# 第四部分 神經網絡
## 四十三、神經網絡簡介
歡迎閱讀機器學習系列教程的一個新部分:深度學習和神經網絡、以及 TensorFlow。人造的神經網絡受生物學啟發,用于指導機器學習,刻意模擬你的大腦(生物神經網絡)。
人造神經網絡是個新的概念,我現在將其用神經網絡來指代。這個概念刻意追溯到 20 世紀 40 年代,并且有數次波動,尤其是跟支持向量機來比較。例如,神經網絡直到 90 年代中期才流行,同時 SVM 使用一種新公開的技術(技術在應用之前經過了很長時間),“核的技巧”,適用于非線性分隔的數據集。有了它,SVM 再次流行起來,將神經網絡和很多有趣的東西遺留在了后面,直到 2011 年。由于大量的可用數據集,以及更加強大的計算機,這個時候神經網絡使用新的技巧,開始優于 SVM。
這就是為什么,如果你打算致力于機器學習領域,理解其它模型也是很重要的,因為趨勢可以或者的確改變了。既然我們有了一些機器,它們能夠實際執行神經網絡,我們就有了一個有些有趣的情況,因為人們一直坐著,一直琢磨這個話題已經有十年了。這并不是說,發表神經研究的論文的人很少見,并且有些具體話題的論文在十年前就寫完了。
神經網絡的模型實際上是個非常簡單的概念。這個概念就是模擬神經元(neuron),并且對于一個基本的神經元,它有樹突(dendrites)、細胞核、軸突(axon)和軸突末梢(axon terminal)。
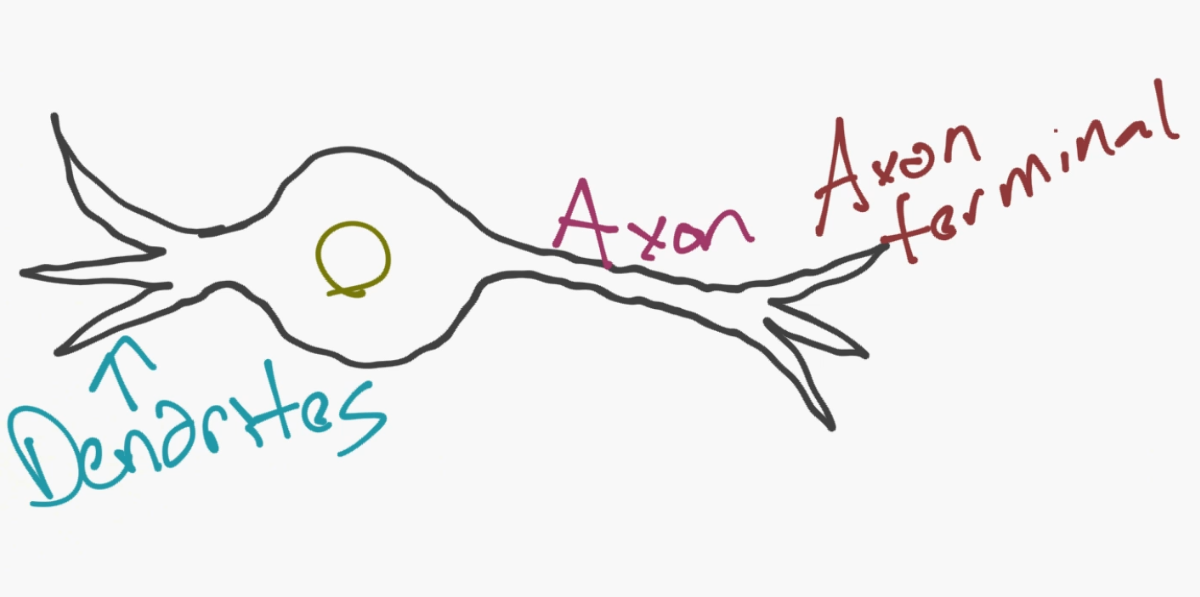
然后,對于一個網絡,你需要兩個神經元。神經元通過樹突和軸突末梢之間的突觸(synapse)來傳遞信息。
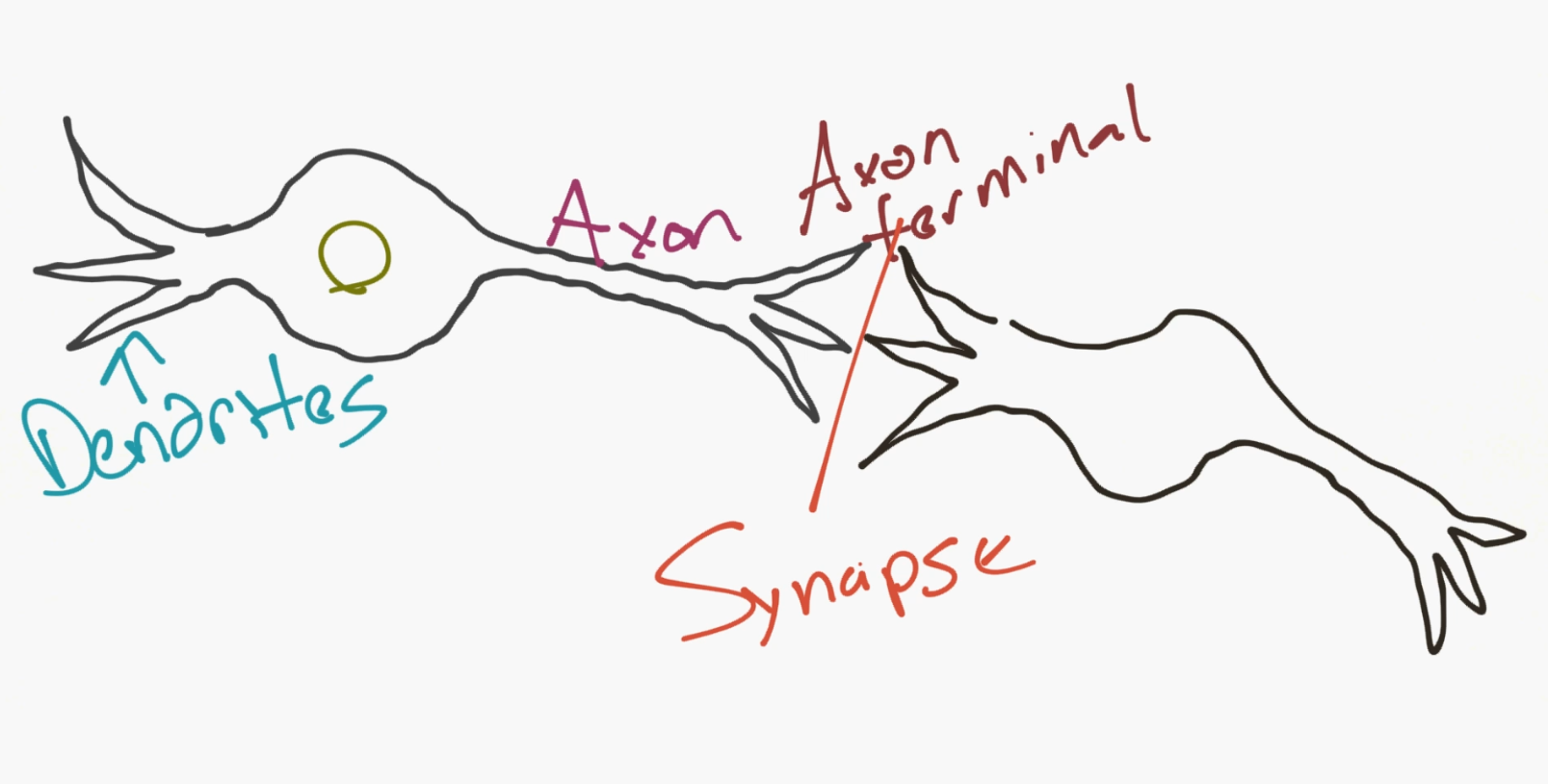
好的,所以這就是神經元的工作方式。現在計算機科學家認為我們可以用這個。所以我們提出了一個人造神經元的模型:
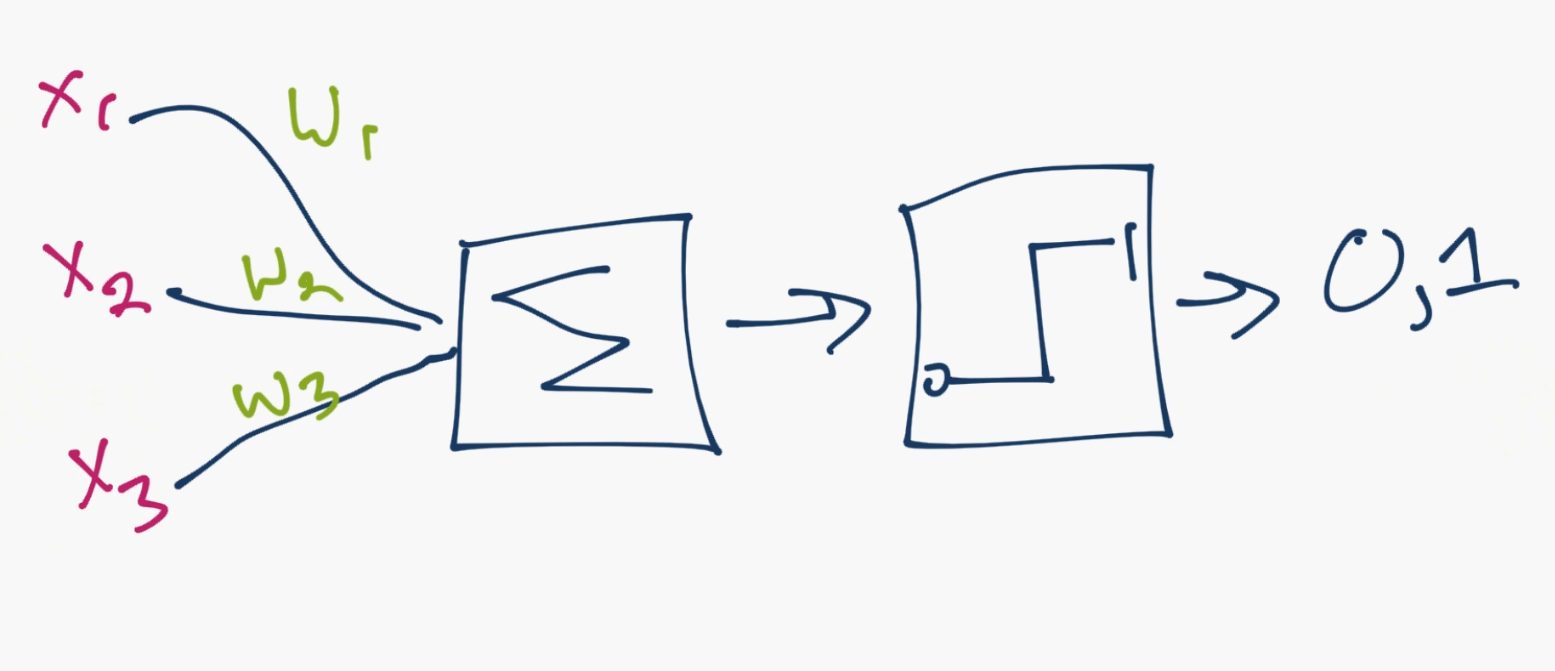
就是這樣。所以你和你的神經元很像了。雖然,我們進一步簡化了事情,并且如果你搜索神經網絡的圖片,你可能看到這個:
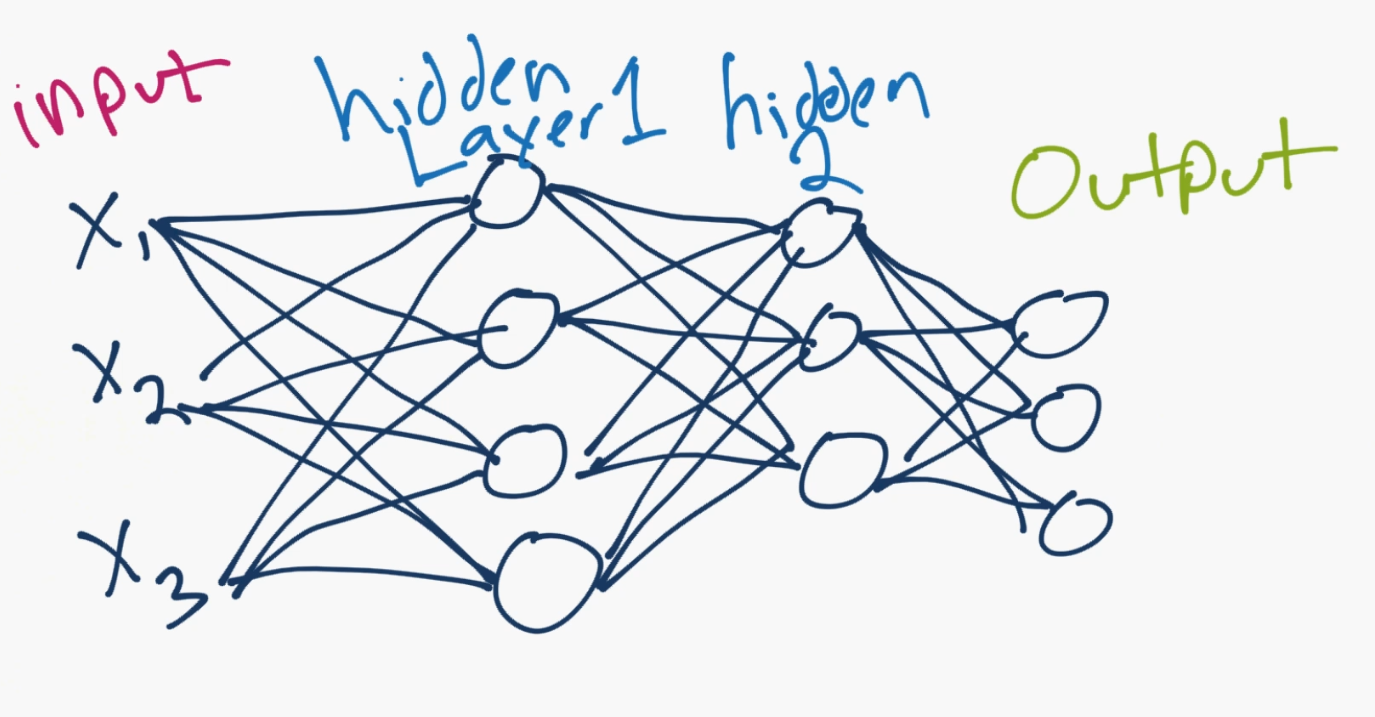
那個圓圈就是神經元或者節點,它們帶有數據上的函數,并且互相連接的線是所傳遞的權重或者信息。每一列都是一個層。你的數據的第一層是輸入層。之后,除非你的輸出就是你的輸入,你擁有至少一個隱藏層。如果你只有一個隱藏層,你就有了一個常規的人造神經網絡。如果你擁有多個隱藏層,你就有了深度神經網絡,是不是很簡單呢?至少是概念上。
所以對于這個模型,你擁有輸入數據,對其加權,并且將其傳給神經元中的函數。神經元中的函數是個閾值函數,也叫作激活函數。基本上,它是使用一個高于或者低于特定值加權之后的總合。如果它是,你就可以得到一個信號(1),或者什么都沒有(0)。然后它加權并且轉給下一個神經元,并且執行同樣的函數。
這就是一個神經網絡模型。所以,什么是權重和閾值函數呢?首先,多虧了 1974 的 Paul Werbos,我們去掉了閾值“變量”。我們不將這些閾值處理為另一個要優化的變量,而是選取然后閾值的值,將其權重為 -1,閾值總是為0,。無論閾值有多大,它都會自行消除,并且始終為 0。我們仍然有一個丑陋的步驟函數,因為神經元產生 0 還是 1 的決策是非常混亂的。我們決定使用某種類型的 sigmoid 函數(S 形)來代替。
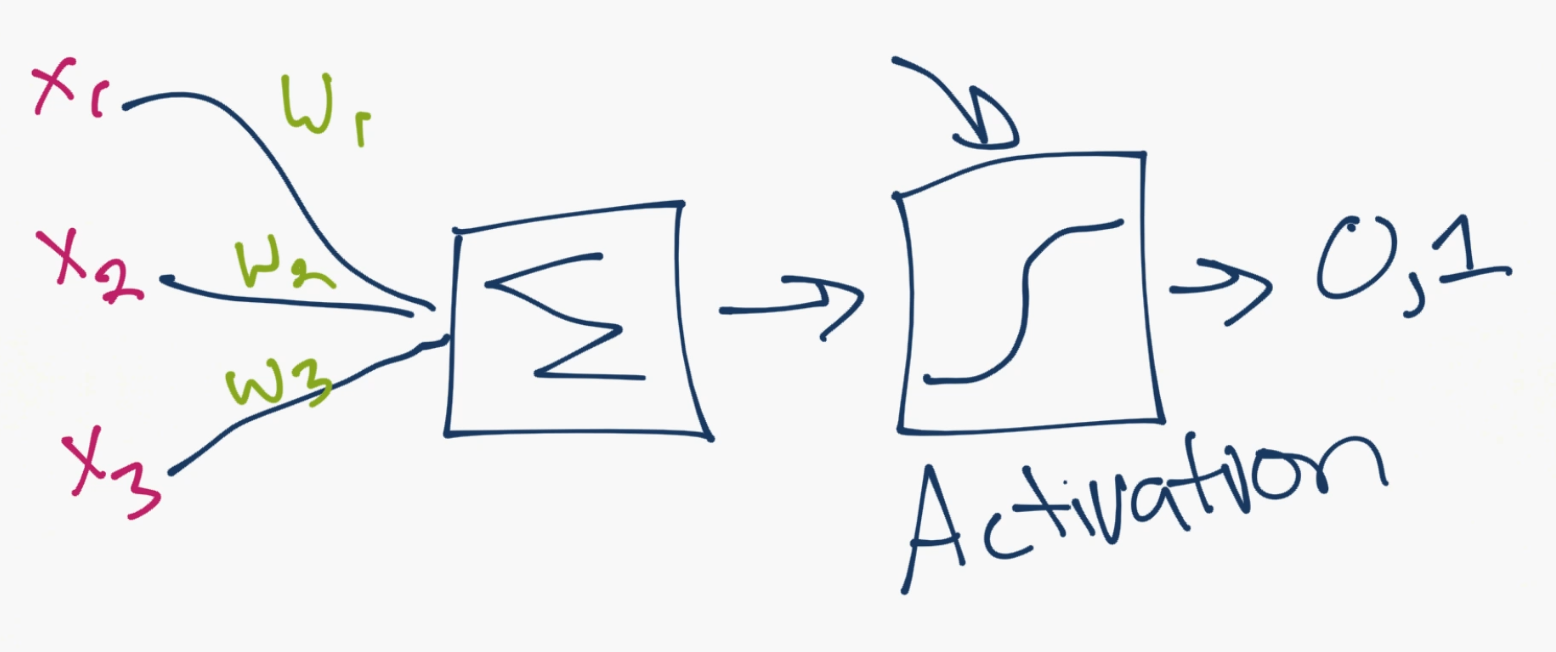
對于權重,它們只是隨機啟動,并且它們對于每個輸入到節點/神經元是唯一的。 然后,在典型的“前饋”(最基本的類型)神經網絡中,你的信息通過你創建的網絡直接傳遞,并使用你的樣本數據,將輸出與期望輸出進行比較。 從這里,你需要調整權重,來幫助你獲得與預期輸出匹配的輸出。 直接通過神經網絡發送數據的行為稱為前饋神經網絡。 我們的數據從輸入層到隱藏層,然后是輸出層。 當我們向后退,開始調整權重來最小化損失/成本時,這稱為反向傳播。
這是一個新的優化問題。 回憶一下,幾個教程之前的支持向量機優化問題,我們如何解釋這是一個很好的凸優化問題。 即使我們有兩個變量,我們的優化問題是一個完美的碗形,所以我們可以知道什么時候達到了最優化,同時沿著路徑執行了大量的步驟,使處理便宜。 使用神經網絡,情況并非如此。 在實際中,你尋找更多成千上萬個變量,甚至數百萬或更多的變量。這里的原始解決方案是使用隨機梯度下降,但還有其他選項,如 AdaGrad 和 Adam Optimizer。無論如何,這是一項巨大的計算任務。
現在你可以看到為什么神經網絡幾乎已經擱置了半個多世紀。 只是最近,我們才擁有了這種能力和架構的機器,以便執行這些操作,以及用于匹配的適當大小的數據集。 好消息是,我們已經有花個世紀來就這個話題進行哲學思考,而且大量的基礎工作已經完成了,只需要實施和測試。
有意思的是,正如我們不完全了解人類大腦一樣,我們并不完全理解神經網絡為什么或如何實現這樣有趣的結果。 通過大量的挖掘和分析,我們可以揭開一些事情,但是由于許多變量和維度,我們實際上并不太了解發生了什么,我們只是看到了很好的結果,并且很開心。 即使是我們的第一個例子,原則上也是非常基本的,但是他做的事情也有驚人的結果。
對于簡單的分類任務,神經網絡在性能上與其他簡單算法相對接近,甚至像 KNN 那樣。 神經網絡中的真正美麗帶來了更大的數據,更復雜的問題,這兩個都使其他機器學習模型變得無力。 例如,當前的神經網絡可以做出如下回答:
> Jack 12 歲,Jane 10 歲,Kate 比 Jane 年長,比 Jack 年輕,Kate 多少歲?
答案是11,一個深度學習模型可以解釋出來,無需你在某種程度上教會如何實際完成邏輯部分。 你只需簡單地傳遞原始數據,它是單詞,甚至是字符,而神經網絡則完成其余部分。 哦,你需要數百萬個樣例! 以數百萬計,我的意思是為了理想的準確度需要約 5 億。
你在哪里得到數以百萬計的樣品?你有一些選擇。圖像數據的一個選擇是 [ImageNet](https://image-net.org/),它在事物的組織中非常類似于 wordnet。如果你不熟悉,你可以提出一個想法。這里的一切都是免費的。接下來,對于文本數據,第一個站點應該是像[維基百科數據轉儲](https://dumps.wikimedia.org/backup-index.html)。這對于更多的深度學習的任務非常有用,而不是標簽數據。接下來,對于更多的文本數據,為什么不去已經被爬去和解析的大部分網站呢?如果這聽起來很有趣,請查看 [CommonCrawl](https://commoncrawl.org/)。這個數據集不是一個笑話,但是它的數據是 PB 級的。對于演講,我并沒有很多思路。一個選項是像 [Tatoeba](https://tatoeba.org/eng/),它有標簽和一些翻譯,這是非常有用的。當一切都失敗時,你可以嘗試創建自己的數據集,但是大小要求相當有挑戰性。另外,你可以隨時尋求幫助。根據我的經驗,存在任何東西的數據集,你只需要找到它。很多時候,Google 在嘗試查找數據集時會失敗,但是人們可以幫助你。目前,你可以在[機器學習 subreddit](https://www.reddit.com/r/machinelearning/) 中嘗試詢問,大概 90% 的內容與神經網絡相關,每個人都需要了解大量的數據集。
現在應該比較明顯的是,像 Facebook 和 Google 這樣的公司,對于 AI 和神經網絡的投入如此之大。 他們實際上擁有所需的數據量來做一些非常有趣的事情。
現在我們有這樣的方式,我們如何在神經網絡上工作? 我們將使用 TensorFlow,這是 Google 的一個相對較新的軟件包,在撰寫本文時仍然是測試版。 還有其他用于機器學習的包,如 Theano 或 Torch,但它們都以類似的方式工作。 我們真的只需要選一個,我選擇 Tensorflow。 在下一個教程中,我們將安裝 TensorFlow。 如果你已經安裝了 TensorFlow,可以跳過下一個教程(使用側面導航欄,或者單擊下一步,滾動到底部,然后再次單擊)。
## 四十四、為神經網絡安裝 TensorFlow(可選)
> 原文:[Installing TensorFlow for Deep Learning - OPTIONAL
](https://pythonprogramming.net/installing-tensorflow-machine-learning-tutorial/)
這是一個可選的教程,用于安裝 TensorFlow。 如果你有 Mac 或者 Linux,你不需要這個教程,只需訪問`TensorFlow.org > get started > pip installation`。 你只需要運行幾個命令,然后就設置好了。 對于 Windows 用戶,你需要使用 Docker 或虛擬機來安裝 TensorFlow。 我選擇虛擬機,因為它很容易,后來可能需要使用雙引導。
對于啟動,TensorFlow 由 Mac 和 Linux 支持,但 Windows 不支持。 如果需要,可以在 Windows 上使用它們的 Docker 發行包。
你可以隨意使用任何你想要的設置,但我個人將在 Windows 機器上的虛擬機上使用 Ubuntu 16.04。 目前,人們要在哪個平臺執行機器學習模型,還是比較不清楚的,所以誰也不知道哪個操作系數最終會成為這個領域的王者。 隨意使用任何你想要使用的方法,這一點不重要,但我仍然簡單通過虛擬機來運行。
首先,下載 [Virtualbox](https://www.virtualbox.org/wiki/Downloads)。 這將允許你虛擬化各種組件,如一些 CPU,GPU 和磁盤空間。 接下來,你需要一個操作系統。 我選擇 [Ubuntu 16.04 64bit](https://www.ubuntu.com/download/alternative-downloads)。 如果你有 64 位處理器,那么你可以運行 64 位的映像,但是你可能需要在 BIOS 設置中啟用硬件虛擬化,這在 BIOS 設置的 CPU 部分顯示。 每個主板是不同的,所以我不能更具體了。 只需在設置和高級設置中查找 CPU 設置選項。
一旦你安裝了 VirtualBox 軟件,以及要使用的操作系統映像,請在 VirtualBox 中單擊“新建”,為新機器命名,選擇操作系統的類型和版本,然后轉到下一個選項。
如果你想看到我的實時選項,你可以觀看視頻。 然而,設置非常簡單。 選擇一個固定大小的硬盤,至少要有 20 GB 的硬盤。 我選擇了 50.VDI。 選擇適配內存的東西。 你仍然需要一些內存留給你的主機,所以不要全部都占了。
一旦你完成了,你可以雙擊虛擬機來嘗試啟動它,你應該得到一個消息,沒有什么可以引導,也沒有任何啟動驅動器。 從這里可以選擇你最近下載的 Ubuntu 安裝映像,并開始安裝過程。 安裝時,你將了解到是否要擦除硬盤驅動器的內容,并替換為 Ubuntu。 可能感覺不舒服,答案是肯定的,那就是你想做的。 這將清除虛擬硬盤上的安裝,而不是實際的硬盤驅動器。
安裝完成后,系統將提示你重啟虛擬機。 重新啟動提示似乎對我沒有太大意義,所以你可以關閉窗口來關閉電源,或者從 GUI 右鍵單擊你的虛擬機,并選擇關閉。
當你關閉虛擬機時,你可以右鍵單擊它,然后進入設置。 在那里,進入系統,并分配多于 cpus(1) 的默認數量。 這些只會在啟動時分配給你的虛擬機,而不是所有時間。 你可能還想為視頻,給自己一些更多的內存。
現在開機,你可能已經注意到你沒有得到很好的解決方案。 你可以運行以下操作來啟用可調整大小的屏幕:
```
sudo apt-get install virtualbox-guest-utils virtualbox-guest-x11 virtualbox-guest-dkms
```
現在,我們準備好在我們的機器上安裝 TensorFlow。 你還需要 Python3,但這是 Ubuntu 16.04 自帶的。 前往 TensorFlow.org,點擊開始,然后在側欄上的`pip installation`。 如果你稍后查看本教程,可能會有所不同。 但是,隨著事情的變化,我會盡力更新這個文本的版本。 所以,在`pip installation`頁面上,指南首先讓我們運行:
```
$ sudo apt-get install python3-pip python3-dev
```
以上在你的終端中運行。 在 Ubuntu 上,你可以按`ctrl + alt + t`使其在 GUI 桌面上出現。 由于我運行的是 64 位版本的 Linux(Ubuntu),有了 Python 3.5,而且想要 CPU 版本,我選擇:
```
# Ubuntu/Linux 64-bit, CPU only, Python 3.5
$ export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.9.0-cp35-cp35m-linux_x86_64.whl
```
之后執行:
```
$ sudo pip3 install --upgrade $TF_BINARY_URL
```
我們完成了。為了測試,我們可以在控制臺中輸入`python3`,并嘗試導入`tensorflow`。 如果工作正常,我們就都設置好了!
我使用 Sublime Text 來編輯 Python 文件。 使用任何你喜歡的 編輯器。在 Ubuntu 上,一旦下載了`.deb`文件,你需要運行:`sudo dpkg -i /path/to/deb/file`,然后`sudo apt-get install -f`。
下一篇教程中,我們打算涉及使用 TensorFlow 的基礎。
## 四十五、深度學習和 TensorFlow 簡介
歡迎閱讀深度學習與神經網絡和 TensorFlow 的第二部分,以及機器學習教程系列的第 44 部分。 在本教程中,我們將介紹一些關于 TensorFlow 的基礎知識,以及如何開始使用它。
像 TensorFlow 和 Theano 這樣的庫不僅僅是深入學習庫,它們是**用于**深入學習的庫。 他們實際上只是數值處理庫,就像 Numpy 一樣。 然而,不同的是,像 TensorFlow 這樣的軟件包使我們能夠以高效率執行特定的機器學習數值處理操作,如巨大的矩陣上的求導。 我們也可以輕松地在 CPU 內核,GPU 內核或甚至多個 GPU 等多個設備上分布式處理。 但這不是全部! 我們甚至可以在具有 TensorFlow 的分布式計算機網絡上分發計算。 所以,雖然 TensorFlow 主要是與機器學習一起使用,但它實際上在其他領域也有使用,因為它真的只是一個龐大的數組操作庫。
什么是張量(tensor)? 到目前為止,在機器學習系列中,我們主要使用向量(numpy 數組),張量可以是一個向量。 最簡單的說,一個張量是一個類似數組的對象,正如你所看到的,一個數組可以容納你的矩陣,你的向量,甚至一個標量。
在這一點上,我們只需要將機器學習問題轉化為張量函數,這可以用每一個 ML 算法來實現。 考慮神經網絡。 神經網絡能夠分解成什么?
我們有數據(`X`),權重(`w`)和閾值(`t`)。 所有這些都是張量嘛? `X`是數據集(一個數組),所以這是一個張量。 權重也是一組權重值,所以它們也是張量。閾值? 與權重相同。 因此,我們的神經網絡確實是`X`,`w`和``t或`f(Xwt)`的函數,所以我們準備完全了,當然可以使用 TensorFlow,但是如何呢?
TensorFlow 的工作方式是,首先定義和描述我們的抽象模型,然后在我們準備好的時候,在會話(session)中成為現實。 在 TensorFlow 術語中,該模型的描述是所謂的“計算圖形”。 我們來玩一個簡單的例子。 首先,我們來構建圖:
```py
import tensorflow as tf
# creates nodes in a graph
# "construction phase"
x1 = tf.constant(5)
x2 = tf.constant(6)
```
所以我們有了一些值。現在,我們可以用這些值做一些事情,例如相乘:
```py
result = tf.mul(x1,x2)
print(result)
```
要注意輸出仍然是個抽象的張量。沒有運行實際計算,只能創建操作。我們的計算圖中的每個操作或“op”都是圖中的“節點”。
要真正看到結果,我們需要運行會話。 一般來說,你首先構建圖形,然后“啟動”圖形:
```py
# defines our session and launches graph
sess = tf.Session()
# runs result
print(sess.run(result))
```
我們也可以將會話的輸出賦給變量:
```py
output = sess.run(result)
print(output)
```
當你完成了一個會話是,你需要關閉它,來釋放所使用的資源。
```py
sess.close()
```
關閉之后,你仍然可以引用`output`變量,但是你不能這樣做了:
```py
sess.run(result)
```
這會返回錯誤另一個選項就是利用 Python 的`with`語句:
```py
with tf.Session() as sess:
output = sess.run(result)
print(output)
```
如果你不熟悉這些操作,它在這些語句所在的代碼塊中使用會話,然后在完成后自動關閉會話,和使用`with`語句打開文件的方法相同。
你還可以在多個設備上使用 TensorFlow,甚至可以使用多臺分布式機器。 在特定 GPU 上運行某些計算的示例是:
```py
with tf.Session() as sess:
with tf.device("/gpu:1"):
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)
```
代碼來自:[TensorFlow 文檔](https://www.tensorflow.org/versions/r0.9/get_started/basic_usage.html#overview)。`tf.matmul`是矩陣乘法函數。
上述代碼將在第二個系統 GPU 上運行計算。 如果你安裝了 CPU 版本,那么這不是一個選項,但是你仍然應該意識到這個可能性。 TensorFlow 的 GPU 版本要求正確設置 CUDA(以及需要支持 CUDA 的 GPU)。 我有幾個支持 CUDA 的 GPU,并希望最終能夠充分使用它們,但這要等到以后了!
現在我們已經有了 TensorFlow 的基礎知識了,下一個教程中我會邀請你,創建一個深度神經網絡的“兔子洞”。 如果你需要安裝 TensorFlow,如果你在 Mac 或 Linux 上,安裝過程非常簡單。 在 Windows 上,也不是很麻煩。 下一個教程是可選的,它只是用于在 Windows 機器上安裝 TensorFlow。
## 四十六、深度學習和 TensorFlow - 創建神經網絡模型
歡迎閱讀深度學習與神經網絡和 TensorFlow 的第三部分,以及機器學習教程系列的第 45 部分。 在本教程中,我們將通過創建我們自己的深度神經網絡(TensorFlow),來進入(下落)的兔子洞。
我們首先使用 MNIST 數據集,該數據集包含 6 萬個手寫和標記數字訓練樣本和 10,000 個的測試樣本,0 到 9,因此共有 10 個“分類”。 我會注意到,這是一個非常小的數據集,就你在任何現實環境中的工作而言,它也應該足夠小到在每個人的電腦上工作。
MNIST 數據集具有圖像,我們將使用純粹的黑色和白色,閾值,圖像,總共 28×28 或 784 像素。 我們的特征是每個像素的像素值,閾值。 像素是“空白”(沒有什么,0),或有東西(1)。 這些是我們的特征。 我們嘗試使用這個非常基本的數據,并預測我們正在查看的數字(0 ~ 9)。 我們希望我們的神經網絡,將以某種方式創建像素之間的關系的內在模型,并且能夠查看數字的新樣例,并且高準確度預測。
雖然這里的代碼不會那么長,但如果你不完全了解應該發生的事情,那么我們可以嘗試凝結我們迄今為止所學到的知識,以及我們在這里會做什么。
首先,我們傳入輸入數據,并將其發送到隱藏層1。因此,我們對輸入數據加權,并將其發送到層1。在那里將經歷激活函數,因此神經元可以決定是否觸發,并將一些數據輸出到輸出層或另一個隱藏層。在這個例子中,我們有三個隱藏層,使之成為深度神經網絡。從我們得到的輸出中,我們將該輸出與預期輸出進行比較。我們使用成本函數(或稱為損失函數)來確定我們的正確率。最后,我們將使用優化器函數,Adam Optimizer。在這種情況下,最小化損失(我們有多錯誤)。成本最小化的方法是通過修改權重,目的是希望降低損失。我們要降低損失的速度由學習率決定。學習率越低,我們學習的速度越慢,我們越有可能獲得更好的結果。學習率越高,我們學習越快,訓練時間更短,也可能會受到影響。當然,這里的收益遞減,你不能只是繼續降低學習率,并且總是做得更好。
通過我們的網絡直接發送數據的行為,意味著我們正在運行前饋神經網絡。 向后調整權重是我們的反向傳播。
我們這樣做是向前和向后傳播,但我們想要多次。 這個周期被稱為一個迭代(epoch)。 我們可以選擇任何數量的迭代,但你可能想要避免太多,這會導致過擬合。
在每個時代之后,我們希望進一步調整我們的權重,降低損失和提高準確性。 當我們完成所有的迭代,我們可以使用測試集進行測試。
清楚了嗎?準備開始了!
```py
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
```
我們導入 TensorFlow 和我們將要使用的樣本數據。 請注意`one_hot`參數。 這個術語來自只有一個元素的點子,在其余元素當中,字面上是“熱”的,或者開啟的。 這對于我們這里的多類分類任務是有用的(0 ~ 9)。 因此,不是簡單的 0 或者 1,我們擁有:
```
0 = [1,0,0,0,0,0,0,0,0]
1 = [0,1,0,0,0,0,0,0,0]
2 = [0,0,1,0,0,0,0,0,0]
3 = [0,0,0,1,0,0,0,0,0]
...
```
好的,所以我們有了數據。 我選擇使用 MNIST 數據集,因為它是一個合適的起始數據集,實際上,收集原始數據并將其轉換為可以使用的東西,比創建機器學習模型本身需要更多的時間,我認為這里大多數人都想學習 神經網絡,而不是網頁抓取和正則表達式。
現在我們要開始構建模型:
```py
n_nodes_hl1 = 500
n_nodes_hl2 = 500
n_nodes_hl3 = 500
n_classes = 10
batch_size = 100
```
我們首先指定每個隱藏層將有多少個節點,我們的數據集有多少份額里,以及我們的批量大小。 雖然你理論上**可以**一次訓練整個網絡,這是不切實際的。 你們中的許多人可能有可以完全處理 MNIST 數據集的計算機,但是大多數人都沒有或可以訪問這種計算機,它們可以一次完成實際大小的數據集。 因此,我們進行批量優化。 在這種情況下,我們進行 100 個批次。
```py
x = tf.placeholder('float', [None, 784])
y = tf.placeholder('float')
```
這些是我們圖中某些值的占位符。 回想一下,你只需在 TensorFlow 圖中構建模型即可。 在這里,TensorFlow 操縱一切,而你不會。 一旦完成,這將更加明顯,你嘗試尋找在哪里修改重量! 請注意,我已經使用`[None,784]`作為第一個占位符中的第二個參數。 這是一個可選參數,然而這樣顯式指定非常有用。 如果你不顯式指定,TensorFlow 會在那里填充任何東西。 如果你的形狀是顯式的,并且一些不同形狀的東西嘗試放進這個變量的地方,TensorFlow 將拋出一個錯誤。
我們現在完成了我們的常量以及其實值。現在我們可以實際構建神經網絡模型了:
```py
def neural_network_model(data):
hidden_1_layer = {'weights':tf.Variable(tf.random_normal([784, n_nodes_hl1])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl1]))}
hidden_2_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl1, n_nodes_hl2])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl2]))}
hidden_3_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl2, n_nodes_hl3])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl3]))}
output_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl3, n_classes])),
'biases':tf.Variable(tf.random_normal([n_classes]))}
```
這里,我們開始定義我們的權重和我們的...等等,這些偏差是什么? 偏差是在通過激活函數之前,與我們的相加的值,不要與偏差節點混淆,偏差節點只是一個總是存在的節點。 這里的偏差的目的主要是,處理所有神經元生成 0 的情況。 偏差使得神經元仍然能夠從該層中觸發。 偏差與權重一樣獨特,也需要優化。
我們迄今所做的一切都是為我們的權重和偏差創建一個起始定義。 對于層的矩陣的應有形狀,這些定義只是隨機值(這是`tf.random_normal`為我們做的事情,它為我們輸出符合形狀的隨機值)。 還沒有發生任何事情,沒有發生流動(前饋)。我們開始流程:
```py
l1 = tf.add(tf.matmul(data,hidden_1_layer['weights']), hidden_1_layer['biases'])
l1 = tf.nn.relu(l1)
l2 = tf.add(tf.matmul(l1,hidden_2_layer['weights']), hidden_2_layer['biases'])
l2 = tf.nn.relu(l2)
l3 = tf.add(tf.matmul(l2,hidden_3_layer['weights']), hidden_3_layer['biases'])
l3 = tf.nn.relu(l3)
output = tf.matmul(l3,output_layer['weights']) + output_layer['biases']
return output
```
在這里,我們將值傳入第一層。 這些值是什么? 它們是原始輸入數據乘以其唯一權重(從隨機開始,但將被優化):`tf.matmul(l1,hidden_2_layer['weights'])`。 然后,我們添加了`tf.add`的偏差。 我們對每個隱藏層重復這個過程,直到我們的輸出,我們的最終值仍然是輸入和權重的乘積,加上輸出層的偏差值。
完成后,我們只需返回該輸出層。 所以現在,我們已經構建了網絡,幾乎完成了整個計算圖形。 在下一個教程中,我們將構建一個函數,使用 TensorFlow 實際運行并訓練網絡。
# 第四十七章 深度學習和 TensorFlow - 神經網絡如何運行
> 原文:[Deep Learning with TensorFlow - Creating the Neural Network Model](https://pythonprogramming.net/tensorflow-neural-network-session-machine-learning-tutorial/)
> 譯者:[飛龍](https://github.com/wizardforcel)
> 協議:[CC BY-NC-SA 4.0](http://creativecommons.org/licenses/by-nc-sa/4.0/)
歡迎閱讀深度學習與神經網絡和 TensorFlow 的第四部分,以及機器學習教程系列的第 46 部分。 在本教程中,我們將在 TensorFlow 中編寫會話期間發生的代碼。
這里的代碼已經更新,以便支持TensorFlow 1.0,但視頻有兩行需要稍微更新。
在前面的教程中,我們構建了人工神經網絡的模型,并用 TensorFlow 建立了計算圖表。 現在我們需要實際建立訓練過程,這將在 TensorFlow 會話中運行。 繼續處理我們的代碼:
```py
def train_neural_network(x):
prediction = neural_network_model(x)
cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=y) )
```
在新的函數`train_neural_network`下,我們傳入數據。 然后,我們通過我們的`neural_network_model`產生一個基于該數據輸出的預測。 接下來,我們創建一個開銷變量,衡量我們有多少錯誤,而且我們希望通過操縱我們的權重來最小化這個變量。 開銷函數是損失函數的代名詞。 為了優化我們的成本,我們將使用`AdamOptimizer`,它是一個流行的優化器,以及其他類似的隨機梯度下降和`AdaGrad`。
```py
optimizer = tf.train.AdamOptimizer().minimize(cost)
```
在`AdamOptimizer()`中,您可以選擇將`learning_rate`指定為參數。默認值為 0.001,這在大多數情況下都不錯。 現在我們定義了這些東西,我們將啟動會話。
```py
hm_epochs = 10
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
```
首先,我們有一個簡單的`hm_epochs`變量,它將確定有多少個迭代(前饋和后退循環)。 接下來,我們使用上一個教程中討論的會話開啟和關閉的語法。 首先,我們初始化所有的變量。這是主要步驟:
```py
for epoch in range(hm_epochs):
epoch_loss = 0
for _ in range(int(mnist.train.num_examples/batch_size)):
epoch_x, epoch_y = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={x: epoch_x, y: epoch_y})
epoch_loss += c
print('Epoch', epoch, 'completed out of',hm_epochs,'loss:',epoch_loss)
```
對于每個迭代,對于我們的數據中的每個批次,我們將針對我們數據批次運行優化器和開銷。 為了跟蹤我們每一步的損失或開銷,我們要添加每個迭代的總開銷。 對于每個迭代,我們輸出損失,每次都應該下降。 這可以用于跟蹤,所以隨著時間的推移,你可以看到收益遞減。 前幾個迭代應該有很大的改進,但是在大約 10 或 20 之間,你會看到很小的變化,或者可能會變得更糟。
現在,在循環之外:
```py
correct = tf.equal(tf.argmax(prediction, 1), tf.argmax(y, 1))
```
這會告訴我們,我們做了多少個預測,它完美匹配它們的標簽。
```py
accuracy = tf.reduce_mean(tf.cast(correct, 'float'))
print('Accuracy:',accuracy.eval({x:mnist.test.images, y:mnist.test.labels}))
```
現在我們擁有了測試集上的最終準確率。現在我們需要:
```py
train_neural_network(x)
```
在 10 到 20 個迭代的某個地方應該有 95% 的準確度。 95% 的準確度,聽起來不錯,但比起更主流的方法,實際上被認為非常糟糕。 我實際上認為 95% 的準確性,這個模型是沒有什么意外的。 考慮到我們給網絡的唯一信息是像素值,就是這樣。 我們沒有告訴它如何尋找模式,或者說如何從 9 中得到一個4 ,或者從 8 中得到一個 1。網絡只是用一個內在的模型來計算出來,純粹是基于像素值來開始,并且達到了 95% 準確性。 對我來說這是驚人的,雖然最先進的技術超過 99%。
目前為止的完整代碼:
```py
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
n_nodes_hl1 = 500
n_nodes_hl2 = 500
n_nodes_hl3 = 500
n_classes = 10
batch_size = 100
x = tf.placeholder('float', [None, 784])
y = tf.placeholder('float')
def neural_network_model(data):
hidden_1_layer = {'weights':tf.Variable(tf.random_normal([784, n_nodes_hl1])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl1]))}
hidden_2_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl1, n_nodes_hl2])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl2]))}
hidden_3_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl2, n_nodes_hl3])),
'biases':tf.Variable(tf.random_normal([n_nodes_hl3]))}
output_layer = {'weights':tf.Variable(tf.random_normal([n_nodes_hl3, n_classes])),
'biases':tf.Variable(tf.random_normal([n_classes])),}
l1 = tf.add(tf.matmul(data,hidden_1_layer['weights']), hidden_1_layer['biases'])
l1 = tf.nn.relu(l1)
l2 = tf.add(tf.matmul(l1,hidden_2_layer['weights']), hidden_2_layer['biases'])
l2 = tf.nn.relu(l2)
l3 = tf.add(tf.matmul(l2,hidden_3_layer['weights']), hidden_3_layer['biases'])
l3 = tf.nn.relu(l3)
output = tf.matmul(l3,output_layer['weights']) + output_layer['biases']
return output
def train_neural_network(x):
prediction = neural_network_model(x)
# OLD VERSION:
#cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(prediction,y) )
# NEW:
cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=y) )
optimizer = tf.train.AdamOptimizer().minimize(cost)
hm_epochs = 10
with tf.Session() as sess:
# OLD:
#sess.run(tf.initialize_all_variables())
# NEW:
sess.run(tf.global_variables_initializer())
for epoch in range(hm_epochs):
epoch_loss = 0
for _ in range(int(mnist.train.num_examples/batch_size)):
epoch_x, epoch_y = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={x: epoch_x, y: epoch_y})
epoch_loss += c
print('Epoch', epoch, 'completed out of',hm_epochs,'loss:',epoch_loss)
correct = tf.equal(tf.argmax(prediction, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct, 'float'))
print('Accuracy:',accuracy.eval({x:mnist.test.images, y:mnist.test.labels}))
train_neural_network(x)
```
下一篇教程中,我們嘗試使用這個準確的模型,并將其應用到一個新的數據集,這對我們來說并沒有準備好。
