
## 為什么需要線程
進程有很多優點,它提供了多道編程,讓我們感覺我們每個人都擁有自己的CPU和其他資源,可以提高計算機的利用率。很多人就不理解了,既然進程這么優秀,為什么還要線程呢?其實,仔細觀察就會發現進程還是有很多缺陷的,主要體現在兩點上:
* 進程只能在一個時間干一件事,如果想同時干兩件事或多件事,進程就無能為力了。
* 進程在執行的過程中如果阻塞,例如等待輸入,整個進程就會掛起,即使進程中有些工作不依賴于輸入的數據,也將無法執行。
## 什么是線程
線程,有時被稱為輕量進程(Lightweight Process,LWP),是程序執行流的最小單元,也是操作系統能夠進行運算調度的最小單位。它被包含在進程之中,是進程中的實際運作單位。一條線程指的是進程中一個單一順序的控制流,一個進程中可以并發多個線程,每條線程并行執行不同的任務。
線程與進程的區別:
* 根本區別:進程是操作系統資源分配的基本單位,而線程是任務調度和執行的基本單位
* 在開銷方面:每個進程都有獨立的代碼和數據空間(程序上下文),程序之間的切換會有較大的開銷;線程可以看做輕量級的進程,同一類線程共享代碼和數據空間,每個線程都有自己獨立的運行棧和程序計數器(PC),線程之間切換的開銷小。
* 所處環境:在操作系統中能同時運行多個進程(程序);而在同一個進程(程序)中有多個線程同時執行(通過CPU調度,在每個時間片中只有一個線程執行)
* 內存分配方面:系統在運行的時候會為每個進程分配不同的內存空間;而對線程而言,除了CPU外,系統不會為線程分配內存(線程所使用的資源來自其所屬進程的資源),線程組之間只能共享資源。
* 包含關系:沒有線程的進程可以看做是單線程的,如果一個進程內有多個線程,則執行過程不是一條線的,而是多條線(線程)共同完成的;線程是進程的一部分,所以線程也被稱為輕權進程或者輕量級進程。
## Python之GIL(Global Interpreter Lock)
首先需要明確的一點是GIL并不是Python的特性,它是在實現Python解析器(CPython)時所引入的一個概念。就好比C++是一套語言(語法)標準,但是可以用不同的編譯器來編譯成可執行代碼。有名的編譯器例如GCC,INTEL C++,Visual C++等。Python也一樣,同樣一段代碼可以通過CPython,PyPy,Psyco等不同的Python執行環境來執行。像其中的JPython就沒有GIL。然而因為CPython是大部分環境下默認的Python執行環境。所以在很多人的概念里CPython就是Python,也就想當然的把GIL歸結為Python語言的缺陷。所以這里要先明確一點:GIL并不是Python的特性,Python完全可以不依賴于GIL。
那么什么是GIL呢,下面是官方文檔給出的解釋:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
為什么會有GIL的原因:
* 由于物理上得限制,各CPU廠商在核心頻率上的比賽已經被多核所取代。為了更有效的利用多核處理器的性能,就出現了多線程的編程方式,而隨之帶來的就是線程間數據一致性和狀態同步的困難。即使在CPU內部的Cache也不例外,為了有效解決多份緩存之間的數據同步時各廠商花費了不少心思,也不可避免的帶來了一定的性能損失。
* Python當然也逃不開,為了利用多核,Python開始支持多線程。而解決多線程之間數據完整性和狀態同步的最簡單方法自然就是加鎖。?于是有了GIL這把超級大鎖,而當越來越多的代碼庫開發者接受了這種設定后,他們開始大量依賴這種特性(即默認python內部對象是thread-safe的,無需在實現時考慮額外的內存鎖和同步操作)。
* 慢慢的這種實現方式被發現是蛋疼且低效的。但當大家試圖去拆分和去除GIL的時候,發現大量庫代碼開發者已經重度依賴GIL而非常難以去除了。有多難?做個類比,像MySQL這樣的“小項目”為了把Buffer Pool Mutex這把大鎖拆分成各個小鎖也花了從5.5到5.6再到5.7多個大版為期近5年的時間,并且仍在繼續。MySQL這個背后有公司支持且有固定開發團隊的產品走的如此艱難,那又更何況Python這樣核心開發和代碼貢獻者高度社區化的團隊呢?
* 所以簡單的說GIL的存在更多的是歷史原因。如果推倒重來,多線程的問題依然還是要面對,但是至少會比目前GIL這種方式會更優雅。
## Python多線程
### 多線程的調用方式
1、直接調用多線程
~~~
import threading
import time
def run(n):
time.sleep(3)
print('task',n)
t1 = threading.Thread(target=run,args=('t1',))
t2 = threading.Thread(target=run,args=('t2',))
t1.start()
t2.start()
t1.join() #等待線程t1執行完畢
PS:
~~~
~~~
#threading.current_thread() 打印當前線程
~~~
~~~
#threading.active_count() 打印當前活躍線程數
~~~
2、繼承式調用多線程(一般這種用的比較少)
~~~
import threading
import time
class MyThread(threading.Thread):
def __init__(self, num):
threading.Thread.__init__(self)
self.num = num
def run(self):
time.sleep(3)
print("running on number:%s" % self.num)
if __name__ == '__main__':
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
~~~
### 守護線程
在線程start之前,可以把線程變成守護線程,守護線程服務于非守護線程,當非守護線程執行完畢之后,程序直接結束,不會管非守護線程是否執行完。t.setDaemon(True),t為生成的線程。
### 互斥鎖(Mutex)
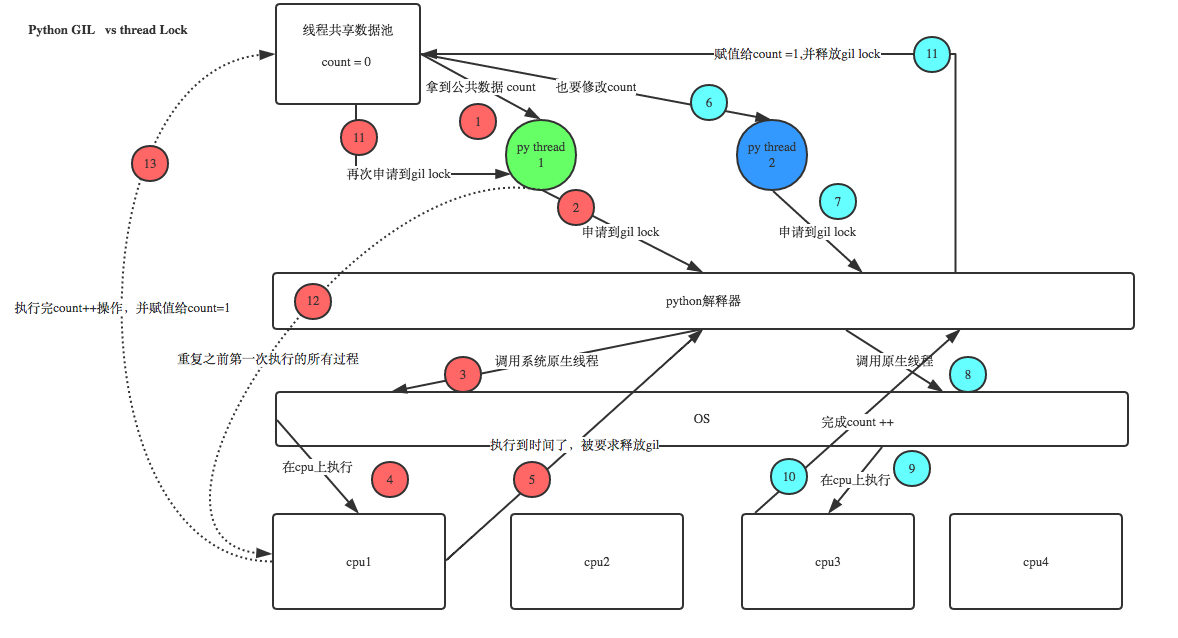
python在使用多線程的時候已經有了GIL為什么還需要線程鎖呢?因為python 的GIL只能控制同一時間只能有一個線程在運行,但是不能控制同一時間只有一個線程在修改數據。有人會問,既然都已經只有一個線程在運行,為什么還會有多個線程在修改數據呢?我們看下面的圖。。。
```
import time
import threading
def addNum():
global num #在每個線程中都獲取這個全局變量
print('--get num:',num )
time.sleep(1)
num -=1 #對此公共變量進行-1操作
num = 100 #設定一個共享變量
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #等待所有線程執行完畢
t.join()
print('final num:', num )
```
PS:不要在3.x上運行,3.x上的結果總是正確的,可能是內部加了鎖
正常來講,這個num結果應該是0, 但在Linux的python 2.7上多運行幾次,會發現,最后打印出來的num結果不總是0,為什么每次運行的結果不一樣呢? 哈,很簡單,假設你有A,B兩個線程,此時都 要對num 進行減1操作, 由于2個線程是并發同時運行的,所以2個線程很有可能同時拿走了num=100這個初始變量交給cpu去運算,當A線程去處完的結果是99,但此時B線程運算完的結果也是99,兩個線程同時CPU運算的結果再賦值給num變量后,結果就都是99。那怎么辦呢? 很簡單,每個線程在要修改公共數據時,為了避免自己在還沒改完的時候別人也來修改此數據,可以給這個數據加一把鎖, 這樣其它線程想修改此數據時就必須等待你修改完畢并把鎖釋放掉后才能再訪問此數據。
```
import time
import threading
def addNum():
global num # 在每個線程中都獲取這個全局變量
lock.acquire() # 修改數據前加鎖
num -= 1 # 對此公共變量進行-1操作
lock.release() # 修改后釋放
num = 100 # 設定一個共享變量
thread_list = []
lock = threading.Lock() # 生成全局鎖
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: # 等待所有線程執行完畢
t.join()
print('final num:', num)
加鎖版本
```
PS:就算以后用3.x的版本也要自己加鎖,即使不加鎖結果正確也要加,因為官方文檔沒有明確指出3.x的版本內部加了鎖。
### RLock遞歸鎖
說白了就是鎖中還有鎖的時候,就不能簡單地使用互斥鎖,要使用遞歸鎖。
```
import threading
def run1():
print("grab the first part data")
lock.acquire()
global num
num += 1
lock.release()
return num
def run2():
print("grab the second part data")
lock.acquire()
global num2
num2 += 1
lock.release()
return num2
def run3():
lock.acquire()
res = run1()
print('--------between run1 and run2-----')
res2 = run2()
lock.release()
print(res, res2)
if __name__ == '__main__':
num, num2 = 0, 0
lock = threading.RLock()
for i in range(10):
t = threading.Thread(target=run3)
t.start()
while threading.active_count() != 1:
print(threading.active_count())
else:
print('----all threads done---')
print(num, num2)
遞歸鎖
```
### **Semaphore(信號量)**
互斥鎖同時只允許一個線程更改數據,而Semaphore是同時允許一定數量的線程更改數據 。
~~~
import threading, time
def run(n):
semaphore.acquire()
time.sleep(1)
print("run the thread: %s\n" % n)
semaphore.release()
num = 0
semaphore = threading.BoundedSemaphore(5) # 最多允許5個線程同時運行
for i in range(20):
t = threading.Thread(target=run, args=(i,))
t.start()
while threading.active_count() != 1:
pass
else:
print('----all threads done---')
print(num)
~~~
## Event事件
?事件處理的機制:全局定義了一個“Flag”,如果“Flag”值為 False,那么當程序執行 event.wait 方法時就會阻塞;如果“Flag”值為True,那么執行event.wait 方法時便不再阻塞。
* clear:將“Flag”設置為False
* set:將“Flag”設置為True
* is\_set:判斷“Flag”是否被設置
* wait:“Flag”值為 False,wait 方法時就會阻塞
? ? 用 threading.Event 實現線程間通信,使用threading.Event可以使一個線程等待其他線程的通知,我們把這個Event傳遞到線程對象中,
? ? Event默認內置了一個標志,初始值為False。一旦該線程通過wait()方法進入等待狀態,直到另一個線程調用該Event的set()方法將內置標志設置為True時,該Event會通知所有等待狀態的線程恢復運行。
? ? 通過Event來實現兩個或多個線程間的交互,下面是一個紅綠燈的例子,即起動一個線程做交通指揮燈,生成幾個線程做車輛,車輛行駛按紅燈停,綠燈行的規則。
```
import threading, time
import random
def light():
if not event.isSet(): #初始化evet的flag為真
event.set() #wait就不阻塞 #綠燈狀態
count = 0
while True:
if count < 10:
print('\033[42;1m---green light on---\033[0m')
elif count < 13:
print('\033[43;1m---yellow light on---\033[0m')
elif count < 20:
if event.isSet():
event.clear()
print('\033[41;1m---red light on---\033[0m')
else:
count = 0
event.set() #打開綠燈
time.sleep(1)
count += 1
def car(n):
while 1:
time.sleep(random.randrange(3, 10))
#print(event.isSet())
if event.isSet():
print("car [%s] is running..." % n)
else:
print('car [%s] is waiting for the red light...' % n)
event.wait() #紅燈狀態下調用wait方法阻塞,汽車等待狀態
if __name__ == '__main__':
car_list = ['BMW', 'AUDI', 'SANTANA']
event = threading.Event()
Light = threading.Thread(target=light)
Light.start()
for i in car_list:
t = threading.Thread(target=car, args=(i,))
t.start()
```
## queue隊列
* class?*`queue.Queue`(*maxsize=0*) #先入先出**
* class?`queue.LifoQueue`(*maxsize=0*) #last in fisrt out?**
* class?*`queue.PriorityQueue`(*maxsize=0*) #存儲數據時可設置優先級的隊列**
隊列常用方法
` Queue.qsize`()
` Queue.empty`() #return True if empty??
` Queue.full`() # return True if full?
` Queue.put`(*item*,?*block=True*,?*timeout=None*)? ? ? ? # priority\_number,?data
`Queue.put_nowait`()??
` Queue.get`()??
` Queue.get_nowait`()??
```
import queue
q2 = queue.Queue()
q1 = queue.LifoQueue()
q = queue.PriorityQueue()
q.put((8,'alex'))
q.put((6,'wusir'))
q.put((7,'json'))
print(q.get())
print(q.get())
print(q.get())
print(q.get(timeout=3))
#自由修改數據自己測試
```
- Python學習
- Python基礎
- Python初識
- 列表生成式,生成器,可迭代對象,迭代器詳解
- Python面向對象
- Python中的單例模式
- Python變量作用域、LEGB、閉包
- Python異常處理
- Python操作正則
- Python中的賦值與深淺拷貝
- Python自定義CLI三方庫
- Python并發編程
- Python之進程
- Python之線程
- Python之協程
- Python并發編程與IO模型
- Python網絡編程
- Python之socket網絡編程
- Django學習
- 反向解析
- Cookie和Session操作
- 文件上傳
- 緩存的配置和使用
- 信號
- FBV&&CBV&&中間件
- Django補充
- 用戶認證
- 分頁
- 自定義搜索組件
- Celery
- 搭建sentry平臺監控
- DRF學習
- drf概述
- Flask學習
- 項目拆分
- 三方模塊使用
- 爬蟲學習
- Http和Https區別
- 請求相關庫
- 解析相關庫
- 常見面試題
- 面試題
- 面試題解析
- 網絡原理
- 計算機網絡知識簡單介紹
- 詳解TCP三次握手、四次揮手及11種狀態
- 消息隊列和數據庫
- 消息隊列之RabbitMQ
- 數據庫之Redis
- 數據庫之初識MySQL
- 數據庫之MySQL進階
- 數據庫之MySQL補充
- 數據庫之Python操作MySQL
- Kafka常用命令
- Linux學習
- Linux基礎命令
- Git
- Git介紹
- Git基本配置及理論
- Git常用命令
- Docker
- Docker基本使用
- Docker常用命令
- Docker容器數據卷
- Dockerfile
- Docker網絡原理
- docker-compose
- Docker Swarm
- HTML
- CSS
- JS
- VUE