
## 疑問
數據存儲在硬盤,InnoDB如何高效讀寫?
頁 + 行格式
數據存儲在硬盤如何高效的利用空間?
行格式
## InnoDB頁簡介
InnoDB需要把數據存儲到硬盤(持久性),但是真正處理數據的過程是發生在內存中的(內存速度快)。所以需要把磁盤中的數據加載到內存中,如果是處理寫入或修改請求的話,還需要把內存中的內容刷新到磁盤上。磁盤的速度非常慢,和內存讀寫差了幾個數量級,所以當我們想從表中獲取某些記錄時,`InnoDB`存儲引擎不能一條一條的把去磁盤讀取記錄,需要更高效的方式。
`InnoDB`采取的方式是:將數據分為若干頁,以 **頁** 作為磁盤和內存之間交互的最小單位。InnoDB中頁的大小一般為 16 KB。也就是一次最少從磁盤中讀取16KB的內容到內存中,一次最少把內存中的16KB內容刷新到磁盤中。
## InnoDB行格式
我們平時是以記錄為單位來向表中插入數據的,這些記錄在磁盤上的存放方式也被稱為`行格式`或者`記錄格式`。設計`InnoDB`存儲引擎的大叔們到現在為止設計了4種不同類型的`行格式`,分別是`Compact`、`Redundant`、`Dynamic`和`Compressed`行格式,隨著時間的推移,他們可能會設計出更多的行格式,但是不管怎么變,在原理上大體都是相同的。
Compact 行格式是MySQL5.1后的默認格式。但在 MySQL 5.7.9 及以后版本,默認行格式是innodb_default_row_format變量決定,**默認值是 Dynamic**
### 指定行格式的語法
我們可以在創建或修改表的語句中指定`行格式`:
```
CREATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名稱
ALTER TABLE 表名 ROW_FORMAT=行格式名稱
```
### COMPACT行格式
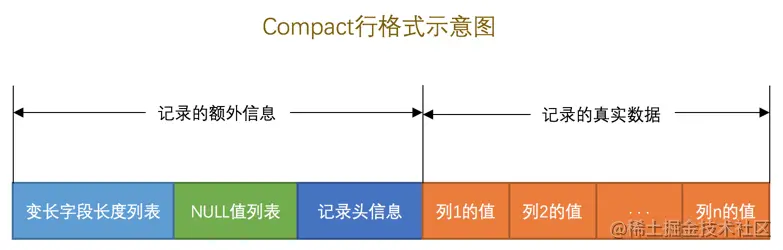
一條完整的記錄其實可以被分為記錄的額外信息和記錄的真實數據兩大部分
#### 記錄的額外信息
這部分信息是服務器為了描述這條記錄而不得不額外添加的一些信息,這些額外信息分為3類,分別是**變長字段長度列表、NULL值列表和記錄頭信息**。
##### 變長字段長度列表
變長字段占用的存儲空間分為兩部分:
1. 真正的數據內容
2. 占用的字節數
在`Compact`行格式中,所有的變長字段數據占用的字節長度都放在記錄的開頭部位, 形成一個變長字段長度列表, 各變長字段數據占用的字節數按照列的順序**逆序存放**。變長字段長度列表中只存儲值為 非NULL 的列內容占用的長度,值為 NULL 的列的長度是不儲存的 。
對于***CHAR(M)***類型的列來說,當列采用的是定長字符集時,該列占用的字節數不會被加到變長字段長度列表,而如果采用變長字符集時,該列占用的字節數也會被加到變長字段長度列表。
### 行溢出數據
#### VARCHAR(M)最多能存儲的數據
`VARCHAR(M)`類型的列最多可以占用`65535`個字節。其中的`M`代表該類型最多存儲的字符數量,`MySQL`對一條記錄占用的最大存儲空間是有限制的,除了`BLOB`或者`TEXT`類型的列之外,**其他所有的列(不包括隱藏列和記錄頭信息)占用的字節長度加起來不能超過`65535`個字節。**
存儲一個`VARCHAR(M)`類型的列,其實需要占用3部分存儲空間:
* 真實數據
* 真實數據占用字節的長度
* `NULL`值標識,如果該列有`NOT NULL`屬性則可以沒有這部分存儲空間
如果該`VARCHAR`類型的列沒有`NOT NULL`屬性,那最多只能存儲`65532`個字節的數據, 有則存儲`65533`個字節的數據。
utf8字符集表示一個字符最多需要3個字節,那在該字符集下,M的最大取值就是21844(也就是:65532/3)個字符。
`MySQL`是以`頁`為基本單位來管理存儲空間的,頁能存儲16kb數據,也就是`16384`字節,而一個`VARCHAR(M)`類型的列就最多可以存儲`65532`個字節,這樣就可能造成一個頁存放不了一條記錄的尷尬情況。這種就會在`記錄的真實數據`處只會存儲該列的一部分數據,把剩余的數據分散存儲在幾個其他的頁中,然后`記錄的真實數據`處用20個字節存儲指向這些頁的地址。
### Dynamic和Compressed行格式
如果某一列中的數據非常多的話,在本記錄的真實數據處只會存儲該列的前`768`個字節的數據和一個指向其他頁的地址,然后把剩下的數據存放到其他頁中,這個過程也叫做`行溢出`,存儲超出`768`字節的那些頁面也被稱為`溢出頁`。
`Dynamic`和`Compressed`行格式,我現在使用的`MySQL`版本是`5.7`,它的默認行格式就是`Dynamic`,這倆行格式和`Compact`行格式挺像,只不過在處理`行溢出`數據時有點兒分歧,它們不會在記錄的真實數據處存儲字段真實數據的前`768`個字節,而是把所有的字節都存儲到其他頁面中,只在記錄的真實數據處存儲其他頁面的地址
`Compressed`行格式和`Dynamic`不同的一點是,`Compressed`行格式會采用壓縮算法對頁面進行壓縮,以節省空間。
## InnoDB數據頁結構
| 名稱 | 中文名 | 占用空間大小 | 簡單描述 |
| :-: | :-: | :-: | :-: |
| `File Header` | 文件頭部 | `38`字節 | 頁的一些通用信息 |
| `Page Header` | 頁面頭部 | `56`字節 | 數據頁專有的一些信息 |
| `Infimum + Supremum` | 最小記錄和最大記錄 | `26`字節 | 兩個虛擬的行記錄 |
| `User Records` | 用戶記錄 | 不確定 | 實際存儲的行記錄內容 |
| `Free Space` | 空閑空間 | 不確定 | 頁中尚未使用的空間 |
| `Page Directory` | 頁面目錄 | 不確定 | 頁中的某些記錄的相對位置 |
| `File Trailer` | 文件尾部 | `8`字節 | 校驗頁是否完整 |
## 記錄在頁中的存儲
一開始生成頁的時候,其實并沒有`User Records`這個部分,每當我們插入一條記錄,都會從`Free Space`部分,也就是尚未使用的存儲空間中申請一個記錄大小的空間劃分到`User Records`部分,當`Free Space`部分的空間全部被`User Records`部分替代掉之后,也就意味著這個頁使用完了,如果還有新的記錄插入的話,就需要去申請新的頁了。
### 記錄頭信息
| 名稱 | 大小(單位:bit) | 描述 |
| :-: | :-: | :-: |
| `預留位1` | `1` | 沒有使用 |
| `預留位2` | `1` | 沒有使用 |
| `delete_mask` | `1` | 標記該記錄是否被刪除 |
| `min_rec_mask` | `1` | B+樹的每層非葉子節點中的最小記錄都會添加該標記 |
| `n_owned` | `4` | 表示當前記錄擁有的記錄數 |
| `heap_no` | `13` | 表示當前記錄在記錄堆的位置信息 |
| `record_type` | `3` | 表示當前記錄的類型,`0`表示普通記錄,`1`表示B+樹非葉節點記錄(目錄項記錄),`2`表示最小記錄,`3`表示最大記錄 |
| `next_record` | `16` | 表示下一條記錄的相對位置 |
* delete_mask
這個屬性標記著當前記錄是否被刪除,占用1個二進制位,值為`0`的時候代表記錄并沒有被刪除,為`1`的時候代表記錄被刪除掉了。這些被刪除的記錄之所以不立即從磁盤上移除,是因為移除它們之后把其他的記錄在磁盤上重新排列需要性能消耗,所以只是打一個刪除標記而已,所有被刪除掉的記錄都會組成一個所謂的垃圾鏈表,在這個鏈表中的記錄占用的空間稱之為所謂的可重用空間,之后如果有新記錄插入到表中的話,可能把這些被刪除的記錄占用的存儲空間覆蓋掉。
* min_rec_mask
B+樹的每層非葉子節點中的最小記錄都會添加該標記
* n_owned
這個分組中的記錄數
* heap_no
這個屬性表示當前記錄在本頁中的位置,值從 2 開始, 0和1分別被自動插入的最小記錄和最大記錄占用了,也就是 Infimum + Supremum 的部分
* record_type
當前記錄的類型,一共有4種類型的記錄,`0`表示普通記錄,`1`表示B+樹非葉節點記錄,`2`表示最小記錄,`3`表示最大記錄。
* next_record
非常重要,它表示從當前記錄的真實數據到下一條記錄的真實數據的地址偏移量
## Page Directory(頁目錄)
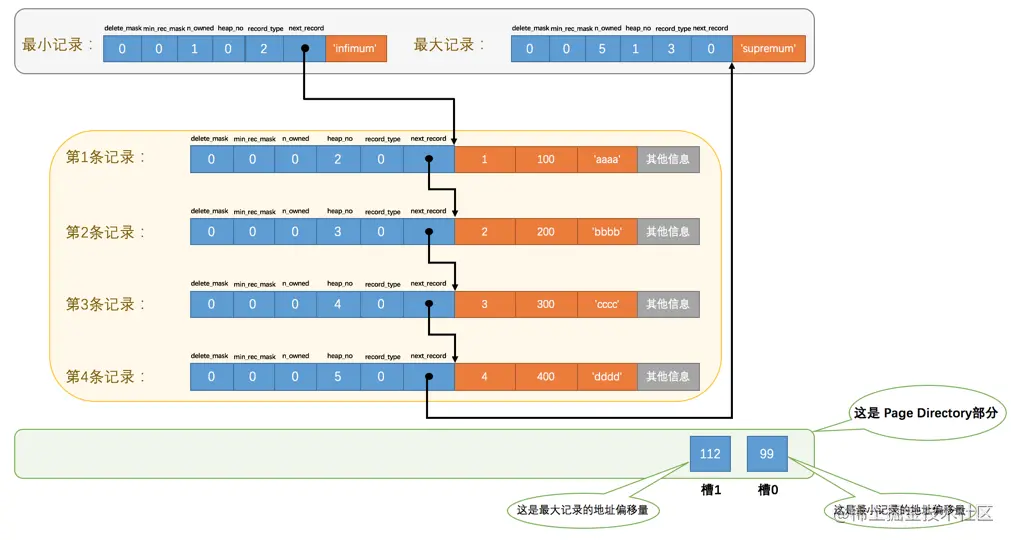
從這個圖中我們需要注意這么幾點:
* 現在`頁目錄`部分中有兩個槽,也就意味著我們的記錄被分成了兩個組,`槽1`中的值是`112`,代表最大記錄的地址偏移量(就是從頁面的0字節開始數,數112個字節);`槽0`中的值是`99`,代表最小記錄的地址偏移量。
* 注意最小和最大記錄的頭信息中的`n_owned`屬性
* 最小記錄的`n_owned`值為`1`,這就代表著以最小記錄結尾的這個分組中只有`1`條記錄,也就是最小記錄本身。
* 最大記錄的`n_owned`值為`5`,這就代表著以最大記錄結尾的這個分組中只有`5`條記錄,包括最大記錄本身還有我們自己插入的`4`條記錄。
每個分組中的記錄條數是有規定的:對于最小記錄所在的分組只能有***1***條記錄,最大記錄所在的分組擁有的記錄條數只能在***1~8***條之間,剩下的分組中記錄的條數范圍只能在是***4~8***條之間。
## Page Header(頁面頭部)
比如本頁中已經存儲了多少條記錄,第一條記錄的地址是什么,頁目錄中存儲了多少個槽等等
| 名稱 | 占用空間大小 | 描述 |
| :-: | :-: | :-: |
| `PAGE_N_DIR_SLOTS` | `2`字節 | 在頁目錄中的槽數量 |
| `PAGE_HEAP_TOP` | `2`字節 | 還未使用的空間最小地址,也就是說從該地址之后就是`Free Space` |
| `PAGE_N_HEAP` | `2`字節 | 本頁中的記錄的數量(包括最小和最大記錄以及標記為刪除的記錄) |
| `PAGE_FREE` | `2`字節 | 第一個已經標記為刪除的記錄地址(各個已刪除的記錄通過`next_record`也會組成一個單鏈表,這個單鏈表中的記錄可以被重新利用) |
| `PAGE_GARBAGE` | `2`字節 | 已刪除記錄占用的字節數 |
| `PAGE_LAST_INSERT` | `2`字節 | 最后插入記錄的位置 |
| `PAGE_DIRECTION` | `2`字節 | 記錄插入的方向 |
| `PAGE_N_DIRECTION` | `2`字節 | 一個方向連續插入的記錄數量 |
| `PAGE_N_RECS` | `2`字節 | 該頁中記錄的數量(不包括最小和最大記錄以及被標記為刪除的記錄) |
| `PAGE_MAX_TRX_ID` | `8`字節 | 修改當前頁的最大事務ID,該值僅在二級索引中定義 |
| `PAGE_LEVEL` | `2`字節 | 當前頁在B+樹中所處的層級 |
| `PAGE_INDEX_ID` | `8`字節 | 索引ID,表示當前頁屬于哪個索引 |
| `PAGE_BTR_SEG_LEAF` | `10`字節 | B+樹葉子段的頭部信息,僅在B+樹的Root頁定義 |
| `PAGE_BTR_SEG_TOP` | `10`字節 | B+樹非葉子段的頭部信息,僅在B+樹的Root頁定義 |
* `PAGE_DIRECTION`
假如新插入的一條記錄的主鍵值比上一條記錄的主鍵值大,我們說這條記錄的插入方向是右邊,反之則是左邊。用來表示最后一條記錄插入方向的狀態就是`PAGE_DIRECTION`。
* `PAGE_N_DIRECTION`
假設連續幾次插入新記錄的方向都是一致的,`InnoDB`會把沿著同一個方向插入記錄的條數記下來,這個條數就用`PAGE_N_DIRECTION`這個狀態表示。當然,如果最后一條記錄的插入方向改變了的話,這個狀態的值會被清零重新統計。
## File Header(文件頭部)
`File Header`針對各種類型的頁都通用,也就是說不同類型的頁都會以`File Header`作為第一個組成部分,它描述了一些針對各種頁都通用的一些信息,比方說這個頁的編號是多少,它的上一個頁、下一個頁是誰
| 名稱 | 占用空間大小 | 描述 |
| :-: | :-: | :-: |
| `FIL_PAGE_SPACE_OR_CHKSUM` | `4`字節 | 頁的校驗和(checksum值) |
| `FIL_PAGE_OFFSET` | `4`字節 | 頁號 |
| `FIL_PAGE_PREV` | `4`字節 | 上一個頁的頁號 |
| `FIL_PAGE_NEXT` | `4`字節 | 下一個頁的頁號 |
| `FIL_PAGE_LSN` | `8`字節 | 頁面被最后修改時對應的日志序列位置(英文名是:Log Sequence Number) |
| `FIL_PAGE_TYPE` | `2`字節 | 該頁的類型 |
| `FIL_PAGE_FILE_FLUSH_LSN` | `8`字節 | 僅在系統表空間的一個頁中定義,代表文件至少被刷新到了對應的LSN值 |
| `FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID` | `4`字節 | 頁屬于哪個表空間 |
* `FIL_PAGE_SPACE_OR_CHKSUM`
這個代表當前頁面的校驗和(checksum)。啥是個校驗和?就是對于一個很長很長的字節串來說,我們會通過某種算法來計算一個比較短的值來代表這個很長的字節串,這個比較短的值就稱為`校驗和`。這樣在比較兩個很長的字節串之前先比較這兩個長字節串的校驗和,如果校驗和都不一樣兩個長字節串肯定是不同的,所以省去了直接比較兩個比較長的字節串的時間損耗。
* `FIL_PAGE_OFFSET`
每一個`頁`都有一個單獨的頁號,就跟你的身份證號碼一樣,`InnoDB`通過頁號來可以唯一定位一個`頁`。
* `FIL_PAGE_TYPE`
這個代表當前`頁`的類型,我們前邊說過,`InnoDB`為了不同的目的而把頁分為不同的類型,我們上邊介紹的其實都是存儲記錄的`數據頁`,其實還有很多別的類型的頁
| 類型名稱 | 十六進制 | 描述 |
| :-: | :-: | :-: |
| `FIL_PAGE_TYPE_ALLOCATED` | 0x0000 | 最新分配,還沒使用 |
| `FIL_PAGE_UNDO_LOG` | 0x0002 | Undo日志頁 |
| `FIL_PAGE_INODE` | 0x0003 | 段信息節點 |
| `FIL_PAGE_IBUF_FREE_LIST` | 0x0004 | Insert Buffer空閑列表 |
| `FIL_PAGE_IBUF_BITMAP` | 0x0005 | Insert Buffer位圖 |
| `FIL_PAGE_TYPE_SYS` | 0x0006 | 系統頁 |
| `FIL_PAGE_TYPE_TRX_SYS` | 0x0007 | 事務系統數據 |
| `FIL_PAGE_TYPE_FSP_HDR` | 0x0008 | 表空間頭部信息 |
| `FIL_PAGE_TYPE_XDES` | 0x0009 | 擴展描述頁 |
| `FIL_PAGE_TYPE_BLOB` | 0x000A | 溢出頁 |
| `FIL_PAGE_INDEX` | 0x45BF | 索引頁,也就是我們所說的`數據頁` |
我們存放記錄的數據頁的類型其實是`FIL_PAGE_INDEX`,也就是所謂的`索引頁`。
* `FIL_PAGE_PREV`和`FIL_PAGE_NEXT`
`InnoDB`可能不可以一次性為這么多數據分配一個非常大的存儲空間,如果分散到多個不連續的頁中存儲的話需要把這些頁關聯起來,`FIL_PAGE_PREV`和`FIL_PAGE_NEXT`就分別代表本頁的上一個和下一個頁的頁號。這樣通過建立一個雙向鏈表把許許多多的頁就都串聯起來了,而無需這些頁在物理上真正連著。
## File Trailer
每個頁的尾部都加了一個`File Trailer`部分,這個部分由`8`個字節組成,校驗頁是否完整
* 前4個字節代表頁的校驗和
這個部分是和`File Header`中的校驗和相對應的。每當一個頁面在內存中修改了,在同步之前就要把它的校驗和算出來,因為`File Header`在頁面的前邊,所以校驗和會被首先同步到磁盤,當完全寫完時,校驗和也會被寫到頁的尾部,如果完全同步成功,則頁的首部和尾部的校驗和應該是一致的。二者不同則意味著同步中間出了錯。
* 后4個字節代表頁面被最后修改時對應的日志序列位置(LSN)
這個`File Trailer`與`File Header`類似,都是所有類型的頁通用的。
## 總結
1. InnoDB為了不同的目的而設計了不同類型的頁,我們把用于存放記錄的頁叫做`數據頁`。
2. 一個數據頁可以被大致劃分為7個部分,分別是
* `File Header`,表示頁的一些通用信息,占固定的38字節。
* `Page Header`,表示數據頁專有的一些信息,占固定的56個字節。
* `Infimum + Supremum`,兩個虛擬的偽記錄,分別表示頁中的最小和最大記錄,占固定的`26`個字節。
* `User Records`:真實存儲我們插入的記錄的部分,大小不固定。
* `Free Space`:頁中尚未使用的部分,大小不確定。
* `Page Directory`:頁中的某些記錄相對位置,也就是各個槽在頁面中的地址偏移量,大小不固定,插入的記錄越多,這個部分占用的空間越多。
* `File Trailer`:用于檢驗頁是否完整的部分,占用固定的8個字節。
3. 每個記錄的頭信息中都有一個`next_record`屬性,從而使頁中的所有記錄串聯成一個`單鏈表`。
4. `InnoDB`會把頁中的記錄劃分為若干個組,每個組的最后一個記錄的地址偏移量作為一個`槽`,存放在`Page Directory`中,所以在一個頁中根據主鍵查找記錄是非常快的,分為兩步:
* 通過二分法確定該記錄所在的槽。
* 通過記錄的next\_record屬性遍歷該槽所在的組中的各個記錄。
5. 每個數據頁的`File Header`部分都有上一個和下一個頁的編號,所以所有的數據頁會組成一個`雙鏈表`。
6. 為保證從內存中同步到磁盤的頁的完整性,在頁的首部和尾部都會存儲頁中數據的校驗和和頁面最后修改時對應的`LSN`值,如果首部和尾部的校驗和和`LSN`值校驗不成功的話,就說明同步過程出現了問題。
- 學習地址
- MySQL
- 查詢優化
- SQL優化
- 關于or、in、not in、!=等走不走索引的說明
- 千萬級數據查詢優化
- MySQL 深度分頁問題
- 嵌套循環 Block Nested Loop 導致索引查詢慢
- MySQL增加日志統計表優化各種日志表的統計功能
- MySQL單機讀寫QPS(性能)優化
- sqlMode 置 select 的值可以比 group 里的多
- drop、delete、truncate的區別
- 尚硅谷MySQL數據庫高級學習筆記
- MySQL架構
- 事務部分
- MySQL知識點
- mysql索引
- Linux docker安裝 mysql 8.0.25
- docker 安裝mysql 5.7
- mysql Field ‘xxx’ doesn’t have a default value
- mysql多實例
- docker中的sql文件導入
- mysql進階知識
- mysql字符集
- 連接的原理
- redo日志
- InnoDB存儲引擎
- InnoDB的數據存儲結構
- B+樹索引
- 文件系統-表空間
- Buffer Pool
- 億級數據導入到es
- MySQL數據復制
- MySQL缺少主鍵的表數據
- mysql update 其中更新的字段根據另一個更新字段作為條件去更新
- MySQL指定字段值排序(將指定值排在前面)
- 設置MySQL連接數、時區
- Navicat15右鍵刪除數據刷新就又恢復了
- MySQL替換字段部分內容
- Java和MySQL統計本周本月本季和年
- 分頁時order by 排序數據重復,丟失
- mysql同一張表根據某個字段刪除重復數據
- mysqldump定時全量熱備
- 專題總結
- 事務
- MySQL事務
- spring事務
- spring事務本類調用
- spring事務傳播行為
- spring事務失效問題
- 鎖和Transactional注解一塊使用的問題
- 數據安全
- 敏感數據
- SQL注入
- 數據源
- XSS
- 接口設計
- 緩存設計
- 限流
- 自定義注解實現根據用戶做QPS限流
- 架構
- 高可用
- Java
- Unsatisfied dependency expressed through field ‘baseMapper‘
- mybatisplus多數據源
- 單個字母前綴的java變量
- spring
- spring循環依賴解決
- 事務@Transactional
- yml 文件配置信息綁定到java工具類的靜態變量上
- @Configuration @Component 區別
- springboot啟動yml文件報錯
- spring方法重試注解Retryable
- spring讀取yml集合數據
- spring自定義注解
- 獲取resource下的圖片資源
- 手機號和電話號的正則驗證
- 獲取字符串中的數字
- mybatis
- mybatis多參數添加數據并返回主鍵
- 統一異常處理
- 分組校驗
- Java讀取Python json.dumps 函數保存的redis數據
- springboot整合springCache
- 若依mybatis值為null的字段沒有返回
- 若依
- 接口白名單
- @JsonFormat時區問題
- RequestParam.value() was empty on parameter 0
- jdk8和hutool請求第三方的https報錯
- springMVC
- springMVC與vue使用post傳數組
- elementUI 時間組件報錯問題
- vue具名插槽slot
- springboot配置maven的profiles(配置微服務多環境切換打包)
- resources 配置文件讀取順序
- Windows的cmd部署jar注意事項
- Java基礎
- JUC(鎖-并發-線程池)
- CAS
- Java 鎖簡介
- synchronized和Logk有什么區別?用新的ock有什么好處
- synchronized鎖介紹
- CompletableFuture
- 多線程
- 線程池
- 集合類
- map見過的小問題
- 退出雙層循環
- StringBuilder和StringBuffer核心區別
- 日志打印
- 打印log日志
- log日志文件生成配置
- 日期時間
- 時間戳轉為時間
- 并發工具
- 連接池
- http調用
- 內網訪問天地圖
- 判等問題
- 數值計算
- null問題
- 異常處理
- 文件IO
- 序列化
- 內存溢出OOM
- Double轉String出現E的問題
- springboot接收前端表單提交多字段和上傳文件
- 子線程的錯誤, 全局異常處理捕獲不到
- vue同一個項目訪問多個不同ip地址接口
- Autowired注解導入為null
- shiro
- UnavailableSecurityManagerException錯誤
- Windows服務器80端口被占用
- java圖片增加水印
- springcloud
- Feign方法配置錯誤導致jar包啟動失敗
- feign調用超時
- Springcloud從Nacos的yml文件讀取出錯
- 定時任務quartz
- JavaPOI導出Excel
- 合并行和列
- 設置樣式
- 設置背景色
- docker
- Linux 安裝
- docker命令
- docker網絡
- docker數據卷
- dockerfile
- docker安裝ping命令
- docker-compose
- docker-compose文件內容介紹
- Linux關閉docker開機啟動
- jar打包為鏡像
- 遷移docker容器存儲位置
- Nginx
- Linux在線安裝Nginx
- nginx.conf 核心配置文件
- vue 和 nginx 刷新頁面會報404
- nginx 轉發給三個集群的tomcat
- ServerName匹配規則
- Nginx負載均衡策略
- location 匹配規則
- Nginx 搭建前端調用后臺接口的集群
- alias與root
- nginx 攔截 post 請求, 帶參數轉發到前端頁面
- 防盜鏈配置
- Nginx的緩存
- 通用Nginx配置
- nginx配置文件服務器
- 后臺jar包得不到正確ip,nginx代理時要處理
- 升級使用websocket協議
- 設置IP黑/白名單
- vue項目get請求Nginx返回html頁面post返回405錯誤
- Nginx限制所有接口流量
- Redis
- 緩存數據一致性
- 內存淘汰策略
- Redis數據類型
- gmt6
- Linux安裝GMT6
- GMT6配置中文
- GMT文件修改Windows版本到Linux版本
- 注意GMT不同字體導致符號不同的問題
- GMT繪制南海諸島小圖
- GMT生成中文圖例
- elasticsearch
- 安裝配置
- Linux安裝配置elasticsearch7.6.2
- Linux 安裝 kibana 7.6.2
- 安裝7.6.2中文分詞器
- docker 安裝elasticsearch7.6.2
- 安裝Logback7.6.2
- springboot使用
- 0. elasticsearch賬號密碼模式訪問
- 1. 配置連接
- 2. 索引
- 3. 批量保存更新
- Result window is too large 10000
- elasticsearch 分詞的字段做排序 fielddata, 設置fielddata=true 無效果
- elasticsearch 完全匹配查詢(精確查詢)
- 模糊搜索
- 日期區間查詢
- 6.x基礎知識
- 自定義詞庫
- elasticsearch集群
- 搜索推薦Suggester
- 查詢es保存的數組
- 億級mysql數據導入到es
- es 報錯 ORBIDDEN/12/index read-only
- es核心概念
- es的分布式架構原理
- 優化大數據量時的ES查詢性能
- canal
- 1. mysql的Binlog
- 2. Canal 的工作原理
- 3. canal同步es
- JVM
- 1 類的字節碼
- 2. 類的加載
- JVM知識點
- Maven
- 依賴沖突
- xxl-job
- docker 安裝配置 xxl-job
- idea
- springboot啟動報錯命令過長
- services統一啟動微服務各模塊
- 云服務器安裝寶塔面板
- 突然出現啟動或者運行特別慢
- 有導入依賴但是顯示紅色同時點擊進去也有依賴
- Linux
- sh文件執行報錯: command not found
- 使用vagrant安裝虛擬機
- Linux 開啟端口
- 開放端口
- 復制文件夾及其文件到另一個文件夾
- 兩個服務器之間映射端口
- TCP協議
- 分層模型
- TCP概述
- 支撐 TCP 協議的基石 —— 首部字段
- 數據包大小對網絡的影響 —— MTU 與 MSS 的奧秘
- 端口號
- 三次握手
- TCP 自連接
- 四次揮手
- TCP 頭部時間戳
- 分布式
- 分布式腦裂問題
- 分布式事務
- 基礎知識
- 實現分布式事務的方案
- 阿里分布式事務中間件seata
- 冪等性問題
- 其他工具
- webstorm git提交代碼后project目錄樹不顯示
- 消息隊列
- 如何保證消費的順序
- 數據結構
- 漫畫算法:小灰的算法之旅
- oracle