
## re模塊
### 正則表達式
正則表達式不僅在python領域,在整個編程屆都占有舉足輕重的地位。不管以后是不是做python開發,只要你是一個程序員就應該了解正則表達式的基本使用。如果未來你要在爬蟲領域發展,你就更應該好好學習這方面的知識。但是,re模塊本質上和正則表達式沒有一毛錢的關系。re模塊和正則表達式的關系 類似于 time模塊和時間的關系,沒有學習python之前,你不知道有一個time模塊,但是你已經認識時間了 12:30就表示中午十二點半。時間有自己的格式,年月日時分秒,12個月,365天......已經成為了一種規則。你也早就牢記于心了。time模塊只不過是python提供給我們的可以方便我們操作時間的一個工具而已。**正則表達式**本身也和python沒有什么關系,就是**匹配字符串內容的一種規則**。
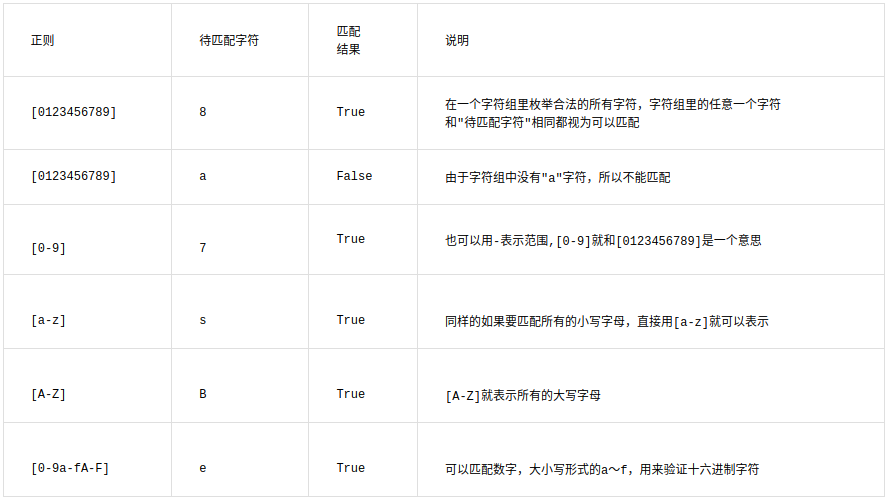
#### 字符組
字符組 : [字符組]
在同一個位置可能出現的各種字符組成了一個字符組,在正則表達式中用[]表示
字符分為很多類,比如數字、字母、標點等等。
假如你現在要求一個位置"只能出現一個數字",那么這個位置上的字符只能是0、1、2...9這10個數之一。
#### 字符
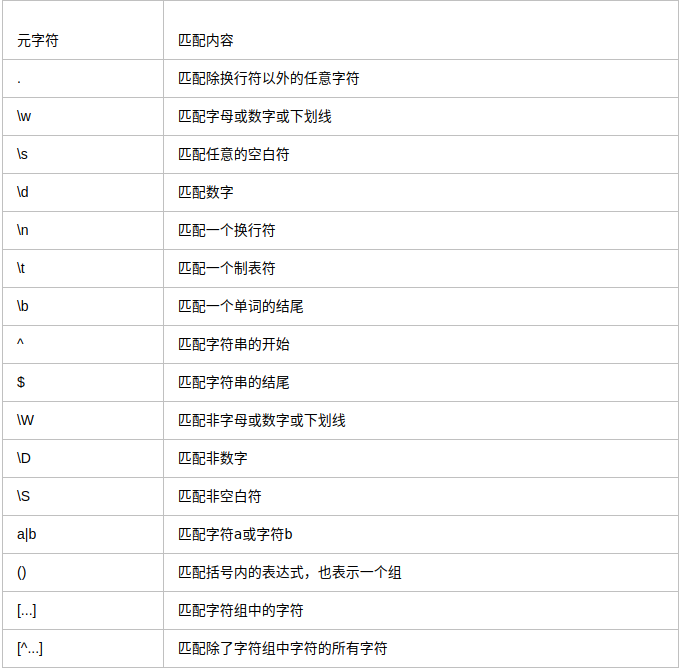
#### 量詞
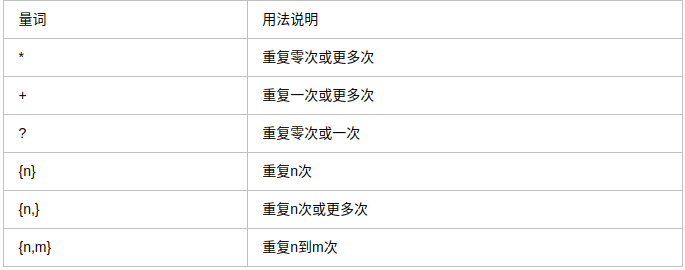
#### .^$
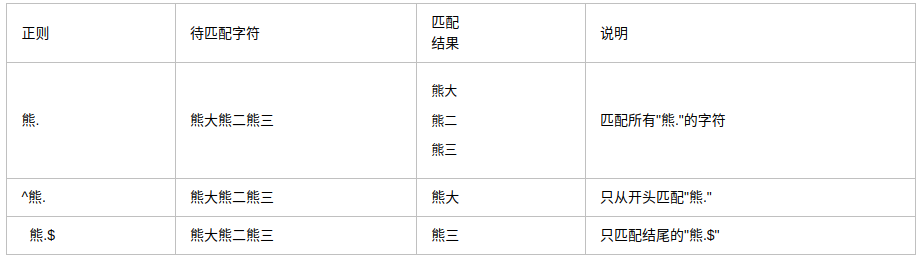
#### \*+?{}
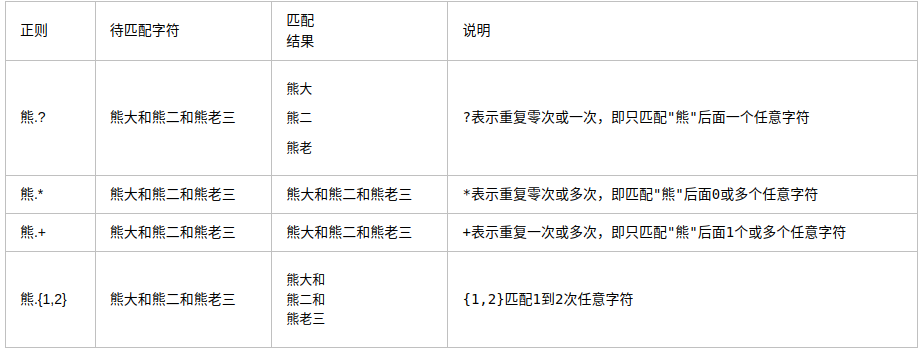
**?注意:前面的\*,+,?等都是貪婪匹配,也就是盡可能匹配,后面加?號使其變成惰性匹配**
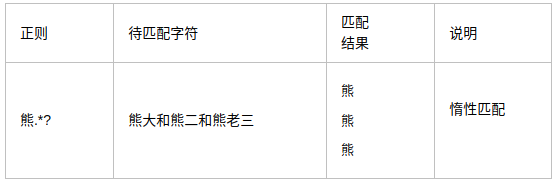
#### 字符集 \[\] \[^\]
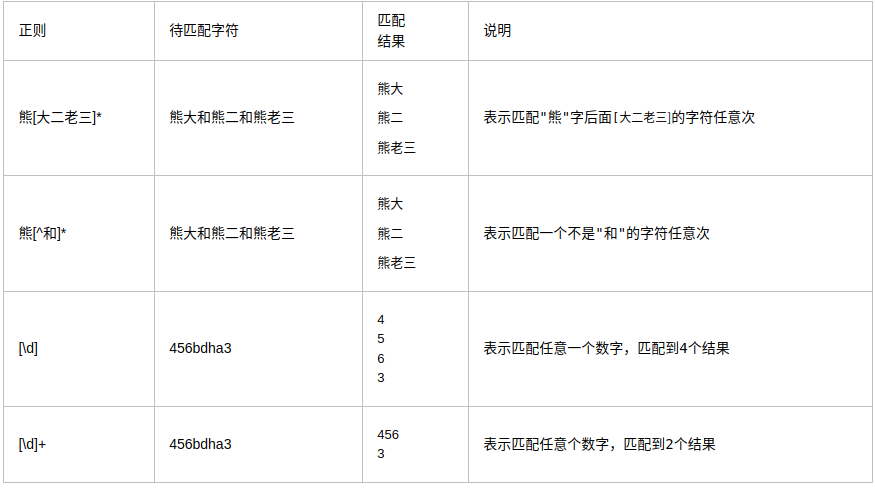
#### ?分組 () 與或 | \[^\]

#### 轉義符\\
在正則表達式中,有很多有特殊意義的是元字符,比如\\n和\\s等,如果要在正則中匹配正常的"\\n"而不是"換行符"就需要對"\\"進行轉義,變成'\\\\'。
在python中,無論是正則表達式,還是待匹配的內容,都是以字符串的形式出現的,在字符串中\\也有特殊的含義,本身還需要轉義。所以如果匹配一次"\\n",字符串中要寫成'\\\\n',那么正則里就要寫成"\\\\\\\\n",這樣就太麻煩了。這個時候我們就用到了r'\\n'這個概念,此時的正則是r'\\\\n'就可以了。
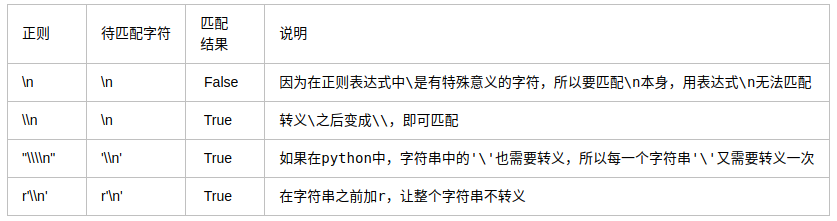
#### ?貪婪匹配
貪婪匹配:在滿足匹配時,匹配盡可能長的字符串,默認情況下,采用貪婪匹配
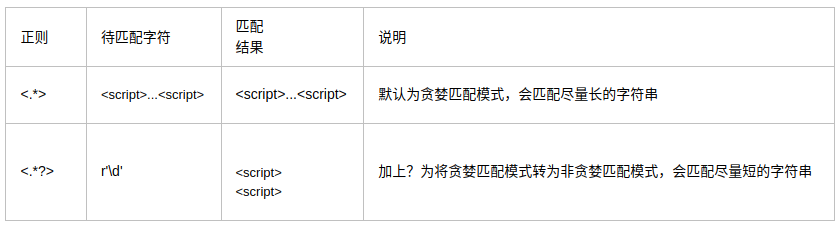
幾個常用的非貪婪匹配Pattern
```
~~~
*? 重復任意次,但盡可能少重復
+? 重復1次或更多次,但盡可能少重復
?? 重復0次或1次,但盡可能少重復
{n,m}? 重復n到m次,但盡可能少重復
{n,}? 重復n次以上,但盡可能少重復
~~~
```
.*?的用法
```
. 是任意字符
* 是取 0 至 無限長度
? 是非貪婪模式。
何在一起就是 取盡量少的任意字符,一般不會這么單獨寫,他大多用在:
.*?x
就是取前面任意長度的字符,直到一個x出現
```
### Python中re模塊下的常用方法
~~~
import re
ret = re.findall('a', 'eva egon yuan') # 返回所有滿足匹配條件的結果,放在列表里
print(ret) #結果 : ['a', 'a']
ret = re.search('a', 'eva egon yuan').group()
print(ret) #結果 : 'a'
# 函數會在字符串內查找模式匹配,只到找到第一個匹配然后返回一個包含匹配信息的對象,該對象可以
# 通過調用group()方法得到匹配的字符串,如果字符串沒有匹配,則返回None。
ret = re.match('a', 'abc').group() # 同search,不過盡在字符串開始處進行匹配
print(ret)
#結果 : 'a'
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在對''和'bcd'分別按'b'分割
print(ret) # ['', '', 'cd']
ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#將數字替換成'H',參數1表示只替換1個
print(ret) #evaHegon4yuan4
ret = re.subn('\d', 'H', 'eva3egon4yuan4')#將數字替換成'H',返回元組(替換的結果,替換了多少次)
print(ret)
obj = re.compile('\d{3}') #將正則表達式編譯成為一個 正則表達式對象,規則要匹配的是3個數字
ret = obj.search('abc123eeee') #正則表達式對象調用search,參數為待匹配的字符串
print(ret.group()) #結果 : 123
import re
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一個存放匹配結果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一個結果
print(next(ret).group()) #查看第二個結果
print([i.group() for i in ret]) #查看剩余的左右結果
~~~
**注意:**
1 findall的優先級查詢
~~~
import re
ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['oldboy'] 這是因為findall會優先把匹配結果組里內容返回,如果想要匹配結果,取消權限即可
ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['www.oldboy.com']
~~~
2 split的優先級查詢
~~~
ret=re.split("\d+","eva3egon4yuan")
print(ret) #結果 : ['eva', 'egon', 'yuan']
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #結果 : ['eva', '3', 'egon', '4', 'yuan']
#在匹配部分加上()之后所切出的結果是不同的,
#沒有()的沒有保留所匹配的項,但是有()的卻能夠保留了匹配的項,
#這個在某些需要保留匹配部分的使用過程是非常重要的。
~~~
- Python學習
- Python基礎
- Python初識
- 列表生成式,生成器,可迭代對象,迭代器詳解
- Python面向對象
- Python中的單例模式
- Python變量作用域、LEGB、閉包
- Python異常處理
- Python操作正則
- Python中的賦值與深淺拷貝
- Python自定義CLI三方庫
- Python并發編程
- Python之進程
- Python之線程
- Python之協程
- Python并發編程與IO模型
- Python網絡編程
- Python之socket網絡編程
- Django學習
- 反向解析
- Cookie和Session操作
- 文件上傳
- 緩存的配置和使用
- 信號
- FBV&&CBV&&中間件
- Django補充
- 用戶認證
- 分頁
- 自定義搜索組件
- Celery
- 搭建sentry平臺監控
- DRF學習
- drf概述
- Flask學習
- 項目拆分
- 三方模塊使用
- 爬蟲學習
- Http和Https區別
- 請求相關庫
- 解析相關庫
- 常見面試題
- 面試題
- 面試題解析
- 網絡原理
- 計算機網絡知識簡單介紹
- 詳解TCP三次握手、四次揮手及11種狀態
- 消息隊列和數據庫
- 消息隊列之RabbitMQ
- 數據庫之Redis
- 數據庫之初識MySQL
- 數據庫之MySQL進階
- 數據庫之MySQL補充
- 數據庫之Python操作MySQL
- Kafka常用命令
- Linux學習
- Linux基礎命令
- Git
- Git介紹
- Git基本配置及理論
- Git常用命令
- Docker
- Docker基本使用
- Docker常用命令
- Docker容器數據卷
- Dockerfile
- Docker網絡原理
- docker-compose
- Docker Swarm
- HTML
- CSS
- JS
- VUE