
## 列表生成式
~~~
a = [i+1 for i in range(10)]
~~~
通過列表生成式,我們可以直接快速的創建一個列表。但是,受到內存限制,列表容量肯定是有限的。而且,創建一個包含100萬個元素的列表,不僅占用很大的存儲空間,如果我們僅僅需要訪問前面幾個元素,那后面絕大多數元素占用的空間都白白浪費了。
所以,如果列表元素可以按照某種算法推算出來,那我們是否可以在循環的過程中不斷推算出后續的元素呢?這樣就可以直接創建一個對象而不必創建完整的list,從而節省大量的空間。在Python中,這種一邊循環一邊計算的機制,稱為生成器:generator。
## 生成器
要創建一個generator,有很多種方法。第一種方法很簡單,只要把一個列表生成式的`[]`改成`()`,就創建了一個generator:

我們可以直接打印出list的每一個元素,但我們怎么打印出generator的每一個元素呢?如果要一個一個打印出來,可以通過`next()`函數獲得generator的下一個返回值:
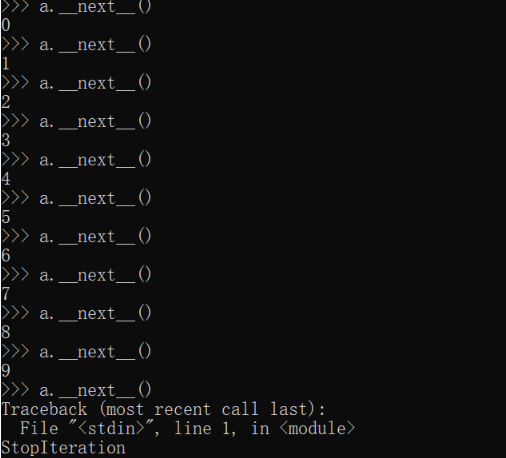
我們講過,generator保存的是算法,每次調用`next()`,就計算出a的下一個元素的值,直到計算到最后一個元素,沒有更多的元素時,拋出`StopIteration`的錯誤。
當然,也使用`for`循環,因為generator也是可迭代對象:
generator非常強大。如果推算的算法比較復雜,用類似列表生成式的`for`循環無法實現的時候,還可以用函數來實現。比如,著名的斐波拉契數列(Fibonacci),除第一個和第二個數外,任意一個數都可由前兩個數相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契數列用列表生成式寫不出來,但是,用函數把它打印出來卻很容易:
~~~
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
~~~
~~~
>>> fib(10)
1
1
2
3
5
8
13
21
34
55
done
~~~
仔細觀察,可以看出,`fib`函數實際上是定義了斐波拉契數列的推算規則,可以從第一個元素開始,推算出后續任意的元素,這種邏輯其實非常類似generator。
也就是說,上面的函數和generator僅一步之遙。要把`fib`函數變成generator,只需要把`print(b)`改為`yield b`就可以了:
~~~
def fib(max):
n,a,b = 0,0,1
while n < max:
yield b
a,b = b,a+b
n += 1
return 'done'
~~~
~~~
>>> f = fib(6)
>>> f
<generator object fib at 0x104feaaa0>
~~~
這就是定義generator的另一種方法。如果一個函數定義中包含`yield`關鍵字,那么這個函數就不再是一個普通函數,而是一個generator。這里,最難理解的就是generator和函數的執行流程不一樣。函數是順序執行,遇到`return`語句或者最后一行函數語句就返回。而變成generator的函數,在每次調用`next()`的時候執行,遇到`yield`語句返回,再次執行時從上次返回的`yield`語句處繼續執行。同樣的我們也可以用`next()方法`來獲取下一個返回值,或者也可以直接使用`for`循環來迭代。
PS:用`for`循環調用generator時,拿不到generator的`return`語句的返回值。如果想要拿到返回值,必須捕獲`StopIteration`錯誤,返回值會包含在`StopIteration`的`value`中:
~~~
>>> g = fib(6)
>>> while True:
... try:
... x = next(g)
... print('g:', x)
... except StopIteration as e:
... print('Generator return value:', e.value)
... break
...
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done
~~~
## 可迭代對象
我們已經知道,可以直接作用于`for`循環的數據類型有以下幾種:
一類是集合數據類型,如`list`、`tuple`、`dict`、`set`、`str`等;
一類是`generator`,包括生成器和帶`yield`的generator function。
這些可以直接作用于`for`循環的對象統稱為可迭代對象:`Iterable`。可以使用`isinstance()`判斷一個對象是否是`Iterable`對象:
~~~
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
~~~
而生成器不但可以作用于`for`循環,還可以被`next()`函數不斷調用并返回下一個值,直到最后拋出`StopIteration`錯誤表示無法繼續返回下一個值了。
**所以,可以被`next()`函數調用并不斷返回下一個值的對象稱為迭代器:`Iterator`**。
## 迭代器
迭代器是訪問集合元素的一種方式。迭代器對象從集合的第一個元素開始訪問,直到所有的元素被訪問完結束。迭代器只能往前不會后退,不過這也沒什么,因為人們很少在迭代途中往后退。另外,迭代器的一大優點是不要求事先準備好整個迭代過程中所有的元素。迭代器僅僅在迭代到某個元素時才計算該元素,而在這之前或之后,元素可以不存在或者被銷毀。這個特點使得它特別適合用于遍歷一些巨大的或是無限的集合,比如幾個G的文件
特點:
1. 訪問者不需要關心迭代器內部的結構,僅需通過next()方法不斷去取下一個內容
2. 不能隨機訪問集合中的某個值 ,只能從頭到尾依次訪問
3. 訪問到一半時不能往回退
4. 便于循環比較大的數據集合,節省內存
可以使用`isinstance()`判斷一個對象是否是`Iterator`對象:
~~~
>>> from collections import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True
>>> isinstance([], Iterator)
False
>>> isinstance({}, Iterator)
False
>>> isinstance('abc', Iterator)
False
~~~
生成器都是`Iterator`對象,但`list`、`dict`、`str`雖然是`Iterable`,卻不是`Iterator`。
把`list`、`dict`、`str`等`Iterable`變成`Iterator`可以使用`iter()`函數:
~~~
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True
~~~
你可能會問,為什么`list`、`dict`、`str`等數據類型不是`Iterator`?
這是因為Python的`Iterator`對象表示的是一個數據流,Iterator對象可以被`next()`函數調用并不斷返回下一個數據,直到沒有數據時拋出`StopIteration`錯誤。可以把這個數據流看做是一個有序序列,但我們卻不能提前知道序列的長度,只能不斷通過`next()`函數實現按需計算下一個數據,所以`Iterator`的計算是惰性的,只有在需要返回下一個數據時它才會計算。
`Iterator`甚至可以表示一個無限大的數據流,例如全體自然數。而使用list是永遠不可能存儲全體自然數的。
## 小結

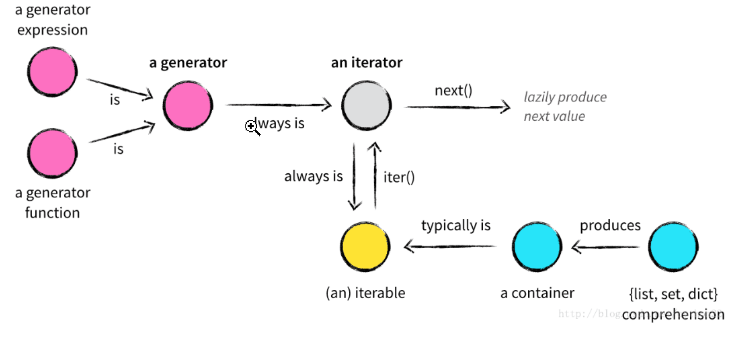
* 凡是可作用于`for`循環的對象都是`Iterable`類型;
* 凡是可作用于`next()`函數的對象都是`Iterator`類型;
* 迭代器對象一定是可迭代對象,但是可迭代對象不一定是迭代器對象;
* 生成器對象一定是迭代器對象,但是迭代器對象不一定是生成器對象;
* 集合數據類型如`list`、`dict`、`str`等是`Iterable`但不是`Iterator`,不過可以通過`iter()`函數獲得一個`Iterator`對象;
- Python學習
- Python基礎
- Python初識
- 列表生成式,生成器,可迭代對象,迭代器詳解
- Python面向對象
- Python中的單例模式
- Python變量作用域、LEGB、閉包
- Python異常處理
- Python操作正則
- Python中的賦值與深淺拷貝
- Python自定義CLI三方庫
- Python并發編程
- Python之進程
- Python之線程
- Python之協程
- Python并發編程與IO模型
- Python網絡編程
- Python之socket網絡編程
- Django學習
- 反向解析
- Cookie和Session操作
- 文件上傳
- 緩存的配置和使用
- 信號
- FBV&&CBV&&中間件
- Django補充
- 用戶認證
- 分頁
- 自定義搜索組件
- Celery
- 搭建sentry平臺監控
- DRF學習
- drf概述
- Flask學習
- 項目拆分
- 三方模塊使用
- 爬蟲學習
- Http和Https區別
- 請求相關庫
- 解析相關庫
- 常見面試題
- 面試題
- 面試題解析
- 網絡原理
- 計算機網絡知識簡單介紹
- 詳解TCP三次握手、四次揮手及11種狀態
- 消息隊列和數據庫
- 消息隊列之RabbitMQ
- 數據庫之Redis
- 數據庫之初識MySQL
- 數據庫之MySQL進階
- 數據庫之MySQL補充
- 數據庫之Python操作MySQL
- Kafka常用命令
- Linux學習
- Linux基礎命令
- Git
- Git介紹
- Git基本配置及理論
- Git常用命令
- Docker
- Docker基本使用
- Docker常用命令
- Docker容器數據卷
- Dockerfile
- Docker網絡原理
- docker-compose
- Docker Swarm
- HTML
- CSS
- JS
- VUE