
第2章 面試需要的基礎知識
2.1 面試官談基礎知識
“C++的基礎知識,如面向對象的特性、構造函數、析構函數、動態綁定等,能夠反映出應聘者是否善于把握問題本質,有沒有耐心深入一個問題。另外還有常用的設計模式、UML圖等,這些都能體現應聘者是否有軟件工程方面的經驗。”
——王海波(Autodesk,軟件工程師)
“對基礎知識的考查我特別重視C++中對內存的使用管理。我覺得內存管理是C++程序員特別要注意的,因為內存的使用和管理會影響程序的效率和穩定性。”
——藍誠(Autodesk,軟件工程師)
“基礎知識反映了一個人的基本能力和基礎素質,是以后工作中最核心的能力要求。我一般考查:(1)數據結構和算法;(2)編程能力;(3)部分數學知識,如概率;(4)問題的分析和推理能力。”
——張曉禹(百度,技術經理)
“我比較重視四塊基礎知識:(1)編程基本功(特別喜歡字符串處理這一類的問題);(2)并發控制;(3)算法、復雜度;(4)語言的基本概念。”
——張珺(百度,高級軟件工程師)
“我會考查編程基礎、計算機系統基礎知識、算法以及設計能力。這些是一個軟件工程師的最基本的東西,這些方面表現出色的人,我們一般認為是有發展潛力的。”
——韓偉東(盛大,高級研究員)
“(1)對OS的理解程度。這些知識對于工作中常遇到的內存管理、文件操作、程序性能、多線程、程序安全等有重要幫助。對于OS理解比較深入的人對于偏底層的工作上手一般比較快。(2)對于一門編程語言的掌握程度。一個熱愛編程的人應該會對某種語言有比較深入的了解。通常這樣的人對于新的編程語言上手也比較快,而且理解比較深入。(3)常用的算法和數據結構。不了解這些的程序員基本只能寫寫‘Hello World’。”
——陳黎明(微軟,SDE II)
2.2 編程語言
程序員寫代碼總是基于某一種編程語言,因此技術面試的時候直接或者間接都會涉及至少一種編程語言。在面試的過程中,面試官要么直接問語言的語法,要么讓應聘者用一種編程語言寫代碼解決一個問題,通過寫出的代碼來判斷應聘者對他使用的語言的掌握程度。現在流行的編程語言很多,不同公司開發用的語言也不盡相同。做底層開發比如經常寫驅動的人更習慣用C,Linux下有很多程序員用C++開發應用程序,基于Windows的C#項目已經越來越多,跨平臺開發的程序員則可能更喜歡Java,隨著蘋果iPad、iPhone的熱銷已經有很多程序員投向了Objective C的陣營,同時還有很多人喜歡用腳本語言如Perl、Python開發短小精致的小應用軟件。因此,不同公司面試的時候對編程語言的要求也有所不同。每一種編程語言都可以寫出一本大部頭的書籍,本書限于篇幅不可能面面俱到。本書中所有代碼都用C/C++/C#實現,下面簡要介紹一些C++/C#常見的面試題。
2.2.1 C++
國內絕大部分高校都開設C++的課程,因此絕大部分程序員都學過C++,于是C++成了各公司面試的首選編程語言。包括Autodesk在內的很多公司在面試的時候會有大量的C++的語法題,其他公司雖然不直接面試C++的語法,但面試題要求用C++實現算法。因此總的說來,應聘者不管去什么公司求職,都應該在一定程度上掌握C++。
通常語言面試有3種類型。第一種類型是面試官直接詢問應聘者對C++概念的理解。這種類型的問題,面試官特別喜歡了解應聘者對C++關鍵字的理解程度。例如:在C++中,有哪4個與類型轉換相關的關鍵字?這些關鍵字各有什么特點,應該在什么場合下使用?
在這種類型的題目中,sizeof是經常被問到的一個概念。比如下面的面試片段,就反復出現在各公司的技術面試中。
面試官:定義一個空的類型,里面沒有任何成員變量和成員函數。對該類型求sizeof,得到的結果是多少?
應聘者:答案是1。
面試官:為什么不是0?
應聘者:空類型的實例中不包含任何信息,本來求sizeof應該是0,但是當我們聲明該類型的實例的時候,它必須在內存中占有一定的空間,否則無法使用這些實例。至于占用多少內存,由編譯器決定。Visual Studio中每個空類型的實例占用1字節的空間。
面試官:如果在該類型中添加一個構造函數和析構函數,再對該類型求sizeof,得到的結果又是多少?
應聘者:和前面一樣,還是1。調用構造函數和析構函數只需要知道函數的地址即可,而這些函數的地址只與類型相關,而與類型的實例無關,編譯器也不會因為這兩個函數而在實例內添加任何額外的信息。
面試官:那如果把析構函數標記為虛函數呢?
應聘者:++的編譯器一旦發現一個類型中有虛擬函數,就會為該類型生成虛函數表,并在該類型的每一個實例中添加一個指向虛函數表的指針。在32位的機器上,一個指針占4字節的空間,因此求sizeof得到4;如果是64位的機器,一個指針占8字節的空間,因此求sizeof則得到8。
面試C/C++的第二種題型就是面試官拿出事先準備好的代碼,讓應聘者分析代碼的運行結果。這種題型選擇的代碼通常包含比較復雜微妙的語言特性,這要求應聘者對C++考點有著透徹的理解。即使應聘者對考點有一點點模糊,那么最終他得到的結果和實際運行的結果可能就會差距甚遠。
比如面試官遞給應聘者一張有如下代碼的A4打印紙要求他分析編譯運行的結果,并提供3個選項:A.編譯錯誤;B.編譯成功,運行時程序崩潰;C.編譯運行正常,輸出10。

在上述代碼中,復制構造函數A(A other)傳入的參數是A的一個實例。由于是傳值參數,我們把形參復制到實參會調用復制構造函數。因此如果允許復制構造函數傳值,就會在復制構造函數內調用復制構造函數,就會形成永無休止的遞歸調用從而導致棧溢出。因此C++的標準不允許復制構造函數傳值參數,在Visual Studio和GCC中,都將編譯出錯。要解決這個問題,我們可以把構造函數修改為A(const A&other),也就是把傳值參數改成常量引用。
第三種題型就是要求應聘者寫代碼定義一個類型或者實現類型中的成員函數。讓應聘者寫代碼的難度自然比讓應聘者分析代碼要高不少,因為能想明白的未必就能寫得清楚。很多考查C++語法的代碼題圍繞在構造函數、析構函數及運算符重載。比如面試題1“賦值運算符函數”就是一個例子。
為了讓大家能順利地通過C++面試,更重要的是能更好地學習掌握C++這門編程語言,這里推薦幾本C++的書,大家可以根據自己的具體情況選擇閱讀的順序:
● 《Effective C++》。這本書很適合在面試之前突擊C++。這本書列舉了使用C++經常出現的問題及解決這些問題的技巧。該書中提到的問題也是面試官很喜歡問的問題。
● 《C++ Primer》。讀完這本書,就會對C++的語法有全面的了解。
● 《Inside C++ Object Model》。這本書有助于我們深入了解C++對象的內部。讀懂這本書后很多C++難題,比如前面的sizeof的問題、虛函數的調用機制等,都會變得很容易。
● 《The C++ Programming Language》。如果是想全面深入掌握C++,沒有哪本書比這本書更適合的了。
面試題1:賦值運算符函數
題目:如下為類型CMyString的聲明,請為該類型添加賦值運算符函數。

當面試官要求應聘者定義一個賦值運算符函數時,他會在檢查應聘者寫出的代碼時關注如下幾點:
● 是否把返回值的類型聲明為該類型的引用,并在函數結束前返回實例自身的引用(即\*this)。只有返回一個引用,才可以允許連續賦值。否則如果函數的返回值是void,應用該賦值運算符將不能做連續賦值。假設有3個CMyString的對象:str1、str2和str3,在程序中語句str1=str2=str3將不能通過編譯。
● 是否把傳入的參數的類型聲明為常量引用。如果傳入的參數不是引用而是實例,那么從形參到實參會調用一次復制構造函數。把參數聲明為引用可以避免這樣的無謂消耗,能提高代碼的效率。同時,我們在賦值運算符函數內不會改變傳入的實例的狀態,因此應該為傳入的引用參數加上const關鍵字。
● 是否釋放實例自身已有的內存。如果我們忘記在分配新內存之前釋放自身已有的空間,程序將出現內存泄露。
● 是否判斷傳入的參數和當前的實例(\*this)是不是同一個實例。如果是同一個,則不進行賦值操作,直接返回。如果事先不判斷就進行賦值,那么在釋放實例自身的內存的時候就會導致嚴重的問題:當\*this和傳入的參數是同一個實例時,那么一旦釋放了自身的內存,傳入的參數的內存也同時被釋放了,因此再也找不到需要賦值的內容了。
經典的解法,適用于初級程序員
當我們完整地考慮了上述4個方面之后,我們可以寫出如下的代碼:

這是一般C++教材上提供的參考代碼。如果接受面試的是應屆畢業生或者C++初級程序員,能全面地考慮到前面四點并完整地寫出代碼,面試官可能會讓他通過這輪面試。但如果面試的是C++高級程序員,面試官可能會提出更高的要求。
考慮異常安全性的解法,高級程序員必備
在前面的函數中,我們在分配內存之前先用delete釋放了實例m\_pData的內存。如果此時內存不足導致new char拋出異常,m\_pData將是一個空指針,這樣非常容易導致程序崩潰。也就是說一旦在賦值運算符函數內部拋出一個異常,CMyString的實例不再保持有效的狀態,這就違背了異常安全性(Exception Safety)原則。
要想在賦值運算符函數中實現異常安全性,我們有兩種方法。一個簡單的辦法是我們先用new分配新內容再用delete釋放已有的內容。這樣只在分配內容成功之后再釋放原來的內容,也就是當分配內存失敗時我們能確保CMyString的實例不會被修改。我們還有一個更好的辦法是先創建一個臨時實例,再交換臨時實例和原來的實例。下面是這種思路的參考代碼:

在這個函數中,我們先創建一個臨時實例strTemp,接著把strTemp.m\_pData和實例自身的m\_pData做交換。由于strTemp是一個局部變量,但程序運行到if的外面時也就出了該變量的作用域,就會自動調用strTemp的析構函數,把strTemp.m\_pData所指向的內存釋放掉。由于strTemp.m\_pData指向的內存就是實例之前m\_pData的內存,這就相當于自動調用析構函數釋放實例的內存。
在新的代碼中,我們在CMyString的構造函數里用new分配內存。如果由于內存不足拋出諸如bad\_alloc等異常,我們還沒有修改原來實例的狀態,因此實例的狀態還是有效的,這也就保證了異常安全性。
如果應聘者在面試的時候能夠考慮到這個層面,面試官就會覺得他對代碼的異常安全性有很深的理解,那么他自然也就能通過這輪面試了。
源代碼:
本題完整的源代碼詳見01\_AssignmentOperator項目。
測試用例:
● 把一個CMyString的實例賦值給另外一個實例。
● 把一個CMyString的實例賦值給它自己。
● 連續賦值。
本題考點:
● 考查對C++的基礎語法的理解,如運算符函數、常量引用等。
● 考查對內存泄露的理解。
● 對高級C++程序員,面試官還將考查應聘者對代碼異常安全性的理解。
2.2.2 C#
C#是微軟在推出新的開發平臺.NET時同步推出的編程語言。由于Windows至今仍然是用戶最多的操作系統,而.NET又是微軟近年來力推的開發平臺,因此C#無論在桌面軟件還是網絡應用的開發上都有著廣泛的應用,所以我們也不難理解為什么現在很多基于Windows系統開發的公司都會要求應聘者掌握C#。
C#可以看成是一門以C++為基礎發展起來的一種托管語言,因此它的很多關鍵字甚至語法都和C++很類似。對一個學習過C++編程的程序員而言,他用不了多長時間學習就能用C#來開發軟件。然而我們也要清醒地認識到,雖然學習C#與C++相同或者類似的部分很容易,但要掌握并區分兩者不同的地方卻不是一件很容易的事情。面試官總是喜歡深究我們模棱兩可的地方以考查我們是不是真的理解了,因此我們要著重注意C#與C++不同的語法特點。下面的面試片段就是一個例子:
面試官:C++中可以用struct和class來定義類型。這兩種類型有什么區別?
應聘者:如果沒有標明成員函數或者成員變量的訪問權限級別,在struct中默認的是public,而在class中默認的是private。
面試官:那在C#中呢?
應聘者:C#和C++不一樣。在C#中如果沒有標明成員函數或者成員變量的訪問權限級別,struct和class中都是private的。struct和class的區別是struct定義的是值類型,值類型的實例在棧上分配內存;而class定義的是引用類型,引用類型的實例在堆上分配內存。
在C#中,每個類型中和C++一樣,都有構造函數。但和C++不同的是,我們在C#中可以為類型定義一個Finalizer和Dispose方法以釋放資源。Finalizer方法雖然寫法與C++的析構函數看起來一樣,都是后面跟類型名字,但與C++析構函數的調用時機是確定的不同,C#的Finalizer是在運行時(CLR)做垃圾回收時才會被調用,它的調用時機是由運行時決定的,因此對程序員來說是不確定的。另外,在C#中可以為類型定義一個特殊的構造函數:靜態構造函數。這個函數的特點是在類型第一次被使用之前由運行時自動調用,而且保證只調用一次。關于靜態構造函數,我們有很多有意思的面試題,比如運行下面的C#代碼,輸出的結果是什么?

在調用類型B的代碼之前先執行B的靜態構造函數。靜態構造函數先初始化類型的靜態變量,再執行函數體內的語句。因此先打印a1再打印a3。接下來執行Bb=newB(),即調用B的普通構造函數。構造函數先初始化成員變量,再執行函數體內的語句,因此先后打印出a2、a4。因此運行上面的代碼,得到的結果將是打印出4行,分別是a1、a3、a2、a4。
我們除了要關注C#和C++不同的知識點之外,還要格外關注C#一些特有的功能,比如反射、應用程序域(AppDomain)等。這些概念還相互關聯,要花很多時間學習研究才能透徹地理解它們。下面的代碼就是一段關于反射和應用程序域的代碼,運行它得到的結果是什么?

上述C#代碼先創建一個名為NewDomain的應用程序域,并在該域中利用反射機制創建類型A的一個實例和類型B的一個實例。我們注意到類型A是繼承自MarshalByRefObject,而B不是。雖然這兩個類型的結構一樣,但由于基類不同而導致在跨越應用程序域的邊界時表現出的行為將大不相同。
先考慮A的情況。由于A繼承自MarshalByRefObject,那么a實際上只是在默認的域中的一個代理實例(Proxy),它指向位于NewDomain域中的A的一個實例。當調用a的方法SetNumber時,是在NewDomain域中調用該方法,它將修改NewDomain域中靜態變量A.Number的值并設為20。由于靜態變量在每個應用程序域中都有一份獨立的拷貝,修改NewDomain域中的靜態變量A.Number對默認域中的靜態變量A.Number沒有任何影響。由于Console.WriteLine是在默認的應用程序域中輸出A.Number,因此輸出仍然是10。
接著討論B。由于B只是從Object繼承而來的類型,它的實例穿越應用程序域的邊界時,將會完整地復制實例。因此在上述代碼中,我們盡管試圖在NewDomain域中生成B的實例,但會把實例b復制到默認的應用程序域。此時調用方法b.SetNumber也是在缺省的應用程序域上進行,它將修改默認的域上的A.Number并設為20。再在默認的域上調用Console.WriteLine時,它將輸出20。
下面推薦兩本C#相關的書籍,以方便大家應對C#面試并學習好C#。
● 《Professional C#》。這本書最大的特點是在附錄中有幾章專門寫給已經有其他語言(如VB、C++和Java)經驗的程序員,它詳細講述了C#和其他語言的區別,看了這幾章之后就不會把C#和之前掌握的語言相混淆。
● Jeffrey Richter的《CLR Via C#》。該書不僅深入地介紹了C#語言,同時對CLR及.NET做了全面的剖析。如果能夠讀懂這本書,那么我們就能深入理解裝箱卸箱、垃圾回收、反射等概念,知其然的同時也能知其所以然,通過C#相關的面試自然也就不難了。
面試題2:實現Singleton模式
題目:設計一個類,我們只能生成該類的一個實例。
只能生成一個實例的類是實現了Singleton(單例)模式的類型。由于設計模式在面向對象程序設計中起著舉足輕重的作用,在面試過程中很多公司都喜歡問一些與設計模式相關的問題。在常用的模式中,Singleton是唯一一個能夠用短短幾十行代碼完整實現的模式。因此,寫一個Singleton的類型是一個很常見的面試題。
不好的解法一:只適用于單線程環境
由于要求只能生成一個實例,因此我們必須把構造函數設為私有函數以禁止他人創建實例。我們可以定義一個靜態的實例,在需要的時候創建該實例。下面定義類型Singleton1就是基于這個思路的實現:

上述代碼在Singleton的靜態屬性Instance中,只有在instance為null的時候才創建一個實例以避免重復創建。同時我們把構造函數定義為私有函數,這樣就能確保只創建一個實例。
不好的解法二:雖然在多線程環境中能工作但效率不高
解法一中的代碼在單線程的時候工作正常,但在多線程的情況下就有問題了。設想如果兩個線程同時運行到判斷instance是否為null的if語句,并且instance的確沒有創建時,那么兩個線程都會創建一個實例,此時類型Singleton1就不再滿足單例模式的要求了。為了保證在多線程環境下我們還是只能得到類型的一個實例,需要加上一個同步鎖。把Singleton1稍做修改得到了如下代碼:

我們還是假設有兩個線程同時想創建一個實例。由于在一個時刻只有一個線程能得到同步鎖,當第一個線程加上鎖時,第二個線程只能等待。當第一個線程發現實例還沒有創建時,它創建出一個實例。接著第一個線程釋放同步鎖,此時第二個線程可以加上同步鎖,并運行接下來的代碼。這個時候由于實例已經被第一個線程創建出來了,第二個線程就不會重復創建實例了,這樣就保證了我們在多線程環境中也只能得到一個實例。
但是類型Singleton2還不是很完美。我們每次通過屬性Instance得到Singleton2的實例,都會試圖加上一個同步鎖,而加鎖是一個非常耗時的操作,在沒有必要的時候我們應該盡量避免。
可行的解法:加同步鎖前后兩次判斷實例是否已存在
我們只是在實例還沒有創建之前需要加鎖操作,以保證只有一個線程創建出實例。而當實例已經創建之后,我們已經不需要再做加鎖操作了。于是我們可以把解法二中的代碼再做進一步的改進:

Singleton3中只有當instance為null即沒有創建時,需要加鎖操作。當instance已經創建出來之后,則無須加鎖。因為只在第一次的時候instance為null,因此只在第一次試圖創建實例的時候需要加鎖。這樣Singleton3的時間效率比Singleton2要好很多。
Singleton3用加鎖機制來確保在多線程環境下只創建一個實例,并且用兩個if判斷來提高效率。這樣的代碼實現起來比較復雜,容易出錯,我們還有更加優秀的解法。
強烈推薦的解法一:利用靜態構造函數
C#的語法中有一個函數能夠確保只調用一次,那就是靜態構造函數,我們可以利用C#這個特性實現單例模式如下:

Singleton4的實現代碼非常簡潔。我們在初始化靜態變量instance的時候創建一個實例。由于C#是在調用靜態構造函數時初始化靜態變量,.NET運行時能夠確保只調用一次靜態構造函數,這樣我們就能夠保證只初始化一次instance。
C#中調用靜態構造函數的時機不是由程序員掌控的,而是當.NET運行時發現第一次使用一個類型的時候自動調用該類型的靜態構造函數。因此在Singleton4中,實例instance并不是第一次調用屬性Singleton4.Instance的時候創建,而是在第一次用到Singleton4的時候就會被創建。假設我們在Singleton4中添加一個靜態方法,調用該靜態函數是不需要創建一個實例的,但如果按照Singleton4的方式實現單例模式,則仍然會過早地創建實例,從而降低內存的使用效率。
強烈推薦的解法二:實現按需創建實例
最后的一個實現Singleton5則很好地解決了Singleton4中的實例創建時機過早的問題:

在上述Singleton5的代碼中,我們在內部定義了一個私有類型Nested。當第一次用到這個嵌套類型的時候,會調用靜態構造函數創建Singleton5的實例instance。類型Nested只在屬性Singleton5.Instance中被用到,由于其私有屬性他人無法使用Nested類型。因此當我們第一次試圖通過屬性Singleton5.Instance得到Singleton5的實例時,會自動調用Nested的靜態構造函數創建實例instance。如果我們不調用屬性Singleton5.Instance,那么就不會觸發.NET運行時調用Nested,也不會創建實例,這樣就真正做到了按需創建。
解法比較
在前面的5種實現單例模式的方法中,第一種方法在多線程環境中不能正常工作,第二種模式雖然能在多線程環境中正常工作但時間效率很低,都不是面試官期待的解法。在第三種方法中我們通過兩次判斷一次加鎖確保在多線程環境能高效率地工作。第四種方法利用C#的靜態構造函數的特性,確保只創建一個實例。第五種方法利用私有嵌套類型的特性,做到只在真正需要的時候才會創建實例,提高空間使用效率。如果在面試中給出第四種或者第五種解法,毫無疑問會得到面試官的青睞。
源代碼:
本題完整的源代碼詳見02\_Singleton項目。
本題考點:
● 考查對單例(Singleton)模式的理解。
● 考查對C#的基礎語法的理解,如靜態構造函數等。
● 考查對多線程編程的理解。
本題擴展:
在前面的代碼中,5種單例模式的實現把類型標記為sealed,表示它們不能作為其他類型的基類。現在我們要求定義一個表示總統的類型President,可以從該類型繼承出FrenchPresident和AmericanPresident等類型。這些派生類型都只能產生一個實例。請問該如何設計實現這些類型?
2.3 數據結構
數據結構一直是技術面試的重點,大多數面試題都是圍繞著數組、字符串、鏈表、樹、棧及隊列這幾種常見的數據結構展開的,因此每一個應聘者都要熟練掌握這幾種數據結構。
數組和字符串是兩種最基本的數據結構,它們用連續內存分別存儲數字和字符。鏈表和樹是面試中出現頻率最高的數據結構。由于操作鏈表和樹需要操作大量的指針,應聘者在解決相關問題的時候一定要留意代碼的魯棒性,否則容易出現程序崩潰的問題。棧是一個與遞歸緊密相關的數據結構,同樣隊列也與廣度優先遍歷算法緊密相關。深刻理解這兩種數據結構能幫助我們解決很多算法問題。
2.3.1 數組
數組可以說是最簡單的一種數據結構,它占據一塊連續的內存并按照順序存儲數據。創建數組時,我們需要首先指定數組的容量大小,然后根據大小分配內存。即使我們只在數組中存儲一個數字,也需要為所有的數據預先分配內存。因此數組的空間效率不是很好,經常會有空閑的區域沒有得到充分利用。
由于數組中的內存是連續的,于是可以根據下標在O(1)時間讀/寫任何元素,因此它的時間效率是很高的。我們可以根據數組時間效率高的優點,用數組來實現簡單的哈希表:把數組的下標設為哈希表的鍵值(Key),而把數組中的每一個數字設為哈希表的值(Value),這樣每一個下標及數組中該下標對應的數字就組成了一個鍵值-值的配對。有了這樣的哈希表,我們就可以在O(1)實現查找,從而可以快速高效地解決很多問題。面試題35“第一個只出現一次的字母”就是一個很好的例子。
為了解決數組空間效率不高的問題,人們又設計實現了多種動態數組,比如C++的STL中的vector。為了避免浪費,我們先為數組開辟較小的空間,然后往數組中添加數據。當數據的數目超過數組的容量時,我們再重新分配一塊更大的空間(STL的vector每次擴充容量時,新的容量都是前一次的兩倍),把之前的數據復制到新的數組中,再把之前的內存釋放,這樣就能減少內存的浪費。但我們也注意到每一次擴充數組容量時都有大量的額外操作,這對時間性能有負面影響,因此使用動態數組時要盡量減少改變數組容量大小的次數。
在C/C++中,數組和指針是相互關聯又有區別的兩個概念。當我們聲明一個數組時,其數組的名字也是一個指針,該指針指向數組的第一個元素。我們可以用一個指針來訪問數組。但值得注意的是,C/C++沒有記錄數組的大小,因此用指針訪問數組中的元素時,程序員要確保沒有超出數組的邊界。下面通過一個例子來了解數組和指針的區別。運行下面的代碼,請問輸出是什么?

答案是輸出“20,4,4”。data1是一個數組,sizeof(data1)是求數組的大小。這個數組包含5個整數,每個整數占4字節,因此總共是20字節。data2聲明為指針,盡管它指向了數組data1的第一個數字,但它的本質仍然是一個指針。在32位系統上,對任意指針求sizeof,得到的結果都是4。在C/C++中,當數組作為函數的參數進行傳遞時,數組就自動退化為同類型的指針。因此盡管函數GetSize的參數data被聲明為數組,但它會退化為指針,size3的結果仍然是4。
面試題3:二維數組中的查找
題目:在一個二維數組中,每一行都按照從左到右遞增的順序排序,每一列都按照從上到下遞增的順序排序。請完成一個函數,輸入這樣的一個二維數組和一個整數,判斷數組中是否含有該整數。
例如下面的二維數組就是每行、每列都遞增排序。如果在這個數組中查找數字7,則返回true;如果查找數字5,由于數組不含有該數字,則返回false。
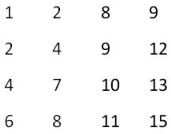
在分析這個問題的時候,很多應聘者都會把二維數組畫成矩形,然后從數組中選取一個數字,分3種情況來分析查找的過程。當數組中選取的數字剛好和要查找的數字相等時,就結束查找過程。如果選取的數字小于要查找的數字,那么根據數組排序的規則,要查找的數字應該在當前選取的位置的右邊或者下邊(如圖2.1(a)所示)。同樣,如果選取的數字大于要查找的數字,那么要查找的數字應該在當前選取的位置的上邊或者左邊(如圖2.1(b)所示)。
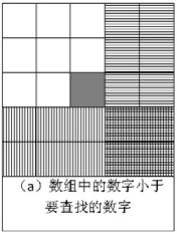
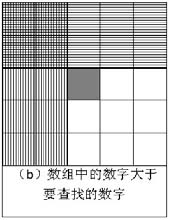
圖2.1 二維數組中的查找
注:在數組中間選擇一個數(深色方格),根據它的大小判斷要查找的數字可能出現的區域(陰影部分)。
在上面的分析中,由于要查找的數字相對于當前選取的位置有可能在兩個區域中出現,而且這兩個區域還有重疊,這問題看起來就復雜了,于是很多人就卡在這里束手無策了。
當我們需要解決一個復雜的問題時,一個很有效的辦法就是從一個具體的問題入手,通過分析簡單具體的例子,試圖尋找普遍的規律。針對這個問題,我們不妨也從一個具體的例子入手。下面我們以在題目中給出的數組中查找數字7為例來一步步分析查找的過程。
前面我們之所以遇到難題,是因為我們在二維數組的中間選取一個數字來和要查找的數字做比較,這樣導致下一次要查找的是兩個相互重疊的區域。如果我們從數組的一個角上選取數字來和要查找的數字做比較,情況會不會變簡單呢?
首先我們選取數組右上角的數字9。由于9大于7,并且9還是第4列的第一個(也是最小的)數字,因此7不可能出現在數字9所在的列。于是我們把這一列從需要考慮的區域內剔除,之后只需要分析剩下的3列(如圖2.2(a)所示)。在剩下的矩陣中,位于右上角的數字是8。同樣8大于7,因此8所在的列我們也可以剔除。接下來我們只要分析剩下的兩列即可(如圖2.2(b)所示)。
在由剩余的兩列組成的數組中,數字2位于數組的右上角。2小于7,那么要查找的7可能在2的右邊,也有可能在2的下邊。在前面的步驟中,我們已經發現2右邊的列都已經被剔除了,也就是說7不可能出現在2的右邊,因此7只有可能出現在2的下邊。于是我們把數字2所在的行也剔除,只分析剩下的三行兩列數字(如圖2.2(c)所示)。在剩下的數字中,數字4位于右上角,和前面一樣,我們把數字4所在的行也刪除,最后剩下兩行兩列數字(如圖2.2(d)所示)。

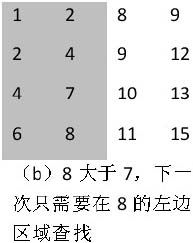

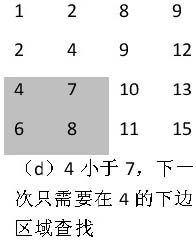
圖2.2 在二維數組中查找7的步驟
注:矩陣中加陰影背景的區域是下一步查找的范圍。
在剩下的兩行兩列4個數字中,位于右上角的剛好就是我們要查找的數字7,于是查找過程就可以結束了。
總結上述查找的過程,我們發現如下規律:首先選取數組中右上角的數字。如果該數字等于要查找的數字,查找過程結束;如果該數字大于要查找的數字,剔除這個數字所在的列;如果該數字小于要查找的數字,剔除這個數字所在的行。也就是說如果要查找的數字不在數組的右上角,則每一次都在數組的查找范圍中剔除一行或者一列,這樣每一步都可以縮小查找的范圍,直到找到要查找的數字,或者查找范圍為空。
把整個查找過程分析清楚之后,我們再寫代碼就不是一件很難的事情了。下面是上述思路對應的參考代碼:

在前面的分析中,我們每一次都是選取數組查找范圍內的右上角數字。同樣,我們也可以選取左下角的數字。感興趣的讀者不妨自己分析一下每次都選取左下角的查找過程。但我們不能選擇左上角或者右下角。以左上角為例,最初數字1位于初始數組的左上角,由于1小于7,那么7應該位于1的右邊或者下邊。此時我們既不能從查找范圍內剔除1所在的行,也不能剔除1所在的列,這樣我們就無法縮小查找的范圍。
源代碼:
本題完整的源代碼詳見03\_FindInPartiallySortedMatrix項目。
測試用例:
● 二維數組中包含查找的數字(查找的數字是數組中的最大值和最小值,查找的數字介于數組中的最大值和最小值之間)。
● 二維數組中沒有查找的數字(查找的數字大于數組中的最大值,查找的數字小于數組中的最小值,查找的數字在數組的最大值和最小值之間但數組中沒有這個數字)。
● 特殊輸入測試(輸入空指針)。
本題考點:
● 考查應聘者對二維數組的理解及編程能力。二維數組在內存中占據連續的空間。在內存中從上到下存儲各行元素,在同一行中按照從左到右的順序存儲。因此我們可以根據行號和列號計算出相對于數組首地址的偏移量,從而找到對應的元素。
● 考查應聘者分析問題的能力。當應聘者發現問題比較復雜時,能不能通過具體的例子找出其中的規律,是能否解決這個問題的關鍵所在。這個題目只要從一個具體的二維數組的右上角開始分析,就能找到查找的規律,從而找到解決問題的突破口。
2.3.2 字符串
字符串是由若干字符組成的序列。由于字符串在編程時使用的頻率非常高,為了優化,很多語言都對字符串做了特殊的規定。下面分別討論C/C++和C#中字符串的特性。
C/C++中每個字符串都以字符'\\0'作為結尾,這樣我們就能很方便地找到字符串的最后尾部。但由于這個特點,每個字符串中都有一個額外字符的開銷,稍不留神就會造成字符串的越界。比如下面的代碼:
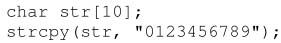
我們先聲明一個長度為10的字符數組,然后把字符串"0123456789"復制到數組中。"0123456789"這個字符串看起來只有10個字符,但實際上它的末尾還有一個'\\0'字符,因此它的實際長度為11個字節。要正確地復制該字符串,至少需要一個長度為11個字節的數組。
為了節省內存,C/C++把常量字符串放到單獨的一個內存區域。當幾個指針賦值給相同的常量字符串時,它們實際上會指向相同的內存地址。但用常量內存初始化數組,情況卻有所不同。下面通過一個面試題來學習這一知識點。運行下面的代碼,得到的結果是什么?

str1和str2是兩個字符串數組,我們會為它們分配兩個長度為12個字節的空間,并把"hello world"的內容分別復制到數組中去。這是兩個初始地址不同的數組,因此str1和str2的值也不相同,所以輸出的第一行是”str1 and str2 are not same”。
str3和str4是兩個指針,我們無須為它們分配內存以存儲字符串的內容,而只需要把它們指向"hello world”在內存中的地址就可以了。由于"hello world”是常量字符串,它在內存中只有一個拷貝,因此str3和str4指向的是同一個地址。所以比較str3和str4的值得到的結果是相同的,輸出的第二行是”str3 and str4 are same”。
在C#中,封裝字符串的類型System.String有一個非常特殊的性質:String中的內容是不能改變的。一旦試圖改變String的內容,就會產生一個新的實例。請看下面的C#代碼:

雖然我們對str做了ToUpper和Insert兩個操作,但操作的結果都是生成一個新的String實例并在返回值中返回,str本身的內容都不會發生改變,因此最終str的值仍然是"hello"。由此可見,如果試圖改變String的內容,改變之后的值只可以通過返回值得到。用String作連續多次修改,每一次修改都會產生一個臨時對象,這樣開銷太大會影響效率。為此C#定義了一個新的與字符串相關的類型StringBuilder,它能容納修改后的結果。因此如果要連續多次修改字符串內容,用StringBuilder是更好的選擇。
和修改String內容類似,如果我們試圖把一個常量字符串賦值給一個String實例,也不是把String的內容改成賦值的字符串,而是生成一個新的String實例。請看下面的代碼:

在上面的代碼中,我們先判斷String是值類型還是引用類型。類型String的定義是public sealed class String {...}。既然是class,那么String自然就是引用類型。接下來在方法ModifyString里,對text賦值一個新的字符串。我們要記得text的內容是不能被修改的。此時會先生成一個新的內容是"world"的String實例,然后把text指向這個新的實例。由于參數text沒有加ref或者out,出了方法ModifyString之后,text還是指向原來的字符串,因此輸出仍然是"hello"。要想實現出了函數之后text變成"world"的效果,我們必須把參數text標記ref或者out。
面試題4:替換空格
題目:請實現一個函數,把字符串中的每個空格替換成"%20"。例如輸入“We are happy.”,則輸出“We%20are%20happy.”。
在網絡編程中,如果URL參數中含有特殊字符,如空格、'#'等,可能導致服務器端無法獲得正確的參數值。我們需要將這些特殊符號轉換成服務器可以識別的字符。轉換的規則是在'%'后面跟上ASCII碼的兩位十六進制的表示。比如空格的ASCII碼是32,即十六進制的0x20,因此空格被替換成"%20"。再比如'#'的ASCII碼為35,即十六進制的0x23,它在URL中被替換為"%23"。
看到這個題目,我們首先應該想到的是原來一個空格字符,替換之后變成'%'、'2'和'0'這3個字符,因此字符串會變長。如果是在原來的字符串上做替換,那么就有可能覆蓋修改在該字符串后面的內存。如果是創建新的字符串并在新的字符串上做替換,那么我們可以自己分配足夠多的內存。由于有兩種不同的解決方案,我們應該向面試官問清楚,讓他明確告訴我們他的需求。假設面試官讓我們在原來的字符串上做替換,并且保證輸入的字符串后面有足夠多的空余內存。
時間復雜度為O(n2)的解法,不足以拿到Offer
現在我們考慮怎么做替換操作。最直觀的做法是從頭到尾掃描字符串,每一次碰到空格字符的時候做替換。由于是把1個字符替換成3個字符,我們必須要把空格后面所有的字符都后移兩個字節,否則就有兩個字符被覆蓋了。
舉個例子,我們從頭到尾把"We are happy."中的每一個空格替換成"%20"。為了形象起見,我們可以用一個表格來表示字符串,表格中的每個格子表示一個字符(如圖2.3(a)所示)。

圖2.3 從前往后把字符串中的空格替換成'%20'的過程
注:(a)字符串"We are happy."。(b)把字符串中的第一個空格替換成'%20'。灰色背景表示需要移動的字符。(c)把字符串中的第二個空格替換成'%20'。淺灰色背景表示需要移動一次的字符,深灰色背景表示需要移動兩次的字符。
我們替換第一個空格,這個字符串變成圖2.3(b)中的內容,表格中灰色背景的格子表示需要做移動的區域。接著我們替換第二個空格,替換之后的內容如圖2.3(c)所示。同時,我們注意到用深灰色背景標注的"happy"部分被移動了兩次。
假設字符串的長度是n。對每個空格字符,需要移動后面O(n)個字符,因此對含有O(n)個空格字符的字符串而言總的時間效率是O(n2)。
當我們把這種思路闡述給面試官后,他不會就此滿意,他將讓我們尋找更快的方法。在前面的分析中,我們發現數組中很多字符都移動了很多次,能不能減少移動次數呢?答案是肯定的。我們換一種思路,把從前向后替換改成從后向前替換。
時間復雜度為O(n)的解法,搞定Offer就靠它了
我們可以先遍歷一次字符串,這樣就能統計出字符串中空格的總數,并可以由此計算出替換之后的字符串的總長度。每替換一個空格,長度增加2,因此替換以后字符串的長度等于原來的長度加上2乘以空格數目。我們還是以前面的字符串"We are happy."為例,"We are happy."這個字符串的長度是14(包括結尾符號'\\0'),里面有兩個空格,因此替換之后字符串的長度是18。
我們從字符串的后面開始復制和替換。首先準備兩個指針,P1和P2。P1指向原始字符串的末尾,而P2指向替換之后的字符串的末尾(如圖2.4(a)所示)。接下來我們向前移動指針P1,逐個把它指向的字符復制到P2指向的位置,直到碰到第一個空格為止。此時字符串包含如圖2.4(b)所示,灰色背景的區域是做了字符拷貝(移動)的區域。碰到第一個空格之后,把P1向前移動1格,在P2之前插入字符串"%20"。由于"%20"的長度為3,同時也要把P2向前移動3格如圖2.4(c)所示。
我們接著向前復制,直到碰到第二個空格(如圖2.4(d)所示)。和上一次一樣,我們再把P1向前移動1格,并把P2向前移動3格插入"%20"(如圖2.4(e)所示)。此時P1和P2指向同一位置,表明所有空格都已經替換完畢。
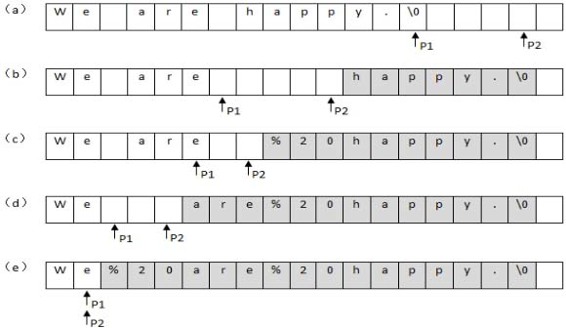
圖2.4 從后往前把字符串中的空格替換成“%20”的過程
注:圖中帶有陰影的區域表示被移動的字符。(a)把第一個指針指向字符串的末尾,把第二個指針指向替換之后的字符串的末尾。(b)依次復制字符串的內容,直至第一個指針碰到第一個空格。(c)把第一個空格替換成'%20',把第一個指針向前移動1格,把第二個指針向前移動3格。(d)依次向前復制字符串中的字符,直至碰到空格。(e)替換字符串中的倒數第二個空格,把第一個指針向前移動1格,把第二個指針向前移動3格。
從上面的分析我們可以看出,所有的字符都只復制(移動)一次,因此這個算法的時間效率是O(n),比第一個思路要快。
在面試的過程中,我們也可以和前面的分析一樣畫一兩個示意圖解釋自己的思路,這樣既能幫助我們理清思路,也能使我們和面試官的交流變得更加高效。在面試官肯定我們的思路之后,就可以開始寫代碼了。下面是參考代碼:

源代碼:
本題完整的源代碼詳見04\_ReplaceBlank項目。
測試用例:
● 輸入的字符串中包含空格(空格位于字符串的最前面,空格位于字符串的最后面,空格位于字符串的中間,字符串中有連續多個空格)。
● 輸入的字符串中沒有空格。
● 特殊輸入測試(字符串是個NULL指針、字符串是個空字符串、字符串只有一個空格字符、字符串中只有連續多個空格)。
本題考點:
● 考查對字符串的編程能力。
● 考查分析時間效率的能力。我們要能清晰地分析出兩種不同方法的時間效率各是多少。
● 考查對內存覆蓋是否有高度的警惕。在分析得知字符串會變長之后,我們能夠意識到潛在的問題,并主動和面試官溝通以尋找問題的解決方案。
● 考查思維能力。在從前到后替換的思路被面試官否定之后,我們能迅速想到從后往前替換的方法,這是解決此題的關鍵。
相關題目:
有兩個排序的數組A1和A2,內存在A1的末尾有足夠多的空余空間容納A2。請實現一個函數,把A2中的所有數字插入到A1中并且所有的數字是排序的。
和前面的例題一樣,很多人首先想到的辦法是在A1中從頭到尾復制數字,但這樣就會出現多次復制一個數字的情況。更好的辦法是從尾到頭比較A1和A2中的數字,并把較大的數字復制到A1的合適位置。
舉一反三:
合并兩個數組(包括字符串)時,如果從前往后復制每個數字(或字符)需要重復移動數字(或字符)多次,那么我們可以考慮從后往前復制,這樣就能減少移動的次數,從而提高效率。
2.3.3 鏈表
鏈表應該是面試時被提及最頻繁的數據結構。鏈表的結構很簡單,它由指針把若干個結點連接成鏈狀結構。鏈表的創建、插入結點、刪除結點等操作都只需要20行左右的代碼就能實現,其代碼量比較適合面試。而像哈希表、有向圖等復雜數據結構,實現它們的一個操作需要的代碼量都較大,很難在幾十分鐘的面試中完成。另外,由于鏈表是一種動態的數據結構,其操作需要對指針進行操作,因此應聘者需要有較好的編程功底才能寫出完整的操作鏈表的代碼。而且鏈表這種數據結構很靈活,面試官可以用鏈表來設計具有挑戰性的面試題。基于上述幾個原因,很多面試官都特別青睞鏈表相關的題目。
我們說鏈表是一種動態數據結構,是因為在創建鏈表時,無須知道鏈表的長度。當插入一個結點時,我們只需要為新結點分配內存,然后調整指針的指向來確保新結點被鏈接到鏈表當中。內存分配不是在創建鏈表時一次性完成,而是每添加一個結點分配一次內存。由于沒有閑置的內存,鏈表的空間效率比數組高。如果單向鏈表的結點定義如下:

那么往該鏈表的末尾中添加一個結點的C語言代碼如下:

在上面的代碼中,我們要特別注意函數的第一個參數pHead是一個指向指針的指針。當我們往一個空鏈表中插入一個結點時,新插入的結點就是鏈表的頭指針。由于此時會改動頭指針,因此必須把pHead參數設為指向指針的指針,否則出了這個函數pHead仍然是一個空指針。
由于鏈表中的內存不是一次性分配的,因而我們無法保證鏈表的內存和數組一樣是連續的。因此如果想在鏈表中找到它的第i個結點,我們只能從頭結點開始,沿著指向下一個結點的指針遍歷鏈表,它的時間效率為O(n)。而在數組中,我們可以根據下標在O(1)時間內找到第i個元素。下面是在鏈表中找到第一個含有某值的結點并刪除該結點的代碼:

除了簡單的單向鏈表經常被設計為面試題之外(面試題5“從尾到頭輸出鏈表”、面試題13“在O(1)時間刪除鏈表結點”、面試題15“鏈表中的倒數第k個結點”、面試題16“反轉鏈表”、面試題17“合并兩個排序的鏈表”、面試題37“兩個鏈表的第一個公共結點”等),鏈表的其他形式同樣也備受面試官的青睞。
● 把鏈表的末尾結點的指針指向頭結點,從而形成一個環形鏈表(面試題45“圓圈中最后剩下的數字”)。
● 鏈表中的結點中除了有指向下一個結點的指針,還有指向前一個結點的指針。這就是雙向鏈表(面試題27“二叉搜索樹與雙向鏈表”)。
● 鏈表中的結點中除了有指向下一個結點的指針,還有指向任意結點的指針,這就是復雜鏈表(面試題26“復雜鏈表的復制”)。
面試題5:從尾到頭打印鏈表
題目:輸入一個鏈表的頭結點,從尾到頭反過來打印出每個結點的值。鏈表結點定義如下:

看到這道題后,很多人的第一反應是從頭到尾輸出將會比較簡單,于是我們很自然地想到把鏈表中鏈接結點的指針反轉過來,改變鏈表的方向,然后就可以從頭到尾輸出了。但該方法會改變原來鏈表的結構。是否允許在打印鏈表的時候修改鏈表的結構?這個取決于面試官的需求,因此在面試的時候我們要詢問清楚面試官的要求。
面試小提示:
在面試中如果我們打算修改輸入的數據,最好先問面試官是不是允許做修改。
通常打印是一個只讀操作,我們不希望打印時修改內容。假設面試官也要求這個題目不能改變鏈表的結構。
接下來我們想到解決這個問題肯定要遍歷鏈表。遍歷的順序是從頭到尾的順序,可輸出的順序卻是從尾到頭。也就是說第一個遍歷到的結點最后一個輸出,而最后一個遍歷到的結點第一個輸出。這就是典型的“后進先出”,我們可以用棧實現這種順序。每經過一個結點的時候,把該結點放到一個棧中。當遍歷完整個鏈表后,再從棧頂開始逐個輸出結點的值,此時輸出的結點的順序已經反轉過來了。這種思路的實現代碼如下:

既然想到了用棧來實現這個函數,而遞歸在本質上就是一個棧結構,于是很自然地又想到了用遞歸來實現。要實現反過來輸出鏈表,我們每訪問到一個結點的時候,先遞歸輸出它后面的結點,再輸出該結點自身,這樣鏈表的輸出結果就反過來了。
基于這樣的思路,不難寫出如下代碼:

上面的基于遞歸的代碼看起來很簡潔,但有個問題:當鏈表非常長的時候,就會導致函數調用的層級很深,從而有可能導致函數調用棧溢出。顯式用棧基于循環實現的代碼的魯棒性要好一些。更多關于循環和遞歸的討論,詳見本書的2.4.2節。
測試用例:
● 功能測試(輸入的鏈表有多個結點,輸入的鏈表只有一個結點)。
● 特殊輸入測試(輸入的鏈表頭結點指針為NULL)。
本題考點:
● 考查對單項鏈表的理解和編程能力。
● 考查對循環、遞歸和棧3個相互關聯的概念的理解。
2.3.4 樹
樹是一種在實際編程中經常遇到的數據結構。它的邏輯很簡單:除了根結點之外每個結點只有一個父結點,根結點沒有父結點;除了葉結點之外所有結點都有一個或多個子結點,葉結點沒有子結點。父結點和子結點之間用指針鏈接。由于樹的操作會涉及大量的指針,因此與樹有關的面試題都不太容易。當面試官想考查應聘者在有復雜指針操作的情況下寫代碼的能力,他往往會想到用與樹有關的面試題。
面試的時候提到的樹,大部分都是二叉樹。所謂二叉樹是樹的一種特殊結構,在二叉樹中每個結點最多只能有兩個子結點。在二叉樹中最重要的操作莫過于遍歷,即按照某一順序訪問樹中的所有結點。通常樹有如下幾種遍歷方式:
● 前序遍歷:先訪問根結點,再訪問左子結點,最后訪問右子結點。圖2.5中的二叉樹的前序遍歷的順序是10、6、4、8、14、12、16。
● 中序遍歷:先訪問左子結點,再訪問根結點,最后訪問右子結點。圖2.5中的二叉樹的中序遍歷的順序是4、6、8、10、12、14、16。
● 后序遍歷:先訪問左子結點,再訪問右子結點,最后訪問根結點。圖2.5中的二叉樹的后序遍歷的順序是4、8、6、12、16、14、10。
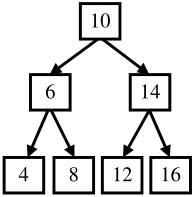
圖2.5 一個二叉樹的例子
這3種遍歷都有遞歸和循環兩種不同的實現方法,每一種遍歷的遞歸實現都比循環實現要簡捷很多。很多面試官喜歡直接或間接考查遍歷(面試題39“二叉樹的深度”、面試題18“樹的子結構”、面試題25“二叉樹中和為某一值的路徑”)的具體代碼實現,面試題6“重建二叉樹”、面試題24“二叉樹的后序遍歷序列”也是考查對遍歷特點的理解,因此應聘者應該對這3種遍歷的6種實現方法都了如指掌。
● 寬度優先遍歷:先訪問樹的第一層結點,再訪問樹的第二層結點……一直到訪問到最下面一層結點。在同一層結點中,以從左到右的順序依次訪問。我們可以對包括二叉樹在內的所有樹進行寬度優先遍歷。圖2.5中的二叉樹的寬度優先遍歷的順序是10、6、14、4、8、12、16。
面試題23“從上到下遍歷二叉樹”就是考查寬度優先遍歷算法的題目。
二叉樹有很多特例,二叉搜索樹就是其中之一。在二叉搜索樹中,左子結點總是小于或等于根結點,而右子結點總是大于或等于根結點。圖2.5中的二叉樹就是一棵二叉搜索樹。我們可以平均在O(logn)的時間內根據數值在二叉搜索樹中找到一個結點。二叉搜索樹的面試題有很多,比如面試題50“樹中兩個結點的最低公共祖先”、面試題27“二叉搜索樹與雙向鏈表”。
二叉樹的另外兩個特例是堆和紅黑樹。堆分為最大堆和最小堆。在最大堆中根結點的值最大,在最小堆中根結點的值最小。有很多需要快速找到最大值或者最小值的問題都可以用堆來解決。紅黑樹是把樹中的結點定義為紅、黑兩種顏色,并通過規則確保從根結點到葉結點的最長路徑的長度不超過最短路徑的兩倍。在C++的STL中,set、multiset、map、multimap等數據結構都是基于紅黑樹實現的。與堆和紅黑樹相關的面試題,請參考面試題30“求最小的k個數字”。
面試題6:重建二叉樹
題目:輸入某二叉樹的前序遍歷和中序遍歷的結果,請重建出該二叉樹。假設輸入的前序遍歷和中序遍歷的結果中都不含重復的數字。例如輸入前序遍歷序列{1,2,4,7,3,5,6,8}和中序遍歷序列{4,7,2,1,5,3,8,6},則重建出圖2.6所示的二叉樹并輸出它的頭結點。二叉樹結點的定義如下:

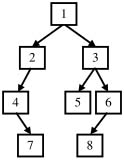
圖2.6 根據前序遍歷序列{1,2,4,7,3,5,6,8}和中序遍歷序列{4,7,2,1,5,3,8,6}重建的二叉樹
在二叉樹的前序遍歷序列中,第一個數字總是樹的根結點的值。但在中序遍歷序列中,根結點的值在序列的中間,左子樹的結點的值位于根結點的值的左邊,而右子樹的結點的值位于根結點的值的右邊。因此我們需要掃描中序遍歷序列,才能找到根結點的值。
如圖2.7所示,前序遍歷序列的第一個數字1就是根結點的值。掃描中序遍歷序列,就能確定根結點的值的位置。根據中序遍歷特點,在根結點的值1前面的3個數字都是左子樹結點的值,位于1后面的數字都是右子樹結點的值。
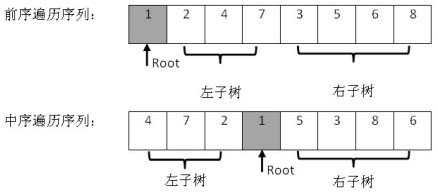
圖2.7 在二叉樹的前序遍歷和中序遍歷的序列中確定根結點的值、左子樹結點的值和右子樹結點的值
由于在中序遍歷序列中,有3個數字是左子樹結點的值,因此左子樹總共有3個左子結點。同樣,在前序遍歷的序列中,根結點后面的3個數字就是3個左子樹結點的值,再后面的所有數字都是右子樹結點的值。這樣我們就在前序遍歷和中序遍歷兩個序列中,分別找到了左右子樹對應的子序列。
既然我們已經分別找到了左、右子樹的前序遍歷序列和中序遍歷序列,我們可以用同樣的方法分別去構建左右子樹。也就是說,接下來的事情可以用遞歸的方法去完成。
在想清楚如何在前序遍歷和中序遍歷的序列中確定左、右子樹的子序列之后,我們可以寫出如下的遞歸代碼:


在函數ConstructCore中,我們先根據前序遍歷序列的第一個數字創建根結點,接下來在中序遍歷序列中找到根結點的位置,這樣就能確定左、右子樹結點的數量。在前序遍歷和中序遍歷的序列中劃分了左、右子樹結點的值之后,我們就可以遞歸地調用函數ConstructCore,去分別構建它的左右子樹。
源代碼:
本題完整的源代碼詳見06\_ConstructBinaryTree項目。
測試用例:
● 普通二叉樹(完全二叉樹,不完全二叉樹)。
● 特殊二叉樹(所有結點都沒有右子結點的二叉樹,所有結點都沒有左子結點的二叉樹,只有一個結點的二叉樹)。
● 特殊輸入測試(二叉樹的根結點指針為NULL、輸入的前序遍歷序列和中序遍歷序列不匹配)。
本題考點:
● 考查應聘者對二叉樹的前序遍歷、中序遍歷的理解程度。只有對二叉樹的不同遍歷算法有了深刻的理解,應聘者才有可能在遍歷序列中劃分出左、右子樹對應的子序列。
● 考查應聘者分析復雜問題的能力。我們把構建二叉樹的大問題分解成構建左、右子樹的兩個小問題。我們發現小問題和大問題在本質上是一致的,因此可以用遞歸的方式解決。更多關于分解復雜問題的討論,請參考本書的4.4節。
2.3.5 棧和隊列
棧是一個非常常見的數據結構,它在計算機領域中被廣泛應用,比如操作系統會給每個線程創建一個棧用來存儲函數調用時各個函數的參數、返回地址及臨時變量等。棧的特點是后進先出,即最后被壓入(push)棧的元素會第一個被彈出(pop)。在面試題22“棧的壓入、彈出序列”中,我們再詳細分析進棧和出棧序列的特點。
通常棧是一個不考慮排序的數據結構,我們需要O(n)時間才能找到棧中最大或者最小的元素。如果想要在O(1)時間內得到棧的最大或者最小值,我們需要對棧做特殊的設計,詳見面試題21“包含min函數的棧”。
隊列是另外一種很重要的數據結構。和棧不同的是,隊列的特點是先進先出,即第一個進入隊列的元素將會第一個出來。在2.3.4節介紹的樹的寬度優先遍歷算法中,我們在遍歷某一層樹的結點時,把結點的子結點放到一個隊列里,以備下一層結點的遍歷。詳細的代碼參見面試題23“從上到下遍歷二叉樹”。
棧和隊列雖然是特點針鋒相對的兩個數據結構,但有意思的是它們卻相互聯系。請看面試題7“用兩個棧實現隊列”,同時讀者也可以考慮如何用兩個隊列實現棧。
面試題7:用兩個棧實現隊列
題目:用兩個棧實現一個隊列。隊列的聲明如下,請實現它的兩個函數appendTail和deleteHead,分別完成在隊列尾部插入結點和在隊列頭部刪除結點的功能。

在上述隊列的聲明中可以看出,一個隊列包含了兩個棧stack1和stack2,因此這道題的意圖是要求我們操作這兩個“先進后出”的棧實現一個“先進先出”的隊列CQueue。
我們通過一個具體的例子來分析往該隊列插入和刪除元素的過程。首先插入一個元素a,不妨先把它插入到stack1,此時stack1中的元素有{a},stack2為空。再壓入兩個元素b和c,還是插入到stack1中,此時stack1中的元素有{a,b,c},其中c位于棧頂,而stack2仍然是空的(如圖2.8(a)所示)。
這個時候我們試著從隊列中刪除一個元素。按照隊列先入先出的規則,由于a比b、c先插入到隊列中,最先被刪除的元素應該是a。元素a存儲在stack1中,但并不在棧頂上,因此不能直接進行刪除。注意到stack2我們還一直沒有使用過,現在是讓stack2發揮作用的時候了。如果我們把stack1中的元素逐個彈出并壓入stack2,元素在stack2中的順序正好和原來在stack1中的順序相反。因此經過3次彈出stack1和壓入stack2操作之后,stack1為空,而stack2中的元素是{c,b,a},這個時候就可以彈出stack2的棧頂a了。此時的stack1為空,而stack2的元素為{c,b},其中b在棧頂(如圖2.8(b)所示)。
如果我們還想繼續刪除隊列的頭部應該怎么辦呢?剩下的兩個元素是b和c,b比c早進入隊列,因此b應該先刪除。而此時b恰好又在棧頂上,因此直接彈出stack2的棧頂即可。這次彈出操作之后,stack1中仍然為空,而stack2為{c}(如圖2.8(c)所示)。
從上面的分析中我們可以總結出刪除一個元素的步驟:當stack2中不為空時,在stack2中的棧頂元素是最先進入隊列的元素,可以彈出。如果stack2為空時,我們把stack1中的元素逐個彈出并壓入stack2。由于先進入隊列的元素被壓到stack1的底端,經過彈出和壓入之后就處于stack2的頂端了,又可以直接彈出。
接下來再插入一個元素d。我們還是把它壓入stack1(如圖2.8(d)所示),這樣會不會有問題呢?我們考慮下一次刪除隊列的頭部stack2不為空,直接彈出它的棧頂元素c(如圖2.8(e)所示)。而c的確是比d先進入隊列,應該在d之前從隊列中刪除,因此不會出現任何矛盾。
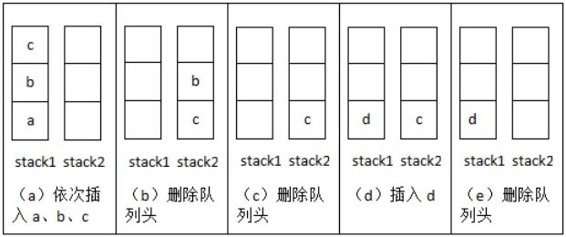
圖2.8 用兩個棧模擬一個隊列的操作
總結完每一次在隊列中插入和刪除操作的過程之后,我們就可以開始動手寫代碼了。參考代碼如下:
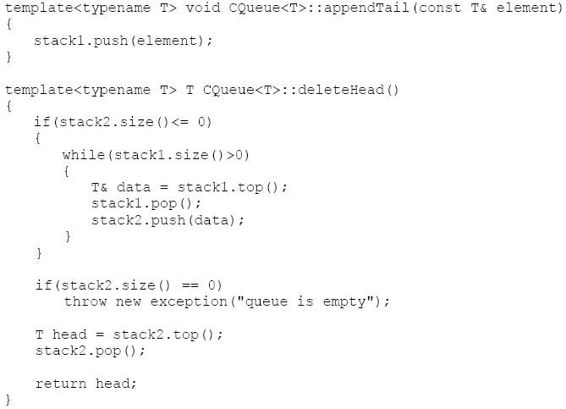
源代碼:
本題完整的源代碼詳見07\_QueueWithTwoStacks項目。
測試用例:
● 往空的隊列里添加、刪除元素。
● 往非空的隊列里添加、刪除元素。
● 連續刪除元素直至隊列為空。
本題考點:
● 考查對棧和隊列的理解。
● 考查寫與模板相關的代碼的能力。
● 考查分析復雜問題的能力。本題解法的代碼雖然只有只有20幾行代碼,但形成正確的思路卻不容易。應聘者能否通過具體的例子分析問題,通過畫圖的手段把抽象的問題形象化,從而解決這個相對比較復雜的問題,是能否順利通過面試的關鍵。
相關題目:
用兩個隊列實現一個棧。
我們通過一系列棧的壓入和彈出操作來分析用兩個隊列模擬一個棧的過程。如圖2.9(a)所示,我們先往棧內壓入一個元素a。由于兩個隊列現在都是空的,我們可以選擇把a插入兩個隊列的任意一個。我們不妨把a插入queue1。接下來繼續往棧內壓入b、c兩個元素,我們把它們都插入queue1。這個時候queue1包含3個元素a、b和c,其中a位于隊列的頭部,c位于隊列的尾部。
現在我們考慮從棧內彈出一個元素。根據棧的后入先出原則,最后被壓入棧的c應該最先被彈出。由于c位于queue1的尾部,而我們每次只能從隊列的頭部刪除元素,因此我們可以先從queue1中依次刪除元素a、b并插入到queue2中,再從queue1中刪除元素c。這就相當于從棧中彈出元素c了(如圖2.9(b)所示)。我們可以用同樣的方法從棧內彈出元素b(如圖2.9(c)所示)
接下來我們考慮往棧內壓入一個元素d。此時queue1已經有一個元素,我們就把d插入到queue1的尾部(如圖2.9(d)所示)。如果我們再從棧內彈出一個元素,此時被彈出的應該是最后被壓入的d。由于d位于queue1的尾部,我們只能先從頭刪除queue1的元素并插入到queue2,直到在queue1中遇到d再直接把它刪除(如圖2.9(e)所示)。
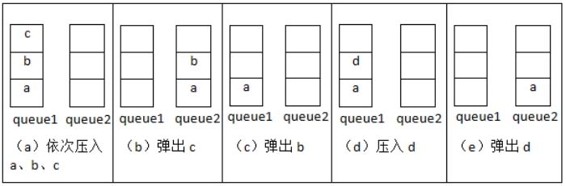
圖2.9 用兩個隊列模擬一個棧的操作
2.4 算法和數據操作
和數據結構一樣,考查算法的面試題也備受面試官的青睞,其中排序和查找是面試時考查算法的重點。在準備面試的時候,我們應該重點掌握二分查找、歸并排序和快速排序,做到能隨時正確、完整地寫出它們的代碼。
有很多算法都可以用遞歸和循環兩種不同的方式實現。通常基于遞歸的實現方法代碼會比較簡潔,但性能不如基于循環的實現方法。在面試的時候,我們可以根據題目的特點,甚至可以和面試官討論選擇合適的方法編程。
位運算可以看成是一類特殊的算法,它是把數字表示成二進制之后對0和1的操作。由于位運算的對象為二進制數字,所以不是很直觀,但掌握它也不難,因為總共只有與、或、異或、左移和右移5種位運算。
2.4.1 查找和排序
查找和排序都是在程序設計中經常用到的算法。查找相對而言較為簡單,不外乎順序查找、二分查找、哈希表查找和二叉排序樹查找。在面試的時候,不管是用循環還是用遞歸,面試官都期待應聘者能夠信手拈來寫出完整正確的二分查找代碼,否則可能連繼續面試的興趣都沒有。面試題8“旋轉數組的最小數字”和面試題38“數字在排序數組中出現的次數”都可以用二分查找算法解決。
面試小提示:
如果面試題是要求在排序的數組(或者部分排序的數組)中查找一個數字或者統計某個數字出現的次數,我們都可以嘗試用二分查找算法。
哈希表和二叉排序樹查找的重點在于考查對應的數據結構而不是算法。哈希表最主要的優點是我們利用它能夠在O(1)時間查找某一元素,是效率最高的查找方式。但其缺點是需要額外的空間來實現哈希表。面試題35“第一個只出現一次的字符”就是用哈希表的特性來高效查找。與二叉排序樹查找算法對應的數據結構是二叉搜索樹,我們將在面試題24“二叉搜索樹的后序遍歷序列”和面試題27“二叉搜索樹與雙向鏈表”中詳細介紹二叉搜索樹的特點。
排序比查找要復雜一些。面試官會經常要求應聘者比較插入排序、冒泡排序、歸并排序、快速排序等不同算法的優劣。強烈建議應聘者在準備面試的時候,一定要對各種排序算法的特點爛熟于胸,能夠從額外空間消耗、平均時間復雜度和最差時間復雜度等方面去比較它們的優缺點。需要特別強調的是,很多公司的面試官喜歡在面試環節中要求應聘者寫出快速排序的代碼。應聘者不妨自己寫一個快速排序的函數并用各種數據作測試。當測試都通過之后,再和經典的實現做比較,看看有什么區別。
實現快速排序算法的關鍵在于先在數組中選擇一個數字,接下來把數組中的數字分為兩部分,比選擇的數字小的數字移到數組的左邊,比選擇的數字大的數字移到數組的右邊。這個函數可以如下實現:

函數RandomInRange用來生成一個在start和end之間的隨機數,函數Swap的作用是用來交換兩個數字。接下來我們可以用遞歸的思路分別對每次選中的數字的左右兩邊排序。下面就是遞歸實現快速排序的參考代碼:

對一個長度為n的數組排序,只需把start設為0、把end設為n-1,調用函數QuickSort即可。
在前面的代碼中,函數Partition除了可以用在快速排序算法中,還可以用來實現在長度為n的數組中查找第k大的數字。面試題29“數組中出現次數超過一半的數字”和面試題30“最小的k個數”都可以用這個函數來解決。
不同的排序算法適用的場合也不盡相同。快速排序雖然總體的平均效率是最好的,但也不是任何時候都是最優的算法。比如數組本身已經排好序了,而每一輪排序的時候都是以最后一個數字作為比較的標準,此時快速排序的效率只有O(n2)。因此在這種場合快速排序就不是最優的算法。在面試的時候,如果面試官要求實現一個排序算法,那么應聘者一定要問清楚這個排序應用的環境是什么、有哪些約束條件,在得到足夠多的信息之后再選擇最合適的排序算法。下面來看一個面試的片段:
面試官:請實現一個排序算法,要求時間效率O(n)。
應聘者:對什么數字進行排序,有多少個數字?
面試官:我們想對公司所有員工的年齡排序。我們公司總共有幾萬名員工。
應聘者:也就是說數字的大小是在一個較小的范圍之內的,對吧?
面試官:嗯,是的。
應聘者:可以使用輔助空間嗎?
面試官:看你用多少輔助內存。只允許使用常量大小輔助空間,不得超過O(n)。
在面試的時候應聘者不要怕問面試官問題,只有多提問,應聘者才有可能明了面試官的意圖。在上面的例子中,該應聘者通過幾個問題就弄清楚了需排序的數字在一個較小的范圍內,并且還可以用輔助內存。知道了這些限制條件,就不難寫出如下的代碼了:

公司員工的年齡有一個范圍。在上面的代碼中,允許的范圍是0~99歲。數組timesOfAge用來統計每個年齡出現的次數。某個年齡出現了多少次,就在數組ages里設置幾次該年齡,這樣就相當于給數組ages排序了。該方法用長度100的整數數組作為輔助空間換來了O(n)的時間效率。
面試題8:旋轉數組的最小數字
題目:把一個數組最開始的若干個元素搬到數組的末尾,我們稱之為數組的旋轉。輸入一個遞增排序的數組的一個旋轉,輸出旋轉數組的最小元素。例如數組{3,4,5,1,2}為{1,2,3,4,5}的一個旋轉,該數組的最小值為1。
這道題最直觀的解法并不難,從頭到尾遍歷數組一次,我們就能找出最小的元素。這種思路的時間復雜度顯然是O(n)。但是這個思路沒有利用輸入的旋轉數組的特性,肯定達不到面試官的要求。
我們注意到旋轉之后的數組實際上可以劃分為兩個排序的子數組,而且前面的子數組的元素都大于或者等于后面子數組的元素。我們還注意到最小的元素剛好是這兩個子數組的分界線。在排序的數組中我們可以用二分查找法實現O(logn)的查找。本題給出的數組在一定程度上是排序的,因此我們可以試著用二分查找法的思路來尋找這個最小的元素。
和二分查找法一樣,我們用兩個指針分別指向數組的第一個元素和最后一個元素。按照題目中旋轉的規則,第一個元素應該是大于或者等于最后一個元素的(這其實不完全對,還有特例,后面再加以討論)。
接著我們可以找到數組中間的元素。如果該中間元素位于前面的遞增子數組,那么它應該大于或者等于第一個指針指向的元素。此時數組中最小的元素應該位于該中間元素的后面。我們可以把第一個指針指向該中間元素,這樣可以縮小尋找的范圍。移動之后的第一個指針仍然位于前面的遞增子數組之中。
同樣,如果中間元素位于后面的遞增子數組,那么它應該小于或者等于第二個指針指向的元素。此時該數組中最小的元素應該位于該中間元素的前面。我們可以把第二個指針指向該中間元素,這樣也可以縮小尋找的范圍。移動之后的第二個指針仍然位于后面的遞增子數組之中。
不管是移動第一個指針還是第二個指針,查找范圍都會縮小到原來的一半。接下來我們再用更新之后的兩個指針,重復做新一輪的查找。
按照上述的思路,第一個指針總是指向前面遞增數組的元素,而第二個指針總是指向后面遞增數組的元素。最終第一個指針將指向前面子數組的最后一個元素,而第二個指針會指向后面子數組的第一個元素。也就是它們最終會指向兩個相鄰的元素,而第二個指針指向的剛好是最小的元素。這就是循環結束的條件。
以前面的數組{3,4,5,1,2}為例,我們先把第一個指針指向第0個元素,把第二個指針指向第4個元素(如圖2.10(a)所示)。位于兩個指針中間(在數組中的下標是2)的數字是5,它大于第一個指針指向的數字。因此中間數字5一定位于第一個遞增子數組中,并且最小的數字一定位于它的后面。因此我們可以移動第一個指針讓它指向數組的中間(圖2.10(b)所示)。
此時位于這兩個指針中間(在數組中的下標是3)的數字是1,它小于第二個指針指向的數字。因此這個中間數字1一定位于第二個遞增字數組中,并且最小的數字一定位于它的前面或者它自己就是最小的數字。因此我們可以移動第二個指針指向兩個指針中間的元素即下標為3的元素(如圖2.10(c)所示)。
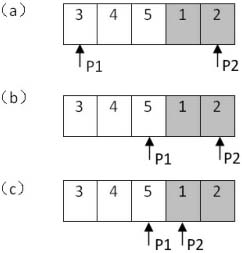
圖2.10 在數組{3,4,5,1,2}中查找最小值的過程
注:旋轉數組中包含兩個遞增排序的子數組,有陰影背景的是第二個子數組。(a)把P1指向數組的第一個數字,P2指向數組的最后一個數字。由于P1和P2中間的數字5大于P1指向的數字,中間的數字在第一個子數組中。下一步把P1指向中間的數字。(b)P1和P2中間的數字1小于P2指向的數字,中間的數字在第二個子數組中。下一步把P2指向中間的數字。(c)P1和P2指向兩個相鄰的數字,則P2指向的是數組中的最小數字。
此時兩個指針的距離是1,表明第一個指針已經指向了第一個遞增子數組的末尾,而第二個指針指向第二個遞增子數組的開頭。第二個子數組的第一個數字就是最小的數字,因此第二個指針指向的數字就是我們查找的結果。
基于這個思路,我們可以寫出如下代碼:

前面我們提到在旋轉數組中,由于是把遞增排序數組前面的若干個數字搬到數組的后面,因此第一個數字總是大于或者等于最后一個數字。但按照定義還有一個特例:如果把排序數組的前面的0個元素搬到最后面,即排序數組本身,這仍然是數組的一個旋轉,我們的代碼需要支持這種情況。此時,數組中的第一個數字就是最小的數字,可以直接返回。這就是在上面的代碼中,把indexMid初始化為index1的原因。一旦發現數組中第一個數字小于最后一個數字,表明該數組是排序的,就可以直接返回第一個數字了。
上述代碼是否就完美了呢?面試官會告訴我們其實不然。他將提示我們再仔細分析下標為index1和index2(index1和index2分別和圖中P1和P2相對應)的兩個數相同的情況。在前面的代碼中,當這兩個數相同,并且它們中間的數字(即indexMid指向的數字)也相同時,我們把indexMid賦值給了index1,也就是認為此時最小的數字位于中間數字的后面。是不是一定這樣?
我們再來看一個例子。數組{1,0,1,1,1}和數組{1,1,1,0,1}都可以看成是遞增排序數組{0,1,1,1,1}的旋轉,圖2.11分別畫出它們由最小數字分隔開的兩個子數組。

圖2.11 數組{0,1,1,1,1}的兩個旋轉{1,0,1,1,1}和{1,1,1,0,1}
注:在這兩個數組中,第一個數字、最后一個數字和中間數字都是1,我們無法確定中間的數字1屬于第一個遞增子數組還是屬于第二個遞增子數組。第二個子數組用灰色背景表示。
在這兩種情況中,第一個指針和第二個指針指向的數字都是1,并且兩個指針中間的數字也是1,這3個數字相同。在第一種情況中,中間數字(下標為2)位于后面的子數組;在第二種情況中,中間數字(下標為2)位于前面的子數組中。因此,當兩個指針指向的數字及它們中間的數字三者相同的時候,我們無法判斷中間的數字是位于前面的子數組中還是后面的子數組中,也就無法移動兩個指針來縮小查找的范圍。此時,我們不得不采用順序查找的方法。
在把問題分析清楚形成清晰的思路之后,我們就可以把前面的代碼修改為:

源代碼:
本題完整的源代碼詳見08\_MinNumberInRotatedArray項目。
測試用例:
● 功能測試(輸入的數組是升序排序數組的一個旋轉,數組中有重復數字或者沒有重復數字)。
● 邊界值測試(輸入的數組是一個升序排序的數組、只包含一個數字的數組)。
● 特殊輸入測試(輸入NULL指針)。
本題考點:
● 考查對二分查找的理解。本題變換了二分查找的條件,輸入的數組不是排序的,而是排序數組的一個旋轉。這要求我們對二分查找的過程有深刻的理解。
● 考查溝通學習能力。本題面試官提出了一個新的概念:數組的旋轉。我們要在很短時間內學習理解這個新概念。在面試過程中如果面試官提出新的概念,我們可以主動和面試官溝通,多問幾個問題把概念弄清楚。
● 考查思維的全面性。排序數組本身是數組旋轉的一個特例。另外,我們要考慮到數組中有相同數字的特例。如果不能很好地處理這些特例,就很難寫出讓面試官滿意的完美代碼。
2.4.2 遞歸和循環
如果我們需要重復地多次計算相同的問題,通常可以選擇用遞歸或者循環兩種不同的方法。遞歸是在一個函數的內部調用這個函數自身。而循環則是通過設置計算的初始值及終止條件,在一個范圍內重復運算。比如求1+2+…+n,我們可以用遞歸或者循環兩種方式求出結果。對應的代碼如下:

通常遞歸的代碼會比較簡潔。在上面的例子里,遞歸的代碼只有一個語句,而循環則需要4個語句。在樹的前序、中序、后序遍歷算法的代碼中,遞歸的實現明顯要比循環簡單得多。在面試的時候,如果面試官沒有特別的要求,應聘者可以盡量多采用遞歸。
面試小提示:
通常基于遞歸實現的代碼比基于循環實現的代碼要簡潔很多,更加容易實現。如果面試官沒有特殊要求,應聘者可以優先采用遞歸的方法編程。
遞歸雖然有簡潔的優點,但它同時也有顯著的缺點。遞歸由于是函數調用自身,而函數調用是有時間和空間的消耗的:每一次函數調用,都需要在內存棧中分配空間以保存參數、返回地址及臨時變量,而且往棧里壓入數據和彈出數據都需要時間。這就不難理解上述的例子中遞歸實現的效率不如循環。
另外,遞歸中有可能很多計算都是重復的,從而對性能帶來很大的負面影響。遞歸的本質是把一個問題分解成兩個或者多個小問題。如果多個小問題存在相互重疊的部分,那么就存在重復的計算。在面試題9“斐波那契數列”及面試題43“n個骰子的點數”中我們將詳細地分析遞歸和循環的性能區別。
除了效率之外,遞歸還有可能引起更嚴重的問題:調用棧溢出。前面分析中提到需要為每一次函數調用在內存棧中分配空間,而每個進程的棧的容量是有限的。當遞歸調用的層級太多時,就會超出棧的容量,從而導致調用棧溢出。在上述例子中,如果輸入的參數比較小,如10,它們都能返回結果55。但如果輸入的參數很大,如5000,那么遞歸代碼在運行的時候就會出錯,但運行循環的代碼能得到正確的結果12502500。
面試題9:斐波那契數列
題目一:寫一個函數,輸入n,求斐波那契(Fibonacci)數列的第n項。斐波那契數列的定義如下:
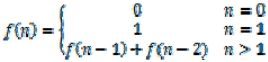
效率很低的解法,挑剔的面試官不會喜歡
很多C語言教科書在講述遞歸函數的時候,都會用Fibonacci作為例子,因此很多應聘者對這道題的遞歸解法都很熟悉。他們看到這道題的時候心中會忍不住一陣竊喜,因為他們能很快寫出如下代碼:

我們的教科書上反復用這個問題來講解遞歸函數,并不能說明遞歸的解法最適合這道題目。面試官會提示我們上述遞歸的解法有很嚴重的效率問題并要求我們分析原因。
我們以求解f(10)為例來分析遞歸的求解過程。想求得f(10),需要先求得f(9)和f(8)。同樣,想求得f(9),需要先求得f(8)和f(7)……我們可以用樹形結構來表示這種依賴關系,如圖2.12所示。
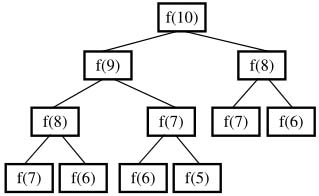
圖2.12 基于遞歸求斐波那契數列的第10項的調用過程
我們不難發現在這棵樹中有很多結點是重復的,而且重復的結點數會隨著n的增大而急劇增加,這意味計算量會隨著n的增大而急劇增大。事實上,用遞歸方法計算的時間復雜度是以n的指數的方式遞增的。讀者不妨求Fibonacci的第100項試試,感受一下這樣遞歸會慢到什么程度。
面試官期待的實用解法
其實改進的方法并不復雜。上述遞歸代碼之所以慢是因為重復的計算太多,我們只要想辦法避免重復計算就行了。比如我們可以把已經得到的數列中間項保存起來,如果下次需要計算的時候我們先查找一下,如果前面已經計算過就不用再重復計算了。
更簡單的辦法是從下往上計算,首先根據f(0)和f(1)算出f(2),再根據f(1)和f(2)算出f(3)……依此類推就可以算出第n項了。很容易理解,這種思路的時間復雜度是O(n)。實現代碼如下:

時間復雜度O(logn)但不夠實用的解法
通常面試到這里也就差不多了,盡管我們還有比這更快的O(logn)算法。由于這種算法需要用到一個很生僻的數學公式,因此很少有面試官會要求我們掌握。不過以防不時之需,我們還是簡要介紹一下這種算法。
在介紹這種方法之前,我們先介紹一個數學公式:
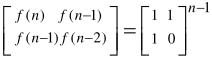
這個公式用數學歸納法不難證明,感興趣的讀者不妨自己證明一下。有了這個公式,我們只需要求得矩陣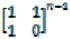即可得到f(n)。現在的問題轉為如何求矩陣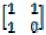的乘方。如果只是簡單地從0開始循環,n次方需要n次運算,那其時間復雜度仍然是O(n),并不比前面的方法快。但我們可以考慮乘方的如下性質:
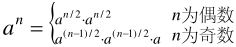
從上面的公式我們可以看出,我們想求得n次方,就要先求得n/2次方,再把n/2次方的結果平方一下即可。這可以用遞歸的思路實現。
由于很少有面試官要求編程實現這種思路,本書中不再列出完整的代碼,感興趣的讀者請參考附帶的源代碼。不過這種基于遞歸用O(logn)的時間求得n次方的算法卻值得我們重視。我們在面試題11“數值的整數次方”中再詳細討論這種算法。
解法比較
用不同的方法求解斐波那契數列的時間效率大不相同。第一種基于遞歸的解法雖然直觀但時間效率很低,在實際軟件開發中不會用這種方法,也不可能得到面試官的青睞。第二種方法把遞歸的算法用循環實現,極大地提高了時間效率。第三種方法把求斐波那契數列轉換成求矩陣的乘方,是一種很有創意的算法。雖然我們可以用O(logn)求得矩陣的n次方,但由于隱含的時間常數較大,很少會有軟件采用這種算法。另外,實現這種解法的代碼也很復雜,不太適用面試。因此第三種方法不是一種實用的算法,不過應聘者可以用它來展示自己的知識面。
除了面試官直接要求編程實現斐波那契數列之外,還有不少面試題可以看成是斐波那契數列的應用,比如:
題目二:一只青蛙一次可以跳上1級臺階,也可以跳上2級。求該青蛙跳上一個n級的臺階總共有多少種跳法。
首先我們考慮最簡單的情況。如果只有1級臺階,那顯然只有一種跳法。如果有2級臺階,那就有兩種跳的方法了:一種是分兩次跳,每次跳1級;另外一種就是一次跳2級。
接著我們再來討論一般情況。我們把n級臺階時的跳法看成是n的函數,記為f(n)。當n>2時,第一次跳的時候就有兩種不同的選擇:一是第一次只跳1級,此時跳法數目等于后面剩下的n-1級臺階的跳法數目,即為f(n-1);另外一種選擇是第一次跳2級,此時跳法數目等于后面剩下的n-2級臺階的跳法數目,即為f(n-2)。因此n級臺階的不同跳法的總數f(n)=f(n-1)+f(n-2)。分析到這里,我們不難看出這實際上就是斐波那契數列了。
源代碼:
本題完整的源代碼詳見09\_Fibonacci項目。
測試用例:
● 功能測試(如輸入3、5、10等)。
● 邊界值測試(如輸入0、1、2)。
● 性能測試(輸入較大的數字,如40、50、100等)。
本題考點:
● 考查對遞歸、循環的理解及編碼能力。
● 考查對時間復雜度的分析能力。
● 如果面試官采用的是青蛙跳臺階的問題,那同時還在考查應聘者的數學建模能力。
本題擴展:
在青蛙跳臺階的問題中,如果把條件改成:一只青蛙一次可以跳上1級臺階,也可以跳上2級……它也可以跳上n級,此時該青蛙跳上一個n級的臺階總共有多少種跳法?我們用數學歸納法可以證明f(n)=2n-1。
相關題目:
我們可以用2×1(圖2.13的左邊)的小矩形橫著或者豎著去覆蓋更大的矩形。請問用8個2×1的小矩形無重疊地覆蓋一個2×8的大矩形(圖2.13的右邊),總共有多少種方法?

圖2.13 一個2×1的矩形和2×8的矩形
我們先把2×8的覆蓋方法記為f(8)。用第一個1×2小矩形去覆蓋大矩形的最左邊時有兩個選擇,豎著放或者橫著放。當豎著放的時候,右邊還剩下2×7的區域,這種情形下的覆蓋方法記為f(7)。接下來考慮橫著放的情況。當1×2的小矩形橫著放在左上角的時候,左下角必須和橫著放一個1×2的小矩形,而在右邊還還剩下2×6的區域,這種情形下的覆蓋方法記為f(6),因此f(8)=f(7)+f(6)。此時我們可以看出,這仍然是斐波那契數列。
2.4.3 位運算
位運算是把數字用二進制表示之后,對每一位上0或者1的運算。二進制及其位運算是現代計算機學科的基石,很多底層的技術都離不開位運算,因此位運算相關的題目也經常出現在面試中。由于我們在日常生活中習慣了十進制,很多人看到二進制及位運算都覺得很難適應。
理解位運算的第一步是理解二進制。二進制是指數字的每一位都是0或者1。比如十進制的2轉化為二進制之后是10,而十進制的10轉換成二進制之后是1010。在程序員圈子里有一個流傳了很久的笑話,說世界上有10種人,一種人知道二進制,而另一種人不知道二進制……
除了二進制,我們還可以把數字表示成其他進制,比如表示時間分秒的六十進制等。針對不太熟悉的進制,已經出現了不少很有意思的面試題。比如:
在Excel 2003中,用A表示第1列,B表示第2列……Z表示第26列,AA表示第27列,AB表示第28列……以此類推。請寫出一個函數,輸入用字母表示的列號編碼,輸出它是第幾列。
這是一道很新穎的關于進制的題目,其本質是把十進制數字用A~Z表示成二十六進制。如果想到這一點,解決這個問題就不難了。
其實二進制的位運算并不是很難掌握,因為位運算總共只有五種運算:與、或、異或、左移和右移。與、或和異或運算的規律我們可以用表2.1總結如下:
表2.1 與、或、異或的運算規律

左移運算符m<<n表示把m左移n位。左移n位的時候,最左邊的n位將被丟棄,同時在最右邊補上n個0。比如:
00001010<<2=00101000
10001010<<3=01010000
右移運算符m>>n表示把m右移n位。右移n位的時候,最右邊的n位將被丟棄。但右移時處理最左邊位的情形要稍微復雜一點。如果數字是一個無符號數值,則用0填補最左邊的n位。如果數字是一個有符號數值,則用數字的符號位填補最左邊的n位。也就是說如果數字原先是一個正數,則右移之后在最左邊補n個0;如果數字原先是負數,則右移之后在最左邊補n個1。下面是對兩個8位有符號數作右移的例子:
00001010>>2=00000010
10001010>>3=11110001
面試題10“二進制中1的個數”就是直接考查位運算的例子,而面試題40“數組中只出現一次的數字”、面試題47“不用加減乘除做加法”等都是根據位運算的特點來解決問題。
面試題10:二進制中1的個數
題目:請實現一個函數,輸入一個整數,輸出該數二進制表示中1的個數。例如把9表示成二進制是1001,有2位是1。因此如果輸入9,該函數輸出2。
可能引起死循環的解法
這是一道很基本的考查二進制和位運算的面試題。題目不是很難,面試官提出問題之后,我們很快就能形成一個基本的思路:先判斷整數二進制表示中最右邊一位是不是1。接著把輸入的整數右移一位,此時原來處于從右邊數起的第二位被移到最右邊了,再判斷是不是1。這樣每次移動一位,直到整個整數變成0為止。現在的問題變成怎么判斷一個整數的最右邊是不是1了。這很簡單,只要把整數和1做位與運算看結果是不是0就知道了。1除了最右邊的一位之外所有位都是0。如果一個整數與1做與運算的結果是1,表示該整數最右邊一位是1,否則是0。基于這個思路,我們很快就能寫出如下代碼:

面試官看了代碼之后可能會問:把整數右移一位和把整數除以2在數學上是等價的,那上面的代碼中可以把右移運算換成除以2嗎?答案是否定的。因為除法的效率比移位運算要低得多,在實際編程中應盡可能地用移位運算符代替乘除法。
面試官接下來可能要問的第二個問題就是:上面的函數如果輸入一個負數,比如0x80000000,運行的時候會發生什么情況?把負數0x80000000右移一位的時候,并不是簡單地把最高位的1移到第二位變成0x40000000,而是0xC0000000。這是因為移位前是個負數,仍然要保證移位后是個負數,因此移位后的最高位會設為1。如果一直做右移運算,最終這個數字就會變成0xFFFFFFFF而陷入死循環。
常規解法
為了避免死循環,我們可以不右移輸入的數字i。首先把i和1做與運算,判斷i的最低位是不是為1。接著把1左移一位得到2,再和i做與運算,就能判斷i的次低位是不是1……這樣反復左移,每次都能判斷i的其中一位是不是1。基于這種思路,我們可以把代碼修改如下:

這個解法中循環的次數等于整數二進制的位數,32位的整數需要循環32次。下面再介紹一種算法,整數中有幾個1就只需要循環幾次。
能給面試官帶來驚喜的解法
在分析這種算法之前,我們先來分析把一個數減去1的情況。如果一個整數不等于0,那么該整數的二進制表示中至少有一位是1。先假設這個數的最右邊一位是1,那么減去1時,最后一位變成0而其他所有位都保持不變。也就是最后一位相當于做了取反操作,由1變成了0。
接下來假設最后一位不是1而是0的情況。如果該整數的二進制表示中最右邊1位于第m位,那么減去1時,第m位由1變成0,而第m位之后的所有0都變成1,整數中第m位之前的所有位都保持不變。舉個例子:一個二進制數1100,它的第二位是從最右邊數起的一個1。減去1后,第二位變成0,它后面的兩位0變成1,而前面的1保持不變,因此得到的結果是1011。
在前面兩種情況中,我們發現把一個整數減去1,都是把最右邊的1變成0。如果它的右邊還有0的話,所有的0都變成1,而它左邊所有位都保持不變。接下來我們把一個整數和它減去1的結果做位與運算,相當于把它最右邊的1變成0。還是以前面的1100為例,它減去1的結果是1011。我們再把1100和1011做位與運算,得到的結果是1000。我們把1100最右邊的1變成了0,結果剛好就是1000。
我們把上面的分析總結起來就是:把一個整數減去1,再和原整數做與運算,會把該整數最右邊一個1變成0。那么一個整數的二進制表示中有多少個1,就可以進行多少次這樣的操作。基于這種思路,我們可以寫出新的代碼:

源代碼:
本題完整的源代碼詳見10\_NumberOf1InBinary項目。
測試用例:
● 正數(包括邊界值1、0x7FFFFFFF)。
● 負數(包括邊界值0x80000000、0xFFFFFFFF)。
● 0。
本題考點:
● 考查對二進制及位運算的理解。
● 考查分析、調試代碼的能力。如果應聘者在面試過程中采用的是第一種思路,當面試官提示他輸入負數將會出現問題時,面試官會期待他能在心中運行代碼,自己找出運行出現死循環的原因。這要求應聘者有一定的調試功底。
相關題目:
● 用一條語句判斷一個整數是不是2的整數次方。一個整數如果是2的整數次方,那么它的二進制表示中有且只有一位是1,而其他所有位都是0。根據前面的分析,把這個整數減去1之后再和它自己做與運算,這個整數中唯一的1就會變成0。
● 輸入兩個整數m和n,計算需要改變m的二進制表示中的多少位才能得到n。比如10的二進制表示為1010,13的二進制表示為1101,需要改變1010中的3位才能得到1101。我們可以分為兩步解決這個問題:第一步求這兩個數的異或,第二步統計異或結果中1的位數。
舉一反三:
把一個整數減去1之后再和原來的整數做位與運算,得到的結果相當于是把整數的二進制表示中的最右邊一個1變成0。很多二進制的問題都可以用這個思路解決。
2.5 本章小結
本章著重介紹應聘者在面試之前應該認真準備的基礎知識。為了應對編程面試,應聘者需要從編程語言、數據結構和算法3方面做好準備。
面試官通常采用概念題、代碼分析題及編程題這3種常見題型來考查應聘者對某一編程語言的掌握程度。本章的2.2節討論了C++/C#語言這3種題型的常見面試題。
數據結構題目一直是面試官考查的重點。數組和字符串是兩種最基本的數據結構。鏈表應該是面試題中使用頻率最高的一種數據結構。如果面試官想加大面試的難度,他很有可能會選用與樹(尤其是二叉樹)相關的面試題。由于棧與遞歸調用密切相關,隊列在圖(包括樹)的寬度優先遍歷中需要用到,因此應聘者也需要掌握這兩種數據結構。
算法是面試官喜歡考查的另外一個重點。查找(特別是二分查找)和排序(特別是快速排序和歸并排序)是面試中最經常考查的算法,應聘者一定要熟練掌握。另外,應聘者還要掌握分析時間復雜度的方法,理解即使是同一思路,基于循環和遞歸的不同實現它們的時間復雜度可能大不相同。
位運算是針對二進制數字的運算規律。只要應聘者熟練掌握了二進制的與、或、異或運算及左移、右移操作,就能解決與位運算相關的面試題。
- 目錄
- 扉頁
- 版權頁
- 推薦序一
- 推薦序二
- 前言
- 第1章 面試的流程
- 1.1 面試官談面試
- 1.2 面試的三種形式
- 1.2.1 電話面試
- 1.2.2 共享桌面遠程面試
- 1.2.3 現場面試
- 1.3 面試的三個環節
- 1.3.1 行為面試環節
- 1.應聘者的項目經驗
- 2.應聘者掌握的技能
- 3.回答“為什么跳槽”
- 1.3.2 技術面試環節
- 1.扎實的基礎知識
- 2.高質量的代碼
- 3.清晰的思路
- 4.優化效率的能力
- 5.優秀的綜合能力
- 1.3.3 應聘者提問環節
- 1.4 本章小結
- 第2章 面試需要的基礎知識
- 2.1 面試官談基礎知識
- 2.2 編程語言
- 2.2.1 C++
- 面試題1:賦值運算符函數
- 經典的解法,適用于初級程序員
- 考慮異常安全性的解法,高級程序員必備
- 2.2.2 C#
- 面試題2:實現Singleton模式
- 不好的解法一:只適用于單線程環境
- 不好的解法二:雖然在多線程環境中能工作但效率不高
- 可行的解法:加同步鎖前后兩次判斷實例是否已存在
- 強烈推薦的解法一:利用靜態構造函數
- 強烈推薦的解法二:實現按需創建實例
- 解法比較
- 2.3 數據結構
- 2.3.1 數組
- 面試題3:二維數組中的查找
- 2.3.2 字符串
- 面試題4:替換空格
- 時間復雜度為O(n2)的解法,不足以拿到Offer
- 時間復雜度為O(n)的解法,搞定Offer就靠它了
- 2.3.3 鏈表
- 面試題5:從尾到頭打印鏈表
- 2.3.4 樹
- 面試題6:重建二叉樹
- 2.3.5 棧和隊列
- 面試題7:用兩個棧實現隊列
- 2.4 算法和數據操作
- 2.4.1 查找和排序
- 面試題8:旋轉數組的最小數字
- 2.4.2 遞歸和循環
- 面試題9:斐波那契數列
- 效率很低的解法,挑剔的面試官不會喜歡
- 面試官期待的實用解法
- 時間復雜度O(logn)但不夠實用的解法
- 解法比較
- 2.4.3 位運算
- 面試題10:二進制中1的個數
- 可能引起死循環的解法
- 常規解法
- 能給面試官帶來驚喜的解法
- 2.5 本章小結
- 第3章 高質量的代碼
- 3.1 面試官談代碼質量
- 3.2 代碼的規范性
- 3.3 代碼的完整性
- 1.從3方面確保代碼的完整性
- 2.3種錯誤處理的方法
- 面試題11:數值的整數次方
- 自以為題目簡單的解法
- 全面但不夠高效的解法,我們離Offer已經很近了
- 全面又高效的解法,確保我們能拿到Offer
- 面試題12:打印1到最大的n位數
- 跳進面試官陷阱
- 在字符串上模擬數字加法的解法,繞過陷阱才能拿到Offer
- 把問題轉換成數字排列的解法,遞歸讓代碼更簡潔
- 面試題13:在O(1)時間刪除鏈表結點
- 面試題14:調整數組順序使奇數位于偶數前面
- 只完成基本功能的解法,僅適用于初級程序員
- 考慮可擴展性的解法,能秒殺Offer
- 3.4 代碼的魯棒性
- 面試題15:鏈表中倒數第k個結點
- 面試題16:反轉鏈表
- 面試題17:合并兩個排序的鏈表
- 面試題18:樹的子結構
- 3.5 本章小結
- 第4章 解決面試題的思路
- 4.1 面試官談面試思路
- 4.2 畫圖讓抽象問題形象化
- 面試題19:二叉樹的鏡像
- 面試題20:順時針打印矩陣
- 4.3 舉例讓抽象問題具體化
- 面試題21:包含min函數的棧
- 面試題22:棧的壓入、彈出序列
- 面試題23:從上往下打印二叉樹
- 面試題24:二叉搜索樹的后序遍歷序列
- 面試題25:二叉樹中和為某一值的路徑
- 4.4 分解讓復雜問題簡單化
- 面試題26:復雜鏈表的復制
- 面試題27:二叉搜索樹與雙向鏈表
- 面試題28:字符串的排列
- 4.5 本章小結
- 第5章 優化時間和空間效率
- 5.1 面試官談效率
- 5.2 時間效率
- 面試題29:數組中出現次數超過一半的數字
- 解法一:基于Partition函數的O(n)算法
- 解法二:根據數組特點找出O(n)的算法
- 解法比較
- 面試題30:最小的k個數
- 解法一:O(n)的算法,只有當我們可以修改輸入的數組時可用
- 解法二:O(nlogk)的算法,特別適合處理海量數據
- 解法比較
- 面試題31:連續子數組的最大和
- 解法一:舉例分析數組的規律
- 解法二:應用動態規劃法
- 面試題32:從1到n整數中1出現的次數
- 不考慮時間效率的解法,靠它想拿Offer有點難
- 從數字規律著手明顯提高時間效率的解法,能讓面試官耳目一新
- 面試題33:把數組排成最小的數
- 5.3 時間效率與空間效率的平衡
- 面試題34:丑數
- 逐個判斷每個整數是不是丑數的解法,直觀但不夠高效
- 創建數組保存已經找到的丑數,用空間換時間的解法
- 面試題35:第一個只出現一次的字符
- 面試題36:數組中的逆序對
- 面試題37:兩個鏈表的第一個公共結點
- 5.4 本章小結
- 第6章 面試中的各項能力
- 6.1 面試官談能力
- 6.2 溝通能力和學習能力
- 1.溝通能力
- 2.學習能力
- 3.善于學習、溝通的人也善于提問
- 6.3 知識遷移能力
- 面試題38:數字在排序數組中出現的次數
- 面試題39:二叉樹的深度
- 需要重復遍歷結點多次的解法,簡單但不足以打動面試官
- 每個結點只遍歷一次的解法,正是面試官喜歡的
- 面試題40:數組中只出現一次的數字
- 面試題41:和為s的兩個數字VS和為s的連續正數序列
- 面試題42:翻轉單詞順序VS左旋轉字符串
- 6.4 抽象建模能力
- 面試題43:n個骰子的點數
- 解法一:基于遞歸求骰子點數,時間效率不夠高
- 解法二:基于循環求骰子點數,時間性能好
- 面試題44:撲克牌的順子
- 面試題45:圓圈中最后剩下的數字
- 經典的解法,用環形鏈表模擬圓圈
- 創新的解法,拿到Offer不在話下
- 6.5 發散思維能力
- 面試題46:求1+2+…+n
- 解法一:利用構造函數求解
- 解法二:利用虛函數求解
- 解法三:利用函數指針求解
- 解法四:利用模板類型求解
- 面試題47:不用加減乘除做加法
- 面試題48:不能被繼承的類
- 常規的解法:把構造函數設為私有函數
- 新奇的解法:利用虛擬繼承,能給面試官留下很好的印象
- 6.6 本章小結
- 第7章 兩個面試案例
- 7.1 案例一:(面試題49)把字符串轉換成整數
- 7.2 案例二:(面試題50)樹中兩個結點的最低公共祖先