
第4章 解決面試題的思路
4.1 面試官談面試思路
“編碼前講自己的思路是一個考查指標。一個合格的應聘者應該在他做事之前明白自己要做的事情究竟是什么,以及該怎么做。一開始就編碼的人員,除非后面表現非常優秀,否則很容易通不過。”
——殷焰(支付寶,高級安全測試工程師)
“讓應聘者給我講具體的問題分析過程,經常會要求他證明。”
——張曉禹(百度,技術經理)
“個人比較傾向于讓應聘者在寫代碼之前解釋他的思路。應聘者如果沒有想清楚就動手本身就不是太好。應聘者可以采用舉例子、畫圖等多種方式,解釋清楚問題本身和問題解決方案是關鍵。”
——何幸杰(SAP,高級工程師)
“對于比較復雜的算法和設計,一般來講最好是在開始寫代碼前講清楚思路和設計。”
——堯敏(淘寶,資深經理)
“喜歡應聘者先講清思路。如果覺察到方案的錯誤和漏洞,我會讓他證明是否正確,主要是希望他能在分析的過程中發現這些錯誤和漏洞并加以改正。”
——陳黎明(微軟,SDE II)
“喜歡應聘者在寫代碼之前先講思路,舉例子和畫圖都是很好的方法。”
——田超(微軟,SDE II)
4.2 畫圖讓抽象問題形象化
畫圖是在面試過程中應聘者用來幫助自己分析、推理的常用手段。很多面試題很抽象,不是很容易找到解決辦法。這時不妨畫出一些與題目相關的圖形,借以輔助自己觀察和思考。圖形能使抽象的問題具體化、形象化,應聘者說不定通過幾個圖形就能找到規律,從而找到問題的解決方案。
有不少與數據結構相關的問題,比如二叉樹、二維數組、鏈表等問題,都可以采用畫圖的方法來分析。很多時候空想未必能想明白題目中隱含的規律和特點,隨手畫幾張圖卻能讓我們輕易找到竅門。比如在面試題19“二叉樹的鏡像”中我們畫幾張二叉樹的圖就能發現,求樹的鏡像的過程其實就是在遍歷樹的同時交換非葉結點的左右子結點。在面試題20“順時針打印矩陣”中,我們畫圖之后很容易就發現可以把矩陣分解成若干個圓圈,然后從外向內打印每個圓圈。面試的時候很多人都會在邊界條件上犯錯誤(因為最后一圈可能退化而不是一個完整的圈),如果畫幾張示意圖,就能夠很容易找到最后一圈退化的規律。對于面試題26“復雜鏈表的復制”,如果能夠畫出每一步操作時的指針操作,那接下來寫代碼就會容易得多。
在面試的時候應聘者需要向面試官解釋自己的思路。對于復雜的問題,應聘者光用語言未必能夠說得清楚。這個時候可以畫出幾個圖形,一邊看著圖形一邊講解,面試官就能更加輕松地理解應聘者的思路。這對應聘者是有益的,因為面試官會覺得他有很好的溝通交流能力。
面試題19:二叉樹的鏡像
題目:請完成一個函數,輸入一個二叉樹,該函數輸出它的鏡像。二叉樹結點的定義如下:

樹的鏡像對很多人來說是一個新的概念,我們未必能夠一下子想出求樹的鏡像的方法。為了能夠形成直觀的印象,我們可以自己畫一棵二叉樹,然后根據照鏡子的經驗畫出它的鏡像。如圖4.1中右邊的二叉樹就是左邊的樹的鏡像。
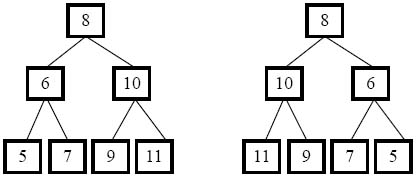
圖4.1 兩棵互為鏡像的二叉樹
仔細分析這兩棵樹的特點,看看能不能總結出求鏡像的步驟。這兩棵樹的根結點相同,但它們的左右兩個子結點交換了位置。因此我們不妨先在樹中交換根結點的兩個子結點,就得到圖4.2中的第二棵樹。
交換根結點的兩個子結點之后,我們注意到值為10、6的結點的子結點仍然保持不變,因此我們還需要交換這兩個結點的左右子結點。交換之后的結果分別是圖4.2中的第三棵樹和第四棵樹。做完這兩次交換之后,我們已經遍歷完所有的非葉子結點。此時變換之后的樹剛好就是原始樹的鏡像。
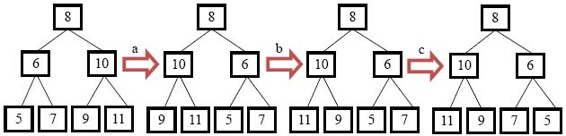
圖4.2 求二叉樹鏡像的過程
注:(a)交換根結點的左右子樹;(b)交換值為10的結點的左右子結點;(c)交換值為6的結點的左右子結點。
總結上面的過程,我們得出求一棵樹的鏡像的過程:我們先前序遍歷這棵樹的每個結點,如果遍歷到的結點有子結點,就交換它的兩個子結點。當交換完所有非葉子結點的左右子結點之后,就得到了樹的鏡像。
想清楚了這個思路,我們就可以動手寫代碼了。參考代碼如下:

源代碼
本題完整的源代碼詳見19\_MirrorOfBinaryTree項目。
測試用例
● 功能測試(普通的二叉樹,二叉樹的所有結點都沒有左子樹或者右子樹,只有一個結點的二叉樹)。
● 特殊輸入測試(二叉樹的根結點為NULL指針)。
本題考點
● 考查對二叉樹的理解。本題實質上是利用樹的遍歷算法解決問題。
● 考查應聘者的思維能力。樹的鏡像是一個抽象的概念,應聘者需要在短時間內想清楚求鏡像的步驟并轉化為代碼。應聘者可以畫圖把抽象的問題形象化,這有助于其快速找到解題思路。
本題擴展
上面的代碼是用遞歸實現的。如果要求用循環,該如何實現?
面試題20:順時針打印矩陣
題目:輸入一個矩陣,按照從外向里以順時針的順序依次打印出每一個數字。例如:如果輸入如下矩陣:
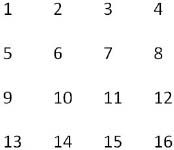
則依次打印出數字1、2、3、4、8、12、16、15、14、13、9、5、6、7、11、10。
這道題完全沒有涉及復雜的數據結構或者高級的算法,看起來是一個很簡單的問題。但實際上解決這個問題,會在代碼中包含多個循環,并且還需要判斷多個邊界條件。如果在把問題考慮得很清楚之前就開始寫代碼,不可避免會越寫越混亂。因此解決這個問題的關鍵在于先要形成清晰的思路,并把復雜的問題分解成若干個簡單的問題。
當我們遇到一個復雜問題的時候,可以用圖形來幫助我們思考。由于是以從外圈到內圈的順序依次打印,我們可以把矩陣想象成若干個圈,如圖4.3所示。我們可以用一個循環來打印矩陣,每一次打印矩陣中的一個圈。
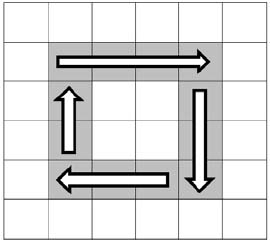
圖4.3 把矩陣看成由若干個順時針方向的圈組成
接下來分析循環結束的條件。假設這個矩陣的行數是rows,列數是columns。打印第一圈的左上角的坐標是(1,1),第二圈的左上角的坐標是(2,2),依此類推。我們注意到,左上角的坐標中行標和列標總是相同的,于是可以在矩陣中選取左上角為(start, start)的一圈作為我們分析的目標。
對一個5×5的矩陣而言,最后一圈只有一個數字,對應的坐標為(2,2)。我們發現5>2×2。對一個6×6的矩陣而言,最后一圈有4個數字,其左上角的坐標仍然為(2,2)。我們發現6>2×2依然成立。于是我們可以得出,讓循環繼續的條件是columns>startX×2并且rows>startY×2。所以我們可以用如下的循環來打印矩陣:

接著我們考慮如何打印一圈的功能,即如何實現PrintMatrixInCircle。如圖4.3所示,我們可以把打印一圈分為四步:第一步從左到右打印一行,第二步從上到下打印一列,第三步從右到左打印一行,第四步從下到上打印一列。每一步我們根據起始坐標和終止坐標用一個循環就能打印出一行或者一列。
不過值得注意的是,最后一圈有可能退化成只有一行、只有一列,甚至只有一個數字,因此打印這樣的一圈就不再需要四步。圖4.4是幾個退化的例子,打印一圈分別只需要三步、兩步甚至只有一步。
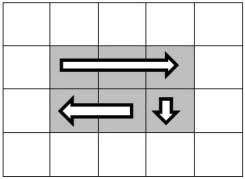
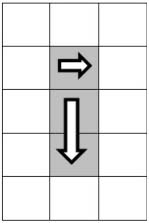
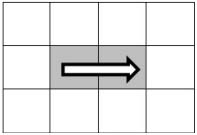
圖4.4 打印矩陣最里面一圈可能只需要三步、兩步甚至一步
因此我們要仔細分析打印時每一步的前提條件。第一步總是需要的,因為打印一圈至少有一步。如果只有一行,那么就不用第二步了。也就是需要第二步的前提條件是終止行號大于起始行號。需要第三步打印的前提條件是圈內至少有兩行兩列,也就是說除了要求終止行號大于起始行號之外,還要求終止列號大于起始列號。同理,需要打印第四步的前提條件是至少有三行兩列,因此要求終止行號比起始行號至少大2,同時終止列號大于起始列號。
通過上述的分析,我們就可以寫出如下代碼:

源代碼:
本題完整的源代碼詳見20\_PrintMatrix項目。
測試用例:
數組有多行多列、數組只有一行、數組中只有一列、數組中只有一行一列。
本題考點:
本題主要考查應聘者的思維能力。從外到內順時針打印矩陣這個過程非常復雜,應聘者如何能很快地找出其規律并寫出完整的代碼,是解決這道題的關鍵。當問題比較抽象不容易理解時,可以試著畫幾個圖形幫助理解,這樣往往能更快地找到思路。
4.3 舉例讓抽象問題具體化
和上一節畫圖的方法一樣,我們也可以借助舉例模擬的方法來思考分析復雜的問題。當一眼看不出問題中隱藏的規律的時候,我們可以試著用一兩個具體的例子模擬操作的過程,這樣說不定就能通過具體的例子找到抽象的規律。比如面試題22“棧的壓入、彈出序列”,很多人都不能立即找到棧的壓入和彈出規律。這時我們可以仔細分析一兩個序列,一步一步模擬壓入、彈出的操作,并從中總結出隱含的規律。面試題24“二叉搜索樹的后序遍歷序列”也類似,我們同樣可以通過一兩個具體的序列找到后續遍歷的規律。
具體的例子也可以幫助我們向面試官解釋算法思路。算法通常是很抽象的,用語言不容易表述得很清楚,我們可以考慮舉出一兩個具體的例子,告訴面試官我們的算法是怎么一步步處理這個例子的。例如在面試題21“包含min函數的棧”中,我們可以舉例模擬壓棧和彈出幾個數字,分析每次操作之后數據棧、輔助棧和最小值各是什么。這樣解釋之后,面試官就能很清晰地理解我們的思路,同時他也會覺得我們有很好的溝通能力,能把復雜的問題用很簡單的方式說清楚。
具體的例子還能幫助我們確保代碼的質量。在面試中寫完代碼之后,應該先檢查一遍,確保沒有問題再交給面試官。怎么檢查呢?我們可以運行幾個測試用例。在分析問題的時候采用的例子就是測試用例。我們可以把這些例子當做測試用例,在心里模擬運行,看每一步操作之后的結果和我們預期的是不是一樣。如果每一步的結果都和事先預計的一致,那我們就能確保代碼的正確性了。
面試題21:包含min函數的棧
題目:定義棧的數據結構,請在該類型中實現一個能夠得到棧的最小元素的min函數。在該棧中,調用min、push及pop的時間復雜度都是O(1)。
看到這個問題,我們的第一反應可能是每次壓入一個新元素進棧時,將棧里的所有元素排序,讓最小的元素位于棧頂,這樣就能在O(1)時間得到最小元素了。但這種思路不能保證最后壓入棧的元素能夠最先出棧,因此這個數據結構已經不是棧了。
我們接著想到在棧里添加一個成員變量存放最小的元素。每次壓入一個新元素進棧的時候,如果該元素比當前最小的元素還要小,則更新最小元素。面試官聽到這種思路之后就會問:如果當前最小的元素被彈出棧了,如何得到下一個最小的元素呢?
分析到這里我們發現僅僅添加一個成員變量存放最小元素是不夠的,也就是說當最小元素被彈出棧的時候,我們希望能夠得到次小元素。因此在壓入這個最小元素之前,我們要把次小元素保存起來。
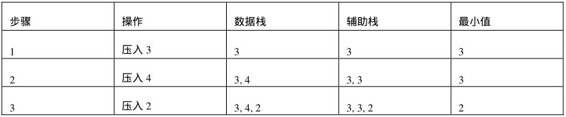
是不是可以把每次的最小元素(之前的最小元素和新壓入棧的元素兩者的較小值)都保存起來放到另外一個輔助棧里呢?我們不妨舉幾個例子來分析一下把元素壓入或者彈出棧的過程(如表4.1所示)。
表4.1 棧內壓入3、4、2、1之后接連兩次彈出棧頂數字再壓入0時,數據棧、輔助棧和最小值的狀態
(續表)
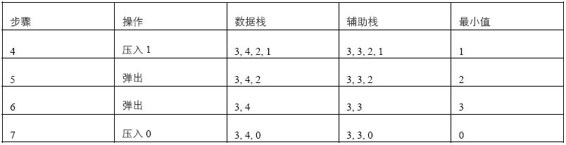
首先往空的數據棧里壓入數字3,顯然現在3是最小值,我們也把這個最小值壓入輔助棧。接下來往數據棧里壓入數字4。由于4大于之前的最小值,因此我們仍然往輔助棧里壓入數字3。第三步繼續往數據棧里壓入數字2。由于2小于之前的最小值3,因此我們把最小值更新為2,并把2壓入輔助棧。同樣當壓入數字1時,也要更新最小值,并把新的最小值1壓入輔助棧。
從表4.1中我們可以看出,如果每次都把最小元素壓入輔助棧,那么就能保證輔助棧的棧頂一直都是最小元素。當最小元素從數據棧內被彈出之后,同時彈出輔助棧的棧頂元素,此時輔助棧的新棧頂元素就是下一個最小值。比如第四步之后,棧內的最小元素是1。當第五步在數據棧內彈出1后,我們把輔助棧的棧頂彈出,輔助棧的棧頂元素2就是新的最小元素。接下來繼續彈出數據棧和輔助棧的棧頂之后,數據棧還剩下3、4兩個數字,3是最小值。此時位于輔助棧的棧頂數字正好也是3,的確是最小值。這說明我們的思路是正確的。
當我們想清楚上述過程之后,就可以寫代碼了。下面是3個關鍵函數push、pop和min的參考代碼。在代碼中,m\_data是數據棧,而m\_min是輔助棧。示例代碼如下:

源代碼:
本題完整的源代碼詳見21\_MinInStack項目。
測試用例:
● 新壓入棧的數字比之前的最小值大。
● 新壓入棧的數字比之前的最小值小。
● 彈出棧的數字不是最小的元素。
● 彈出棧的數字是最小的元素。
本題考點:
● 考查分析復雜問題的思維能力。在面試的時候,很多應聘者都止步于添加一個變量保存最小元素的思路。其實只要舉個例子多做幾次入棧、出棧的操作就能看出問題,并想到也要把最小元素用另外的輔助棧保存。當我們面對一個抽象復雜的問題的時候,可以用幾個具體的例子來找出規律。找到規律之后再解決問題,就容易多了。
● 考查應聘者對棧的理解。
面試題22:棧的壓入、彈出序列
題目:輸入兩個整數序列,第一個序列表示棧的壓入順序,請判斷第二個序列是否為該棧的彈出順序。假設壓入棧的所有數字均不相等。例如序列1、2、3、4、5是某棧的壓棧序列,序列4、5、3、2、1是該壓棧序列對應的一個彈出序列,但4、3、5、1、2就不可能是該壓棧序列的彈出序列。
解決這個問題很直觀的想法就是建立一個輔助棧,把輸入的第一個序列中的數字依次壓入該輔助棧,并按照第二個序列的順序依次從該棧中彈出數字。
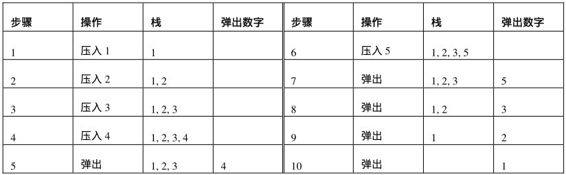
以彈出序列4、5、3、2、1為例分析壓棧和彈出的過程。第一個希望被彈出的數字是4,因此4需要先壓入到輔助棧里面。壓入棧的順序由壓棧序列確定了,也就是在把4壓入進棧之前,數字1、2、3都需要先壓入到棧里面。此時棧里包含4個數字,分別是1、2、3、4,其中4位于棧頂。把4彈出棧后,剩下的三個數字是1、2和3。接下來希望被彈出的數字是5,由于它不是棧頂數字,因此我們接著在第一個序列中把4以后數字壓入輔助棧中,直到壓入了數字5。這個時候5位于棧頂,就可以被彈出來了。接下來希望被彈出的三個數字依次是3、2和1。由于每次操作前它們都位于棧頂,因此直接彈出即可。表4.2總結了本例中入棧和出棧的步驟。
表4.2 壓棧序列為1、2、3、4、5,彈出序列4、5、3、2、1對應的壓棧和彈出過程
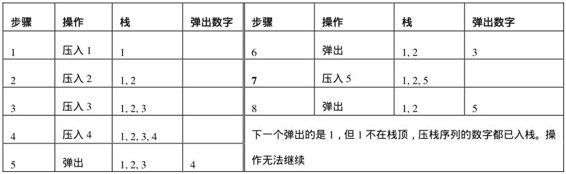
接下來再分析彈出序列4、3、5、1、2。第一個彈出的數字4的情況和前面一樣。把4彈出之后,3位于棧頂,可以直接彈出。接下來希望彈出的數字是5,由于5不是棧頂數字,到壓棧序列里把沒有壓棧的數字壓入輔助棧,直至遇到數字5。把數字5壓入棧之后,5就位于棧頂了,可以彈出。此時棧內有兩個數字1和2,其中2位于棧頂。由于接下來需要彈出的數字是1,但1不在棧頂,我們需要從壓棧序列中尚未壓入棧的數字中去搜索這個數字。但此時壓棧序列中所有數字都已經壓入棧了。所以該序列不是序列1、2、3、4、5對應的彈出序列。表4.3總結了這個例子中壓棧和彈出的過程。
表4.3 一個壓入順序為1、2、3、4、5的棧沒有一個彈出序列為4、3、5、1、2
總結上述入棧、出棧的過程,我們可以找到判斷一個序列是不是棧的彈出序列的規律:如果下一個彈出的數字剛好是棧頂數字,那么直接彈出。如果下一個彈出的數字不在棧頂,我們把壓棧序列中還沒有入棧的數字壓入輔助棧,直到把下一個需要彈出的數字壓入棧頂為止。如果所有的數字都壓入棧了仍然沒有找到下一個彈出的數字,那么該序列不可能是一個彈出序列。
形成了清晰的思路之后,我們就可以動手寫代碼了。下面是一段參考代碼:

源代碼:
本題完整的源代碼詳見22\_StackPushPopOrder項目。
測試用例:
● 功能測試(輸入的兩個數組含有多個數字或者只有1個數字,第二個數組是或者不是第一個數組表示的壓入序列對應的棧的彈出序列)。
● 特殊輸入測試(輸入兩個NULL指針)。
本題考點:
● 考查分析復雜問題的能力。剛聽到這個面試題的時候,很多人可能都沒有思路。這個時候,可以通過舉一兩個例子,一步步分析壓棧、彈出的過程,從中找出規律。
● 考查應聘者對棧的理解。
面試題23:從上往下打印二叉樹
題目:從上往下打印出二叉樹的每個結點,同一層的結點按照從左到右的順序打印。例如輸入圖4.5中的二叉樹,則依次打印出8、6、10、5、7、9、11。
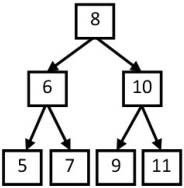
圖4.5 一棵二叉樹,從上往下按層打印的順序為8、6、10、5、7、9、11
二叉樹結點的定義如下:

這道題實質是考查樹的遍歷算法,只是這種遍歷不是我們熟悉的前序、中序或者后序遍歷。由于我們不太熟悉這種按層遍歷的方法,可能一下子也想不清楚遍歷的過程。那面試的時候怎么辦呢?我們不妨先分析一下打印圖4.5中的二叉樹的過程。
因為按層打印的順序決定應該先打印根結點,所以我們從樹的根結點開始分析。為了接下來能夠打印值為8的結點的兩個子結點,我們應該在遍歷到該結點時把值為6和10的兩個結點保存到一個容器里,現在容器內就有兩個結點了。按照從左到右打印的要求,我們先取出值為6的結點。打印出值6之后把它的值分別為5和7的兩個結點放入數據容器。此時數據容器中有三個結點,值分別為10、5和7。接下來我們從數據容器中取出值為10的結點。注意到值為10的結點比值為5、7的結點先放入容器,此時又比這兩個結點先取出,這就是我們通常說的先入先出,因此不難看出這個數據容器應該是一個隊列。由于值為5、7、9、11的結點都沒有子結點,因此只要依次打印即可。整個打印過程如表4.4所示。
表4.4 按層打印圖4.5中的二叉樹的過程
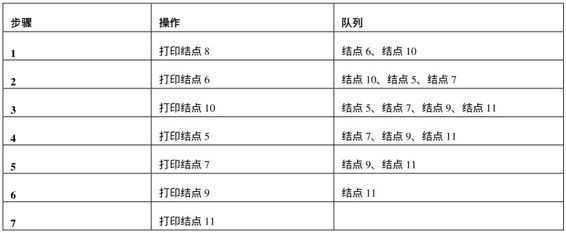
通過上面具體例子的分析,我們可以找到從上到下打印二叉樹的規律:每一次打印一個結點的時候,如果該結點有子結點,則把該結點的子結點放到一個隊列的末尾。接下來到隊列的頭部取出最早進入隊列的結點,重復前面的打印操作,直至隊列中所有的結點都被打印出來為止。
既然我們已經確定數據容器是一個隊列了,現在的問題就是如何實現隊列。實際上我們無須自己動手實現,因為STL已經為我們實現了一個很好的deque(兩端都可以進出的隊列)。下面是用deque實現的參考代碼:

本題考點:
● 考查思維能力。按層從上到下遍歷二叉樹,這對很多應聘者是個新概念,要在短時間內想明白遍歷的過程不是一件容易的事情。應聘者通過具體的例子找出其中的規律并想到基于隊列的算法,是解決這個問題的關鍵所在。
● 考查應聘者對二叉樹及隊列的理解。
本題擴展:
如何廣度優先遍歷一個有向圖?這同樣也可以基于隊列實現。樹是圖的一種特殊退化形式,從上到下按層遍歷二叉樹,從本質上來說就是廣度優先遍歷二叉樹。
舉一反三:
不管是廣度優先遍歷一個有向圖還是一棵樹,都要用到隊列。第一步我們把起始結點(對樹而言是根結點)放入隊列中。接下來每一次從隊列的頭部取出一個結點,遍歷這個結點之后把從它能到達的結點(對樹而言是子結點)都依次放入隊列。我們重復這個遍歷過程,直到隊列中的結點全部被遍歷為止。
面試題24:二叉搜索樹的后序遍歷序列
題目:輸入一個整數數組,判斷該數組是不是某二叉搜索樹的后序遍歷的結果。如果是則返回true,否則返回false。假設輸入的數組的任意兩個數字都互不相同。
例如輸入數組{5,7,6,9,11,10,8},則返回true,因為這個整數序列是圖4.6二叉搜索樹的后序遍歷結果。如果輸入的數組是{7,4,6,5},由于沒有哪棵二叉搜索樹的后序遍歷的結果是這個序列,因此返回false。
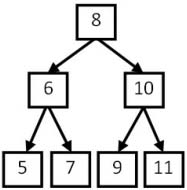
圖4.6 后序遍歷序列5、7、6、9、11、10、8對應的二叉搜索樹
在后序遍歷得到的序列中,最后一個數字是樹的根結點的值。數組中前面的數字可以分為兩部分:第一部分是左子樹結點的值,它們都比根結點的值小;第二部分是右子樹結點的值,它們都比根結點的值大。
以數組{5,7,6,9,11,10,8}為例,后序遍歷結果的最后一個數字8就是根結點的值。在這個數組中,前3個數字5、7和6都比8小,是值為8的結點的左子樹結點;后3個數字9、11和10都比8大,是值為8的結點的右子樹結點。
我們接下來用同樣的方法確定與數組每一部分對應的子樹的結構。這其實就是一個遞歸的過程。對于序列5、7、6,最后一個數字6是左子樹的根結點的值。數字5比6小,是值為6的結點的左子結點,而7則是它的右子結點。同樣,在序列9、11、10中,最后一個數字10是右子樹的根結點,數字9比10小,是值為10的結點的左子結點,而11則是它的右子結點。
我們再來分析另一個整數數組{7,4,6,5}。后序遍歷的最后一個數是根結點,因此根結點的值是5。由于第一個數字7大于5,因此在對應的二叉搜索樹中,根結點上是沒有左子樹的,數字7、4和6都是右子樹結點的值。但我們發現在右子樹中有一個結點的值是4,比根結點的值5小,這違背了二叉搜索樹的定義。因此不存在一棵二叉搜索樹,它的后序遍歷的結果是7、4、6、5。
找到了規律之后再寫代碼,就不是一件很困難的事情了。下面是參考代碼:

源代碼:
本題完整的源代碼詳見24\_SquenceOfBST項目。
測試用例:
● 功能測試(輸入的后序遍歷的序列對應一棵二叉樹,包括完全二叉樹、所有結點都沒有左/右子樹的二叉樹、只有一個結點的二叉樹;輸入的后序遍歷的序列沒有對應一棵二叉樹)。
● 特殊輸入測試(指向后序遍歷序列的指針為NULL指針)。
本題考點:
● 考查分析復雜問題的思維能力。能否解決這道題的關鍵在于應聘者是否能找出后序遍歷的規律。一旦找到規律了,用遞歸的代碼編碼相對而言就簡單了。在面試的時候,應聘者可以從一兩個例子入手,通過分析具體的例子尋找規律。
● 考查對二叉樹后序遍歷的理解。
相關題目:
輸入一個整數數組,判斷該數組是不是某二叉搜索樹的前序遍歷的結果。這和前面問題的后序遍歷很類似,只是在前序遍歷得到的序列中,第一個數字是根結點的值。
舉一反三:
如果面試題是要求處理一棵二叉樹的遍歷序列,我們可以先找到二叉樹的根結點,再基于根結點把整棵樹的遍歷序列拆分成左子樹對應的子序列和右子樹對應的子序列,接下來再遞歸地處理這兩個子序列。本面試題是應用這個思路,面試題6“重建二叉樹”也是應用這個思路。
面試題25:二叉樹中和為某一值的路徑
題目:輸入一棵二叉樹和一個整數,打印出二叉樹中結點值的和為輸入整數的所有路徑。從樹的根結點開始往下一直到葉結點所經過的結點形成一條路徑。二叉樹結點的定義如下:

例如輸入圖4.7中二叉樹和整數22,則打印出兩條路徑,第一條路徑包含結點10、12,第二條路徑包含結點10、5和7。
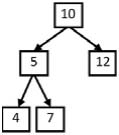
圖4.7 二叉樹中有兩條和為22的路徑:一條路徑經過結點10、5、7,另一條路徑經過結點10、12
一般的數據結構和算法的教材都沒有介紹樹的路徑,因此對大多數應聘者而言,這是一個新概念,也就很難一下子想出完整的解題思路。這個時候我們可以試著從一兩個具體的例子入手,找到規律。
以圖4.7的二叉樹作為例子來分析。由于路徑是從根結點出發到葉結點,也就是說路徑總是以根結點為起始點,因此我們首先需要遍歷根結點。在樹的前序、中序、后序三種遍歷方式中,只有前序遍歷是首先訪問根結點的。
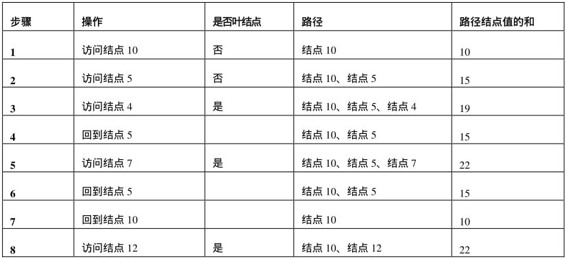
按照前序遍歷的順序遍歷圖4.7中的二叉樹,在訪問結點10之后,就會訪問結點5。從二叉樹結點的定義可以看出,在本題的二叉樹結點中沒有指向父結點的指針,訪問到結點5的時候,我們是不知道前面經過了哪些結點的,除非我們把經過的路徑上的結點保存下來。每訪問到一個結點的時候,我們都把當前的結點添加到路徑中去。到達結點5時,路徑中包含兩個結點,它們的值分別是10和5。接下來遍歷到結點4,我們把這個結點也添加到路徑中。這個時候已經到達了葉結點,但路徑上三個結點的值之和是19。這個和不等于輸入的值22,因此不是符合要求的路徑。
我們接著要遍歷其他的結點。在遍歷下一個結點之前,先要從結點4回到結點5,再去遍歷結點5的右子結點7。值得注意的是,回到結點5的時候,由于結點4已經不在前往結點7的路徑上了,我們需要把結點4從路徑中刪除。接下來訪問到結點7的時候,再把該結點添加到路徑中。此時路徑中三個結點10、5、7之和剛好是22,是一條符合要求的路徑。
我們最后要遍歷的結點是12。在遍歷這個結點之前,需要先經過結點5回到結點10。同樣,每一次當從子結點回到父結點的時候,我們都需要在路徑上刪除子結點。最后從結點10到達結點12的時候,路徑上的兩個結點的值之和也是22,因此這也是一條符合條件的路徑。
我們可以用表4.5總結上述的分析過程。
表4.5 遍歷圖4.7中的二叉樹的過程
分析完前面具體的例子之后,我們就找到了一些規律。當用前序遍歷的方式訪問到某一結點時,我們把該結點添加到路徑上,并累加該結點的值。如果該結點為葉結點并且路徑中結點值的和剛好等于輸入的整數,則當前的路徑符合要求,我們把它打印出來。如果當前結點不是葉結點,則繼續訪問它的子結點。當前結點訪問結束后,遞歸函數將自動回到它的父結點。因此我們在函數退出之前要在路徑上刪除當前結點并減去當前結點的值,以確保返回父結點時路徑剛好是從根結點到父結點的路徑。我們不難看出保存路徑的數據結構實際上是一個棧,因為路徑要與遞歸調用狀態一致,而遞歸調用的本質就是一個壓棧和出棧的過程。
形成了清晰的思路之后,就可以動手寫代碼了。下面是一段參考代碼:

在前面的代碼中,我們用標準模板庫中的vector實現了一個棧來保存路徑,每一次都用push\_back在路徑的末尾添加結點,用pop\_back在路徑的末尾刪除結點,這樣就保證了棧的先入后出的特性。這里沒有直接用STL中的stack的原因是在stack中只能得到棧頂元素,而我們打印路徑的時候需要得到路徑上的所有結點,因此在代碼實現的時候std::stack不是最好的選擇。
源代碼:
本題完整的源代碼詳見25\_PathInTree項目。
測試用例:
● 功能測試(二叉樹中有一條、多條符合條件的路徑,二叉樹中沒有符合條件的路徑)。
● 特殊輸入測試(指向二叉樹根結點的指針為NULL指針)。
本題考點:
● 考查分析復雜問題的思維能力。應聘者遇到這個問題的時候,如果一下子沒有思路,不妨從一個具體的例子開始,一步步分析路徑上包含哪些結點,這樣就能找出其中的規律,從而想到解決方案。
● 考查對二叉樹的前序遍歷的理解。
4.4 分解讓復雜問題簡單化
很多讀者可能都知道“各個擊破”的軍事思想,這種思想的精髓是當敵我實力懸殊時,我們可以把強大的敵人分割開來,然后集中優勢兵力打敗被分割開來的小部分敵人。要一下子戰勝總體很強大的敵人很困難,但戰勝小股敵人就容易多了。同樣,在面試中當我們遇到復雜的大問題的時候,如果能夠先把大問題分解成若干個簡單的小問題,然后再逐個解決這些小問題,那可能也會容易很多。
我們可以按照解決問題的步驟來分解復雜問題,每一步解決一個小問題。比如在面試題26“復雜鏈表的復制”中,我們將復雜鏈表復制的過程分解成三個步驟。在寫代碼的時候我們為每一步定義一個函數,這樣每個函數完成一個功能,整個過程的邏輯也就非常清晰明了了。
在計算機領域有一類算法叫分治法,即“分而治之”,采用的就是各個擊破的思想。我們把分解之后的小問題各個解決,然后把小問題的解決方案結合起來解決大問題。比如面試題27“二叉搜索樹與雙向鏈表”中,轉換整個二叉樹是一個大問題,我們先把這個大問題分解成轉換左子樹和右子樹兩個小問題,然后再把轉換左右子樹得到的鏈表和根結點鏈接起來,就解決了整個大問題。通常分治法思路都可以用遞歸的代碼實現。
在面試題28“字符串的排列”中,我們把整個字符串分為兩部分:第一個字符及它后面的所有字符。我們先拿第一個字符和后面的每個字符交換,交換之后再求后面所有字符的排列。整個字符串的排列是一個大問題,那么第一個字符之后的字符串的排列就是一個小問題。因此這實際上也是分治法的應用,可以用遞歸實現。
面試題26:復雜鏈表的復制
題目:請實現函數ComplexListNode\* Clone(ComplexListNode\* pHead),復制一個復雜鏈表。在復雜鏈表中,每個結點除了有一個m\_pNext指針指向下一個結點外,還有一個m\_pSibling 指向鏈表中的任意結點或者NULL。結點的C++定義如下:
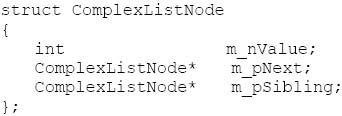
圖4.8是一個含有5個結點的復雜鏈表。圖中實線箭頭表示m\_pNext指針,虛線箭頭表示m\_pSibling指針。為簡單起見,指向NULL的指針沒有畫出。
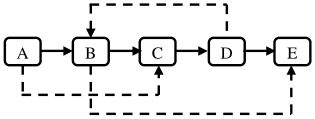
圖4.8 一個含有5個結點的復雜鏈表
注:在復雜鏈表的結點中,除了有指向下一結點的指針(實線箭頭)外,還有指向任意結點的指針(虛線箭頭)。
聽到這個問題之后,很多應聘者的第一反應是把復制過程分成兩步:第一步是復制原始鏈表上的每一個結點,并用m\_pNext鏈接起來;第二步是設置每個結點的m\_pSibling指針。假設原始鏈表中的某個結點N的m\_pSibling指向結點S,由于S的位置在鏈表中可能在N的前面也可能在N的后面,所以要定位S的位置需要從原始鏈表的頭結點開始找。如果從原始鏈表的頭結點開始沿著m\_pNext經過s步找到結點S,那么在復制鏈表上結點N’的m\_pSibling(記為S’)離復制鏈表的頭結點的距離也是沿著m\_pNext指針s步。用這種辦法我們就可以為復制鏈表上的每個結點設置m\_pSibling指針。
對于一個含有n個結點的鏈表,由于定位每個結點的m\_pSibling都需要從鏈表頭結點開始經過O(n)步才能找到,因此這種方法的總時間復雜度是O(n2)。
由于上述方法的時間主要花費在定位結點的m\_pSibling上面,我們試著在這方面去做優化。我們還是分為兩步:第一步仍然是復制原始鏈表上的每個結點N創建N’,然后把這些創建出來的結點用m\_pNext鏈接起來。同時我們把<N,N’>的配對信息放到一個哈希表中。第二步還是設置復制鏈表上每個結點的m\_pSibling。如果在原始鏈表中結點N的m\_pSibling指向結點S,那么在復制鏈表中,對應的N’應該指向S’。由于有了哈希表,我們可以用O(1)的時間根據S找到S’。
第二種方法相當于用空間換時間。對于有n個結點的鏈表我們需要一個大小為O(n)的哈希表,也就是說我們以O(n)的空間消耗把時間復雜度由O(n2)降低到O(n)。
接下來我們再換一種思路,在不用輔助空間的情況下實現O(n)的時間效率。第三種方法的第一步仍然是根據原始鏈表的每個結點N創建對應的N’。這一次,我們把N’鏈接在N的后面。圖4.8的鏈表經過這一步之后的結構,如圖4.9所示。

圖4.9 復制復雜鏈表的第一步
注:復制原始鏈表的任意結點N并創建新結點N',再把N'鏈接到N的后面。
完成這一步的代碼如下:

第二步設置復制出來的結點的m\_pSibling。假設原始鏈表上的N的m\_pSibling指向結點S,那么其對應復制出來的N’是N的m\_pNext指向的結點,同樣S’也是S的m\_pNext指向的結點。設置m\_pSibling之后的鏈表如圖4.10所示。

圖4.10 復制復雜鏈表的第二步
注:如果原始鏈表上的結點N的m\_pSibling指向S,則它對應的復制結點N'的m\_pSibling指向S的下一結點S'。
下面是完成第二步的參考代碼:

第三步把這個長鏈表拆分成兩個鏈表:把奇數位置的結點用m\_pNext鏈接起來就是原始鏈表,把偶數位置的結點用m\_pNext鏈接起來就是復制出來的鏈表。圖4.10中的鏈表拆分之后的兩個鏈表如圖4.11所示。
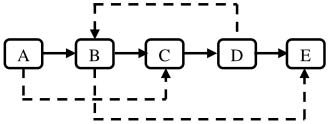
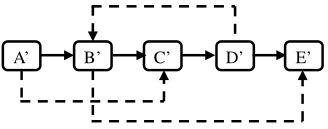
圖4.11 復制復雜鏈表的第三步
注:把第二步得到的鏈表拆分成兩個鏈表,奇數位置上的結點組成原始鏈表,偶數位置上的結點組成復制出來的鏈表。
要實現第三步的操作,也不是很難的事情。其對應的代碼如下:

我們把上面三步合起來,就是復制鏈表的完整過程:

源代碼:
本題完整的源代碼詳見26\_CopyComplexList項目。
測試用例:
● 功能測試(包括結點中的m\_pSibling指向結點自身,兩個結點的m\_pSibling形成環狀結構,鏈表中只有一個結點)。
● 特殊輸入測試(指向鏈表頭結點的指針為NULL指針)。
本題考點:
● 考查應聘者對復雜問題的思維能力。本題中的復雜鏈表是一種不太常見的數據結構,而且復制這種鏈表的過程也較為復雜。我們把復雜鏈表的復制過程分解成三個步驟,同時把每一個步驟都用圖形化的方式表示出來,這些方法都能幫助我們理清思路。寫代碼的時候,我們為每一個步驟定義一個子函數,最后在復制函數中先后調用者3個函數。有了這些清晰的思路之后再寫代碼,就容易多了。
● 考查應聘者分析時間效率和空間效率的能力。當應聘者提出第一種和第二種思路的時候,面試官會提示此時在效率上還不是最優解。這個時候應聘者要能自己分析出這兩種算法的時間復雜度和空間復雜度各是多少。
面試題27:二叉搜索樹與雙向鏈表
題目:輸入一棵二叉搜索樹,將該二叉搜索樹轉換成一個排序的雙向鏈表。要求不能創建任何新的結點,只能調整樹中結點指針的指向。比如輸入圖4.12中左邊的二叉搜索樹,則輸出轉換之后的排序雙向鏈表。
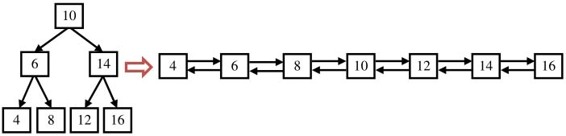
圖4.12 一棵二叉搜索樹及轉換之后的排序雙向鏈表
二叉樹結點的定義如下:

在二叉樹中,每個結點都有兩個指向子結點的指針。在雙向鏈表中,每個結點也有兩個指針,它們分別指向前一個結點和后一個結點。由于這兩種結點的結構相似,同時二叉搜索樹也是一種排序的數據結構,因此在理論上有可能實現二叉搜索樹和排序的雙向鏈表的轉換。在搜索二叉樹中,左子結點的值總是小于父結點的值,右子結點的值總是大于父結點的值。因此我們在轉換成排序雙向鏈表時,原先指向左子結點的指針調整為鏈表中指向前一個結點的指針,原先指向右子結點的指針調整為鏈表中指向后一個結點指針。接下來我們考慮該如何轉換。
由于要求轉換之后的鏈表是排好序的,我們可以中序遍歷樹中的每一個結點,這是因為中序遍歷算法的特點是按照從小到大的順序遍歷二叉樹的每一個結點。當遍歷到根結點的時候,我們把樹看成三部分:值為10的結點、根結點值為6的左子樹、根結點值為14的右子樹。根據排序鏈表的定義,值為10的結點將和它的左子樹的最大一個結點(即值為8的結點)鏈接起來,同時它還將和右子樹最小的結點(即值為12的結點)鏈接起來,如圖4.13所示。
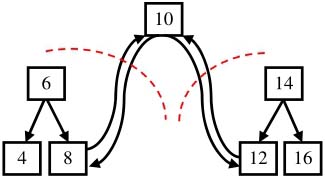
圖4.13 把二叉搜索樹看成三部分
注:根結點、左子樹和右子樹。在把左、右子樹都轉換成排序的雙向鏈表之后再和根結點鏈接起來,整棵二叉搜索樹也就轉換成了排序的雙向鏈表。
按照中序遍歷的順序,當我們遍歷轉換到根結點(值為10的結點)時,它的左子樹已經轉換成一個排序的鏈表了,并且處在鏈表中的最后一個結點是當前值最大的結點。我們把值為8的結點和根結點鏈接起來,此時鏈表中的最后一個結點就是10了。接著我們去遍歷轉換右子樹,并把根結點和右子樹中最小的結點鏈接起來。至于怎么去轉換它的左子樹和右子樹,由于遍歷和轉換過程是一樣的,我們很自然地想到可以用遞歸。
基于上述分析過程,我們可以寫出如下代碼:

在上面的代碼中,我們用pLastNodeInList指向已經轉換好的鏈表的最后一個結點(也是值最大的結點)。當我們遍歷到值為10的結點的時候,它的左子樹都已經轉換好了,因此pLastNodeInList指向值為8的結點。接著把根結點鏈接到鏈表中之后,值為10的結點成了鏈表中的最后一個結點(新的值最大的結點),于是pLastNodeInList指向了這個值為10的結點。接下來把pLastNodeInList 作為參數傳入函數遞歸遍歷右子樹。我們找到右子樹中最左邊的子結點(值為12的結點,在右子樹中值最小),并把該結點和值為10的結點鏈接起來。
源代碼:
本題完整的源代碼詳見27\_ConvertBinarySearchTree項目。
測試用例:
● 功能測試(輸入的二叉樹是完全二叉樹,所有結點都沒有左/右子樹的二叉樹,只有一個結點的二叉樹)。
● 特殊輸入測試(指向二叉樹根結點的指針為NULL指針)。
本題考點:
● 考查應聘者分析復雜問題的能力。無論是二叉樹還是雙向鏈表,都有很多指針。要實現這兩種不同數據結構的轉換,需要調整大量的指針,因此這個過程會很復雜。為了把這個復雜的問題分析清楚,我們可以把樹分為三個部分:根結點、左子樹和右子樹,然后把左子樹中最大的結點、根結點、右子樹中最小的結點鏈接起來。至于如何把左子樹和右子樹內部的結點鏈接成鏈表,那和原來的問題的實質是一樣的,因此可以遞歸解決。解決這個問題的關鍵在于把一個大的問題分解成幾個小問題,并遞歸地解決小問題。
● 考查對二叉樹、雙向鏈表的理解及編程能力。
面試題28:字符串的排列
題目:輸入一個字符串,打印出該字符串中字符的所有排列。例如輸入字符串abc,則打印出由字符a、b、c所能排列出來的所有字符串abc、acb、bac、bca、cab和cba。
如何求出幾個字符的所有排列,很多人都不能一下子想出解決方案。那我們是不是可以考慮把這個復雜的問題分解成小的問題呢?比如,我們把一個字符串看成由兩部分組成:第一部分為它的第一個字符,第二部分是后面的所有字符。在圖4.14中,我們用兩種不同的背景顏色區分字符串的兩部分。
我們求整個字符串的排列,可以看成兩步:首先求所有可能出現在第一個位置的字符,即把第一個字符和后面所有的字符交換。圖4.14就是分別把第一個字符a和后面的b、c等字符交換的情形。首先固定第一個字符(如圖4.14(a)所示),求后面所有字符的排列。這個時候我們仍把后面的所有字符分成兩部分:后面字符的第一個字符,以及這個字符之后的所有字符。然后把第一個字符逐一和它后面的字符交換(如圖4.14(b)所示)……
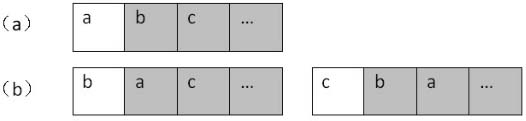
圖4.14 求字符串的排列的過程
注:(a)把字符串分為兩部分,一部分是字符串的第一個字符,另一部分是第一個字符以后的所有字符(有陰影背景的區域)。接下來我們求陰影部分的字符串的排列。(b)拿第一個字符和它后面的字符逐個交換。
分析到這里,我們就可以看出,這其實是很典型的遞歸思路,于是我們不難寫出如下代碼:

在函數Permutation(char\* pStr, char\* pBegin)中,指針pStr指向整個字符串的第一個字符,pBegin指向當前我們做排列操作的字符串的第一個字符。在每一次遞歸的時候,我們從pBegin向后掃描每一個字符(即指針pCh指向的字符)。在交換pBegin和pCh指向的字符之后,我們再對pBegin后面的字符串遞歸地做排列操作,直至pBegin指向字符串的末尾。
源代碼:
本題完整的源代碼詳見28\_StringPermutation項目。
測試用例:
● 功能測試(輸入的字符串中有1個或者多個字符)。
● 特殊輸入測試(輸入的字符串的內容為空或者是NULL指針)。
本題考點:
● 考查思維能力。當整個問題看起來不能直接解決的時候,應聘者能否想到把字符串分成兩部分,從而把大問題分解成小問題來解決,是能否順利解決這個問題的關鍵。
● 考查對遞歸的理解和編程能力。
本題擴展:
如果不是求字符的所有排列,而是求字符的所有組合,應該怎么辦呢?還是輸入三個字符a、b、c,則它們的組合有a、b、c、ab、ac、bc、abc。當交換字符串中的兩個字符時,雖然能得到兩個不同的排列,但卻是同一個組合。比如ab和ba是不同的排列,但只算一個組合。
如果輸入n個字符,則這n個字符能構成長度為1的組合、長度為2的組合、……、長度為n的組合。在求n個字符的長度為m(1≤m≤n)的組合的時候,我們把這n個字符分成兩部分:第一個字符和其余的所有字符。如果組合里包含第一個字符,則下一步在剩余的字符里選取m-1個字符;如果組合里不包含第一個字符,則下一步在剩余的n-1個字符里選取m個字符。也就是說,我們可以把求n個字符組成長度為m的組合的問題分解成兩個子問題,分別求n-1個字符串中長度為m-1的組合,以及求n-1個字符的長度為m的組合。這兩個子問題都可以用遞歸的方式解決。
相關題目:
1.輸入一個含有8個數字的數組,判斷有沒有可能把這8個數字分別放到正方體的8個頂點上(如圖4.15所示),使得正方體上三組相對的面上的4個頂點的和都相等。
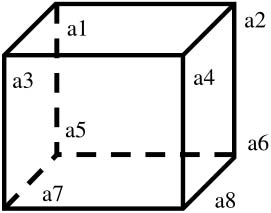
圖4.15 把8個數字放到正方體的8個頂點上
這相當于先得到a1、a2、a3、a4、a5、a6、a7和a8這8個數字的所有排列,然后判斷有沒有某一個的排列符合題目給定的條件,即a1+a2+a3+a4=a5+a6+a7+a8,a1+a3+a5+a7=a2+a4+a6+a8,并且a1+a2+a5+a6=a3+a4+a7+a8。
2.在8×8的國際象棋上擺放8個皇后,使其不能相互攻擊,即任意兩個皇后不得處在同一行、同一列或者同一對角線上。圖4.16中的每個黑色格子表示一個皇后,這就是一種符合條件的擺放方法。請問總共有多少種符合條件的擺法?

圖4.16 8×8的國際象棋棋盤上擺著8個皇后(黑色小方格),任意兩個皇后不在同一行、同一列或者同一對角線上
由于8個皇后的任意兩個不能處在同一行,那么肯定是每一個皇后占據一行。于是我們可以定義一個數組ColumnIndex\[8\],數組中第i個數字表示位于第i行的皇后的列號。先把數組ColumnIndex的8個數字分別用0~7初始化,接下來就是對數組ColumnIndex做全排列。因為我們是用不同的數字初始化數組,所以任意兩個皇后肯定不同列。我們只需判斷每一個排列對應的8個皇后是不是在同一對角線上,也就是對于數組的兩個下標i和j,是不是i-j=ColumnIndex\[i\]-ColumnIndex\[j\]或者j-i=ColumnIndex\[i\]-ColumnIndex\[j\]。
舉一反三:
如果面試題是按照一定要求擺放若干個數字,我們可以先求出這些數字的所有排列,然后再一一判斷每個排列是不是滿足題目給定的要求。
4.5 本章小結
面試的時候我們難免會遇到難題,畫圖、舉例子和分解這三種辦法能夠幫助我們解決復雜的問題(如圖4.17所示)。
圖4.17 解決復雜問題的三種方法:畫圖、舉例子和分解。
圖形能使抽象的問題形象化。當面試題涉及鏈表、二叉樹等數據結構時,如果在紙上畫幾張草圖,題目中隱藏的規律就有可能變得很直觀。
一兩個例子能使抽象的問題具體化。很多與算法相關的問題都很抽象,未必一眼就能看出它們的規律。這個時候我們不妨舉幾個例子,一步一步模擬運行的過程,說不定就能發現其中的規律,從而找到解決問題的竅門。
把復雜問題分解成若干個小問題,是解決很多復雜問題的有效方法。如果我們遇到的問題很大,可以嘗試先把大問題分解成小問題,然后再遞歸地解決這些小問題。分治法、動態規劃等方法都是應用分解復雜問題的思路。
- 目錄
- 扉頁
- 版權頁
- 推薦序一
- 推薦序二
- 前言
- 第1章 面試的流程
- 1.1 面試官談面試
- 1.2 面試的三種形式
- 1.2.1 電話面試
- 1.2.2 共享桌面遠程面試
- 1.2.3 現場面試
- 1.3 面試的三個環節
- 1.3.1 行為面試環節
- 1.應聘者的項目經驗
- 2.應聘者掌握的技能
- 3.回答“為什么跳槽”
- 1.3.2 技術面試環節
- 1.扎實的基礎知識
- 2.高質量的代碼
- 3.清晰的思路
- 4.優化效率的能力
- 5.優秀的綜合能力
- 1.3.3 應聘者提問環節
- 1.4 本章小結
- 第2章 面試需要的基礎知識
- 2.1 面試官談基礎知識
- 2.2 編程語言
- 2.2.1 C++
- 面試題1:賦值運算符函數
- 經典的解法,適用于初級程序員
- 考慮異常安全性的解法,高級程序員必備
- 2.2.2 C#
- 面試題2:實現Singleton模式
- 不好的解法一:只適用于單線程環境
- 不好的解法二:雖然在多線程環境中能工作但效率不高
- 可行的解法:加同步鎖前后兩次判斷實例是否已存在
- 強烈推薦的解法一:利用靜態構造函數
- 強烈推薦的解法二:實現按需創建實例
- 解法比較
- 2.3 數據結構
- 2.3.1 數組
- 面試題3:二維數組中的查找
- 2.3.2 字符串
- 面試題4:替換空格
- 時間復雜度為O(n2)的解法,不足以拿到Offer
- 時間復雜度為O(n)的解法,搞定Offer就靠它了
- 2.3.3 鏈表
- 面試題5:從尾到頭打印鏈表
- 2.3.4 樹
- 面試題6:重建二叉樹
- 2.3.5 棧和隊列
- 面試題7:用兩個棧實現隊列
- 2.4 算法和數據操作
- 2.4.1 查找和排序
- 面試題8:旋轉數組的最小數字
- 2.4.2 遞歸和循環
- 面試題9:斐波那契數列
- 效率很低的解法,挑剔的面試官不會喜歡
- 面試官期待的實用解法
- 時間復雜度O(logn)但不夠實用的解法
- 解法比較
- 2.4.3 位運算
- 面試題10:二進制中1的個數
- 可能引起死循環的解法
- 常規解法
- 能給面試官帶來驚喜的解法
- 2.5 本章小結
- 第3章 高質量的代碼
- 3.1 面試官談代碼質量
- 3.2 代碼的規范性
- 3.3 代碼的完整性
- 1.從3方面確保代碼的完整性
- 2.3種錯誤處理的方法
- 面試題11:數值的整數次方
- 自以為題目簡單的解法
- 全面但不夠高效的解法,我們離Offer已經很近了
- 全面又高效的解法,確保我們能拿到Offer
- 面試題12:打印1到最大的n位數
- 跳進面試官陷阱
- 在字符串上模擬數字加法的解法,繞過陷阱才能拿到Offer
- 把問題轉換成數字排列的解法,遞歸讓代碼更簡潔
- 面試題13:在O(1)時間刪除鏈表結點
- 面試題14:調整數組順序使奇數位于偶數前面
- 只完成基本功能的解法,僅適用于初級程序員
- 考慮可擴展性的解法,能秒殺Offer
- 3.4 代碼的魯棒性
- 面試題15:鏈表中倒數第k個結點
- 面試題16:反轉鏈表
- 面試題17:合并兩個排序的鏈表
- 面試題18:樹的子結構
- 3.5 本章小結
- 第4章 解決面試題的思路
- 4.1 面試官談面試思路
- 4.2 畫圖讓抽象問題形象化
- 面試題19:二叉樹的鏡像
- 面試題20:順時針打印矩陣
- 4.3 舉例讓抽象問題具體化
- 面試題21:包含min函數的棧
- 面試題22:棧的壓入、彈出序列
- 面試題23:從上往下打印二叉樹
- 面試題24:二叉搜索樹的后序遍歷序列
- 面試題25:二叉樹中和為某一值的路徑
- 4.4 分解讓復雜問題簡單化
- 面試題26:復雜鏈表的復制
- 面試題27:二叉搜索樹與雙向鏈表
- 面試題28:字符串的排列
- 4.5 本章小結
- 第5章 優化時間和空間效率
- 5.1 面試官談效率
- 5.2 時間效率
- 面試題29:數組中出現次數超過一半的數字
- 解法一:基于Partition函數的O(n)算法
- 解法二:根據數組特點找出O(n)的算法
- 解法比較
- 面試題30:最小的k個數
- 解法一:O(n)的算法,只有當我們可以修改輸入的數組時可用
- 解法二:O(nlogk)的算法,特別適合處理海量數據
- 解法比較
- 面試題31:連續子數組的最大和
- 解法一:舉例分析數組的規律
- 解法二:應用動態規劃法
- 面試題32:從1到n整數中1出現的次數
- 不考慮時間效率的解法,靠它想拿Offer有點難
- 從數字規律著手明顯提高時間效率的解法,能讓面試官耳目一新
- 面試題33:把數組排成最小的數
- 5.3 時間效率與空間效率的平衡
- 面試題34:丑數
- 逐個判斷每個整數是不是丑數的解法,直觀但不夠高效
- 創建數組保存已經找到的丑數,用空間換時間的解法
- 面試題35:第一個只出現一次的字符
- 面試題36:數組中的逆序對
- 面試題37:兩個鏈表的第一個公共結點
- 5.4 本章小結
- 第6章 面試中的各項能力
- 6.1 面試官談能力
- 6.2 溝通能力和學習能力
- 1.溝通能力
- 2.學習能力
- 3.善于學習、溝通的人也善于提問
- 6.3 知識遷移能力
- 面試題38:數字在排序數組中出現的次數
- 面試題39:二叉樹的深度
- 需要重復遍歷結點多次的解法,簡單但不足以打動面試官
- 每個結點只遍歷一次的解法,正是面試官喜歡的
- 面試題40:數組中只出現一次的數字
- 面試題41:和為s的兩個數字VS和為s的連續正數序列
- 面試題42:翻轉單詞順序VS左旋轉字符串
- 6.4 抽象建模能力
- 面試題43:n個骰子的點數
- 解法一:基于遞歸求骰子點數,時間效率不夠高
- 解法二:基于循環求骰子點數,時間性能好
- 面試題44:撲克牌的順子
- 面試題45:圓圈中最后剩下的數字
- 經典的解法,用環形鏈表模擬圓圈
- 創新的解法,拿到Offer不在話下
- 6.5 發散思維能力
- 面試題46:求1+2+…+n
- 解法一:利用構造函數求解
- 解法二:利用虛函數求解
- 解法三:利用函數指針求解
- 解法四:利用模板類型求解
- 面試題47:不用加減乘除做加法
- 面試題48:不能被繼承的類
- 常規的解法:把構造函數設為私有函數
- 新奇的解法:利用虛擬繼承,能給面試官留下很好的印象
- 6.6 本章小結
- 第7章 兩個面試案例
- 7.1 案例一:(面試題49)把字符串轉換成整數
- 7.2 案例二:(面試題50)樹中兩個結點的最低公共祖先