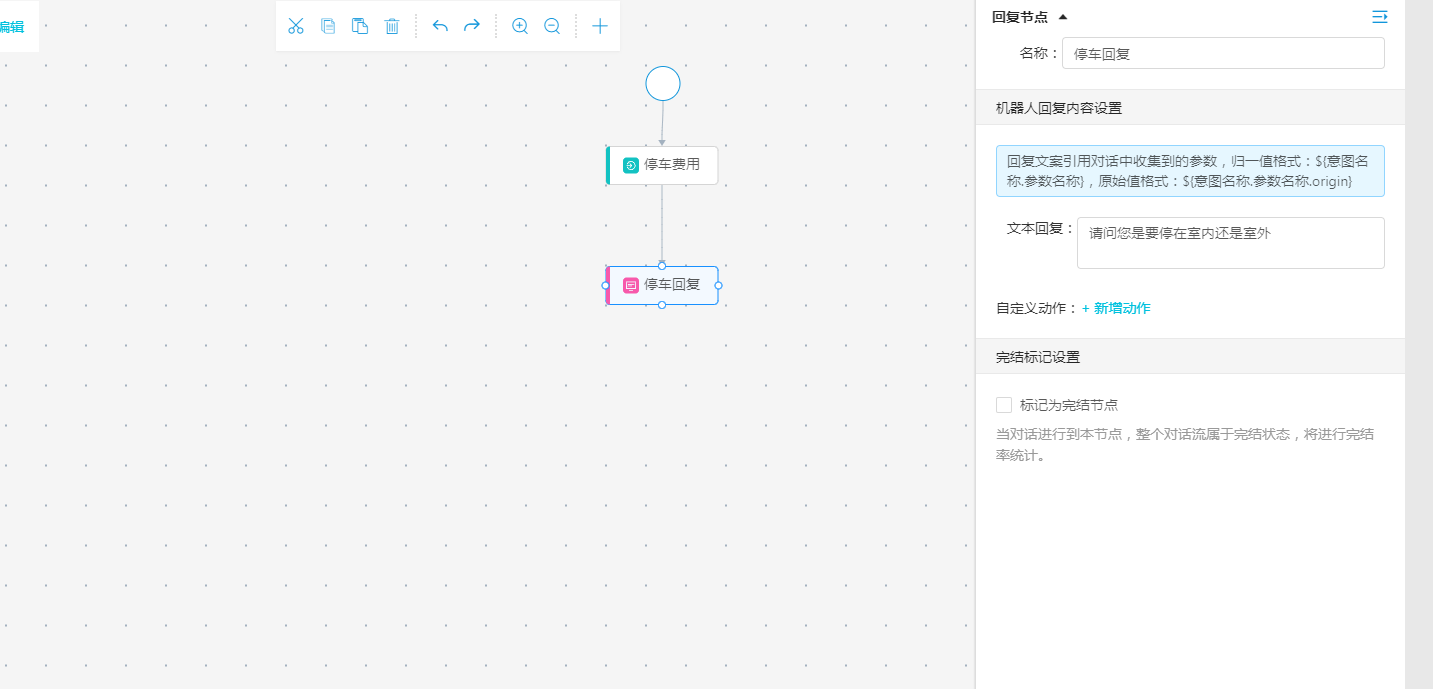
用戶根據反問導引,可能會說室內,室外,都可以等回復,根據不同意圖再進行新意圖的創建以及與意圖節點的綁定,同時,針對不同意圖進行針對性回復。
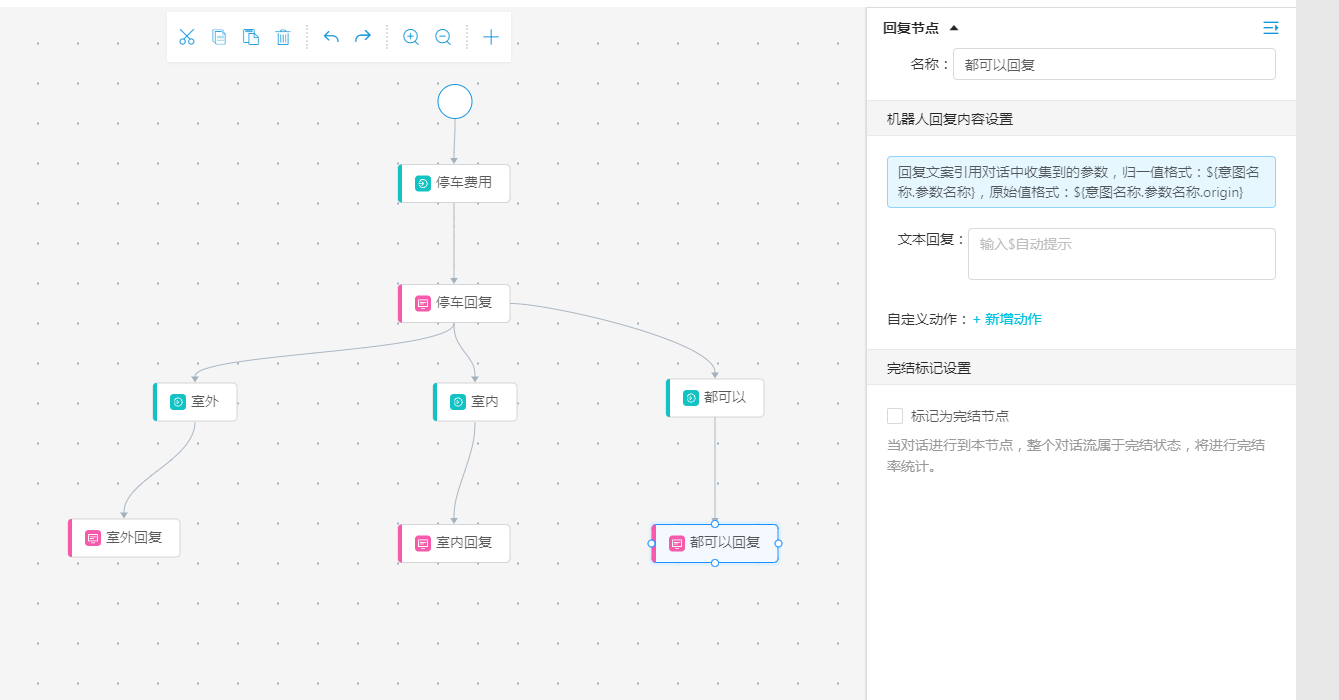
編寫完畢后,點擊保存草稿,可以把當前的對話流保存。
## 4.5 專有名詞
指專有名詞是同類型單詞的合集,如:城市、日期、顏色等。語義通過專有名詞進行理解, 然后抽取并輸出機器可以理解的格式。例如用戶說「我喜歡綠色」,我們都知道綠色是一種顏色,但如果我們不預先告訴機器,機器是不會知道的。為了讓機器能夠理解綠色,我們可以創建一個詞庫,把常見的顏色列舉,這樣機器再遇到這些詞,就能知道是一種顏色。
A. 標準名詞:在生活和業務當中,有很多不同的詞語代表著同一種意思,例如:北京、帝都、中國首都。這幾個詞語都是指同一個城市,那么我們可以通過配置的方式將這些詞語指定到一個標準名詞:例如,北京是中國城市中的一個,那么他屬于城市這個類名詞下面,同時他又可以叫帝都、北平等。那么我們可以讓北京作為名詞成員,帝都作為同義詞。
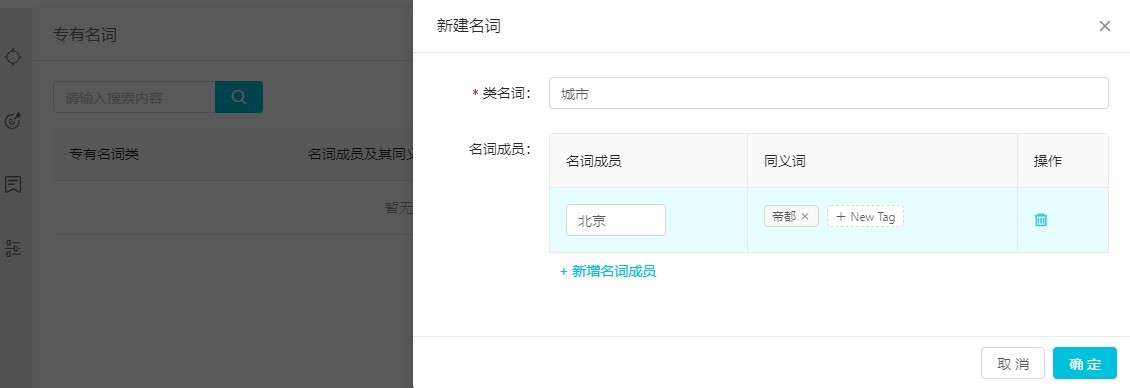
B.正則名詞:正則名詞是基于問法規則的名詞體系,例如手機號碼,我們沒辦法窮舉,但是他其實是有一個體系的,我們就用一個文法規則來表述(1\\d{10}),詳細的正則規則見正則規則文檔。
除了我們自己創建的名詞外, 系統還預置了非常多的系統內置名詞, 例如: @sys.date\\@sys.geo-city 等。他們本身是一系列固定的詞組,但是我們人工維護又很麻煩(例如全國的城市、區縣),系統為了解決這個問題,就自動內置了很多的實體,方便我們進行引用。
通常專有名詞會和意圖進行綁定。例如,在詢問天氣時,我們是需要時間和地點的,那么我們就需要引入城市和時間兩個專有名詞。正好這兩個詞是系統有預置,我們可以通過兩種方式引用:
1. 劃詞引用:在劃詞配置界面,直接針對用戶詢問進行劃詞,例如用戶問“明天杭州天氣怎么樣”,其實明天和杭州是可變的,不同的值結果也不一樣,那么我們就稱之為槽位,相對應的值(“明天”“杭州”)稱之為槽值,我們引用專有名詞拓展整體槽值范圍。用鼠標劃取下方對應取值范圍,點擊添加標注,選擇對應專有名詞(@sys.date、@sys.geo-city) 編輯完畢后,點擊修改參數名稱,讓自己好記一些(例如,改成 date 和 city)點擊保存, 即可實現劃詞引用。這個時候,用戶說后天南京天氣怎么樣,前天合肥天氣怎么樣,系統就都能識別了。
2. 高級配置引用:除了劃詞配置外,我們還可直接對專有名詞進行 LGF 規則引用,引用方式如下:
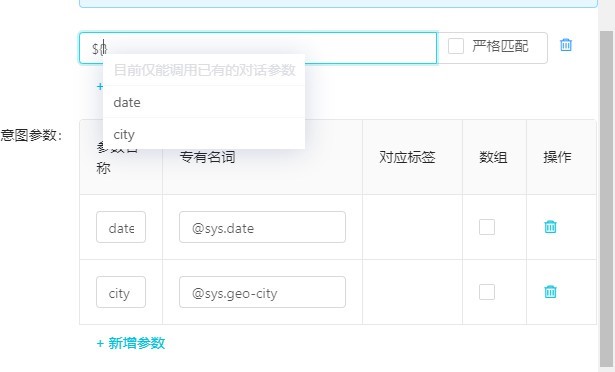
點擊編輯意圖-高級配置-新增參數,添加對應所需要的意圖參數,并改寫相關信息(參數名稱)。
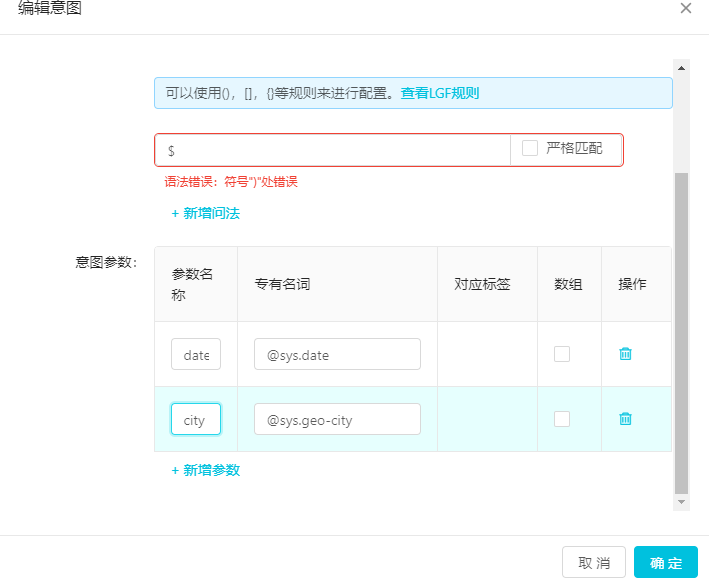
點擊新增問法,輸入”${}”,系統會自動推薦參數引用,選擇對應參數。注意,LGF 規則只能調用目前已有(下方意圖參數中已有)的參數,沒有關聯的參數無法引用。
當意圖參數勾選詞組時,則在收集改參數的時候,可以按照數組的模式收集若干條信息。例如,我可以在city 那里勾選數組,則我在收集信息的時候,可以收集若干個城市的信息。意圖和專有名詞綁定后,后面可以對接填槽節點來收集信息。
## 4.6 填槽節點
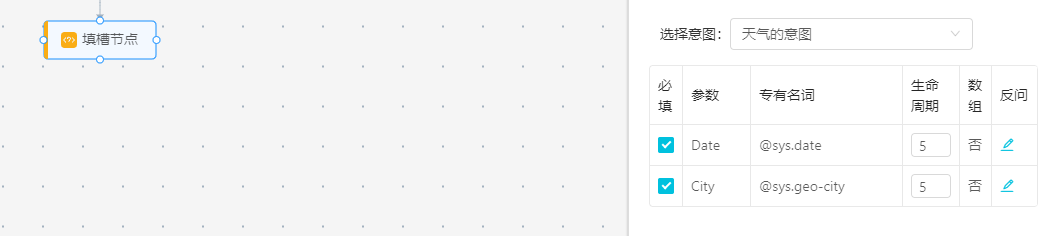
填槽節點主要實現兩個功能:1.收集當前節點下沒有收集到的名詞信息,2.把收集到的名詞的值收集到系統里。這里的信息收集主要是通過節點的反問來實現的。
在將填槽節點拖至畫布,點擊鏈接意圖和填槽節點,選擇對應的意圖(通常系統會默認鏈接的那個意圖節點所綁定的意圖)。系統會自動跳出這個意圖下所綁定的參數。我們可以勾選必選或者不勾選必選,同時,在后面編輯對應反問。
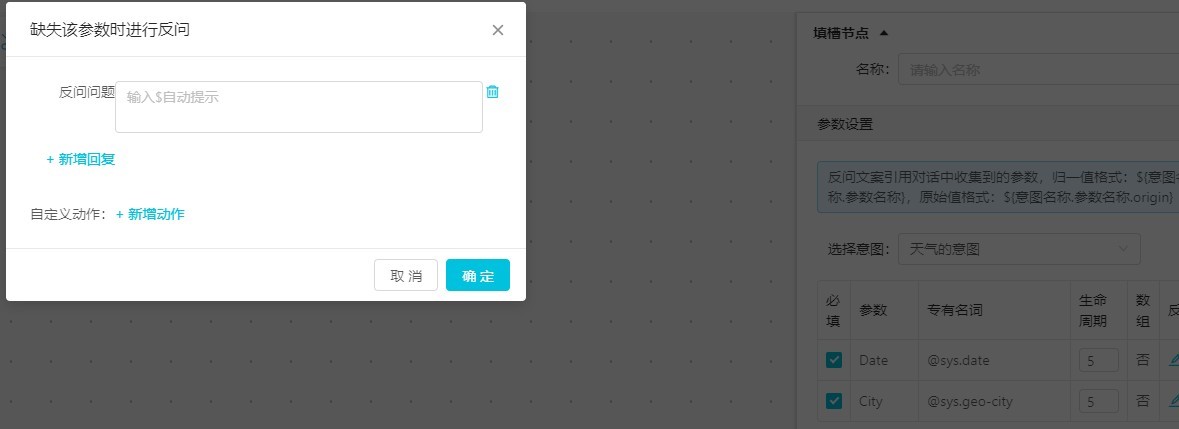
點擊訪問下的筆按鈕,點擊新增回復,創建該參數反問(即,用戶沒有說這個參數的時候我們反問用戶讓用戶把參數提交上來):
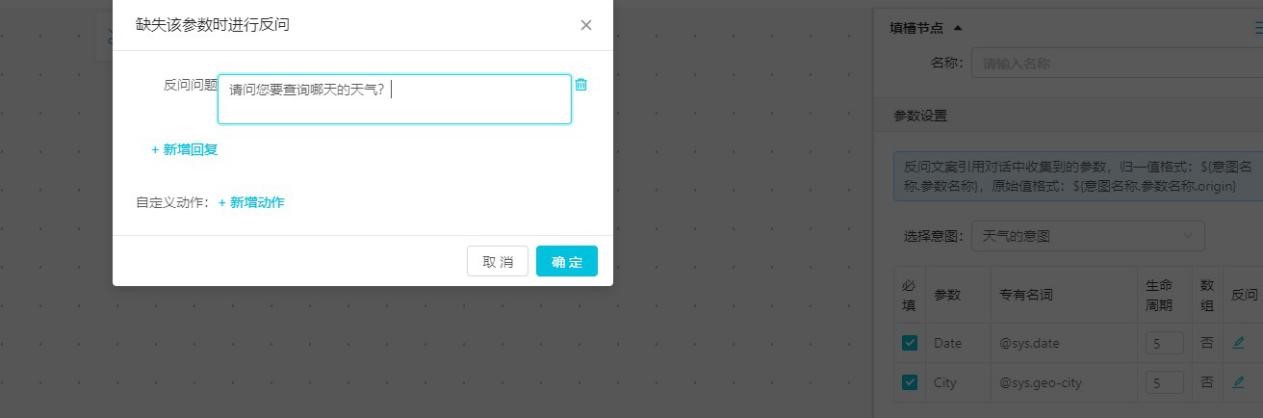
編寫完畢后點擊保存。進入下一環節。
如果沒有填槽節點,即使用戶表述中觸發了對應槽值,我們也沒有辦法將槽值傳到系統以及函數,所以填槽節點的存在是重要的,哪怕他不要執行反問的那個動作(如果前面已經有這個值,那么收集這個值的對應反問就不需要觸發)。
## 4.7 函數節點
通過函數節點,我們可以實現對于 api 接口的調用或者對函數的調用。
API 接口:我們可以根據使用已經成型的接口,對數據進行調用,通常情況會有 post 和 get 兩種模式,回傳內容可能是在 query、header、body 三種方式,調用方式和回傳字段由接口定義。
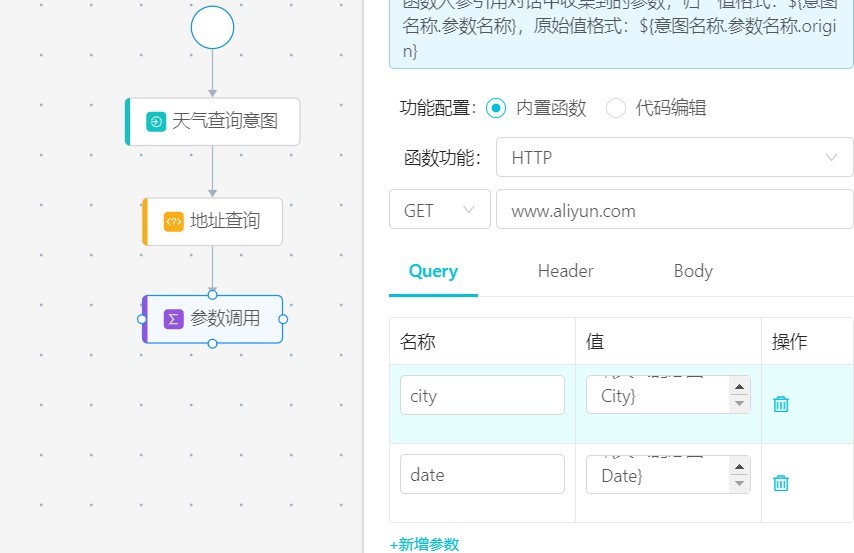
例如,在天氣查詢字段中,我們的接口連接為:www.aliyun.com,調用方式為 get,接口字段為city、date,對應的字段的值引用對應系統中的某些值。在天氣查詢里面,主要是上傳City 和Date 的值。引用方式是${天氣的意圖.City}(前面是意圖,后面是意圖相關參數,這個時候引用的是專有的專有名詞的值。如果想引用原有的值(比如直接引用了同義詞),需要用${天氣的意圖.City.orgin})。
如果涉及到函數計算調用,通常涉及到函數編寫,這個時候需要開發進入協助編寫調用。
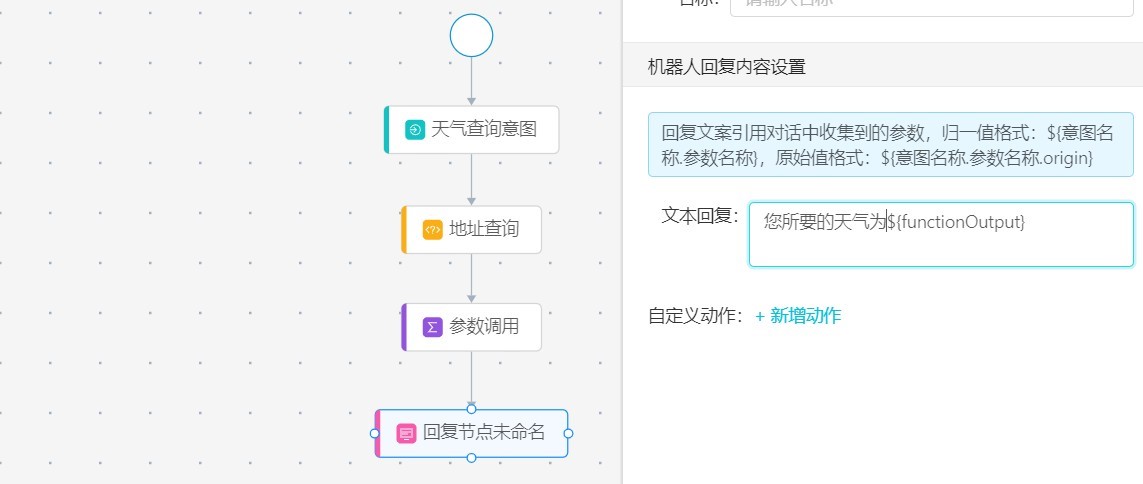
調用對應參數后,我們可以針對返回的結果進行調用,調用方式為${functionOutput},如果涉及返回結果的具體某個值,那么可以用${functionOutput.XXX.XXX}的方式進行調用。上面內容可以在回復節點里面對文檔綜合使用
## 4.8 聯調測試
上述內容填充完畢后,我們點擊保存草稿、測試,即可將對話流上傳測試。

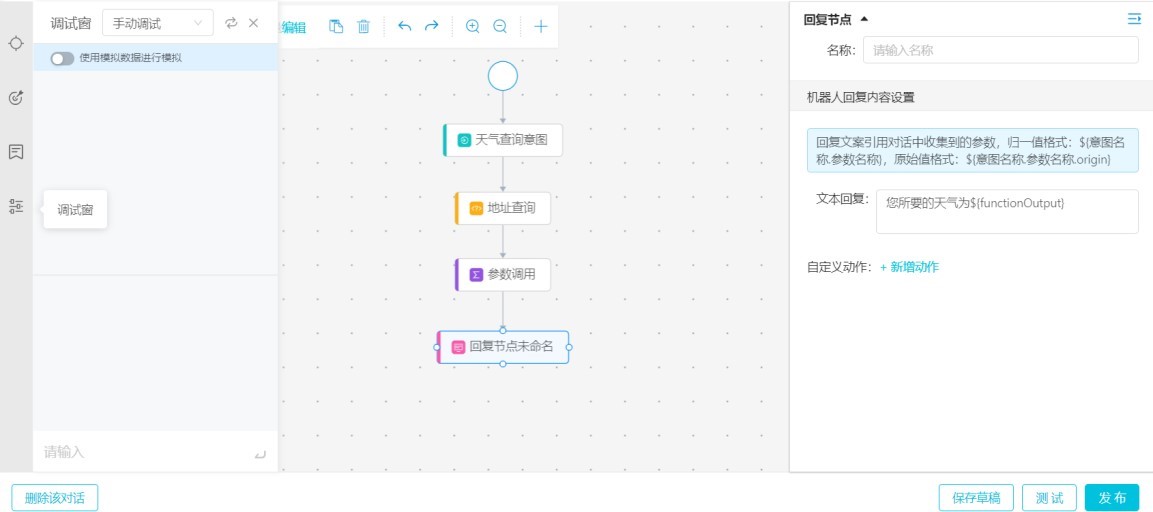
點擊調試窗,進入調試頁面,我們可以按照我們梳理的意圖,進行問答的測試,看配置的流程是否有問題。在配置的過程中可能會出現如下問題:
1. 名稱沖突:當對話流中各個節點出現重名的時候,是沒有辦法保存的;
2. 最終節點不是回復節點:最終節點必須是回復節點(報錯為:葉節點只能為 response 節點);
3. 函數調用異常:可能是調用的方式出現異常,或者上傳的字段出現異常,或者鑒權的方式出現異常等,具體分析建議可以讓開發看下。
4. 其他異常:按 case 進行溝通。例如,流程可能出現異常,跳轉錯誤、系統超時等;
## 4.9 導入對話流
除了自己編寫創建對話流之外,我們還可以將對應的對話流進行導出導入。點擊對話工廠- 某個對話流右上角-點擊導出,即可導出對應對話流。注意,只有發布過的對話流才可以進行導出設置。

導出之后的對話流可以備份或者導入到其他的對話工廠中,點擊對話工廠右上角“導入對話流”,選擇導出的字符串,則可以導入對應的對話流。對話流導入后是未發布狀態,需要進入對話流之后測試發布。

# 五、 高級設置
## 5.1 視角
項目實際實施過程中,針對不同的渠道,我們可能會有不同的處理方案,比如在釘釘上給的答案和在 WEB 上給的答案不一致的情況,我們通過視角來對不同渠道的咨詢進行答案的區 分,這樣從不同的視角咨詢過來后,就可以給他吐當前渠道的答案,以此區分。前端調用的時候,可以根據不同視角的參數來區分。
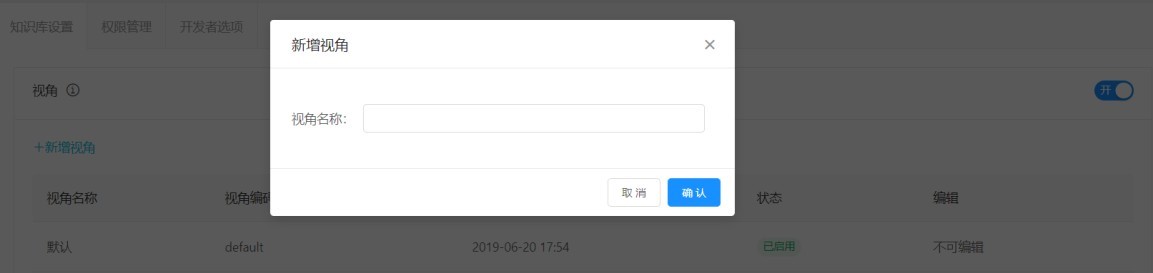
A.創建視角:點擊高級設置-視角-新增視角,創建視角名稱,點擊確認:
B. 編輯視角:點擊新增視角下的編輯,可以對當前意圖進行更名、關閉等操作。關閉后該視角不可調用。
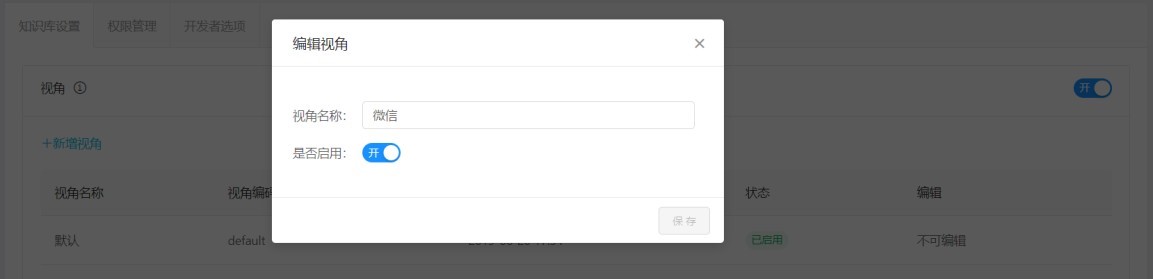
所有已經創建的視角可以在維護 FAQ 的時候對當前創建的視角進行創建。
# 六、 數據洞察
## 6.1 接待概況
我們可以對某個機器人的接待情況進行數據監控梳理。我們可以搜索、點選某個機器人,選 擇某個時間段(可以點選時間,如昨天、前天、近 7 天等),還可以直接選某段時間。
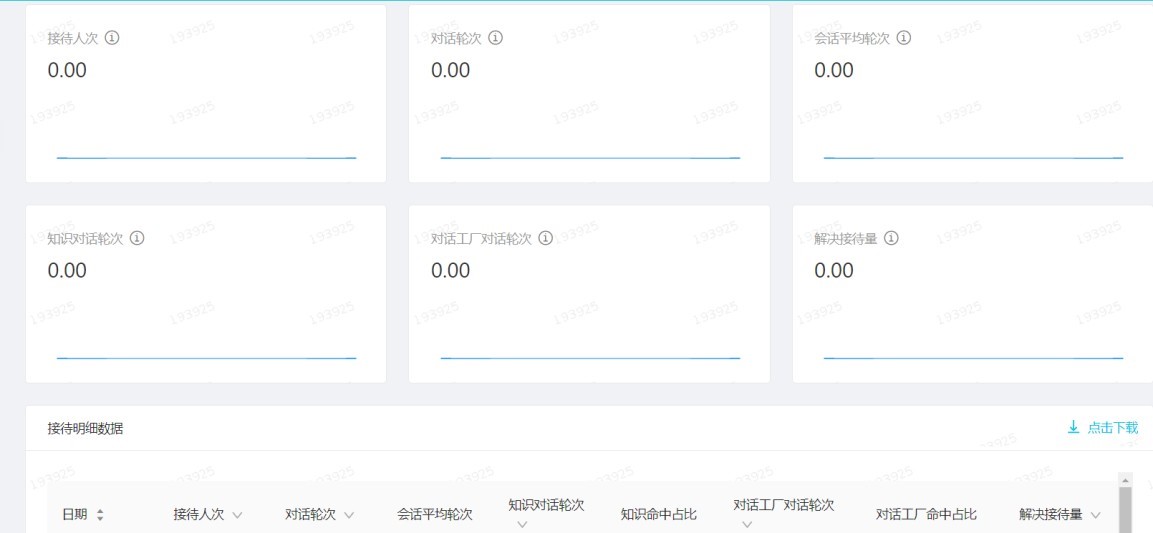
我們可以看某個數據的趨勢,還可以直接把數據列表下載下來。
接待人次:按 session 量計算
對話輪次:用戶發出一次對話,記為一個對話輪次
會話平均輪次:對話輪次/接待人次
知識對話輪次:直接命中知識的對話輪次
對話工廠對話輪次:觸發對話工廠的對話輪次
解決接待量:排除轉人工(如有)、無答案、最后一次推薦未點擊、點踩(如有)的服務 session量(接待人次)
上述指標主要是業務的量的指標,可以看看機器人承載了多少業務量。
## 6.2知識分析
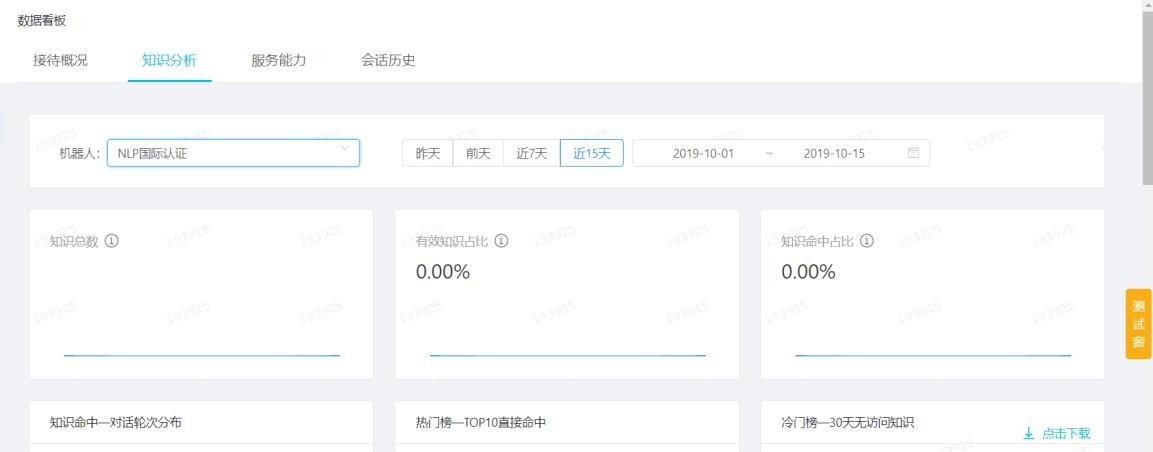
該數據主要對整體的知識進行分析,通過知識數量、有效知識占比、命中占比等數據,來看我們數據維護的粒度、廣度是否合適。
我們可以下載知識明細,看下整體知識的運行情況。
## 6.3服務能力
服務能力主要是考察無答案率、推薦未點擊率的識別效果。可以選擇某個時段 ,看這個時段的無答案率。無答案率、推薦未點擊率越高,整體的機器人的服務能力越差。我們可以根據無答案聚類、推薦未點擊聚類等結果,進行結果的優化。
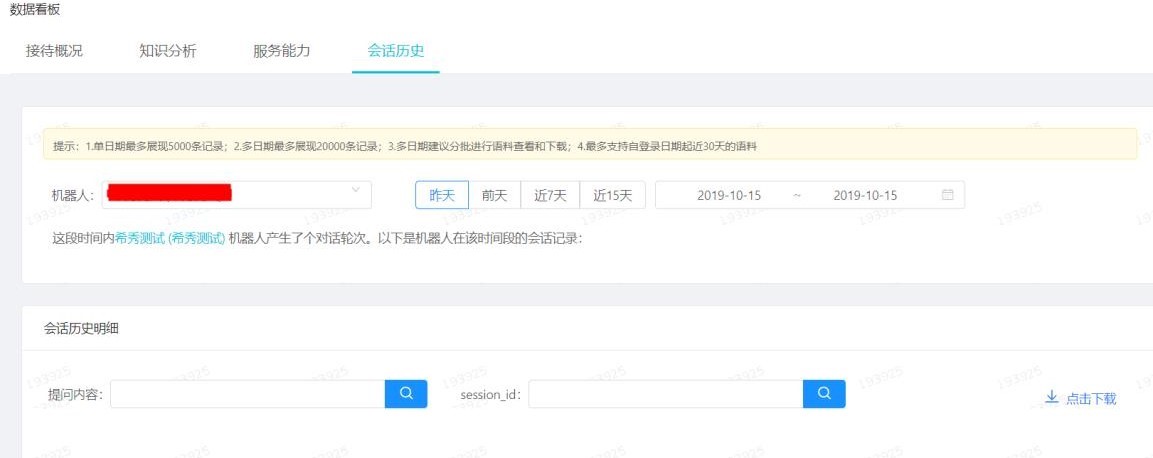
## 6.4 會話歷史
整體的會話歷史可以在此下載,我們可以對下載的數據進行標注、聚類、分析,提升整體機器人的表現。