
## NoSQL簡單介紹
? NoSQL(NoSQL = Not Only SQL ),意即“不僅僅是SQL”,泛指非關系型的數據庫,隨著互聯網web2.0網站的興起,傳統的關系數據庫在應付web2.0網站,特別是超大規模和高并發的SNS類型的web2.0純動態網站已經顯得力不從心,暴露了很多難以克服的問題,而非關系型的數據庫則由于其本身的特點得到了非常迅速的發展。NoSQL數據庫的產生就是為了解決大規模數據集合多重數據種類帶來的挑戰,尤其是大數據應用難題。
## NoSQL數據庫的四大分類
| 分類 | Examples舉例 | 典型應用場景 | 數據模型 | 優點 | 缺點 |
| --- | --- | --- | --- | --- | --- |
| 鍵值(key-value)\[3\]? | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 內容緩存,主要用于處理大量數據的高訪問負載,也用于一些日志系統等等。\[3\]? | Key 指向 Value 的鍵值對,通常用hash table來實現\[3\]? | 查找速度快 | 數據無結構化,通常只被當作字符串或者二進制數據\[3\]? |
| 列存儲數據庫\[3\]? | Cassandra, HBase, Riak | 分布式的文件系統 | 以列簇式存儲,將同一列數據存在一起 | 查找速度快,可擴展性強,更容易進行分布式擴展 | 功能相對局限 |
| 文檔型數據庫\[3\]? | CouchDB, MongoDb | Web應用(與Key-Value類似,Value是結構化的,不同的是數據庫能夠了解Value的內容) | Key-Value對應的鍵值對,Value為結構化數據 | 數據結構要求不嚴格,表結構可變,不需要像關系型數據庫一樣需要預先定義表結構 | 查詢性能不高,而且缺乏統一的查詢語法。 |
| 圖形(Graph)數據庫\[3\]? | Neo4J, InfoGrid, Infinite Graph | 社交網絡,推薦系統等。專注于構建關系圖譜 | 圖結構 | 利用圖結構相關算法。比如最短路徑尋址,N度關系查找等 | 很多時候需要對整個圖做計算才能得出需要的信息,而且這種結構不太好做分布式的集群方案。
|
## Redis簡單介紹
redis是業界主流的key-value nosql 數據庫之一。和Memcached類似,它支持存儲的value類型相對更多,包括string(字符串)、list(列表)、set(集合)、zset(sorted set --有序集合)和hash(哈希類型)。這些數據類型都支持push/pop、add/remove及取交集并集和差集及更豐富的操作,而且這些操作都是原子性的。在此基礎上,redis支持各種不同方式的排序。與memcached一樣,為了保證效率,數據都是緩存在內存中。區別的是redis會周期性的把更新的數據寫入磁盤或者把修改操作寫入追加的記錄文件,并且在此基礎上實現了master-slave(主從)同步。
### Redis優點
* 異常快速?:?Redis是非常快的,每秒可以執行大約110000設置操作,81000個/每秒的讀取操作。
* 支持豐富的數據類型?:?Redis支持最大多數開發人員已經知道如列表,集合,可排序集合,哈希等數據類型。
這使得在應用中很容易解決的各種問題,因為我們知道哪些問題處理使用哪種數據類型更好解決。
* 操作都是原子的?:?所有?Redis?的操作都是原子,從而確保當兩個客戶同時訪問?Redis?服務器得到的是更新后的值(最新值)。
* MultiUtility工具:Redis是一個多功能實用工具,可以在很多如:緩存,消息傳遞隊列中使用(Redis原生支持發布/訂閱),在應用程序中,如:Web應用程序會話,網站頁面點擊數等任何短暫的數據。
## Python操作Redis
### 1、操作模式
redis-py提供兩個類Redis和StrictRedis用于實現Redis的命令,StrictRedis用于實現大部分官方的命令,并使用官方的語法和命令,Redis是StrictRedis的子類,用于向后兼容舊版本的redis-py。
~~~
import redis
r = redis.Redis(host='localhost',port=6379)
r.set('name','wusir')
print(r.get('name'))
~~~
### 2、連接池
redis-py使用connection pool來管理對一個redis server的所有連接,避免每次建立、釋放連接的開銷。默認,每個Redis實例都會維護一個自己的連接池。可以直接建立一個連接池,然后作為參數Redis,這樣就可以實現多個Redis實例共享一個連接池。
~~~
import redis
pool = redis.ConnectionPool(host='localhost',port=6379)
r = redis.Redis(connection_pool=pool)
r.set('name2','alex')
print(r.get('name2'))
~~~
## Redis操作
### windows上面安裝服務
~~~
安裝:redis-server --service-install redis.windows.conf
卸載:redis-server --service-uninstall
啟動:redis-server --service-start
停止:redis-server --service-stop
~~~
### 1、String操作
redis中的String在在內存中按照一個name對應一個value來存儲。
set(name, value)
~~~
在Redis中設置值,默認,不存在則創建,存在則修改
~~~
expire key seconds
~~~
給key設置過期時間
~~~
setnx(name, value)
~~~
設置值,只有name不存在時,執行設置操作(添加)
~~~
setex(name, time, value)
~~~
# 設置值
# 參數:
# time,過期時間(數字秒 或 timedelta對象)
~~~
psetex(name, time\_ms, value)
~~~
# 設置值
# 參數:
# time_ms,過期時間(數字毫秒 或 timedelta對象)
~~~
mset(\*args, \*\*kwargs)
~~~
批量設置值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
~~~
get(name)
~~~
獲取值
~~~
mget(keys, \*args)
~~~
批量獲取
~~~
getset(name, value)
~~~
設置新值并獲取原來的值
~~~
getrange(key, start, end)
~~~
# 獲取子序列(根據字節獲取,非字符)
# 參數:
# name,Redis 的 name
# start,起始位置(字節)
# end,結束位置(字節)
# 如: "wusir" ,0-3表示 "wusi"
~~~
setrange(name, offset, value)
~~~
# 修改字符串內容,從指定字符串索引開始向后替換(新值太長時,則向后添加)
# 參數:
# offset,字符串的索引,字節(一個漢字三個字節)
# value,要設置的值
~~~
setbit(name, offset, value)
~~~
# 對name對應值的二進制表示的位進行操作
# 參數:
# name,redis的name
# offset,位的索引(將值變換成二進制后再進行索引)
# value,值只能是 1 或 0
# 注:如果在Redis中有一個對應: n1 = "foo",
那么字符串foo的二進制表示為:01100110 01101111 01101111
所以,如果執行 setbit('n1', 7, 1),則就會將第7位設置為1,
那么最終二進制則變成 01100111 01101111 01101111,即:"goo"
特別的,如果source是漢字,對于utf-8,每一個漢字占 3 個字節,那么 "博客園" 則有 9個字節
對于漢字,for循環時候會按照 字節 迭代,那么在迭代時,將每一個字節轉換 十進制數,然后再將十進制數轉換成二進制
~~~
getbit(name, offset)
~~~
# 獲取name對應的值的二進制表示中的某位的值 (0或1)
~~~
bitcount(key, start=None, end=None)
~~~
# 獲取name對應的值的二進制表示中 1 的個數
# 參數:
# key,Redis的name
# start,位起始位置
# end,位結束位置
~~~
strlen(name)
~~~
# 返回name對應值的字節長度(一個漢字3個字節)
~~~
append(key, value)
~~~
# 在redis name對應的值后面追加內容
# 參數:
key, redis的name
value, 要追加的字符串
~~~
### 2、Hash操作
hash表現形式上有些像pyhton中的dict,可以存儲一組關聯性較強的數據 , redis中Hash在內存中的存儲格式如下圖:
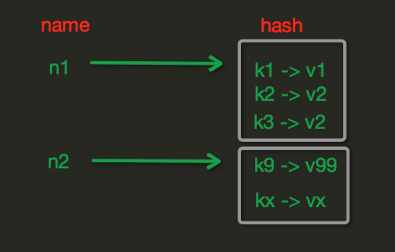
hset(name, key, value)
~~~
# name對應的hash中設置一個鍵值對(不存在,則創建;否則,修改)
# 參數:
# name,redis的name
# key,name對應的hash中的key
# value,name對應的hash中的value
# 注:
# hsetnx(name, key, value),當name對應的hash中不存在當前key時則創建(相當于添加)
~~~
hmset(name, mapping)
~~~
# 在name對應的hash中批量設置鍵值對
# 參數:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
~~~
hget(name,key)
~~~
# 在name對應的hash中獲取根據key獲取value
~~~
hmget(name, keys, \*args)
~~~
# 在name對應的hash中獲取多個key的值
# 參數:
# name,reids對應的name
# keys,要獲取key集合,如:['k1', 'k2', 'k3']
# *args,要獲取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
~~~
hgetall(name)
~~~
獲取name對應hash的所有鍵值
~~~
hlen(name)
~~~
# 獲取name對應的hash中鍵值對的個數
~~~
hkeys(name)
~~~
# 獲取name對應的hash中所有的key的值
~~~
hvals(name)
~~~
# 獲取name對應的hash中所有的value的值
~~~
hdel(name,\*keys)
~~~
# 將name對應的hash中指定key的鍵值對刪除
~~~
### 3、list操作
List操作,redis中的List在在內存中按照一個name對應一個List來存儲。如圖:
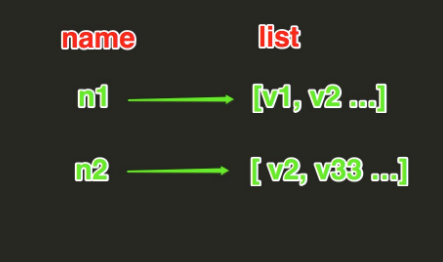
lpush(name,values)
~~~
# 在name對應的list中添加元素,每個新的元素都添加到列表的最左邊
# 如:
# r.lpush('oo', 11,22,33)
# 保存順序為: 33,22,11
# 擴展:
# rpush(name, values) 表示從右向左操作
~~~
llen(name)
~~~
# name對應的list元素的個數
~~~
linsert(name, where, refvalue, value))
~~~
# 在name對應的列表的某一個值前或后插入一個新值
# 參數:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,標桿值,即:在它前后插入數據
# value,要插入的數據
~~~
r.lset(name, index, value)
~~~
# 對name對應的list中的某一個索引位置重新賦值
# 參數:
# name,redis的name
# index,list的索引位置
# value,要設置的值
~~~
r.lrem(name, value, num)
~~~
# 在name對應的list中刪除指定的值
# 參數:
# name,redis的name
# value,要刪除的值
# num, num=0,刪除列表中所有的指定值;
# num=2,從前到后,刪除2個;
# num=-2,從后向前,刪除2個
~~~
lpop(name)
~~~
# 在name對應的列表的左側獲取第一個元素并在列表中移除,返回值則是第一個元素
# 更多:
# rpop(name) 表示從右向左操作
~~~
lindex(name, index)
~~~
在name對應的列表中根據索引獲取列表元素
~~~
lrange(name, start, end)
~~~
# 在name對應的列表分片獲取數據
# 參數:
# name,redis的name
# start,索引的起始位置
# end,索引結束位置
~~~
ltrim(name, start, end)
~~~
# 在name對應的列表中移除沒有在start-end索引之間的值
# 參數:
# name,redis的name
# start,索引的起始位置
# end,索引結束位置
~~~
### 4、set集合操作
Set操作,Set集合就是不允許重復的列表
sadd(name,values)
~~~
# name對應的集合中添加元素
~~~
scard(name)
~~~
獲取name對應的集合中元素個數
~~~
sdiff(keys, \*args)
~~~
在第一個name對應的集合中且不在其他name對應的集合的元素集合
~~~
sinter(keys, \*args)
~~~
# 獲取多一個name對應集合的交集
~~~
?sunion(keys, \*args)
~~~
# 獲取多一個name對應的集合的并集
~~~
有序集合,在集合的基礎上,為每元素排序;元素的排序需要根據另外一個值來進行比較,所以,對于有序集合,每一個元素有兩個值,即:值和分數,分數專門用來做排序。
zadd(name, \*args, \*\*kwargs)
~~~
# 在name對應的有序集合中添加元素
# 如:
# zadd('zz', 'n1', 1, 'n2', 2)
# 或
# zadd('zz', n1=11, n2=22)
~~~
zcard(name)
~~~
# 獲取name對應的有序集合元素的數量
~~~
zcount(name, min, max)
~~~
# 獲取name對應的有序集合中分在 [min,max] 之間的個數
~~~
r.zrange( name, start, end, desc=False, withscores=False, score\_cast\_func=float)
~~~
# 按照索引范圍獲取name對應的有序集合的元素
# 參數:
# name,redis的name
# start,有序集合索引起始位置(非分數)
# end,有序集合索引結束位置(非分數)
# desc,排序規則,默認按照分數從小到大排序
# withscores,是否獲取元素的分數,默認只獲取元素的值
# score_cast_func,對分數進行數據轉換的函數
# 更多:
# 從大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float)
# 按照分數范圍獲取name對應的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 從大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
~~~
zrank(name, value)
~~~
# 獲取某個值在 name對應的有序集合中的排行(從 0 開始)
# 更多:
# zrevrank(name, value),從大到小排序
~~~
**其他常用操作**
del (\*names)
~~~
# 根據刪除redis中的任意數據類型
~~~
exists(name)
~~~
# 檢測redis的name是否存在
~~~
keys(pattern='\*')
~~~
# 根據模型獲取redis的name
# 更多:
# KEYS * 匹配數據庫中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
~~~
rename(src, dst)
~~~
# 對redis的name重命名為
~~~
type(name)
~~~
# 獲取name對應值的類型
~~~
keys \*
~~~
查看當前db下所有的key
~~~
select num? ? 注:num為0-15的數字
~~~
切換到指定的數據庫
~~~
help 指令
~~~
查看該指令的幫助
~~~
- Python學習
- Python基礎
- Python初識
- 列表生成式,生成器,可迭代對象,迭代器詳解
- Python面向對象
- Python中的單例模式
- Python變量作用域、LEGB、閉包
- Python異常處理
- Python操作正則
- Python中的賦值與深淺拷貝
- Python自定義CLI三方庫
- Python并發編程
- Python之進程
- Python之線程
- Python之協程
- Python并發編程與IO模型
- Python網絡編程
- Python之socket網絡編程
- Django學習
- 反向解析
- Cookie和Session操作
- 文件上傳
- 緩存的配置和使用
- 信號
- FBV&&CBV&&中間件
- Django補充
- 用戶認證
- 分頁
- 自定義搜索組件
- Celery
- 搭建sentry平臺監控
- DRF學習
- drf概述
- Flask學習
- 項目拆分
- 三方模塊使用
- 爬蟲學習
- Http和Https區別
- 請求相關庫
- 解析相關庫
- 常見面試題
- 面試題
- 面試題解析
- 網絡原理
- 計算機網絡知識簡單介紹
- 詳解TCP三次握手、四次揮手及11種狀態
- 消息隊列和數據庫
- 消息隊列之RabbitMQ
- 數據庫之Redis
- 數據庫之初識MySQL
- 數據庫之MySQL進階
- 數據庫之MySQL補充
- 數據庫之Python操作MySQL
- Kafka常用命令
- Linux學習
- Linux基礎命令
- Git
- Git介紹
- Git基本配置及理論
- Git常用命令
- Docker
- Docker基本使用
- Docker常用命令
- Docker容器數據卷
- Dockerfile
- Docker網絡原理
- docker-compose
- Docker Swarm
- HTML
- CSS
- JS
- VUE