
第3章 高質量的代碼
3.1 面試官談代碼質量
“一般會考查代碼的容錯處理能力,對一些特別的輸入會詢問應聘人員是否考慮、如何處理。不能容忍代碼只是針對一種假想的‘正常值’進行處理,不考慮異常狀況,也不考慮資源的回收等問題。”
——殷焰(支付寶,高級安全測試工程師)
“如果是因為粗心犯錯,可以原諒,因為畢竟面試的時候會緊張;不能容忍的是,該掌握的知識點卻沒有掌握,而且提醒了還不知道。比如下面的:

注:1 由于精度原因不能用等號判斷兩個小數是否相等,請參考面試題11“數值的整數次方”。
——馬凌洲(Autodesk,Software Development Manager)
“最不能容忍功能錯誤,忽略邊界情況。”
——尹彥(Intel,Software Engineer)
“如果一個程序員連變量、函數命名都毫無章法,解決一個具體問題都找不到一個最合適的數據結構,這會讓面試官印象大打折扣,因為這個只能說明他程序寫得太少,不夠熟悉。”
——吳斌(NVidia,Graphics Architect)
“我會從程序的正確性和魯棒性兩方面檢驗代碼的質量。會關注對輸入參數的檢查、處理錯誤和異常的方式、命名方式等。對于沒有工作經驗的學生,程序正確性之外的錯誤基本都能容忍,但經過提示后希望能夠很快解決。對于有工作經驗的人,不能容忍考慮不周到、有明顯的魯棒性錯誤。”
——田超(微軟,SDE II)
3.2 代碼的規范性
面試官是根據應聘者寫出的代碼來決定是否錄用他的。如果應聘者代碼寫得不夠規范,影響面試官閱讀代碼的興致,那面試官就會默默地減去幾分。如圖3.1所示,書寫、布局和命名都決定著代碼的規范性。
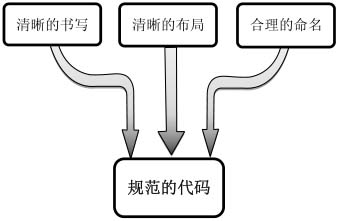
圖3.1 影響代碼規范性的因素:書寫、布局和命名
首先,規范的代碼書寫清晰。絕大部分面試都是要求應聘者在白紙或者白板上書寫。由于現代人已經習慣了敲鍵盤打字,手寫變得越來越不習慣,因此寫出來的字潦草難辨。雖然應聘者沒有必要為了面試特意去練字,但在面試過程中減慢寫字的速度,盡量把每個字母寫清楚還是很有必要的。不用擔心沒有時間去寫代碼,通常編程面試的代碼量都不會超過50行,書寫不用花多少時間,關鍵是在寫代碼之前形成清晰的思路并能把思路用編程語言清楚地書寫出來。
其次,規范的代碼布局清晰。平時程序員在集成開發環境如Visual Studio里面寫代碼,依靠專業工具調整代碼的布局,加入合理的縮進并讓括號對齊成對呈現。離開了這些工具手寫代碼,我們就要格外注意布局問題。當循環、判斷較多,邏輯較復雜時,縮進的層次可能會比較多。如果布局不夠清晰,縮進也不能體現代碼的邏輯,面試官面對這樣的代碼將會頭暈腦脹。
最后,規范的代碼命名合理。很多初學編程的人在寫代碼時總是習慣用最簡單的名字來命名,變量名是i、j、k,函數名是f、g、h。由于這樣的名字不能告訴讀者對應的變量或者函數的意義,代碼一長就會變得晦澀難懂。強烈建議應聘者在寫代碼的時候,用完整的英文單詞組合命名變量和函數,比如函數需要傳入一個二叉樹的根結點作為參數,則可以把該參數命名為BinaryTreeNode\* pRoot,不要因為這樣會多寫幾個字母而覺得麻煩。如果一眼能看出變量、函數的用途,應聘者就能避免自己搞混淆而犯一些低級的錯誤。同時合理的命名也能讓面試官一眼就能讀懂代碼的意圖,而不是讓他去猜變量m到底是數組中的最大值還是最小值。
面試小提示:
應聘者在寫代碼的時候,最好用完整的英文單詞組合命名變量和函數,以便面試官能一眼讀懂代碼的意圖。
3.3 代碼的完整性
在面試的過程中,面試官會非常關注應聘者考慮問題是否周全。面試官通過檢查代碼是否完整來考查應聘者的思維是否全面。通常面試官會檢查應聘者的代碼是否完成了基本功能、輸入邊界值是否能得到正確的輸出、是否對各種不合規范的非法輸入做出了合理的錯誤處理。
1.從3方面確保代碼的完整性
應聘者在寫代碼之前,首先要把可能的輸入都想清楚,從而避免在程序中出現各種各樣的質量漏洞。也就是說在編碼之前要考慮單元測試。如果能夠設計全面的單元測試用例并在代碼中體現出來,那么寫出的代碼自然也就是完整正確的了。通常我們可以從功能測試、邊界測試和負面測試三方面設計測試用例,以確保代碼的完整性(如圖3.2所示)。
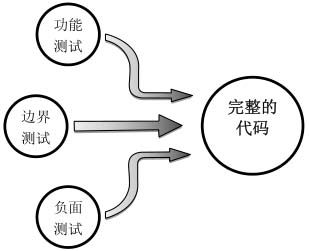
圖3.2 從功能測試、邊界測試、負面測試3個方面設計測試用例,以保證代碼的完整性
首先要考慮的是普通功能測試的測試用例。我們首先要保證寫出的代碼能夠完成面試官要求的基本功能。比如面試題要求完成的功能是把字符串轉換成整數,我們就可以考慮輸入字符串”123”來測試自己寫的代碼。這里要把零、正數和負數都考慮進去。
考慮功能測試的時候,我們要盡量突破常規思維的限制。面試的時候我們經常受到慣性思維的限制,從而看不到更多的功能需求。比如面試題12“打印1到最大的n位數”,很多人覺得這題很簡單。最大的3位數是999、最大的4位數是9999,這些數字很容易就能算出來。但是最大的n位數都能用int型表示嗎?超出int的范圍我們可以考慮long long類型,超出long long能夠表示的范圍呢?面試官是不是要求考慮任意大的數字?如果面試官確認題目要求的是任意大的數字,那么這個題目就是一個大數問題,此時我們需要特殊的數據結構來表示數字,比如用字符串或者數組來表示大的數字,以確保不會溢出。
其次需要考慮各種邊界值的測試用例。很多時候我們的代碼中都會有循環或者遞歸。如果我們的代碼是基于循環,那么結束循環的邊界條件是否正確?如果是遞歸,遞歸終止的邊界值是否正確?這些都是邊界測試時要考慮的用例。還是以字符串轉換成整數的問題為例,我們寫出的代碼應該確保能夠正確轉換最大的正整數和最小的負整數。
最后還需要考慮各種可能的錯誤的輸入,也就是通常所說的負面測試的測試用例。我們寫出的函數除了要順利地完成要求的功能之外,當輸入不符合要求的時候還能做出合理的錯誤處理。在設計把字符串轉換成整數的函數的時候,我們就要考慮當輸入的字符串不是一個數字,比如”1a2b3c”,我們怎么告訴函數的調用者這個輸入是非法的。
前面我們說的都是要全面考慮當前需求對應的各種可能輸入。在軟件開發過程中,永遠不變的就是需求會一直改變。如果我們在面試的時候寫出的代碼能夠把將來需求可能的變化都考慮進去,在需求發生變化的時候能夠盡量減少代碼改動的風險,那我們就向面試官展示了自己對程序可擴展性和可維護性的理解,通過面試就是水到渠成的事情了。請參考面試題14“調整數組順序使奇數位于偶數前面”中關于可擴展性和可維護性的討論。
2.3種錯誤處理的方法
通常我們有3種方式把錯誤信息傳遞給函數的調用者。第一種方式是函數用返回值來告知調用者是否出錯。比如很多Windows的API就是這個類型。Windows中很多API的返回值為0表示API調用成功,而返回值不為0表示在API調用的過程中出錯了。微軟為不同的非零返回值定義了不同的意義,調用者可以根據這些返回值判斷出錯的原因。這種方式最大的問題是使用不便,因為函數不能直接把計算結果通過返回值賦值給其他變量,同時也不能把這個函數計算的結果直接作為參數傳遞給其他函數。
第二種方式是當發生錯誤時設置一個全局變量。此時我們可以在返回值中傳遞計算結果了。這種方法比第一種方法使用起來更加方便,因為調用者可以直接把返回值賦值給其他變量或者作為參數傳遞給其他函數。Windows的很多API運行出錯之后,也會設置一個全局變量。我們可以通過調用函數GetLastError分析這個表示錯誤的全局變量,從而得知出錯的原因。但這個方法有個問題:調用者很容易就會忘記去檢查全局變量,因此在調用出錯的時候忘記做相應的錯誤處理,從而留下安全隱患。
第三種方式是異常。當函數運行出錯的時候,我們就拋出一個異常,我們還可以根據不同的出錯原因定義不同的異常類型。因此函數的調用者根據異常的類型就能知道出錯的原因,從而做相應的處理。另外,我們能顯式劃分程序正常運行的代碼塊(try模塊)和處理異常的代碼塊(catch模塊),邏輯比較清晰。異常在高級語言如C#中是強烈推薦的錯誤處理方式,但有些早期的語言比如C語言還不支持異常。另外,當拋出異常的時候,程序的執行會打亂正常的順序,對程序的性能有很大的影響。
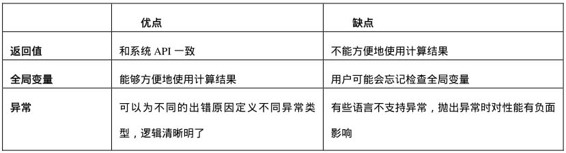
上述3種錯誤處理的方式各有其優缺點(如表3.1所示)。那么,面試的時候我們該采用哪種方式呢?這要看面試官的需求。在聽到面試官的題目之后,我們要盡快分析出可能存在哪些非法的輸入,并和面試官討論該如何處理這些非法輸入。
表3.1 返回值、全局變量和異常三種錯誤處理方式的優缺點比較
面試題11:數值的整數次方
題目:實現函數double Power(double base, int exponent),求base的exponent次方。不得使用庫函數,同時不需要考慮大數問題。
我們都知道在C語言的庫中有一個pow函數可以用來求乘方,本題要求實現類似于pow的功能。要求實現特定庫函數(特別是處理數值和字符串的函數)的功能,是一類常見的面試題。在本書收集的面試題中,除了這個題目外,還有面試題49“把字符串轉換成整數”要求實現庫函數atoi的功能。這就要求我們平時編程的時候除了能熟練使用庫函數外,更重要的是要理解庫函數的實現原理。
自以為題目簡單的解法
由于不需要考慮大數問題,這道題看起來很簡單,可能不少應聘者在看到題目30秒后就能寫出如下的代碼:

不過遺憾的是,寫得快不一定就能得到面試官的青睞,因為面試官會問要是輸入的指數(exponent)小于1即是零和負數的時候怎么辦?上面的代碼完全沒有考慮,只包括了指數是正數的情況。
全面但不夠高效的解法,我們離Offer已經很近了
我們知道當指數為負數的時候,可以先對指數求絕對值,然后算出次方的結果之后再取倒數。既然有求倒數,我們很自然就要想到有沒有可能對0求倒數,如果對0求倒數怎么辦?當底數(base)是零且指數是負數的時候,如果不做特殊處理,就會出現對0求倒數從而導致程序運行出錯。怎么告訴函數的調用者出現了這種錯誤?前面提到我們可以采用3種方法:返回值、全局代碼和異常。面試的時候可以向面試官闡述每種方法的優缺點,然后一起討論決定選用哪種方式。
最后需要指出的是,由于0的0次方在數學上是沒有意義的,因此無論是輸出0還是1都是可以接受的,但這都需要和面試官說清楚,表明我們已經考慮到這個邊界值了。
有了這些相對而言已經全面很多的考慮,我們就可以把最初的代碼修改如下:

在上述代碼中我們采用全局變量來標識是否出錯。如果出錯了,則返回的值是0。但為了區分是出錯的時候返回的0,還是底數為0的時候正常運行返回的0,我們還定義了一個全局變量g\_InvalidInput。當出錯時,這個變量被設為true,否則為false。這樣做的好處是,我們可以把返回值直接傳遞給其他變量,比如寫double result=Power(2,3),也可以把函數的返回值直接傳遞給其他需要double型參數的函數。但缺點是這個函數的調用者有可能會忘記去檢查g\_InvalidInput以判斷是否出錯,留下了安全隱患。由于有優點也有缺點,因此我們在寫代碼之前要和面試官討論采用哪種出錯處理方式最合適。
一個細節值得我們注意:在判斷底數base是不是等于0時,不能直接寫base==0,這是因為在計算機內表示小數時(包括float和double型小數)都有誤差。判斷兩個小數是否相等,只能判斷它們之差的絕對值是不是在一個很小的范圍內。如果兩個數相差很小,就可以認為它們相等。這就是我們定義函數equal的原因。
面試小提示:
由于計算機表示小數(包括float和double型小數)都有誤差,我們不能直接用等號(==)判斷兩個小數是否相等。如果兩個小數的差的絕對值很小,比如小于0.0000001,就可以認為它們相等。
此時我們考慮得已經很周詳了,已經能夠達到很多面試官的要求了。但是如果我們碰到的面試官是一個在效率上追求完美的人,那么他有可能會提醒我們函數PowerWithUnsignedExponent還有更快的辦法。
全面又高效的解法,確保我們能拿到Offer
如果輸入的指數exponent為32,我們在函數PowerWithUnsignedExponent的循環中需要做31次乘法。但我們可以換一種思路考慮:我們的目標是求出一個數字的32次方,如果我們已經知道了它的16次方,那么只要在16次方的基礎上再平方一次就可以了。而16次方是8次方的平方。這樣以此類推,我們求32次方只需要做5次乘法:先求平方,在平方的基礎上求4次方,在4次方的基礎上求8次方,在8次方的基礎上求16次方,最后在16次方的基礎上求32次方。
也就是說,我們可以用如下公式求a的n次方:
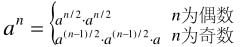
這個公式看起來是不是眼熟?我們前面在介紹用O(logn)時間求斐波那契數列時,就討論過這個公式,這個公式很容易就能用遞歸來實現。新的PowerWithUnsignedExponent代碼如下:

最后再提醒一個細節:我們用右移運算符代替了除以2,用位與運算符代替了求余運算符(%)來判斷一個數是奇數還是偶數。位運算的效率比乘除法及求余運算的效率要高很多。既然要優化代碼,我們就把優化做到極致。
在面試的時候,我們可以主動提醒面試官注意代碼中的兩處細節(判斷base是否等于0和用位運算替代乘除法及求余運算),讓他知道我們對編程的細節很重視。細節很重要,因為細節決定成敗,一兩個好的細節說不定就能讓面試官下定決心給我們Offer。
源代碼:
本題完整的源代碼詳見11\_Power項目。
測試用例:
把底數和指數分別設為正數、負數和零。
本題考點:
● 考查思維的全面性。這個問題本身不難,但能順利通過的應聘者不是很多。有很多人會忽視底數為0而指數為負數時的錯誤處理。
● 對效率要求比較高的面試官還會考查應聘者快速做乘方的能力。
面試題12:打印1到最大的n位數
題目:輸入數字n,按順序打印出從1最大的n位十進制數。比如輸入3,則打印出1、2、3一直到最大的3位數即999。
跳進面試官陷阱
這個題目看起來很簡單。我們看到這個問題之后,最容易想到的辦法是先求出最大的n位數,然后用一個循環從1開始逐個打印。于是我們很容易就能寫出如下的代碼:

初看之下好像沒有問題,但如果仔細分析這個問題,我們就能注意到面試官沒有規定n的范圍。當輸入的n很大的時候,我們求最大的n位數是不是用整型(int)或者長整型(long long)都會溢出?也就是說我們需要考慮大數問題。這是面試官在這道題里設置的一個大陷阱。
在字符串上模擬數字加法的解法,繞過陷阱才能拿到Offer
經過前面的分析,我們很自然地想到解決這個問題需要表達一個大數。最常用也是最容易的方法是用字符串或者數組表達大數。接下來我們用字符串來解決大數問題。
用字符串表示數字的時候,最直觀的方法就是字符串里每個字符都是’0’到’9’之間的某一個字符,用來表示數字中的一位。因為數字最大是n位的,因此我們需要一個長度為n+1的字符串(字符串中最后一個是結束符號’\\0’)。當實際數字不夠n位的時候,在字符串的前半部分補0。
首先我們把字符串中的每一個數字都初始化為’0’,然后每一次為字符串表示的數字加1,再打印出來。因此我們只需要做兩件事:一是在字符串表達的數字上模擬加法,二是把字符串表達的數字打印出來。
基于上面的分析,我們可以寫出如下代碼:

在上面的代碼中,函數Increment實現在表示數字的字符串number上增加1,而函數PrintNumber打印出number。這兩個看似簡單的函數都暗藏著小小的玄機。
我們需要知道什么時候停止在number上增加1,即什么時候到了最大的n位數“999…99”(n個9)。一個最簡單的辦法是每次遞增之后,都調用庫函數strcmp比較表示數字的字符串number和最大的n位數“999…99”,如果相等則表示已經到了最大的n位數并終止遞增。雖然調用strcmp很簡單,但對于長度為n的字符串,它的時間復雜度為O(n)。
我們注意到只有對“999…99”加1的時候,才會在第一個字符(下標為0)的基礎上產生進位,而其他所有情況都不會在第一個字符上產生進位。因此當我們發現在加1時第一個字符產生了進位,則已經是最大的n位數,此時Increment返回true,因此函數Print1ToMaxOfNDigits中的while循環終止。如何在每一次增加1之后快速判斷是不是到了最大的n位數是本題的一個小陷阱。下面是Increment函數的參考代碼,它實現了用O(1)時間判斷是不是已經到了最大的n位數:

接下來我們再考慮如何打印用字符串表示的數字。雖然庫函數printf可以很方便就能打印一個字符串,但在本題中調用printf并不是最合適的解決方案。前面我們提到,當數字不夠n位的時候,我們在數字的前面補0,打印的時候這些補位的0不應該打印出來。比如輸入3的時候,數字98用字符串表示成“098”。如果直接打印出098,就不符合我們的習慣。為此我們定義了函數PrintNumber,在這個函數里,我們只有在碰到第一個非0的字符之后才開始打印,直至字符串的結尾。能不能按照我們的閱讀習慣打印數字,是面試官設置的另外一個小陷阱。實現代碼如下:

把問題轉換成數字排列的解法,遞歸讓代碼更簡潔
上述思路雖然比較直觀,但由于模擬了整數的加法,代碼有點長。要在面試短短幾十分鐘時間里完整正確地寫出這么長的代碼,對很多應聘者而言不是一件容易的事情。接下來我們換一種思路來考慮這個問題。如果我們在數字前面補0的話,就會發現n位所有十進制數其實就是n個從0到9的全排列。也就是說,我們把數字的每一位都從0到9排列一遍,就得到了所有的十進制數。只是我們在打印的時候,數字排在前面的0我們不打印出來罷了。
全排列用遞歸很容易表達,數字的每一位都可能是0~9中的一個數,然后設置下一位。遞歸結束的條件是我們已經設置了數字的最后一位。

函數PrintNumber和前面第二種思路中的一樣,這里就不再重復了。
源代碼:
本題完整的源代碼詳見12\_Print1ToMaxOfNDigits項目。
測試用例:
● 功能測試(輸入1、2、3……)。
● 特殊輸入測試(輸入-1、0)。
本題考點:
● 考查解決大數問題的能力。面試官出這個題目的時候,他期望應聘者能意識到這是一個大數問題,同時還期待應聘者能定義合適的數據表示方式來解決大數問題。
● 如果應聘者采用第一種思路即在數上加1逐個打印的思路,面試官會關注他判斷是否已經到了最大的n位數時采用的方法。應聘者要注意到不同方法的時間效率相差很大。
● 如果應聘者采用第二種思路,面試官還將考查他用遞歸方法解決問題的能力。
● 面試官還將關注應聘者打印數字時會不會打印出位于數字最前面的0。這里能體現出應聘者在設計開發軟件時是不是會考慮用戶的使用習慣。通常我們的軟件設計和開發需要符合大部分用戶的人機交互習慣。
本題擴展:
在前面的代碼中,我們都是用一個char型字符表示十進制數字的一位。8個bit的char型字符最多能表示256個字符,而十進制數字只有0~9的10個數字。因此用char型字符串來表示十進制的數字并沒有充分利用內存,有一些浪費。有沒有更高效的方式來表示大數?
相關題目:
定義一個函數,在該函數中可以實現任意兩個整數的加法。由于沒有限定輸入兩個數的大小范圍,我們也要把它當做大數問題來處理。在前面的代碼的第一個思路中,實現了在字符串表示的數字上加1的功能,我們可以參考這個思路實現兩個數字的相加功能。另外還有一個需要注意的問題:如果輸入的數字中有負數,我們應該怎么去處理?
面試小提示:
如果面試題是關于n位的整數并且沒有限定n的取值范圍,或者是輸入任意大小的整數,那么這個題目很有可能是需要考慮大數問題的。字符串是一個簡單、有效的表示大數的方法。
面試題13:在O(1)時間刪除鏈表結點
題目:給定單向鏈表的頭指針和一個結點指針,定義一個函數在O(1)時間刪除該結點。鏈表結點與函數的定義如下:

在單向鏈表中刪除一個結點,最常規的做法無疑是從鏈表的頭結點開始,順序遍歷查找要刪除的結點,并在鏈表中刪除該結點。
比如在圖3.3(a)所示的鏈表中,我們想刪除結點i,可以從鏈表的頭結點a開始順序遍歷,發現結點h的m\_pNext指向要刪除的結點i,于是我們可以把結點h的m\_pNext指向i的下一個結點即結點j。指針調整之后,我們就可以安全地刪除結點i并保證鏈表沒有斷開(如圖3.3(b)所示)。這種思路由于需要順序查找,時間復雜度自然就是O(n)了。
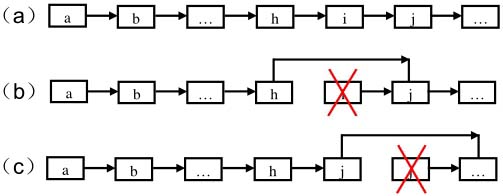
圖3.3 在鏈表中刪除一個結點的兩種方法
注:(a)一個鏈表。(b)刪除結點i之前,先從鏈表的頭結點開始遍歷到i前面的一個結點h,把h的m\_pNext指向i的下一個結點j,再刪除結點i。(c)把結點j的內容復制覆蓋結點i,接下來再把結點i的m\_pNext指向j的下一個結點之后刪除結點j。這種方法不用遍歷鏈表上結點i前面的結點。
之所以需要從頭開始查找,是因為我們需要得到將被刪除的結點的前面一個結點。在單向鏈表中,結點中沒有指向前一個結點的指針,所以只好從鏈表的頭結點開始順序查找。
那是不是一定需要得到被刪除的結點的前一個結點呢?答案是否定的。我們可以很方便地得到要刪除的結點的一下結點。如果我們把下一個結點的內容復制到需要刪除的結點上覆蓋原有的內容,再把下一個結點刪除,那是不是就相當于把當前需要刪除的結點刪除了?
我們還是以前面的例子來分析這種思路。我們要刪除結點i,先把i的下一個結點j的內容復制到i,然后把i的指針指向結點j的下一個結點。此時再刪除結點j,其效果剛好是把結點i給刪除了(如圖3.3(c)所示)。
上述思路還有一個問題:如果要刪除的結點位于鏈表的尾部,那么它就沒有下一個結點,怎么辦?我們仍然從鏈表的頭結點開始,順序遍歷得到該結點的前序結點,并完成刪除操作。
最后需要注意的是,如果鏈表中只有一個結點,而我們又要刪除鏈表的頭結點(也是尾結點),此時我們在刪除結點之后,還需要把鏈表的頭結點設置為NULL。
有了這些思路,我們就可以動手寫代碼了。下面是這種思路的參考代碼:

接下來我們分析這種思路的時間復雜度。對于n-1個非尾結點而言,我們可以在O(1)時把下一個結點的內存復制覆蓋要刪除的結點,并刪除下一個結點;對于尾結點而言,由于仍然需要順序查找,時間復雜度是O(n)。因此總的平均時間復雜度是\[(n-1)\*O(1)+O(n)\]/n,結果還是O(1),符合面試官的要求。
值得注意的是,上述代碼仍然不是完美的代碼,因為它基于一個假設:要刪除的結點的確在鏈表中。我們需要O(n)的時間才能判斷鏈表中是否包含某一結點。受到O(1)時間的限制,我們不得不把確保結點在鏈表中的責任推給了函數DeleteNode的調用者。在面試的時候,我們可以和面試官討論這個假設,這樣面試官就會覺得我們考慮問題非常全面。
源代碼:
本題完整的源代碼詳見13\_DeleteNodeInList項目。
測試用例:
● 功能測試(從有多個結點的鏈表的中間刪除一個結點,從有多個結點的鏈表中刪除頭結點,從有多個結點的鏈表中刪除尾結點,從只有一個結點的鏈表中刪除唯一的結點)。
● 特殊輸入測試(指向鏈表頭結點指針的為NULL指針,指向要刪除的結點為NULL指針)。
本題考點:
● 考查應聘者對鏈表的編程能力。
● 考查應聘者的創新思維能力。這道題要求應聘者打破常規的思維模式。當我們想刪除一個結點時,并不一定要刪除這個結點本身。可以先把下一個結點的內容復制出來覆蓋被刪除結點的內容,然后把下一個結點刪除。這種思路不是很容易想到的。
● 考查應聘者思維的全面性。即使應聘者想到刪除下一個結點這個辦法,也未必能通過這輪面試。應聘者要全面考慮到刪除的結點位于鏈表的尾部及輸入的鏈表只有一個結點這些特殊情況。
面試題14:調整數組順序使奇數位于偶數前面
題目:輸入一個整數數組,實現一個函數來調整該數組中數字的順序,使得所有奇數位于數組的前半部分,所有偶數位于數組的后半部分。
如果不考慮時間復雜度,最簡單的思路應該是從頭掃描這個數組,每碰到一個偶數時,拿出這個數字,并把位于這個數字后面的所有數字往前挪動一位。挪完之后在數組的末尾有一個空位,這時把該偶數放入這個空位。由于每碰到一個偶數就需要移動O(n)個數字,因此總的時間復雜度是O(n2)。但是,這種方法不能讓面試官滿意。不過如果我們在聽到題目之后馬上能說出這個解法,面試官至少會覺得我們的思維非常敏捷。
只完成基本功能的解法,僅適用于初級程序員
這個題目要求把奇數放在數組的前半部分,偶數放在數組的后半部分,因此所有的奇數應該位于偶數的前面。也就是說我們在掃描這個數組的時候,如果發現有偶數出現在奇數的前面,我們可以交換它們的順序,交換之后就符合要求了。
因此我們可以維護兩個指針,第一個指針初始化時指向數組的第一個數字,它只向后移動;第二個指針初始化時指向數組的最后一個數字,它只向前移動。在兩個指針相遇之前,第一個指針總是位于第二個指針的前面。如果第一個指針指向的數字是偶數,并且第二個指針指向的數字是奇數,我們就交換這兩個數字。
下面以一個具體的例子比如輸入數組{1,2,3,4,5}來分析這種思路。在初始化時,把第一個指針指向數組第一個數字1,而把第二個指針指向最后一個數字5(如圖3.4(a)所示)。第一個指針指向的數字1是一個奇數,不需要處理,我們把第一個指針向后移動,直到碰到一個偶數2。此時第二個指針已經指向了奇數,因此不需要移動。此時兩個指針指向的位置如圖3.4(b)所示。這個時候我們發現偶數2位于奇數5的前面,符合我們的交換條件,于是交換兩個指針指向的數字(如圖3.4(c)所示)。
接下來我們繼續向后移第一個指針,直到碰到下一個偶數4,并向前移動第二個指針,直到碰到第一個奇數3(如圖3.4(d)所示)。我們發現第二個指針已經在第一個指針的前面了,表示所有的奇數都已經在偶數的前面了。此時的數組是{1,5,3,4,2},的確是奇數位于數組的前半部分而偶數位于后半部分。
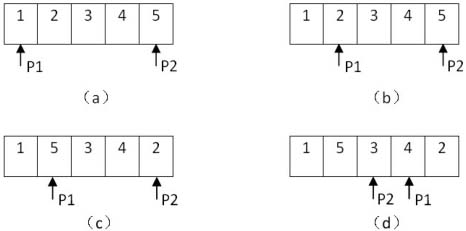
圖3.4 調整數組{1,2,3,4,5} 使得奇數位于偶數前面的過程
注:(a)把第一個指針指向數組的第一個數字,第二個指針指向最后一個數字。(b)向后移動第一個指針直至它指向偶數2,此時第二個指針指向奇數5,不需要移動。(c)交換兩個指針指向的數字。(d)向后移動第一個指針直至它指向偶數4,向前移動第二個指針直至它指向奇數3。由于第二個指針移到了第一個指針的前面,表明所有的奇數都位于偶數的前面。
基于這個分析,我們可以寫出如下代碼:

考慮可擴展性的解法,能秒殺Offer
如果是面試應屆畢業生或者工作時間不長的程序員,面試官會滿意前面的代碼。但如果應聘者申請的是資深的開發職位,那面試官可能會接著問幾個問題。
面試官:如果把題目改成把數組中的數按照大小分為兩部分,所有負數都在非負數的前面,該怎么做?
應聘者:這很簡單,可以重新定義一個函數。在新的函數里,只要修改第二個和第三個while循環中的判斷條件就行了。
面試官:如果再把題目改改,變成把數組中的數分為兩部分,能被3整除的數都在不能被3整除的數的前面。怎么辦?
應聘者:我們還是可以定義一個新的函數。在這個函數中……
面試官:(打斷應聘者的話)難道就沒有更好的辦法?
這個時候應聘者應該要反應過來,面試官期待我們提供的不僅僅是解決一個問題的辦法,而是解決一系列同類型問題的通用辦法。這就是面試官在考查我們對擴展性的理解,即希望我們能夠給出一個模式,在這個模式下能夠很方便地把已有的解決方案擴展到同類型的問題上去。
回到面試官新提出的兩個問題上來。我們發現要解決這兩個新的問題,其實只需要修改函數ReorderOddEven中的兩處判斷的標準,而大的邏輯框架完全不需要改動。因此我們可以把這個邏輯框架抽象出來,而把判斷的標準變成一個函數指針,也就是用一個單獨的函數來判斷數字是不是符合標準。這樣我們就把整個函數解耦成兩部分:一是判斷數字應該在數組前半部分還是后半部分的標準,二是拆分數組的操作。于是我們可以寫出下面的代碼:

在上面的代碼中,函數Reorder根據func的標準把數組pData分成兩部分;而函數isEven則是一個具體的標準,即判斷一個數是不是偶數。有了這兩個函數,我們可以很方便地把數組中的所有奇數移到偶數的前面。實現代碼如下:

如果把問題改成把數組中的負數移到非負數的前面,或者把能被3整除的數移到不能被3整數的數的前面,都只需定義新的函數來確定分組的標準,而函數Reorder不需要做任何改動。也就是說解耦的好處就是提高了代碼的重用性,為功能擴展提供了便利。
源代碼:
本題完整的源代碼詳見14\_ReorderArray項目。
測試用例:
● 功能測試(輸入數組中的奇數、偶數交替出現,輸入的數組中所有偶數都出現在奇數的前面,輸入的數組中所有奇數都出現在偶數的前面)。
● 特殊輸入測試(輸入NULL指針、輸入的數組只包含一個數字)。
本題考點:
● 考查應聘者的快速思維能力。要在短時間內按照要求把數組分隔成兩部分,不是一件容易的事情,需要較快的思維能力。
● 對于已經工作過幾年的應聘者,面試官還將考查其對擴展性的理解,要求應聘者寫出的代碼具有可重用性。
3.4 代碼的魯棒性
魯棒是英文Robust的音譯,有時也翻譯成健壯性。所謂的魯棒性是指程序能夠判斷輸入是否合乎規范要求,并對不合要求的輸入予以合理的處理。
容錯性是魯棒性的一個重要體現。不魯棒的軟件在發生異常事件的時候,比如用戶輸入錯誤的用戶名、試圖打開的文件不存在或者網絡不能連接,就會出現不可預見的詭異行為,或者干脆整個軟件崩潰。這樣的軟件對于用戶而言,不亞于一場災難。
由于魯棒性對軟件開發非常重要,面試官在招聘的時候對應聘者寫出的代碼是否魯棒也非常關注。提高代碼的魯棒性的有效途徑是進行防御性編程。防御性編程是一種編程習慣,是指預見在什么地方可能會出現問題,并為這些可能出現的問題制定處理方式。比如試圖打開文件時發現文件不存在,我們可以提示用戶檢查文件名和路徑;當服務器連接不上時,我們可以試圖連接備用服務器等。這樣當異常情況發生時,軟件的行為也盡在我們的掌握之中,而不至于出現不可預見的事情。
在面試時,最簡單也最實用的防御性編程就是在函數入口添加代碼以驗證用戶輸入是否符合要求。通常面試要求的是寫一兩個函數,我們需要格外關注這些函數的輸入參數。如果輸入的是一個指針,那指針是空指針怎么辦?如果輸入的是一個字符串,那么字符串的內容為空怎么辦?如果能把這些問題都提前考慮到,并做相應的處理,那么面試官就會覺得我們有防御性編程的習慣,能夠寫出魯棒的軟件。
當然并不是所有與魯棒性相關的問題都只是檢查輸入的參數這么簡單。我們看到問題的時候,要多問幾個“如果不……那么……”這樣的問題。比如面試題15“鏈表中倒數第k個結點”,這里隱含著一個條件就是鏈表中結點的個數大于k。我們就要問如果鏈表中的結點的數目不是大于k個,那么代碼會出什么問題?這樣的思考方式能夠幫助我們發現潛在的問題并提前解決問題。這比讓面試官發現問題之后我們再去慌忙分析代碼查找問題的根源要好得多。
面試題15:鏈表中倒數第k個結點
題目:輸入一個鏈表,輸出該鏈表中倒數第k個結點。為了符合大多數人的習慣,本題從1開始計數,即鏈表的尾結點是倒數第1個結點。例如一個鏈表有6個結點,從頭結點開始它們的值依次是1、2、3、4、5、6。這個鏈表的倒數第3個結點是值為4的結點。
鏈表結點定義如下:

為了得到倒數第k個結點,很自然的想法是先走到鏈表的尾端,再從尾端回溯k步。可是我們從鏈表結點的定義可以看出本題中的鏈表是單向鏈表,單向鏈表的結點只有從前往后的指針而沒有從后往前的指針,因此這種思路行不通。
既然不能從尾結點開始遍歷這個鏈表,我們還是把思路回到頭結點上來。假設整個鏈表有n個結點,那么倒數第k個結點就是從頭結點開始的第n-k+1個結點。如果我們能夠得到鏈表中結點的個數n,那我們只要從頭結點開始往后走n-k+1步就可以了。如何得到結點數n?這個不難,只需要從頭開始遍歷鏈表,每經過一個結點,計數器加1就行了。
也就是說我們需要遍歷鏈表兩次,第一次統計出鏈表中結點的個數,第二次就能找到倒數第k個結點。但是當我們把這個思路解釋給面試官之后,他會告訴我們他期待的解法只需要遍歷鏈表一次。
為了實現只遍歷鏈表一次就能找到倒數第k個結點,我們可以定義兩個指針。第一個指針從鏈表的頭指針開始遍歷向前走k-1,第二個指針保持不動;從第k步開始,第二個指針也開始從鏈表的頭指針開始遍歷。由于兩個指針的距離保持在k-1,當第一個(走在前面的)指針到達鏈表的尾結點時,第二個指針(走在后面的)指針正好是倒數第k個結點。
下面以在有6個結點的鏈表中找倒數第3個結點為例分析這個思路的過程。首先用第一個指針從頭結點開始向前走兩(2=3-1)步到達第3個結點(如圖3.5(a)所示)。接著我們把第二個指針初始化指向鏈表的第一個結點(如圖3.5(b)所示)。最后讓兩個指針同時向前遍歷,當第一個指針到達鏈表的尾結點時,第二個指針指向的剛好就是倒數第3個結點(如圖3.5(c)所示)。
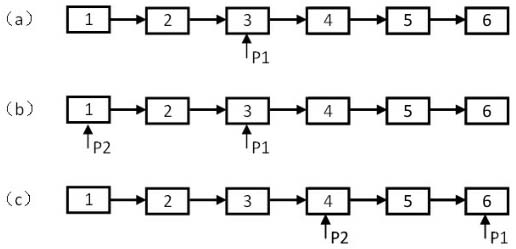
圖3.5 在有6個結點的鏈表上找倒數第3個結點的過程
注:(a)第一個指針在鏈表上走兩步。(b)把第二個指針指向鏈表的頭結點。(c)兩個指針一同沿著鏈表向前走。當第一個指針指向鏈表的尾結點時,第二個指針指向倒數第3個結點。
想清楚這個思路之后,很多人很快就能寫出如下的代碼:

有不少人在面試之前從網上看到過用兩個指針遍歷的思路來解這道題,因此聽到面試官問這道題,他們心中一陣竊喜,很快就能寫出代碼。可是幾天之后他們等來的不是Offer,卻是拒信,于是百思不得其解。其實原因很簡單,就是自己寫的代碼不夠魯棒。以上面的代碼為例,面試官可以找出3種辦法讓這段代碼崩潰:
輸入的pListHead為空指針。由于代碼會試圖訪問空指針指向的內存,程序崩潰。
輸入的以pListHead為頭結點的鏈表的結點總數少于k。由于在for循環中會在鏈表上向前走k-1步,仍然會由于空指針造成程序崩潰。
輸入的參數k為0。由于k是一個無符號整數,那么在for循環中k-1得到的將不是-1,而是4294967295(無符號的0xFFFFFFFF)。因此for循環執行的次數遠遠超出我們的預計,同樣也會造成程序崩潰。
這么簡單的代碼卻存在3個潛在崩潰的風險,我們可以想象當面試官看到這樣的代碼時會有什么樣的心情,最終他給出的是拒信而不是Offer雖是意料之外但也在情理之中。
面試小提示:
面試過程中寫代碼要特別注意魯棒性。如果寫出的代碼存在多處崩潰的風險,那我們很有可能和Offer失之交臂。
針對前面指出的3個問題,我們要分別處理。如果輸入的鏈表頭指針為NULL,那么整個鏈表為空,此時查找倒數第k個結點自然應該返回NULL。如果輸入的k是0,也就是試圖查找倒數第0個結點,由于我們計數是從1開始的,因此輸入0沒有實際意義,也可以返回NULL。如果鏈表的結點數少于k,在for循環中遍歷鏈表可能會出現指向NULL的m\_pNext,因此我們在for循環中應該加一個if判斷。修改之后的代碼如下:

源代碼:
本題完整的源代碼詳見15\_KthNodeFromEnd項目。
測試用例:
● 功能測試(第k個結點在鏈表的中間,第k個結點是鏈表的頭結點,第k個結點是鏈表的尾結點)。
● 特殊輸入測試(鏈表頭結點為NULL指針,鏈表的結點總數少于k,k等于0)。
本題考點:
● 考查對鏈表的理解。
● 考查代碼的魯棒性。魯棒性是解決這道題的關鍵所在。如果應聘者寫出的代碼有著多處崩潰的潛在風險,那么他是很難通過這輪面試的。
相關題目:
● 求鏈表的中間結點。如果鏈表中結點總數為奇數,返回中間結點;如果結點總數是偶數,返回中間兩個結點的任意一個。為了解決這個問題,我們也可以定義兩個指針,同時從鏈表的頭結點出發,一個指針一次走一步,另一個指針一次走兩步。當走得快的指針走到鏈表的末尾時,走得慢的指針正好在鏈表的中間。
● 判斷一個單向鏈表是否形成了環形結構。和前面的問題一樣,定義兩個指針,同時從鏈表的頭結點出發,一個指針一次走一步,另一個指針一次走兩步。如果走得快的指針追上了走得慢的指針,那么鏈表就是環形鏈表;如果走得快的指針走到了鏈表的末尾(m\_pNext指向NULL)都沒有追上第一個指針,那么鏈表就不是環形鏈表。
舉一反三:
當我們用一個指針遍歷鏈表不能解決問題的時候,可以嘗試用兩個指針來遍歷鏈表。可以讓其中一個指針遍歷的速度快一些(比如一次在鏈表上走兩步),或者讓它先在鏈表上走若干步。
面試題16:反轉鏈表
題目:定義一個函數,輸入一個鏈表的頭結點,反轉該鏈表并輸出反轉后鏈表的頭結點。鏈表結點定義如下:

解決與鏈表相關的問題總是有大量的指針操作,而指針操作的代碼總是容易出錯的。很多面試官喜歡出鏈表相關的問題,就是想通過指針操作來考查應聘者的編碼功底。為了避免出錯,我們最好先進行全面的分析。在實際軟件開發周期中,設計的時間通常不會比編碼的時間短。在面試的時候我們不要急于動手寫代碼,而是一開始仔細分析和設計,這將會給面試官留下很好的印象。與其很快寫出一段漏洞百出的代碼,倒不如仔細分析再寫出魯棒的代碼。
為了正確地反轉一個鏈表,需要調整鏈表中指針的方向。為了將調整指針這個復雜的過程分析清楚,我們可以借助圖形來直觀地分析。在圖3.6(a)所示的鏈表中,h、i和j是3個相鄰的結點。假設經過若干操作,我們已經把結點h之前的指針調整完畢,這些結點的m\_pNext都指向前面一個結點。接下來我們把i的m\_pNext指向h,此時的鏈表結構如圖3.6(b)所示。

圖3.6 反轉鏈表中結點的m\_pNext指針導致鏈表出現斷裂
注:(a)一個鏈表。(b)把i之前所有的結點的m\_pNext都指向前一個結點,導致鏈表在結點i、j之間斷裂。
不難注意到,由于結點i的m\_pNext指向了它的前一個結點,導致我們無法在鏈表中遍歷到結點j。為了避免鏈表在結點i處斷開,我們需要在調整結點i的m\_pNext之前,把結點j保存下來。
也就是說我們在調整結點i的m\_pNext指針時,除了需要知道結點i本身之外,還需要i的前一個結點h,因為我們需要把結點i的m\_pNext指向結點h。同時,我們還事先需要保存i的一個結點j,以防止鏈表斷開。因此相應地我們需要定義3個指針,分別指向當前遍歷到的結點、它的前一個結點及后一個結點。
最后我們試著找到反轉后鏈表的頭結點。不難分析出反轉后鏈表的頭結點是原始鏈表的尾結點。什么結點是尾結點?自然是m\_pNext為NULL的結點。
有了前面的分析,我們不難寫出如下代碼:

在面試的過程中,我們發現應聘者的代碼中經常出現如下3種問題:
● 輸入的鏈表頭指針為NULL或者整個鏈表只有一個結點時,程序立即崩潰。
● 反轉后的鏈表出現斷裂。
● 返回的反轉之后的頭結點不是原始鏈表的尾結點。
在實際面試的時候,不同應聘者的思路各不相同,因此寫出的代碼也不一樣。那么應聘者如何才能及時發現并糾正代碼中的問題,以確保不犯上述錯誤呢?一個很好的辦法就是提前想好測試用例。在寫出代碼之后,立即用事先準備好的測試用例檢查測試。如果面試是以手寫代碼的方式,那也要在心里默默運行代碼做單元測試。只有確保代碼通過測試之后,再提交面試官。我們要記住一點:自己多花時間找出問題并修正問題,比在面試官找出問題之后再去慌慌張張修改代碼要好得多。其實面試官檢查應聘者代碼的方法也是用他事先準備好的測試用例來測試。如果應聘者能夠想到這些測試用例,并用它們來檢查測試自己的代碼,那就能保證有備無患、萬無一失了。
以這道題為例,我們至少應該想到幾類測試用例對代碼做功能測試:
● 輸入的鏈表頭指針是NULL。
● 輸入的鏈表只有一個結點。
● 輸入的鏈表有多個結點。
如果我們確信代碼能夠通過這3類測試用例的測試,那我們就有很大的把握能夠通過這輪面試了。
源代碼:
本題完整的源代碼詳見16\_ReverseList項目。
測試用例:
● 功能測試(輸入的鏈表含有多個結點,鏈表中只有一個結點)。
● 特殊輸入測試(鏈表頭結點為NULL指針)。
本題考點:
● 考查應聘者對鏈表、指針的編程能力。
● 特別注重考查應聘者思維的全面性及寫出來的代碼的魯棒性。
本題擴展:
用遞歸實現同樣的反轉鏈表的功能。
面試題17:合并兩個排序的鏈表
題目:輸入兩個遞增排序的鏈表,合并這兩個鏈表并使新鏈表中的結點仍然是按照遞增排序的。例如輸入圖3.7中的鏈表1和鏈表2,則合并之后的升序鏈表如鏈表3所示。鏈表結點定義如下:

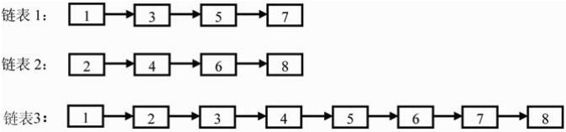
圖3.7 合并兩個排序鏈表的過程
注:鏈表1和鏈表2是兩個遞增排序的鏈表,合并這兩個鏈表得到升序鏈表為鏈表3。
這是一個經常被各公司采用的面試題。在面試過程中,我們發現應聘者最容易犯兩種錯誤:一是在寫代碼之前沒有對合并的過程想清楚,最終合并出來的鏈表要么中間斷開了要么并沒有做到遞增排序;二是代碼在魯棒性方面存在問題,程序一旦有特殊的輸入(如空鏈表)就會崩潰。接下來分析如何解決這兩個問題。
首先分析合并兩個鏈表的過程。我們的分析從合并兩個鏈表的頭結點開始。鏈表1的頭結點的值小于鏈表2的頭結點的值,因此鏈表1的頭結點將是合并后鏈表的頭結點(如圖3.8(a)所示)。
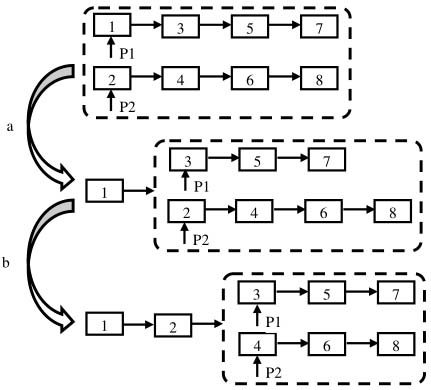
圖3.8 合并兩個遞增鏈表的過程
注:(a)鏈表1的頭結點的值小于鏈表2的頭結點的值,因此鏈表1的頭結點是合并后鏈表的頭結點。(b)在剩余的結點中,鏈表2的頭結點的值小于鏈表1的頭結點的值,因此鏈表2的頭結點是剩余結點的頭結點,把這個結點和之前已經合并好的鏈表的尾結點鏈接起來。
我們繼續合并兩個鏈表中剩余的結點(圖3.8中虛線框中的鏈表)。在兩個鏈表中剩下的結點依然是排序的,因此合并這兩個鏈表的步驟和前面的步驟是一樣的。我們還是比較兩個頭結點的值。此時鏈表2的頭結點的值小于鏈表1的頭結點的值,因此鏈表2的頭結點的值將是合并剩余結點得到的鏈表的頭結點。我們把這個結點和前面合并鏈表時得到的鏈表的尾結點(值為1的結點)鏈接起來,如圖3.8(b)所示。
當我們得到兩個鏈表中值較小的頭結點并把它鏈接到已經合并的鏈表之后,兩個鏈表剩余的結點依然是排序的,因此合并的步驟和之前的步驟是一樣的。這就是典型的遞歸的過程,我們可以定義遞歸函數完成這一合并過程。
接下來我們來解決魯棒性的問題。每當代碼試圖訪問空指針指向的內存時程序就會崩潰,從而導致魯棒性問題。在本題中一旦輸入空的鏈表就會引入空的指針,因此我們要對空鏈表單獨處理。當第一個鏈表是空鏈表,也就是它的頭結點是一個空指針時,那么把它和第二個鏈表合并,顯然合并的結果就是第二個鏈表。同樣,當輸入的第二個鏈表的頭結點是空指針的時候,我們把它和第一個鏈表合并得到的結果就是第一個鏈表。如果兩個鏈表都是空鏈表,合并的結果是得到一個空鏈表。
在我們想清楚合并的過程,并且知道哪些輸入可能會引起魯棒性問題之后,就可以動手寫代碼了。下面是一段參考代碼:

源代碼:
本題完整的源代碼詳見17\_MergeSortedLists項目。
測試用例:
● 功能測試(輸入的兩個鏈表有多個結點,結點的值互不相同或者存在值相等的多個結點)。
● 特殊輸入測試(兩個鏈表的一個或者兩個頭結點為NULL指針、兩個鏈表中只有一個結點)。
本題考點:
● 考查應聘者分析問題的能力。解決這個問題需要大量的指針操作,應聘者如果沒有透徹地分析問題形成清晰的思路,那么他很難寫出正確的代碼。
● 考查應聘者能不能寫出魯棒的代碼。由于有大量指針操作,應聘者如果稍有不慎就會在代碼中遺留很多與魯棒性相關的隱患。建議應聘者在寫代碼之前全面分析哪些情況會引入空指針,并考慮清楚怎么處理這些空指針。
面試題18:樹的子結構
題目:輸入兩棵二叉樹A和B,判斷B是不是A的子結構。二叉樹結點的定義如下:

例如圖3.9中的兩棵二叉樹,由于A中有一部分子樹的結構和B是一樣的,因此B是A的子結構。
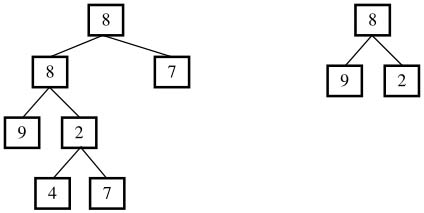
圖3.9 兩棵二叉樹A和B,右邊的樹B是左邊的樹A的子結構
和鏈表相比,樹中的指針操作更多也更復雜,因此與樹相關的問題通常會比鏈表的要難。如果想加大面試的難度,樹的題目是很多面試官的選擇。面對著大量的指針操作,我們要更加小心,否則一不留神就會在代碼中留下隱患。
現在回到這個題目本身。要查找樹A中是否存在和樹B結構一樣的子樹,我們可以分成兩步:第一步在樹A中找到和B的根結點的值一樣的結點R,第二步再判斷樹A中以R為根結點的子樹是不是包含和樹B一樣的結構。
以上面的兩棵樹為例來詳細分析這個過程。首先我們試著在樹A中找到值為8(樹B的根結點的值)的結點。從樹A的根結點開始遍歷,我們發現它的根結點的值就是8。接著我們就去判斷樹A的根結點下面的子樹是不是含有和樹B一樣的結構(如圖3.10所示)。在樹A中,根結點的左子結點的值是8,而樹B的根結點的左子結點是9,對應的兩個結點不同。
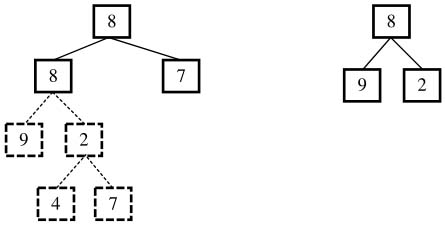
圖3.10 樹A的根結點和B的根結點的值相同,但樹A的根結點下面(實線部分)的結構和樹B的結構不一致
因此我們仍然需要遍歷樹A,接著查找值為8的結點。我們在樹的第二層中找到了一個值為8的結點,然后進行第二步判斷,即判斷這個結點下面的子樹是否含有和樹B一樣結構的子樹(如圖3.11所示)。于是我們遍歷這個結點下面的子樹,先后得到兩個子結點9和2,這和樹B的結構完全相同。此時我們在樹A中找到了一個和樹B的結構一樣的子樹,因此樹B是樹A的子結構。
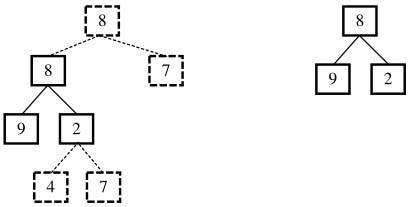
圖3.11 在樹A中找到第二個值為8的結點,該結點下面(實線部分)的結構和B的結構一致
第一步在樹A中查找與根結點的值一樣的結點,這實際上就是樹的遍歷。對二叉樹這種數據結構熟悉的讀者自然知道可以用遞歸的方法去遍歷,也可以用循環的方法去遍歷。由于遞歸的代碼實現比較簡潔,面試時如果沒有特別要求,我們通常都會采用遞歸的方式。下面是參考代碼:

在面試的時候,我們一定要注意邊界條件的檢查,即檢查空指針。當樹A或樹B為空的時候,定義相應的輸出。如果沒有檢查并做相應的處理,程序非常容易崩潰,這是面試時非常忌諱的事情。
在上述代碼中,我們遞歸調用HasSubtree遍歷二叉樹A。如果發現某一結點的值和樹B的頭結點的值相同,則調用DoesTree1HaveTree2,做第二步判斷。
第二步是判斷樹A中以R為根結點的子樹是不是和樹B具有相同的結構。同樣,我們也可以用遞歸的思路來考慮:如果結點R的值和樹B的根結點不相同,則以R為根結點的子樹和樹B肯定不具有相同的結點;如果它們的值相同,則遞歸地判斷它們各自的左右結點的值是不是相同。遞歸的終止條件是我們到達了樹A或者樹B的葉結點。參考代碼如下:

我們注意到上述代碼有多處判斷一個指針是不是NULL,這樣做是為了避免試圖訪問空指針而造成程序崩潰,同時也設置了遞歸調用的退出條件。在寫遍歷樹的代碼的時候一定要高度警惕,在每一處需要訪問地址的時候都要問自己這個地址有沒有可能是NULL,如果是NULL該怎么處理。
面試小提示:
二叉樹相關的代碼有大量的指針操作,每一次使用指針的時候,我們都要問自己這個指針有沒有可能是NULL,如果是NULL該怎么處理。
為了確保自己的代碼完整正確,在寫出代碼之后應聘者至少要用幾個測試用例來檢驗自己的程序:樹A和樹B的頭結點有一個或者兩個都是空指針,在樹A和樹B中所有結點都只有左子結點或者右子結點,樹A和樹B的結點中含有分叉。只有這樣才能寫出讓面試官滿意的魯棒代碼。
源代碼:
本題完整的源代碼詳見18\_SubstructureInTree項目。
測試用例:
● 功能測試(樹A和樹B都是普通的二叉樹,樹B是或者不是樹A的子結構)。
● 特殊輸入測試(兩棵二叉樹的一個或者兩個根結點為NULL指針、二叉樹的所有結點都沒有左子樹或者右子樹)。
本題考點:
● 考查對二叉樹遍歷算法的理解及遞歸編程能力。
● 考查代碼的魯棒性。本題的代碼中含有大量的指針操作,稍有不慎程序就會崩潰。應聘者需要采用防御性編程的方式,每次訪問指針地址之前都要考慮這個指針有沒有可能是NULL。
3.5 本章小結
本章從規范性、完整性和魯棒性3個方面介紹了如何在面試時寫出高質量的代碼,如圖3.12所示。
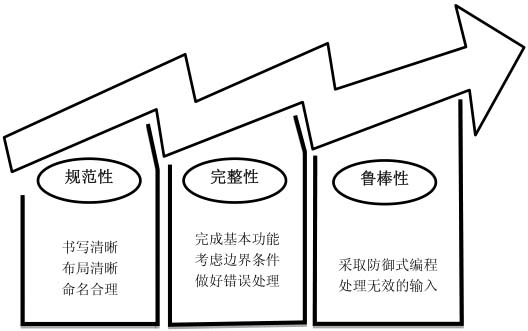
圖3.12 從規范性、完整性和魯棒性3個方面提高代碼的質量
大多數面試都是要求應聘者在白紙或者白板上寫代碼。應聘者在編碼的時候要注意規范性,盡量清晰地書寫每個字母,通過縮進和對齊括號讓代碼布局合理,同時合理命名代碼中的變量和函數。
最好在編碼之前全面考慮所有可能的輸入,確保寫出的代碼在完成了基本功能之外,還考慮了邊界條件,并做好了錯誤處理。只有全面考慮到這3方面的代碼才是完整的代碼。
另外,要確保自己寫出的程序不會輕易崩潰。平時在寫代碼的時候,應聘者最好養成防御式編程的習慣,在函數入口判斷輸入是否有效并對各種無效輸入做好相應的處理。
- 目錄
- 扉頁
- 版權頁
- 推薦序一
- 推薦序二
- 前言
- 第1章 面試的流程
- 1.1 面試官談面試
- 1.2 面試的三種形式
- 1.2.1 電話面試
- 1.2.2 共享桌面遠程面試
- 1.2.3 現場面試
- 1.3 面試的三個環節
- 1.3.1 行為面試環節
- 1.應聘者的項目經驗
- 2.應聘者掌握的技能
- 3.回答“為什么跳槽”
- 1.3.2 技術面試環節
- 1.扎實的基礎知識
- 2.高質量的代碼
- 3.清晰的思路
- 4.優化效率的能力
- 5.優秀的綜合能力
- 1.3.3 應聘者提問環節
- 1.4 本章小結
- 第2章 面試需要的基礎知識
- 2.1 面試官談基礎知識
- 2.2 編程語言
- 2.2.1 C++
- 面試題1:賦值運算符函數
- 經典的解法,適用于初級程序員
- 考慮異常安全性的解法,高級程序員必備
- 2.2.2 C#
- 面試題2:實現Singleton模式
- 不好的解法一:只適用于單線程環境
- 不好的解法二:雖然在多線程環境中能工作但效率不高
- 可行的解法:加同步鎖前后兩次判斷實例是否已存在
- 強烈推薦的解法一:利用靜態構造函數
- 強烈推薦的解法二:實現按需創建實例
- 解法比較
- 2.3 數據結構
- 2.3.1 數組
- 面試題3:二維數組中的查找
- 2.3.2 字符串
- 面試題4:替換空格
- 時間復雜度為O(n2)的解法,不足以拿到Offer
- 時間復雜度為O(n)的解法,搞定Offer就靠它了
- 2.3.3 鏈表
- 面試題5:從尾到頭打印鏈表
- 2.3.4 樹
- 面試題6:重建二叉樹
- 2.3.5 棧和隊列
- 面試題7:用兩個棧實現隊列
- 2.4 算法和數據操作
- 2.4.1 查找和排序
- 面試題8:旋轉數組的最小數字
- 2.4.2 遞歸和循環
- 面試題9:斐波那契數列
- 效率很低的解法,挑剔的面試官不會喜歡
- 面試官期待的實用解法
- 時間復雜度O(logn)但不夠實用的解法
- 解法比較
- 2.4.3 位運算
- 面試題10:二進制中1的個數
- 可能引起死循環的解法
- 常規解法
- 能給面試官帶來驚喜的解法
- 2.5 本章小結
- 第3章 高質量的代碼
- 3.1 面試官談代碼質量
- 3.2 代碼的規范性
- 3.3 代碼的完整性
- 1.從3方面確保代碼的完整性
- 2.3種錯誤處理的方法
- 面試題11:數值的整數次方
- 自以為題目簡單的解法
- 全面但不夠高效的解法,我們離Offer已經很近了
- 全面又高效的解法,確保我們能拿到Offer
- 面試題12:打印1到最大的n位數
- 跳進面試官陷阱
- 在字符串上模擬數字加法的解法,繞過陷阱才能拿到Offer
- 把問題轉換成數字排列的解法,遞歸讓代碼更簡潔
- 面試題13:在O(1)時間刪除鏈表結點
- 面試題14:調整數組順序使奇數位于偶數前面
- 只完成基本功能的解法,僅適用于初級程序員
- 考慮可擴展性的解法,能秒殺Offer
- 3.4 代碼的魯棒性
- 面試題15:鏈表中倒數第k個結點
- 面試題16:反轉鏈表
- 面試題17:合并兩個排序的鏈表
- 面試題18:樹的子結構
- 3.5 本章小結
- 第4章 解決面試題的思路
- 4.1 面試官談面試思路
- 4.2 畫圖讓抽象問題形象化
- 面試題19:二叉樹的鏡像
- 面試題20:順時針打印矩陣
- 4.3 舉例讓抽象問題具體化
- 面試題21:包含min函數的棧
- 面試題22:棧的壓入、彈出序列
- 面試題23:從上往下打印二叉樹
- 面試題24:二叉搜索樹的后序遍歷序列
- 面試題25:二叉樹中和為某一值的路徑
- 4.4 分解讓復雜問題簡單化
- 面試題26:復雜鏈表的復制
- 面試題27:二叉搜索樹與雙向鏈表
- 面試題28:字符串的排列
- 4.5 本章小結
- 第5章 優化時間和空間效率
- 5.1 面試官談效率
- 5.2 時間效率
- 面試題29:數組中出現次數超過一半的數字
- 解法一:基于Partition函數的O(n)算法
- 解法二:根據數組特點找出O(n)的算法
- 解法比較
- 面試題30:最小的k個數
- 解法一:O(n)的算法,只有當我們可以修改輸入的數組時可用
- 解法二:O(nlogk)的算法,特別適合處理海量數據
- 解法比較
- 面試題31:連續子數組的最大和
- 解法一:舉例分析數組的規律
- 解法二:應用動態規劃法
- 面試題32:從1到n整數中1出現的次數
- 不考慮時間效率的解法,靠它想拿Offer有點難
- 從數字規律著手明顯提高時間效率的解法,能讓面試官耳目一新
- 面試題33:把數組排成最小的數
- 5.3 時間效率與空間效率的平衡
- 面試題34:丑數
- 逐個判斷每個整數是不是丑數的解法,直觀但不夠高效
- 創建數組保存已經找到的丑數,用空間換時間的解法
- 面試題35:第一個只出現一次的字符
- 面試題36:數組中的逆序對
- 面試題37:兩個鏈表的第一個公共結點
- 5.4 本章小結
- 第6章 面試中的各項能力
- 6.1 面試官談能力
- 6.2 溝通能力和學習能力
- 1.溝通能力
- 2.學習能力
- 3.善于學習、溝通的人也善于提問
- 6.3 知識遷移能力
- 面試題38:數字在排序數組中出現的次數
- 面試題39:二叉樹的深度
- 需要重復遍歷結點多次的解法,簡單但不足以打動面試官
- 每個結點只遍歷一次的解法,正是面試官喜歡的
- 面試題40:數組中只出現一次的數字
- 面試題41:和為s的兩個數字VS和為s的連續正數序列
- 面試題42:翻轉單詞順序VS左旋轉字符串
- 6.4 抽象建模能力
- 面試題43:n個骰子的點數
- 解法一:基于遞歸求骰子點數,時間效率不夠高
- 解法二:基于循環求骰子點數,時間性能好
- 面試題44:撲克牌的順子
- 面試題45:圓圈中最后剩下的數字
- 經典的解法,用環形鏈表模擬圓圈
- 創新的解法,拿到Offer不在話下
- 6.5 發散思維能力
- 面試題46:求1+2+…+n
- 解法一:利用構造函數求解
- 解法二:利用虛函數求解
- 解法三:利用函數指針求解
- 解法四:利用模板類型求解
- 面試題47:不用加減乘除做加法
- 面試題48:不能被繼承的類
- 常規的解法:把構造函數設為私有函數
- 新奇的解法:利用虛擬繼承,能給面試官留下很好的印象
- 6.6 本章小結
- 第7章 兩個面試案例
- 7.1 案例一:(面試題49)把字符串轉換成整數
- 7.2 案例二:(面試題50)樹中兩個結點的最低公共祖先